Http协议原理解析第一篇
一:http的由来:
OSI模型把网络通信分成七层:物理层、数据链路层、网络层、传输层、会话层、表示层和应用层,对于开发网络应用人员来说,一般把网络分成五层,这样比较容易理解。这五层为:物理层、数据链路层、网络层、传输层和应用层(最顶层),下面是一张网络分层的图片(来源于网络):

网络中的计算机互相通信就是实现了层与层之间的通信,要实现层与层之间的通信,则各层都要遵守规则,这样才能完成更好的通信, 我们就把它们之间遵守的规则就叫个“协议”,然而网络上的五层之间遵守的协议不一样,每层都有各自的协议。下面就由下至上的讲述每层的协议
物理层:物理层是五层模型中的最底层,物理层为计算机之间的数据通信提供了传输媒体和互连设备,为数据传输提供了可靠的环境,媒体包括电缆、光纤、无线信道等,互连设备指是计算机和调制解调器之间的互连设备,如各种插头、插座等。该层的作用是透明的传输比特流(即二进制流),为数据链路层提供一个传输原始比特流的物理连接
数据链路层:数据链路层是模型中的第2层,该层对接受到物理层传输过来的比特流进行分组,一组电信号构成的数据包,就叫做"帧",数据链链路层就是来传输以"帧"为单位的数据包,把数据传递给上一层(网络层),帧数据由两部分组成:帧头和帧数据,帧头包括接受方物理地址(就是网卡的地址)和其他的网络信息,帧数据就是要传输的数据体。数据帧的最长为1500字节,如果数据很长,就必须分割成多个帧进行发送。
网络层:
该层通过寻址(寻址地址)来建立两个节点之间的连接,大家都知道我们的电脑连接上网络后都一个IP地址,我们可以通过IP地址来确定不同的计算机是否在同一个子网路。如果我们的电脑连接上网络后就有两种地址:物理地址和网络地址(IP地址),网络上的计算机要通信,必须要知道通信的计算机“在哪里”, 首先通过网络地址来判断是否处于同一个子网络,然后再对物理地址(MAC)地址进行处理,从而准确确定要通信计算机的位置。
在网络层中有我们熟悉的IP协议(即规定网络地址的协议),目前广泛采用的是IP协议第四版(IPv4),这个版本规定,网络地址由32位二进制位组成。我们可以自己配置IP地址也可以自动获得的方式得到IP地址,Ip地址分成两部分,前24位代表网络,后8位代表主机号, 如192.168.254.1和192.168.254.2就处于同一个子网络里,因为这两个IP地址的前24位相同。
网络层中以IP数据包的形式来传递数据,IP数据包也包括两部分:头(Head)和数据(Data),IP数据包放进数据帧中的数据部分进行传输。
传输层:
通过MAC和IP地址,我们可以找到互联网上任意两台主机来建立通信。然而这里有一个问题,找到主机后,主机上有很多程序都需要用到网络,比如说你在一边听歌和好用QQ聊天, 当网络上发送来一个数据包时, 是怎么知道它是表示聊天的内容还是歌曲的内容的, 这时候就需要一个参数来表示这个数据包是发送给那个程序(进程)来使用的,这个参数我们就叫做端口号,主机上用端口号来标识不同的程序(进程),端口是0到65535之间的一个整数,0到1023的端口被系统占用,用户只能选择大于1023的端口。
传输层的功能就是建立端口到端口的通信,网络层就是建立主机与主机的通信,这样如果我们确定了主机和端口,这样就可以实现程序之间的通信了。我们所说的Socket编程就是通过代码来实现传输层之间的通信。因为初始化Socket类对象要指定IP地址和端口号。
在传输层有两个非常重要的协议:UDP 协议和TCP协议
采用UDP协议话传输的就是UDP数据包,同样UDP数据包也由头和数据两部分组成,头部分主要标识了发送端口和接受端口,数据部分就是具体的内容信息。同样UDP数据包是放入IP数据包中的"数据"部分,IP数据包再放入数据帧中在网络上传输。
由于UDP协议的可靠性差(数据发送后无法确定对方是否收到),所以又定义了一个可靠性高的协议——TCP协议,TCP协议采取了握手的方式要确保对方收到了数据。
应用层:应用层是模型中的最顶层,是用户与网络的接口,该层通过应用程序来完成网络用户的应用需求。该层的数据放在TCP数据包的数据部分,该层定义了一个很重要的协议——Http协议,我们一般的Web开发都是基于应用层的开发, 所以后面专题将会和大家介绍下Http协议。
既然知道http是大家在应用层的一个协议比如我们浏览网页什么的就是http应用IOS上层也是基于http的协议比较简单些,效率高灵活的比较难。
二:HTTP协议如何工作
大家都知道一般的通信流程:首先客户端发送一个请求(request)给服务器,服务器在接收到这个请求后将生成一个响应(response)返回给客户端。
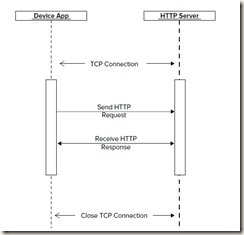
1. Request和Response的格式
Request格式:
HTTP请求行
(请求)头
空行
可选的消息体
注:请求行和标题必须以<CR><LF> 作为结尾(也就是,回车然后换行)。空行内必须只有<CR><LF>而无其他空格。在HTTP/1.1 协议中,所有的请求头,除Host外,都是可选的。
实例:
GET / HTTP/1.1
Host: gpcuster.cnblogs.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Connection: keep-alive
If-Modified-Since: Mon, 25 May 2009 03:19:18 GMT
Response格式:
HTTP状态行
(应答)头
空行
可选的消息体
实例:
HTTP/1.1 200 OK
Cache-Control: private, max-age=30
Content-Type: text/html; charset=utf-8
Content-Encoding: gzip
Expires: Mon, 25 May 2009 03:20:33 GMT
Last-Modified: Mon, 25 May 2009 03:20:03 GMT
Vary: Accept-Encoding
Server: Microsoft-IIS/7.0
X-AspNet-Version: 2.0.50727
X-Powered-By: ASP.NET
Date: Mon, 25 May 2009 03:20:02 GMT
Content-Length: 12173
消息体的内容(略)
2. 建立连接的方式
HTTP支持2中建立连接的方式:非持久连接和持久连接(HTTP1.1默认的连接方式为持久连接)。
1) 非持久连接
让我们查看一下非持久连接情况下从服务器到客户传送一个Web页面的步骤。假设该贝面由1个基本HTML文件和10个JPEG图像构成,而且所有这些对象都存放在同一台服务器主机中。再假设该基本HTML文件的URL为:gpcuster.cnblogs.com/index.html。
下面是具体步骡:
1.HTTP客户初始化一个与服务器主机gpcuster.cnblogs.com中的HTTP服务器的TCP连接。HTTP服务器使用默认端口号80监听来自HTTP客户的连接建立请求。
2.HTTP客户经由与TCP连接相关联的本地套接字发出—个HTTP请求消息。这个消息中包含路径名/somepath/index.html。
3.HTTP服务器经由与TCP连接相关联的本地套接字接收这个请求消息,再从服务器主机的内存或硬盘中取出对象/somepath/index.html,经由同一个套接字发出包含该对象的响应消息。
4.HTTP服务器告知TCP关闭这个TCP连接(不过TCP要到客户收到刚才这个响应消息之后才会真正终止这个连接)。
5.HTTP客户经由同一个套接字接收这个响应消息。TCP连接随后终止。该消息标明所封装的对象是一个HTML文件。客户从中取出这个文件,加以分析后发现其中有10个JPEG对象的引用。
6.给每一个引用到的JPEG对象重复步骡1-4。
上述步骤之所以称为使用非持久连接,原因是每次服务器发出一个对象后,相应的TCP连接就被关闭,也就是说每个连接都没有持续到可用于传送其他对象。每个TCP连接只用于传输一个请求消息和一个响应消息。就上述例子而言,用户每请求一次那个web页面,就产生11个TCP连接。
2) 持久连接
非持久连接有些缺点。首先,客户得为每个待请求的对象建立并维护一个新的连接。对于每个这样的连接,TCP得在客户端和服务器端分配TCP缓冲区,并维持TCP变量。对于有可能同时为来自数百个不同客户的请求提供服务的web服务器来说,这会严重增加其负担。其次,如前所述,每个对象都有2个RTT的响应延长——一个RTT用于建立TCP连接,另—个RTT用于请求和接收对象。最后,每个对象都遭受TCP缓启动,因为每个TCP连接都起始于缓启动阶段。不过并行TCP连接的使用能够部分减轻RTT延迟和缓启动延迟的影响。
在持久连接情况下,服务器在发出响应后让TCP连接继续打开着。同一对客户/服务器之间的后续请求和响应可以通过这个连接发送。整个Web页面(上例中为包含一个基本HTMLL文件和10个图像的页面)自不用说可以通过单个持久TCP连接发送:甚至存放在同一个服务器中的多个web页面也可以通过单个持久TCP连接发送。通常,HTTP服务器在某个连接闲置一段特定时间后关闭它,而这段时间通常是可以配置的。持久连接分为不带流水线(without pipelining)和带流水线(with pipelining)两个版本。如果是不带流水线的版本,那么客户只在收到前一个请求的响应后才发出新的请求。这种情况下,web页面所引用的每个对象(上例中的10个图像)都经历1个RTT的延迟,用于请求和接收该对象。与非持久连接2个RTT的延迟相比,不带流水线的持久连接已有所改善,不过带流水线的持久连接还能进一步降低响应延迟。不带流水线版本的另一个缺点是,服务器送出一个对象后开始等待下一个请求,而这个新请求却不能马上到达。这段时间服务器资源便闲置了。
HTTP/1.1的默认模式使用带流水线的持久连接。这种情况下,HTTP客户每碰到一个引用就立即发出一个请求,因而HTTP客户可以一个接一个紧挨着发出各个引用对象的请求。服务器收到这些请求后,也可以一个接一个紧挨着发出各个对象。如果所有的请求和响应都是紧挨着发送的,那么所有引用到的对象一共只经历1个RTT的延迟(而不是像不带流水线的版本那样,每个引用到的对象都各有1个RTT的延迟)。另外,带流水线的持久连接中服务器空等请求的时间比较少。与非持久连接相比,持久连接(不论是否带流水线)除降低了1个RTT的响应延迟外,缓启动延迟也比较小。其原因在于既然各个对象使用同一个TCP连接,服务器发出第一个对象后就不必再以一开始的缓慢速率发送后续对象。相反,服务器可以按照第一个对象发送完毕时的速率开始发送下一个对象。
3. 缓存的机制
HTTP/1.1中缓存的目的是为了在很多情况下减少发送请求,同时在许多情况下可以不需要发送完整响应。前者减少了网络回路的数量;HTTP利用一个“过期(expiration)”机制来为此目的。后者减少了网络应用的带宽;HTTP用“验证(validation)”机制来为此目的。
HTTP定义了3种缓存机制:
l Freshness allows a response to be used without re-checking it on the origin server, and can be controlled by both the server and the client. For example, the Expires response header gives a date when the document becomes stale, and the Cache-Control: max-age directive tells the cache how many seconds the response is fresh for.
l Validation can be used to check whether a cached response is still good after it becomes stale. For example, if the response has a Last-Modified header, a cache can make a conditional request using the If-Modified-Since header to see if it has changed.
l Invalidation is usually a side effect of another request that passes through the cache. For example, if URL associated with a cached response subsequently gets a POST, PUT or DELETE request, the cached response will be invalidated.
4. 响应授权激发机制
这些机制能被用于服务器激发客户端请求并且使客户端授权。
详细的信息请参考:RFC 2617: HTTP Authentication: Basic and Digest Access
- 5. 基于HTTP的应用
- 多线程下载
- 下载工具开启多个发出HTTP请求的线程
- 每个http请求只请求资源文件的一部分:Content-Range: bytes 20000-40000/47000
- 合并每个线程下载的文件
- HTTPS传输协议原理
- 两种基本的加解密算法类型

- 通信过程:
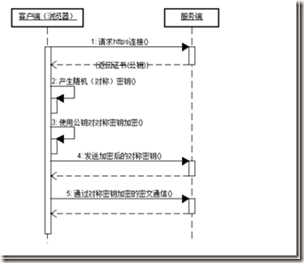
优点:
- 客户端产生的密钥只有客户端和服务器端能得到
- 加密的数据只有客户端和服务器端才能得到明文
- 客户端到服务端的通信是安全的
- 服务器和客户端交互:
- 身份认证
- cookie
- http请求的几个方法:

- 我们经常会遇到这个问题GET和POST的区别
我们看看GET和POST的区别
1. GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的Body中.
2. GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
3. GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值。
4. GET方式提交数据,会带来安全问题,比如一个登录页面,通过GET方式提交数据时,用户名和密码将出现在URL上,如果页面可以被缓存或者其他人可以访问这台机器,就可以从历史记录获得该用户的账号和密码.
由于篇幅问题接下来再分章节介绍
Http协议原理解析第一篇的更多相关文章
- 3D游戏常用技巧Normal Mapping (法线贴图)原理解析——高级篇
1.概述 上一篇博客,3D游戏常用技巧Normal Mapping (法线贴图)原理解析——基础篇,讲了法线贴图的基本概念和使用方法.而法线贴图和一般的纹理贴图一样,都需要进行压缩,也需要生成mipm ...
- 入木三分学网络第一篇--VRRP协议详解第一篇(转)
因为keepalived使用了VRRP协议,所有有必要熟悉一下. 虚拟路由冗余协议(Virtual Router Redundancy Protocol,简称VRRP)是解决局域网中配置静态网关时,静 ...
- Coap协议学习笔记-第一篇
1. 物联网应用上一般使用单片机(或者其他SOC),单片机的RAM内存一般只有20KB~~128KB左右,然而一个TCP协议栈可能就20KB,所以只能用UDP,因为UDP相对小很多,然后在UDP上加了 ...
- HTTPS协议原理解析
一.对称加密与非对称加密 1,定义: 对称加密:加密和解密的秘钥使用的是同一个. 非对称加密:与对称加密算法不同,非对称加密算法需要两个密钥:公开密钥(publickey)和私有密钥(privatek ...
- IT创业失败案例解析 - 第一篇
创业启示录:创业失败报告这个系列包括30多家创业公司的失败案例分析.本文就有由其中一家IT创业公司的CTO所撰写.还是那句老话,成功的故事固然非常鼓舞人心,但我们也可以从失败故事中学到很多. 以下是译 ...
- ASP.NET WebAPI框架解析第一篇
ASP.NET WebAPI有两种寄宿模式,一种是WebHost,一种是SelfHost,为什么可以有两种模式的原因在于WebAPI有一个相对独立的消息处理管道,只要给这个消息管道传递一个封装好的对象 ...
- 基于GBT28181:SIP协议组件开发-----------第一篇环境搭建
原创文章,引用请保证原文完整性,尊重作者劳动,原文地址http://www.cnblogs.com/qq1269122125/p/3930018.html,qq:1269122125. SIP协议在安 ...
- Apktool源码解析——第一篇
著名的apktool是android逆向界用的最普遍的一个工具,这个项目的原始地址在这里http://code.google.com/p/android-apktool/,但是你们都懂的在天朝谷歌是无 ...
- Java-XML解析第一篇主流开源类库解析XML
1.流行的XML解析框架 1>底层解析方式:存在编码复杂性.难扩展.难复用.....想了解底层解析方式请参考:浅谈 Java XML 底层解析方式 2>Dom4j:基于 JAXP 解析方式 ...
随机推荐
- Dev属性设置
DisplayFormat 设置显示格式如:{0:P}表示显示为百分号模式.如数据源中为0.5.表示出来为50% 2.GridContro总合计及分组合计: 常规总合计直接RunDesigner-Gr ...
- spring in action 7.1 小结
0 AbstractAnnotationConfigDispatcherServletInitializer剖析,在Servlet 3.0环境中,容器会在类路径中查找实现ServletContaine ...
- Angularjs Directive - Compile vs. Link
如果我想实现这样一个功能,当一个input失去光标焦点时(blur),执行一些语句,比如当输入用户名后,向后台发ajax请求查询用户名是否已经存在,好有及时的页面相应. 输入 hellobug 失去 ...
- Qt 积累
总结(-) 1> 定时器的使用 QTimer *timer = new QTimer(this); connect(timer, SIGNAL(timeout()), this, SLOT(u ...
- 应用SVN比较文件定位修改
用SVN checkout一个版A本到一个目录中,再从别的地方找到版本B复制到版本A所在的目录中,选择复制和替换,再要比较的文件上右键-->SVN-->diff
- win32环境下显示中文
//编码转换 //#if (CC_TARGET_PLATFORM == CC_PLATFORM_WIN32) // string title = "成绩"; // GBK2UTF8 ...
- Python3制作中文词云图
1. 准备好文本数据 2. pip install jieba 3. pip install wordcloud 4. 下载字体例如Songti.ttc(mac系统下的称呼,并将字体放在项目文件夹下) ...
- 在编写JSP的时候出现XXX cannot be resolved to a type
今天遇到这个情况,却发现是eclipse抽风,说javax.servlet.http.Cookie找不到定义,但是经过浏览器测试,可以运行,而JSP源文件中eclipse死活要报错.表示无语. 关于e ...
- systemd启动多实例
最近用了centos7,启动管理器用的是systemd,感觉很好玩. 1.开机自动启动 新建一个service文件放到/usr/lib/systemd/system/ 比如: [Unit] Descr ...
- maven配置nexus
setting配置: <?xml version="1.0" encoding="UTF-8"?> <!-- Licensed to the ...