elasticsearch聚合之bucket terms聚合
1. 背景
此处简单记录一下bucket聚合下的terms聚合。记录一下terms聚合的各种用法,以及各种注意事项,防止以后忘记。
2. 前置条件
2.1 创建索引
PUT /index_person
{
"settings": {
"number_of_shards": 1
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "keyword"
},
"sex": {
"type": "keyword"
},
"age": {
"type": "integer"
},
"province": {
"type": "keyword"
},
"address": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
2.2 准备数据
PUT /_bulk
{"create":{"_index":"index_person","_id":1}}
{"id":1,"name":"张三","sex":"男","age":20,"province":"湖北","address":"湖北省黄冈市罗田县匡河镇"}
{"create":{"_index":"index_person","_id":2}}
{"id":2,"name":"李四","sex":"男","age":19,"province":"江苏","address":"江苏省南京市"}
{"create":{"_index":"index_person","_id":3}}
{"id":3,"name":"王武","sex":"女","age":25,"province":"湖北","address":"湖北省武汉市江汉区"}
{"create":{"_index":"index_person","_id":4}}
{"id":4,"name":"赵六","sex":"女","age":30,"province":"北京","address":"北京市东城区"}
{"create":{"_index":"index_person","_id":5}}
{"id":5,"name":"钱七","sex":"女","age":16,"province":"北京","address":"北京市西城区"}
{"create":{"_index":"index_person","_id":6}}
{"id":6,"name":"王八","sex":"女","age":45,"province":"北京","address":"北京市朝阳区"}
3. 各种聚合
3.1 统计人数最多的2个省
3.1.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_sex": {
"terms": {
"field": "province",
"size": 2
}
}
}
}
3.1.2 运行结果
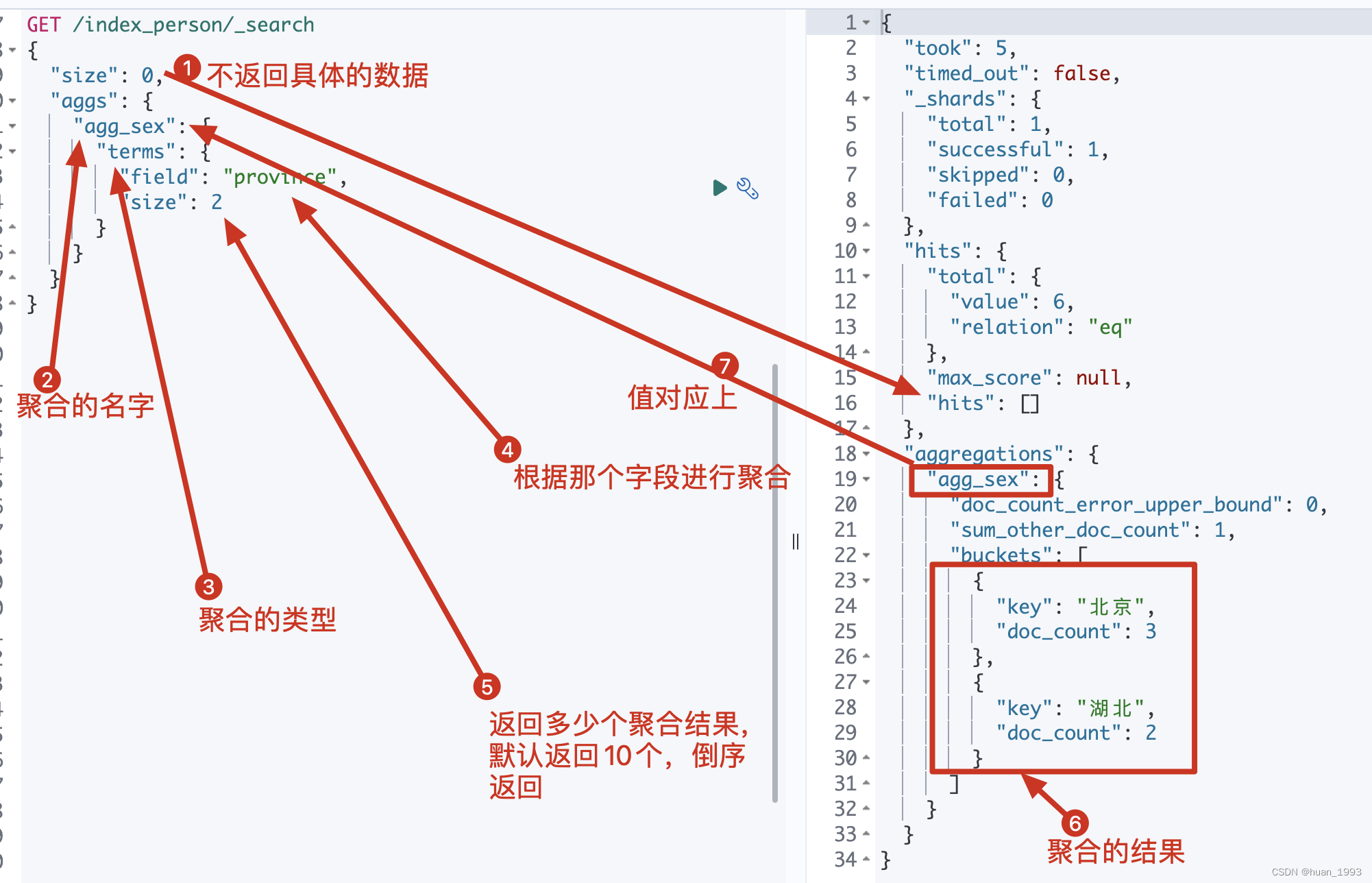
3.2 统计人数最少的2个省
3.2.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_sex": {
"terms": {
"field": "province",
"size": 2,
"order": {
"_count": "asc"
}
}
}
}
}
注意: 不推荐使用 _count:asc来统计,会导致统计结果不准,看下方的总结章节。
3.2.2 运行结果
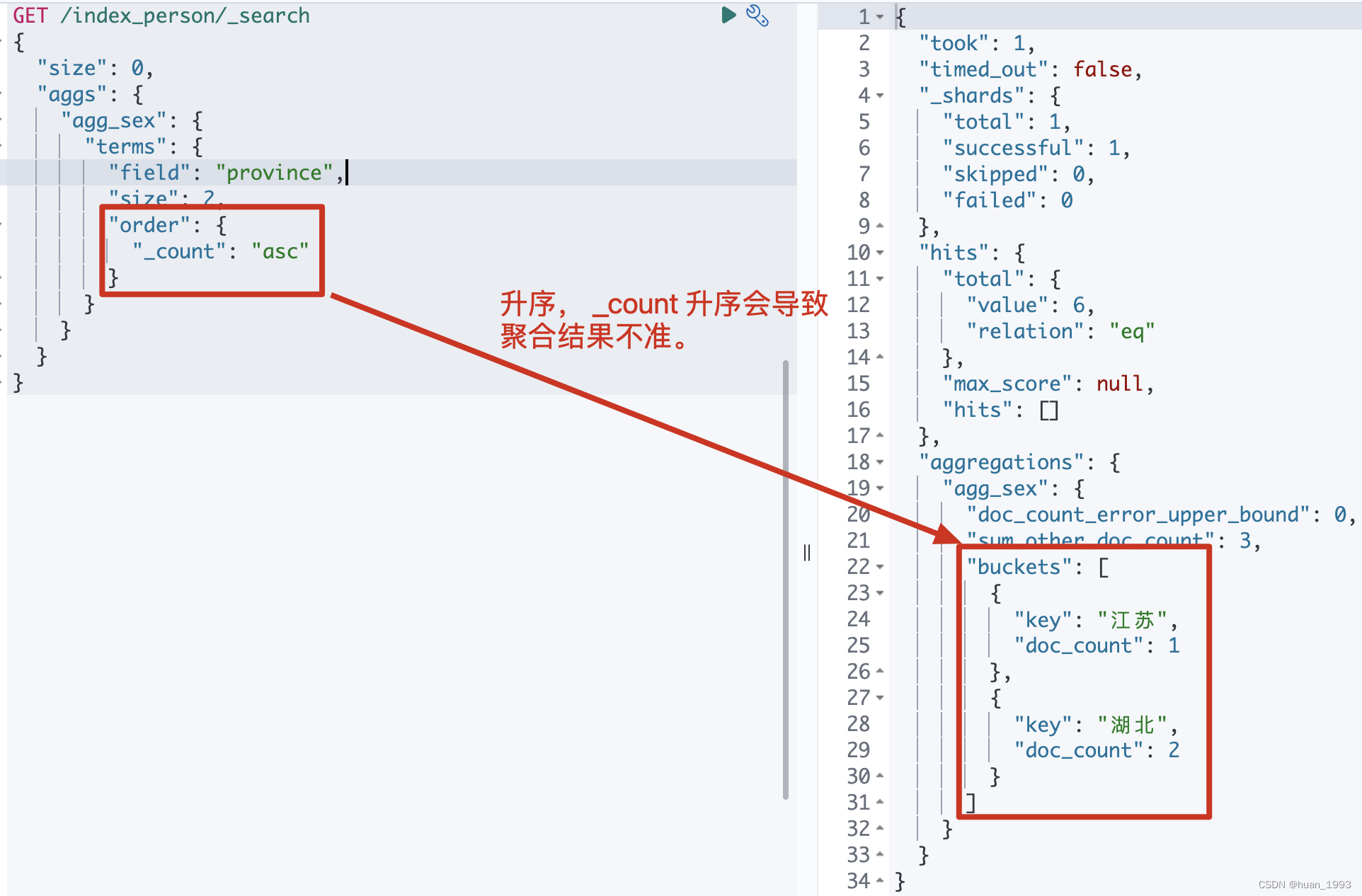
3.3 根据字段值排序-根据年龄聚合,返回年龄最小的2个聚合
3.3.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_sex": {
"terms": {
"field": "age",
"size": 2,
"order": {
"_key": "asc"
}
}
}
}
}
注意: 这种根据字段值来排序,聚合的结果是正确的。
3.3.2 运行结果
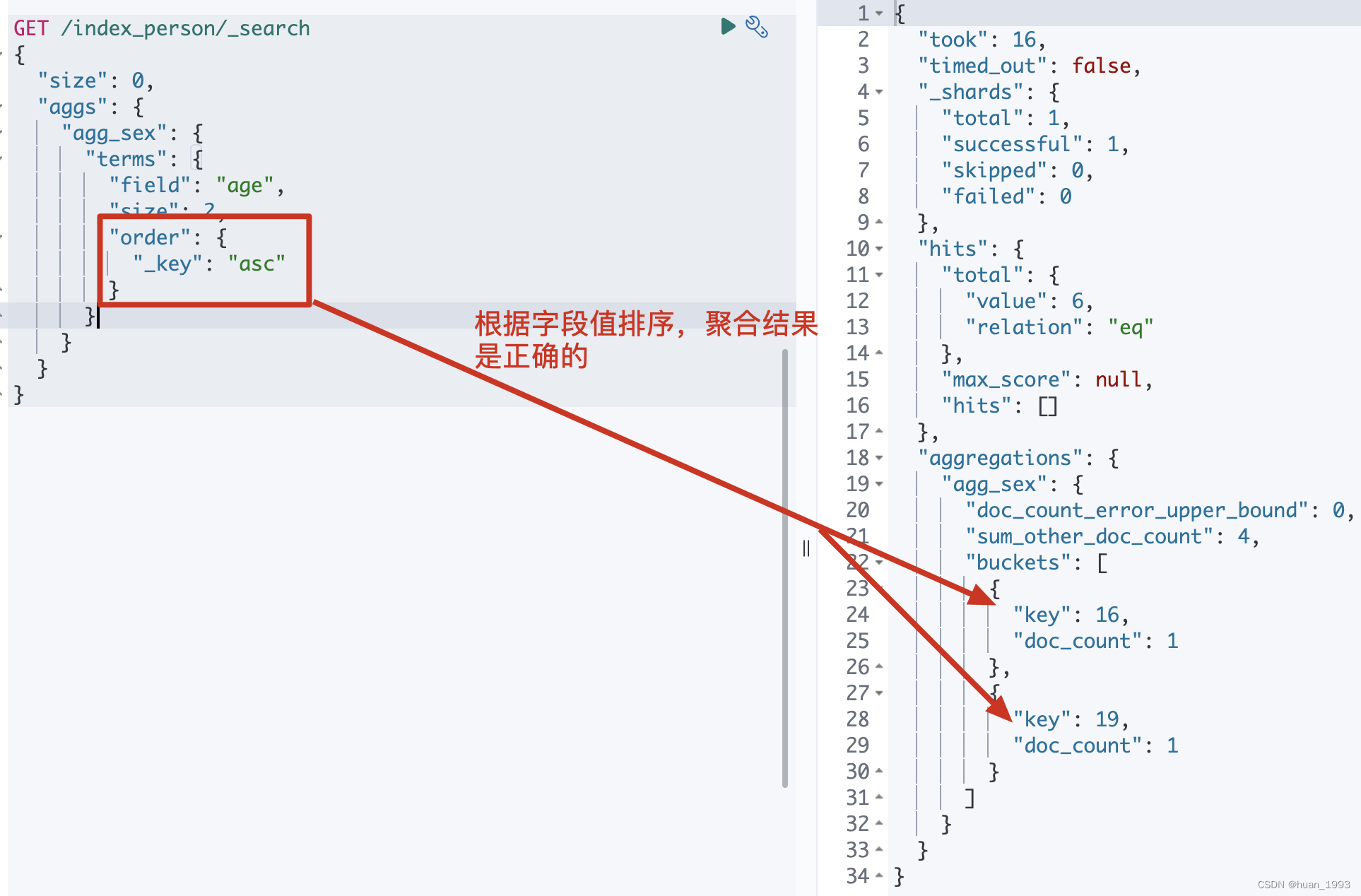
3.4 子聚合排序-先根据省聚合,然后根据每个聚合后的最小年龄排序
3.4.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_sex": {
"terms": {
"field": "province",
"order": {
"min_age": "asc"
}
},
"aggs": {
"min_age": {
"min": {
"field": "age"
}
}
}
}
}
}
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_sex": {
"terms": {
"field": "province",
"order": {
"min_age.min": "asc"
}
},
"aggs": {
"min_age": {
"stats": {
"field": "age"
}
}
}
}
}
}
注意: 子聚合排序一般也是不准的,但是如果是根据子聚合的最大值倒序和最小值升序又是准的。
3.4.2 运行结果

3.5 脚本聚合-根据省聚合,如果地址中有黄冈市则需要出现黄冈市
3.5.1 dsl
GET /index_person/_search
{
"size": 0,
"runtime_mappings": {
"province_sex": {
"type": "keyword",
"script": """
String province = doc['province'].value;
String address = doc['address.keyword'].value;
if(address.contains('黄冈市')){
emit('黄冈市');
}else{
emit(province);
}
"""
}
},
"aggs": {
"agg_sex": {
"terms": {
"field": "province_sex"
}
}
}
}

3.5.2 运行结果
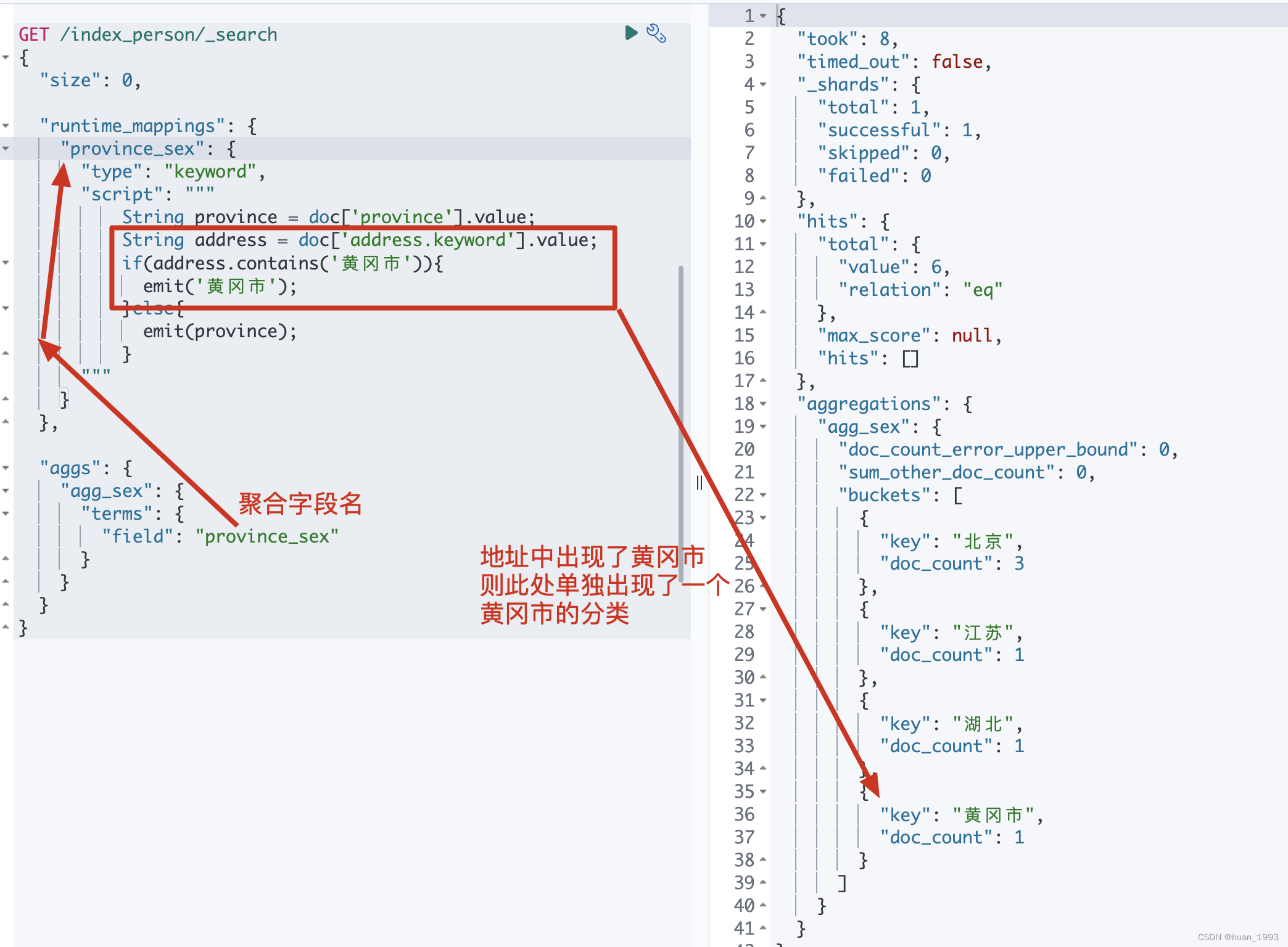
3.6 filter-以省分组,并且只包含北的省,但是需要排除湖北省
3.6.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_province": {
"terms": {
"field": "province",
"include": ".*北.*",
"exclude": ["湖北"]
}
}
}
}
注意: 当是字符串时,可以写正则表达式,当是数组时,需要写具体的值。
3.6.2 运行结果

3.7 多term聚合-根据省和性别聚合,然后根据最大年龄倒序
3.7.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"genres_and_products": {
"multi_terms": {
"size": 10,
"shard_size": 25,
"order":{
"max_age": "desc"
},
"terms": [
{
"field": "province",
"missing": "defaultProvince"
},
{
"field": "sex"
}
]
},
"aggs": {
"max_age": {
"max": {
"field": "age"
}
}
}
}
}
}
注意: terms聚合默认不支持多字段聚合,需要借助别的方式。此处使用multi terms来实现多字段聚合。
3.7.2 运行结果
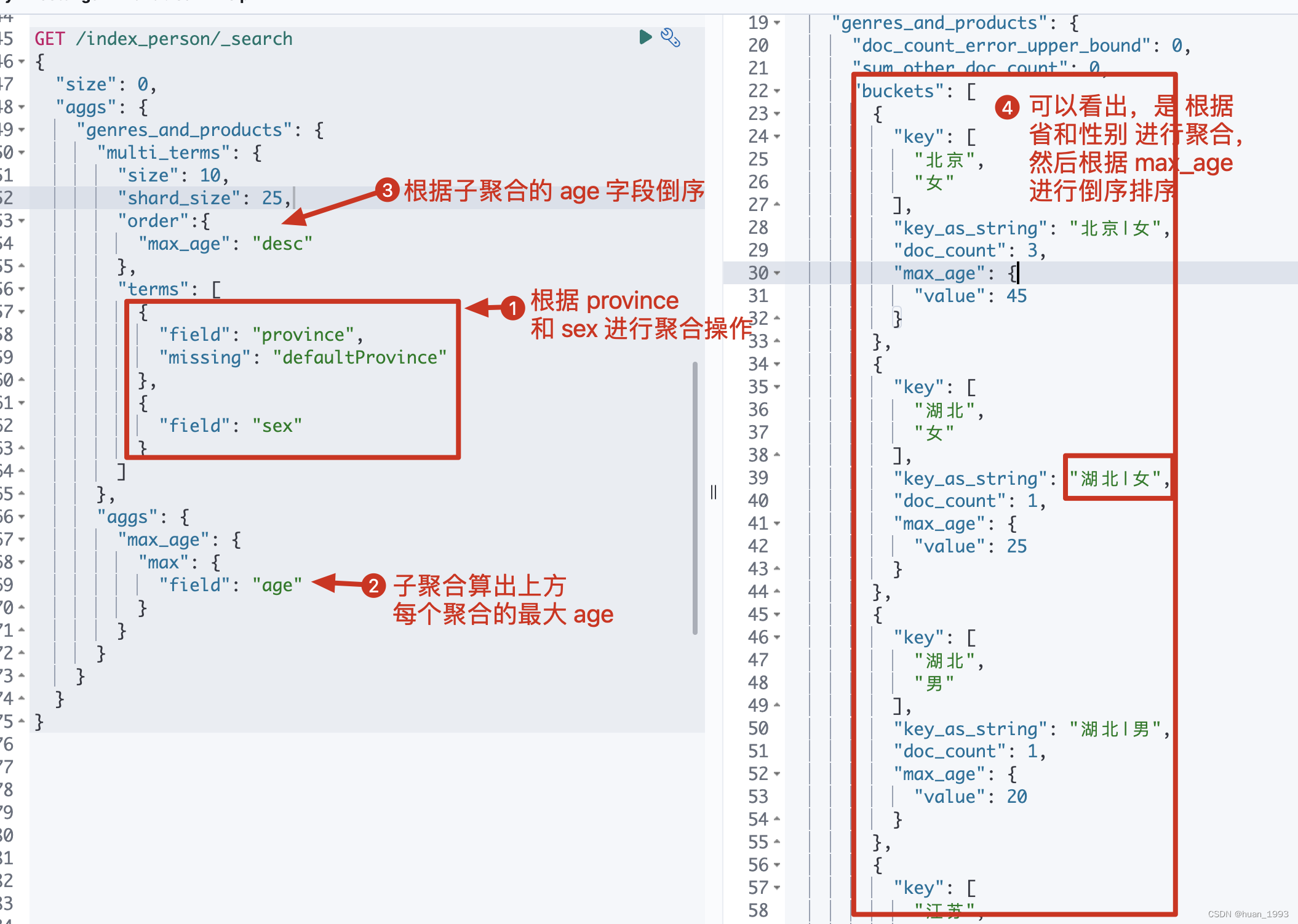
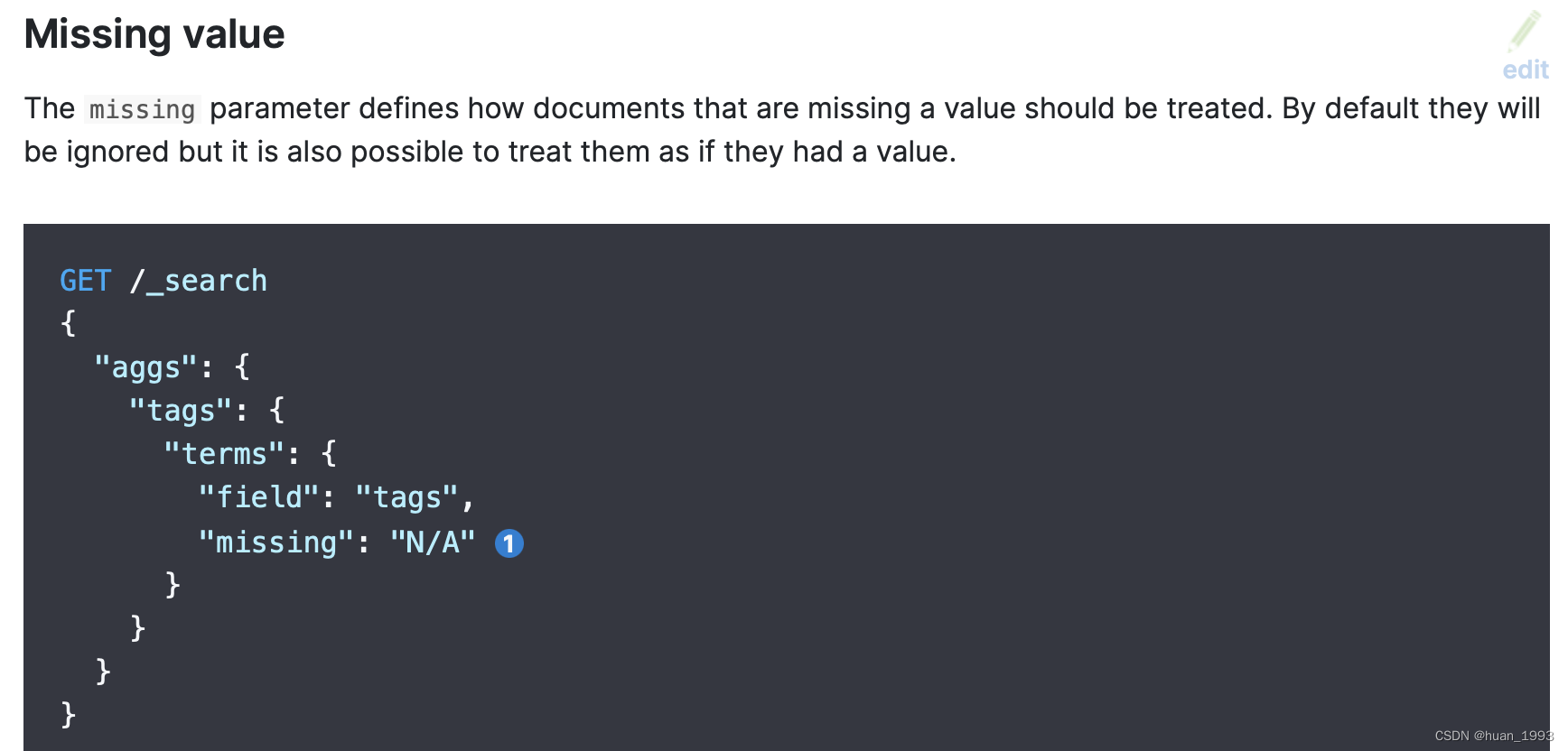
3.8 missing value 处理
3.9 多个聚合-同时返回根据省聚合和根据性别聚合
3.9.1 dsl
GET /index_person/_search
{
"size": 0,
"aggs": {
"agg_province": {
"terms": {
"field": "province"
}
},
"agg_sex":{
"terms": {
"field": "sex",
"size": 10
}
}
}
}
3.9.2 运行结果

4. 总结
4.1 可以聚合的字段
一般情况下,只有如下几种字段类型可以进行聚合操作 keyword,numeric,ip,boolean和binary类型的字段。text类型的字段默认情况下是不可以进行聚合的,如果需要聚合,需要开启fielddata。

4.2 如果我们想返回所有的聚合Term结果
如果我们只想返回100或1000个唯一结果,可以增大size参数的值。但是如果我们想返回所有的,那么推荐使用 composite aggregation
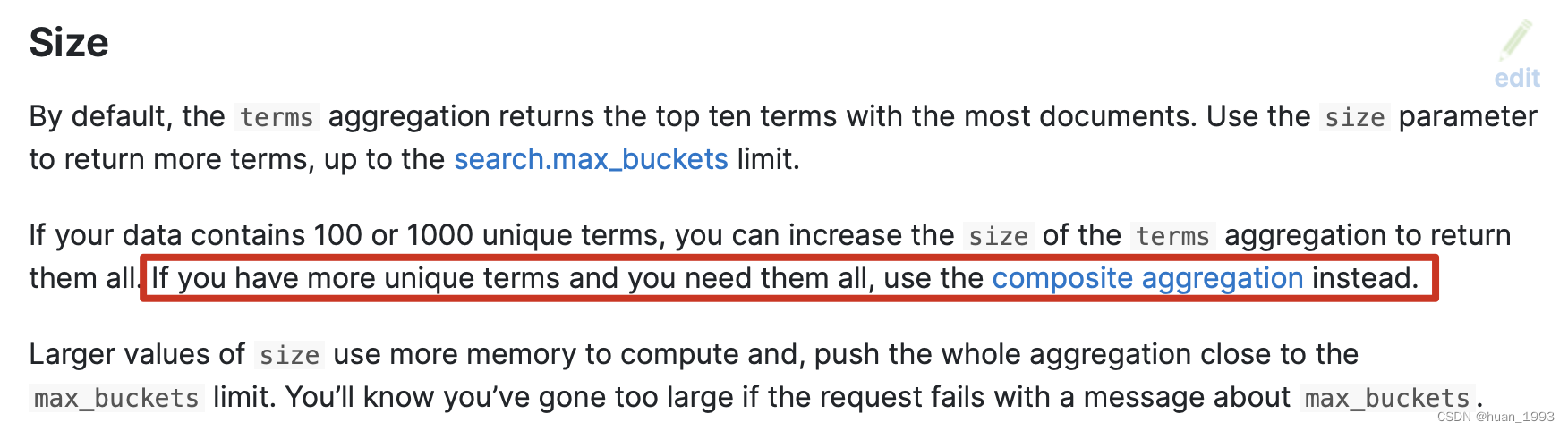
4.3 聚合数据不准
我们通过terms聚合到的结果是一个大概的结果,不一定是完全正确的。
为什么?.
举个例子: 如果我们的集群有3个分片,此处我们想返回值最高的5个统计。即size=5,假设先不考虑shard_size参数,那么此时每个节点会返回值最高的5个统计,然后再次聚合,返回,返回最终值最高的5个。这个貌似没什么问题,但是因为我们的数据是分布es的各个节点上的,可能某个统计项(北京市的用户数),在A节点是是排名前5,但是在B节点上不是排名前5,那么最终的统计结果是否是就会漏统计了。
如何解决:
我们可以让es在每个节点上多返回几个结果,比如:我们的size=5,那么我们每个节点就返回 size * 1.5 + 10 个结果,那么误差相应的就会减少。 而这个size * 1.5 + 10就是shard_size的值,当然我们也可以手动指定,但一般需要比size的值大。

4.4 排序注意事项
4.4.1 _count 排序
默认情况下,使用的是 _count 倒序的,但是我们可以指定成升序,但是这是不推荐的,会导致错误结果。如果我们想要升序,可以使用 rare_terms聚合。

4.4.2 字段值排序
使用字段值排序,不管是正序还是倒序,结果是准确的。

4.4.3 子聚合排序

4.5 多term聚合

5、源码地址
6. 参考链接
- https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-terms-aggregation.html
- https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-multi-terms-aggregation.html
elasticsearch聚合之bucket terms聚合的更多相关文章
- 011-elasticsearch5.4.3【四】-聚合操作【二】-桶聚合【bucket】过滤、嵌套、反转、分组、排序、范围
一.概述 bucketing(桶)聚合:划分不同的“桶”,将数据分配到不同的“桶”里.非常类似sql中的group语句的含义. metric既可以作用在整个数据集上,也可以作为bucketing的子聚 ...
- Elasticsearch(9) --- 聚合查询(Bucket聚合)
Elasticsearch(9) --- 聚合查询(Bucket聚合) 上一篇讲了Elasticsearch聚合查询中的Metric聚合:Elasticsearch(8) --- 聚合查询(Metri ...
- Elasticsearch聚合 之 Date Histogram聚合
Elasticsearch的聚合主要分成两大类:metric和bucket,2.0中新增了pipeline还没有研究.本篇还是来介绍Bucket聚合中的常用聚合--date histogram.参考: ...
- ES Terms 聚合数据不确定性
Elasticsearch是一个分布式的搜索引擎,每个索引都可以有多个分片,用来将一份大索引的数据切分成多个小的物理索引,解决单个索引数据量过大导致的性能问题,另外每个shard还可以配置多个副本,来 ...
- ElasticSearch 2 (35) - 信息聚合系列之近似聚合
ElasticSearch 2 (35) - 信息聚合系列之近似聚合 摘要 如果所有的数据都在一台机器上,那么生活会容易许多,CS201 课商教的经典算法就足够应付这些问题.但如果所有的数据都在一台机 ...
- Elasticsearch聚合 之 Range区间聚合
Elasticsearch提供了多种聚合方式,能帮助用户快速的进行信息统计与分类,本篇主要讲解下如何使用Range区间聚合. 最简单的例子,想要统计一个班级考试60分以下.60到80分.80到100分 ...
- Elasticsearch学习系列四(聚合搜索)
聚合分析 聚合分析是数据库中重要的功能特性,完成对一个查询的集中数据的聚合计算.如:最大值.最小值.求和.平均值等等.对一个数据集求和,算最大最小值等等,在ES中称为指标聚合,而对数据做类似关系型数据 ...
- Flask聚合函数(基本聚合函数、分组聚合函数、去重聚合函数))
Flask聚合函数 1.基本聚合函数(sun/count/max/min/avg) 使用聚合函数先导入:from sqlalchemy import func 使用方法: sun():func.sum ...
- Elasticsearch 聚合统计与SQL聚合统计语法对比(一)
Es相比关系型数据库在数据检索方面有着极大的优势,在处理亿级数据时,可谓是毫秒级响应,我们在使用Es时不仅仅进行简单的查询,有时候会做一些数据统计与分析,如果你以前是使用的关系型数据库,那么Es的数据 ...
随机推荐
- 在 node 中使用 jquery ajax
对于前端同学来说,ajax 请求应该不会陌生.jquery 真的ajax请求做了封装,可以通过下面的方式发送一个请求并获取相应结果: $.ajax({ url: "https://echo. ...
- 第三课:nodejs npm和vue
1.安装node js 2.node js给windows提供了一个可以直接执行js的环境{node提供翻译} 3.npm是包管理器 a.npm是nodejs的组成部分 b.管 包(package) ...
- K8S Pod及其控制器
Pod K8S里能够运行的最小逻辑单元,1个Pod可以运行多个容器 Pod 控制器 Pod控制器是Pod启动的一种模版,用来保证在K8S中启动的Pod始终按照人们的预期运行(副本数,生命周期.健康状态 ...
- 大规模数据分析统一引擎Spark最新版本3.3.0入门实战
@ 目录 概述 定义 Hadoop与Spark的关系与区别 特点与关键特性 组件 集群概述 集群术语 部署 概述 环境准备 Local模式 Standalone部署 Standalone模式 配置历史 ...
- C#,根据路径获取某个数字开头的所有文件夹,并获取最新文件夹进行替换文件
项目需求获取某路径下为1开头文件夹,并替换最新文件夹内容,话不多说,上代码 private void Form1_Load(object sender, EventArgs e) { try { st ...
- Win32简单图形界面程序逆向
Win32简单图形界面程序逆向 前言 为了了解与学习底层知识,从 汇编开始 -> C语言 -> C++ -> PE文件 ,直至今天的Win32 API,着实学的令我头皮发麻(笑哭). ...
- (数据科学学习手札143)为geopandas添加gdb文件写出功能
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,很多读者朋友跟随着我先前写作的 ...
- .NET 反向代理-YARP 根据域名转发
前段时间发布过一个关于 YARP 的简单介绍,感兴趣的小伙伴恭请移步看看 .NET 反向代理-YARP - 一事冇诚 - 博客园 (cnblogs.com) 作为反向代理,必不可少的当然是根据域名代理 ...
- Elasticsearch 主从同步之跨集群复制
文章转载自:https://mp.weixin.qq.com/s/alHHxXont6XFm_m9PfsGfw 1.什么是跨集群复制? 跨集群复制(Cross-cluster replication, ...
- 开启tcp_timestamps和tcp_tw_recycle造成NAT转发连接不上
文章转载自:https://segmentfault.com/a/1190000022264813