【Python数据挖掘】回归模型与应用
线性回归 ( Linear Regression )
线性回归中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归称为一元线性回归。
如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归。
在监督学习中,学习样本为 D = { (x(i), y(i));i =1, . . . , m } ,预测的结果y(i)为连续值变量,需要学习映射 f:X → Y ,并且假定输入X和输出Y之间有线性相关关系。
给出一组数据:
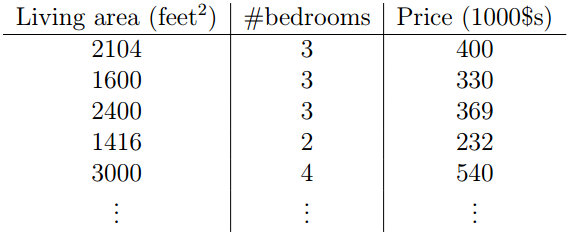
其中x是实数域中的二维向量。比如,xi1是第i个房子的居住面积,xi2是这个房子的房间数。
为了执行监督学习,我们需要决定怎样在计算机中表示我们的函数/假设。我们可以近似地使用线性函数来表示。

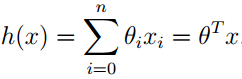 (矩阵形式)
(矩阵形式)
现在,有了训练数据,我们怎么挑选,或者说得知θ的值呢?一个可信的方法是使得h(x)与y更加接近,至少对于我们训练的例子来说是这样的。
于是,我们定义一个损失函数 / 成本函数( loss function / cost function ):
我们把 x 到 y 的映射函数 f 记作 θ 的函数 hθ(x)
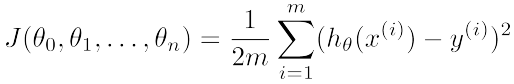
损失函数有很多种类型,根据需求进行选择。
然后进行最小化损失函数,将函数优化成凸函数 (往往只会有一个全局最优解,不用过多担心算法收敛到局部最优解) 。
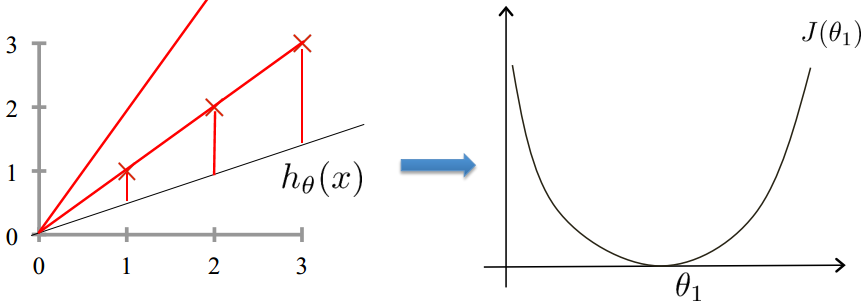
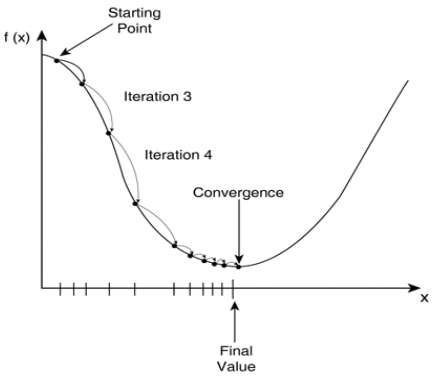
梯度下降 ( Gradient Descent algorithm )
最快的速度最小化损失函数,比作如何最快地下山,也就是每一步都应该往坡度最陡的方向往下走,而坡度最陡的方向就是损失函数相应的偏导数。
因此算法迭代的规则是:
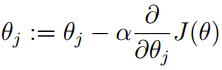
假设现在有n个特征、或者变量xj (j=1…n)

其中α是算法的参数learning rate,α越大每一步下降的幅度越大,速度也会越快,但过大有可能反复震荡,导致算法不准确。
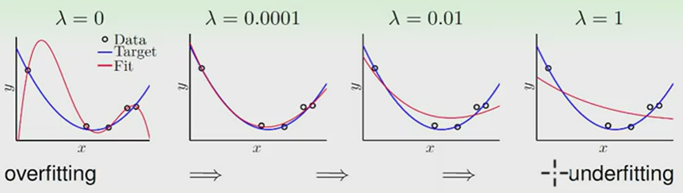
欠拟合与过拟合(Underfitting and Overfitting)
欠拟合问题:特征值少,模型过于简单不足与支撑。
过拟合问题:有非常多特征,模型很复杂, 我们的假设函数曲线可以对原始数据拟合得非常好, 但丧失了一般性, 从而导致对新给的待预测样本,预测效果差。
正则项、正则化
通过正则项控制参数幅度。
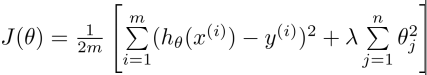
正则项有多种方式选择,常采用的有:
L1正则:|θj|
L2正则:θj2
Logistic 回归(Logistic Regression)
采用线性回归解决分类问题时,往往会遇到模型健壮性低,遇到噪声时,受干扰严重。
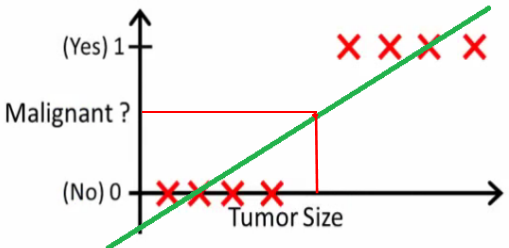
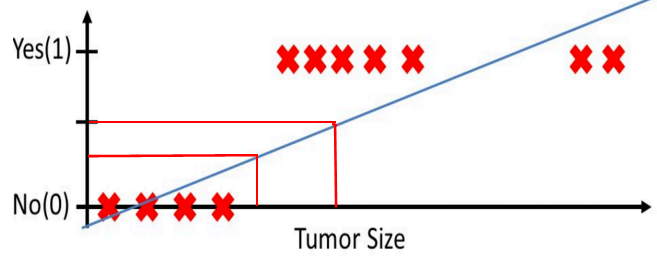
我们可以对旧的线性回归算法来进行适当的修改来得到我们想要的函数。
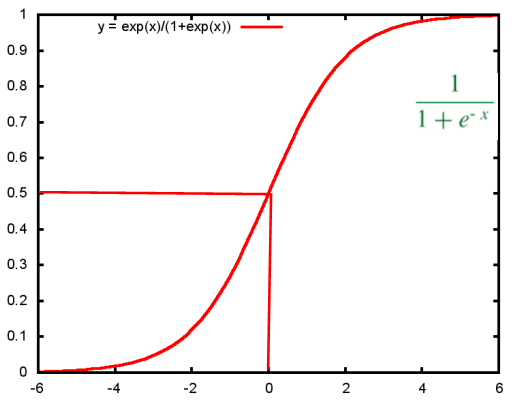
引入sigmoid 函数:
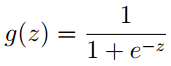
对原函数hθ(x)进行改写得到:
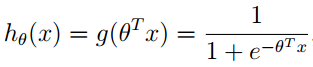
观察函数图像发现:当x大于0时,y的值大于0.5,根据这特性可以将线性回归得到的预测值压缩在0~1范围内。
1.线性判定边界:
假设线性函数为: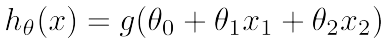 ,
,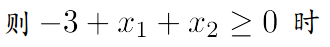
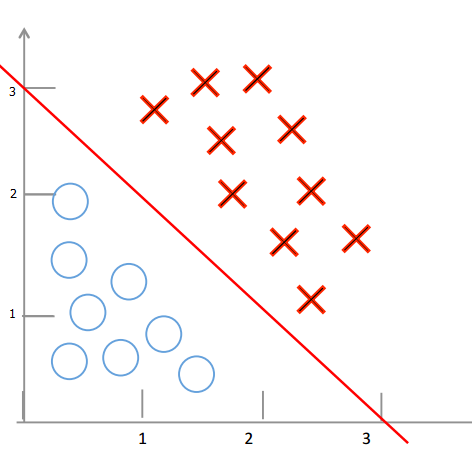
当 hθ(x) > 0 时,g(hθ(x)) 的值为大于 0.5;
当 hθ(x) < 0 时,g(hθ(x)) 的值为小于 0.5;
2.非线性判定边界:
假设函数为: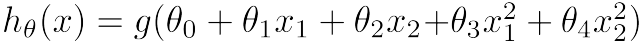
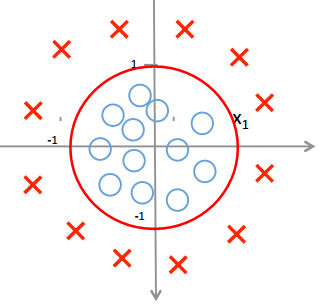
当θ0=0,θ1=0,θ2=0,θ3=1,θ4=1,得到函数g(x12+x22-1),边界为一个圆,圆内点的值小于0
定义损失函数:

该函数为非凸函数,有局部最小值,应选择其他函数。

定义损失函数为:
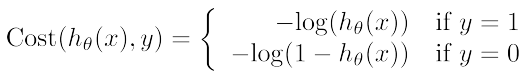
该函数的图像如下:
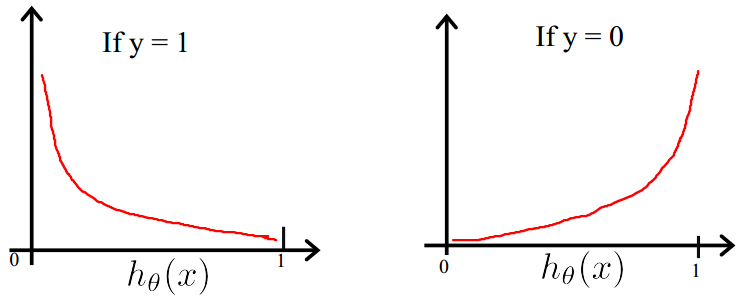
我们可以发现该函数在:
y=1的正样本中,hθ(x)趋向于0.99~9 ,此时我们希望得到的代价越小,而当得到的预测值是0.00~1时,我们希望它的代价越大;
y=0的负样本中,hθ(x)趋向于0.00~1 ,此时我们希望得到的代价越小,而当得到的预测值是0.99~9时,我们希望它的代价越大;
损失函数可以改写成:
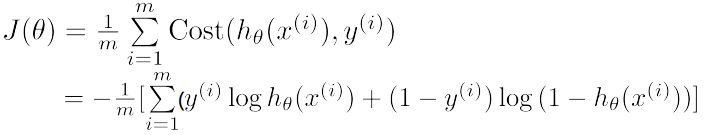
加入正则项:
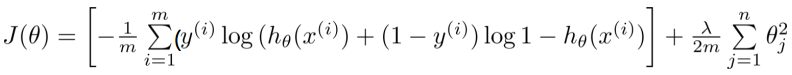
二分类与多分类
one vs one
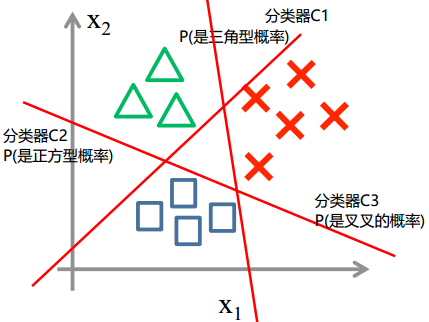
one vs rest
方法一:

1.先对三角形与叉叉进行分类,得到分类器C1,以及概率值Pc1(x) 和 1-Pc1(x)
2.然后对三角形与正方形进行分类,得到分类器C2,以及概率值Pc2(x) 和 1-Pc2(x)
3.最后对正方形与叉叉进行分类,得到分类器C3,以及概率值Pc3(x) 和 1-Pc3(x)
得到通过3个分类器,6个概率值,概率值最大的判断为相应的类型!
方法二:
1.先对三角形进行分类,判断是否为三角形,得到分类器C1,以及概率值Pc1(x)
2.然后对正方形进行分类,判断是否为正方形,得到分类器C2,以及概率值Pc2(x)
3.最后对叉叉叉进行分类,判断是否为叉叉叉,得到分类器C3,以及概率值Pc3(x)
得到3个分类器,3个概率值,概率值最大的判断为相应的类型!
应用一:( Linear Regression )
1、导入相应的包,设置画图格式:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt import seaborn as sns
sns.set_context('notebook')
sns.set_style('white')
plt.figure(figsize=(8,6))
2、数据准备:
【Python数据挖掘】回归模型与应用的更多相关文章
- 机器学习之路:python 集成回归模型 随机森林回归RandomForestRegressor 极端随机森林回归ExtraTreesRegressor GradientBoostingRegressor回归 预测波士顿房价
python3 学习机器学习api 使用了三种集成回归模型 git: https://github.com/linyi0604/MachineLearning 代码: from sklearn.dat ...
- 手写数字识别 ----Softmax回归模型官方案例注释(基于Tensorflow,Python)
# 手写数字识别 ----Softmax回归模型 # regression import os import tensorflow as tf from tensorflow.examples.tut ...
- 逻辑回归模型(Logistic Regression)及Python实现
逻辑回归模型(Logistic Regression)及Python实现 http://www.cnblogs.com/sumai 1.模型 在分类问题中,比如判断邮件是否为垃圾邮件,判断肿瘤是否为阳 ...
- 机器学习——手把手教你用Python实现回归树模型
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天这篇是机器学习专题的第24篇文章,我们来聊聊回归树模型. 所谓的回归树模型其实就是用树形模型来解决回归问题,树模型当中最经典的自然还是决 ...
- [Python]数据挖掘(1)、梯度下降求解逻辑回归——考核成绩分类
ps:本博客内容根据唐宇迪的的机器学习经典算法 学习视频复制总结而来 http://www.abcplus.com.cn/course/83/tasks 逻辑回归 问题描述:我们将建立一个逻辑回归模 ...
- Python之逻辑回归模型来预测
建立一个逻辑回归模型来预测一个学生是否被录取. import numpy as np import pandas as pd import matplotlib.pyplot as plt impor ...
- 吴裕雄 数据挖掘与分析案例实战(7)——岭回归与LASSO回归模型
# 导入第三方模块import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn import mod ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
随机推荐
- Java callback
Java中的回调(callback)是很重要的一个概念,spring整合hibernate大量使用了这种技术. 究竟怎样才是回调呢? 这是网上最多见到的说明: 1.class A,clas ...
- CodeForces 35D Animals
G - Animals Time Limit:2000MS Memory Limit:65536KB 64bit IO Format:%I64d & %I64u Submit ...
- C语言 · 打印1~100间的质数(素数)
算法提高 c++_ch02_04 时间限制:1.0s 内存限制:256.0MB 问题描述 输出1~100间的质数并显示出来.注意1不是质数. 输出格式 每行输出一个质数. 2 3 . ...
- EmWebAdmin 导航栏分析
templates/gentelella/base.tpl <!DOCTYPE html> <html lang="en"> <!-- Smarty ...
- 如何对MySQL中的大表进行数据归档
使用MySQL的过程,经常会遇到一个问题,比如说某张”log”表,用于保存某种记录,随着时间的不断的累积数据,但是只有最新的一段时间的数据是有用的:这个时候会遇到性能和容量的瓶颈,需要将表中的历史数据 ...
- [Python基础]Python中remove,del和pop的区别
以a=[1,2,3] 为例,似乎使用del, remove, pop一个元素2 之后 a都是为 [1,3], 如下:http://Novell.Me >>> a=[1,2,3] &g ...
- Mac下修改应用程序的菜单快捷键!
点击左上角苹果按钮,系统偏好设置 > 键盘 > 快捷键 > 应用快捷键 点击右下角添加按钮,选择chrome程序,输入菜单中文名以及快捷键 1.如何用F5刷新 鼠标悬停在左上角的刷新 ...
- 扫描线 - UVALive - 6864 Strange Antennas
Strange Antennas Problem's Link: http://acm.hust.edu.cn/vjudge/problem/viewProblem.action?id=87213 M ...
- MapReduce 中的两表 join 几种方案简介
转自:http://my.oschina.net/leejun2005/blog/95186 MapSideJoin例子:http://my.oschina.net/leejun2005/blog/1 ...
- oracle起定时任务,每隔1秒执行一次
创建一个测试表和一个存储过程: create table a(a date); create or replace procedure test as begin insert into a valu ...