Job流程:Shuffle详解
此文承接Job流程:Mapper类分析.MapReduce为确保每个reducer的输入都按键排序,数据从map输出到reducer输入的这段过程成为Shuffle。
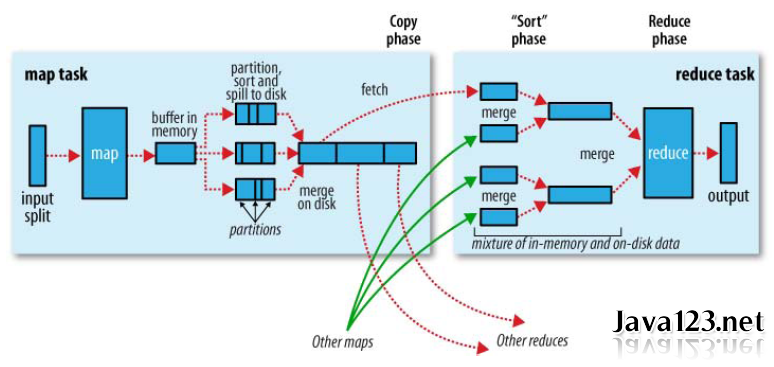
map端
1).Spill溢写. 每个map()方法都将处理结果输出到一个环形内存缓冲区buf(100MB)中(mapreduce.task.io.sort.mb)。一旦缓冲区的数据量达到阀值0.8(mapreduce.map.sort.spill. percent),就会启动一个后台线程将缓冲区的数据溢写(spill to disk)到本地磁盘指定的目录下(mapreduce.cluster.local.dir)。溢写线程启动,首先锁定这80MB的内存,执行溢写前相关的一系列操作。而map输出则继续往剩下的20MB内存中写,互不影响。溢写磁盘过程中,如果缓冲区被填满,map输出会被阻塞,直到溢写磁盘过程完成。
map()函数只为key做加1操作,即内存缓存区内容为:
<a,1> <b,1> <a,1> <c,1> <a,1> <d,1>
2).Partition和Sort. 溢写线程写入磁盘前的相关操作:首先根据map输出最终要传送到的reducer把内存中的数据划分成相应的分区Partitioner,然后在各个分区中按Key进行内排序Sort。如果制定了combiner(1)操作,它会在内排序后的输出上进行。当以上步骤完成之后,溢写线程才开始写入磁盘。
注意:写磁盘时压缩map输出,不仅可以加快写磁盘速度,节约磁盘空间,而且减少传给reduce的数据量。默认是不压缩的,启动压缩只要将mapreduce.map.output.compress设置为true即可。详见解读:hadoop压缩格式
系统默认的HashPartition:只是把key hash后按reduceTask的个数取模,因此一般来说,不同的key分配到哪个reducer是随即的!所以,单个reducer内的数据是有序的,但reducer之间的数据却是乱序的!要想数据整体排序:①只设一个reducer,②使用TotalOrderPartitioner!
经过Partition和Sort后数据为:
<a,1> <a,1> <a,1> <b,1> <c,1> <d,1>
如果有Combiner阶段,则处理后的数据为:
<a,3> <b,1> <c,1> <d,1>
3).Merge合并. 每次Spill操作都会产生一个新的溢写文件,因此在map结果写入磁盘过程中会不断产生80MB的溢写文件。在map阶段完成之前,要将所有溢写文件被合并merge(或叫分组group)成一个已分区且已排序的map输出文件,此阶段是基于字节流排序过程。属性mapreduce.task.io.sort.factor控制着一次最多合并多少个溢出写文件,默认10。如果制定了combiner(2)操作,它会在合并后的大文件上运行。
注意:merge时不同partition间key是不会比较的,只有同一partition的key才会进行排序和合并。
merge的算法:每个spill文件中key/value都是有序的,但不同的文件却是乱序的,类似多个有序文件的多路归并算法。首先分别取出需要merge的spillfile的最小的key/value,放入一个内存堆中,然后每次从堆中取出一个最小的值,并把此值保存到merge的输出文件中。这里和hbase中scan的算法非常相似!
假设当前map节点生成两个相同的Spill文件,则Merge结果:
<a,3> <a,3> <b,1> <b,1> <c,1> <c,1> <d,1> <d,1>
如果有Combiner阶段:
<a,6> <b,2> <c,2> <d,2>
4).map端总结:
- 对于map输出的partition分区是在写入内存buf前就做好的了。我们可以通过继承Partitioner类实现自定义分区,将自己想要的数据分到同一个reducer中。
- 在spill过程中map输出也会继续。因此,对内存buf相关参数的调优是MR调优的重点之一。
- 排序是MR默认的行为,内存中的排序是对结构化的对象进行比较,调用的是compareTo()方法。而merge阶段排序是对序列化后的字节数组进行排序,调用Comparator比较器中的compare()方法进行二次排序。
- Combiner在spill和merge阶段都会进行。Combiner是基于Key对Map结果进行规约处理,减小Map与Reduce之间的数据量传输。但需要注意不是所有的场景都适合combine,比如平均值。
- Combiner本身已经执行了reduce()操作,为什么在Reducer阶段还要执行reduce()操作? 回答:combiner只是处理了各个节点自身的Map中间结果,而Reducer则是将各个节点的Map结果汇集,再进行统一处理。
reduce如何知道要从那个NM取得map输出呢?
a). map任务成功完成之后,它会通过心跳机制通知MR-AM状态已更新。因此,对于指定作业的MR-AM知道map输出的映射关系。reduce中有一个线程定期询问MR-AM以便获得map输出的位置,直到reduce获得所有map的输出位置。
b). 由于reducer可能失败,因此MR-AM并没有在第一个reducer检索到map输出时就立即从磁盘上删除它们。相反,MR-AM会等待,直到整个MR作业完成才删除map输出。
Reduce端
5).HTTP请求. map输出文件保存在运行map任务的NodeManage节点的本地磁盘。reducer通过HTTP方式从各个NM上拷贝map中间结果,而每个NM通过jetty server处理这些http请求,所以可以适当配置调整jetty server的工作线程数(mapreduce.tasktracker.http.threads,默认40)。此设置针对整个MR任务,而不是针对每个map子任务。在运行大型作业的大型集群上,此值可以根据需要调整。
6).Copy阶段. 现在,NM需要为分区文件运行reduce任务。更进一步,reduce任务需要集群上若干个map任务的中间结果作为其特殊的分区文件。每个map任务的完成时间可能不同,因此只要有一个map任务完成,reduce任务就开始复制其输出。这就是reduce任务的复制阶段(copy phase)。Reduce任务默认有5个线程从map端拷贝数据,对应属性mapreduce.reduce.shuffle.parallelcopies。
7).Sort/Merge阶段. Map结果首先会被复制到reduce节点的内存缓冲区(mapreduce.reduce.shuffle.input.buffer.percent,默认0.70. 指定内存HeapSize的多少比例用于缓存数据,内存大小可通过mapred.child.java.opts来设置,默认200M),达到缓冲区阈值(mapreduce.reduce.shuffle.merge.percent,默认0.66),则合并后溢写到本地磁盘。随着磁盘上溢写文件的不断增多,reduce任务进入排序阶段(sort phase)。更恰当的说是合并阶段,因为排序已在map端进行,这个阶段将合并map输出,维持其顺序排序。合并是循环进行的。比如,如果有50个map输出,而合并因子是10(mapreduce.task.io.sort.factor,默认10,与map的合并类似),合并将进行5趟。每趟将10个文件合并成一个文件,因此最后有5个中间文件。
注意:为了合并,压缩的map输出都必须在内存中被解压缩。
8).执行Reduce. 在最后阶段,即reduce阶段,直接把5个中间文件输入reduce()函数,从而省略了一次合并写入磁盘,再从磁盘读取数据的往返行程。最后的合并既可来自内存和磁盘片段。在reduce阶段,对已排序的输入中每个键调用一次reduce()函数。此阶段的输出直接写到HDFS中,并且本NM节点保存第一个块副本(block replica)。
Job流程:Shuffle详解的更多相关文章
- 【转】ANDROID自定义视图——onMeasure,MeasureSpec源码 流程 思路详解
原文地址:http://blog.csdn.net/a396901990/article/details/36475213 简介: 在自定义view的时候,其实很简单,只需要知道3步骤: 1.测量—— ...
- (转)CentOS系统启动流程图文详解
CentOS系统启动流程图文详解. 原文:http://www.linuxidc.com/Linux/2017-03/141966.htm 熟悉系统启动流程对于我们学习Linux系统是非常有帮助的,虽 ...
- ANDROID自定义视图——onMeasure,MeasureSpec源码 流程 思路详解
简介: 在自定义view的时候,其实很简单,只需要知道3步骤: 1.测量--onMeasure():决定View的大小 2.布局--onLayout():决定View在ViewGroup中的位置 3. ...
- Struts2-整理笔记(一)介绍、搭建、流程、详解struts.xml
Struts2是一种前端的技术框架 替代Servlet来处理请求 Struts2优势 自动封装参数 参数校验 结果的处理(转发|重定向) 国际化 显示等待页面 表单的防止重复提交 搭建框架:导 ...
- Spark技术内幕: Shuffle详解(一)
通过上面一系列文章,我们知道在集群启动时,在Standalone模式下,Worker会向Master注册,使得Master可以感知进而管理整个集群:Master通过借助ZK,可以简单的实现HA:而应用 ...
- Spark中的Spark Shuffle详解
Shuffle简介 Shuffle描述着数据从map task输出到reduce task输入的这段过程.shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过s ...
- 【转】ANDROID自定义视图——onLayout源码 流程 思路详解
转载(http://blog.csdn.net/a396901990) 简介: 在自定义view的时候,其实很简单,只需要知道3步骤: 1.测量——onMeasure():决定View的大小 2.布局 ...
- Mysql高手系列 - 第18篇:mysql流程控制语句详解(高手进阶)
Mysql系列的目标是:通过这个系列从入门到全面掌握一个高级开发所需要的全部技能. 这是Mysql系列第18篇. 环境:mysql5.7.25,cmd命令中进行演示. 代码中被[]包含的表示可选,|符 ...
- struts2-环境搭建-访问流程-配置详解-常量配置-类详解
1 struts2概述 1.1 概念 1.2 struts2使用优势 自动封装参数 参数校验 结果的处理(转发|重定向) 国际化 显示等待页面 表单的防止重复提交 struts2具有更加先进的架构以 ...
随机推荐
- dreamweaver中Dw设置svn进行版本控制
需要工具: VisualSVN dwcs5+ 点击查看教程
- POJ1330Nearest Common Ancestors最近公共祖先LCA问题
用的离线算法Tarjan 该算法的详细解释请戳 http://www.cnblogs.com/Findxiaoxun/p/3428516.html 做这个题的时候,直接把1470的代码copy过来,改 ...
- MySQL单列索引和组合索引的区别介绍(转)
原文:http://database.51cto.com/art/201011/233234.htm MySQL单列索引是我们使用MySQL数据库中经常会见到的,MySQL单列索引和组合索引的区别可能 ...
- celery-rabbitmq 安装部署
一:Python安装 1.下载python3源码 wget https://www.python.org/ftp/python/3.5.0/Python-3.5.0.tgz 2.解压 tar xf P ...
- java 多线程 day08 java5多线程新特性
/** * Created by chengtao on 17/12/3. */public class Thread0801_java5_Atomaic { /* 三个包: http://tool. ...
- (转)理解POST和PUT的区别,顺便提下RESTful
这两个方法咋一看都可以更新资源,但是有本质区别的 具体定义可以百度,我这里就不贴了,光说我自己的理解 首先解释幂等,幂等是数学的一个用语,对于单个输入或者无输入的运算方法,如果每次都是同样的结果,则称 ...
- Oracle扩容表空间
1.程序报错,无法进行修改操作,通过日志,看到如下错误 2.通过google查询,问题是表空间文件不够了 "表空间大小(M)",(a.bytes "已使用空间(M)&qu ...
- Singleton: this & instance
public class Singleton{ private static final Singleton instance = new Singleton(); private String na ...
- java通过url抓取网页数据-----正则表达式
原文地址https://www.cnblogs.com/xiaoMzjm/p/3894805.html [本文介绍] 爬取别人网页上的内容,听上似乎很有趣的样子,只要几步,就可以获取到力所不能及的东西 ...
- 工作笔记-javascript-网络层封装
/** * @Author Mona * @Date 2016-12-08 * @description 网络层封装 */ /** * 封装基本请求方式 */ window.BaseRequest = ...