论文笔记:Access Path Selection In A Relational Database Management System
论文笔记:Access Path Selection In A Relation Database Management System
这篇文章是 1979 年由 IBM 发表的。主要介绍了 System-R 系统的查询优化器设计。
二. Processing Of An SQL Statement
- parsing 将 SQL 转换成抽象语法树
- optimization 查询优化
- code generation 使用 code generator 一个表驱动程序,将 ASL 转成机器代码。
- execution 在执行的过程中,parse tree 被替换为可执行的机器代码以及相关的数据结构。
Optimizer 处理流程
- 处理代码块
- 处理每个代码块中的 From 语句
- 输出为执行计划
Code Generator 处理流程
将 ASL(Access Specification Language)语言转换为 machine language code
Execution 处理流程
将 parser tree 转换为机器码和相关的数据结构,生成的机器码可以立即执行,也可以存储到数据库中,稍后执行。当机器码最终执行时,通过 RSI 接口进行数据扫描,这些扫描是沿着 Optimizer 选择的访问路径进行的。
三. The Research Storage System (RSS)
存储子系统,负责关系的物理存储,访问路径,多用户的锁,日志和恢复系统。RSS 为上层提供了面向 tuple 的接口 RSI。
主要功能
- physical storage
- access paths on relations
- logging
- recovery
Physical Storage
- tuple 存储在 page(每个 page 4k byte)中,不能跨 page 存储 tuple,且 tuple 间没有间隔。
- page 通过 segment 进行组织。
- tuple 也不能跨 segment 进行存储。
- 每个 tuple 都有一个标识。
Two Type Of Scan
- segment scan
- index scan,index 由用户创建,存储于独立的 index page 中。
Access Times
在这节,反复出现了对于寻找一个 tuple 需要访问几次 page 的描述。这里进行总结。
对于 segment scan
所有的非空 page 都会访问到,并且每个 page 只会被访问一次。对于 index scan
index page 只会被访问一次,data page 可能会被访问多次。
Clustered Index
介绍了一下聚簇索引:

Sargable Predicate

(SARGS) Both index and segment scans may optionally take a set of predicates, called search arguments.
(Sargable) Search Argument Able.
通过 SARGS 可以减少 RSI 层的工作,在 RSS 层就把无用的 tuple 过滤掉了。
四. Cost For Single Relation Access Paths (important)
先介绍最简单的情况,对单表的查询,然后介绍了 2-ways jon 以及 n-ways joins,最后介绍嵌套查询。
使用如下公式计算计划的代价:

- PAGE FETCHES 反应了 I/O 情况。
- RSI CALLS 是可以通过 RSS 层预知的数量。大部分的 CPU 操作都集中在 RSS 层,所以 RSI CALLS 是一个度量 CPU 操作的很好指标。
- W 是一个可以调整的变量。用于调整 I/O 操作 和 CPU 操作之间的权重。
统计信息所涉及到的元数据如下所示:

随后介绍了一下统计信息是如何生成的。统计信息的生成需要使用独立的命令,并不在 INSERT,DELETE,UPDATE 过程中生成或更新。因为额外的操作会有锁瓶颈,动态化更新统计信息往往会导致修改表的操作变为序列化的操作。
使用这些统计信息,优化器为谓词列表中的每个布尔因子使用选择率 "F",该选择率大致对应到满足谓词的 tuple 的期望分数。Table1 给出了不同谓词的选择率。这里只显示部分,如下图所示:

ti 为第i个查询块中所涉及的表和其中所有谓词的选择率的基数
n 为查询中的所有子查询个数
Query Cardinality (QCARD) 查询的基数:QCARD = $ \prod_{i=1}^nti $
为单表选择最佳的访问路径,在所有可能的访问路径上,结合统计信息和上述公式中的谓词选择率。"interesting order" 是指 tuple 的顺序是由语句块中的group by 或者 order by 语句造成的。
对于单表,通过估计每个访问路径上的代价(顺序扫描 + 索引)可以找到代价最低的访问路径。在给 tuple 排序的过程中伴随着代价的预估。以 SALARY 上的 index 进行升序扫描数据,将会产生代价 C 和一组升序的 SALARY。为单表查找代价最低的访问路径,我们只需要检查有 "interesting order" 的最低代价的访问路径,和 "unordered" 的最低代价访问路径。"unordered" 并不意味着 tuple 没有顺序,而是指这个 order 没有 "interesting"。如果查询中没有 group by 或者 order by 语句,就意味着没有 "interesting order"。那么就选择访问路径代价最低的那个。如果查询中有 group by 或者 order by,那么必须将(生成 "interesting order" 的代价),与(无序的最低访问路径代价 + QCARD 中排序为正确结果的成本)进行比较。选择最低代价作为查询块的计划。
对于单表的访问路径代价公式,由下图给出:

这些公式给出了index page获取 + data page获取 + factor * (RSI Calls) ?(这段不知道怎么理解)
W 是介于 page fetches 和 RSI calls 之间的权重因子。在某些情况下,根据检索的数据集是否完全在 RSS 缓冲池中(或者每个用户的缓冲池),给出了几个替代公式。对于 cluster index ,我们假设一个 page 在检索每个 tuple 的过程中一直驻留在缓冲区中。对于非 cluster index 假设对那些没进入缓冲区的关系,这个关系相对于缓冲区大小来说足够大,每个 tuple 的获取都需要进行 page fetch。
五. Access Path Selection For Joins
这部分先介绍了一下几个概念,outer releation,inner releation,以及 join columns。
Nested Loop Joins
不详细介绍了
Merge Scan Joins
使用 mergin scans 的必要条件:
- join 列有序。
- interesting order。
- 如果有多个 join 谓词,只使用其中一个,其他的当作普通谓词。
- 仅支持等值连接。
- 如果 join 列没有索引,必须先排序。
N-ways Joins
可以被视为多个 2-way joins 的序列,在做第二次 2-way join 时第一次的 2-way join 不必完成。只要我们得到了一个 join 后的 tuple 就可以进行 3-way join 去构造所需结果。在 n-ways joins 中只有需要有序的中间结果时才会进行物理存储。
不同的 join order 差别非常大。n 个表的 join 就有 $ n! $ 种 join 顺序。
用于减少搜索空间的启发式的方法有:
- 优先执行带有谓词的 join,使得没有谓词的执行的越晚越好。
- 寻找最优 join 顺序的时候,估计每个 join 子集的行数,并保存。除此之外无序的 join,截至到当前的 join 过程中或得的 "interesting order",代价最低的 join 方式和其代价,都需要被保存。
介绍 search tree 的构造方法:
- 一个动态规划算法,先找到访问单个关系的最小代价,然后找到两表 join 的最小代价的路径,然后第三个表和两表 join 的最小代价的结果进行 join ,找出最小代价的路径(这个过程中是需要考虑 "interesting order")。(使用启发式算法进行路径搜索,在此基础上选择最小的代价的路径。)
Computation Of Costs
对每个 join 关系,都会保存(Cost + Cardinality + Interesting Order)即 join 代价,结果行数,"interesting order" 的组合。
Example Of Tree
单表
现有如下表:

共三个表 EMP,DEPT,JOB。一个查询,这个查询是需要将这个三个表进行 Join 操作。
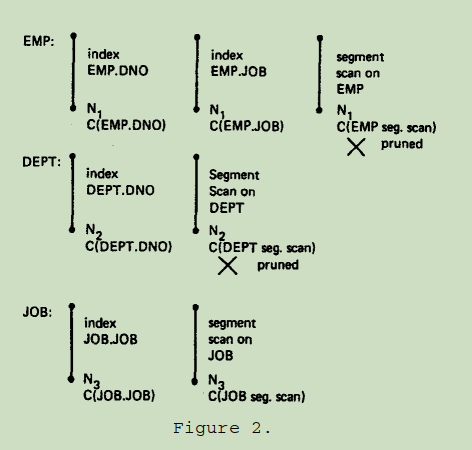
对于 EMP 表,DNO 上有索引,JOB 上有索引,DNO, JOB 有 "interesting order"。假设使用 JOB 上的索引扫描 EMP 表有最低的代价。因此 segment scan 被排除。
对于 DEPT 表,可以使用 DNO 索引,和 segment scan。假设使用 DNO 上的索引代价更低。因此 segment scan 被排除。
对于 JOB 表,使用 JOB 上的索引,和 segment scan。假设使用 segment scan 代价更低,因此两条路径都被保留。
上述所剩余路径构造的搜索树如下图所示:
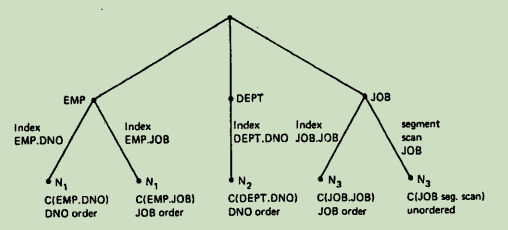
C(EMP.DNO) 指的是 EMP 通过 DNO 进行索引扫描,以及其上所有谓词
应用于所读取上来的 tuple 所需的代价。
两个表
当对第二个表进行 join 时,通过谓词与第一个表进行生成新的访问路径。如下图,使用 nest-loop join 所构造的 search tree:
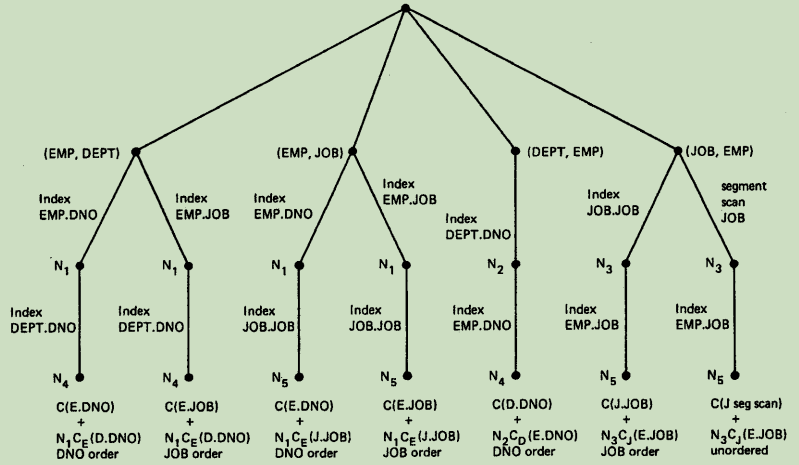
(Ni 指的是不同结果的基数)
如图所示,假设表 EMP 和 JOB 进行 join 操作使用JOB 上的索引扫描数据,代价最低,实际上可用通个前面所述的公式计算。
表 EMP 与 DEPT 表进行 Join,假设 DNO index 扫描数据代价是最低的。
使用 merged join 所构造的搜索树:
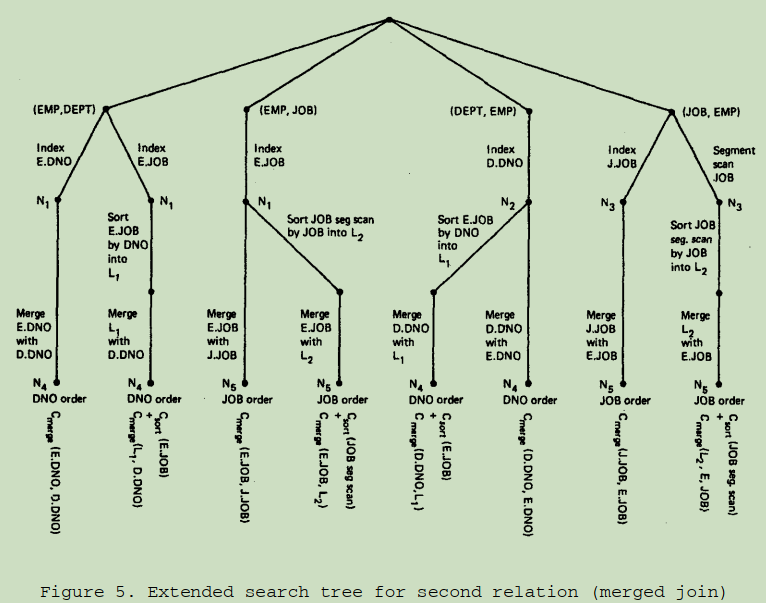
正如单表扫遍所展示的搜索树,有一个按照 DNO order 的方式扫描 EMP 表,和 DEPT 表上的 DNO 进行 merging scan join,在这个过程中不用进行任何的排序操作。或许也通过 JOB 对 EMP 表进行排序,然后进行 merging scan join 会代价更低。
三个表
在得到 nest loop join 两个表的搜索树和 merged join 的两个表的搜索树后,保存每个路径上的最低代价。经过这次剪枝,得到三个表 join 的搜索树如下图所示:
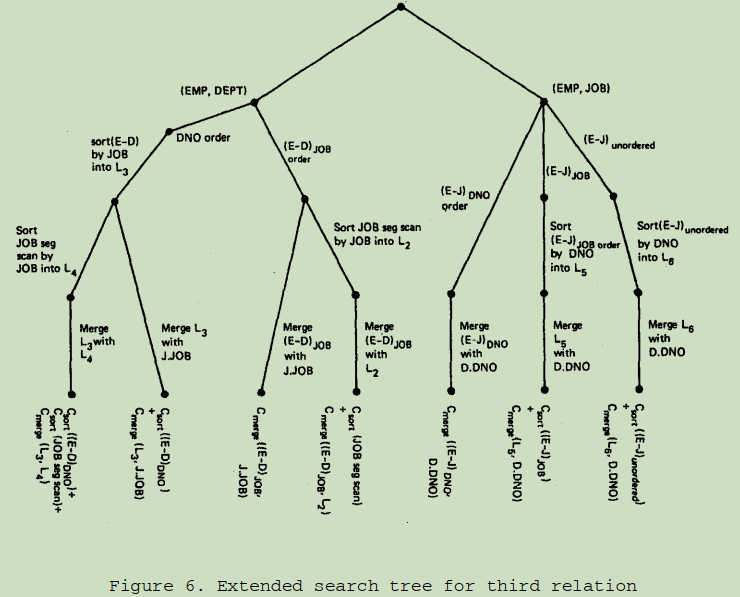
经过两表 join 后,将其结果与剩余的那个表进行 Join。通过 nest loop join 进行前两个表的 join,第三个表使用 merge scan join。
notes:
- 所有的 JOB 列的表都是排好序的
- join 过程中没有排序操作进行
- 每次会物化一个 tuple 的中间结果,物化的表不会进行存储
- 每次都会和最低的代价做比较
六. Nested Queries
介绍如何处理嵌套查询。
对于如下几个运算符 (=, -=, >, >=, <, <=),子查询的返回结果必须是一个值。如下图所示:
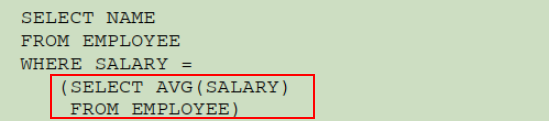
图中子查询是一个 avg 函数的返回结果。
如果子查询的结果只需要被计算一次,那么优化器就会在使用这个子查询结果之前将它的结果计算出来,然后将这个结果从原查询中替换掉。
对于非相关子查询中的谓词,嵌套最深的谓词会最先进行计算。
相关子查询的处理,对于相关子查询,外部查询的每个 tuple 都会使得引用这个 tuple 的子查询执行一次。如果引用列有序且重复元素多,就可以减少子查询的执行次数。判断引用列是不是每个值都不同,如果表的基数 > 索引的基数,说明列中存在重复值。
七. Conclusion
System R 系统的路径选择通过使用单表查询,Join 操作,以及嵌套查询来描述。如何在执行过程中做出正确的选择,将在即将发表的论文中做进一步描述。初步的结果表明,虽然优化器的代价预测的精确度不如绝对值--在大量路径下的真正最优路径。在许多情况下,所考虑的所有路径的估计成本之间的顺序与实际测量成本之间的顺序完全相同。
更进一步的,路径选择的压力不应该过大。对于 2-way join,查询优化的代价大概 5-20 次数据库检索,这个数字甚至可能更大,当选择器被放到 System R 的应用程序被编译一次,运行多次的环境中,优化的成本被摊分到多次运行中。
这种路径选择,对比于这个领域中的其他工作,关键之处在于使用统计信息,引入 CPU 的利用到代价计算公式和决定 join 顺序的方法。很多查询是和 CPU 密切相关的,特别是在 merge-sort 的过程中临时表的创建和排序。选择率的概念允许优化器尽可能的利用查询的限制性谓词,作用在 RSS 搜索参数和搜索路径中。记住 "interesting ordering" 等价类规范对于 join 和 order 或者 group。本文的优化器会比大多数的路径选择器记录更多,但是这些额外的工作可以避免存储和排序中间结果。tree pruning 和 tree searching 技术允许额外的记录操作能被高效的执行。验证优化器的代价公式的有更多的工作需要去做,但是我们可以从这些初步的工作中肯定,数据库系统能够支持非过程的查询语言,与当前的支持更多过程式的语言的有相同的性能。
词汇
disjunctive normal form (DNF) 析取范式
任何命题公式,最终都能够化成 \((A1 \wedge A2)\vee(A3 \wedge A4)\)
的形式,这种先\(\wedge\)合取,再\(\vee\)析取的范式,称为析取范式。
conjunctive normal form (CNF) 合取范式
任何命题公式,最终都能够化成 \((A1 \vee A2)\wedge(A3 \vee A4)\)
的形式,这种先\(\vee\)析取,再\(\wedge\)合取的范式,称为合取范式。
cardinality 基数 数据库中某个表的某个列中不重复的行的总个数。
selectivity 选择率 谓词的过滤条件返回的结果的行数占未加谓词过滤条件的行数。
when possible 在可能的情况下
thus far 迄今;现在为止
if any 若有的话;即便要
forthcoming 即将发生(或出版等)的
preliminary 预备性的;初步的;开始的
permits 允许;准许
clues 线索,迹象
furnishes 在(房屋等)处布置家具
Reference
- 原文链接
- https://blog.csdn.net/weixin_43919570/article/details/122501131
- https://zhuanlan.zhihu.com/p/590776990
论文笔记:Access Path Selection In A Relational Database Management System的更多相关文章
- 论文笔记 - RETRIEVE: Coreset Selection for Efficient and Robust Semi-Supervised Learning
Motivation 虽然半监督学习减少了大量数据标注的成本,但是对计算资源的要求依然很高(无论是在训练中还是超参搜索过程中),因此提出想法:由于计算量主要集中在大量未标注的数据上,能否从未标注的数据 ...
- 【论文笔记】Malware Detection with Deep Neural Network Using Process Behavior
[论文笔记]Malware Detection with Deep Neural Network Using Process Behavior 论文基本信息 会议: IEEE(2016 IEEE 40 ...
- 论文笔记系列-Neural Network Search :A Survey
论文笔记系列-Neural Network Search :A Survey 论文 笔记 NAS automl survey review reinforcement learning Bayesia ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- 论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN
论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN ICCV 2017 Paper: http://op ...
- 论文笔记:Mastering the game of Go with deep neural networks and tree search
Mastering the game of Go with deep neural networks and tree search Nature 2015 这是本人论文笔记系列第二篇 Nature ...
- 论文笔记:CNN经典结构2(WideResNet,FractalNet,DenseNet,ResNeXt,DPN,SENet)
前言 在论文笔记:CNN经典结构1中主要讲了2012-2015年的一些经典CNN结构.本文主要讲解2016-2017年的一些经典CNN结构. CIFAR和SVHN上,DenseNet-BC优于ResN ...
- Self-paced Clustering Ensemble自步聚类集成论文笔记
Self-paced Clustering Ensemble自步聚类集成论文笔记 2019-06-23 22:20:40 zpainter 阅读数 174 收藏 更多 分类专栏: 论文 版权声明 ...
- 【论文笔记系列】AutoML:A Survey of State-of-the-art (下)
[论文笔记系列]AutoML:A Survey of State-of-the-art (上) 上一篇文章介绍了Data preparation,Feature Engineering,Model S ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
随机推荐
- pat乙级1014 福尔摩斯的约会
#include<stdio.h> #include<stdlib.h> #include<string.h> #include<math.h> int ...
- Reverse for 'blog_detail.html' not found.解决方法
初学django遇到了以下问题: 查找解决方法的时候发现有以下几个原因: 1.字母打错 2.多加了空格 随后 我发现 报错的代码中多加了'.html'..删掉后就没问题了.
- replace 常用积累
1.替换有,或者.为: obj.keyword.replace(/,|./g,';') 2.替换元素标签类似于<em>文字</em>这种 let name=item.name. ...
- 免费语音转文字----使用Adobe Premiere Pro
软件版本:Adobe Premiere Pro 2023 打开Adobe Premiere Pro,新建项目: 将要转为文字的录音拖入轨道: 序列→自动转录序列: 选择想要的设置,转录 ...
- lombok.config
# 声明该配置文件是一个根配置文件,从该配置文件所在的目录开始扫描 config.stopBubbling=true # 全局配置 equalsAndHashCode 的 callSuper 属性为t ...
- vue 3.0 总线程bus引入(mitt)
vue 3.0 移除了 $on,$off 和 $once 方法,$emit 仍然是现有 API 的一部分,因为它用于触发由父组件以声明方式附加的事件处理程序. 官方推荐使用第三方类库. mitt举例 ...
- 关于sqlsugar二级缓存
二级缓存 1.优点 (1).维护方便:SqlSugar的 二级缓存 支持单表和多表的 CRUD 自动缓存更新 ,减少了复杂的缓存KEY维护操作 (2).使用方便:可以直接在Queryable.With ...
- Linux安装jdk之openjdk
使用yum源 1.查看yum库中都有哪些jdk版本 yum search java|grep jdk 2.选择指定的版本安装,注意最后的 * 以及yum源安装的是openjdk,注意openjdk的区 ...
- Vue-cli JSX踩坑问题!
今天封装一个公用组件库,期间使用到了JSX,发现在Data配置中去配置渲染函数出现了 h function is not defined的问题?? 网上查询一大堆所谓安装JSX的东西,其实Vue-cl ...
- [人脸识别]01-python环境准备-安装opencv
安装opencv pip install opencv-python pip install matplotlib pip install opencv-contrib-python --user