8.Flink实时项目之CEP计算访客跳出
1.访客跳出明细介绍
首先要识别哪些是跳出行为,要把这些跳出的访客最后一个访问的页面识别出来。那么就要抓住几个特征:
该页面是用户近期访问的第一个页面,这个可以通过该页面是否有上一个页面(last_page_id)来判断,如果这个表示为空,就说明这是这个访客这次访问的第一个页面。
首次访问之后很长一段时间(自己设定),用户没继续再有其他页面的访问。
这第一个特征的识别很简单,保留 last_page_id 为空的就可以了。但是第二个访问的判断,其实有点麻烦,首先这不是用一条数据就能得出结论的,需要组合判断,要用一条存在的数据和不存在的数据进行组合判断。而且要通过一个不存在的数据求得一条存在的数据。更麻烦的他并不是永远不存在,而是在一定时间范围内不存在。那么如何识别有一定失效的组合行为呢?
最简单的办法就是 Flink 自带的 CEP 技术。这个 CEP 非常适合通过多条数据组合来识别某个事件。
用户跳出事件,本质上就是一个条件事件加一个超时事件的组合。
流程图
2.代码实现
创建任务类UserJumpDetailApp.java,从kafka读取页面日志
import com.zhangbao.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
/**
* @author zhangbao
* @date 2021/10/17 10:38
* @desc
*/
public class UserJumpDetailApp {
public static void main(String[] args) {
//webui模式,需要添加pom依赖
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
// StreamExecutionEnvironment env1 = StreamExecutionEnvironment.createLocalEnvironment();
//设置并行度
env.setParallelism(4);
//设置检查点
// env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setCheckpointTimeout(60000);
// env.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/gmall/flink/checkpoint/userJumpDetail"));
// //指定哪个用户读取hdfs文件
// System.setProperty("HADOOP_USER_NAME","zhangbao");
//从kafka读取数据源
String sourceTopic = "dwd_page_log";
String group = "user_jump_detail_app_group";
String sinkTopic = "dwm_user_jump_detail";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(sourceTopic, group);
DataStreamSource<String> kafkaDs = env.addSource(kafkaSource);
kafkaDs.print("user jump detail >>>");
try {
env.execute("user jump detail task");
} catch (Exception e) {
e.printStackTrace();
}
}
}3. flink CEP编程
官方文档:https://nightlies.apache.org/flink/flink-docs-release-1.12/dev/libs/cep.html
处理流程
1.从kafka读取日志数据
2.设定时间语义为事件时间并指定事件时间字段ts
3.按照mid分组
4.配置CEP表达式
1.第一次访问的页面:last_page_id == null
2.第一次访问的页面在10秒内,没有进行其他操作,没有访问其他页面
5.根据表达式筛选流
6.提取命中的数据
设定超时时间标识 timeoutTag
flatSelect 方法中,实现 PatternFlatTimeoutFunction 中的 timeout 方法。
所有 out.collect 的数据都被打上了超时标记
本身的 flatSelect 方法因为不需要未超时的数据所以不接受数据。
通过 SideOutput 侧输出流输出超时数据
7.将跳出数据写回到kafka
package com.zhangbao.gmall.realtime.app.dwm;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.zhangbao.gmall.realtime.utils.MyKafkaUtil;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkGenerator;
import org.apache.flink.api.common.eventtime.WatermarkGeneratorSupplier;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.cep.CEP;
import org.apache.flink.cep.PatternFlatSelectFunction;
import org.apache.flink.cep.PatternFlatTimeoutFunction;
import org.apache.flink.cep.PatternStream;
import org.apache.flink.cep.pattern.Pattern;
import org.apache.flink.cep.pattern.conditions.SimpleCondition;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.util.List;
import java.util.Map;
/**
* @author zhangbao
* @date 2021/10/17 10:38
* @desc
*/
public class UserJumpDetailApp {
public static void main(String[] args) {
//webui模式,需要添加pom依赖
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
// StreamExecutionEnvironment env1 = StreamExecutionEnvironment.createLocalEnvironment();
//设置并行度
env.setParallelism(4);
//设置检查点
// env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setCheckpointTimeout(60000);
// env.setStateBackend(new FsStateBackend("hdfs://hadoop101:9000/gmall/flink/checkpoint/userJumpDetail"));
// //指定哪个用户读取hdfs文件
// System.setProperty("HADOOP_USER_NAME","zhangbao");
//从kafka读取数据源
String sourceTopic = "dwd_page_log";
String group = "user_jump_detail_app_group";
String sinkTopic = "dwm_user_jump_detail";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(sourceTopic, group);
DataStreamSource<String> jsonStrDs = env.addSource(kafkaSource);
/*//测试数据
DataStream<String> jsonStrDs = env
.fromElements(
"{\"common\":{\"mid\":\"101\"},\"page\":{\"page_id\":\"home\"},\"ts\":10000} ",
"{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"home\"},\"ts\":12000}",
"{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"good_list\",\"last_page_id\":" +
"\"home\"},\"ts\":15000} ",
"{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"good_list\",\"last_page_id\":" +
"\"detail\"},\"ts\":30000} "
);
dataStream.print("in json:");*/
//对读取到的数据进行结构转换
SingleOutputStreamOperator<JSONObject> jsonObjDs = jsonStrDs.map(jsonStr -> JSON.parseObject(jsonStr));
// jsonStrDs.print("user jump detail >>>");
//从flink1.12开始,时间语义默认是事件时间,不需要额外指定,如果是之前的版本,则要按以下方式指定事件时间语义
//env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//指定事件时间字段
SingleOutputStreamOperator<JSONObject> jsonObjWithTSDs = jsonObjDs.assignTimestampsAndWatermarks(
WatermarkStrategy.<JSONObject>forMonotonousTimestamps().withTimestampAssigner(
new SerializableTimestampAssigner<JSONObject>() {
@Override
public long extractTimestamp(JSONObject jsonObject, long l) {
return jsonObject.getLong("ts");
}
}
));
//按照mid分组
KeyedStream<JSONObject, String> ketByDs = jsonObjWithTSDs.keyBy(
jsonObject -> jsonObject.getJSONObject("common").getString("mid")
);
/**
* flink CEP表达式
* 跳出规则,满足两个条件:
* 1.第一次访问的页面:last_page_id == null
* 2.第一次访问的页面在10秒内,没有进行其他操作,没有访问其他页面
*/
Pattern<JSONObject, JSONObject> pattern = Pattern.<JSONObject>begin("first")
.where( // 1.第一次访问的页面:last_page_id == null
new SimpleCondition<JSONObject>() {
@Override
public boolean filter(JSONObject jsonObject) throws Exception {
String lastPageId = jsonObject.getJSONObject("page").getString("last_page_id");
System.out.println("first page >>> "+lastPageId);
if (lastPageId == null || lastPageId.length() == 0) {
return true;
}
return false;
}
}
).next("next")
.where( //2.第一次访问的页面在10秒内,没有进行其他操作,没有访问其他页面
new SimpleCondition<JSONObject>() {
@Override
public boolean filter(JSONObject jsonObject) throws Exception {
String pageId = jsonObject.getJSONObject("page").getString("page_id");
System.out.println("next page >>> "+pageId);
if(pageId != null && pageId.length()>0){
return true;
}
return false;
}
}
//时间限制模式,10S
).within(Time.milliseconds(10000));
//将cep表达式运用到流中,筛选数据
PatternStream<JSONObject> patternStream = CEP.pattern(ketByDs, pattern);
//从筛选的数据中再提取数据超时数据,放到侧输出流中
OutputTag<String> timeOutTag = new OutputTag<String>("timeOut"){};
SingleOutputStreamOperator<Object> outputStreamDS = patternStream.flatSelect(
timeOutTag,
//获取超时数据
new PatternFlatTimeoutFunction<JSONObject, String>() {
@Override
public void timeout(Map<String, List<JSONObject>> map, long l, Collector<String> collector) throws Exception {
List<JSONObject> first = map.get("first");
for (JSONObject jsonObject : first) {
System.out.println("time out date >>> "+jsonObject.toJSONString());
//所有 out.collect 的数据都被打上了超时标记
collector.collect(jsonObject.toJSONString());
}
}
},
//获取未超时数据
new PatternFlatSelectFunction<JSONObject, Object>() {
@Override
public void flatSelect(Map<String, List<JSONObject>> map, Collector<Object> collector) throws Exception {
//不超时的数据不提取,所以这里不做操作
}
}
);
//获取侧输出流的超时数据
DataStream<String> timeOutDs = outputStreamDS.getSideOutput(timeOutTag);
timeOutDs.print("jump >>> ");
//将跳出数据写回到kafka
timeOutDs.addSink(MyKafkaUtil.getKafkaSink(sinkTopic));
try {
env.execute("user jump detail task");
} catch (Exception e) {
e.printStackTrace();
}
}
}
测试数据
将从kafka读取数据的方式切换成固定数据内容,如下:
//测试数据
DataStream<String> jsonStrDs = env
.fromElements(
"{\"common\":{\"mid\":\"101\"},\"page\":{\"page_id\":\"home\"},\"ts\":10000} ",
"{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"home\"},\"ts\":12000}",
"{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"good_list\",\"last_page_id\":" +
"\"home\"},\"ts\":15000} ",
"{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"good_list\",\"last_page_id\":" +
"\"detail\"},\"ts\":30000} "
);
dataStream.print("in json:");然后从dwm_user_jump_detail主题消费数据
./kafka-console-consumer.sh --bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092 --topic dwm_user_jump_detail
8.Flink实时项目之CEP计算访客跳出的更多相关文章
- 7.Flink实时项目之独立访客开发
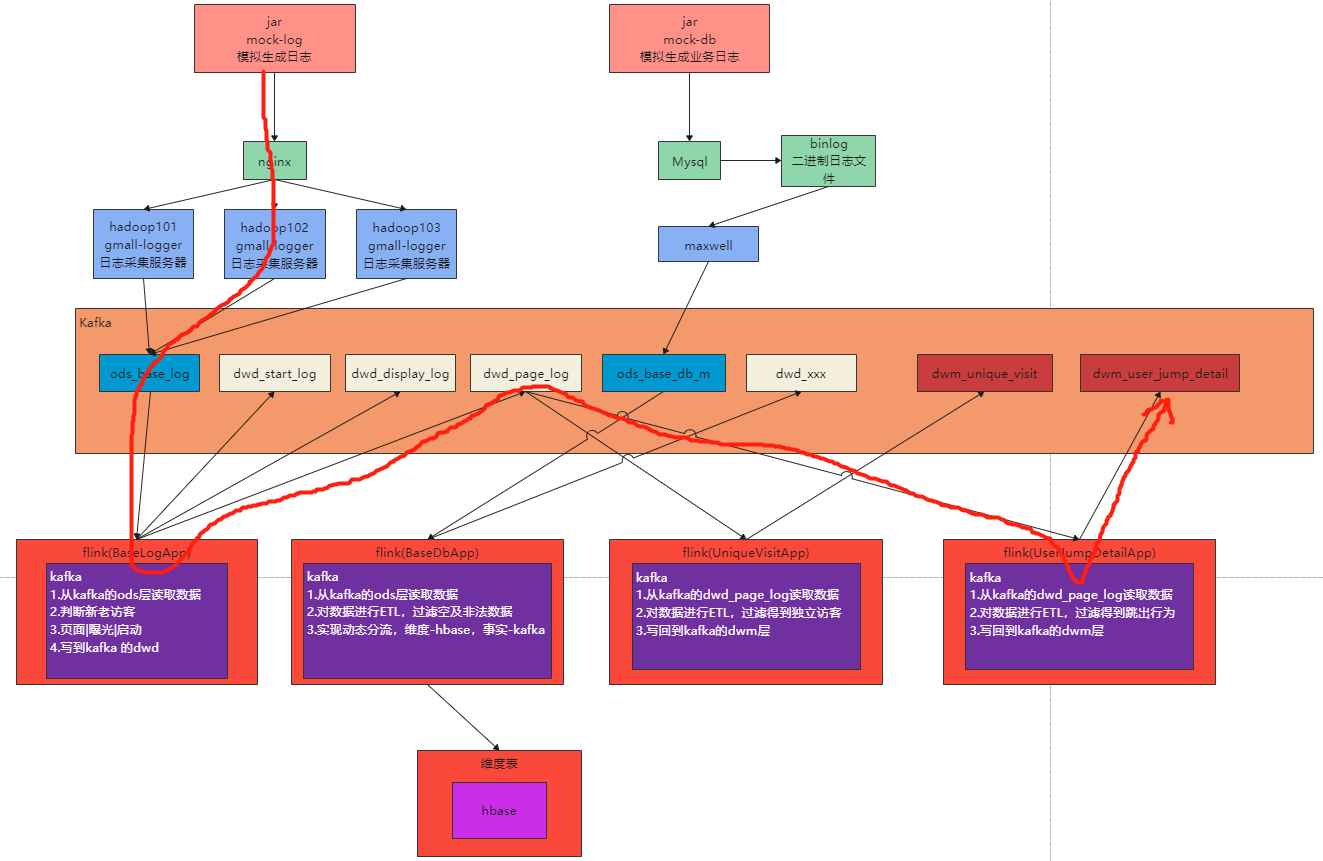
1.架构说明 在上6节当中,我们已经完成了从ods层到dwd层的转换,包括日志数据和业务数据,下面我们开始做dwm层的任务. DWM 层主要服务 DWS,因为部分需求直接从 DWD 层到DWS 层中间 ...
- 4.Flink实时项目之数据拆分
1. 摘要 我们前面采集的日志数据已经保存到 Kafka 中,作为日志数据的 ODS 层,从 kafka 的ODS 层读取的日志数据分为 3 类, 页面日志.启动日志和曝光日志.这三类数据虽然都是用户 ...
- 5.Flink实时项目之业务数据准备
1. 流程介绍 在上一篇文章中,我们已经把客户端的页面日志,启动日志,曝光日志分别发送到kafka对应的主题中.在本文中,我们将把业务数据也发送到对应的kafka主题中. 通过maxwell采集业务数 ...
- 10.Flink实时项目之订单维度表关联
1. 维度查询 在上一篇中,我们已经把订单和订单明细表join完,本文将关联订单的其他维度数据,维度关联实际上就是在流中查询存储在 hbase 中的数据表.但是即使通过主键的方式查询,hbase 速度 ...
- 11.Flink实时项目之支付宽表
支付宽表 支付宽表的目的,最主要的原因是支付表没有到订单明细,支付金额没有细分到商品上, 没有办法统计商品级的支付状况. 所以本次宽表的核心就是要把支付表的信息与订单明细关联上. 解决方案有两个 一个 ...
- 3.Flink实时项目之流程分析及环境搭建
1. 流程分析 前面已经将日志数据(ods_base_log)及业务数据(ods_base_db_m)发送到kafka,作为ods层,接下来要做的就是通过flink消费kafka 的ods数据,进行简 ...
- 9.Flink实时项目之订单宽表
1.需求分析 订单是统计分析的重要的对象,围绕订单有很多的维度统计需求,比如用户.地区.商品.品类.品牌等等.为了之后统计计算更加方便,减少大表之间的关联,所以在实时计算过程中将围绕订单的相关数据整合 ...
- 6.Flink实时项目之业务数据分流
在上一篇文章中,我们已经获取到了业务数据的输出流,分别是dim层维度数据的输出流,及dwd层事实数据的输出流,接下来我们要做的就是把这些输出流分别再流向对应的数据介质中,dim层流向hbase中,dw ...
- 1.Flink实时项目前期准备
1.日志生成项目 日志生成机器:hadoop101 jar包:mock-log-0.0.1-SNAPSHOT.jar gmall_mock |----mock_common |----mock ...
随机推荐
- 精通 Pandas · 翻译完成
协议:CC BY-NC-SA 4.0 欢迎任何人参与和完善:一个人可以走的很快,但是一群人却可以走的更远. 在线阅读 ApacheCN 面试求职交流群 724187166 ApacheCN 学习资源 ...
- Antd组件Table树型多选全选问题
组件库antd里面的树型选择不能做到勾选父组件然后一起勾选子组件情况,我也不知道是组件库的问题还是原本设计就是这样 刚好组件库存在rowselection的配置项,既然存在拓展方法,又遇到需求,那么就 ...
- Git refusing to merge unrelated histories (拒绝合并不相关仓库)
感谢原文作者:lindexi_gd 原文链接:https://blog.csdn.net/lindexi_gd/article/details/52554159 本文讲的是把git在最新2.9.2,合 ...
- git reset HEAD 与 git reset --hard HEAD的区别
感谢原文作者:天地逍遥 原文链接:https://www.jianshu.com/p/aeb50b94e6c0 git reset HEAD 是将咱暂存区和HEAD的提交保持一致 git reset ...
- Yarn命令列表
常用命令: 创建项目:yarn init 安装依赖包:yarn == yarn install 添加依赖包:yarn add Yarn命令列表 命令 操作 参数 标签 yarn add 添加依赖包 包 ...
- iOS测试模板
测试模板,每次写一个功能测试Demo时总是要新建一个工程,导入一些第三方库,比较麻烦,先提供一个测试模板,提供一些常用第三方库,自己就不用导了 使用Cocospod管理第三方库 常用(其他自行添加) ...
- Vue小白练级之路---001表单验证功能的一般实现思路
思路: 先各自验证 非空校验 具体规则校验 后兜底校验( 防止用户没输入信息直接登录 ) 实现:( 以 element-ui 为例 ) 在 标签上用 model 动态绑定收集数据的对象(form) 在 ...
- Spring中@Autowired 注解的注入规则
默认根据类型,匹配不到则根据bean名字 1.声明一个service接口 public interface HelloService { void sayHello(); } 2.service接口的 ...
- D介绍-概述
INTRODUCTION THE SELENIUM PROJECT AND TOOLS Selenium controls web browsers Selenium is many things, ...
- 磁盘分区 & Linux 三剑客之 awk
今日内容 磁盘分区 Linux 三剑客之 awk 内容详细 一.磁盘分区 磁盘分区 --> 挂载 步骤 1.关机 2.添加硬盘 3.创建分区 fdisk /dev/sdb or gdisk /d ...