spark学习2(hive0.13安装)
第一步:hive安装
通过WinSCP将apache-hive-0.13.1-bin.tar.gz上传到/usr/hive/目录下
[root@spark1 hive]# chmod u+x apache-hive-0.13.1-bin.tar.gz #增加执行权限
[root@spark1 hive]# tar -zxvf apache-hive-0.13.1-bin.tar.gz #解压
[root@spark1 hive]# mv apache-hive-0.13.1-bin hive-0.13
[root@spark1 hive]# vi /etc/profile #配置环境变量
export HIVE_HOME=/usr/hive/hive-0.13
export PATH=$HIVE_HOME/bin
[root@spark1 hive]# source /etc/profile #是环境变量生效
[root@spark1 hive]# which hive #查看安装路径
第二步:安装mysql
[root@spark1 hive]# yum install -y mysql-server #下载安装
[root@spark1 hive]# service mysqld start #启动mysql
[root@spark1 hive]# chkconfig mysqld on #设置开机自动启动
[root@spark1 hive]# yum install -y mysql-connector-java #yum安装mysql connector
[root@spark1 hive]# cp /usr/share/java/mysql-connector-java-5.1.17.jar /usr/hive/hive-0.13/lib #拷贝到hive中的lib目录下
第三步:在mysql上创建hive元数据库,并对hive进行授权
mysql> create database if not exists hive_metadata;
mysql> grant all privileges on hive_metadata.* to 'hive'@'%' identified by 'hive';
mysql> grant all privileges on hive_metadata.* to 'hive'@'localhost' identified by 'hive';
mysql> grant all privileges on hive_metadata.* to 'hive'@'spark1' identified by 'hive';
mysql> flush privileges;
mysql> use hive_metadata;
mysql> exit
第四步:配置文件
[root@spark1 hive]# cd /usr/hive/hive-0.13/conf #进入到conf目录
[root@spark1 conf]# mv hive-default.xml.template hive-site.xml #重命名
[root@spark1 conf]# vi hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://spark1:3306/hive_metadata?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
[root@spark1 conf]# mv hive-env.sh.template hive-env.sh #重命名
[root@spark1 ~]# vi /usr/hive/hive-0.13/bin/hive-config.sh #加入java、hive、hadoop 路径
export JAVA_HOME=/usr/java/jdk1.8
export HIVE_HOME=/usr/hive/hive-0.13
export HADOOP_HOME=/usr/hadoop/hadoop-2.6.0
[hadoop@spark1 hive]$ cd hive-0.13
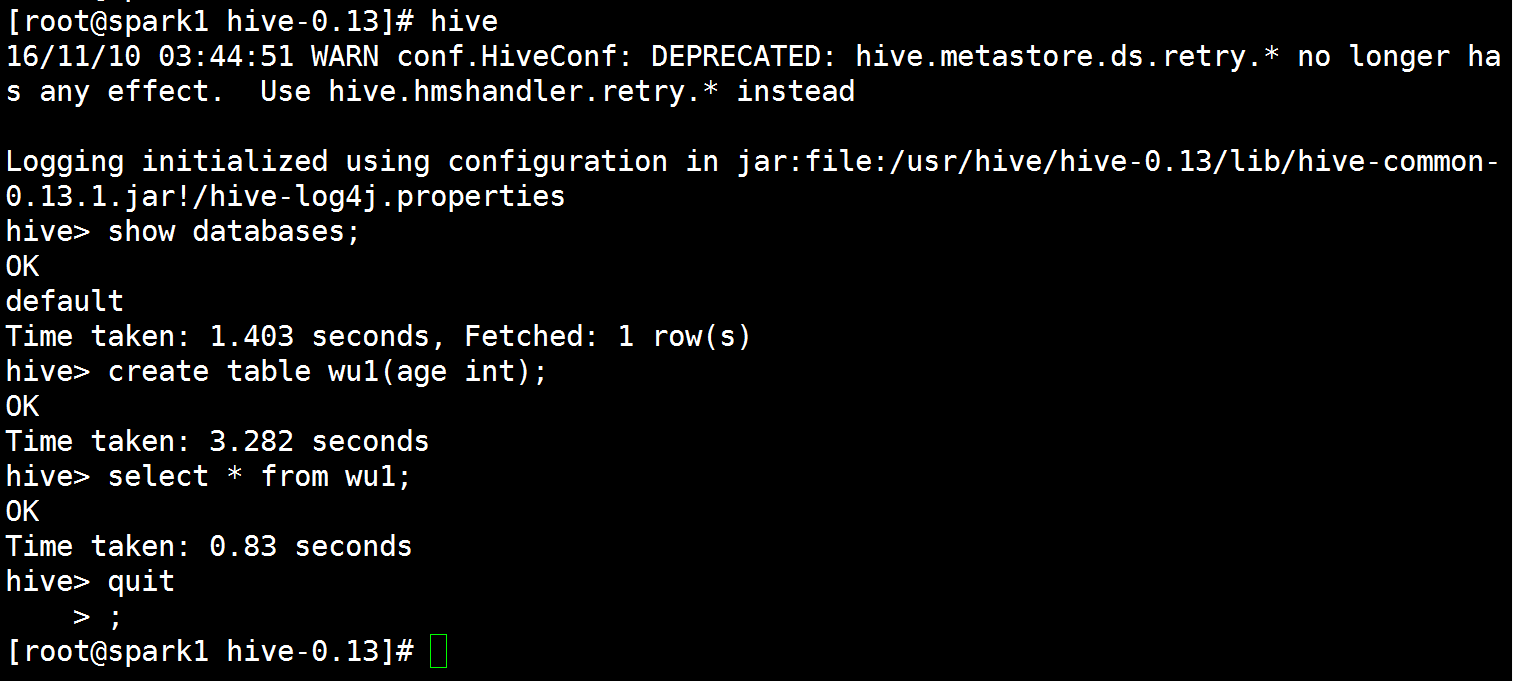
[hadoop@spark1 hive-0.13]$ hive #进入hive开始使用
测试hive
hive> show databases;
hive> create table wu1(age int);
hive> select * from wu1;
hive> quit;
结果如下图

spark学习2(hive0.13安装)的更多相关文章
- Hive-0.13安装
Hive只需在使用节点安装即可. 1.上传tar包.解压 tar -zxvf apache-hive-0.13.0-bin.tar.gz -C /hadoop/ 配置HIVE_HOME环境变量 ...
- Hive0.13.1介绍及安装部署
一.简介 hive由Facebook开源用于解决海量结构化日志的数据统计.hive是基于Hadoop的一个数据仓库工具,是基于Hadoop之上的,文件是存储在HDFS上的,底层运行的是MR程序.hiv ...
- Spark学习(一) -- Spark安装及简介
标签(空格分隔): Spark 学习中的知识点:函数式编程.泛型编程.面向对象.并行编程. 任何工具的产生都会涉及这几个问题: 现实问题是什么? 理论模型的提出. 工程实现. 思考: 数据规模达到一台 ...
- 在Hadoop-2.2.0集群上安装 Hive-0.13.1 with MySQL
fesh个人实践,欢迎经验交流!本文Blog地址:http://www.cnblogs.com/fesh/p/3872872.html 软件环境 操作系统:Ubuntu14.04 JDK版本:jdk1 ...
- hive0.13.1安装-mysql server作为hive的metastore
hive0.13.1在hadoop2.4.1伪分布式部署上安装过程 环境:redhat enterprice 6.5 +hadoop2.4.1+hive0.13.1+mysql单节点伪分布式部署 相关 ...
- spark学习2-1(hive1.2安装)
由于前面安装版本过老,导致学习过程中出现了很多问题,今天安装了一个新一点的版本.安装结束启动时遇到一点问题,记录在这里. 第一步:hive-1.2安装 通过WinSCP将apache-hive-1.2 ...
- Spark学习笔记--Linux安装Spark集群详解
本文主要讲解如何在Linux环境下安装Spark集群,安装之前我们需要Linux已经安装了JDK和Scala,因为Spark集群依赖这些.下面就如何安装Spark进行讲解说明. 一.安装环境 操作系统 ...
- _00018 Hadoop-2.2.0 + Hbase-0.96.2 + Hive-0.13.1 分布式环境整合,Hadoop-2.X使用HA方式
博文作者:妳那伊抹微笑 itdog8 地址链接 : http://www.itdog8.com(个人链接) 博客地址:http://blog.csdn.net/u012185296 个性签名:世界上最 ...
- spark 学习路线及参考课程
一.Scala编程详解: 第1讲-Spark的前世今生 第2讲-课程介绍.特色与价值 第3讲-Scala编程详解:基础语法 第4讲-Scala编程详解:条件控制与循环 第5讲-Scala编程详解:函数 ...
随机推荐
- 如何导入和导出应用数据通过电子邮件应用程序在你的IOS
本文转载至 http://blog.csdn.net/zaitianaoxiang/article/details/6657887 http://yueding920.blog.163.com/bl ...
- js 时间戳转换为指定的日期格式
function formatDate(date, fmt) { if (/(y+)/.test(fmt)) { fmt = fmt.replace(RegExp.$1, (date.getFul ...
- poj 1717==洛谷P1282 多米诺骨牌
Dominoes Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 6571 Accepted: 2178 Descript ...
- 【BZOJ3638】Cf172 k-Maximum Subsequence Sum 线段树区间合并(模拟费用流)
[BZOJ3638]Cf172 k-Maximum Subsequence Sum Description 给一列数,要求支持操作: 1.修改某个数的值 2.读入l,r,k,询问在[l,r]内选不相交 ...
- Tarjan 求桥,割,强连通
最近遇到了这种模板题,记录一下 tarjan求桥,求割 #include <bits/stdc++.h> using namespace std; #define MOD 99824435 ...
- F - 简单计算器(栈)
F - 简单计算器 Time Limit:1000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u Descripti ...
- MySQL 5.7.9修改root密码以及新特性
原文地址:http://www.cnblogs.com/Gbeniot/p/5156633.html
- AGS Server10.1中地图文档更新如何使服务更新
一.需求背景 发布服务的mxd文档发生了更改,如何对该mxd文档映射的地图服务进行更新. 二.分析 由于在10.1中地图服务的发布采用的是msd的形式,也就是虽然在ArcMap中准备的地图文档是mxd ...
- echarts系列之动态加载数据
1.echarts学习前言 最近接触到echarts,发现数据可视化真的是魅力无穷啊,各种变幻的曲线交错,以及‘曼妙’的动画效果真是让人如痴如醉! 下面就来一起欣赏她的美... “ ECharts是中 ...
- HDU1950-Bridging signals-最长上升子序列
Description 'Oh no, they've done it again', cries the chief designer at the Waferland chip factory. ...