Apache ShenYu 集成 RocketMQ 实时采集海量日志的实践
本文作者:胡泰室, 快手Java开发工程师。
认识Apache ShenYu(神禹)
网关最重要的是流量治理,而流量治理与大禹治水有很多相似的地方,因此,网关的流量治理项目被命名为神禹。
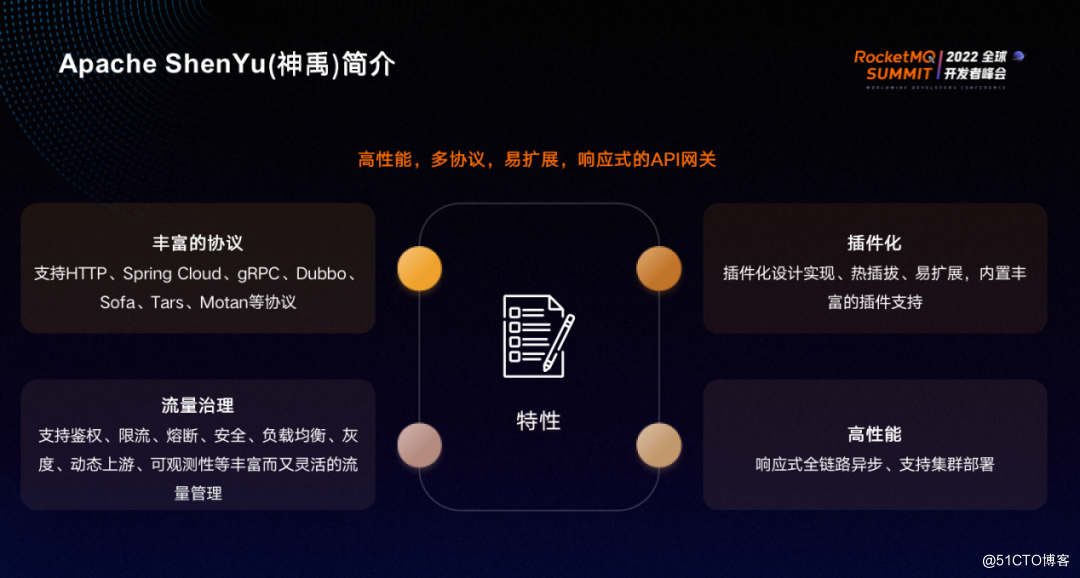
ShenYu是一个高性能、多协议、易扩展、响应式的 API 网关,主要特性包括丰富的协议、插件化、流量治理和高性能。
ShenYu支持 HTTP、Spring Cloud、gRPC、Dubbo、Sofa、Tars、Motan 等协议。为了保证可扩展性,ShenYu采用了插件化的设计,支持热插拔,内置丰富的插件。插件化设计最大的好处为可扩展性强,ShenYu大量的流量治理功能都各自对应了不同的插件。ShenYu支持鉴权、限流、熔断、安全、负载均衡、灰度、动态上游、可观测性等丰富而灵活的流量管理。由于网关对性能要求特别高,ShenYu采用了响应式全链路异步,支持集群部署、蓝绿发布等。
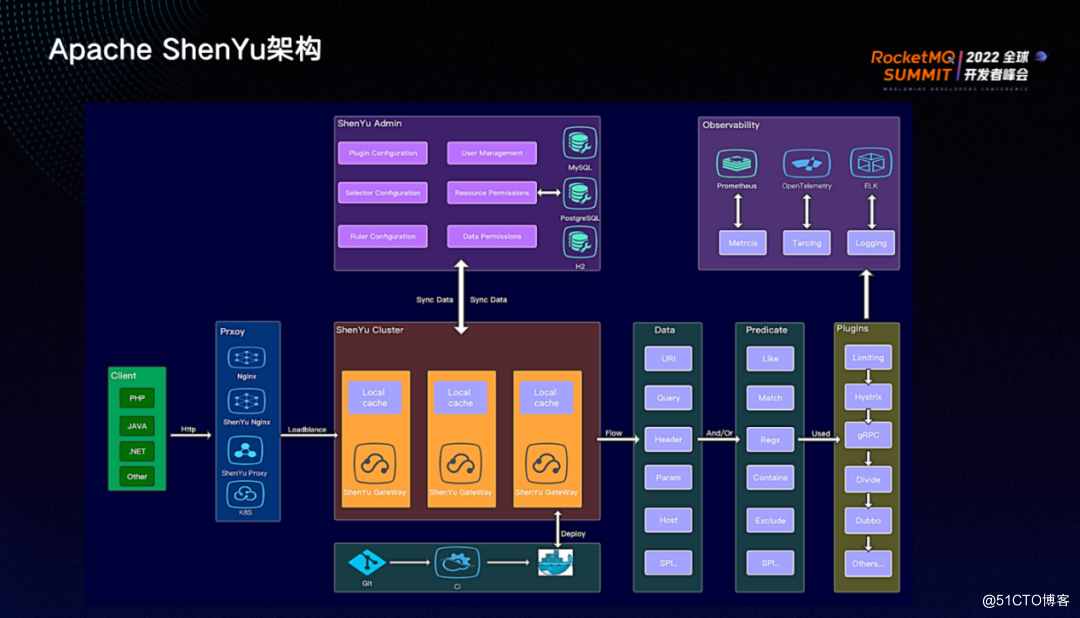
客户端发起请求经过网关,再由网关将请求转换到服务提供者,并将服务提供者的响应发送给客户端。
从发起请求的角度来看架构,它支持多语言,不限操作平台。HTTP 请求首先经过一层代理层,代理层可以是 Nginx、ShenYuNginx、ShenYu代理或 K8s,将请求通过负载均衡路由到ShenYu集群中的节点上。ShenYu网关接收到请求之后,首先对请求进行筛选。网关为了保证性能,将各种元数据都存储在本地内存中,再配合高效的算法来实现高性能。
数据的请求处理离不开元数据,而元数据的获取主要依靠ShenYu网关与ShenYu后台的同步机制,在ShenYu admin 后台进行数据变更后,比如插件变更、选择器变更、规则变更、数据变更等,会通过一定的方式将变更同步到ShenYu网关中。
用户可以根据项目特点选择拉取或推送的同步方式。首先要对流量进行筛选,可以根据请求的 URL 查询参数、请求头、请求参数、host或请求 Body 等进行匹配。匹配的条件可以是 like、match、正则表达、包含或排除等,再通过 SPI 的方式来加载对应的实现。
如果流量匹配,则将流量转发到各个插件。各个插件形成插件链,每一个插件链对于匹配的流量会执行其插件功能。最终请求会经过出口插件转发到服务提供者,然后将服务提供者的响应转交给客户端。
对于网关运行状态的监控是非常重要的模块,可观测性指标loggin的请求量可能非常大,导致日志量也很大,这种情况一般需要集成消息队列。
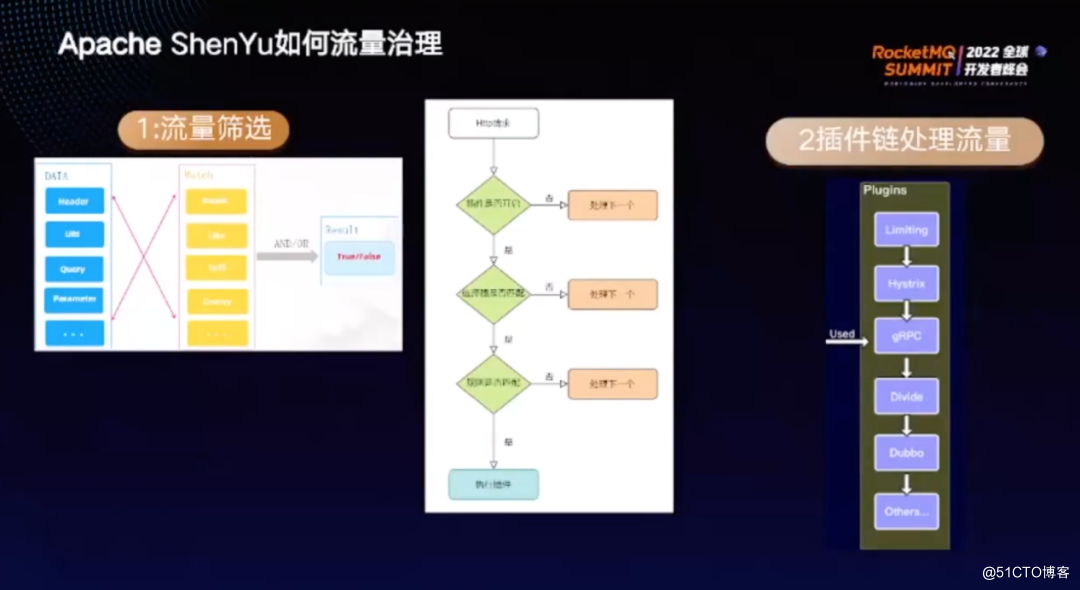
ShenYu的流量筛选流程如上图所示,每个请求都有一定的元数据,可以根据这些元数据进行匹配来筛选出需要的请求。ShenYu的流量筛选有两个非常重要的组件,分别是选择器和规则。
请求到达后,首先判断插件是否开启,如果未开启,则不予处理;如果已开启,则插件对应的选择器会判断请求是否匹配。如果请求匹配,则将交给规则再进行一次匹配;如果不匹配,则交给下一个插件进行处理,匹配则执行插件。
选择器相当于一级匹配,是一种粗粒度的匹配,而规则相当于二级匹配,是一种细粒度的匹配,这样的设计能够保证更高的灵活性。
插件形成了一条插件链,前一个插件执行完后再决定是否交由下一个插件进行处理。
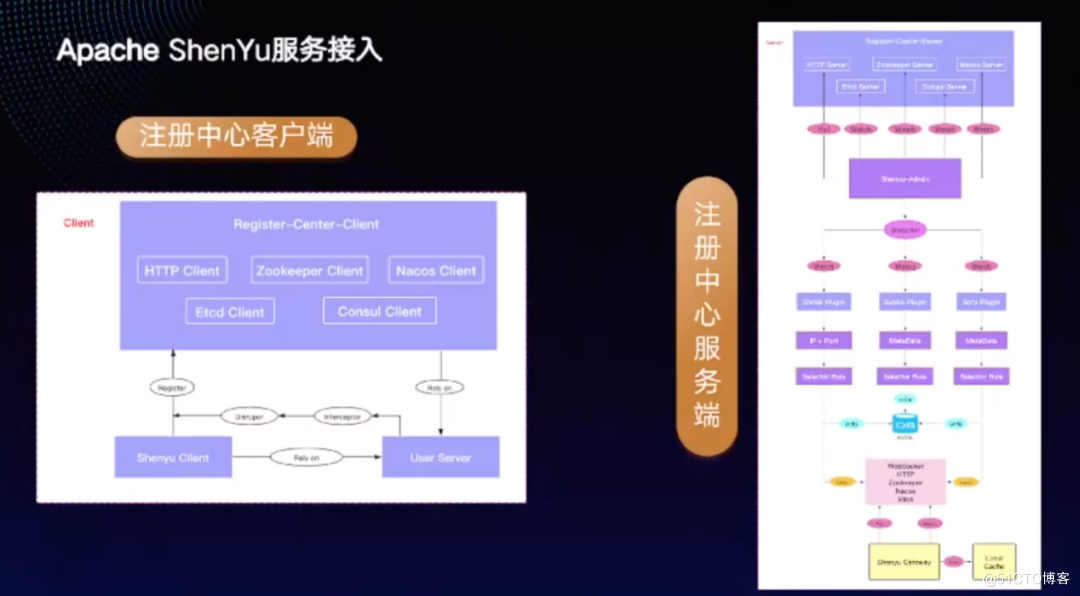
有流量的筛选必然还需要流量的处理,流量的处理会将服务提供者接入到网关ShenYu,提供一系列的ShenYu客户端用于接入服务提供者。服务提供者依赖ShenYu的接入客户端,当服务提供者启动时,ShenYu客户端会获取到元数据信息,并将元数据信息发送到 Disruptor ,注册中心的客户端会获取到Disruptor中的数据,再发送到注册中心。注册中心支持很多方式,比如 HTTP 方式、Zookeeper、Nacos 等。
在注册中心服务端,ShenYu admin 会监听到注册中心的数据变化,可自行配置选择哪种注册中心以及哪种同步方式。ShenYu admin 监听到元数据的变更后,将其同步到ShenYu网关,比如通过保存MySQL 进行持久化或通过Zookeeper等同步到ShenYu网关,再更新至本地缓存。
ShenYu的流量治理是动态的,使用非常灵活、方便。
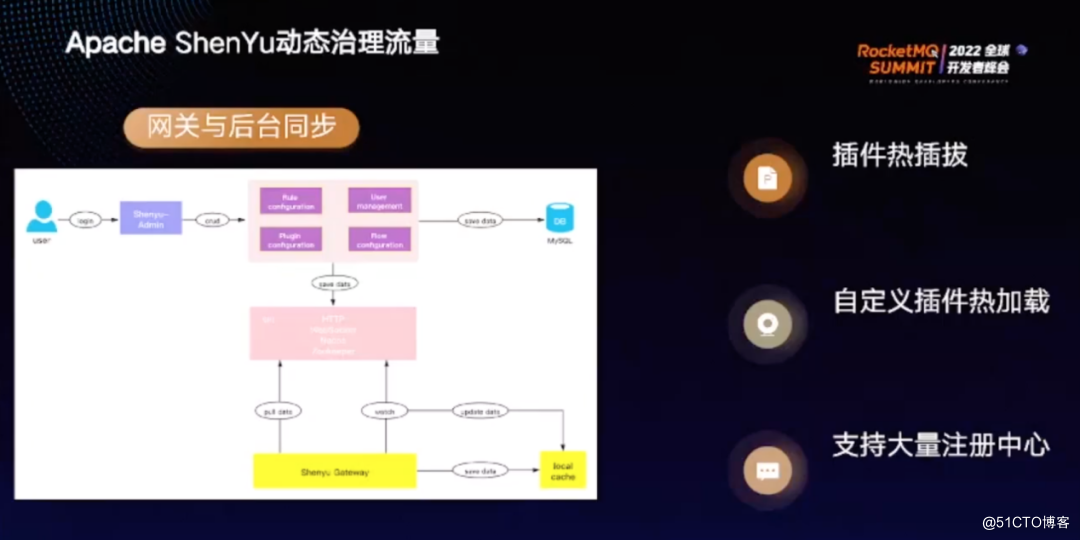
ShenYu网关和后台的同步中,如果用户对元数据进行了操作或通过 API 的方式对元数据进行了操作,ShenYu admin 监测到变化后,将会通过 SPI 的方式加载出用户配置的同步方式,支持 HTTP 等拉取类型的方式,也支持WebSocket 等推送的方式。ShenYu网关监听到元数据变更后会立即更新缓存,对接下来的请求生效。
ShenYu支持插件热插拔,比如针对一些无用插件可以直接排除,对于依赖的插件可以在后台控制是否开启并配置各种元数据。另外,官方自带插件无法覆盖所有场景,用户也可以自定义插件,ShenYu提供了自定义的类加载器。同时,社区也在开发通过管理后台上传自己的插件,用户操作更方便。注册中心方面,ShenYu几乎支持所有主流注册中心。
上图为ShenYu贡献者数量发展情况。可以看出,从 2021 年起,贡献者的数量表现为稳步、持续的增长,而2021年正是ShenYu捐献给Apache的时间节点。这也表明了自ShenYu加入阿帕奇孵化器之后,其活跃度越来越高,贡献者越来越多,用户也在增多。
ShenYu社区的运营方式为社区大于代码,其生态较为丰富,几乎支持所有主流的 RPC 框架,成长非常迅速。
ShenYu可观测性日志
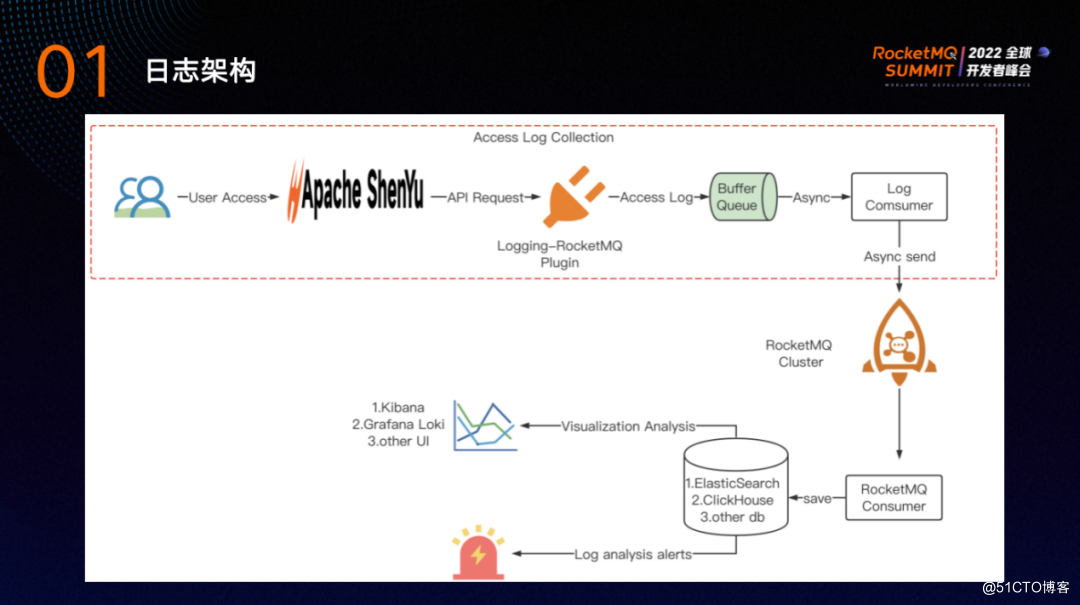
上图为ShenYu的可观测性日志架构。
一次用户请求经过Apache ShenYu,由 Logging-RocketMQ 插件来实现日志。Logging-RocketMQ插件会将 Access Log日志放入缓冲队列中,后台会起一个日志消费者以异步的方式消费日志,再将日志发送到RocketMQ 集群。为了收集日志,需要再启动一个 RocketMQ Consumer 将日志批量持久化,可以写入 Elasticsearch 、Clickhouse 或其他 DB。
在可视化方面,可以选择 Kibana、Grafana、Loki或对接公司内部的日志系统。针对日志可以进行日志聚合分析,对日志情况进行报警,比如可以对请求量、请求耗时、请求异常情况进行告警等。

日志中非常重要的参数是入参和出参,它们能够非常方便地帮助排查故障。ShenYu底层是基于 reactor 的异步非阻塞模式,是一种响应式网关,发布订阅模式。请求的 Body 和响应的 Body 面临只能取一次的问题,如果当前日志取了一次 Body ,则接下来的订阅者将会取不到 Body 。AccessLog 的采集需要满足完全无副作用,是一种辅助功能。
在入参采集上采用装饰器设计模式,将请求进行委托,继承了 ServerHttpRequestDecorator。制定一个请求需要重写 getBody 方法,且需要采用无副作用的方式。以 do 开头的是无副作用的方法,采集认证即从这种无作用的方法里插入日志采集的代码。同时 dataBuffer 要采取 readonlyBuffer 的方式才能避免无副作用。这也是一种流式读取的方式,因此在doFinally方法里才能确定请求的 Body 读取完毕了。
出参的采集也是采用装饰器设计模式,将响应进行委托,继承 ServerHttpResponseDecorator, 重写 writeWith 方法。同理,在 writeWith 方法中,首先对 Body 参数进行 from 的转换,然后在 doOnNext里面收集响应的 Body ,最终在doFinally里确定响应的 Body 已经收集完毕,此时可将日志发送到缓冲队列中。
发生异常时,ShenYu提供了全局的异常处理器,在全局的异常处理器里也加入了日志的采集。
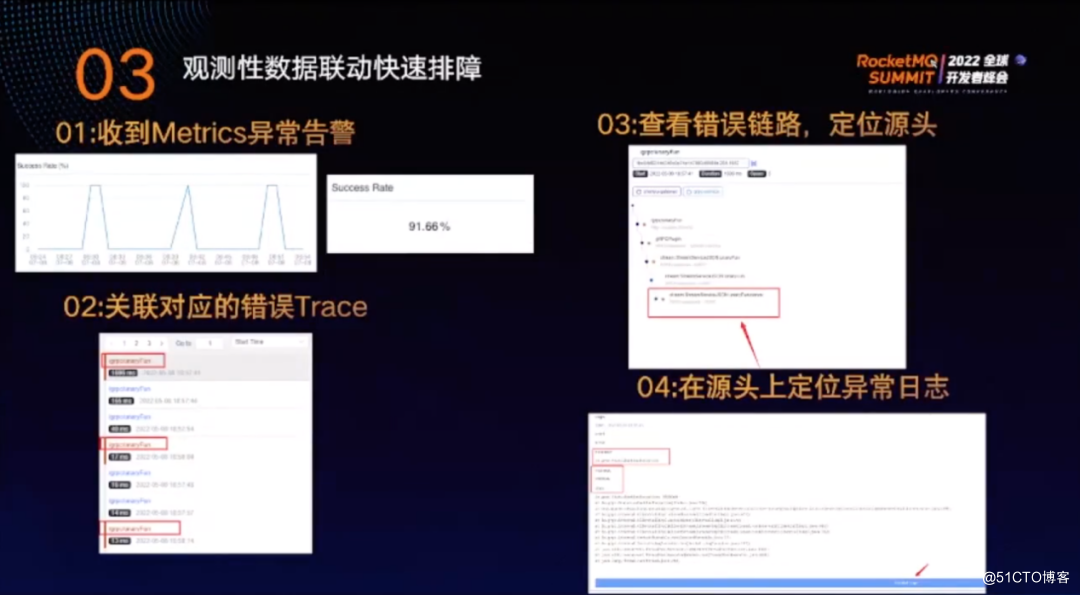
排除故障的流程如下:
①收到 Metrics异常告警,但此时往往无法获知具体哪个节点出现错误。
②关联对应的错误Trace,Trace 的最大功能在于定位到故障节点。
③查看错误链路,定位源头。
④在源头上定位异常日志。
上述流程说明日志和 Trace 需要进行联动。一次请求产生的所有日志都需要能够进行串联,一般通过 Trace ID 串联。
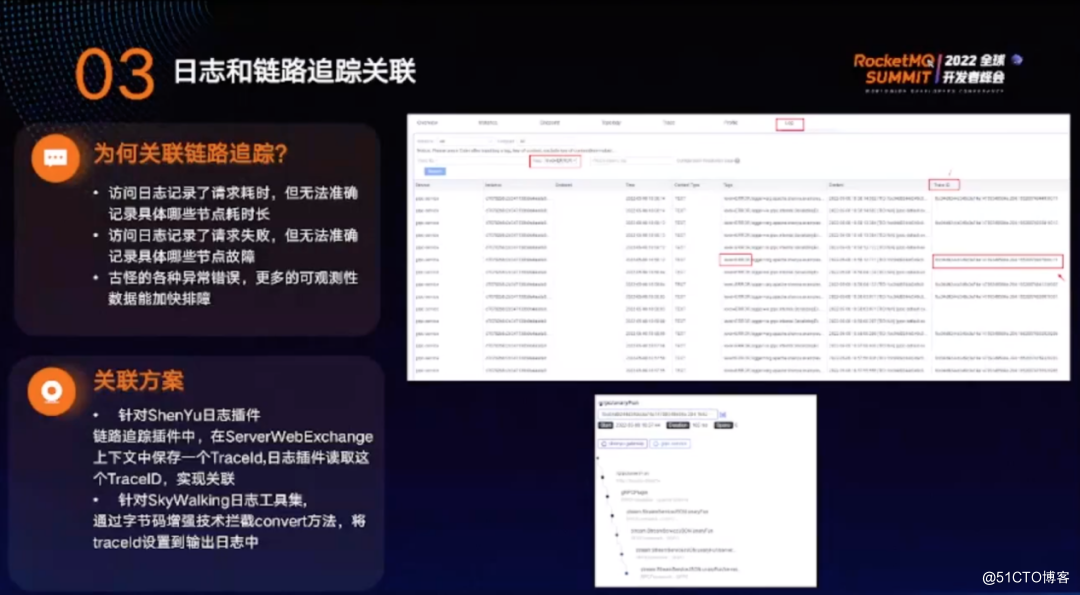
访问日志记录了请求耗时,但是无法准确记录哪些节点耗时长;也记录了请求失败,但无法准确记录哪些节点故障;此外,还有各种异常错误,更多的可观测性数据能够加快排障。
ShenYu日志插件与链路追踪进行关联的方案如下:
- 如果采用了ShenYu日志插件配合其他链路追踪,在链路追踪插件中,以 SkyWalking为例,链路追踪必然会访问到ServerWebExchange,插件可以在ServerWebExchange的上下文中保存 Trace ID,ShenYu的日志插件即可读取 Trace ID 实现关联。
- 如果仅使用了 SkyWalking日志工具集,它自带关联,在日志配置文件中配置 Trace ID 变量,然后通过字节码增强技术拦截 convert方法,将 Trace ID 设置到输出日志中。
右图可见,每个人都有一个 Trace ID 字段,点击 Trace ID 字段即可关联本次请求经过的所有链路。
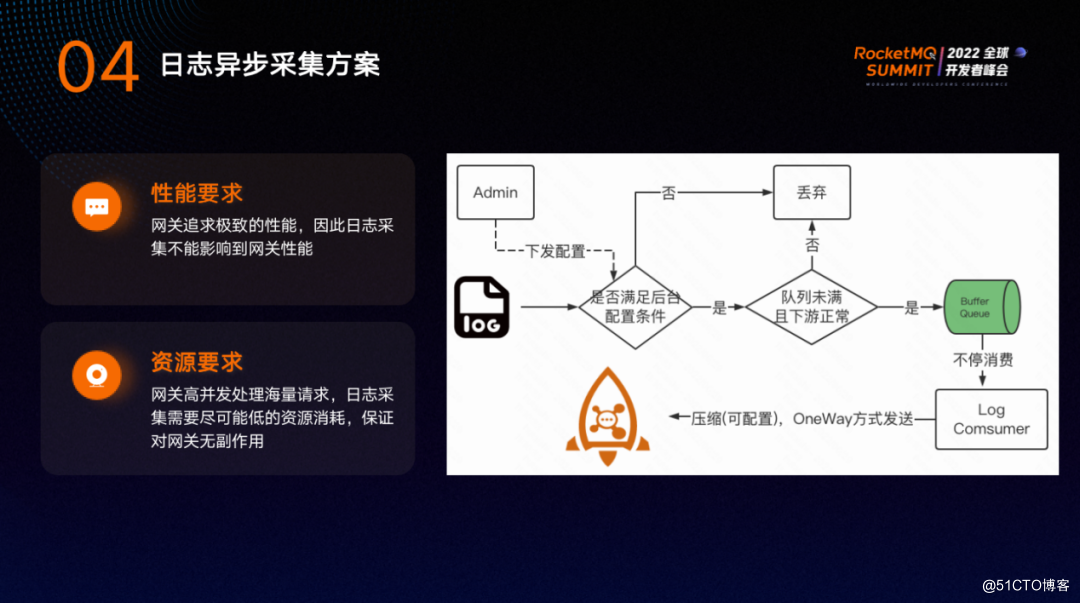
日志异步采集方案有两个要求:
- 性能方面:要求网关追求极致的性能,因此日志采集以及一切辅助性的功能不能影响网关性能。
- 资源方面:网关高并发处理海量请求,日志采集需要尽可能低的资源消耗,保证对网关无副作用。
一个请求会产生 Access Log,Admin首先会判断其是否满足配置条件,条件可以通过某些字段自行配置,从 admin 配置并下发到 Logging-Rock插件。另外还可以配置采样,如果日志不满足采样,将会被丢弃。
通过一系列的判断之后,还需要判断缓存队列是否有足够的容量,如果队列已满或下游不正常,也会将日志丢弃。如果将日志直接发送到 RocketMQ 集群,会产生一次 IO 调用,IO调用非常耗时,而如果将日志放入内存缓存队列的耗时可以忽略不计,因此这里需要引入缓存队列。
后台的Log Consumer 会不停地从缓存队列中取日志,取出的日志可以进行压缩,压缩可配置,再通过 OneWay 的方式进行发送。
采样有很多种实现方式,此处采用了生成随机数再对随机数进行取余的方式判断请求日志是否要采样,但是在ShenYu网关中并没有这样做,因为生成随机数是一种较为耗时的操作,而网关对性能要求非常高。
ShenYu日志采样采用 bitmap 的实现,将bitmap 设置为 100 位,设置采样百分比,可以将一定比例的位设置为true,其他设置为 false,然后进行随机打乱。在内存中可以维护自增变量,每次进行自增,就这这层变量进行取余,然后判断对应的位是否开启。如果开启,则进行采样,避免了生成随机数这种耗时的方式。
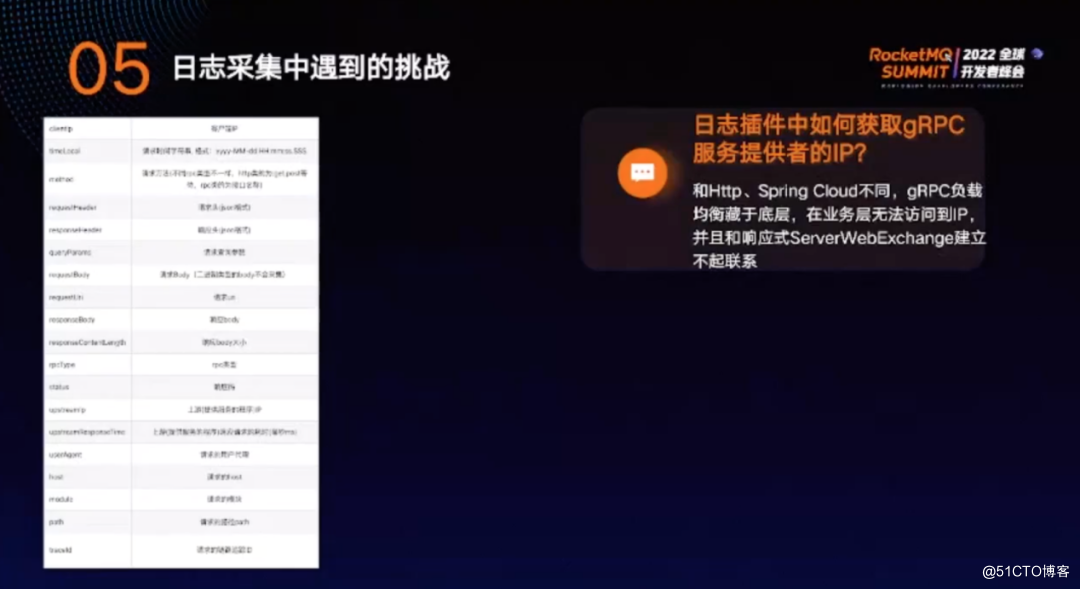
日志采集中的字段有客户端 IP、时间、方法、请求头、响应头、查询参数、请求 Body 、请求的 URL、响应Body、响应内容长度、 RPC 类型、状态、上游 IP 等。通过这些字段可以得出哪些请求耗时较高、某种类型的请求量是多少、请求的异常情况。当发生异常时,可以通过上游IP定位到发生异常的上游。很多时候整个集群的任意节点都有问题,但也可能只是集群中的某几个节点有问题,此时,上游 IP 的排障功能优势可以大会极大的作用。
日志采集中遇到的一大挑战是日志插件中如何获取 gRPC 服务提供者的 IP。与Http、Sprin Cloud 不同,gRPC负载均衡藏于底层,业务层无法访问到 IP, 且与响应式 ServerWebExchange无法建立联系。另外,在链路追踪中也需要获取上游 IP,SkyWalking如何实现?
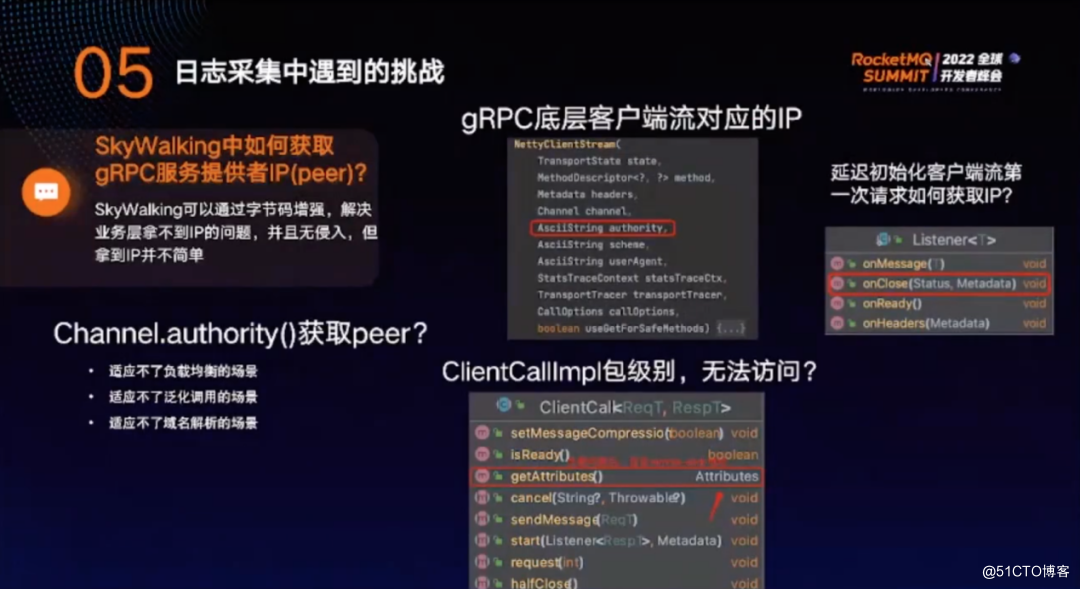
SkyWalking通过字节码增强的方式解决业务层无法获取 IP 的问题,并且无侵入。但获取 IP 并不容易,常规的做法是通过 Channel.authority() 来获取 peer,但这种方式存在很大的局限性:
其一,适应不了负载均衡的场景;
其二,适应不了泛化调用的场景。网关通过泛化调用,而泛化调用没有 channel。
其三,适应不了域名解析的场景。
经过分析,gRPC底层客户端流对应的IP 可以从Netty客户端获取,即authority。此外,由于延迟初始化,第一次调用方法是一个空方法。由于 gRPC 的请求有监听器,因此可以在 onClose 方法里进行处理。调用 onClose 说明请求已经发送完,也意味着客户端一定已经完成初始化。但这种方式依然不够不准确,所以需要通过另外一种方式。
ClientCallImpl有一个getAttributes属性,调用了Netty客户端流的属性。在该属性中包含 Remote Addr,这便是上游 IP 地址。ClientCallImpl为包级别,在业务层无法访问的,只能访问到对象,可以通过反射获取 IP 。

集成RocketMQ主要基于以下两个方面考虑:
第一,削峰填谷。业务高峰期可能出现万亿级别的消息吞吐,请求量越大,响应式日志也会越多。如果没有分布式消息队列,日志系统可能会崩溃或将大量日志丢弃。引入 RocketMQ能够实现削峰填谷,面对万亿级的消息吞吐,可以将大量日志先发送到 RocketMQ进行暂存,再由消费者不断地从RocketMQ进行消费。
第二,解耦。ShenYu是开源项目,各个公司、项目可能都有自己的日志系统,如何将ShenYu与这些日志系统进行对接?答案是解耦。集成RocketMQ后,ShenYu可以将日志发送到消息队列中,各个项目或是公司可以根据业务特点从 RocketMQ中消费日志,再将日志入库到自己的日志系统。采用这种解耦方式更易于对接和维护,同时ShenYu社区提供了多种消息队列。
RocketMQ具有以下几个优秀特性:
- 金融级可靠。丢弃日志可能会在统计上造成很大麻烦,比如订单日志丢失会导致交易额不准确。
- 纳秒级延迟。ShenYu网关对性能要求非常高,所以消费日志需要尽可能高的性能,而RocketMQ是纳秒级的延迟。
- 万亿级消息吞吐。业务高峰期可能会产生万亿级的日志,如果RocketMQ性能不强,将无法支撑如此巨量的日志系统。
- 海量 Topic 支持。ShenYu网关可以是多租户的方式,即不同业务可以共用网关集群,不同日志可以发送到不同集群中,能够更好地实现隔离。
- 超大规模堆积支持。业务高峰期出现万亿级的消息吞吐,RocketMQ 必然会堆积大量消息,而消费者无法短时间内完成所有消费,需要消息队列能够支持超大规模的堆积。
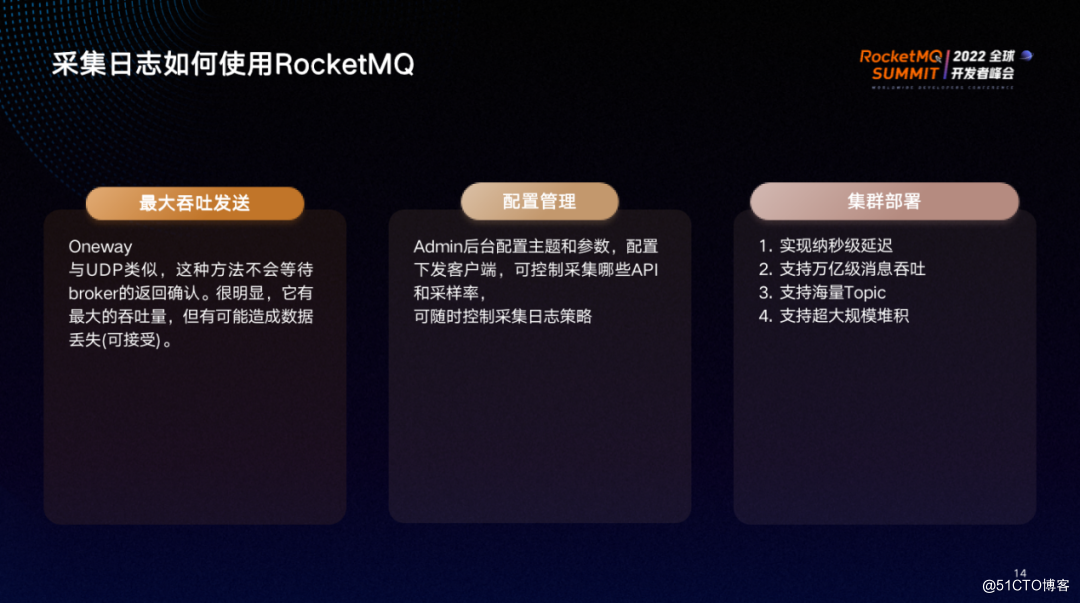
采集日志使用RocketMQ时,由于网关对性能要求高,所以需要以尽可能低的延迟消费日志。选择 OneWay 的发送方式,与 UDP 类似,这种方法不会等待 Broker的返回确认,它有最大的吞吐量,但极端情况下可能造成数据丢失(可接受)。
在配置管理方面,admin后台配置主题和参数,配置下发客户端,可控制采集哪些 API 、采样率以及各种过滤条件,比如控制Body大小,包体特别大可以丢弃。可实时控制采集日志策略,另外支持日志压缩,支持实时关闭或开启日志收集。
在RocketMQ方面需要集群部署,单节点部署可用性非常低,集群部署能够更好地实现纳米级延迟,支持万亿级消息吞吐,支持海量Topic,支持超大规模堆积,以上都是集群部署相比于单节点部署的好处。
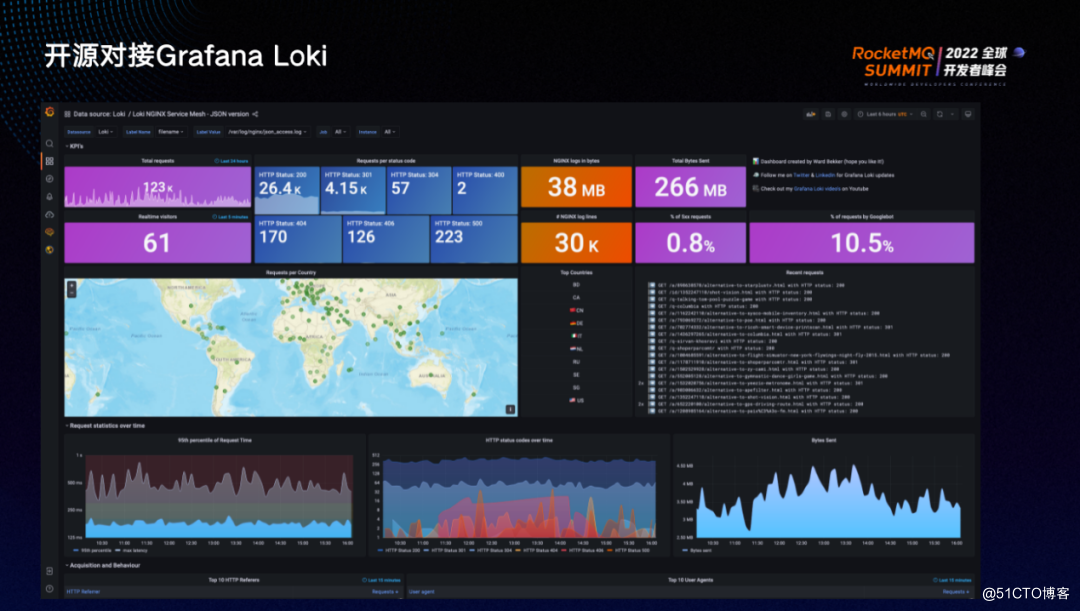
采集了日志后需要对日志进行消费,主要通过可视化手段。ShenYu是开源项目,可对接各种开源项目,比如 Kibana、Grafana、Loki等。Grafana 在可观测性方面能够一站式支持Metrics、Logging和Trace。
可视化关注各个接口的请求量、耗时以及异常情况,包括网络方面的比如字节的吞吐、发送/接收的字节数等,也可以配置告警,可以进行聚合操作,比如判断出一段时间内哪些接口的请求量环比突然增高、哪些接口耗时突然增加、哪些接口异常量突然增加等。
加入 Apache RocketMQ 社区
十年铸剑,Apache RocketMQ 的成长离不开全球接近 500 位开发者的积极参与贡献,相信在下个版本你就是 Apache RocketMQ 的贡献者,在社区不仅可以结识社区大牛,提升技术水平,也可以提升个人影响力,促进自身成长。
社区 5.0 版本正在进行着如火如荼的开发,另外还有接近 30 个 SIG(兴趣小组)等你加入,欢迎立志打造世界级分布式系统的同学加入社区,添加社区开发者微信:rocketmq666 即可进群,参与贡献,打造下一代消息、事件、流融合处理平台。

微信扫码添加小火箭进群
另外还可以加入钉钉群与 RocketMQ 爱好者一起广泛讨论:

钉钉扫码加群
Apache ShenYu 集成 RocketMQ 实时采集海量日志的实践的更多相关文章
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
- Openresty+Lua+Kafka实现日志实时采集
简介 在很多数据采集场景下,Flume作为一个高性能采集日志的工具,相信大家都知道它.许多人想起Flume这个组件能联想到的大多数都是Flume跟Kafka相结合进行日志的采集,这种方案有很多他的优点 ...
- 海量日志采集Flume(HA)
海量日志采集Flume(HA) 1.介绍: Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据 ...
- 基于Flume+Kafka+ Elasticsearch+Storm的海量日志实时分析平台(转)
0背景介绍 随着机器个数的增加.各种服务.各种组件的扩容.开发人员的递增,日志的运维问题是日渐尖锐.通常,日志都是存储在服务运行的本地机器上,使用脚本来管理,一般非压缩日志保留最近三天,压缩保留最近1 ...
- Dubbo学习系列之十六(ELK海量日志分析框架)
外卖公司如何匹配骑手和订单?淘宝如何进行商品推荐?或者读者兴趣匹配?还有海量数据存储搜索.实时日志分析.应用程序监控等场景,Elasticsearch或许可以提供一些思路,作为业界最具影响力的海量搜索 ...
- Flume采集处理日志文件
Flume简介 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据 ...
- ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台(elk5.2+filebeat2.11)
ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台 参考:http://www.tuicool.com/articles/R77fieA 我在做ELK日志平台开始之初选择为 ...
- ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台
日志分析平台,架构图如下: 架构解读 : (整个架构从左到右,总共分为5层) 第一层.数据采集层 最左边的是业务服务器集群,上面安装了filebeat做日志采集,同时把采集的日志分别发送给两个logs ...
- flume实时采集mysql数据到kafka中并输出
环境说明 centos7(运行于vbox虚拟机) flume1.9.0(flume-ng-sql-source插件版本1.5.3) jdk1.8 kafka(版本忘了后续更新) zookeeper(版 ...
- 采用Flume实时采集和处理数据
它已成功安装Flume在...的基础上.本文将总结使用Flume实时采集和处理数据,详细过程,如下面: 第一步,在$FLUME_HOME/conf文件夹下,编写Flume的配置文件,命名为flume_ ...
随机推荐
- 01 - 快速体验 Spring Security 5.7.2 | 权限管理基础
在前面SpringBoot 2.7.2 的系列文章中,已经创建了几个 computer 相关的接口,这些接口直接通过 Spring Doc 或 POSTMAN 就可以访问.例如: GET http:/ ...
- TCP/UDP报文格式
TCP报文格式 源端口:数据发送方的端口号 目的端口:数据接收方的端口号 序号:本数据报文中的第一个字节的序号(在数据流中每个字节都对应一个序号) 确认号:希望收到的下一个数据报文中的第一个字节的序号 ...
- ansible 003 常用模块
常用模块 file 模块 管理被控端文件 回显为绿色则,未变更,符合要求 黄色则改变 红色则报错 因为默认值为file,那么文件不存在,报错 改为touch则创建 将state改为directory变 ...
- 01_Django-介绍-项目结构-URL和视图函数
01_Django-介绍-项目结构-URL和视图函数 视频:https://www.bilibili.com/video/BV1vK4y1o7jH 博客:https://blog.csdn.net/c ...
- Vben Admin 源码学习:状态管理-角色权限
前言 本文将对 Vue-Vben-Admin 角色权限的状态管理进行源码解读,耐心读完,相信您一定会有所收获! 更多系列文章详见专栏 Vben Admin 项目分析&实践 . 本文涉及到角 ...
- 这份数据安全自查checklist请拿好,帮你补齐安全短板的妙招全在里面!
企业数据安全自查Checklist! 快来对照表单,看看你的数据安全及格了吗? 一.京东云安全Checklist建议 京东云安全拥有业界领先的安全研究团队,经过多年实践与经验积累,京东云已面向不同业务 ...
- KMP&Z函数详解
KMP 一些简单的定义: 真前缀:不是整个字符串的前缀 真后缀:不是整个字符串的后缀 当然不可能这么简单的,来个重要的定义 前缀函数: 给定一个长度为\(n\)的字符串\(s\),其 \(前缀函数\) ...
- 13. 第十二篇 二进制安装kubelet
文章转载自:https://mp.weixin.qq.com/s?__biz=MzI1MDgwNzQ1MQ==&mid=2247483842&idx=1&sn=1ef1cb06 ...
- Solutions:网站搜索 - Elastic Site Search
- Elasticsearch Dockerfile 例子
文章转载自:https://elasticstack.blog.csdn.net/article/details/111692444 前提条件 在继续执行本教程中概述的步骤之前,你需要具备一个关键的先 ...