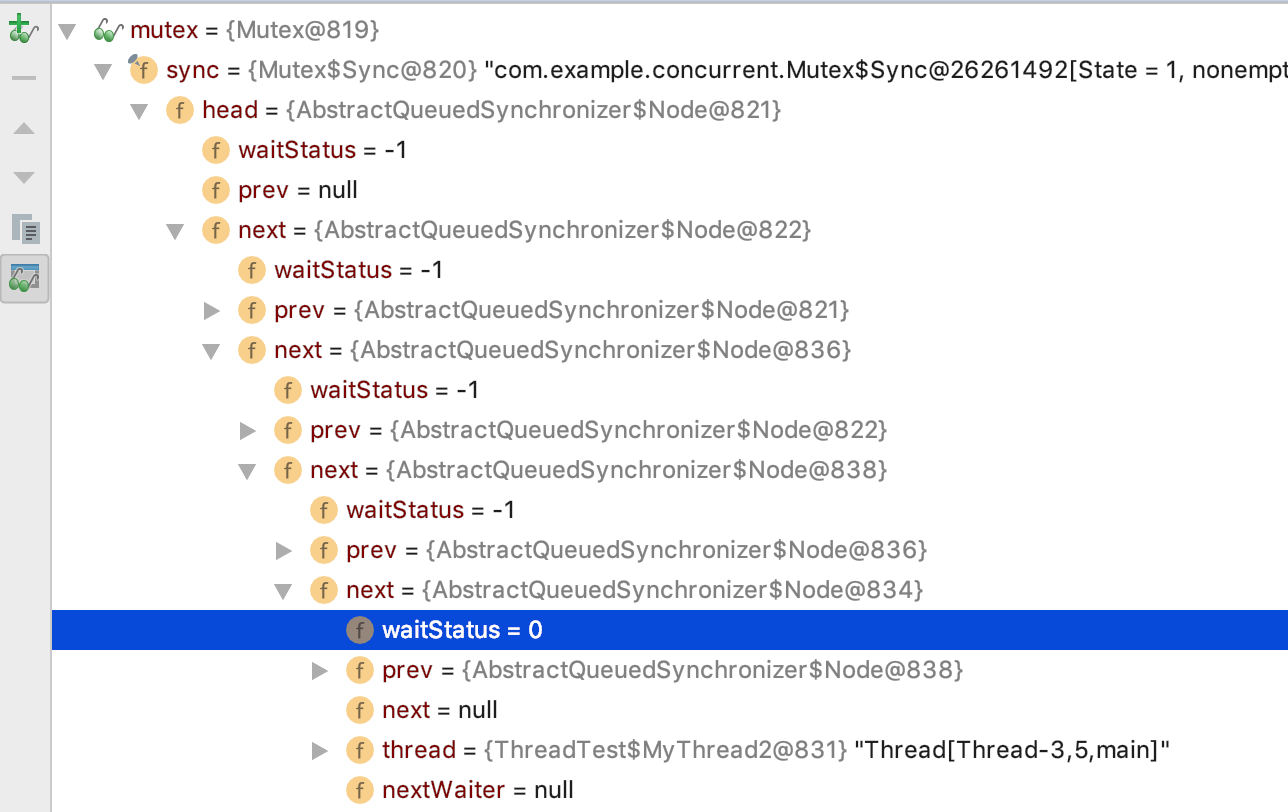
AQS的数据结构及实现原理
|
int waitStatus
|
等待状态:
1 ,在队列中等待的线程等待超时或者被中断,从队列中取消等待;
-1,后继节点处于等待;
-2,节点在等待队列中,当condition被signal()后,会从等待队列转到同步队列;
-3,表示下一次共享式同步状态获取将会被无条件传播下去;
0,初始状态
|
|
Node prev
|
前驱节点
|
|
Node next
|
后继节点
|
|
Node nextWaiter
|
等待队列中的后继节点,如果当前节点是共享的,则这个字段将是一个SHARED常量,也就是说节点类型(独占或共享)和等待队列中的后继节点共用同一字段
|
|
Thread thread
|
获取同步状态的线程
|

public final void acquire(int arg) {
if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor(); //获取当前节点的前节点
if (p == head && tryAcquire(arg)) { // 前节点为head,并且自己获取同步成功,说明前节点线程已经执行结束
setHead(node); //既然前节点的线程结束了,那就把自己设为head节点
p.next = null; // help GC //断开前节点,便于回收
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) //这里会将线程挂起
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h); //唤醒后继节点的操作在这里
return true;
}
return false;
}
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0) //小于0,说明没获取成功
doAcquireShared(arg); //继续获取
}
private void doAcquireShared(int arg) {
final Node node = addWaiter(Node.SHARED); //节点类型为共享类型
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor(); //尾节点的前一个节点(当前节点就是尾节点)
if (p == head) { //前节点是head,则再次获取锁
int r = tryAcquireShared(arg); // 这个tryAcquireShared()的返回值是共享资源的剩余量,就是还可以允许访问的线程数
if (r >= 0) { //如果获取到了锁,进行相关设置
setHeadAndPropagate(node, r); // 进行head节点替换,并且如果剩余量有剩余,则继续往下传递
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) //没获取到锁,则将线程挂起
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
private boolean doAcquireNanos(int arg, long nanosTimeout) throws InterruptedException {
if (nanosTimeout <= 0L)
return false;
final long deadline = System.nanoTime() + nanosTimeout;
final Node node = addWaiter(Node.EXCLUSIVE); //节点类型是独占式的
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) { //前节点为head,则尝试获取锁
setHead(node);
p.next = null; // help GC
failed = false;
return true;
}
nanosTimeout = deadline - System.nanoTime(); // 计算剩余时间
if (nanosTimeout <= 0L) // 剩余时间已经到了
return false;
if (shouldParkAfterFailedAcquire(p, node) && nanosTimeout > spinForTimeoutThreshold) //没获取到锁,时间也没到,则挂起一小段时间。注意如果时间剩余非常小了,比spinForTimeoutThreshold还小,则不挂起了,直接死循环一小会儿,进行获取锁
LockSupport.parkNanos(this, nanosTimeout);
if (Thread.interrupted())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
public class TwinsLock implements Lock {
private final Sync sync ;
private static final class Sync extends AbstractQueuedSynchronizer{
Sync(int count){
if(count <= 0){
throw new IllegalArgumentException("count must large than zero .");
}
setState(count); // 这里可以看到,count就是可重入的线程数
}
public int tryAcquireShared(int reduceCount){
for(;;){
int current = getState();
int newCount = current - reduceCount;
if(newCount < 0 || compareAndSetState(current, newCount)){//能把数量减掉并设置,就相当于获取锁成功
return newCount;
}
}
}
public boolean tryReleaseShared(int returnCount){
for(;;){
int current = getState();
int newCount = current + returnCount;
if(compareAndSetState(current, newCount)){
return true;
}
}
}
}
public TwinsLock (int count){
this.sync = new Sync(count);
}
@Override
public void lock() {
sync.acquireShared(1);
}
@Override
public void unlock() {
sync.releaseShared(1);
}
// 其它方法
}
public class SharedTest {
private int count = 0;
private final TwinsLock twinsLock = new TwinsLock(1);
@Test
public void test(){
MyThread mt1 = new MyThread();
MyThread mt2 = new MyThread();
MyThread mt3 = new MyThread();
MyThread mt4 = new MyThread();
MyThread mt5 = new MyThread();
mt1.start();
mt2.start();
mt3.start();
mt4.start();
mt5.start();
try {
mt1.join();
mt2.join();
mt3.join();
mt4.join();
mt5.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("最终结果:" + count);
}
class MyThread extends Thread{
@Override
public void run() {
for(int i=0;i<1000;i++){
twinsLock.lock();
try {
count = count + 1;
}catch (Exception e){
System.out.println("异常啦 ~ ~ " +e.getMessage());
}finally {
twinsLock.unlock();
}
}
}
}
}
AQS的数据结构及实现原理的更多相关文章
- Java 中队列同步器 AQS(AbstractQueuedSynchronizer)实现原理
前言 在 Java 中通过锁来控制多个线程对共享资源的访问,使用 Java 编程语言开发的朋友都知道,可以通过 synchronized 关键字来实现锁的功能,它可以隐式的获取锁,也就是说我们使用该关 ...
- MySQL索引背后的数据结构及算法原理【转】
本文来自:张洋的MySQL索引背后的数据结构及算法原理 摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持 ...
- MySQL 索引背后的数据结构及算法原理
本文转载自http://blog.jobbole.com/24006/ 摘要本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引 ...
- MySQL索引背后的数据结构及算法原理 (转)
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- MySQL(二)索引背后的数据结构及算法原理
本文转载自CodingLabs,原文链接 MySQL索引背后的数据结构及算法原理 目录 摘要 一.数据结构及算法基础 1. 索引的本质 2. B-Tree和B+Tree 3. 为什么使用B-Tree( ...
- CodingLabs - MySQL索引背后的数据结构及算法原理
原文:CodingLabs - MySQL索引背后的数据结构及算法原理 首页 | 标签 | 关于我 | +订阅 | 微博 MySQL索引背后的数据结构及算法原理 作者 张洋 | 发布于 2011-10 ...
- MySQL索引之数据结构及算法原理
MySQL索引之数据结构及算法原理 MySQL支持多个存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BTree索引,哈希索引,全文索引等等.本文只关注BTre ...
- 一文搞懂AQS及其组件的核心原理
@ 目录 前言 AbstractQueuedSynchronizer Lock ReentrantLock 加锁 非公平锁/公平锁 lock tryAcquire addWaiter acquireQ ...
- 【转】MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
随机推荐
- HTML5 Canvas游戏开发实战 PDF扫描版
HTML5 Canvas游戏开发实战主要讲解使用HTML5 Canvas来开发和设计各类常见游戏的思路和技巧,在介绍HTML5 Canvas相关特性的同时,还通过游戏开发实例深入剖析了其内在原理,让读 ...
- 【转】Android ActionBar完全解析,使用官方推荐的最佳导航栏(上)
转载请注明出处:http://blog.csdn.net/guolin_blog/article/details/18234477 本篇文章主要内容来自于Android Doc,我翻译之后又做了些加工 ...
- angular resolve路由
import { Resolve, ActivatedRouteSnapshot, RouterStateSnapshot, Router } from "@angular/router&q ...
- Docker 的部署方式
在使用 docker run 命令启动 Docker 容器时,如果需要进行端口映射.目录挂载.网络信息等配置,整条命令将变得非常长,并且由于是一条 shell 命令,修改和复用也不方便.我们在大规模部 ...
- loj #6201. 「YNOI2016」掉进兔子洞
#6201. 「YNOI2016」掉进兔子洞 您正在打galgame,然后突然发现您今天太颓了,于是想写个数据结构题练练手: 给出一个长为 nnn 的序列 aaa. 有 mmm 个询问,每次询问三个区 ...
- Ubuntu16.04LTS安装集成开发工具IDE: CodeBlocks 和Eclipse-cdt
上文中,我们已经介绍了QT5.10.0在Ubuntu下的安装 https://www.cnblogs.com/si-lei/p/9240230.html, 接下来我们介绍CodeBlocks以及Ecl ...
- 条目八《永不建立auto_ptr的容器》
条目八<永不建立auto_ptr的容器> 重要的事说三次,永不建立auto_ptr的容器,永不建立auto_ptr的容器,永不建立auto_ptr的容器!!! 为什么? 实质是auto_p ...
- 品味ZooKeeper之纵古观今_1
品味ZooKeeper之纵古观今 本章思维导图 这一系列主要是从整体到细节来品味Zookeeper,先从宏观来展开,介绍zookeeper诞生的原因,接着介绍整体设计框架,接着是逐个细节击破. 本章是 ...
- SpringCloud-Zuul搭建
一.创建工程,在pom中引入Zuul 二.重写路由加载类,实在路由的动态注册和路由转发 package com.genius.gateway.zuul; import com.genius.gatew ...
- gnome-terminal
在终端中打开终端: gnome-terminal 同时打开多个终端: gnome-terminal --window --window 此处有几个 --window 就会打开几个终端 最大化形式打开终 ...