Spark的job调优(1)
本文翻译之cloudera的博客,本系列有两篇,第二篇看心情了
概论
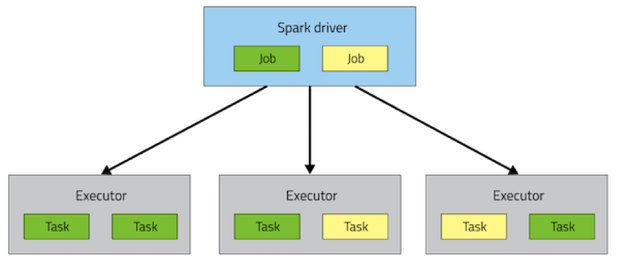
Spark如何执行应用
sc.textFile("someFile.txt").map(mapFunc).flatMap(flatMapFunc).filter(filterFunc).count()
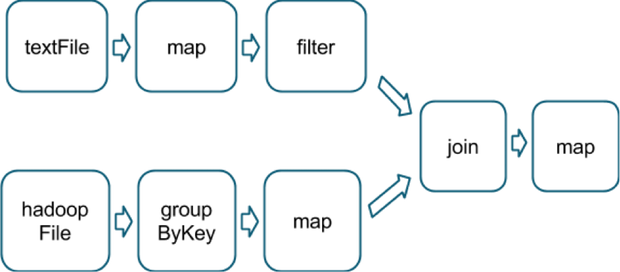
val tokenized = sc.textFile(args(0)).flatMap(_.split(' '))val wordCounts = tokenized.map((_,1)).reduceByKey(_ + _)val filtered = wordCounts.filter(_._2 >=1000)val charCounts = filtered.flatMap(_._1.toCharArray).map((_,1)).reduceByKey(_ + _)charCounts.collect()
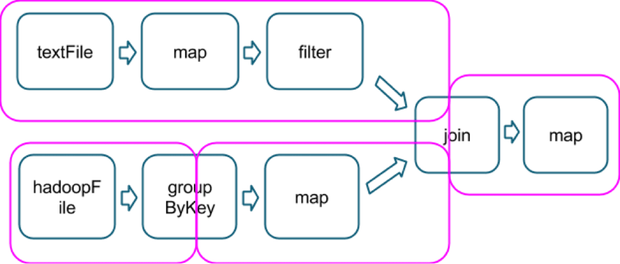
选择正确的操作
- 当执行一个associative reductive 操作时不要使用groupbykey,例如。 rdd.groupbykey().mapValues(_.sum)和rdd.reduceBykey(_+_)的结果一样,但是前面的操作会导致所有的数据进行网络传输,后者只会先在本地计算每个patition相同key的和,然后通过shuffler合并所有本地计算的和(都会有shuffle,但是传输的数据减少了很多)
- 当输入和输出的类型不一样时不要使用reduceByKey,例如
当写一个transformation用来找到每一个key对应唯一的一个字符串是,一种方式如下:rdd.map(kv => (kv._1, new Set[String]() + kv._2)).reduceByKey(_ ++ _),该操作会导致大量的不必要的set对象,每个key都会创建一个,这里最好使用aggregateBykey,它会执行map端的聚集更有效val zero =new collection.mutable.Set[String]()rdd.aggregateByKey(zero)((set, v)=> set += v,(set1, set2)=> set1 ++= set2)
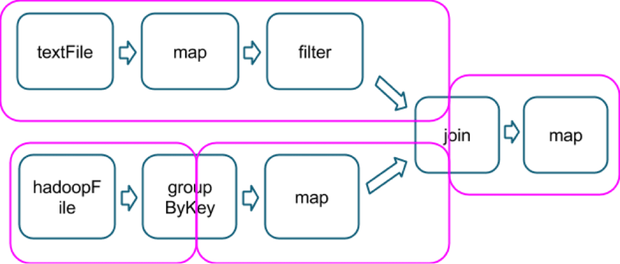
什么时候shuffle不会发生
rdd1 = someRdd.reduceByKey(...)rdd2 = someOtherRdd.reduceByKey(...)rdd3 = rdd1.join(rdd2)
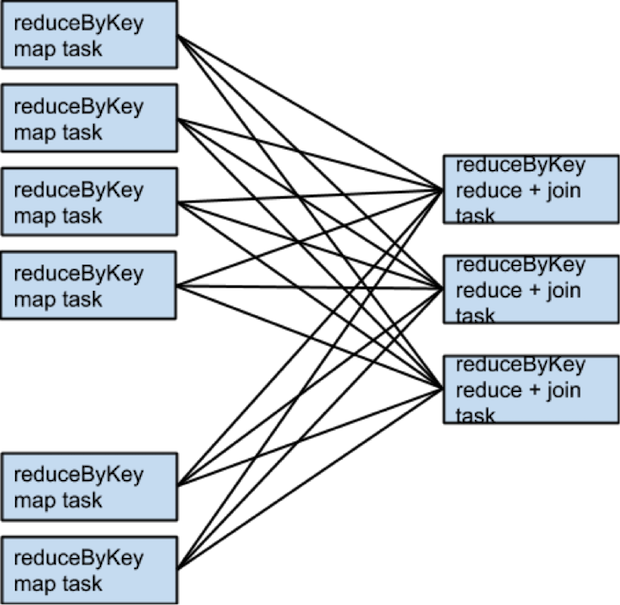
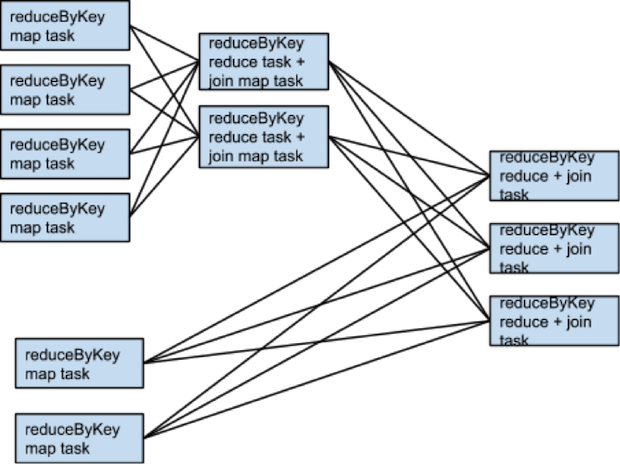
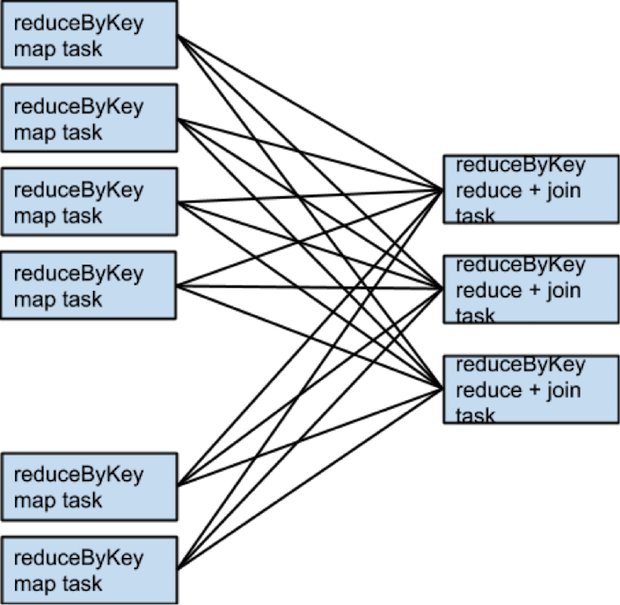
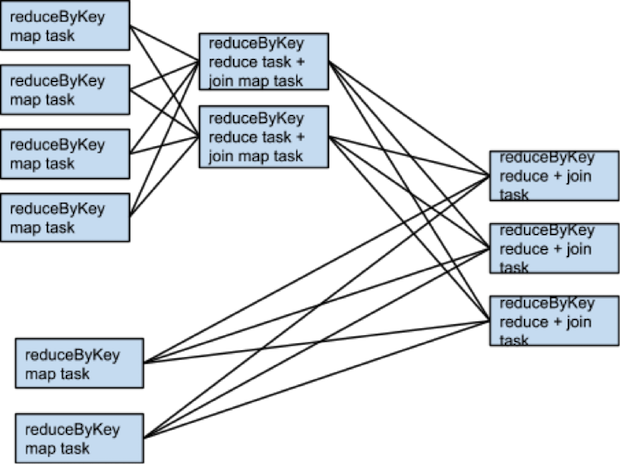
什么时候需要更多的shuffle
二次排序
{kind=link}
{kind=link}
{kind=link}
Spark的job调优(1)的更多相关文章
- Spark:性能调优
来自:http://blog.csdn.net/u012102306/article/details/51637366 资源参数调优 了解完了Spark作业运行的基本原理之后,对资源相关的参数就容易理 ...
- Spark的性能调优杂谈
下面这些关于Spark的性能调优项,有的是来自官方的,有的是来自别的的工程师,有的则是我自己总结的. 基本概念和原则 <1> 每一台host上面可以并行N个worker,每一个worke ...
- spark submit参数调优
在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都可以在spark-submit命令中作为参数设置.很多Spark初学者,通常不知道该设置哪些必要的参数,以及如何设置 ...
- Spark Streaming性能调优详解
Spark Streaming性能调优详解 Spark 2015-04-28 7:43:05 7896℃ 0评论 分享到微博 下载为PDF 2014 Spark亚太峰会会议资料下载.< ...
- spark 资源参数调优
资源参数调优 了解完了Spark作业运行的基本原理之后,对资源相关的参数就容易理解了.所谓的Spark资源参数调优,其实主要就是对Spark运行过程中各个使用资源的地方,通过调节各种参数,来优化资源使 ...
- Spark(九)Spark之Shuffle调优
一.概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO.序列化.网络数据传输等操作.因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行 ...
- Spark(六)Spark之开发调优以及资源调优
Spark调优主要分为开发调优.资源调优.数据倾斜调优.shuffle调优几个部分.开发调优和资源调优是所有Spark作业都需要注意和遵循的一些基本原则,是高性能Spark作业的基础:数据倾斜调优,主 ...
- Spark的性能调优
下面这些关于Spark的性能调优项,有的是来自官方的,有的是来自别的的工程师,有的则是我自己总结的. Data Serialization,默认使用的是Java Serialization,这个程序员 ...
- Spark Streaming性能调优详解(转)
原文链接:Spark Streaming性能调优详解 Spark Streaming提供了高效便捷的流式处理模式,但是在有些场景下,使用默认的配置达不到最优,甚至无法实时处理来自外部的数据,这时候我们 ...
- Spark Streaming性能调优
数据接收并行度调优(一) 通过网络接收数据时(比如Kafka.Flume),会将数据反序列化,并存储在Spark的内存中.如果数据接收称为系统的瓶颈,那么可以考虑并行化数据接收.每一个输入DStrea ...
随机推荐
- UI多线程调用:线程间操作无效: 从不是创建控件"Form1"的线程访问它.
有两种方式解决 1.在窗体构造函数中写Control.CheckForIllegalCrossThreadCalls =false;2.使用Invoke等委托函数. 问题原因是.net2.0以后拒绝多 ...
- bisect模块用于插入
参考链接: chttp://www.cnblogs.com/skydesign/archive/2011/09/02/2163592.html水
- 2 分支语句——《Swift3.0 从入门到出家》
2 分支语句 当程序面临多个选择,每一个选择都会执行不同的代码块,这个时候就要使用分支语句.常见的分支语句有: if 选择语句:if... if…else if…elseif…else if是现实生活 ...
- 选择排序的JavaScript实现
思想 原址比较的排序算法.即首先找到数结构中的最小值并将其放置在第一位,然后找到第二小的值将其放置在第二位...以此类推. 代码 function selectionSort(arr) { const ...
- 1056 Mice and Rice
题意:略 思路:利用queue来模拟一轮一轮的比赛.自己第一遍做的时候完全没有用queue做的意识,代码写的贼烦最后还只得了17分,非常郁闷.通过本题反映出对queue的应用场景季度不熟悉,STL里面 ...
- thinkphp使用自定义类方法
1.通过Model调用 <?php /** * 积分模型 api接口 */ class ApiModel{ private $url = 'http://js.yunlutong.com/Cus ...
- (转)编写 DockerFile
这几天在研究怎样制作docker image. 其中使用dockerfile是一种可记录制作image的过程的并且是容易重复使用的一种方式.在园子里看到了一篇好文,于是分享到这里~~ 原文链接: ht ...
- MFC学习(二)
WinApp封装了程序的主入口WinMain,WinMain就和C语言的main函数地位一样,是Win32程序的入口.在MFC的封装中,一个程序启动,Windows调用WinMain,这个WinMai ...
- C Primer Plus学习笔记(十一)- 存储类别、链接和内存管理
存储类别 从硬件方面来看,被储存的每个值都占用一定的物理内存,C 语言把这样的一块内存称为对象(object) 对象可以储存一个或多个值.一个对象可能并未储存实际的值,但是它在储存适当的值时一定具有相 ...
- Python类(一)-实例化一个类
#-*- coding:utf-8 -*- __author__ = "MuT6 Sch01aR" class Person(): n = 123 #类变量 def __init_ ...