SQLAlchemy 学习笔记(二):ORM
照例先看层次图
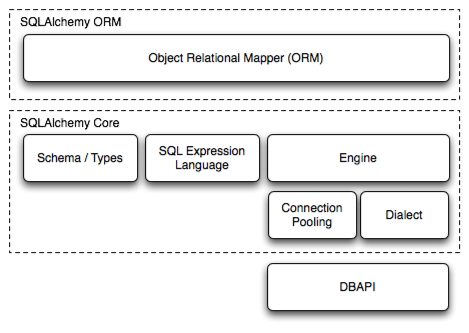
一、声明映射关系
使用 ORM 时,我们首先需要定义要操作的表(通过 Table),然后再定义该表对应的 Python class,并声明两者之间的映射关系(通过 Mapper)。
方便起见,SQLAlchemy 提供了 Declarative 系统来一次完成上述三个步骤,Declarative 系统提供 base class,这个 base class 会为继承了它的 Python class(可称作 model)创建 Table,并维护两者的映射关系。
from sqlalchemy.ext.declarative import declarative_base
from SQLAlchemy import Column, Integer, String
Base = declarative_base() # 拿到 Base 类
class User(Base):
id = Column(Integer, primary_key=True)
username = Column(String(32), nullable=False, index=True) # 添加 index 提升搜索效率
fullname = Column(String(64))
password = Column(String(32)) # 真实情况下一般只存 hash
def __repr__(self):
return f"<User {self.username}>"
这样就声明好了一个对象-关系映射,上一篇文章说过所有的 Table 都在某个 MetaData 中,可以通过 Base.metadata 获取它。
Base.metadata.create_all(engine) # 通过 metadata 创建表(或者说生成模式 schema)
engine 的创建请见上篇文档 SQLAlchemy 学习笔记(一):Engine 与 SQL 表达式语言
约束条件
可参考 SQL 基础笔记(三):约束 与 SQLAlchemy 学习笔记(一):Engine 与 SQL 表达式语言 - 表定义中的约束
使用 ORM 来定义约束条件,与直接使用 SQL 表达式语言定义很类似,也有两种方法:
- 直接将约束条件作为
Column、ForeignKey的参数传入。这种方式最简洁,也最常用。 - 使用
UniqueConstraint、CheckConstraint等类构造约束,然后放入__table_args__属性中。举例:
class User(Base):
id = Column(Integer, primary_key=True)
username = Column(String(32), nullable=False, index=True) # 添加 index 提升搜索效率
fullname = Column(String(64))
password = Column(String(32)) # 真实情况下一般只存 hash
# 顾名思义,这是 `Table` 类的参数的序列。里面的约束条件会被用于构建 __table__
__table_args__ = (UniqueConstraint('username', name='c_user'),) # username 的唯一性约束
def __repr__(self):
return f"<User {self.username}>"
二、获取 session
上一节讲 engine 时,我们是通过 connection 来与数据库交互,而在 ORM 中我们使用 Session 访问数据库。
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine) # 获取 session
三、增删改查
直接使用 SQL 表达式语言时,我们使用 insert()、select()、update()、delete() 四个函数构造 SQL,使用 where() 添加条件,使用 model.join(another_model) 进行 join 操作。
而使用 ORM 时,数据库操作不再与 SQL 直接对应。我们现在是通过操作 Python 对象来操作数据库了。
现在,我们通过 db.session.add()、db.session.delete() 进行添加与删除,使用 db.session.query(Model) 进行查询,通过 filter 和 filter_by 添加过滤条件。
而修改,则是先查询出对应的 row 对象,直接修改这个对象,然后 commit 就行。
- 增添:
ed_user = User(name='ed', fullname='Ed Jones', password='edspassword') # 用构造器构造对象
session.add(ed_user) # 添加,此外还有批量添加 add_all([user1, user2...])
session.commit() # 必须手动 commit
- 修改:
ed_user = session.query(User).filter_by(name='ed').first() # 先获取到 User 对象
ed_user.password = 'f8s7ccs' # 改了密码
session.commit() # 提交
# 批量修改
session.query(User).filter(User.home=='shanghai') \
.update({User.login_num:0}) # 将所有上海的用户的 login_num 设为 0
session.commit()
- 删除:
ed_user = session.query(User).filter_by(name='ed').first() # 先获取到 User 对象
session.delete(ed_user) # 直接删除(session 知道 ed_user 属于哪个表)
session.commit() # 提交
# 批量删除
session.query(User).filter(User.home=='shanghai') \
.delete() # 删除所有上海的用户
session.commit()
同样的,也可以在外面检查异常,然后调用 session.rollback() 实现失败回滚。
四、进阶查询
- filter_by:使用关键字参数进行过滤,前面的演示中已经用过多次了。
- filter:它对应 SQL 表达式语言中的 where,支持各种复杂的 SQL 语法。
- group_by: 通过指定 column 分组
- distinct(): 去重
- join(): 关联
query.filter(User.name == 'ed') # 这个等同于 filter_by,但是更繁琐
query.filter(User.name != 'ed') # 不等于,这个就是 filter_by 无法做到的了
query.filter(User.name.like('%ed%')) # SQL like 的 like 语法
query.filter(User.name.in_(['ed', 'wendy', 'jack'])) # 包含
# 查询还可以嵌套
query.filter(User.name.in_(
session.query(User.name).filter(User.name.like('%ed%'))
))
query.filter(~User.name.in_(['ed', 'wendy', 'jack'])) # 不包含
query.filter(User.name == None) # NULL 对应 Python 的 None
from sqlalchemy import or_, and_, in_
query.filter(or_(User.name == 'ed', User.name == 'wendy')) # OR 语法
query.group_by(User.name) # 分组
query.distinct() # 去重
from sqlalchemy import func # SQL 函数包
session.query(func.count(User.name)).filter_by(xxx=xxx) # 使用 count 函数
# join 关联
# 默认使用内联(inner),即只取两表的交集
session.query(User, Address).filter(User.id==Address.user_id) # 方法一
session.query(User).join(Address).\ # 方法二
filter(Address.email_address=='jack@google.com')
# 外联 outer join,将另一表的列联结到主表,没有的行为 NULL
session.query(User).outerjoin(User.addresses) \
.filter(Address.email_address=='jack@google.com')
执行查询,获取数据
查询返回 query 对象,但 SQL 还没有被执行,直到你调用下列几个方法:
# 构造 query 对象
query = session.query(User).filter(User.name.like('%ed')).order_by(User.id)
# 1. all 返回所有结果的列表
res_list = query.all()
# 2. first 先在 SQL 中加入限制 `limit 1`,然后执行。
res = query.first()
# 3. one 执行 sql 并获取所有结果
# 如果结果不止一行,抛出 MultipleResultsFound Error!!!
# 如果结果为空,抛出 NoResultFound Error !!!
res = query.one()
4. one_or_none 差别在于结果为空,它不抛出异常,而是返回 None
res = query.one_or_none()
参考
SQLAlchemy 学习笔记(二):ORM的更多相关文章
- WPF的Binding学习笔记(二)
原文: http://www.cnblogs.com/pasoraku/archive/2012/10/25/2738428.htmlWPF的Binding学习笔记(二) 上次学了点点Binding的 ...
- AJax 学习笔记二(onreadystatechange的作用)
AJax 学习笔记二(onreadystatechange的作用) 当发送一个请求后,客户端无法确定什么时候会完成这个请求,所以需要用事件机制来捕获请求的状态XMLHttpRequest对象提供了on ...
- [Firefly引擎][学习笔记二][已完结]卡牌游戏开发模型的设计
源地址:http://bbs.9miao.com/thread-44603-1-1.html 在此补充一下Socket的验证机制:socket登陆验证.会采用session会话超时的机制做心跳接口验证 ...
- JMX学习笔记(二)-Notification
Notification通知,也可理解为消息,有通知,必然有发送通知的广播,JMX这里采用了一种订阅的方式,类似于观察者模式,注册一个观察者到广播里,当有通知时,广播通过调用观察者,逐一通知. 这里写 ...
- java之jvm学习笔记二(类装载器的体系结构)
java的class只在需要的时候才内转载入内存,并由java虚拟机的执行引擎来执行,而执行引擎从总的来说主要的执行方式分为四种, 第一种,一次性解释代码,也就是当字节码转载到内存后,每次需要都会重新 ...
- Java IO学习笔记二
Java IO学习笔记二 流的概念 在程序中所有的数据都是以流的方式进行传输或保存的,程序需要数据的时候要使用输入流读取数据,而当程序需要将一些数据保存起来的时候,就要使用输出流完成. 程序中的输入输 ...
- 《SQL必知必会》学习笔记二)
<SQL必知必会>学习笔记(二) 咱们接着上一篇的内容继续.这一篇主要回顾子查询,联合查询,复制表这三类内容. 上一部分基本上都是简单的Select查询,即从单个数据库表中检索数据的单条语 ...
- NumPy学习笔记 二
NumPy学习笔记 二 <NumPy学习笔记>系列将记录学习NumPy过程中的动手笔记,前期的参考书是<Python数据分析基础教程 NumPy学习指南>第二版.<数学分 ...
- Learning ROS for Robotics Programming Second Edition学习笔记(二) indigo tools
中文译著已经出版,详情请参考:http://blog.csdn.net/ZhangRelay/article/category/6506865 Learning ROS for Robotics Pr ...
随机推荐
- JavaScript监控输入框字数变化,超出限制则禁止输入
JavaScript监控输入框字数变化,超出则禁止输入 不废话,给你看看效果: 1.无输入状态: 2.输入三个字符: 3.超出5个后报错: 现在粘出代码,首先是html代码: <body> ...
- Oracle数据库补充
约束: 什么是约束以及约束的作用: 为保证数据的完整性(一致性,准确性),需要对数据进行限制,这个限制就叫做约束 目的:保证数据的完整性(一致性,正确性),使数据符合业务规则(业务逻辑) 约束 ...
- beep版千与千寻主题曲(转载自Ice_watermelon233)
#include <bits/stdc++.h> #include <windows.h> #define qdo 262 #define qre 294 #define qm ...
- JetBrains 全家桶激活码
原文地址:https://blog.csdn.net/usher_ou/article/details/77970172 RDNJ63FZWD-eyJsaWNlbnNlSWQiOiJSRE5KNjNG ...
- web前端总结面试问题<经常遇到的手写代码>
冒泡排序 var arr = [5,8,3,6,9] for(var i=0;i<arr.length;i++){ for(var j=i+1;j<arr.length;j++){ if( ...
- webpack和sass功能简介
1.webpack webpack 是一个打包工具,为什么需要打包?因为有的人的脚本开发语言可能是 CoffeeScript 或者是 TypeScript,样式开发工具可能是 Less 或者 Sass ...
- collections模块的使用
1. Counter counter是collections中的一个模块, 它能够统计出字符串/文本中的每一个元素出现的次数, 并可以对结果进行进一步的处理. 使用方法 传入: 字符串 默认返回: C ...
- webBrowser 应用编程函数总结
/*============================说明部分================================= 实现一下函数需包含头文件 #include <Winine ...
- POJ-2421-Constructing Roads(最小生成树 普利姆)
Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 26694 Accepted: 11720 Description The ...
- sudo mount -o loop pm.img /mnt/floppy
sudo mount -o loop pm.img /mnt/floppy 最近在学<一个操作系统的实现>,由于这本书比较老了,所以有一些对于软盘的操作指令现在用会出现一些错误,当我进行虚 ...