预处理指令详解(C语言
一、预处理符号
预处理符号是C语言内置的符号,是可以直接使用的。

其中,若遵顼ANSI C,则__STDC__ 为1,否则未定义。
二、#define
1)定义标识符
define可以用来定义标识符,其语法为:#define name stuff,经过预处理后,stuff会被直接替换为name。
若stuff的内若过长,可在句末加上\续行符号,像这样:
#include<stdio.h>
#define Piccaso "Pablo,Diego,José\
Francisco,de,Paula,Juan,Nepomuceno\
,María,de,los,Remedios,Cipriano,de\
,la,Santísima,Trinidad,Ruiz,y,Picasso"
int main()
{
printf("%s", Piccaso);
return 0;
}

示例1: 数值替换

int main()
{
int a = 100;
return 0;
}
示例2: 循环替换

#include<stdio.h>
int main()
{
while(1)
{
printf("A");
}
return 0;
}
运行代码,将会在屏幕上死循环地打印A。
示例3: 分支替换

int main()
{
int input = 0;
switch (input)
{
case 1:
break;
case 2:
break;
case 3:
}
return 0;
}
2)宏定义
define允许有参数的文本替换,这种操作通常称为宏,其语法为:#define name(list) stuff,其中,list是由逗号隔开的符号表,符号有可能出现在stuff中。
示例1:

int main()
{
printf("%d", 5+5);
return 0;
}
示例2:

int main()
{
printf("%d", 10*double(5+1));
return 0;
}
因为#define的功能只是替换,若要利用宏定义实现快捷的函数操作,最好的方法是在宏定义时多加括号,以便于达到整体求值的效果,像这样:#define double(x) (x)+(x)。
注意: 由于宏是直接替换,因此传参时严禁使用自增,自减,传参时使用,替换后依然会再次执行,会导致不可预测的后果。
3)字符串转换符#
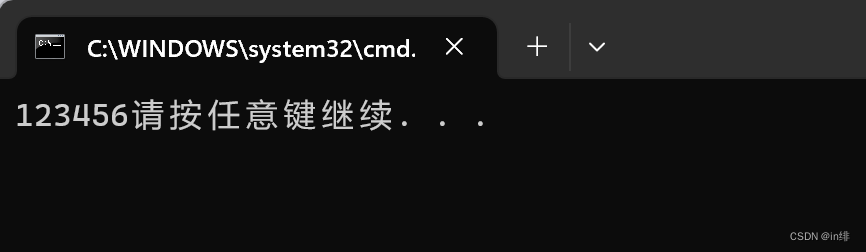
字符串有自动连接的特点,例如运行以下这段代码:
#include<stdio.h>
int main()
{
printf("123" "456");
return 0;
}
效果图:
字符串转换符#就是利用这个特性,它可以将宏定义中传入的参数,替换为字符串格式。
#include<stdio.h>
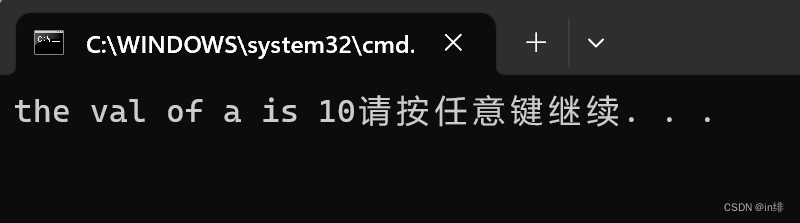
#define sum(x) printf("the val of "#x" is %d",x)
int main()
{
int a = 10;
sum(a);
return 0;
}
在上述代码中,#号将a直接转化为字符串,随后三个字符串拼接在一起。
效果图:
利用该方法可以只传参一次实现值和名同时打印。
4)片段链接符##
在宏定义时,片段连接符##可以实现将两个符号连接在一起,使其成为一个符号,前提是这个合成的符号必须已经被定义。
#include<stdio.h>
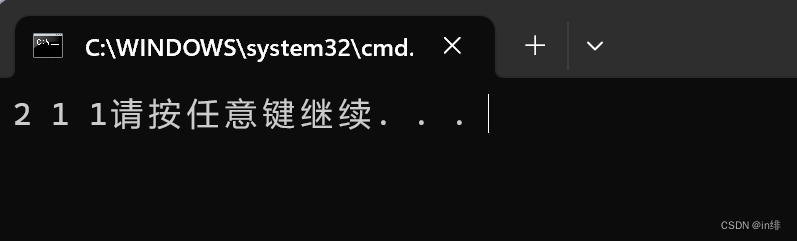
#define double(x) sum##x*=2
int main()
{
int sum1 = 1;
int sum2 = 1;
int sum3 = 1;
double(1);
printf("%d %d %d", sum1, sum2, sum3);
return 0;
}
在上述代码中,##会把sum和参数x连接在一起,当我们传入1经过预处理后,等效于:sum1*=2 。
效果图:
5)宏定义VS函数
宏定义的优势:
- 宏定义的执行速度远远超过函数,当执行简单的计算时,更适合使用宏定义。
- 宏定义传参时没有类型检测,可以将任意的数据传入。
- 宏定义是直接替换,可以传入各种各样的符号,实现许许多多函数做不到的功能。(可以传入类型、传入函数、传入语句等等)
宏定义的劣势:
- 宏定义不能调试、不能递归,因此宏定义只适合做简单的计算。
- 宏定义是直接替换,因此相邻操作符的优先级很有可能产生不期望的顺序,因此要尽可能带括号。
- 宏定义传参没有类型检测,因此不够严谨。
6)命名公约
以下几条公约,必须遵守
- 宏定义的名必须全部大写。
- 函数名不可以全部大写。
三、#undef
#undef宏定义删除,可以在函数内部使用!

被删除后的标识就不能再使用了。
四、命令行编译
指在VScode或Linux等用命令行执行编译的环境下,可以在编译时对变量进行赋值。
五、条件编译
在写程序时,有些代码是为了查看某个部分是否正确而写的的调试代码。
删除很可惜,但又不想让其编译,此时就可以使用选择性编译。
但实质上使用if语句或直接注释会更加方便,但在C语言内置的头文件中,为了节约时间经常使用条件编译。
1)常量表达式判断
#if 常量表达式
//...
#endif
常量表达式为真,则中间的语句编译;
常量表达式为假,则中间的语句不编译。
此外,也可以写成多分支的表达式条件编译。
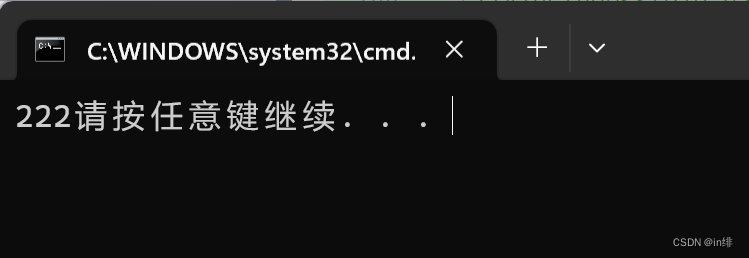
int main()
{
#if 0
printf("111");
#elif 1
printf("222");
#else 0
printf("333");
#endif
return 0;
}
效果图:
2)是否定义判断
判断某个符号是否被定义,只要被定义,就编译中间的语句,无论其被定义为什么。
#include<stdio.h>
#define MAX
int main()
{
#if defined(MAX)//或#ifdef MAX
printf("111");
#endif
return 0;
}
或判断某个符号是否没定义,没定义则编译。
#include<stdio.h>
#define MAX
int main()
{
#if !defined(MAX)//或#ifndef MAX
printf("111");
#endif
return 0;
}
3)嵌套判断
条件编译是可以互相嵌套的。
#include<stdio.h>
#define DEBUG
int main()
{
#ifdef DEBUG
#if 1
printf("111");
#elif 0
printf("222");
#endif
#endif
return 0;
}
如上述代码是在是否定义判断中嵌套常量表达式判断。
效果图:
六、头文件的包含
1)双引号与尖括号
对于#include来说,后面的文件有两种引用方法:
- 双引号,优先在本地文件寻找,找不到再去标准库中寻找,都没有则报错。
- 尖括号,直接在标准库中寻找,找不到则报错。
所有的头文件在包含时都可以使用双引号,但为了速度和区别位置,建议自己写的头文件用双引号,标准库中的用尖括号。
2)头文件的嵌套包含
可以将许许多多的头文件都包含在一个自己创建的头文件中,最后只需要在其他的源文件中包含该自己创建的头文件即可,像这样:

3)头文件重复包含解决方法
在写多人合作的大型项目时,每个程序员可能都要包含一次公用的头文件,当他们写的代码汇总时,这个头文件可能会被包含多次。
因此,我们使用条件编译来解决这个问题。
#if !defined(TIME)
#define TIME
//...
//... //在这里实现各种函数
//...
#endif
假设上述代码为head.h,当我们第一次包含head.h时,由于TIME没有被定义,因此会定义一个TIME,同时编译里面的函数。
当我们第二次包含head.h时,因为TIME被定义过了,即使head.h里面的内容被拷贝到源文件中,也不会进行编译,从而加快了速度。
注意: 在头文件开头加入#pragma once即可一键实现上述效果,不必冗杂的代码,但仅限于自己写的头文件,标准库的头文件已经帮你加完了。
感谢您的阅读与耐心~
预处理指令详解(C语言的更多相关文章
- #pragma 预处理指令详解
源地址:http://blog.csdn.net/jx_kingwei/article/details/367312 #pragma 预处理指令详解 在所有的预处理指令中, ...
- pragma comment的使用 pragma预处理指令详解
pragma comment的使用 pragma预处理指令详解 #pragma comment( comment-type [,"commentstring"] ) 该宏放置一 ...
- C#中的预处理指令详解
这篇文章主要介绍了C#中的预处理指令详解,本文讲解了#define 和 #undef.#if.#elif.#else和#endif.#warning和#error.#region和#endregion ...
- C++中的#pragma 预处理指令详解
源地址:http://blog.csdn.net/roger_77/article/details/660311 在所有的预处理指令中,#pragma 指令可能是最复杂的了,它的作用是设定编译器的状态 ...
- 常用C/C++预处理指令详解
预处理是在编译之前的处理,而编译工作的任务之一就是语法检查,预处理不做语法检查.预处理命令以符号“#”开头. 常用的预处理指令包括: 宏定义:#define 文件包含:#include 条件编译:#i ...
- pragma指令详解(转载)
#pragma comment( comment-type [,"commentstring"] ) 该宏放置一个注释到对象文件或者可执行文件.comment-type是一个预定义 ...
- GCC 指令详解及动态库、静态库的使用
GCC 指令详解及动态库.静态库的使用 一.GCC 1.1 GCC 介绍 GCC 是 Linux 下的编译工具集,是「GNU Compiler Collection」的缩写,包含 gcc.g++ 等编 ...
- [转]JVM指令详解(上)
作者:禅楼望月(http://www.cnblogs.com/yaoyinglong) 本文主要记录一些JVM指令,便于记忆与查阅. 一.未归类系列A 此系列暂未归类. 指令码 助记符 ...
- C#中的预处理器指令详解
这篇文章主要介绍了C#中的预处理器指令详解,本文讲解了#define 和 #undef.#if.#elif.#else和#endif.#warning和#error.#region和#endregio ...
- rsync指令详解
rsync指令详解(更详细的看官方文档http://rsync.samba.org/ftp/rsync/rsync.html) [root@Centos epel]# rsync --help rsy ...
随机推荐
- Hive详解(02) - Hive 3.1.2安装
Hive详解(02) - Hive 3.1.2安装 安装准备 Hive下载地址 Hive官网地址:http://hive.apache.org/ 官方文档查看地址:https://cwiki.apac ...
- CF构造题1600-1800(2)
H. Hot Black Hot White(COMPFEST 14 - Preliminary Online Mirror (Unrated, ICPC Rules, Teams Preferred ...
- 序列化框架-Kyro简述
网上有很多资料说 Kryo 只能在 Java 上使用,这点是不对的,事实上除 Java 外,Scala 和 Kotlin 这些基于 JVM 的语言同样可以使用 Kryo 实现序列化. 1.使用方法 ( ...
- Linux简易入门
安装Linux系统 VMware安装 首先安装VMware VMware下载地址 在镜像网站下载镜像,直接进行安装 虚拟机安装 镜像下载地址 这里使用\(16.04\)版本 点击创建新的虚拟机 根据向 ...
- Map集合概述-Map常用子类
Map集合概述 现实生活中,我们常会看到这样的一种集合︰IP地址与主机名,身份证号与个人,系统用户名与系统用户对象等,这种--对应的关系,就叫做映射.Java提供了专门的集合类用来存放这种对象关系的对 ...
- java跨域问题解决
问题描述:在使用前后端分离的情况下,前端访问后端时会出现跨域问题 解决方式: 1.设置跨域 1).单个控制器方法CORS注解 在单个方法中加入注解@CrossOrigin. 2).整个控制器启用COR ...
- nginx解决vue跨域问题
location /epayapi { proxy_pass http://127.0.0.1:7011; proxy_set_header Host $host; proxy_set_header ...
- 力扣每日一题2023.1.19---2299. 强密码检验器 II
如果一个密码满足以下所有条件,我们称它是一个 强 密码: 它有至少 8 个字符. 至少包含 一个小写英文 字母. 至少包含 一个大写英文 字母. 至少包含 一个数字 . ...
- JMH测试工具
参考:https://blog.csdn.net/agonie201218/article/details/122333354 1 简介 JMH即Java Microbenchmark Harness ...
- fiddler的简单使用
一.fiddler接口测试介绍 二.fiddler过滤器的使用 fiddler可以指定只抓哪些包,通过filters实现 如果需要抓取多个网站,各个需要抓取的网站之间用分号隔开 三.fiddler抓取 ...