操作系统学习笔记5 | 用户级线程 && 内核级线程
在上一部分中,我们了解到操作系统实现多进程图像需要组织、切换、考虑进程之间的影响,组织就是用PCB的队列实现,用到了一些简单的数据结构知识。而本部分重点就是进程之间的切换。
参考资料:
课程:哈工大操作系统(本部分对应 L10 && L11 && L12)
-
这一部分比较难,一难在理解,二难在实现,其中L12是最难的,反复看了很多遍。之后需要反复回顾。
1. 用户级线程
1.1 线程
我们聊的是进程切换,为什么引入了线程?
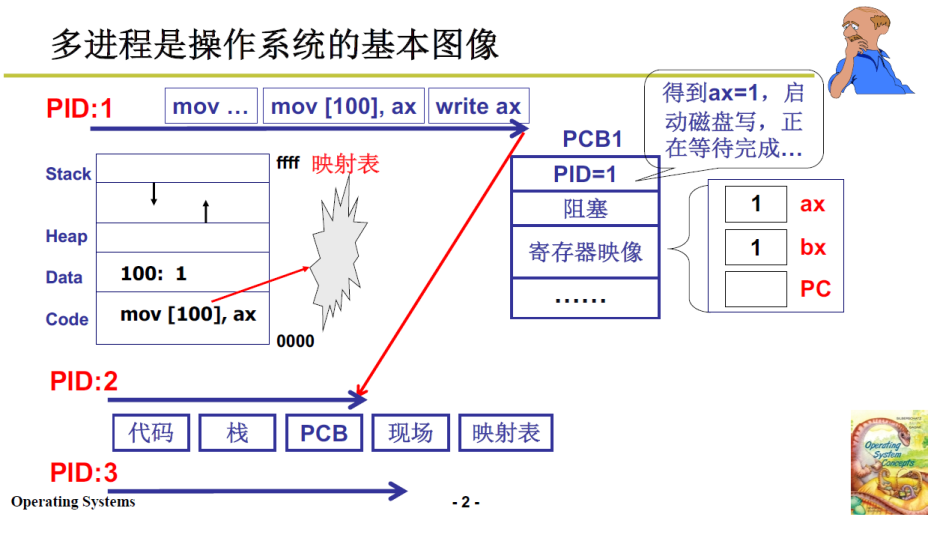
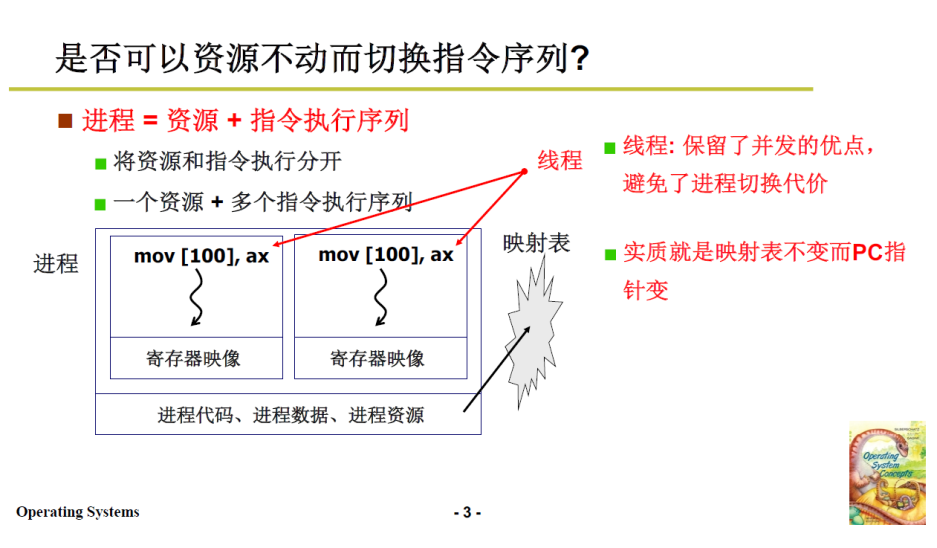
进程 = 资源 + 指令执行序列,资源包括内存映射表等等
实现进程之间的切换是需要消耗资源的,当进程切换频繁,这种消耗就不能忽视了;
是否可以资源不变,而只切换指令执行序列呢?实现了多段程序交替执行,而且不需要切换资源这种消耗时间的操作,时间上还会更快;
实质就是映射表不变而PC指针变
由此引入线程的概念,Thread.
进程 = 一个资源 + 多个指令执行序列(即多个线程)
- 只切换指令执行序列,而不切换资源
- 保留了并发的优点,避免了进程切换代价
本部分专注于线程的切换,而不关注资源的切换,而大的进程切换,需要结合内存管理来理解。
线程切换也是进程切换的一部分,学习线程的切换也就是在学习进程切换的一个部分。
可以理解为:进程切换=线程切换 + 内存映射表切换。
1.2 线程设计的实用性
上面提出了一种轻量化进程的想法,下面分析这种想法是否实用。
以浏览器为例,
当前浏览器打开多个 Tab 页面是多进程,而加载同一个页面的不同资源是多线程,比如:js引擎线程;定时触发器线程;GUI渲染线程等等
这样就比单线程顺序加载好很多;
而且这些线程还要共享资源,比如接收数据的线程从网站上接收的数据还需要在显示文本、显示图片的线程上使用;所以没有必要进行地址分离,在同一套地址上处理更为方便;
1.3 浏览器多线程的设计理解
尝试简单实现这个浏览器多线程模型,借此理解操作系统的实现方式.
//下面代码,启动了多个线程,同时出发
void WebExplorer(){
char URL[] = "http://cms.hit.edu.cn"
char buffer[1000];
pthread_create(...,GetData, URL, buffer);
pthread_create(...,Show, buffer);
}
// 从网站上下载数据包,如文本、图片
void GetData(char *URL, char *p){...};
// 到显示器上显示内容
void Show(char* p){...};
上面代码只讲了多个线程同时出发,下面还要实现线程之间的交替执行,才叫多线程,才能提高CPU利用率:
需要在线程的执行函数中(如
GetData())增加一些内容上文提到过的在读写磁盘时释放CPU需要内核级线程的支持,本部分先讲解用户级。用户级线程完全是用户态,不会进入内核。
要想切换用户级线程,需要主动调用
yeild来释放CPU可以完全不靠操作系统实现线程切换,也就是说线程切换可以手操切换,这也是多线程编程的理论基础。具体可见
yeild源码比如,当GetData将文本下载完成后,调用
yeild主动释放CPU,切换出去,进行文本的显示工作yield 礼让,让当前线程从运行态进入就绪态,重新与其他线程争夺进入运行态

1.4 Create && Yield 函数理解
Yield 函数
释放CPU控制权,进行进程间的切换,
Create函数
创建线程,就可以实现同时触发多段代码,Create就是要制造出第一次切换时应该的样子
1.4.1 Yield && 线程切换机制
举个实际程序例子:
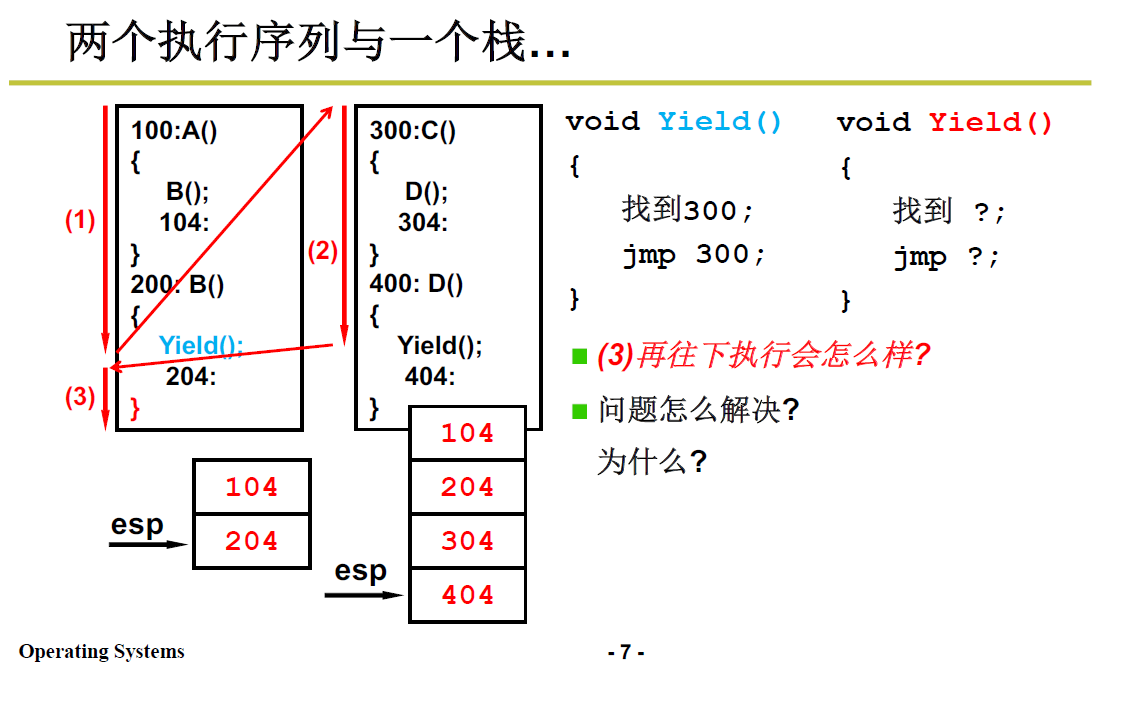
首先执行A,会跳到B执行,由于B执行完之后会返回A执行,所以要将B函数返回地址104 压栈
这是线程内部的函数调用
B执行时调用了 Yield,于是跳到Yield 去执行,同样地,把返回地址压栈。
Yield 的核心操作就是修改PC指针;在该例子中指向了线程二地址为300的C函数,调用D函数,压栈返回地址304;
执行D函数,又使用了 Yield,压栈404;而此处的Yield的跳转就是找下一个线程需要进行处的程序地址。如果从(2)跳回(3),则为204.
返回左侧204处后进行到右大括号,会成为
ret汇编指令,进行弹栈操作,弹出了404,这样,程序就出错了,因为线程由于函数调用的关系在栈中纠缠起来了。
问题出在哪呢?
- 我们想要实现的是,单个线程中就做该线程中的事情,因而204返回后应当弹出104,但是弹出了404.
- 本质问题:两个线程共用了一个栈
- 我们需要将不同线程的栈分开:如下图所示:
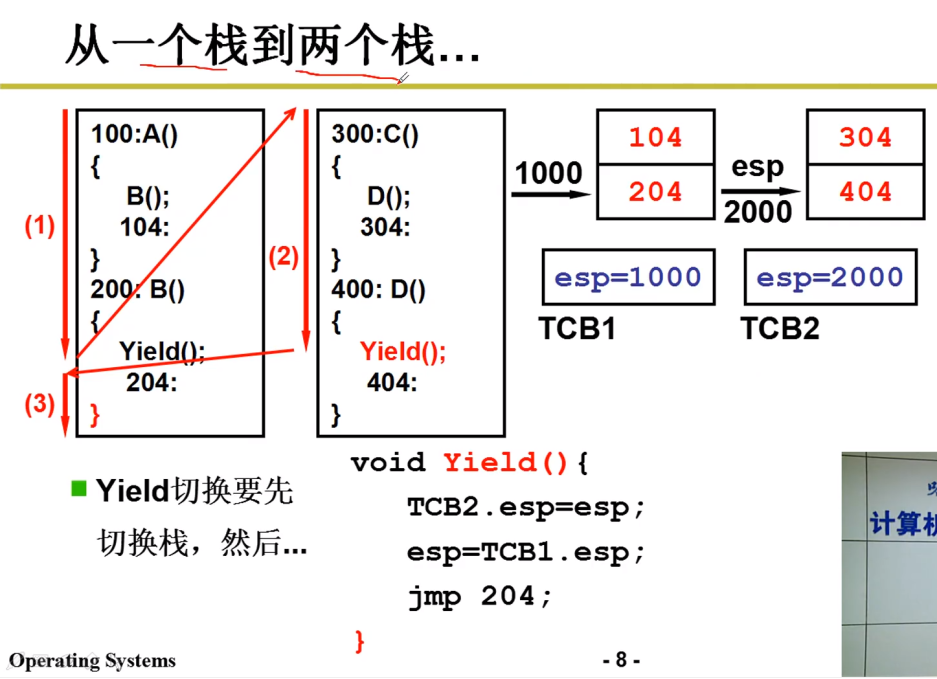
这个跟进程不能共享内存需要地址映射的原因相似,因而处理时采取的操作也类似:
每个线程拥有自己的栈,但切换线程也需要切换栈,需要结构来存储栈的情况;
在线程跳转前,用 TCB 存储栈情况,
TCB:Tread Control Block
ESP(Extended Stack Pointer):扩展栈指针寄存器
比如线程1切换到线程2时,将左侧的栈放入TCB1(具体操作是esp的当前值1000放入TCB,保存了当前指令地址),切换回来时,就从TCB1中恢复(具体操作为TCB中的esp重新赋值给esp,使其指向原先指令地址)。
线程2 转移到 线程1 同理;

栈切换完成后,(栈只存储了函数调用的返回的地址等信息),还需要PC的切换,即进行上图的
jmp 204,到达204处向下执行,到达ret指令,要弹栈返回;结果,弹栈返回204,重新回到了204处。乱套了。
虽然这样保证了函数调用只在一个栈中跳,但是还是出现了问题。
我们想一下204是怎么来的?
在调用
Yield()时,将 204 压入栈中,那就应当在Yield返回时弹,而Yield返回处实在上图的右括号处,而右括号前面的jmp指令导致其永远不会返回,也就永远弹不出204.所以把
jmp 204去掉。即 Yield 只需要切换栈,不需要进行PC的转换
函数调用的压栈机制已经做了这件事。
1.4.2 Create
前面已经提到过了,Create 即做出切换所需的样子:
三样:栈 + TCB + 存放在栈中的返回地址
执行过程:
- 申请内存分配TCB
- 申请内存来分配栈
- 栈顶压入线程的初始地址
- TCB中保存栈顶指针
- Create返回的时候,从栈里弹出的地址就是线程的初始地址
具体见下面代码:

1.5 梳理整合
上面Create 和 Yield 都明白后,多线程的情况也就基本实现了。可以把上面的浏览器代码和多线程组装在一起:
用一个主程序,开启各个线程,每个线程设计自己的函数进行自己的工作;
在浏览器的各线程中调用 Yield ,使 CPU 进行线程切换。
而通过Yield函数弹栈,实现PC的切换;
将这些函数统一编译在一起,就得到了浏览器

1.6 Yield 是用户程序
为什么这一部分是用户级线程呢?
上述举的例子是浏览器的例子,我们的实现(Yield)也没有涉及太多操作系统的内容, Yield 是一个用户程序层面的函数,完全没有进入内核。
用户级线程是内核级线程切换的子部分,而且这个子部分是可以单独使用,与操作系统的联系并不紧密;理解起来较为简单;
Yeild 中包含
next(),它是用来线程调度的,即选择下一个占用CPU的线程缺点:
以上述浏览器为例,执行GetData时,由于时从网上下载数据,需要进行网卡IO,网卡是计算机硬件,要想访问硬件必须通过操作系统;
而网卡IO会慢一些,会引发进程阻塞,进而执行其他进程
重点来了,由于内核看不到同进程的其他线程,OS 就切换到了其他进程,达不到上述线程切换的效果;
即使CPU只有当前浏览器一个进程,OS 也会空转,因为用户级线程对操作系统不可见。
而核心级线程 ThreadCreate 是系统调用,创建线程时,会进入内核;TCB也在内核中;此时各个线程对于操作系统是可见的,当 GetData 停滞,操作系统就会切换到其他线程(如Show)
内核级线程的并发性更好。
当然,对于内核级线程而言,此时 原先的 Yield 成为内核级的程序 Schedule,对于用户就不可访问了。
2. 内核级线程
Kernel Threads.
回到我们提出线程的初心,是想分而治之地实现进程切换,线程切换即进程切换中的指令流切换,而在用户级的线程无法实现进程切换的全部特征(因为进程是在内核中的,用户级线程无法深入内核)。
我们可以通过用户级线程理解线程的相关特点,而前文所说的:进程切换 = 线程切换 + 资源切换(内存管理)中的线程,实际上应当是 内核级线程。
而实际上,用户级线程也是内核级线程的一部分。
这部分就主要来看如何切换内核级线程。
2.1 为什么会有内核级线程
核心级线程的优点和必要性原因有很多,我们只挑其中一个讲解。
当前PC机多核居多,如果操作系统不支持核心级线程,那么计算机多核的设计是无效的。
下图左侧为多处理器,右侧为多核;
多处理器架构,每个处理器有自己的缓存、内存映射(MMU)
单个处理器多核架构,只有一套缓存+内存映射,有多个运算部件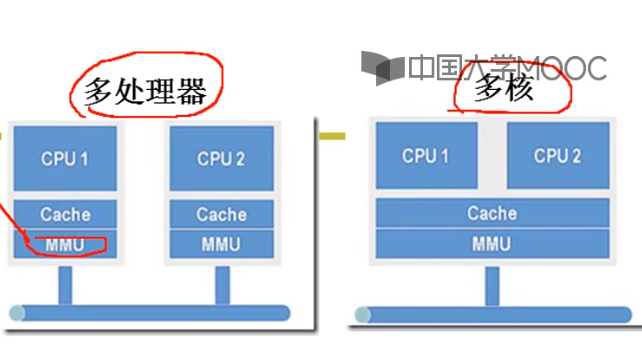
两者的区别是多处理器的每个CPU都有自己的一套缓存和MMU(内存映射,Memory Management Unit);后者多核中多个CPU使用同一套缓存和映射,多个执行序列使用同一套资源和映射,所以多核实际上就是多线程。
而如果我们要使用多核,也即我们要将多个程序分配到多核架构的多个CPU上,这时我们的操作需要面向硬件、分配到物理设备CPU上;需要穿过内核,所以这时线程需要是内核级线程。
小总结,为什么进程不能满足需求呢,以及内核级线程为什么是必要的?
如果没有线程,只有多进程,那么 MMU 内存映射在多进程切换的时候就必须跟着切换,共享的Cache、MMU 就会失去意义,变得很麻烦;
充分发挥多核架构的效果是并行。
并行和并发:
- 并行是同时触发、同时执行,相当于多个人分别同时来做多件事;
- 并发是同时出发交替执行,只有一套资源;相当于一个人干干这个又干干那个;
- 不要把多核、多处理器的架构概念和并行、并发捆绑在一起。两种概念的判定标准并不一样。
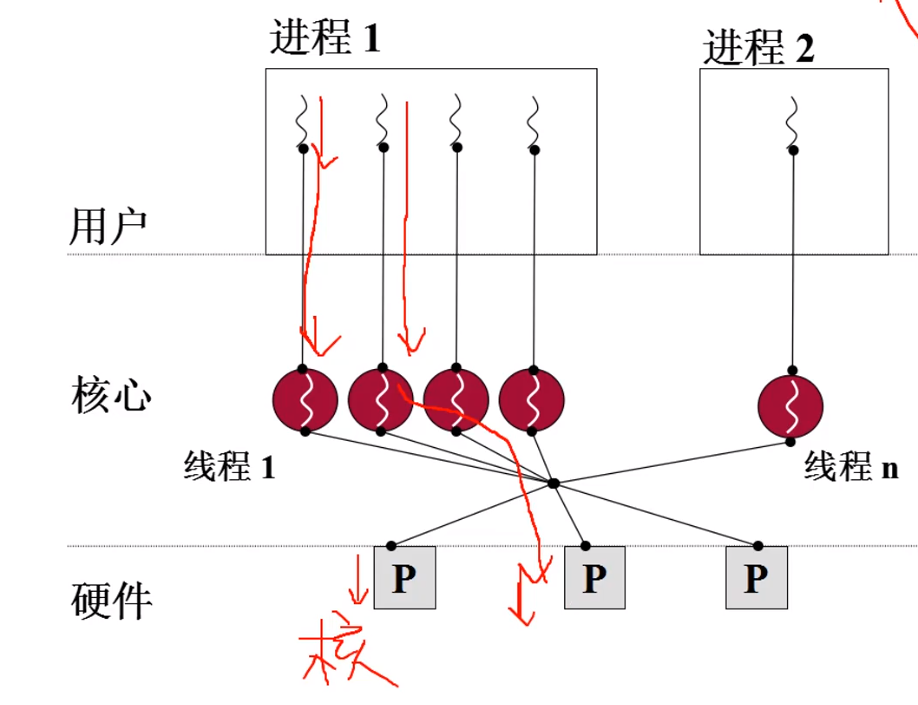
如果没有内核级线程,只有用户级线程,那么操作系统内核就无法感知这些线程,也就无法把这些线程分配到多个核上,多核就失去了意义
下图展示的就是,用户程序级别的函数只有通过内核,才能分配到底层的核中合理使用。
2.2 内核级线程实现原理
内核级线程和用户级线程的区别:
- 用户级线程两个线程之间分用两个栈;
- 内核级线程两个线程之间分用两套栈;
一套栈是指每个内核级线程有一个用户栈和一个内核栈;进行两个内核级线程的切换就需要切换的两个线程的栈,即两套栈。
关于用户栈和内核栈:
- 我们平时使用的是在用户级别的程序,所以还是需要用户栈;
- 而进行内核级线程切换需要进入内核,并且内核中相应也有函数调用,所以需要内核栈。
什么时候会出现内核栈呢?
进入内核时;具体点说,进入内核的唯一方式就是 中断;
在用户态执行时就使用用户栈,一有对应中断,操作系统通过硬件会找到内核栈并启用
如何找到内核栈下部分 3 会细说。
收到中断,内核态启用后需要压栈,需要在内核栈中先依次压入源SS、源SP、EFLAGS、源PC、源CS等内容
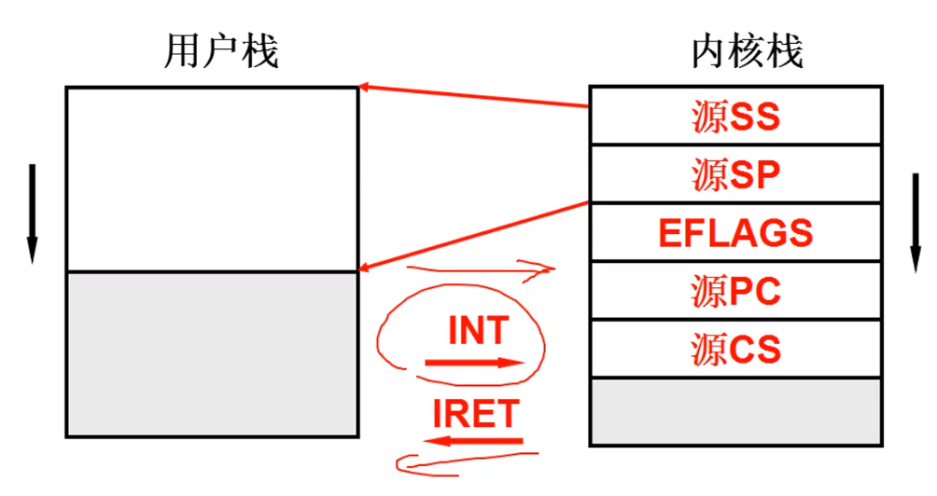
源SS和源SP是指向用户栈的指针,也就是说内核栈中存放了指向用户栈的指针;源PC和源CS是用户栈中的返回地址;(这点非常重要!)
SS:存放栈顶段地址,SP:存放栈顶偏移地址
EFLAGS 是标志寄存器,用于存放一些标志位,保存当前运行状态;比如进位,溢出,奇偶等等,详见:X86标志寄存器EFLAGS详解
从内核态返回用户态的时候(IRET中断返回指令),会从内核栈弹出这些信息,根据这些信息就可以恢复到用户栈;
2.3 内核级线程原理举例
通过一个例子来看看通过中断进入内核级线程,过程是什么样的。
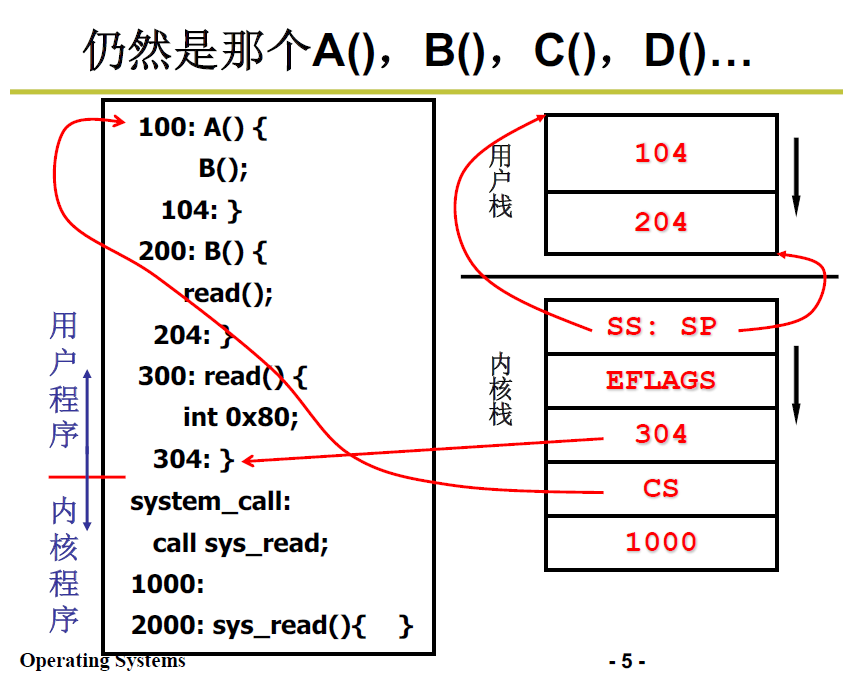
A调用B,B中不再调用yield,调用
read()库函数,展开为一段含int 0x80的指令触发中断,进入内核,启动内核栈
内核栈按次序保存了
- SS:SP,指向用户栈的指针
- EFLAGS,标志位
- 304(PC),返回用户程序的偏移地址
- CS,返回用户程序的段基址
- 1000是调用 sys_read 时压入栈中的PC值,
系统调用返回(IRET)的时候,就会根据 SS:SP 切换回用户栈,根据 CS:PC 切换到用户程序的指令;
那么如何实现内核级线程切换呢?
sys_read 启动磁盘读,将自己变成阻塞,操作系统去找下一个线程并切换
sys_read(){
//找到next;
switch_to(cur,next);
// next 和 cur 分别是下一个和当前的 TCB
}
这里 TCB 和用户级线程相似,依然是要保存当前栈指针,通过下一个内核级线程的 TCB 找到内核栈指针,然后通过 ret 切换到某个内核程序,再通过上面提过的 cs:pc 切换到用户程序。
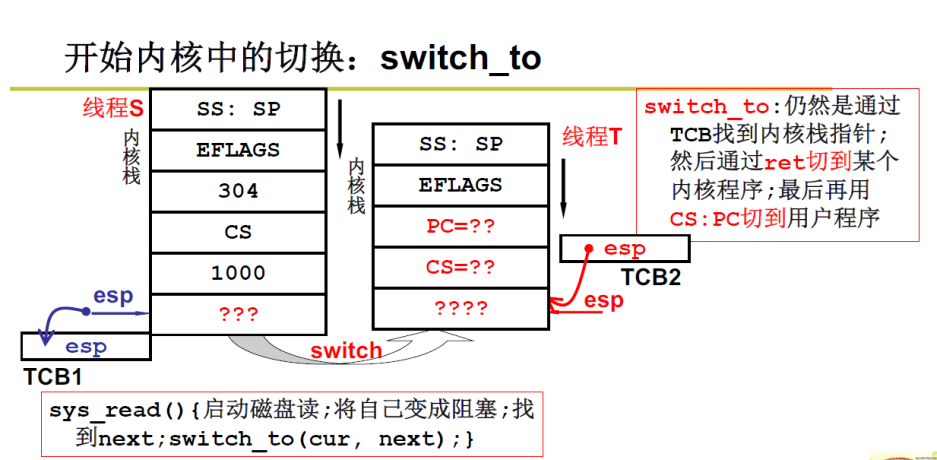
更详细地说:
用当前的 S 线程的 TCB,把当前S的栈顶地址 esp 存下来;存下来之后,进入到 next 下一个线程 T;
这时要把 T 线程的 TCB 中的栈顶地址拿出来赋给esp寄存器,这样才能把T线程的栈利用起来;
进入 T 线程后,在内核中的工作往往只是任务的一部分,我们还需要回到 T 线程的用户级去进行,所以借助 T 线程的栈中的 PC 和 CS 能够链接到 T 线程的用户态代码,接着去执行它;
而利用 ss:sp 就可以链接到线程 T 的用户栈;
如何实现 线程T 栈的切换(即拿到内核栈向用户态切换)?
- 答:包含 iret 中断返回 的代码。
- 上图问号处的具体填写,如下图:
- PC:CS 是500,是函数 C 的开始地址
- ????是 包含 iret 中断返回的 代码地址

2.4 内核线程 switch_to 的五段论
这里对 2.3 中的内容再做一次梳理,归纳整理为五个部分。
中断入口:由 线程A 的 用户态代码进入内核,才能完成内核栈与用户栈的联系
中断处理:引发线程切换,找到下一个线程的TCB
这里引发线程切换的原因有很多,比如操作系统的分时系统,当时钟中断时,也会引出 schedule。
根据 找到的TCB ,调用 switch_to;
内核栈切换
中断出口:使用 iret 内核栈返回到线程 B 的用户栈和用户态代码
下部分会再详细讲解这部分的代码。

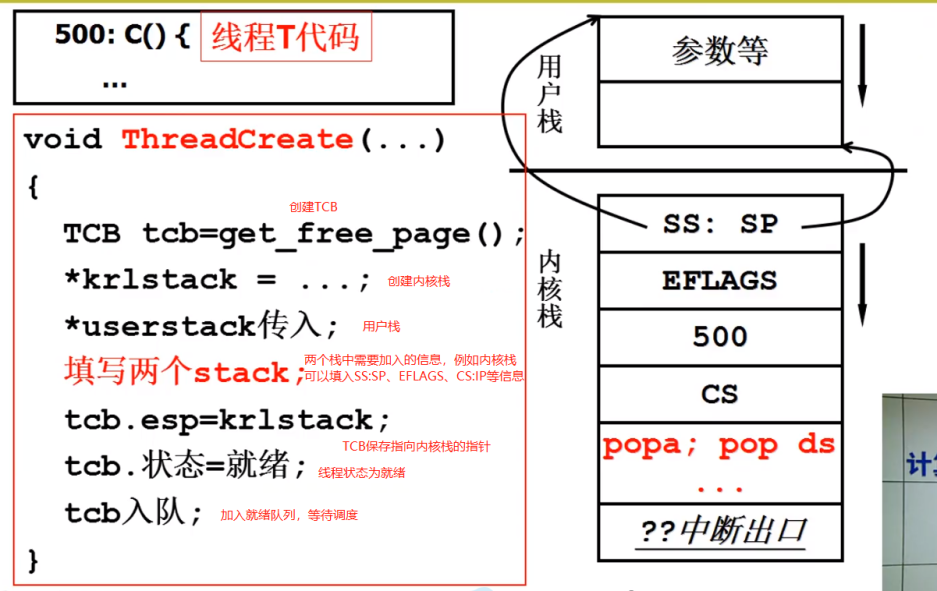
2.5 ThreadCreate 的实现原理
跟用户级线程一样,讲完线程切换的机制,就要说一说线程的初始化与创建机制(1.4.2的 Create)。
回忆上文 内核栈线程切换 所需的结构:
- 用户栈 + 内核栈 + TCB
将它们做成可以如上文切换的样子就可以;
申请一段内存作为 TCB;
申请一段内存作为 内核栈;
初始化内核栈;
申请一段用户段内存作为用户栈;
将内核栈指针指向用户栈;
设置函数地址;
此处CS一定是0F,至于为什么,在内存管理处会提及,也可以参见《Linux 源码剖析》。
TCB关联内核栈;
2.6 简单总结
用户级线程、核心级线程的对比,用户级线程和核心级线程搭配的效果最好;
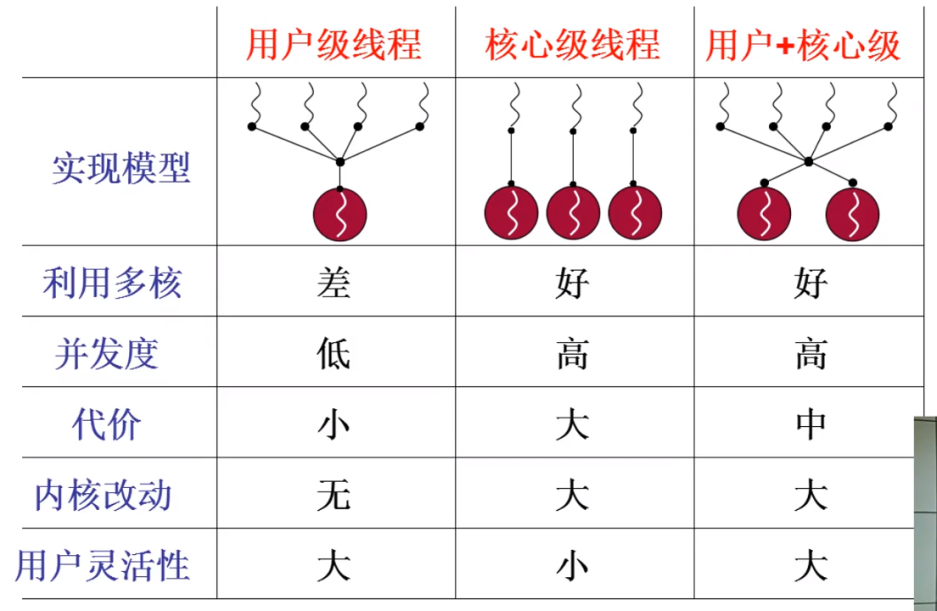
代价:用户级线程完全不需要进入内核,也就不需要额外的内核数据结构,用户想起多少个用户级线程都行,就像浏览器想开多少个标签都行,如果用内核级线程来启动浏览器标签,那么启动多了之后就卡了;
用户灵活性:用户级线程可以由用户利用 Yield 自己实现调度,自己决定什么时候切换,而核心级线程的调度与切换是在内核中提前写好的。
3. 内核级线程实现
这部分来讲内核级线程的具体代码实现。
linux0.11 不支持内核级线程,但是进程和内核级线程非常像,只是没有资源切换。大实验就是在0.11内核上实现内核级线程;
内核级线程的切换过程对用户程序来说是透明的,用户可以看见的只是用户栈、用户级线程的切换。
具体实现过程如下图所示,
切换的原理就是上面第二部分的五段论,两套栈之间的切换
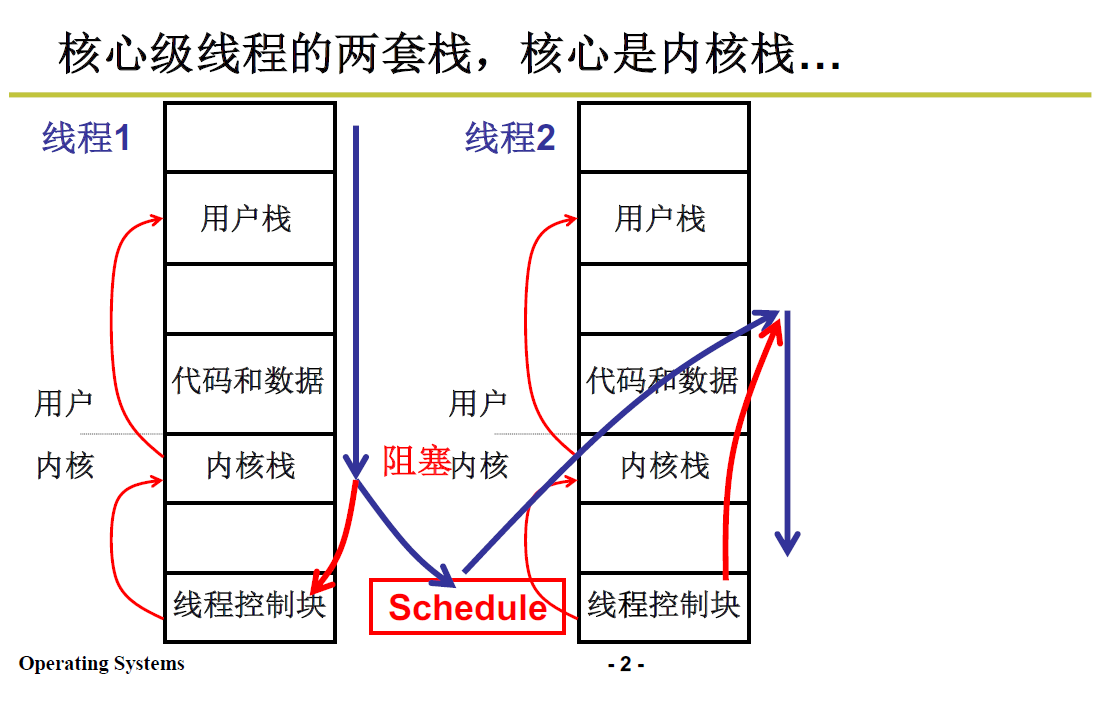
- 用户栈1通过 int 中断进入内核
- 内核栈1 -> TCB1
- TCB切换,即找到下一个 TCB2
- TCB2 -> 内核栈2
- 完成切换后通过 iret 返回用户态2
3.1 中断入口:进入内核
3.1.1 int 0x80
这一部分应当与上文2.3结合着看。
前面提到过,进入内核靠的是中断,引起中断的原因有很多:系统调用、时钟中断、键盘中断等;我们比较熟悉的是系统调用引起的中断,比如 fork() 这个系统调用。
fork,创建系统线程调用;从这里进去内核就可以看到创建线程、切换线程两个过程。
代码:
main(){
A();
B();
}
A(){
fork();
}
调用main,将返回地址exit压入用户栈
然后main函数中,首先调用A,将返回地址B压入用户栈
A 的返回地址就是 B的初始地址,所以是 ret=B;
接下来进入A函数,调用 fork 函数,fork函数展开成汇编代码:
# 首先将__NR_fork(即系统调用 fork 的编号)放入 eax 寄存器
mov %eax,__NR_fork
# 然后就是int 0x80中断指令,开始做进入内核态的准备工作
INT 0X80
mov res,%eax
现在用户栈为下图中间的模样:
一旦执行 INT 指令,开始做进入内核的准备工作;
CPU 就找到 当前内核栈;
在内核栈中压入 指向当前用户栈的 SS:SP
在内核栈中压入EFLAGS
cs和ip:压入用户程序的返回地址,即 int 中断指令的下一条;
int 0x80 对应的是系统调用,开始执行_system_call的代码
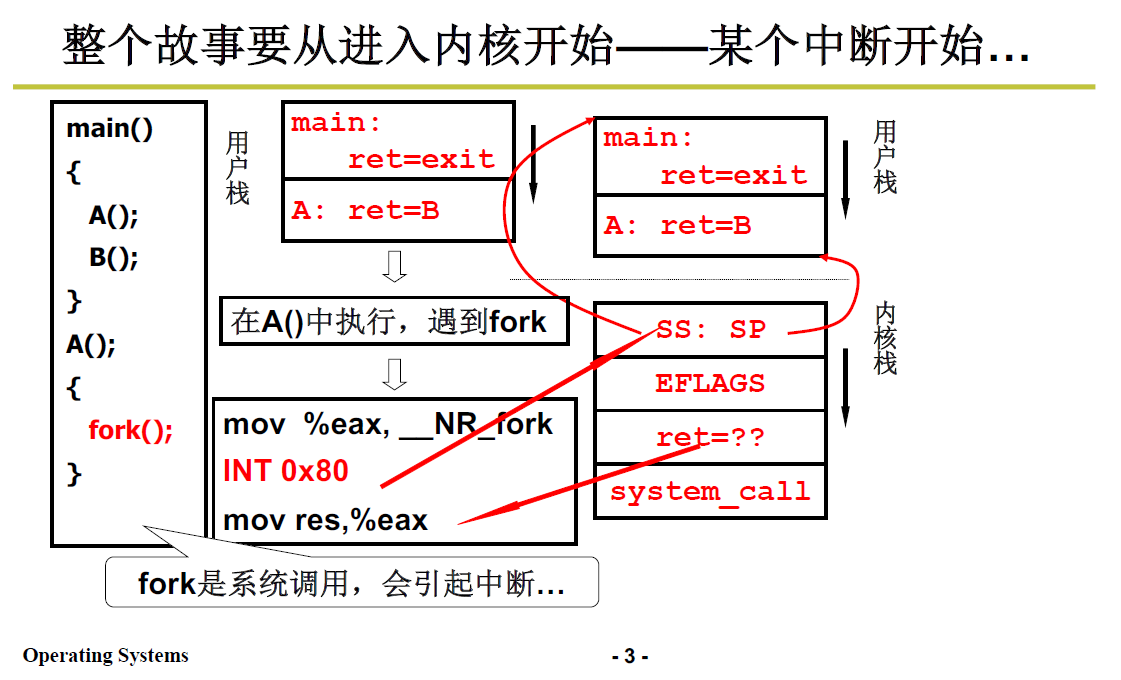
3.1.2 _system_call
前面几讲讲过,int0x80是由 system_call 函数来处理的。
这里需要复习第二讲,操作系统接口。当时以
whoami为例讲解了上层用户程序 到 sys_write 级别函数的工作机制。
下面来看看 system_call 做了什么:
3.1.1 中,我们依然处于用户态,需要中断进入内核来实现上面所说的压栈工作,这与前文提到的压栈并不矛盾,只是更深入解析其实现过程;
将当前用户态的寄存器等数据放入内核栈中(保存现场),用于将来切换回该线程后弹栈返回该线程的用户层:
void sched_init(){
set_system_gate(0x80,&system_call);
}
_system_call:
push %ds..%fs
push1 %edx...
call sys_fork
push1 %eax
#这一句在3.4中又提到了
调用 sys_call_table 表 中的 sys_fork进入内核来具体地处理创建线程这件事;
具体sys_fork的功能性代码,即创建进程的过程,这个在3.4 fork时再讲,
到这里就是五段论中的第一段:从用户栈到内核栈的关联建立;接下来需要在内核中进行中间三段。
3.2 中间三段:进行切换
这部分就是五段论中的中间三段
泛化一点讲,进行 sys_fork 级别的功能代码时,可能就会因为需要等待磁盘、键盘等设备响应而引起系统的阻塞,或者遇到系统的时钟阻塞,进而需要进行线程切换。
上文的例子中,sys_fork 的功能代码本身并不会引起阻塞(要想阻塞只会是类似于系统的时钟阻塞),所以在代码 call sys_fork 后会继续向下执行,会有如下判断程序:
mov1 _current,%eax
cmpl $0,state(%eax)
jne reschedule
cmpl $0,counter(%eax)
je reschedule
ret_from_sys_call:
注意这里是AT&T汇编,和 intel 汇编(王爽汇编)刚好反着的。
state 此前存放在PCB中:
current是当前的PCB结构体的地址。state是该结构体的一个成员,如果当前 state≠0,表示当前进程阻塞,就进行 系统重新调度(schedule),实现线程切换:reschedule;至于下面又出现了 cmpl $0,counter(%eax),并跟着一句 je;意思是判断操作系统的时间片是否用光,用光了也需要切换。
切换完后,就是五段论的第五段中断出口 iret :ret_from_sys_call。见 3.3 中断返回。
reschedule 的汇编代码:
reschedule:
push1 $ret_from_sys_call
jmp _schedule
可见放入地址后,调用 _schedule 这个C函数;当C函数返回,就会从栈中弹出,执行 上文的 ret_from_sys_call. 返回到用户层。

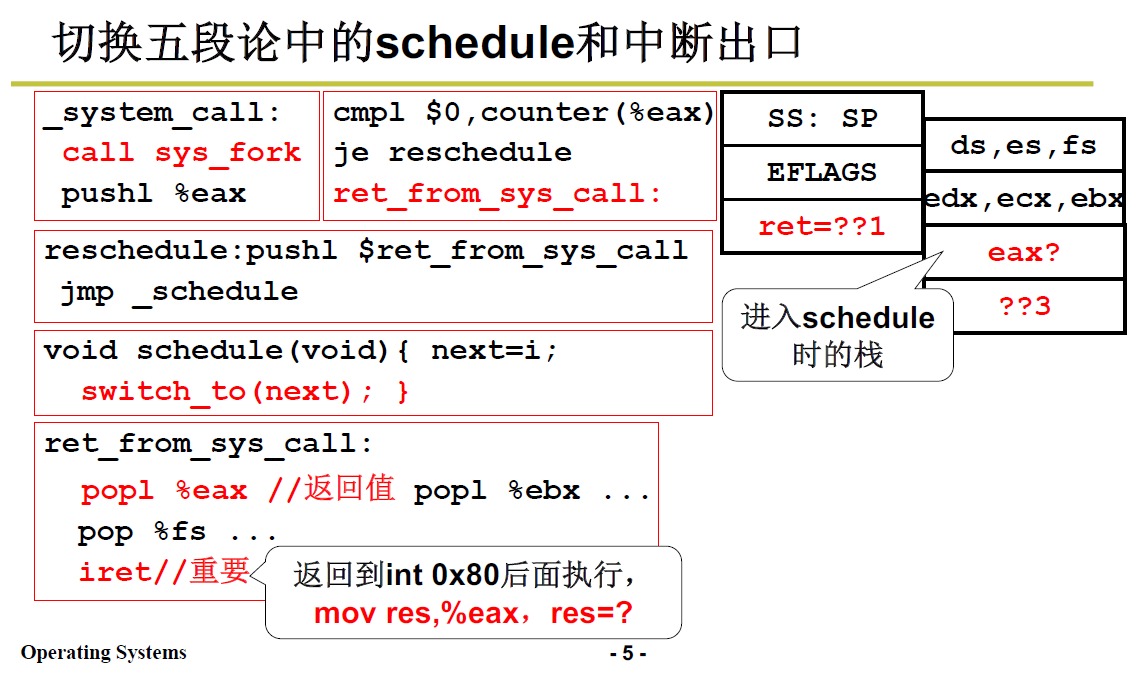
那么 schedule 引发了什么:
调度 next,依据一定的规则找到下一个线程/进程以及PCB,这个规则后面专门用一篇笔记来学习。
switch_to,linux0.11目前不是用内核栈切换的,而是通过TSS,tasks struct segment进行切换的,实验四是要将其变成基于 内核栈Kernel Thread 的切换。
前者实现原理简单,但效率较低;后者是现代操作系统普遍使用的方法。
3.2.1 TSS 切换
intel CPU架构已经实现了这种方式,代码只需要 ljmp一句即可;下面看看这种跳转方式:
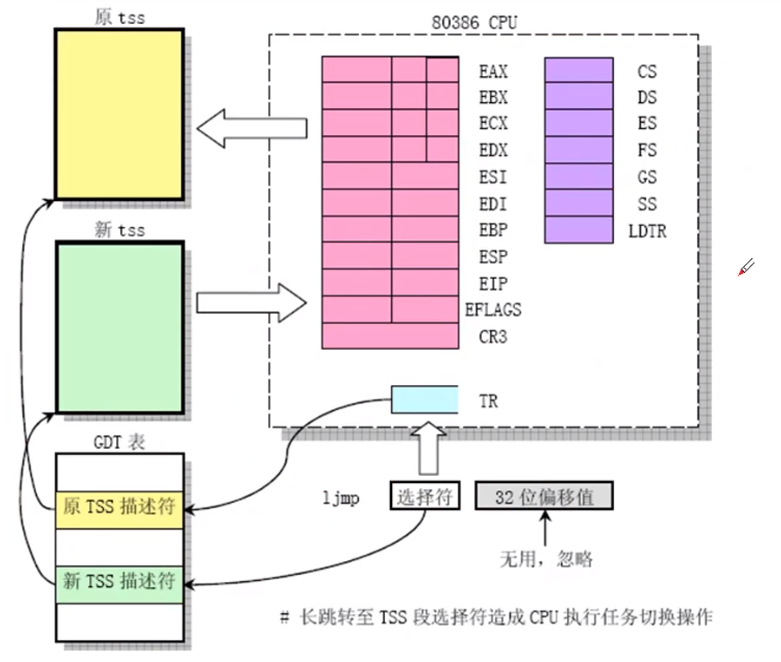
ljmp指令是长跳转指令,即TSS段的跳转切换,使用TR寄存器+GDT表,如上图所示:
TSS在内存中,104个字节保存着所有的寄存器的值
TR是TSS段的选择符(选择子),拿这个选择符TR去查GDT表,找到对应的TSS描述符,这个TSS描述符指向了TSS段
这一点跟前几讲中查找GDT表的方式一样。
TR-> GDT表中的TSS的描述符-> TSS段
上面调度算法选择下一个进程后:
原来的TSS段是通过一个TR来查找的(类似于一个指针存贮着任务信息的地址)
当进行核心线切换的时候,会将TR指向第二个线程描述符,也就是通过调度算法找到的线程n,其对应的TSS(n)
第2步中,将TR切换到新的线程段,所以将此时的线程信息填入到CPU中
这里的 TSS(n) 中的 n 就是 GDT 表的索引
参考资料:《Linux内核完全解析》第五章
具体代码如下,是一段内嵌汇编,具体语义不细说了,就是上面的过程。


分析:
- 与 内核栈的对比:TSS记录了所有的信息,而内核栈只记录必要的信息,并且利用函数调用栈的特性少记信息。
- 由于TSS保存了很多东西,所以切换很慢(保存现场和恢复现场的过程很慢),并且只用ljmp一条指令完成,也不能通过指令流水来优化,不能充分利用CPU的流水线加速
3.2.2 内核栈切换
这部分在实验四中,具体实现在实验中体会。
TSS方案:核心就是3条指令:int、switch_to中的ljmp、iret,再加上其它的代码,总共加起来20、30句;
改成栈的方案,也不会超过100句。
3.3 中断返回:返回用户态
前面3.2中3.2.1 之前的部分讲解到,ret_from_sys_call会实现返回用户层。
ret_from_sys_call:
pop1 %eax
pop %fs... ###一堆pop弹栈,弹出用户的东西
iret ###最核心代码,返回到用户层
3.4 ThreadCreate | fork
3.4.1 fork 过程 && copy_process参数表
前文3.1.2中讲到了 sys_fork 的功能代码,下面继续接着这里向更深处讲解:
fork实际上是 linux 中创建子进程的一种方式,创建子进程,所以可以通过 fork 这个系统调用看看 ThreadCreate 的过程。
fork实际上要做的是,把原来的进程一分为二,一条为调用fork的父进程,另一条是父进程调用fork函数copy出来的子进程。
形状上像一个叉子。
sys_fork的功能代码如下图:
push语句,将当前进程的参数压入父进程的内核栈
调用了 copy_process 这个C函数,将上述参数传递给子进程;
调用 copy_process 时就会倒序从栈里取出参数,按照这些参数来创建子进程;
copy_process 的参数表与栈的对应情况:
(注意这里栈被分为左右两部分:
栈里的eax对应第一个参数int nr
栈里的ebp对应第二个参数long ebp
......
栈里的ret= ??1 对应参数 long eip,也就是int 0x80的下一条指令的地址作为返回地址,
这里可见3.1.1 int0x80,也就是上面所说的B函数。
右部分的最底端就是 _sys_fork的第一条push指令放入的 gs
右部分的最顶端 ??4 就是 call _copy_process的时候的PC,对应指令 addl $20, %esp
左部分的最顶端 ??2 就是 call _sys_fork 的时候的PC,翻到上面的图可以看到,对应的指令是 pushl %eax
左部分的内容是从进入 int 0x80 中断到 call _sys_fork之前就准备好的,右部分的内容是进入 sys_fork 后才准备的参数
这样子进程就跟父进程基本一样;(只有一个地方有差别)

3.4.2 copy_proces 的细节
回忆一下前文2.5中的创建进程需要做的事情:
- 申请内存空间
- 创建TCB
- 创建内核栈和用户栈
- 填写两个栈
- 关联栈和TCB
copy_process 要做的事情是:
申请内存创建TCB
get_free_page();获得一页内存;
而不是 malloc(用户态代码),这一点后续内存管理会讲;
页:系统初始化时,mem_map 将内存打成4k为单位的单元格;这里的 PAGE_SIZE 就是 4k。
通过强制类型转换作为PCB
p是页的初始地址
初始化TSS,创建内核栈和用户栈:
注意,这里是3.2中TSS的切换方案,没有使用内核栈和用户栈,只是说相当于设置用户栈和内核栈
这里esp0表示内核栈;esp表示用户栈;
esp0指向页的顶端地址
0x10 表示内核数据段和内核堆栈段(一个段)
这样如下图所示,一页内存中底下是PCB,上面是内核栈;这样内核栈和PCB就设置好了;
--------------------下面是设置用户栈---------------------------
ss 和 esp 是上文 3.4.1 中的 copy_process 中的参数表的内容;由父进程传递给当前正要创建的子进程;
这说明:父进程和子进程用的是相同的用户栈
当然,内核栈是分开的,用户栈可以共用。
并且这句话也关联了栈和TCB
至此,除了填写两个栈没有做,其他四步都做了
而填写栈不需要,因为基于内核栈切换中,主要填写eip,而TSS切换中eip已经存入TSS,不需要填写栈,只需要用TSS初始化一下即可。
eip是int指令执行后的下一句话,本文例子中的B函数
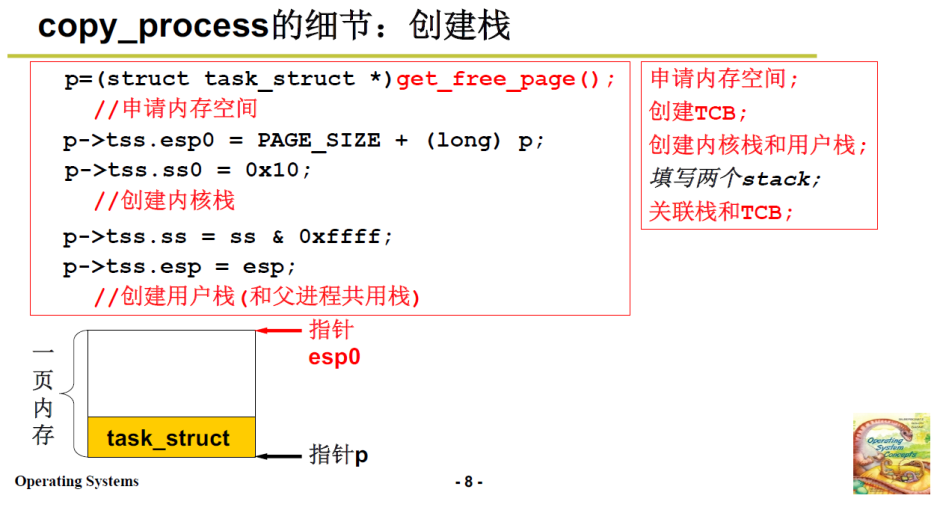
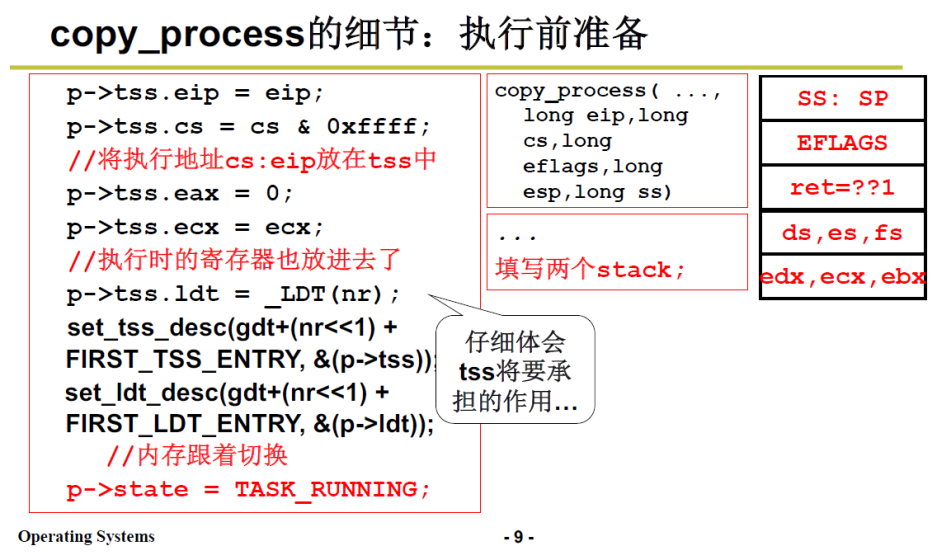
接下来初始化TSS,即使用copy_process传入的参数来初始化子进程的TSS。
p->tss.eip =父进程传入的 eip,也就是说返回用户态后,执行的第一条指令地址(int 0x80的下一条指令)和父进程保持一致
p->tss.cs 同理
p->tss.eax 置为0,eax保存的是返回值,见上文3.1.1中 的汇编代码最后一句;
看下面我对于整个过程的梳理
- 剩下的部分与内存管理 有关。
nr不是地址,而是task数组中空闲task_struct的标号!
下面梳理一下整个父子进程的过程:
在A函数中运行,遇到了fork,也就是父进程执行如下汇编代码(3.1.1~3.2的例子,以及其对应的汇编)
# 首先将__NR_fork(即系统调用 fork 的编号)放入 eax 寄存器
mov %eax,__NR_fork
# 然后就是int 0x80中断指令,开始做进入内核态的准备工作
INT 0X80
mov res,%eax
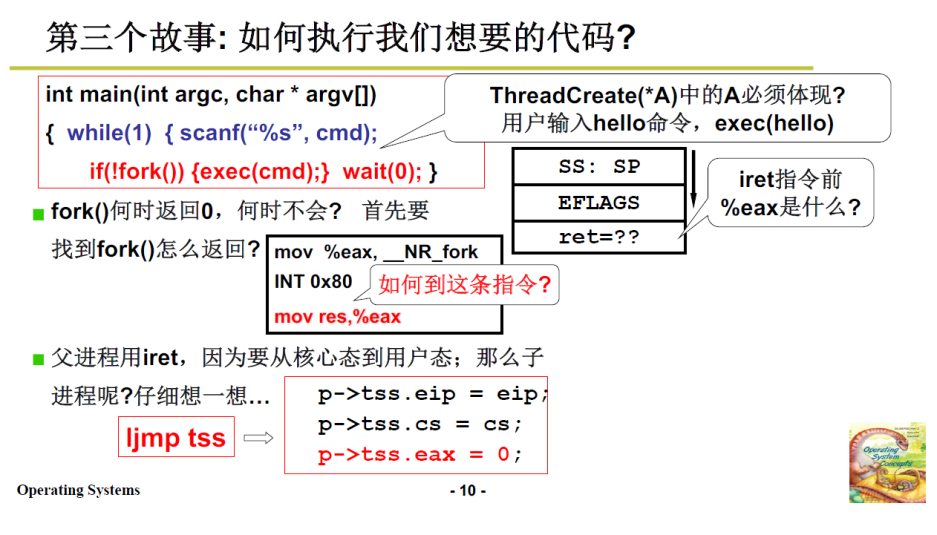
fork 执行完毕,新建了一个子进程,此时还没有执行子进程。则int指令结束,返回,接下来会执行 3.1.2 中的 _system_call
虽说fork的功能代码不会引发阻塞,但是我们假设其引发了阻塞(比如系统的时间片用完了,需要切换),于是system_call检测到阻塞,的调度下一个进程后,进行 switch_to
switch_to 切换到子进程,子进程进行3.2.1 中的TSS切换,由于前文提过的父子进程的eip相同,则子进程开始就工作上面汇编代码的最后一句
mov res,%eax,这里子进程的eax已经被赋值为0
操作系统学习笔记4中的4.1 中提到过
if(!fork()){...}的经典语句。而子进程调用fork()的返回值是0,父进程调用fork()的返回值是1,所以通常会用fork()的返回值区分是父进程还是子进程来编写代码。
达成的效果就是:
- 子进程执行 if 语句段内的语句;父进程跳过不执行;
- 形成了一个叉子(fork)状的分叉
3.5 如何执行我们的代码\实际举例
上述过程已经回扣了例子,可能还是抽象,用操作系统学习笔记4中 终端shell 的例子再说明一下。
下图可见,子进程通过 if语句结构,在父进程的壳子里(shell终端),执行自己的功能,比如 ls (子进程)在终端(父进程)里,但是执行自己显示目录的功能。
简单看看 exec 的系统调用讲解(此时就是子进程了):
exec 内部调用的是 sys_execve;
子进程在sys_execve之前执行的就是 fork 的代码(与父进程相同),fork 的代码准备好了子进程的内核栈,大部分信息来自父进程
随后子进程执行 _sys_execve,找到了命令功能性代码(实际上编译完成后是可执行文件),从可执行文件中取出必要的信息
例如可执行文件的入口地址,即第一条指令的地址
用这些信息修改了内核栈中用于 IRET 的参数,即返回地址,使得从sys_execve返回(IRET)后,就转而去执行输入的命令,之后执行的指令和父进程就完全没关系了
sys_execve(最后这里没太懂原理,涉及了编译)
下图2中就有 _sys_execve 的汇编代码
首先计算得到 栈中EIP的地址
0x1C是28,esp+28就是 ret=??1 的位置,也就是返回用户程序的地址
压入栈中,作为 do_execve的参数,然后 call _do_execve
do_execve的代码如下2图
将栈中EIP修改为ex.a_entry,即可执行程序的入口地址
同时修改了即eip[3]即 SP为当前申请的页内存
ex.a_entry 是可执行程序入口地址,在编译时产生可执行文件时写入。

4. 总结
- 理解 switch_to 对应的栈切换,将自己变成计算机,能够执行整个过程
- ThreadCreate的目的就是初始化一套栈。
操作系统学习笔记5 | 用户级线程 && 内核级线程的更多相关文章
- 操作系统学习笔记----进程/线程模型----Coursera课程笔记
操作系统学习笔记----进程/线程模型----Coursera课程笔记 进程/线程模型 0. 概述 0.1 进程模型 多道程序设计 进程的概念.进程控制块 进程状态及转换.进程队列 进程控制----进 ...
- Django:学习笔记(9)——用户身份认证
Django:学习笔记(9)——用户身份认证 User
- 并发编程学习笔记(3)----synchronized关键字以及单例模式与线程安全问题
再说synchronized关键字之前,我们首先先小小的了解一个概念-内置锁. 什么是内置锁? 在java中,每个java对象都可以用作synchronized关键字的锁,这些锁就被称为内置锁,每个对 ...
- 深挖计算机基础:趣谈Linux操作系统学习笔记
参考极客时间专栏<趣谈Linux操作系统>学习笔记 核心原理篇:内存管理 趣谈Linux操作系统学习笔记:第二十讲 趣谈Linux操作系统学习笔记:第二十一讲 趣谈Linux操作系统学习笔 ...
- ucore操作系统学习笔记(二) ucore lab2物理内存管理分析
一.lab2物理内存管理介绍 操作系统的一个主要职责是管理硬件资源,并向应用程序提供具有良好抽象的接口来使用这些资源. 而内存作为重要的计算机硬件资源,也必然需要被操作系统统一的管理.最初没有操作系统 ...
- 操作系统学习笔记(五)--CPU调度
由于第四章线程的介绍没有上传视频,故之后看书来补. 最近开始学习操作系统原理这门课程,特将学习笔记整理成技术博客的形式发表,希望能给大家的操作系统学习带来帮助.同时盼望大家能对文章评论,大家一起多多交 ...
- ucore操作系统学习笔记(一) ucore lab1系统启动流程分析
一.ucore操作系统介绍 操作系统作为一个基础系统软件,对下控制硬件(cpu.内存.磁盘网卡等外设),屏蔽了底层复杂多样的硬件差异:对上则提供封装良好的应用程序接口,简化应用程序开发者的使用难度.站 ...
- 操作系统学习笔记10 | I/O、显示器与键盘
从这一部分开始介绍操作系统的设备驱动,操作系统通过文件系统的抽象驱动设备让用户能够使用显示器.键盘等交互工具.并讲解printf和scanf是如何实现敲下键盘将字符显示到屏幕上的. 参考资料: 课程: ...
- ucos实时操作系统学习笔记——任务间通信(消息)
ucos另一种任务间通信的机制是消息(mbox),个人感觉是它是queue中只有一个信息的特殊情况,从代码中可以很清楚的看到,因为之前有关于queue的学习笔记,所以一并讲一下mbox.为什么有了qu ...
随机推荐
- c++ 关于二分的STL 详解
一.解释 以前遇到二分的题目都是手动实现二分,不得不说错误比较多,关于返回值,关于区间的左闭右开等很容易出错,最近做题发现直接使用STL中的二分函数方便快捷还不会出错,不过对于没有接触过的同学,二分函 ...
- DirectX11 With Windows SDK--19(Dev) 编译Assimp并加载模型、新的Effects框架
前言 注意:这一章进行了重写,对应教程Dev分支第19章的项目,在更新完后面的项目后会替换掉原来第19章的教程 在前面的章节中我们一直使用的是由代码生成的几何模型,但现在我们希望能够导入模型设计师生成 ...
- 讲一个linux服务启动报错问题排查
例子 首先我们在/usr/lib/systemd/system目录下创建一个服务文件,写下服务启动任务配置.下面我以prometheus的node_exporter为例 vim /usr/lib/sy ...
- GitHub-SSH密钥获取
SSH密钥 需要先安装git的客户端,下载: http://git-scm.com/download/ 使用下列步骤完成密钥的添加. 检查系统是否存在密钥 运行 Git Bash, 在弹出的终端中输入 ...
- 【python基础】第01回 计算机基础1
本章内容概要 1.文件路径2.typora主要功能介绍3.typora语法学习(markdown)4.计算机的本质5.计算机五大组成部分6.网络博文编写教程 本章内容详解 1.文件路径 --路径:可以 ...
- 为什么不建议使用自定义Object作为HashMap的key?
此前部门内的一个线上系统上线后内存一路飙高.一段时间后直接占满.协助开发人员去分析定位,发现内存中某个Object的量远远超出了预期的范围,很明显出现内存泄漏了. 结合代码分析发现,泄漏的这个对象,主 ...
- 520到了,作为一个python程序员,必须整点肤白貌美的爬虫代码给你们~
马上520就快到啦~ 整点好看的给你们看下~ 直接开搞~ 代码流程 模拟浏览器向服务器发送一个http请求,网站接收到请求后返回数据.在写爬虫代码的时候一定先要去模拟浏览器访问,因为现在的网站当接收到 ...
- NC235250 牛可乐的翻转游戏
NC235250 牛可乐的翻转游戏 题目 题目描述 牛可乐发明了一种新型的翻转游戏! 在一个有 \(n\) 行 \(m\) 列的棋盘上,每个格子摆放有一枚棋子,每一枚棋子的颜色要么是黑色,要么是白色. ...
- 【python笔记】Qt+云函数 实现简单的登录框制作
[python笔记]Qt+云函数 实现简单的登录框制作 备注:前置条件:QtDesigner.pycharm.PyQt5.配置好的云函数(百度的叫函数计算CFC,用来充当一个简陋的服务器,主要是免费) ...
- 4-12 Spring Security + JWT
Spring Security + JWT 此前,在处理登录的业务中,当视为登录成功时,返回的字符串并不是JWT数据,则应该将此数据改为必要的JWT数据. @Service public class ...