【MySQL速通篇001】5000字吃透MySQL部分重要知识点
写在前面
这篇5000多字博客也花了我几天的时间,主要是我对MySQL一部分重要知识点的理解【后面当然还会写博客补充噻,欢迎关注我哟】,当然这篇文章可能也会有不恰当的地方【毕竟也写了这么多字,错别字可能也不少】,不足的地方欢迎各位的指正。
ps:【文章最后有相关练习题的分享】
一、主键和外键知识点补充
1.1、 主键的概念
1、什么时候用主键?2、主键有什么用处 3、一张表可以设置几个主键?4、一个主键只能是一列吗?5、主键和唯一索引有什么区别?
1)每个表应该有一个主键 。 定义一个保证唯一标识每个logging的主键。
2)数据库主键,指的是一个列或多列的组合,其值能唯一地标识表中的每一行,通过它可强制表的实体完整性。主键主要是用与其他表的外键关联,以及文本记录的修改与删除。
3) 一张表只可以有一个主键
4)主键不一定只有一列,有些表的主键是多个属性构成的。表定义为列的集合
5)主键是一种约束,唯一索引是一种索引,两者在本质上是不同的。 1、主键创建后一定包含一个唯一性索引,唯一性索引并不一定就是主键。 2、唯一性索引列允许空值,而主键列不允许为空值。 3、主键列在创建时,已经默认为空值 + 唯一索引了。 4、主键可以被其他表引用为外键,而唯一索引不能。
1.2、主键的创建
1.2.1、创建一个主键
比如我们要创建一张名为 "tb1"的表并且将它的id列设置为主键
creat table tb1(id int not null auto_increment primary key,)
1.2.2、创建多个主键
为“tb1”的表创建多个主键
creat table tb1(id int not null auto_increment ,pid int(11) not NULL,primary key(id, pid))
二、补充知识点
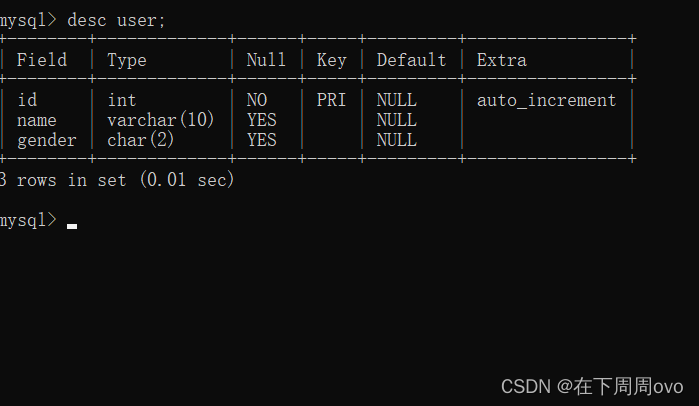
2.1、desc 表名;
desc tablenames 主要用来查看数据表的表结构
比如用以下命令创建了一张‘user’表
create table user(id int auto_increment primary key,name varchar(10),gender char(2))engine=innodb default charset=utf8;使用以上命令后可以得到如下结果:
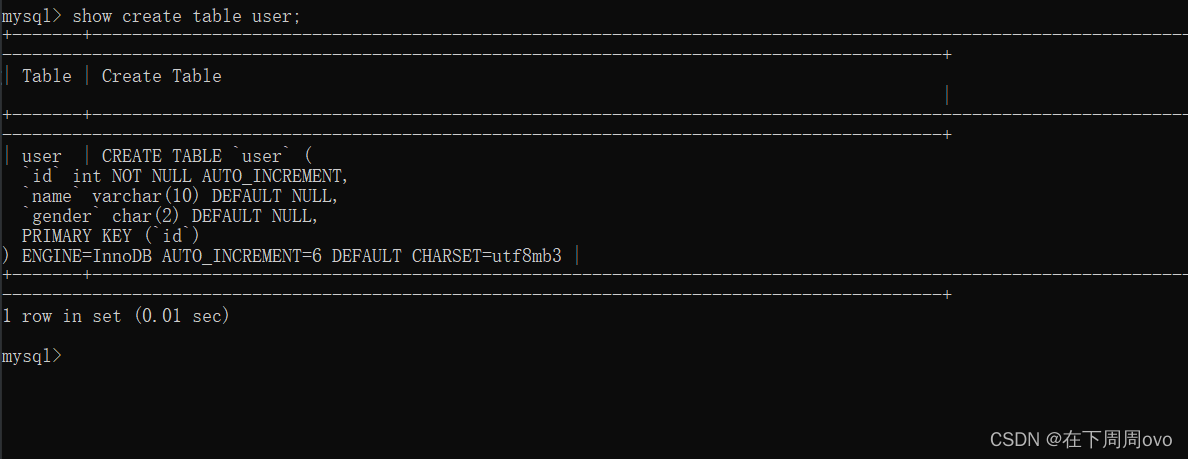
2.2、show create table 表名;
该语句的功能:查看表创建时的定义
列如对上面的‘user’表执行该操作得到如下结果:
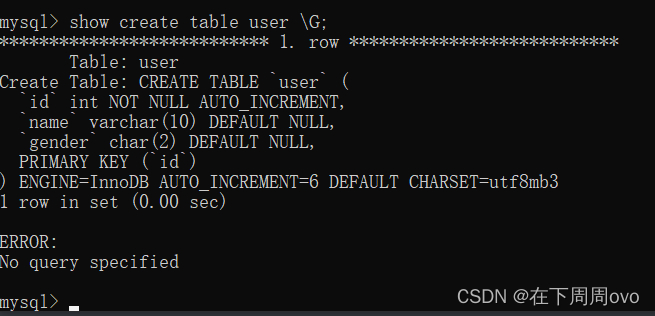
但是上面的结果看起来非常混乱,我们可以使用\G【\G 的作用是将查到的结构旋转90度变成纵向】使得结果更加美观
三、自增列起始值设置
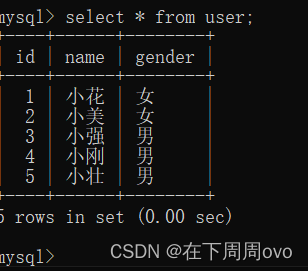
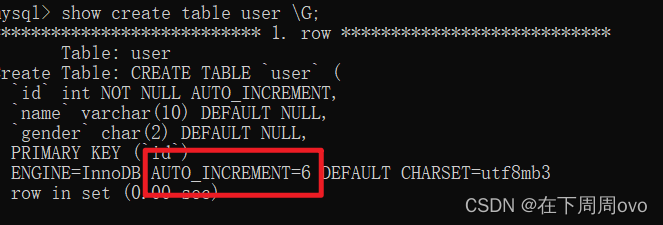
我们首先查看上面user表中的数据
不难看出这个表的id列已经自增到了5,其中show create table 表名;可以看出AUTO_INCREMENT=6,这个就表示接下来id列要递增成为的数字,
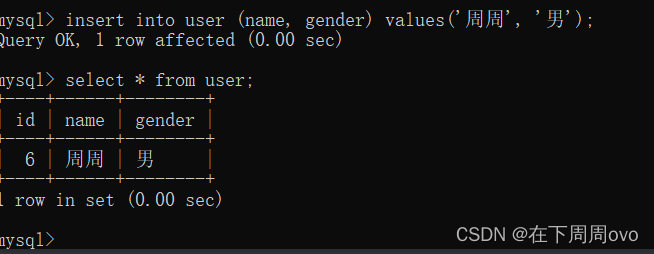
下一步我们使用delete from user;语句来删除这个表接着我们使用
insert into user (name, gender) values('周周', '男');再向表中插入一列会发现id列是从6开始递增
这时我们就会想,可不可以重新从1开始,或者自定义开始递增时的值呢?
3.1、设置自增列初始值语句
alter table user AUTO_INCREMENT=1;
要特别注意如果设置的初始值小于原来表递增列最后一个数据的值,那么语句是不会生效的
四、自增列步长设置
4.1、步长设置语法
步长设置我就不举例了,上面是设置递增列的初始值,这个是步长【不设置默认是1】
语法:
set session auto_increment_increment=2; 设置会话步长show session variables like 'auto_inc%'; 查看全局变量但是要强调一点:
MySQL: 自增步长是基于会话级别的【登入一次mysql就是一次会话】,改变一次步长之后同一次会话创建的所有表的步长都会改变为你设置的步长;
SqlServer:自增步长:是基础表级别的:可以单独的对某一张表的步长进行设置,而不改变全局的步长;
总结:SqlServer方便一点
MySQL: 自增步长基于会话级别:show session variables like 'auto_inc%'; 查看全局变量set session auto_increment_increment=2; 设置会话步长# set session auto_increment_offset=10;基于全局级别(接下来开的所有会话的步长都会改变):show global variables like 'auto_inc%'; 查看全局变量set global auto_increment_increment=2; 设置会话步长# set global auto_increment_offset=10; 设置起始值SqlServer:自增步长:基础表级别:CREATE TABLE `t5` (`nid` int(11) NOT NULL AUTO_INCREMENT,`pid` int(11) NOT NULL,`num` int(11) DEFAULT NULL,PRIMARY KEY (`nid`,`pid`)) ENGINE=InnoDB AUTO_INCREMENT=4, 步长=2 DEFAULT CHARSET=utf8CREATE TABLE `t6` (`nid` int(11) NOT NULL AUTO_INCREMENT,`pid` int(11) NOT NULL,`num` int(11) DEFAULT NULL,PRIMARY KEY (`nid`,`pid`)) ENGINE=InnoDB AUTO_INCREMENT=4, 步长=20 DEFAULT CHARSET=utf8
五、唯一索引知识点
5.1、什么是唯一索引?
所谓唯一索引,就是在创建索引时,限制索引的字段值必须是唯一的。通过该类型的索引可以比普通索引更快速地查询某条记录。唯一索引顾名思义不可以重复,但是可以为空,这也是它与主键的区别之一
5.3、创建唯一索引的方式
创建方法一:
CREATE UNIQUE INDEX indexName ON mytable(username(length))创建方法二【联合唯一索引】:
UNIQUE indexName (列名,列名),在创建表时的例子:
create table t1(id int ....,num int,xx int,UNIQUE 唯一索引名称 (列名,列名),# 示例UNIQUE uql (num,xx),)
六、外键变种详细知识点
6.1、什么是外键变种
顾名思义就是外键的多种形式,下面会通过举例子的方式讲述
6.2、外键变种之一对一
比如我们有两张表【用户表】 和【博客表】,如果每个用户只能注册一个博客,那么用户账号与博客账号的外键关系就是一对一
用户表:id name age1 xaiom 232 eagon 343 lxxx 454 owen 83博客表:id url user_id (外键 + 唯一约束)1 /xiaom 22 /zekai 13 /lxxx 34 /owen 4
6.3、外键变种之多对多
这个也是比较容易理解的,就比如我有两张表【用户表】 和【主机表】,每个用户可以登入多台主机,同时每台主机也可以被多个用户同时使用,这种关系就是多对多
用户表:id name phone1 root1 12342 root2 12353 root3 12364 root4 12375 root5 12386 root6 12397 root7 12408 root8 1241主机表:id hostname1 c1.com2 c2.com3 c3.com4 c4.com5 c5.com为了方便查询, 用户下面有多少台主机以及某一个主机上有多少个用户, 我们需要新建第三张表:用户主机表:id userid hostid1 1 12 1 23 1 34 2 45 2 56 3 27 3 4创建的时候, userid 和 hostid 必须是外键, 然后联合唯一索引 unique(userid, hostid),(避免重复出现)【联合唯一索引在多对多的情况下可以视情况而写】Django orm 也会设计
七、数据行操作补充
7.1、增操作
向表的某一行插入数据
insert into 表名(列名1, 列名2) values('行一内容', '行一内容'), ('行二内容', '行二内容')向表的多行插入数据
insert into 表名(列名1, 列名2) values('行一内容', '行一内容'), ('行二内容', '行二内容')向某一张表中插入另一张表中的内容
insert into 表一(name,age) select name,age from 表二;
7.2、删操作
假设我创建了一张表叫【tb1】其中列名有【name】列和【id】列
# 删除表delect from tb1# 带条件的删除# 把id不等于2的行删除delete from tb1 where id !=2delete from tb1 where id =2delete from tb1 where id > 2delete from tb1 where id >=2# 把id > 2,并且name='alex'的数据行删除delete from tb1 where id >=2 or name='alex'
7.3、改操作
同样的使用上面删操作的表
# 把tb1表中的id > 2,并且name='XX'的数据行,的名字设为'alex',其他的不变update tb1 set name='alex' where id>12 and name='xx'update tb1 set name='alex',age=19 where id>12 and name='xx'
7.4、查操作
基础的查操作
# 查看表中所有数据select * from tb1;# 查看表中id,name列的数据select id,name from tb1;select id,name from tb1 where id > 10 or name ='xxx';# 查看表中id,name列的数据,并将name列名重新取个叫cname的别名select id,name as cname from tb1 where id > 10 or name ='xxx';select name,age,11 from tb1;进阶的查操作
select * from tb1 where id != 1# 查看id为(1,5,12)中的数的行select * from tb1 where id in (1,5,12);select * from tb1 where id not in (1,5,12);# 查tb1表中值id为tb11中元素的行select * from tb1 where id in (select id from tb11)# 查看id为5到12之间数的行select * from tb1 where id between 5 and 12;通配符的查操作
# 查询表中以ale开头的所有用户 %表示后面可以有任意多个字符,比如可以匹配到【alex,alexk】select * from tb1 where name like "ale%"# 查询表中以ale开头的所有用户 _表示后面只能有一个字符,比如【alex】可以匹配到但是【alexxxx】就不可以匹配到select * from tb1 where name like "ale_"
7.5、limit以及order by语句
将上面知识是先看下面的图:
在我们浏览器搜素想要的内容时,返回的结果通常是很多的,如果一次将结果全部显示给你,那么电脑可能会崩溃,这时浏览器就会默认返回结果的前几十条,这种对想要查询结果的条数的限制我们在数据库中也可以使用limit来实现7.5.1、limit【限制】的用法
# 查看表中的前十条数据select * from tb1 limit 10;# 从0行开始后面取十条数据select * from tb1 limit 0,10;select * from tb1 limit 10,10;# 从20行开始后面取十条数据select * from tb1 limit 20,10;# 从第20行开始读取,读取10行;select * from tb1 limit 10 offset 20;7.5.2、order by【排序语句】
# 将表tb1按id列从大到小排select * from tb1 order by id desc; 大到小 【口诀先d后c,d在c后面所以是从大到小】select * from tb1 order by id asc; 小到大 【口诀先a后c,c在a后面所以是从小到大】# 将表tb1按age列从大到小排,如果id数值相同就按id列大小从小到大排select * from tb1 order by age desc,id desc;拓展要点:取后十条数据
# 实现原理:将tb1表逆序,然后在取前十条数据,这样就相当于取了原表的最后十条数据select * from tb1 order by id desc limit 10;

八、MySQL分组操作知识点
关键语句:
group by首先我们按如下的方式创建两张表【department表】【userinfo表】
department表CREATE table department(id int auto_increment primary key,title varchar(32))engine=innodb default charset=utf8;userinfo表CREATE table userinfo(id int auto_increment primary key,name varchar(32),age int,depart_id int,CONSTRAINT fk_usrt_depart FOREIGN key (depart_id) REFERENCES department(id))engine=innodb default charset=utf8;# 给两张表加数据# department表+----+-------+| id | title |+----+-------+| 1 | 财务 || 2 | 公关 || 3 | 测试 || 4 | 运维 |+----+-------+# userinfo表+----+------+------+-----------+| id | name | age | depart_id |+----+------+------+-----------+| 1 | 小费 | 6 | 1 || 2 | 小港 | 6 | 3 || 3 | 小干 | 6 | 2 || 4 | 小刚 | 6 | 4 || 5 | 小强 | 6 | 4 || 6 | 小美 | 6 | 4 || 7 | 小亮 | 6 | 2 || 8 | 小每 | 6 | 1 |+----+------+------+-----------+对于语句我就不多解释了,主要看结果就可以了
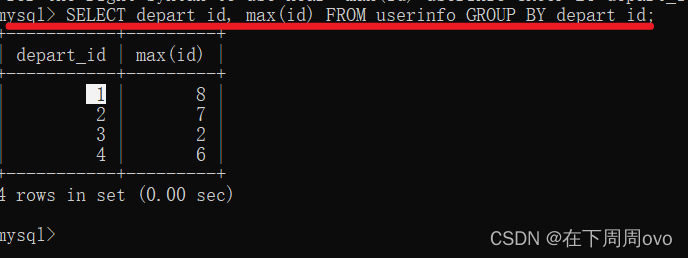
1、将同一个部门的人放在一起,并且用户部门相同取id值大的用户
SELECT depart_id, max(id) FROM userinfo GROUP BY depart_id;输出结果:
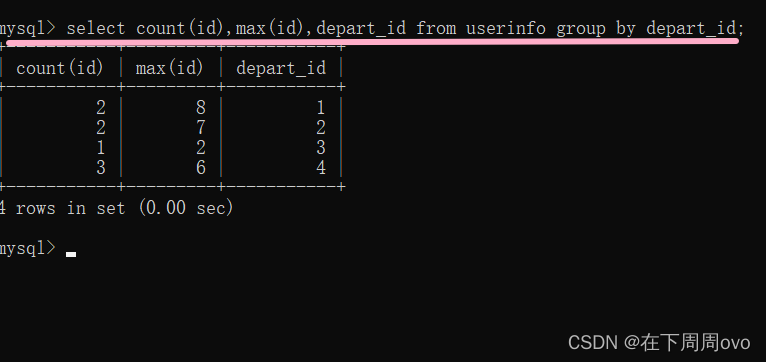
2、在上面操作的基础上显示各个部门的人数
select count(id),max(id),depart_id from userinfo group by depart_id;输出结果:
3、如果对于聚合函数结果进行二次筛选时?必须使用having
select count(id),depart_id from userinfo group by depart_id having count(id) > 1;
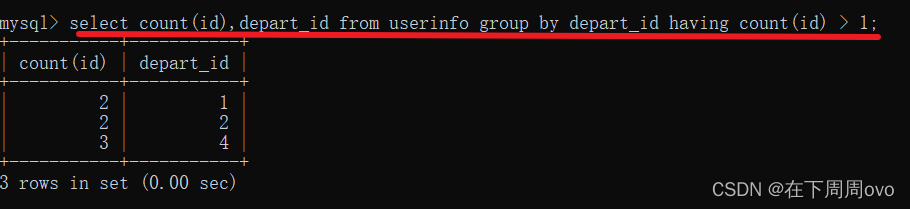
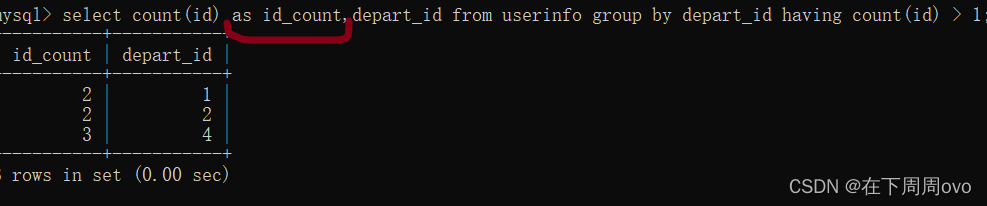
4、上面的列名为count(id),这是看着有点不舒服的,我们可以使用as关键字改名
5、进一步的进阶方式
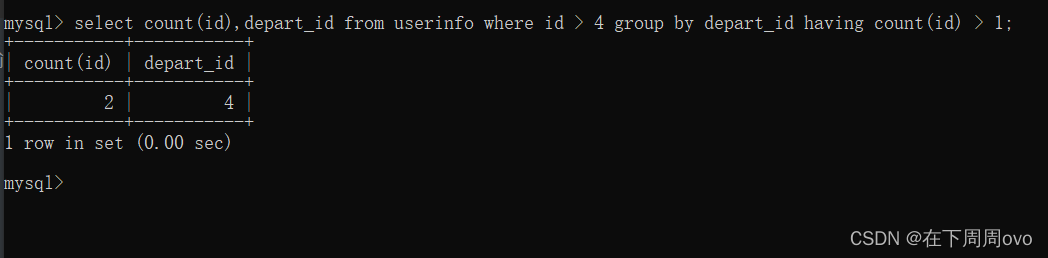
select count(id),depart_id from userinfo where id > 4 group by depart_id having count(id) > 1;
九、MySQL连表操作
9.1、连表操作概念
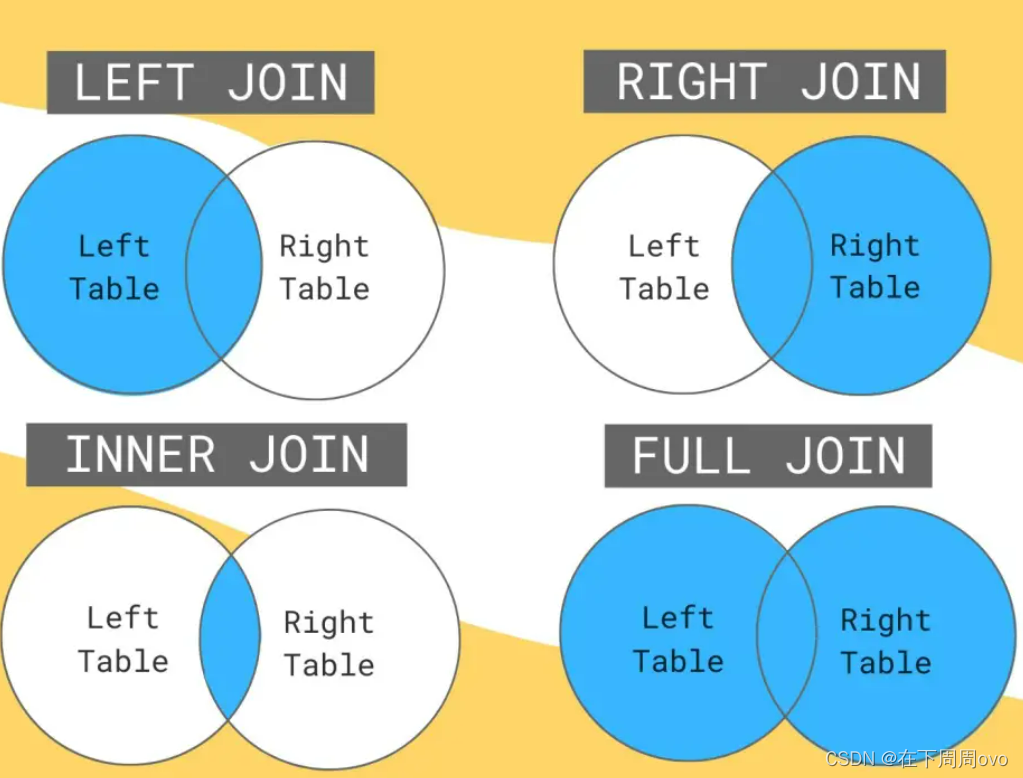
连表顾名思义就是将两张表连在一起查看的操作,操作大的分为两种内连接和外连接,而外连接又分为左连接、右连接和全连接。
内连接(inner join):只包含匹配的记录。
外连接(outer join):除了包含匹配的记录还包含不匹配的记录。{
1. 左连接(left join):返回匹配的记录,以及表 A 多余的记录。
2. 右连接(right join):返回匹配的记录,以及表 B 多余的记录。
3. 全连接(full join):返回匹配的记录,以及表 A 和表 B 各自的多余记录。
}
用网上一张图比较好的图可以更加方便理解如下:
下面我们都用【department表】【user_mess表】来举例:
# department表+----+-------+| id | title |+----+-------+| 1 | 财务 || 2 | 公关 || 3 | 测试 || 4 | 运维 |+----+-------+# user_mess表+----+------+-----------+| id | name | depart_id |+----+------+-----------+| 1 | 小费 | 1 || 2 | 小港 | 1 || 3 | 小干 | 2 || 4 | 小刚 | 4 |+----+------+-----------+执行如下语句可以连接两张表:
select * from user_mess,department where user_mess.depart_id = department.id;输出结果:+----+------+-----------+----+-------+| id | name | depart_id | id | title |+----+------+-----------+----+-------+| 1 | 小费 | 1 | 1 | 财务 || 2 | 小港 | 1 | 1 | 财务 || 3 | 小干 | 2 | 2 | 公关 || 4 | 小刚 | 4 | 4 | 运维 |+----+------+-----------+----+-------+4 rows in set (0.00 sec)
9.2、内连接
内连接 语法: a inner join b ,但是一般 inner 可以省略不写,也就是如下形式
select * from a join b ;执行下面语句:
select * from user_mess join department;输出结果:+----+------+-----------+----+-------+| id | name | depart_id | id | title |+----+------+-----------+----+-------+| 4 | 小刚 | 4 | 1 | 财务 || 3 | 小干 | 2 | 1 | 财务 || 2 | 小港 | 1 | 1 | 财务 || 1 | 小费 | 1 | 1 | 财务 || 4 | 小刚 | 4 | 2 | 公关 || 3 | 小干 | 2 | 2 | 公关 || 2 | 小港 | 1 | 2 | 公关 || 1 | 小费 | 1 | 2 | 公关 || 4 | 小刚 | 4 | 3 | 测试 || 3 | 小干 | 2 | 3 | 测试 || 2 | 小港 | 1 | 3 | 测试 || 1 | 小费 | 1 | 3 | 测试 || 4 | 小刚 | 4 | 4 | 运维 || 3 | 小干 | 2 | 4 | 运维 || 2 | 小港 | 1 | 4 | 运维 || 1 | 小费 | 1 | 4 | 运维 |+----+------+-----------+----+-------+说明:像这样不加查询条件会形成 笛卡尔积 。笛卡尔积的意思是:是指包含两个集合中任意取出两个元素构成的组合的集合。// 两表分别交叉查询了一遍;也可以加上条件查询条件 on 或者 using ,两者的区别在于 都是查询出符合条件的结果集 ,但是using会优化掉相同的字段。
下面来举个栗子更好理解:
# 使用on语句添加条件select * from user_mess join department on user_mess.depart_id = department.id;输出结果:+----+------+-----------+----+-------+| id | name | depart_id | id | title |+----+------+-----------+----+-------+| 1 | 小费 | 1 | 1 | 财务 || 2 | 小港 | 1 | 1 | 财务 || 3 | 小干 | 2 | 2 | 公关 || 4 | 小刚 | 4 | 4 | 运维 |+----+------+-----------+----+-------+4 rows in set (0.00 sec)这时我们可以发现这与上面的
select * from user_mess,department where user_mess.depart_id = department.id;语句输出结果是相同的
9.3、外连接
9.3.1、左连接
语法:
# 左连接既 左边 tb_left 表作为基表(主表)显示所有行, tb_right 表作为外表 条件匹配上的就显示,没匹配上的就用 Null 填充select * from tb_left left join tb_right on tb_left.id = tb_left.id ;栗子:
select * from user_mess left join department on user_mess.depart_id = department.id;输出结果:+----+------+-----------+------+-------+| id | name | depart_id | id | title |+----+------+-----------+------+-------+| 1 | 小费 | 1 | 1 | 财务 || 2 | 小港 | 1 | 1 | 财务 || 3 | 小干 | 2 | 2 | 公关 || 4 | 小刚 | 4 | 4 | 运维 |+----+------+-----------+------+-------+4 rows in set (0.00 sec)
9.3.1、右连接
语法:
# 右连接即 右边 tb_right 表作为基表(主表)显示所有行, tb_left 表作为外表 条件匹配上的就显示,没匹配上的就用 Null 填充; 和左连接相反。select * from tb_left right join tb_right on tb_left.id = tb_left.id ;栗子:
select * from user_mess right join department on user_mess.depart_id = department.id;输出结果:+------+------+-----------+----+-------+| id | name | depart_id | id | title |+------+------+-----------+----+-------+| 2 | 小港 | 1 | 1 | 财务 || 1 | 小费 | 1 | 1 | 财务 || 3 | 小干 | 2 | 2 | 公关 || NULL | NULL | NULL | 3 | 测试 || 4 | 小刚 | 4 | 4 | 运维 |+------+------+-----------+----+-------+5 rows in set (0.00 sec)
9.3.1、全外连接
语法:
# 经查找发现 MySQL 是不支持所谓 tb_left full join tb_right 语作为 全外连接查询的,想要实现全外连接查询可以通过 union 实现,union 操作符用于合并两个或多个 SELECT 语句的结果集,语句如下:select * from tb_left left join tb_right on tb_left.id = tb_right.id union select * from tb_left right join tb_right on tb_left.id = tb_right.id ;栗子:
select * from user_mess left join department on user_mess.depart_id = department.id union select * from user_mess right join department on user_mess.depart_id = department.id;输出结果:+------+------+-----------+------+-------+| id | name | depart_id | id | title |+------+------+-----------+------+-------+| 1 | 小费 | 1 | 1 | 财务 || 2 | 小港 | 1 | 1 | 财务 || 3 | 小干 | 2 | 2 | 公关 || 4 | 小刚 | 4 | 4 | 运维 || NULL | NULL | NULL | 3 | 测试 |+------+------+-----------+------+-------+5 rows in set (0.00 sec)值得注意的是:注:当 union 和 all 一起使用时(即 union all ),重复的行不会去除。
栗子:
select * from user_mess left join department on user_mess.depart_id = department.id union all select * from user_mess right join department on user_mess.depart_id = department.id;输出结果:+------+------+-----------+------+-------+| id | name | depart_id | id | title |+------+------+-----------+------+-------+| 1 | 小费 | 1 | 1 | 财务 || 2 | 小港 | 1 | 1 | 财务 || 3 | 小干 | 2 | 2 | 公关 || 4 | 小刚 | 4 | 4 | 运维 || 2 | 小港 | 1 | 1 | 财务 || 1 | 小费 | 1 | 1 | 财务 || 3 | 小干 | 2 | 2 | 公关 || NULL | NULL | NULL | 3 | 测试 || 4 | 小刚 | 4 | 4 | 运维 |+------+------+-----------+------+-------+9 rows in set (0.00 sec)
9.4、交叉连接
概念:
交错连接 语法:tb1 cross join tb2 ;交错连接可以加查询条件,也可以不加查询条件,如果不加查询条件会形成 笛卡尔积,类似内连接效果,同样可以使用 using 语句优化字段。
栗子:
select * from user_mess cross join department;输出结果:+----+------+-----------+----+-------+| id | name | depart_id | id | title |+----+------+-----------+----+-------+| 4 | 小刚 | 4 | 1 | 财务 || 3 | 小干 | 2 | 1 | 财务 || 2 | 小港 | 1 | 1 | 财务 || 1 | 小费 | 1 | 1 | 财务 || 4 | 小刚 | 4 | 2 | 公关 || 3 | 小干 | 2 | 2 | 公关 || 2 | 小港 | 1 | 2 | 公关 || 1 | 小费 | 1 | 2 | 公关 || 4 | 小刚 | 4 | 3 | 测试 || 3 | 小干 | 2 | 3 | 测试 || 2 | 小港 | 1 | 3 | 测试 || 1 | 小费 | 1 | 3 | 测试 || 4 | 小刚 | 4 | 4 | 运维 || 3 | 小干 | 2 | 4 | 运维 || 2 | 小港 | 1 | 4 | 运维 || 1 | 小费 | 1 | 4 | 运维 |+----+------+-----------+----+-------+16 rows in set (0.00 sec)
9.5、总结各种连表操作
1、内连接和交叉连接是十分相似的,只是语句语法有所不同,但最后查询出来的结果集的效果都是一样的,添加条件查询就只查询匹配条件的行,不添加条件查询则形成 笛卡尔积(生成重复多行) 而降低效率。
2、左连接以左边表为基础表 显示所有行 ,右边表条件匹配的行显示,不匹配的则有 Null 代替。
3、右连接以右边表为基础表 显示所有行 ,左边表条件匹配的行显示,不匹配的则有 Null 代替。
十、小结
恭喜你看到了最后,现在看了这么多,不如赶快网上找些题目自己动手实践一波撒。
不知道在哪找?放心我帮你找好了。
【MySQL练习题】复制链接打开阿里云盘就行了:https://www.aliyundrive.com/s/D24NKjfNpTW
【MySQL速通篇001】5000字吃透MySQL部分重要知识点的更多相关文章
- MYSQL数据库的套接字文件,pid文件,表结构文件
socket文件:当用Unix域套接字方式进行连接时需要的文件. pid文件:MySQL实例的进程ID文件. MySQL表结构文件:用来存放MySQL表结构定义文件. 套接字文件 Unix系统下本地连 ...
- UNIX域套接字连接mysql
用户可以在配置文件中指定套接字文件的路径,如--socket=/data/mysql/mysql.sock [root@localhost ~]# mysql -uroot -p123456 -S / ...
- MySQL数据库的套接字文件和pid文件
MySQL数据库的套接字文件和pid文件 socket文件:当用Unix域套接字方式进行连接时需要的文件. pid文件:MySQL实例的进程ID文件. MySQL表结构文件:用来存放MySQL表结构定 ...
- 千金良方说:"我现在奉上179341字的MySQL资料包,还来得及吗?有"代码段、附录、和高清图!!"
上一篇"上发布过"一不小心,我就上传了 279674 字的 MySQL 学习资料到 github 上了",我在更早之前,在微信公众号"老叶茶馆"上发布 ...
- mysql时间格式化,按时间段查询的MySQL语句
描述:有一个会员表,有个birthday字段,值为'YYYY-MM-DD'格式,现在要查询一个时间段内过生日的会员,比如'06-03'到'07-08'这个时间段内所有过生日的会员. SQL语句: Se ...
- MySQL工具:管理员必备的10款MySQL工具
MySQL是一个复杂的的系统,需要许多工具来修复,诊断和优化它.幸运的是,对于管理员,MySQL已经吸引了很多软件开发商推出高品质的开源工具来解决MySQL的系统的复杂性,性能和稳定性,其中大部分是免 ...
- 一、初识MySQL数据库 二、搭建MySQL数据库(重点) 三、使用MySQL数据库 四、认识MySQL数据库的数据类型 五、操作MySQL数据库的数据(重点)
一.初识MySQL数据库 ###<1>数据库概述 1. 数据库 长期存储在计算机内的,由组织的可共享的数据集合 存储数据的仓库 文件 ...
- Database基础(一):构建MySQL服务器、 数据库基本管理 、MySQL 数据类型、表结构的调整
一.构建MySQL服务器 目标: 本案例要求熟悉MySQL官方安装包的使用,快速构建一台数据库服务器: 安装MySQL-server.MySQl-client软件包 修改数据库用户root的密码 确认 ...
- MYSQL设置远程账户登陆总结,mysql修改、找回密码、增加新用户,MySQL数据库的23个注意事项
1.5 设置及修改Mysql root用户密码1 设置密码方法mysqladmin -u root password '123456'mysqladmin -u root -p'123456' pas ...
- 连接Mysql提示Can’t connect to local MySQL server through socket的解决方法
mysql,mysqldump,Mysqladmin,php连接mysql服务常会提示下面错误: ERROR 2002 (HY000): Can't connect to local MySQL se ...
随机推荐
- uniapp vue3下的代理转发不生效问题,亲测有效解决
以前配置过vue vite 的代理转发,没想到在uniapp的代理转发下翻车了,其实是一个很小的问题.调试过程中,尝试了webpack.vite 等写法 在根目录下 创建了 vite.config.j ...
- PyTorch复现VGG学习笔记
PyTorch复现ResNet学习笔记 一篇简单的学习笔记,实现五类花分类,这里只介绍复现的一些细节 如果想了解更多有关网络的细节,请去看论文<VERY DEEP CONVOLUTIONAL N ...
- SQLMap入门——查询当前用户下的所有数据库
确定网站存在注入后,用于查询当前用户下的所有数据库 python sqlmap.py -u http://localhost/sqli-labs-master/Less-1/?id=1 --dbs
- MyBatis是如何初始化的?
摘要:我们知道MyBatis和数据库的交互有两种方式有Java API和Mapper接口两种,所以MyBatis的初始化必然也有两种:那么MyBatis是如何初始化的呢? 本文分享自华为云社区< ...
- 【转载】VUE入门教程
vue-cli是官方提供的一个脚手架,用于快速生成一vue项目,有点类似java中使用maven构建项目 需要环境 Node.js : http://nodejs.cn/download/ 安装完后在 ...
- [数据结构]深度优先搜索算法(Depth-First-Search,DFS)
深度优先搜索算法的概念 与广度优先搜索算法不同,深度优先搜索算法类似与树的先序遍历.这种搜索算法所遵循的搜索策略是尽可能"深"地搜索一个图.它的基本思想如下:首先访问图中某一个起始 ...
- P8881 懂事时理解原神
简要题意 \(T\) 组数据,每组数据给出一个 \(n\) 个顶点,\(m\) 条边的无向无权图.求出使用下面的伪代码求 \(1\) 为源点的单源最短路答案正确的概率.保留 \(3\) 位小数. in ...
- 基于 VScode 搭建 Qt 运行环境
插件 C/C++ Qt tools Qt Configure CMake CMake Tools 下载 qt https://download.qt.io/official_releases/onli ...
- Java基础学习笔记-类的静态属性和静态方法--待继续补充
程序运行时的内存占用 代码区(code area) 存放代码 数据区(data area) 存放全局数据.静态数据 堆区(heap area) 存放动态申请的数据 栈区(stack area) 存放局 ...
- 如何通过Java应用程序添加或删除 PDF 中的附件
当我们在制作PDF文件或者PPT演示文稿的时候,为了让自己的文件更全面详细,就会在文件中添加附件.并且将相关文档附加到 PDF 可以方便文档的集中管理和传输.那么如何添加或删除 PDF 中的附件呢?别 ...