11.Spark Streaming源码解读之Driver中的ReceiverTracker架构设计以及具体实现彻底研究
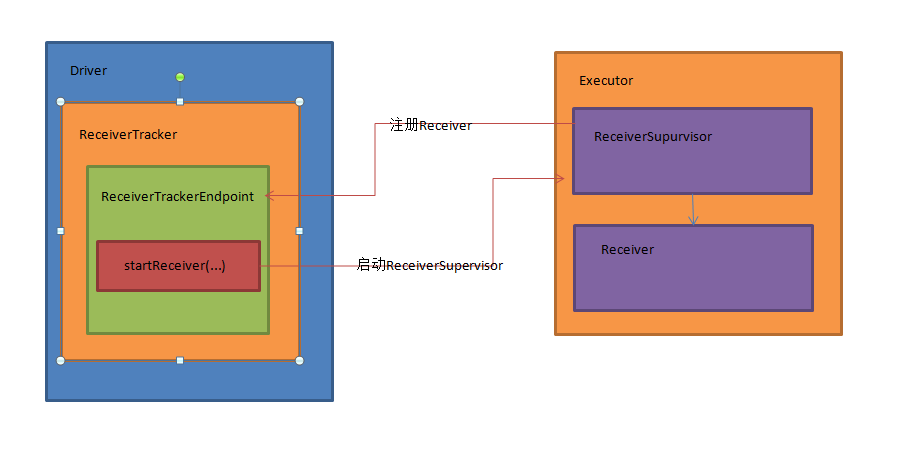
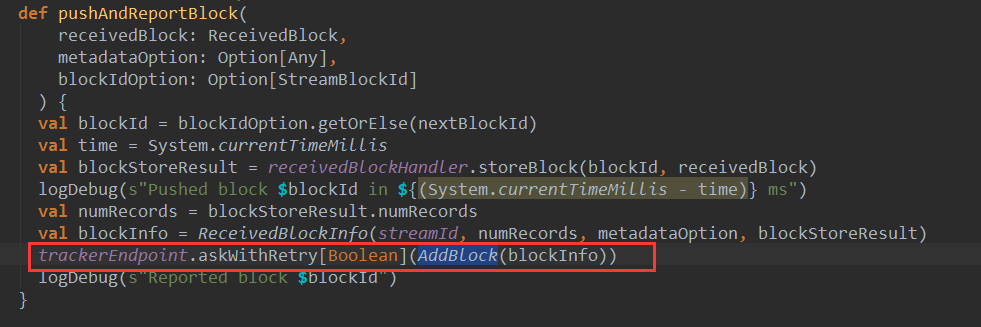
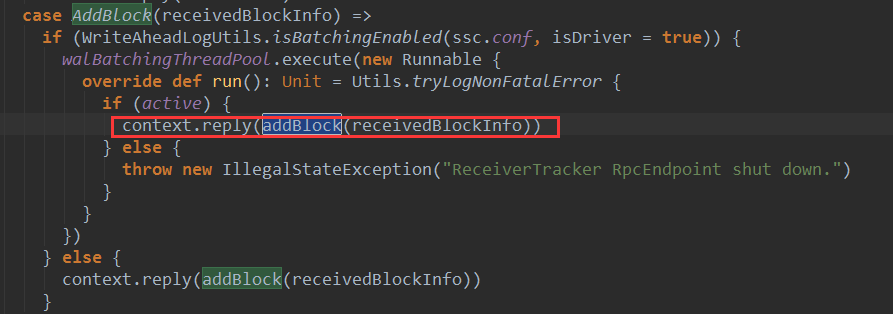
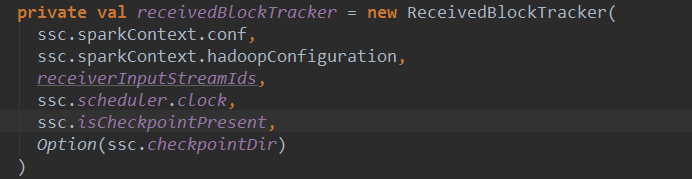
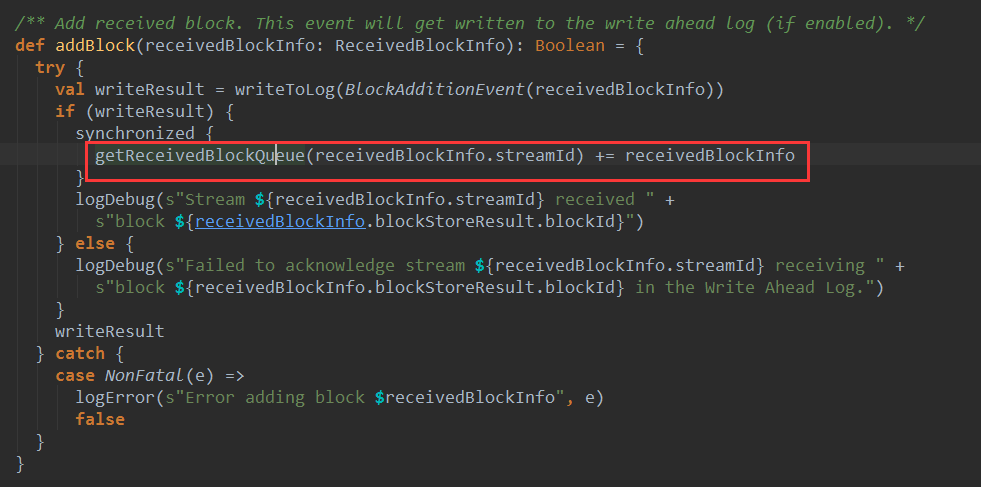
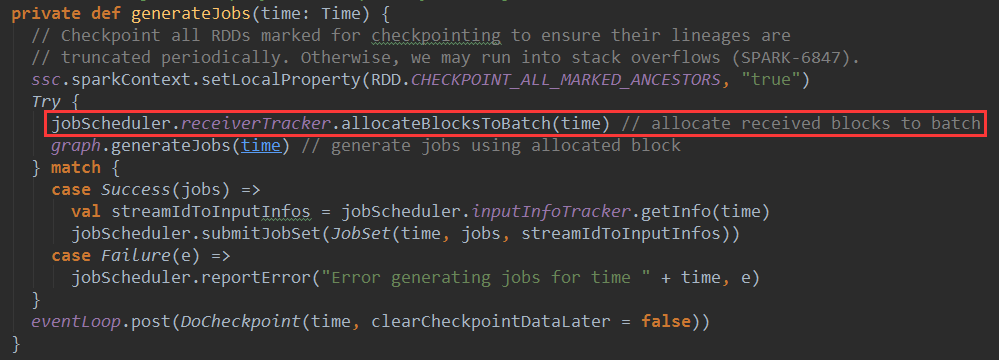
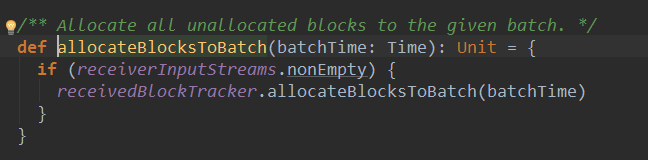
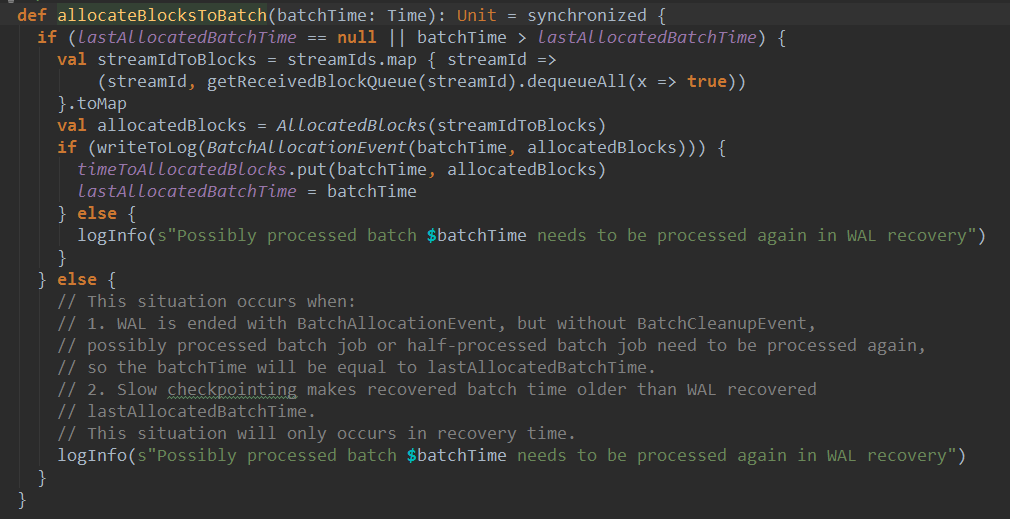
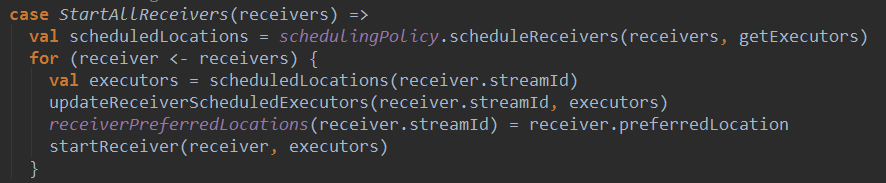
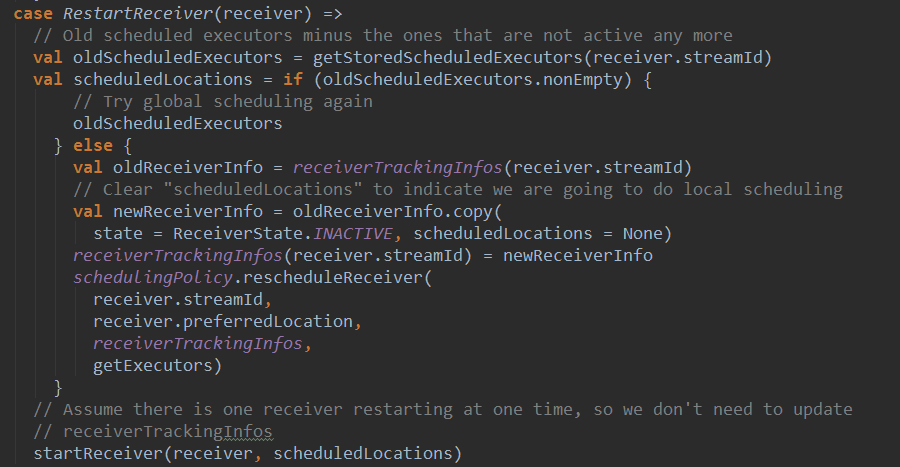
上篇文章详细解析了Receiver不断接收数据的过程,在Receiver接收数据的过程中会将数据的元信息发送给ReceiverTracker:






11.Spark Streaming源码解读之Driver中的ReceiverTracker架构设计以及具体实现彻底研究的更多相关文章
- Spark Streaming源码解读之Driver中ReceiverTracker架构设计以具体实现彻底研究
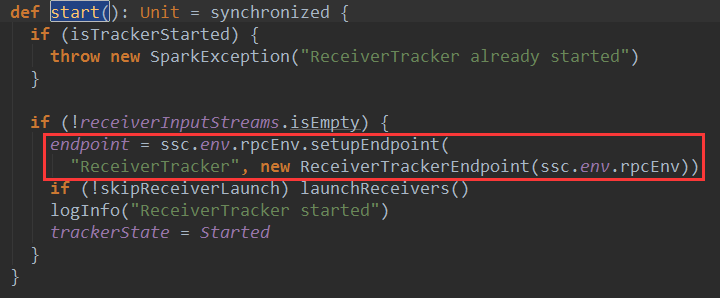
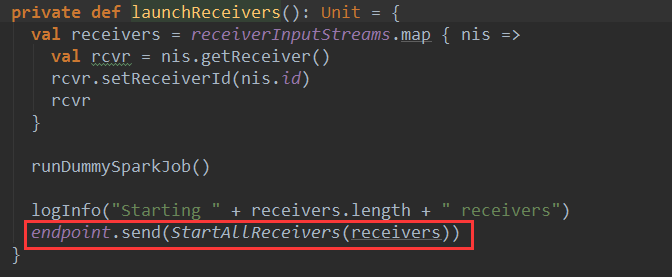
本期内容 : ReceiverTracker的架构设计 消息循环系统 ReceiverTracker具体实现 一. ReceiverTracker的架构设计 1. ReceiverTracker可以以 ...
- Spark Streaming源码解读之Driver容错安全性
本期内容 : ReceivedBlockTracker容错安全性 DStreamGraph和JobGenerator容错安全性 Driver的安全性主要从Spark Streaming自己运行机制的角 ...
- Spark Streaming源码解读之JobScheduler内幕实现和深度思考
本期内容 : JobScheduler内幕实现 JobScheduler深度思考 JobScheduler 是整个Spark Streaming调度的核心,需要设置多线程,一条用于接收数据不断的循环, ...
- Spark Streaming源码解读之流数据不断接收和全生命周期彻底研究和思考
本节的主要内容: 一.数据接受架构和设计模式 二.接受数据的源码解读 Spark Streaming不断持续的接收数据,具有Receiver的Spark 应用程序的考虑. Receiver和Drive ...
- 15、Spark Streaming源码解读之No Receivers彻底思考
在前几期文章里讲了带Receiver的Spark Streaming 应用的相关源码解读,但是现在开发Spark Streaming的应用越来越多的采用No Receivers(Direct Appr ...
- Spark Streaming源码解读之流数据不断接收全生命周期彻底研究和思考
本期内容 : 数据接收架构设计模式 数据接收源码彻底研究 一.Spark Streaming数据接收设计模式 Spark Streaming接收数据也相似MVC架构: 1. Mode相当于Rece ...
- Spark Streaming源码解读之Receiver生成全生命周期彻底研究和思考
本期内容 : Receiver启动的方式设想 Receiver启动源码彻底分析 多个输入源输入启动,Receiver启动失败,只要我们的集群存在就希望Receiver启动成功,运行过程中基于每个Tea ...
- Spark Streaming源码解读之生成全生命周期彻底研究与思考
本期内容 : DStream与RDD关系彻底研究 Streaming中RDD的生成彻底研究 问题的提出 : 1. RDD是怎么生成的,依靠什么生成 2.执行时是否与Spark Core上的RDD执行有 ...
- Spark Streaming源码解读之Job动态生成和深度思考
本期内容 : Spark Streaming Job生成深度思考 Spark Streaming Job生成源码解析 Spark Core中的Job就是一个运行的作业,就是具体做的某一件事,这里的JO ...
随机推荐
- 「Linux+Django」uwsgi服务启动(start)停止(stop)重新装载(reload)
转自:http://blog.51cto.com/12482328/2087535?cid=702003 1. 添加uwsgi相关文件 在之前的文章跟讲到过centos中搭建nginx+uwsgi+f ...
- springsecurity basic 认证
Basic Access Authentication scheme是在HTTP1.0提出的认证方法,它是一种基于challenge/response的认证模式,针对特定的realm需要提供用户名和密 ...
- linux命令df中df -h和df -i的区别
df 命令: linux中df命令的功能是用来检查linux服务器的文件系统的磁盘空间占用情况.可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息. 1.命令格式: df [选项] [ ...
- [BZOJ1911][BZOJ1912][BZOJ1913]APIO2010解题报告
特别行动队 Description 这个好像斜率优化不是一般地明显了啊...只不过要分a的正负两种情况考虑是维护上凸还是下凸 /********************************** ...
- 简易安装sqoop
版本 :hive-0.13.1-cdh5.3.6.tar.gz 1:解压 然后 进到 conf 目录 修改 sqoop-env.sh 2:如果使用mysql 数据库 要将 mysql驱动包拷贝到 ...
- 1030 大数进制转换(51Nod + JAVA)
题目链接:https://www.51nod.com/onlineJudge/questionCode.html#!problemId=1030 题目: 代码实现如下: import java.mat ...
- HDU 1059 Dividing (dp)
题目链接 Problem Description Marsha and Bill own a collection of marbles. They want to split the collect ...
- 大聊Python----装饰器
什么是装饰器? 装饰器其实和函数没啥区别,都是用def去定义的,其本质就是函数,而功能就是装饰其他的函数,说白了就是为其他函数提供附加功能 装饰器有什么作用? 比如你是一个公司的员工,你所写的程序里有 ...
- docker 镜像导入和导出
使用 docker commit 即可把这个容器变为一个镜像 docker commit 8d93082a9ce1 ubuntu:myubuntu 这时候 docker 容器会被创建为一个新的 Ubu ...
- Java从零到企业级电商项目实战
欢迎关注我的微信公众号:"Java面试通关手册"(坚持原创,分享各种Java学习资源,面试题,优质文章,以及企业级Java实战项目回复关键字免费领取)回复关键字:"电商项 ...