Python中的Unicode编码和UTF-8编码
下午看廖雪峰的Python2.7教程,看到 字符串和编码 一节,有一点感受,结合崔庆才的Python博客 ,把这种感受记录下来:
ASCII码:是用一个字节(8bit, 0-255)中的127个字母表示大小写字母,数字和一些符号.主要用来表示现代英语和西欧语言。
所以处理中文就出现问题了,因为中文处理至少需要两个字节,所以中国制定了GB2312。
所以,各国制定了各国的标准。日本制定了Shift_JIS,韩国制定了Euc-kr。。。那么,乱码就来了。
为了统一,Unicode诞生了。统一码把所有语言都统一到一套编码里。解决了乱码问题,但是存储和传输效率低下的问题又来了。
因为ASCII编码是1个字节,而Unicode编码通常是2个字节。你表示一个英文字母一个字节就够了,但是Unicode却不得不用两个字节来表示(另一个字节补0)。
为了节约,出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间(ASCII码可以看成是UTF-8的一部分,所以大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作)。
现在如果我要用Notepad编辑一个python的脚本,我打开文件的过程中,内存中就开辟了一段空间,来临时存储我保存的代码,在计算机内存中,统一使用Unicode编码。
所以我写的中文字符串,要在前面加u表示是Unicode编码的字符串。
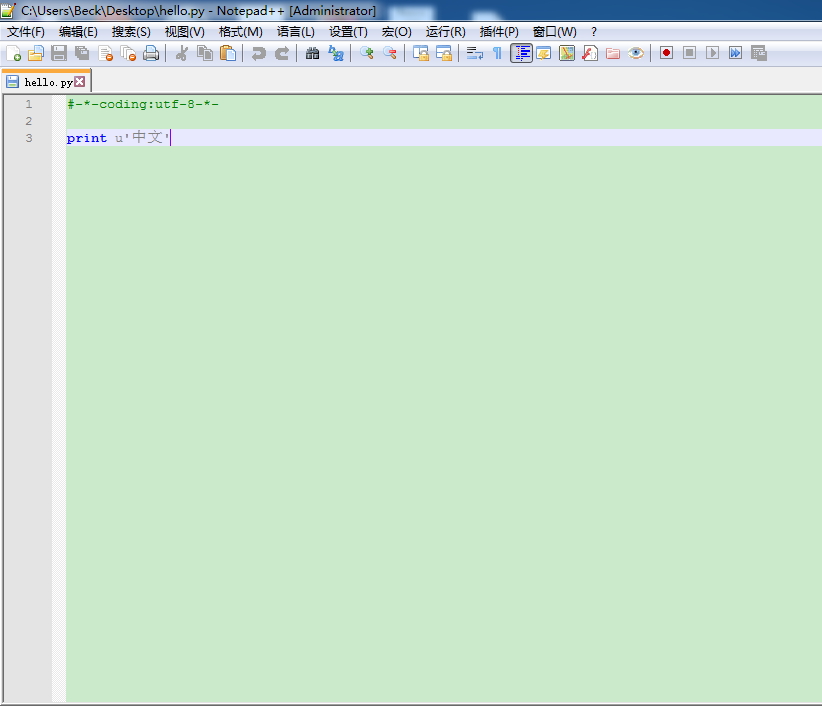
静觅博客中也是:

但是为什么有时候,我们要用到decode('utf-8'),再结合静觅博客来看:
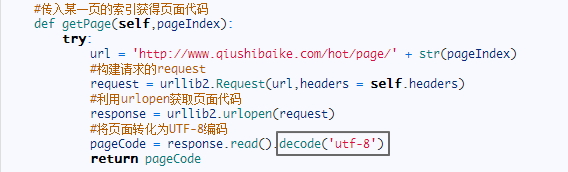
因为糗事百科的服务器发送给客户端(也就是浏览器)的响应的编码就是‘UTF-8':
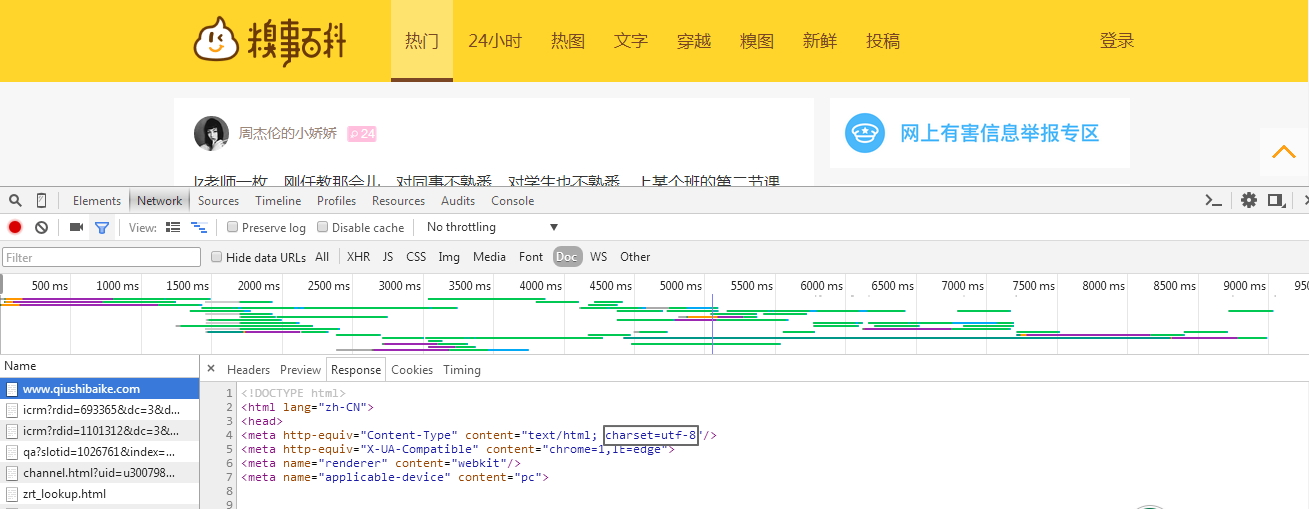

为了在文本编辑(读取文本)时,内存中需要Unicode编码,所以用decode('utf-8')解码,把UTF-8转化为Unicode编码(同理,encode('utf-8')是把Unicode转化为UTF-8编码)。
当保存文本到保存到硬盘或者需要传输的时候,就转换为UTF-8编码,所以我们需要在python脚本开头定义#-*-coding:utf-8-*-

图片来源
廖雪峰的官方网站:https://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/001386819196283586a37629844456ca7e5a7faa9b94ee8000
静觅 崔庆才的个人博客:http://cuiqingcai.com/990.html
Python中的Unicode编码和UTF-8编码的更多相关文章
- python 中的unicode详解
通过例子来看问题是比较容易懂的. 首先来看,下面这个是我新建的一个txt文件,名字叫做ivan_utf8.txt,然后里面随便编辑了一些东西. 然后来用控制台打开这个文件,同样也是截图: 这里就是简单 ...
- 关于python中的unicode字符串的使用
基于python2.7中的字符串: unicode-->编码encode('utf-8')-->写入文件 读出文件-->解码decode('utf-8')-->unicode ...
- Python中的数据类型、变量、字符编码、输入输出、注释
数据类型 number(数字) 用于存储类型,通常分为int.long.float.complex: int:32位机器上占32位,取值范围为-231 ~ 231 - 1:64位机器上占64位,取值范 ...
- python中的while循环,格式化输出,运算符,编码
一.while循环 1.1语法 while 条件: 代码块(循环体) else: 当上面的条件为假的的时候,才会执行. 执行顺序:先判断条件是否为真,如果是真的,执行循环体,再次判断条件,直到条件不成 ...
- python 中的while循环、格式化、编码初始
while循环 循环:不断重复着某件事就是循环 while 关键字 死循环:while True: 循环体 while True: # 死循环# print("坚强")# pr ...
- python中url解析 or url的base64编码
目录 from urllib.parse import urlparse, quote, unquote, urlencode1.解析url的组成成分:urlparse(url)2.url的base6 ...
- python的str,unicode对象的encode和decode方法, Python中字符编码的总结和对比bytes和str
python_2.x_unicode_to_str.py a = u"中文字符"; a.encode("GBK"); #打印: '\xd6\xd0\xce\xc ...
- python中unicode 和 str相互转化
python中的str对象其实就是"8-bit string" ,字节字符串,本质上类似java中的byte[]. 而python中的unicode对象应该才是等同于java中的S ...
- python中unicode和unicodeescape
在python中,unicode是内存编码集,一般我们将数据存储到文件时,需要将数据先编码为其他编码集,比如utf-8.gbk等. 读取数据的时候再通过同样的编码集进行解码即可. #python3 & ...
随机推荐
- Android系统移植与调试之------->如何使用PhotoShop转换24位的bmp图片为16位bmp图片
使用Android移植时候,很多图片都需要16为的bmp格式,所以研究了一下如何从24位转换成16位,供大家参阅 step1:查看bmp图片的属性,如下图所示,是24位的 step2:用PhotoSh ...
- windows 安装 python _ flask
1:首先安装python虚拟环境;(略) 2: 添加一个虚拟环境: 在你的项目目录里直接 virtualenv venv 启动虚拟环境;\venv\Scripts 直接运行activate 3: 在虚 ...
- boost之日期date_time
date_time库使用的日期基于格里高利历,支持从1400-01-01到9999-12-31的日期. 空的构造函数会创建一个值为not_a_date_time的无效日期:顺序传入年月日值则创建一个对 ...
- node.js及node-inspector的调试方法
1.先运行 $ node --debug-brk test.js 2.再在新的窗口运行: $ node-inspector 3.再打开Chrome浏览器输入node-inspector提示的地址,就会 ...
- 20170421 F110 常见问题
F110常見問題以及處理方式 1. Vendor中沒有與F110中相同的Payment method 解決辦法: 在Vendor主檔中維護Payment method 2. 結報被Block 解決辦法 ...
- second application:use an arcgis.com webmap
<!DOCTYPE html> <html> <head> <title>Create a Web Map</title> <meta ...
- Ubuntu启动自动登录并启动程序
最近在研究Ubuntu,需要在系统启动之后自动登录,并且启动某个程序. 手上拿到的系统只有一个空桌面,其他嘛也没有,鼠标右键也不管用.于是借助自己的虚拟机研究发现,自动启动程序配置文件在: /home ...
- linux ip别名和辅助ip地址
转:https://blog.csdn.net/xiewen99/article/details/54729112?utm_source=itdadao&utm_medium=referral ...
- Java Collection API
在 Java2中,有一套设计优良的接口和类组成了Java集合框架Collection,使程序员操作成批的数据或对象元素极为方便.这些接口和类有很多对抽象数据类型操作的API,而这是我们常用的且在数据结 ...
- 20145240《Java程序设计》课程总结
20145240<Java程序设计>课程总结 每周读书笔记链接汇总 20145240 <Java程序设计>第一周学习总结:http://www.cnblogs.com/2014 ...