SQL Server排名函数与排名开窗函数
什么是排名函数?说实话我也不甚清楚,我知道 order by 是排序用的,那么什么又是排名函数呢?
接下来看几个示例就明白了。
首先建立一个表,随便插入一些数据。

ROW_NUMBER 函数:直接排序,ROW_NUMBER函数是以上升进行直接排序,并且以连续的顺序给每一行数据一个唯一的序号。(即排名连续)
-- 以下是根据 U_Pwd 这一列进行排名(升序)
select *,
'第'+convert(varchar,ROW_NUMBER() over(order by U_Pwd))+'名' RowNum
from UserInfo

RANK 函数:并列排序,在 order by 子句中指定的列,如果返回一行数据与另一行具有相同的值,rank函数将给这些行赋予相同的排名数值。
在排名的过程中,保持一个内部计数值,当值有所改变时,排名序号将有一个跳跃。(即排名不连续)
-- 以下是根据 U_Pwd 这一列进行排名(升序)
select *,
'第 '+convert(varchar,rank() over(order by U_Pwd))+' 名' RowNum
from UserInfo

可以明确的看到有4行数据并列第2名,然后直接就是第6名,这是因为 order by 子句中指定的列 U_Pwd 的值相同。
DENSE_RANK 函数:并列排序,这一点与 RANK() 函数类似,order by 子句指定的列的值相同,排名数值相同,但是后面是连续的。(即排名连续)
-- 以下是根据 U_Pwd 这一列进行排名(升序)
select *,
'第 '+convert(varchar,DENSE_RANK() over(order by U_Pwd))+' 名' RowNum
from UserInfo

可以看到即使有4行数据并列第2名,但是接下来依然是第3名。
NTILE 函数:将查询的结果分发到指定数量的组中。 各个组有编号,编号从1开始。 对于每一行,NTILE 将返回此行所属的组的编号。
组中的行数计算方式为 total_num_rows(结果集的总行数) / num_groups(指定的组数)。
如果有余数 n,则前面 n 个组获得一个附加行。因此,可能不会所有组都获得相等数量的行,但是组大小最大只可能相差一行。
例如,如果总行数是 53,组数是 5,53 / 5 等于10余数是3,按上面个规则就是,每组分配10行,又因余数为3,所以前面3组每组附加一行。
则前三个组每组包含 11 行,其余两个组每组包含 10 行。
另一方面,如果总行数可被组数整除,则行数将在组之间平均分布。 例如,如果总行数为 50,有五个组,则每组将包含 10 行。
-- 以下是根据 U_Pwd 这一列进行分组
select *,
'第 '+convert(varchar,NTILE(3) over(order by U_Pwd))+' 组' RowNum
from UserInfo

这个表中有10条数据,指定分为3组,10/3等于3余数1。
PS:排名函数后面必须有 over() 子句。
排名开窗函数:
ROW_NUMBER、DENSE_RANK、RANK、NTILE属于排名函数,OVER()就是窗口函数。
窗口函数OVER()指定一组行,开窗函数计算从窗口函数输出的结果集中各行的值。
开窗函数不需要使用GROUP BY就可以对数据进行分组,还可以同时返回基础行的列和聚合列。
排名开窗函数可以单独使用ORDER BY 语句,也可以和PARTITION BY同时使用。
ODER BY 指定排名开窗函数的顺序。在排名开窗函数中必须使用ORDER BY语句。
PARTITION BY用于将结果集进行分组,开窗函数应用于每一组。
-- 以下是先根据 U_Pwd 这一列进行分组,然后每一组再根据 U_Pwd 排序
select *,
'第'+convert(varchar,ROW_NUMBER() over(partition by U_Pwd order by U_Pwd))+'名' RowNum
from UserInfo
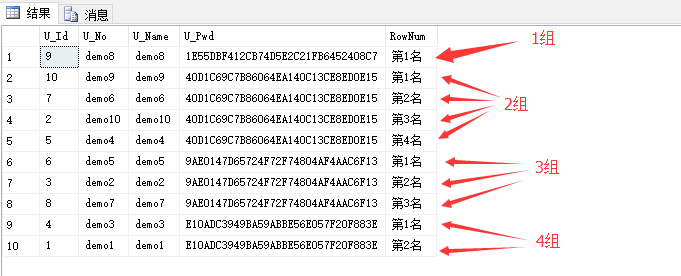
因为 U_Pwd 这一列有4种不同的值,所以分为4组,然后 ROW_NUMBER 再在每一组中进行连续排序。
-- 以下是先根据 U_Pwd 这一列进行分组,然后每一组再根据 U_Pwd 排序
select *,
'第'+convert(varchar,rank() over(partition by U_Pwd order by U_Pwd))+'名' RowNum
from UserInfo

因为 U_Pwd 这一列有4种不同的值,所以同样是分为4组,然后 RANK 再在每一组中进行排序,因为RANK是并列排序,所以全部都是第一名。下面换个字段排序试试看。
-- 以下是先根据 U_Pwd 这一列进行分组,然后每一组再根据 U_Name 排序
select *,
'第'+convert(varchar,rank() over(partition by U_Pwd order by U_Name))+'名' RowNum
from UserInfo

-- 以下是先根据 U_Pwd 这一列进行分组,然后每一组再根据 U_Pwd 排序
select *,
'第'+convert(varchar,DENSE_RANK() over(partition by U_Pwd order by U_Pwd))+'名' RowNum
from UserInfo

因为 U_Pwd 这一列有4种不同的值,所以同样是分为4组,然后 DENSE_RANK 再在每一组中进行排序,因为DENSE_RANK也是并列排序,所以全部都是第一名。下面换个字段排序试试看。
-- 以下是先根据 U_Pwd 这一列进行分组,然后每一组再根据 U_Name 排序
select *,
'第'+convert(varchar,DENSE_RANK() over(partition by U_Pwd order by U_Name))+'名' RowNum
from UserInfo
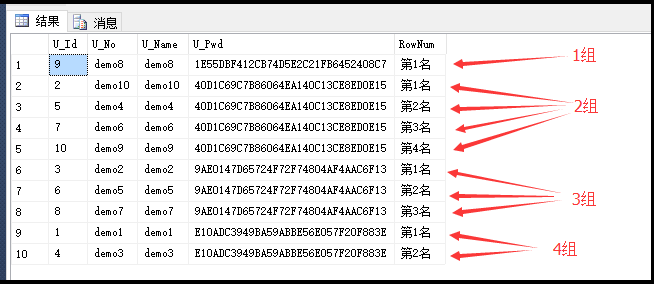
-- 以下是先根据 U_Pwd 这一列进行分组,然后每一组再根据 NTILE(3) 指定的组数分组,最后在根据 order by 子句指定的字段 U_Pwd 排序
select *,
'第'+convert(varchar,NTILE(3) over(partition by U_Pwd order by U_Pwd))+'名' RowNum
from UserInfo

因为 U_Pwd 这一列有4种不同的值,所以同样是分为4组。第1组有1条数据,所以就1个区。第2组有4条数据,4/3等于1余数1,所以第2组分为3个区,又因余数为1,所以第1个区附加1行。第3组有3条数据,3/3等于1余数为0,所以第3组有3个区。第4组有2条数据,所以分为2个区。
PS:在排序开窗函数中使用 PARTITION BY 子句需要放置在 ORDER BY子句之前。
参考:
http://www.cnblogs.com/jhxk/articles/2531595.html
SQL Server排名函数与排名开窗函数的更多相关文章
- SQL Server聚合函数与聚合开窗函数 (转载)
以下面这个表的数据作为示例. 什么是聚合函数?聚合函数:聚合函数就是对一组值进行计算后返回单个值(即分组).聚合函数在计算时都会忽略空值(null).所有的聚合函数均为确定性函数.即任何时候使用一组相 ...
- SQL Server聚合函数与聚合开窗函数
以下面这个表的数据作为示例. 什么是聚合函数? 聚合函数:聚合函数就是对一组值进行计算后返回单个值(即分组).聚合函数在计算时都会忽略空值(null). 所有的聚合函数均为确定性函数.即任何时候使用一 ...
- SQL Server 中截取字符串常用的函数
SQL Server 中截取字符串常用的函数: 1.LEFT ( character_expression , integer_expression ) 函数说明:LEFT ( '源字符串' , '要 ...
- SQL Server中的LEFT、RIGHT函数
SQL Server中的LEFT.RIGHT函数. LEFT:返回字符串中从左边开始指定个数字符. LEFT(character_expression,integer_expression); RIG ...
- Spark(十三)SparkSQL的自定义函数UDF与开窗函数
一 自定义函数UDF 在Spark中,也支持Hive中的自定义函数.自定义函数大致可以分为三种: UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_ ...
- SQL Server 中的窗口函数(2012 新函数)
简介 SQL Server 2012之后对窗口函数进行了极大的加强,但对于很多开发人员来说,对窗口函数却不甚了解,导致了这样强大的功能被浪费,因此本篇文章主要谈一谈SQL Server中窗口函数的概念 ...
- 在SQL SERVER中实现RSA加解密函数(第二版)
/*************************************************** 作者:herowang(让你望见影子的墙) 日期:2010.1.5 注: 转载请保留此信息 更 ...
- 在SQL SERVER中实现RSA加解密函数(第一版)
/*************************************************** 作者:herowang(让你望见影子的墙) 日期:2010.1.1 注: 转载请保留此信息 ...
- SQL Server编程(02)自定义函数
在编程过程中,我们通常把特定的功能语句块封装称函数,方便代码的重用.我们可以在SQL Server中自定义函数,根据函数返回值的区别,我们自定义的函数分两种:标量值函数和表值函数. 自定义函数的优点: ...
- 实现SQL Server中的切割字符串SplitString函数,返回Table
有时我们要用到批量操作时都会对字符串进行拆分,可是SQL Server中却没有自带Split函数,所以要自己来实现了. -- ===================================== ...
随机推荐
- 配置linux的环境变量
下面是配置linux的环境变量:(记得source .bash_profile). 修改/etc/profile文件 (全局所有用户) vi 此文件/etc/profile在profile文件末尾加入 ...
- C++中的自动存储、静态存储和动态存储
根据用于分配内存的方法,C++中有3中管理数据内存的方式:自动存储.静态存储和动态存储(有时也叫做自由存储空间或堆).在存在是间的长短方面,以这三种方式分配的数据对象各不相同.下面简要介绍这三种类型( ...
- 在Eclipse中显示.project和.classpath和.setting目录
在Eclipse中显示.project, .classpath, .gitignore文件和.setting文件夹 在Eclipse中使用git,并显示.gitigonre文件,进行项目管理 在Ecl ...
- 解决 Unable to load native-hadoop library for your platform
安装hadoop启动之后总有警告:Unable to load native-hadoop library for your platform... using builtin-java classe ...
- 【BZOJ5073】[Lydsy十月月赛]小A的咒语 DP(错解)
[BZOJ5073][Lydsy十月月赛]小A的咒语 题解:沙茶DP,完全不用后缀数组. 用f[i][j]表示用了A的前i个字符,用了j段,最远能匹配到哪.因为显然我们能匹配到的地方越远越好,所以我们 ...
- 160524、Linux下如何启动、关闭Oracle以及打开关闭监听
1. linux下启动oraclesu - oraclesqlplus /nologconn /as sysdbastartupexitlsnrctl startexit2. linux下关闭orac ...
- JAVA编程你必须知道的那些英文单词
第一章: JDK(Java Development Kit) java开发工具包 JVM(Java Virtual Machine) java虚拟机 Javac 编译命令 ...
- hibernate的日期映射
2. 映射 Java 的时间, 日期类型 1). 两个基础知识: I. 在 Java 中, 代表时间和日期的类型包括: java.util.Date 和 java.util.Calendar. 此外, ...
- 回车(CR)换行(LF)的来历及区别
转自https://blog.csdn.net/lw370481/article/details/8229344 一.回车”(Carriage Return)和“换行”(Line Feed)起源 回车 ...
- Centos7.0配置MySQL主从服务器
主服务器:192.168.186.131 从服务器:192.168.186.133 主从服务器mysql版本尽量保持一致,安装步骤请阅mysql安装步骤 一.修改主服务器配置文件 # vi /et ...