day5-subprocess模块
一、概述
实际应用中,有些时候我们不得不跟操作系统进行指令级别的交互,如Linux中的shell。Python中早期通过os模块和commands模块来实现操作系统级别的交互,但从2.4版本开始,官方建议使用subprocess模块。因此对于os和commands模块只会简单讲解,重点会放在subprocess模块和Popen类上。
对于指令的执行,我们一般关注以下两点:
- 命令执行的状态码--表示命令执行是否成功
- 命令执行的输出结果--命令执行成功后的输出
二、os与commands模块
Python中提供了以下几个函数来帮助我们完成命令行指令的执行:
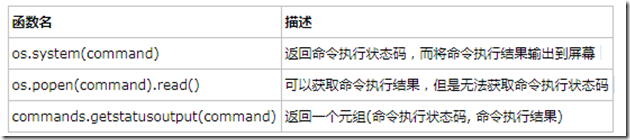
说明:
- os.popen(command)函数得到的是一个文件对象,因此除了read()方法外还支持write()等方法,具体要根据command来定;
- commands模块只存在于Python 2.7中,且不支持windows平台,因此commands模块很少被使用。另外,commands模块实际上也是通过对os.popen()的封装来完成的。
以上内容转载自http://www.cnblogs.com/yyds/p/7288916.html,下面是简单的程序示例:
- os.system()
1 >>> import os
2 >>> os.system('pwd')
3 /root #命令执行结果
4 0 #命令执行状态
5 >>> os.system('pwd1')
6 sh: pwd1: command not found
7 32512
8 >>> res=os.system('wget')
9 wget: missing URL
10 Usage: wget [OPTION]... [URL]...
11
12 Try ‘wget --help’ for more options.
13 >>> res=os.system('redis')
14 sh: redis: command not found #命令执行结果
15 >>> res
16 32512 #命令执行状态上述程序表明,os.system一次性返回命令执行结果和执行状态返回码,如果用变量存储,则需要单独获取状态码。
- os.popen()
创建一个文件对象,需要通过read()方法获取,并且只会返回命令执行结果,没有状态码1 >>> import os
2 >>> os.popen('uptime')
3 <open file 'uptime', mode 'r' at 0x7ff37451cc00>
4 >>> print(os.popen('uptime').read())
5 07:21:57 up 33 days, 2:00, 1 user, load average: 0.00, 0.00, 0.00 - commands.getstatusoutput()
1 >>> import commands
2 >>> commands.getstatusoutput('who')
3 (0, 'root pts/0 2018-03-05 07:15 (172.17.35.6)')
4 >>> commands.getstatusoutput('uptime')
5 (0, ' 07:24:34 up 33 days, 2:02, 1 user, load average: 0.00, 0.00, 0.00')需要注意的是commands模块仅支持linux平台,且在python 3.5版本后不再支持。
三、subprocess模块的常用函数
subprocess模块是关键建议使用的模块,顾名思义是建立一个子进程,用来运行与系统交互的指令。Subporcess模块常用的函数有以下几类: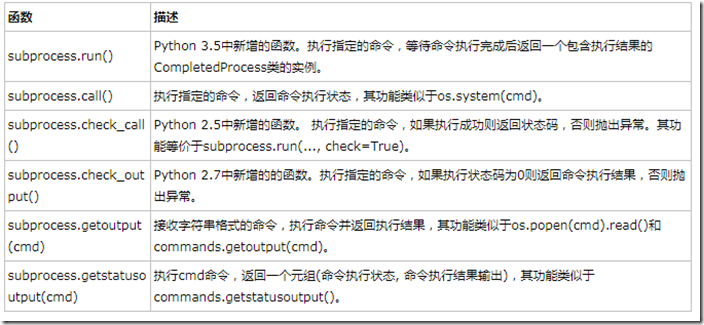
说明:
- 在Python 3.5之后的版本中,官方文档中提倡通过subprocess.run()函数替代其他函数来使用subproccess模块的功能;
- 在Python 3.5之前的版本中,我们可以通过subprocess.call(),subprocess.getoutput()等上面列出的其他函数来使用subprocess模块的功能;
- subprocess.run()、subprocess.call()、subprocess.check_call()和subprocess.check_output()都是通过对subprocess.Popen的封装来实现的高级函数,因此如果我们需要更复杂功能时,可以通过subprocess.Popen来完成。
- subprocess.getoutput()和subprocess.getstatusoutput()函数是来自Python 2.x的commands模块的两个遗留函数。它们隐式的调用系统shell,并且不保证其他函数所具有的安全性和异常处理的一致性。另外,它们从Python 3.3.4开始才支持Windows平台。
上述内容转载自http://www.cnblogs.com/yyds/p/7288916.html
下面详解讲解函数的具体用法。
3.1 subprocess.run()
语法:subprocess.run(args, *, stdin=None, stdout=None, stderr=None, shell=False)
使用说明:这是python 3.5版本才新增出现的函数,用于执行指定的命令,等待命令执行完成后返回一个包含执行结果的CompletedProcess类的实例。
这里重点讲述下shell=False这个参数:
默认情况下这个参数为False,不调用shell本身支持的一些特性(如管道、文件名通配符、环境变量扩展功能)必须以列表形式传递需要执行的命令,第一个元素作为命令,后续的元素作为命令参数;而shell=True参数会让subprocess.call接受字符串类型的变量作为命令,并调用shell去执行这个字符串(可以使用shell的特性了,如管道、文件名通配符、环境变量扩展功能),如果命令使用了shell的分隔符,那么还可以一次性执行多条命令,使用起来很方便。
问题来了,既然shell=True使用更方便,为什么默认值是Flase呢?这是因为万一对传入的命令检查不够仔细,执行了危险的命令比如 rm -rf / 这种那后果会非常严重,而使用shell=False就可以避免这种风险,因此是一种安全机制。
还是上程序把(程序在linux下运行效果更直观):
1 >>> import subprocess
2 >>> subprocess.run(['ls', '-l']) #列表形式传递命令
3 total 28
4 -rw-------. 1 root root 1096 Sep 24 2015 anaconda-ks.cfg
5 -rw-r--r-- 1 root root 238 Jan 11 13:12 history_command
6 -rw-r--r--. 1 root root 8835 Sep 24 2015 install.log
7 -rw-r--r--. 1 root root 3384 Sep 24 2015 install.log.syslog
8 drwxr-xr-x 3 root root 4096 Mar 6 04:55 software
9 CompletedProcess(args=['ls', '-l'], returncode=0)#返回了状态码
10 >>> subprocess.run('ls -l', shell=True)
11 total 28
12 -rw-------. 1 root root 1096 Sep 24 2015 anaconda-ks.cfg
13 -rw-r--r-- 1 root root 238 Jan 11 13:12 history_command
14 -rw-r--r--. 1 root root 8835 Sep 24 2015 install.log
15 -rw-r--r--. 1 root root 3384 Sep 24 2015 install.log.syslog
16 drwxr-xr-x 3 root root 4096 Mar 6 04:55 software
17 CompletedProcess(args='ls -l', returncode=0) #单字符串形式传递命令
18 >>> subprocess.run('ls|wc -l', shell=True)
19 5
20 CompletedProcess(args='ls|wc -l', returncode=0)
21 >>> subprocess.run('ls|wc -l')
22 Traceback (most recent call last):
23 File "<stdin>", line 1, in <module>
24 File "/usr/local/python_3.6.2/lib/python3.6/subprocess.py", line 403, in run
25 with Popen(*popenargs, **kwargs) as process:
26 File "/usr/local/python_3.6.2/lib/python3.6/subprocess.py", line 707, in __init__
27 restore_signals, start_new_session)
28 File "/usr/local/python_3.6.2/lib/python3.6/subprocess.py", line 1333, in _execute_child
29 raise child_exception_type(errno_num, err_msg)
30 FileNotFoundError: [Errno 2] No such file or directory: 'ls|wc -l'
注意:
如果必须使用shell的特性而没有设置shell的参数为Ture,程序会直接报错没有该文件或目录。
3.2 subprocess.call()
语法:subprocess.run(args, *, stdin=None, stdout=None, stderr=None, shell=False)
使用说明:执行指定的命令,返回执行状态返回码,其功能类似于os.system(cmd)。在使用这个函数时,不要使用 stdout=PIPE 或 stderr=PIPE 参数,不然会导致子进程输出的死锁。如果要使用管道,可以在 communicate()方法中使用Popen(网上看到的论述,需要后续实践)
1 >>> import subprocess
2 >>> subprocess.call('ls|wc -l', shell=True) #管道符,必须调用shell才能支持
3 37 #命令执行结果
4 0 #命令执行状态返回码
3.3 subprocess.check_call()
语法:subprocess.check_call(args, *, stdin=None, stdout=None, stderr=None, shell=False)
使用说明:运行由args指定的命令,直到命令执行完成。如果返回码为零,则返回。否则,抛出 CalledProcessError异常。CalledProcessError对象包含有返回码的属性值。
1 >>> import subprocess
2 >>> subprocess.check_call('ls -l', shell=True)
3 total 28
4 -rw-------. 1 root root 1096 Sep 24 2015 anaconda-ks.cfg
5 -rw-r--r-- 1 root root 238 Jan 11 13:12 history_command
6 -rw-r--r--. 1 root root 8835 Sep 24 2015 install.log
7 -rw-r--r--. 1 root root 3384 Sep 24 2015 install.log.syslog
8 drwxr-xr-x 3 root root 4096 Mar 6 04:55 software
9 0返回码
10 >>> subprocess.check_call('ls1', shell=True) #执行出错
11 /bin/sh: ls1: command not found
12 Traceback (most recent call last):
13 File "<stdin>", line 1, in <module>
14 File "/usr/local/python_3.6.2/lib/python3.6/subprocess.py", line 291, in check_call
15 raise CalledProcessError(retcode, cmd)
16 subprocess.CalledProcessError: Command 'ls1' returned non-zero exit status 127.
注意:细心的同学可能会发现程序执行后返回的不只是状态码,还有传递的指令执行的结果,注意命令执行执行的结果是subprocess创建的子进程执行命令后返回的输出,上述几个函数都是这样。何以见得?
1 >>> import subprocess
2 >>> res=subprocess.check_call('ls', shell=True)
3 anaconda-ks.cfg history_command install.log install.log.syslog software
4 >>> res
5 0
3.4 subprocess.check_output()
语法:subprocess.check_output(args, *, stdin=None, stderr=None, shell=False, universal_newlines=False, timeout=None)
使用说明:
Python 2.7中新增的的函数。执行指定的命令,如果执行状态码为0则返回命令执行结果,否则抛出CalledProcessError异常。
universal_newlines参数说明: 该参数影响的是输入与输出的数据格式,比如它的值默认为False,此时stdout和stderr的输出是字节序列;当该参数的值设置为True时,stdout和stderr的输出是字符串。
1 >>> import subprocess
2 >>> subprocess.check_output('ls', shell=True) #默认返回的结果是字节序列
3 b'anaconda-ks.cfg\nhistory_command\ninstall.log\ninstall.log.syslog\nsoftware\n'
4 >>> subprocess.check_output('ls', shell=True, universal_newlines=True) #输出字符串形式
5 'anaconda-ks.cfg\nhistory_command\ninstall.log\ninstall.log.syslog\nsoftware\n'
6 >>> subprocess.check_output('ls1', shell=True, universal_newlines=True) #执行失败
7 /bin/sh: ls1: command not found
8 Traceback (most recent call last):
9 File "<stdin>", line 1, in <module>
10 File "/usr/local/python_3.6.2/lib/python3.6/subprocess.py", line 336, in check_output
11 **kwargs).stdout
12 File "/usr/local/python_3.6.2/lib/python3.6/subprocess.py", line 418, in run
13 output=stdout, stderr=stderr)
14 subprocess.CalledProcessError: Command 'ls1' returned non-zero exit status 127.
注意:
1. 不要在这个函数中使用 stdout=PIPE 或 stderr=PIPE, 否则会造成子进程死锁。如果需要使用管道,可以在 communicate()方法中使用Popen.
2. 如果要捕捉结果中的标准错误,可使用 stderr=subprocess.STDOUT参数,实际测试也只是输出了状态码,并没有给出具体的错误原因信息,待后续验证。
3.5 subprocess.getoutput()
语法:subprocess.getoutput(cmd)
使用说明:接收字符串格式的命令,执行命令并返回执行结果,其功能类似于os.popen(cmd).read()和commands.getoutput(cmd)。
1 >>> import subprocess
2 >>> subprocess.getoutput('ls', shell=True)
3 Traceback (most recent call last):
4 File "<stdin>", line 1, in <module>
5 TypeError: getoutput() got an unexpected keyword argument 'shell' #不再接受其他参数
6 >>>
7 >>> subprocess.getoutput('ls') #纯字符串形式输出结果
8 'anaconda-ks.cfg\nhistory_command\ninstall.log\ninstall.log.syslog\nsoftware'
9 >>> subprocess.getoutput('ls1')
10 '/bin/sh: ls1: command not found'
3.6 subprocess.getstatusoutput()
语法:subprocess.getstatusoutput(cmd)
使用说明:执行cmd命令,返回一个元组(命令执行状态, 命令执行结果输出),其功能类似于commands.getstatusoutput()。
1 >>> import subprocess
2 >>> subprocess.getstatusoutput('ls')
3 (0, 'anaconda-ks.cfg\nhistory_command\ninstall.log\ninstall.log.syslog\nsoftware')
4 >>> subprocess.getstatusoutput('ls1')
5 (127, '/bin/sh: ls1: command not found')
6 >>>
四、subprocess.Popen()
该类用于在一个新的进程中执行一个子程序。前面我们提到过,上面介绍的这些函数都是基于subprocess.Popen类实现的,通过使用这些被封装后的高级函数可以很方便的完成一些常见的需求。由于subprocess模块底层的进程创建和管理是由Popen类来处理的,因此,当我们无法通过上面那些高级函数来实现一些不太常见的功能时就可以通过subprocess.Popen类提供的灵活的api来完成。
1 class subprocess.Popen(args, bufsize=-1, executable=None, stdin=None, stdout=None, stderr=None,
2 preexec_fn=None, close_fds=True, shell=False, cwd=None, env=None, universal_newlines=False,
3 startup_info=None, creationflags=0, restore_signals=True, start_new_session=False, pass_fds=())
参数说明:
•args: 要执行的shell命令,可以是字符串,也可以是命令各个参数组成的序列。当该参数的值是一个字符串时,该命令的解释过程是与平台相关的,因此通常建议将args参数作为一个序列传递。
•bufsize: 指定缓存策略,0表示不缓冲,1表示行缓冲,其他大于1的数字表示缓冲区大小,负数表示使用系统默认缓冲策略。
•stdin, stdout, stderr: 分别表示程序标准输入、输出、错误句柄。 它们的值可以是PIPE, 一个存在的文件描述符(正整数),一个存在的文件对象或 None.
•preexec_fn: 用于指定一个将在子进程运行之前被调用的可执行对象,只在Unix平台下有效。
•close_fds: 如果该参数的值为True,则除了0,1和2之外的所有文件描述符都将会在子进程执行之前被关闭。
•shell: 该参数用于标识是否使用shell作为要执行的程序,如果shell值为True,则建议将args参数作为一个字符串传递而不要作为一个序列传递。
•cwd: 如果该参数值不是None,则该函数将会在执行这个子进程之前改变当前工作目录。
•env: 用于指定子进程的环境变量,如果env=None,那么子进程的环境变量将从父进程中继承。如果env!=None,它的值必须是一个映射对象。
•universal_newlines: 如果该参数值为True,则该文件对象的stdin,stdout和stderr将会作为文本流被打开,否则他们将会被作为二进制流被打开。
•startupinfo和creationflags: 这两个参数只在Windows下有效,它们将被传递给底层的CreateProcess()函数,用于设置子进程的一些属性,如主窗口的外观,进程优先级等
4.1 Popen类的常用方法
Open类的常用方法大概可分为两类,一类是与子进程进行交互的方法,如stdin,stdout,stderr,communicate,kill,terminate,send_signal,另外一类是获取子进程的状态信息,如pid,poll,下面逐一展开它们的用法:
- stdin
stdin实现向子进程的输入。1 >>> import subprocess
2 >>> p1=subprocess.Popen(['python'], stdin=subprocess.PIPE, stdout=subprocess.PIP
3 E, stderr=subprocess.PIPE)
4 >>>
5 >>>
6 >>> p1.stdin.write("print('Hello World!')")
7 Traceback (most recent call last):
8 File "<stdin>", line 1, in <module>
9 TypeError: a bytes-like object is required, not 'str'
10 >>> p1=subprocess.Popen(['python'], stdin=subprocess.PIPE, stdout=subprocess.PIP
11 E, stderr=subprocess.PIPE, universal_newlines=True)
12 >>>
13 >>> p1.stdin.write("print('Hello World!')")
14 21
15 >>> out,err=p1.communicate()
16 >>> p1.stdin.close()
17 >>> print(out)
18 Hello World!
19注意上述示例程序中的universal_newlines=True参数,不使用该参数输入时会提示输入的对象必须是二进制类型的,使用后才能直接输入文本流。
communicate在下文单独讲述。 - stdout
stdout捕获子进程的输出1 import subprocess
2
3 p1 = subprocess.Popen(['dir'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True, shell=True)
4 print(p1.stdout.read())
5
6 输出:
7 驱动器 D 中的卷是 本地磁盘
8 卷的序列号是 6651-23F0
9
10 D:\python\S13\Day5\test 的目录
11
12 2018/03/10 08:07 <DIR> .
13 2018/03/10 08:07 <DIR> ..
14 2017/12/26 07:43 8 1.txt
15 2017/12/26 06:32 374 2.py
16 ...注意:在windows平台下运行类似程序时,由于很多命令都是cmd.exe支持的,因此需要加上shell=True参数,否则会提示找不到文件。
- stderr
stderr用于捕获子进程的错误输出,前提是程序本身没有语法错误,能正常进入到子程序执行环节1 import subprocess
2
3 p1 = subprocess.Popen(['dir 1'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True, shell=True)
4 print(p1.stderr.read())
5
6 输出:
7 '"dir 1"' 不是内部或外部命令,也不是可运行的程序
8 或批处理文件。 - commucate()与死锁问题
诚然,上面讲述的讲述的stdin,stdout,stderr也能完成与子进程的一些必要交互(输入,捕获输出好,捕获错误),他们都通过PIPE管道来进行处理,大致流程如下: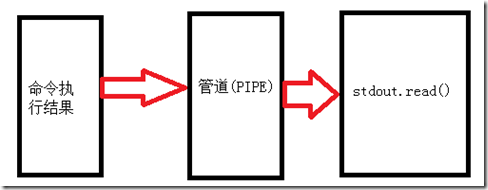
由于PIPE本质上是问文本流提供一个缓冲区,其容量是有限的,因此比较安全的做法是及时清理管道的内容,以避免可能的死锁问题。
死锁问题:
如果你使用了管道,而又不去处理管道的输出,那么小心点,如果子进程输出数据过多,死锁就会发生了,比如下面的用法:
p=subprocess.Popen("longprint", shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT) p.wait()
longprint是一个假想的有大量输出的进程,那么在我的xp, Python2.5的环境下,当输出达到4096时,死锁就发生了。当然,如果我们用p.stdout.readline或者p.communicate去清理输出,那么无论输出多少,死锁都是不会发生的。或者我们不使用管道,比如不做重定向,或者重定向到文件,也都是可以避免死锁的。
官方文档里推荐使用Popen.communicate()。这个方法会把输出放在内存,而不是管道里,所以这时候上限就和内存大小有关了,一般不会有问题。而且如果要获得程序返回值,可以在调用Popen.communicate()之后取Popen.returncode的值。
p.communicate()会立即阻塞父进程,直到子进程执行完毕,在不超过内存情况下还能避免wait()阻塞父进程可能带来的死锁问题,因此一般情况下推荐使用(子进程输出不超过内存大小)。
它本身附带input和timeout参数,它的输出是一个包含标准输出和错误输出的元组(stdout,stderr),我们一般使用out,err=p.communicate()来分别处理stdout和stderr。1 import subprocess
2
3 p1 = subprocess.Popen(['python'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True)
4 p1.communicate(input="print('Hello world!')")
5 out,err=p1.communicate()
6 print(p1.communicate())
7 print(out)
8
9 输出:
10 ('Hello world!\n', '')
11 Hello world!
12捕获错误输出:
1 >>> import subprocess
2 >>> p1 = subprocess.Popen(['ls','007'], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True)
3 >>> out,err=p1.communicate()
4 >>> print(err)
5 ls: cannot access 007: No such file or directory如果子进程输出过多,还是要考虑通过文件来接收输出,方法是把stdout指向一个open好的具备写权限的文件对象(还记得stdin,stdout,stderr就是相应的句柄吗)即可:
1 >>> import subprocess
2 >>> file = open('file.log', encoding='utf-8', mode='a')
3 >>> p1 = subprocess.Popen('ping -c 10 baidu.com', stdin=subprocess.PIPE, stdout=file, stderr=subprocess.PIPE, universal_newlines=True, shell=True)
4 >>> print(p1.communicate())
5 (None, '')
6 >>> quit()
7 [root@test211 ~]# ls -ltr
8 total 32
9 -rw-r--r--. 1 root root 3384 Sep 24 2015 install.log.syslog
10 -rw-r--r--. 1 root root 8835 Sep 24 2015 install.log
11 -rw-------. 1 root root 1096 Sep 24 2015 anaconda-ks.cfg
12 -rw-r--r-- 1 root root 238 Jan 11 13:12 history_command
13 drwxr-xr-x 3 root root 4096 Mar 6 04:55 software
14 -rw-r--r-- 1 root root 818 Mar 11 07:10 file.log
15 [root@test211 ~]# cat file.log
16 PING baidu.com (111.13.101.208) 56(84) bytes of data.
17 64 bytes from 111.13.101.208: icmp_seq=1 ttl=52 time=43.7 ms
18 64 bytes from 111.13.101.208: icmp_seq=2 ttl=52 time=42.4 ms
19 64 bytes from 111.13.101.208: icmp_seq=3 ttl=52 time=43.1 ms
20 64 bytes from 111.13.101.208: icmp_seq=4 ttl=52 time=43.6 ms
21 64 bytes from 111.13.101.208: icmp_seq=5 ttl=52 time=43.5 ms
22 64 bytes from 111.13.101.208: icmp_seq=6 ttl=52 time=43.7 ms
23 64 bytes from 111.13.101.208: icmp_seq=7 ttl=52 time=43.4 ms
24 64 bytes from 111.13.101.208: icmp_seq=8 ttl=52 time=42.4 ms
25 64 bytes from 111.13.101.208: icmp_seq=9 ttl=52 time=43.6 ms
26 64 bytes from 111.13.101.208: icmp_seq=10 ttl=52 time=43.6 ms
27
28 --- baidu.com ping statistics ---
29 10 packets transmitted, 10 received, 0% packet loss, time 9058ms
30 rtt min/avg/max/mdev = 42.437/43.349/43.760/0.479 ms这方面的示例还比较粗浅,实际场景的用法,还有待后续实践深入。
- poll()
定时检查子进程是否已结束,结束则返回0,反之返回None1 >>> import subprocess
2 >>> p1 = subprocess.Popen(["ping -c 10 baidu.com"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True, shell=True)
3 >>> print(p1.poll())
4 None #子进程未结束
5 >>> print(p1.poll())
6 0 #子进程已结束 - wait()
阻塞父进程,等待子进程结束,并返回子进程执行状态码1 >>> import subprocess
2 >>> p1 = subprocess.Popen(["ping -c 10 baidu.com"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True, shell=True)
3 >>> p1.wait()
4 0
5 >>> import subprocess
6 >>> p2 = subprocess.Popen(["sleep 15;ls 007"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True, shell=True)
7 >>> p2.wait()
8 2
9 >>> p3 = subprocess.Popen(["sleep 15;pwd1"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True, shell=True)
10 >>> p3.wait()
11 127从上述程序可看出,返回的子进程状态码,非0代表执行失败。
- pid()
返回父进程的pid,即发起Popen的进程,注意并非发起的子进程1 >>> import subprocess
2 >>> p1 = subprocess.Popen(["ping -c 5 baidu.com"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True, shell=True)
3 >>> print(p1.pid)
4 4219
5
6 查看pid的进程
7 [root@test211 ~]# ps -ef|grep 4219
8 root 4219 4218 0 21:37 pts/0 00:00:00 [ping] <defunct>
9 root 4223 4150 0 21:38 pts/1 00:00:00 grep --color 4219这里需要注意的是,子进程的命令执行完毕,父进程不会自己结束,感兴趣的同学可以持续观察ps -ef的输出
- kill()
杀死子进程,注意发起Popen的父进程不受影响。对比测试:
正常执行子进程的命令:1 import subprocess
2 p1 = subprocess.Popen('ping -n 5 baidu.com', stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True, shell=True)
3 out,error=p1.communicate()
4 print(p1.pid)
5 print(out)
6
7 输出:
8 9060
9
10 正在 Ping baidu.com [111.13.101.208] 具有 32 字节的数据:
11 来自 111.13.101.208 的回复: 字节=32 时间=33ms TTL=55
12 来自 111.13.101.208 的回复: 字节=32 时间=33ms TTL=55
13 来自 111.13.101.208 的回复: 字节=32 时间=34ms TTL=55
14 来自 111.13.101.208 的回复: 字节=32 时间=69ms TTL=55
15 来自 111.13.101.208 的回复: 字节=32 时间=33ms TTL=55
16
17 111.13.101.208 的 Ping 统计信息:
18 数据包: 已发送 = 5,已接收 = 5,丢失 = 0 (0% 丢失),
19 往返行程的估计时间(以毫秒为单位):
20 最短 = 33ms,最长 = 69ms,平均 = 40ms调用kill()方法后:
1 import subprocess
2 p1 = subprocess.Popen('ping -n 5 baidu.com', stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True, shell=True)
3 p1.kill()
4 out,error=p1.communicate()
5 print(p1.pid)
6 print(out)
7
8 输出:(只能获取到pid,子进程没有任何输出了)
9 9144 - terminate()
终止子进程 p ,等于向子进程发送 SIGTERM 信号。1 import subprocess
2 p1 = subprocess.Popen('ping -n 5 baidu.com', stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True, shell=True)
3 p1.terminate() #终止子进程
4 out,error=p1.communicate()
5 print(p1.pid)
6 print(out)
7
8 输出:(没有子进程的任何输出了)
9 7448 - send_signal()
向子进程发送信号,Linux下有用。以后用到再说把。 - returncode
返回子进程的执行状态码,相当于Linux下的$?,便于判断子进程命令是否执行成功。0表示子进程命令执行ok,非0表示执行有误。1 >>> import subprocess
2 >>> p1 = subprocess.Popen('ping -c 5 baidu.com', stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True, shell=True)
3 >>> print(p1.returncode)
4 None
5 >>> out,error=p1.communicate()
6 >>> print(p1.returncode)
7 0
8 >>> p2 = subprocess.Popen('ping1 -c 5 baidu.com', stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True, shell=True)
9 >>> out,error=p2.communicate()
10 >>> print(p2.returncode)
11 127
12 >>>
实际应用中,可能还存在处理异步subprocess的需求,到时再深入学习了。
day5-subprocess模块的更多相关文章
- python3.x Day5 subprocess模块!!
subprocess模块: # subprocess用来替换多个旧模块和函数 os.system os.spawn* os.popen* popen2.* commands.* subprocess简 ...
- Python学习-day5 常用模块
day5主要是各种常用模块的学习 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 conf ...
- python学习道路(day7note)(subprocess模块,面向对象)
1.subprocess模块 因为方法较多我就写在code里面了,后面有注释 #!/usr/bin/env python #_*_coding:utf-8_*_ #linux 上调用python脚 ...
- Python 之路 Day5 - 常用模块学习
本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 configpars ...
- subprocess模块
subprocess的目的就是启动一个新的进程并且与之通信. subprocess模块中只定义了一个类: Popen.可以使用Popen来创建进程,并与进程进行复杂的交互.它的构造函数如下: subp ...
- subprocess模块还提供了很多方便的方法来使得执行 shell 命令
现在你可以看到它正常地处理了转义. 注意 实际上你也可以在shell=False那里直接使用一个单独的字符串作为参数, 但是它必须是命令程序本身,这种做法和在一个列表中定义一个args没什么区别.而如 ...
- Python subprocess模块学习总结
从Python 2.4开始,Python引入subprocess模块来管理子进程,以取代一些旧模块的方法:如 os.system.os.spawn*.os.popen*.popen2.*.comman ...
- Python 线程池的原理和实现及subprocess模块
最近由于项目需要一个与linux shell交互的多线程程序,需要用python实现,之前从没接触过python,这次匆匆忙忙的使用python,发现python确实语法非常简单,功能非常强大,因为自 ...
- python笔记之subprocess模块
python笔记之subprocess模块 [TOC] 从Python 2.4开始,Python引入subprocess模块来管理子进程,以取代一些旧模块的方法:如 os.system.os.spaw ...
- python 学习day5(模块)
一.模块介绍 模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能 ...
随机推荐
- Protobuf 数据类型
.proto Type Notes C++ Type Java Type double double double float float float int32 Uses var ...
- log4j的配置和使用
日志记录 在应用程序中添加日志记录总的来说基于三个目的: 监视代码中变量的变化情况,周期性的记录到文件中供其他应用进行统计分析工作: 跟踪代码运行时轨迹,作为日后审计的依据:担当集成开发环境中的调试器 ...
- Codeforces Round #412 (rated, Div. 2, base on VK Cup 2017 Round 3) D - Dynamic Problem Scoring
地址:http://codeforces.com/contest/807/problem/D 题目: D. Dynamic Problem Scoring time limit per test 2 ...
- spark2.10安装部署(集成hadoop2.7+)
这里默认你的hadoop是已经安装好的,master是node1,slaver是node2-3,hdfs启动在node1,yarn启动在node2,如果没安装好hadoop可以看我前面的文章 因为这里 ...
- win7 eclipse设置Courier New字体
win7系统 1.控制面板-->字体.找到Courier New 字体,右键->显示,这种字体就开始变亮了. 2.eclipse里设置: windows-->Preferences- ...
- springmvc获取bean
1.普通注解方式获取 2.springcontextholder获取 ChatHistoryService chatHistoryService = SpringContextHolder.getBe ...
- 详解Java中的clone方法 -- 原型模式
转自: http://blog.csdn.net/zhangjg_blog/article/details/18369201 Java中对象的创建 clone顾名思义就是复制, 在Java语言中, ...
- JS正则表达式从入门到入土(7)—— 分组
分组 在使用正则的时候,有时候会想要匹配一串字符串连续出现多次的情况,比如:我想匹配字符串Byron连续出现3次的情况. 有些人会直接写: Byron{3} 但是,这种情况仅仅会匹配Byro加上三个n ...
- F1Book报表在Win7下运行出现显示不完整问题
Q: Win7环境下,明明报表要显示20多行,可是显示18行,即显示不完全情况(或常常出现报表底部内容不见了,fe:最后的签名或备注消失了)?? A:只要更新Vcf132.ocx即可. 操 ...
- Java实现:服务端登录系统并跳转到系统内的指定页面(不调用浏览器)
Java实现:服务端登录系统并跳转到系统内的指定页面(不调用浏览器) 1,思路:根据爬虫思想: 2,代码: /** * ClassName:AuthFr * Function: TODO * Reas ...