公司内部一次关于OOM故障复盘分享
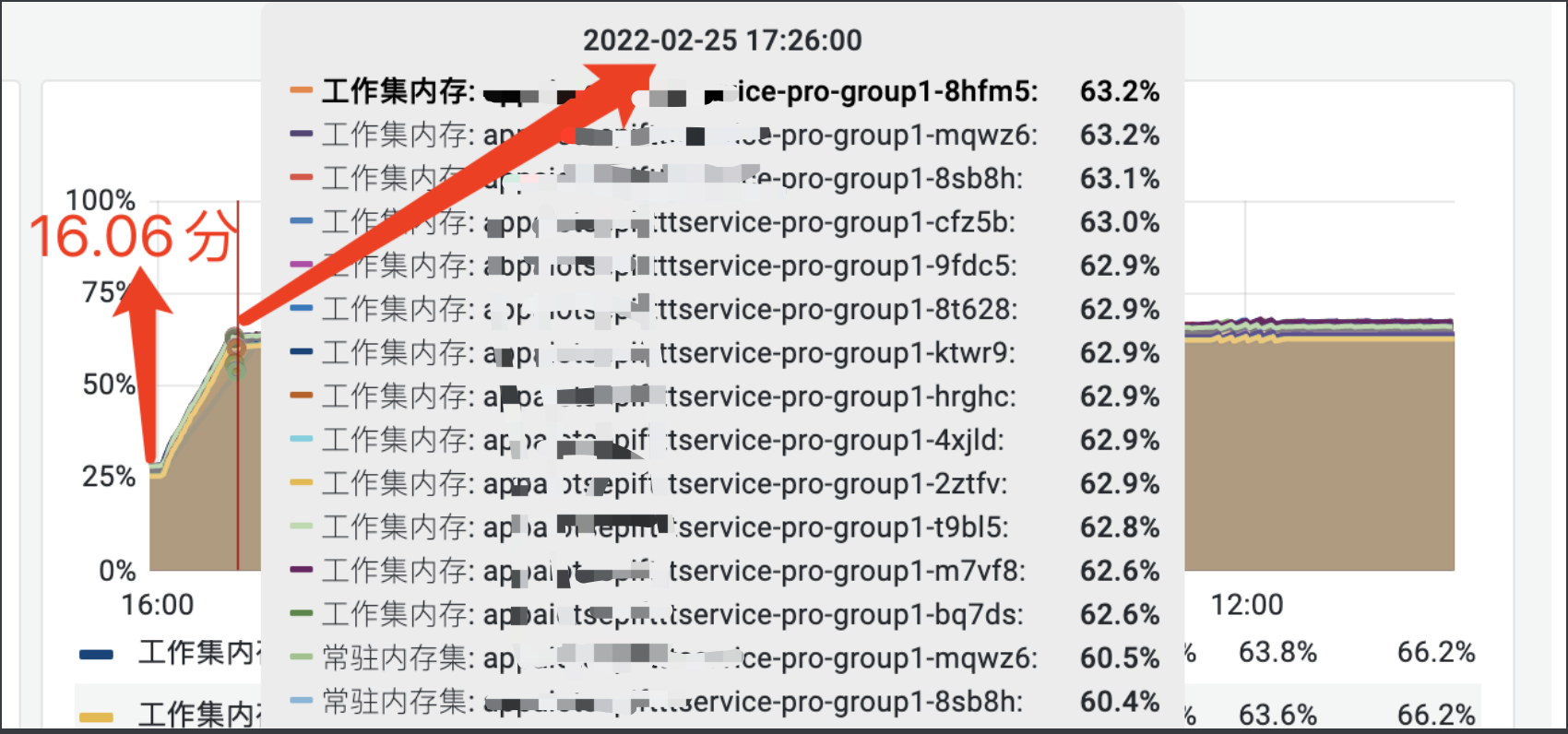
最近笔者有点忙,这次OOM事故发生过去两周前,记得笔者那天正带着家人在外地玩,正中午跟友人吃饭的时候,钉钉连续告警爆表,接着就是钉钉电话(显示广东抬头)一看就知道BBQ了,又一次故障发生了,今天把那次故障复盘一下,做个总结,也给小伙伴分享一下 我是怎么从接到告警开始,怎么一步一步分析故障,然后定位到问题,最后完美解决,成功上线解决问题的。

上述告警内容,由于笔者所在服务是用CMS垃圾回收器,当其GC次数太频繁,达到公司监控平台设置的阈值时,就会通过钉钉通知告知开发者,发送到对应的控制台上。这个异常先从字面意义上来说倒也比较明显,如果老年代里的对象太多,无法提供空间容纳年轻代传递过来的对象的时候,就会触发FULL GC。
这里我们先简单分析一下,对象什么情况下会进入老年代,以及老年代又是在什么情况下会触发FULL GC?只有先知道了原理性东西,你才能带着思路去分析,真实线上场景属于对应哪种情况
首先科普一下对象什么情况下会进入老年代?
1)躲过15次GC之后进入老年代

线上由于比较麻烦dump线程。而且现场已经过去了,所以我还是自己写了一段压测代码(类似Jmeter效果),来压测相应的总入口,看看具体是哪个对象占了大内存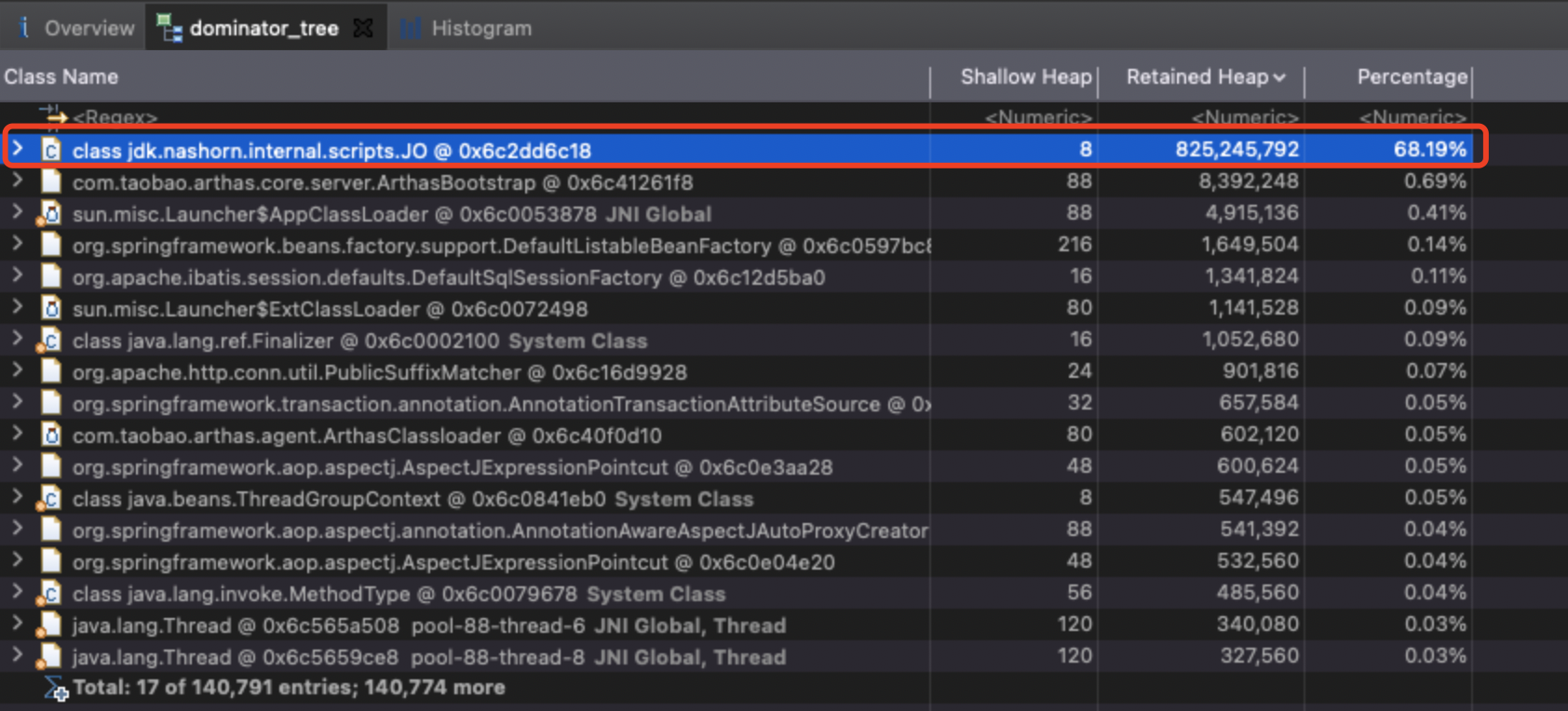
很明显是有一个nashorn相关对象占据了比较大的占比。那这个对象其实对应笔者的程序是
- ScriptEngineManager manager = new ScriptEngineManager();
ScriptEngine engine = manager.getEngineByName("nashorn");
Compilable compEngine = (Compilable) engine;
try {
CompiledScript compile = compEngine.compile(script);
}catch(Exception e){
}
简单来说,Nashorn的编译入口可以从 Context.compileScript() 开始看:[ JavaScript源码 ] -> ( 语法分析器 Parser ) -> [ 抽象语法树(AST) ir ] -> ( 编译优化 Compiler ) -> [ 优化后的AST + Java Class文件(包含Java字节码) ] -> JVM加载和执行生成的字节码 -> [ 运行结果 ]
此过程是十分耗时的,每次执行eval 去运行js ,都需要编译成字节码、然后加载执行。同时会将编译过的字节码缓存起来,以便后续使用,因此加载的类会长时间存活,占用很大的内存空间。
所以笔者尝试将CompiledScript这一对象第一次编译完后,本地缓存起来用
- private static Map<Long, CompiledScript> scriptMap = new ConcurrentHashMap<>();
缓存起来,下一次如果已经存在,就直接拿来用。
重新压测后效果还是明显的
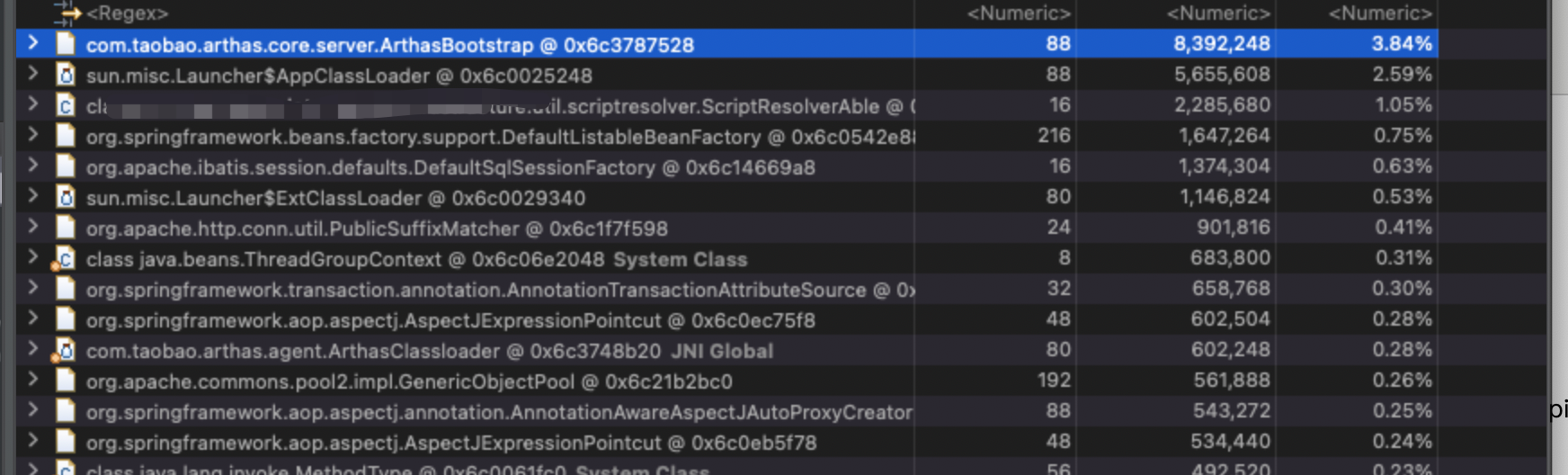
- 总结
线上场景 特别对于一些新的框架或技术 如果你的流量很大,笔者那时参与了这个项目,工期特别短,功能又特别多,想着先上线,下一步再做压测,想不到等不到下一步问题就暴露出来了
公司内部一次关于OOM故障复盘分享的更多相关文章
- 公司内部一次关于kafka消息队列消费积压故障复盘分享
背景现象 1.20晚上8点业务线开始切换LBS相关流量,在之后的1个小时时间内,积压量呈上升趋势,一路到达50W左右,第二天的图没贴出具体是50W数字,以下是第一天晚上的贴图部分. 现象一: 现象二: ...
- HBase 查询导致RegionServer OOM故障复盘
背景:我司作为某运营商公司的技术咨询公司,发现有第三方开发公司在使用HBase 1.1.2 (HDP 2.4.2.258版本)一段时间使用正常后,从某一天开始报OOM,从而导致RegionServer ...
- Rafy 领域实体框架 - 公司内部培训视频
本月给公司内部一个项目做架构重构,其中使用到了 Rafy 框架.所以我培训了 Rafy 领域实体框架的使用方法,过程中录制了视频,方便其他同事查看.现在把视频放到园里来分享下,有兴趣的朋友可以看看,有 ...
- 故障复盘究竟怎么做?美图SRE结合10年经验做了三大总结(附模板)
美图崇尚的故障文化是 "拥抱故障,卓越运维",倡导的基准是 No-Blame, 即「不指责,重改进」.今年 9 月 TakinTalks 社区曾经分享过美图的三段式故障治理方法(美 ...
- 一次线上OOM故障排查经过
转贴:http://my.oschina.net/flashsword/blog/205266 本文是一次线上OOM故障排查的经过,内容比较基础但是真实,主要是记录一下,没有OOM排查经验的同学也可以 ...
- 公司内部Samba 服务器架设
1.需求 在公司内部打造一个文件管理系统,其作用域仅仅在公司内部,支持在线对文件的修改和保存操作等,同时也要注意权限问题. 2.策划 目前设立四个群组:运维.开发 .测试和普通,当然所对应的对文件的访 ...
- 关于运维之故障复盘篇-Case Study
关于故障的事后复盘,英文名 Case Study是非常有必要做的,当然是根据故障的级别,不可能做到每个故障都Case Study,除非人员和时间充足: 文档能力也是能力的一种,一般工程师的文档能力比较 ...
- 生产环境想要对某个Pod排错、数据恢复、故障复盘有什么办法?
生产环境想要对某个Pod排错.数据恢复.故障复盘有什么办法? k8s考点灵魂拷问9连击之5 考点之简单描述一下k8s副本集ReplicaSet有什么作用? 考点之为什么ReplicaSet将取代Rep ...
- 搭建公司内部的NuGet Server
随着公司业务慢慢的拓展,项目便会越来越来多,很多项目会依赖其他项目DLL,比如一些底层的技术框架DLL引用,还有各业务系统的也有可能会有引用的可能. 项目多,交叉引用多,如果要是有一个DLL更新,那就 ...
随机推荐
- WordPress子模板继承
很多时候我们不想重写模板,而是想在某个模板的基础上进行修改,那么这个时候我们就需要用到模板继承技巧. 子主题开发 style.css 是必须的文件,只需要新增 Template: 父模板的文件夹名
- SpringMVC主要组件
1.DispatcherServlet:前端控制器,接收所有请求(如果配置/,则不包含jsp) 2.handlermapping:判断请求格式,判断希望具体要执行的那个方法 3.HanderAdapt ...
- Java线程--CompletionService使用
原创:转载需注明原创地址 https://www.cnblogs.com/fanerwei222/p/11871911.html Java线程--CompletionService使用 public ...
- Java开发调试技巧及Eclipse快捷键使用方法
1. 快捷键 syso 通过打印输出来调试,println可接受object型的参数,能输出任何类型 Syso输出的是黑色字体,代表的是Debug的信息 Syse,输出的是红色字体,代表错误的输出信息 ...
- 第一个OC类
1.如何声明一个类 格式 注意: 1.必须以@interface开头,@end结尾 2.成员变量的声明,必须写在@interface与@end之间的大括号中 3.方法的声明必须在{}下面,不能写在{} ...
- js实现网页中英文翻译
1,html 2,metrics.js 3,需要 http://www.microsoftTranslator.com/ajax/v3/WidgetV3.ashx?siteData=ueOIGRSKk ...
- 【CF888G】Xor-MST(生成树 Trie)
题目链接 大意 给出\(N\)个点的点权,定义两个点之间的边权为这两个点权的异或和,求这\(N\)个点间的最小生成树. 思路 贪心地想,相连的两个点异或和应当尽量的小. 那么应先从高位确定,因为高位的 ...
- 一加6刷入kali nethunter
Installing Kali NetHunter On the OnePlus 6 准备工具: adb: https://jingyan.baidu.com/article/22fe7cedf67e ...
- Linux基础入门笔记
今天带来Linux入门的一些基础的笔记,科班出身的同学们,Linux已经成为了必修课了,下面我带来关于Linux的相关入门知识以及Linux简单的介绍! Linux内核最初只是由芬兰人林纳斯·托瓦兹( ...
- VS Code开发TypeScript
TypeScript是JaveScript的超集,为JavaScript增加了很多特性,它可以编译成纯JavaScript在浏览器上运行.TypeScript已经成为各种流行框架和前端应用开发的首选. ...