【R】数据导入读取read.table函数详解,如何读取不规则的数据(fill=T)
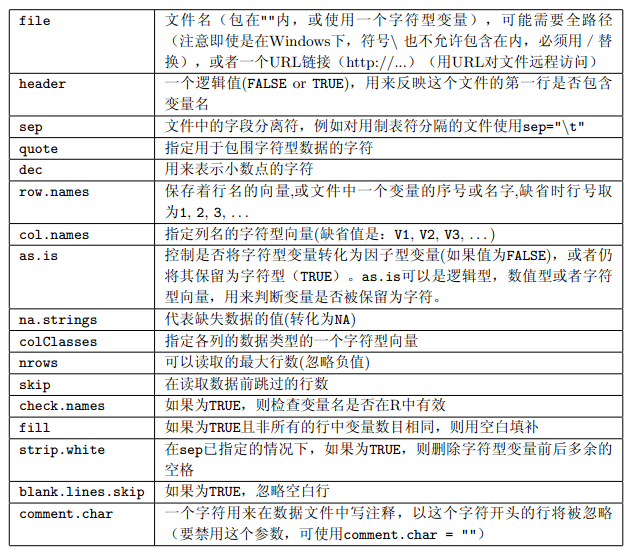
函数 read.table 是读取矩形格子状数据最为便利的方式。因为实际可能遇到的情况比较多,所以预设了一些函数。这些函数调用了 read.table 但改变了它的一些默认参数。
注意,read.table 不是一种有效地读大数值矩阵的方法:见下面的 scan 函数。
一些需要考虑到问题是:
- 编码问题
如果文件中包含非-ASCII字符字段,要确保以正确的编码方式读取。这是在UTF-8的本地系统里面读取Latin-1文件的一个主要问题。此时,可以如下处理
read.table(file("file.dat", encoding="latin1"))注意,这在任何可以呈现Latin-1名字的本地系统里面运行。
- 首行问题
我们建议你明确地设定
header参数。按照惯例,首行只有对应列的字段而没有行标签对应的字段。因此,它会比余下的行少一个字段。(如果需要在 R 里面看到这一行,设置header = TRUE。)如果要读取的文件里面有行标签的头字段(可能是空的),以下面的方式读取read.table("file.dat", header = TRUE, row.names = 1)列名字可以通过
col.names显式地设定;显式设定的名字会替换首行里面的列名字(如果存在的话)。 - 分隔符问题
通常,打开文件看一下就可以确定文件所使用的字段分隔符,但对于空白分割的文件,可以选择默认的
sep = ""(它能使用任何空白符作为分隔符,比如空格,制表符,换行符),sep = " "或者sep = "\t"。注意,分隔符的选择会影响输入的被引用的字符串。如果你有含有空字段的制表符分割的文件,一定要使用
sep = "\t"。 - 引用 默认情况下,字符串可以被 " 或 ' 括起,并且两种情况下,引号内部的字符都作为字符串的一部分。有效的引用字符(可能没有)的设置由参数
quote控制。对于sep = "\n",默认值改为quote = ""。如果没有设定分隔字符,在被引号括起的字符串里面,引号需要用 C格式的逃逸方式逃逸,即在引号前面直接加反斜杠 \。
如果设定了分隔符,在被引号括起的字符串里面,按照电子表格的习惯,把引号重复两次以达到逃逸的效果。例如
'One string isn''t two',"one more"可以被下面的命令读取
read.table("testfile", sep = ",")这在默认分隔符的文件里面不起作用。
- 缺损值 默认情况下,文件是假定用
NA表示缺损值,但是,这可以通过参数na.strings改变。参数na.strings是一个可以包括一个或多个缺损值得字符描述方式的向量。数值列的空字段也被看作是缺损值。
在数值列,值
NaN,Inf和-Inf都可以被接受的。 - 尾部空字段省略的行
从一个电子表格中导出的文件通常会把拖尾的空字段(包括?堑姆指舴? 忽略掉。为了读取这样的文件,必须设置参数
fill = TRUE。 - 字符字段中的空白
如果设定了分隔符,字符字段起始和收尾处的空白会作为字段一部分看待的。为了去掉这些空白,可以使用参数
strip.white = TRUE。 - 空白行
默认情况下,
read.table忽略空白行。这可以通过设置blank.lines.skip = FALSE来改变。但这个参数只有在和fill = TRUE共同使用时才有效。这时,可能是用空白行表明规则数据中的缺损样本。 - 变量的类型
除非你采取特别的行动,
read.table将会为数据框的每个变量选择一个合适的类型。如果字段没有缺损以及不能直接转换,它会按logical,integer,numeric和complex的顺序依次判断字段类型。如果所有这些类型都失败了,变量会转变成因子。参数
colClasses和as.is提供了很大的控制权。as.is会 抑制字符向量转换成因子(仅仅这个功能)。colClasses运行为输入中的每个列设置需要的类型。注意,
colClasses和as.is对每 列专用,而不是每个变量。因此,它对行标签列也同样适用(如果有的话)。 - 注释
默认情况下,
read.table用 # 作为注释标识字符。如果碰到该字符(除了在被引用的字符串内),该行中随后的内容将会被忽略。只含有空白和注释的行被当作空白行。如果确认数据文件中没有注释内容,用
comment.char = ""会比较安全 (也可能让速度比较快)。 - 逃逸
许多操作系统有在文本文件中用反斜杠作为逃逸标识字符的习惯,但是Windows系统是个例外(在路径名中使用反斜杠)。在 R 里面,用户可以自行设定这种习惯是否用于数据文件。
read.table和scan都有一个逻辑参数allowEscapes。从 R 2.2.0 开始,该参数默认为否,而且反斜杠是唯一被解释为逃逸引用符的字符(在前面描述的环境中)。如果该参数设为是,以C形式的逃逸规则解释,也就是控制符如\a, \b, \f, \n, \r, \t, \v,八进制和十六进制如\040和\0x2A一样描述。任何其它逃逸字符都看着是自己,包括反斜杠。
常用函数 read.csv 和 read.delim 为 read.table 设定参数以符合英语语系本地系统中电子表格导出的CSV和制表符分割的文件。这两个函数对应的变种 read.csv2 和 read.delim2 是针对在逗号作为小数点的国家使用时设计的。
如果 read.table 的可选项设置不正确,错误信息通常以下面的形式显示
Error in scan(file = file, what = what, sep = sep, :
line 1 did not have 5 elements
或者
Error in read.table("files.dat", header = TRUE) :
more columns than column names
这些信息可能足以找到问题所在,但是辅助函数 count.fields 可以进一步的深入研究问题所在。
读大的数据格子(data grid)时,效率最重要。设定 comment.char = "",以原子向量类型(逻辑型,整型,数值型,复数型,字符型或原味型)设置每列的 colClasses ,给定需要读入的行数 nrows (适当地高估一点比不设置这个参数好)等措施会提高效率。
【R】数据导入读取read.table函数详解,如何读取不规则的数据(fill=T)的更多相关文章
- 数据导入读取read.table函数详解,如何读取不规则的数据(fill=T)
函数 read.table 是读取矩形格子状数据最为便利的方式.因为实际可能遇到的情况比较多,所以预设了一些函数.这些函数调用了 read.table 但改变了它的一些默认参数. 注意,read.ta ...
- C语言memset函数详解
C语言memset函数详解 memset() 的作用:在一段内存块中填充某个给定的值,通常用于数组初始化与数组清零. 它是直接操作内存空间,mem即“内存”(memory)的意思.该函数的原型为: # ...
- AdapterView的使用与getView函数详解
作者:徐冉.文章首发在他的个人博客. ) AdapterView&Adapter家族 adapterview就是和数据有关的控件,如listview,gridview,spinnerview等 ...
- 在java poi导入Excel通用工具类示例详解
转: 在java poi导入Excel通用工具类示例详解 更新时间:2017年09月10日 14:21:36 作者:daochuwenziyao 我要评论 这篇文章主要给大家介绍了关于在j ...
- Linux C popen()函数详解
表头文件 #include<stdio.h> 定义函数 FILE * popen( const char * command,const char * type); 函数说明 popen( ...
- Netsuite Formula > Oracle函数列表速查(PL/SQL单行函数和组函数详解).txt
PL/SQL单行函数和组函数详解 函数是一种有零个或多个参数并且有一个返回值的程序.在SQL中Oracle内建了一系列函数,这些函数都可被称为SQL或PL/SQL语句,函数主要分为两大类: 单行函数 ...
- CreateFile函数详解
CreateFile函数详解 CreateFile The CreateFile function creates or opens the following objects and returns ...
- MYSQL常用内置函数详解说明
函数中可以将字段名当作变量来用,变量的值就是该列对应的所有值:在整理98在线字典数据时(http://zidian.98zw.com/),有这要一个需求,想从多音字duoyinzi字段值提取第一个拼音 ...
- Linux环境fork()函数详解
Linux环境fork()函数详解 引言 先来看一段代码吧, 1 #include <sys/types.h> 2 #include <unistd.h> 3 #include ...
随机推荐
- WordArray (An array of 32-bit words.
CryptoJS中WordArray - qiqi715 - 博客园 http://www.cnblogs.com/qiqi715/p/9623421.html
- Webstorm如何设置背景色为护眼色(豆绿色)
本文主要讲webstorm如何设置背景色. 1.打开idea Settings 选择 Editor——Color Scheme——General 注意:如果是Mac,在webstorm界面按键:“co ...
- 2015-03-06——ajax基础
IE6 必须使用Microsoft.XMLHTTP ActiveX组件来实例化一个对象 IE7已实现了XMLHttpRequest对象 var request = new ActiveXObject ...
- Git 命令行帮助
Git usage: git [--version] [--help] [-C <path>] [-c name=value] [--exec-path[=<path>]] [ ...
- Python3.6全栈开发实例[022]
22.完成彩票36选7的功能. 从36个数中随机的产生7个数. 最终获取到7个不重复的数据作为最终的开奖结果.随机数: from random import randintrandint(0, 20) ...
- 操作系统/应用程序、操作中的“并发”、线程和进程,python中线程和进程(GIL锁),python线程编写+锁
并发编程前言: 1.网络应用 1)爬虫 直接应用并发编程: 2)网络框架 django flask tornado 源码-并发编程 3)socketserver 源码-并发编程 2.运维领域 1)自动 ...
- Ubantu安装Odoo10学习日志
Windows安装是十分简单的,无论是何种方式,在了解大体情况下,我开始尝试下将Odoo搭建部署在Ubantu上. 1.Odoo是什么? Odoo是一个开源框架,针对ERP的需求发展出来,适合定制出符 ...
- Log图文详解(Log.v,Log.d,Log.i,Log.w,Log.e)
android.util.Log常用的方法有以下5个:Log.v() Log.d() Log.i() Log.w() 以及 Log.e() .根据首字母对应VERBOSE,DEBUG,INFO, WA ...
- mysql数据库补充知识7 索引原理与慢查询优化
一 介绍 为何要有索引? 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句 ...
- gearman mysql持久化
gearman 创建Mysql持久化队列的方式如下: 启动gearman,命令如下: gearmand命令: -b, –backlog=BACKLOG 连接请求队列的最大值 -d, –daemon D ...