通过实例程序验证与优化谈谈网上很多对于Java DCL的一些误解以及为何要理解Java内存模型
个人创作公约:本人声明创作的所有文章皆为自己原创,如果有参考任何文章的地方,会标注出来,如果有疏漏,欢迎大家批判。如果大家发现网上有抄袭本文章的,欢迎举报,并且积极向这个 github 仓库 提交 issue,谢谢支持~
本文基于 OpenJDK 11 以上的版本
最近爆肝了这系列文章 全网最硬核 Java 新内存模型解析与实验,从底层硬件,往上全面解析了 Java 内存模型设计,并给每个结论都配有了相关的参考的论文以及验证程序,我发现多年来对于 Java 内存模型有很多误解,并且我发现很多很多人都存在这样的误解,所以这次通过不断优化一个经典的 DCL (Double Check Locking)程序实例来帮助大家消除这个误解。
首先有这样一个程序, 我们想实现一个单例值,只有第一次调用的时候初始化,并且有多线程会访问这个单例值,那么我们会有:

getValue 的实现就是经典的 DCL 写法。
在 Java 内存模型的限制下,这个 ValueHolder 有两个潜在的问题:
- 如果根据 Java 内存模型的定义,不考虑实际 JVM 的实现,那么 getValue 是有可能返回 null 的。
- 可能读取到没有初始化完成的 Value 的字段值。
下面我们就这两个问题进行进一步分析并优化。
根据 Java 内存模型的定义,不考虑实际 JVM 的实现,getValue 有可能返回 null 的原因
在 全网最硬核 Java 新内存模型解析与实验 文章的7.1. Coherence(相干性,连贯性)与 Opaque中我们提到过:假设某个对象字段 int x 初始为 0,一个线程执行:

另一个线程执行(r1, r2 为本地变量):

那么这个实际上是两次对于字段的读取(对应字节码 getfield),在 Java 内存模型下,可能的结果是包括:
r1 = 1, r2 = 1r1 = 0, r2 = 1r1 = 1, r2 = 0r1 = 0, r2 = 0
其中第三个结果很有意思,从程序上理解即我们先看到了 x = 1,之后又看到了 x 变成了 0.实际上这是因为编译器乱序。如果我们不想看到这个第三种结果,我们所需要的特性即 coherence。这里由于private Value value是普通的字段,所以根据 Java 内存模型来看并不保证 coherence。
回到我们的程序,我们有三次对字段读取(对应字节码 getfield),分别位于:

由于 1,2 之间有明显的分支关系(2 根据 1 的结果而执行或者不执行),所以无论在什么编译器看来,都要先执行 1 然后执行 2。但是对于 1 和 3,他们之间并没有这种依赖关系,在一些简单的编译器看来,他们是可以乱序执行的。在 Java 内存模型下,也没有限制 1 与 3 之间是否必须不能乱序。所以,可能你的程序先执行 3 的读取,然后执行 1 的读取以及其他逻辑,最后方法返回 3 读取的结果。
但是,在 OpenJDK Hotspot 的相关编译器环境下,这个是被避免了的。OpenJDK Hotspot 编译器是比较严谨的编译器,它产生的 1 和 3 的两次读取(针对同一个字段的两次读取)也是两次互相依赖的读取,在编译器维度是不会有乱序的(注意这里说的是编译器维度哈,不是说这里会有内存屏障连可能的 CPU 乱序也避免了,不过这里针对同一个字段读取,前面已经说了仅和编译器乱序有关,和 CPU 乱序无关)
不过,这个仅仅是针对一般程序的写法,我们可以通过一些奇怪的写法骗过编译器,让他任务两次读取没有关系,例如在全网最硬核 Java 新内存模型解析与实验 文章的7.1. Coherence(相干性,连贯性)与 Opaque中的实验环节,OpenJDK Hotspot 对于下面的程序是没有编译器乱序的:

但是如果你换成下面这种写法,就骗过了编译器:
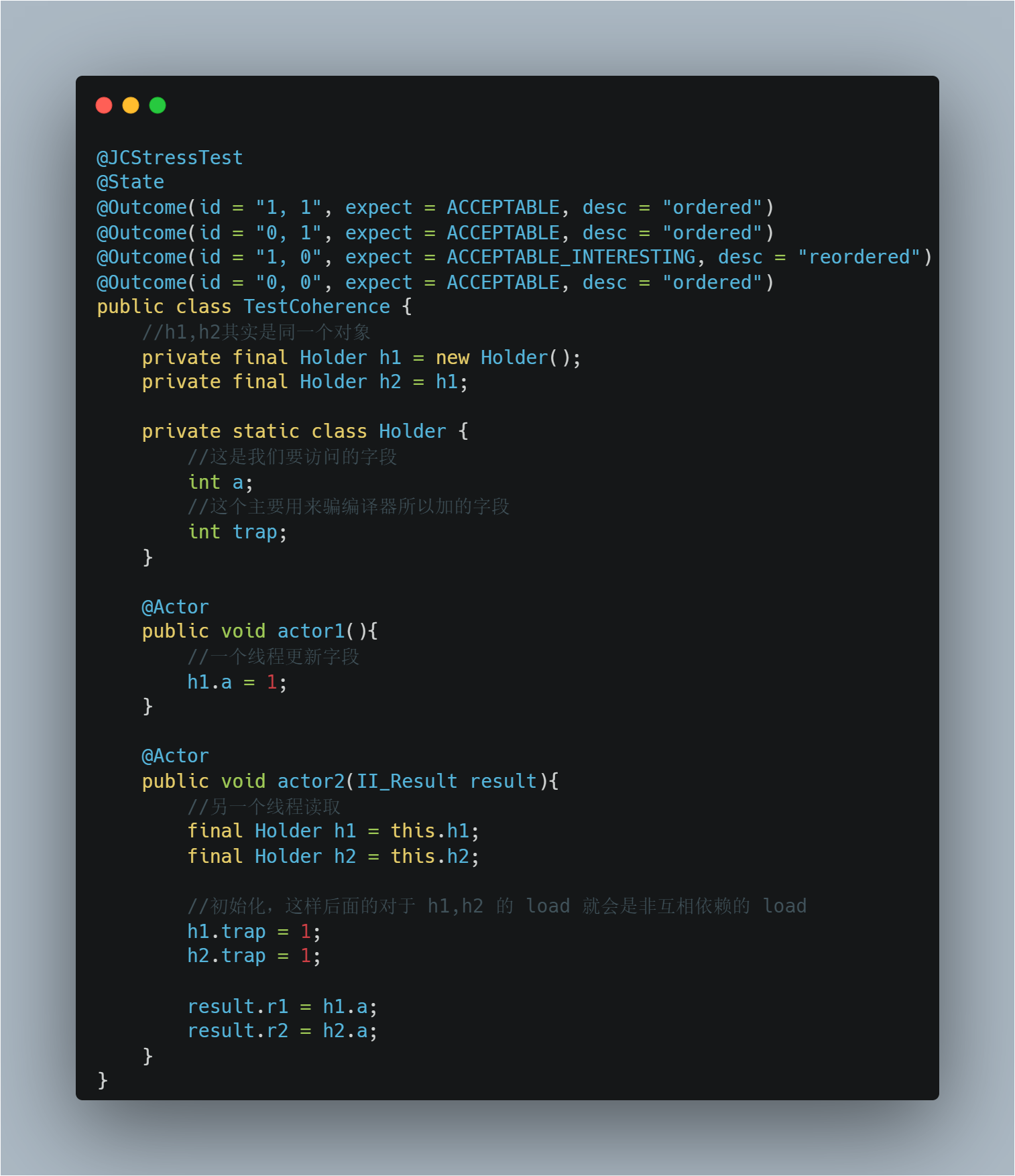
我们不用太深究其原理,直接看其中一个结果:

对于 DCL 这种写法,我们也是可以骗过编译器的,但是一般我们不会这么写,这里就不赘述了。
可能读取到没有初始化完成的 Value 的字段值
这个就不只是编译器乱序了,还涉及了 CPU 指令乱序以及 CPU 缓存乱序,需要内存屏障解决可见性问题。
我们从 Value 类的构造器入手:

对于 value = new Value(10); 这一步,将代码分解为更详细易于理解的伪代码则是:
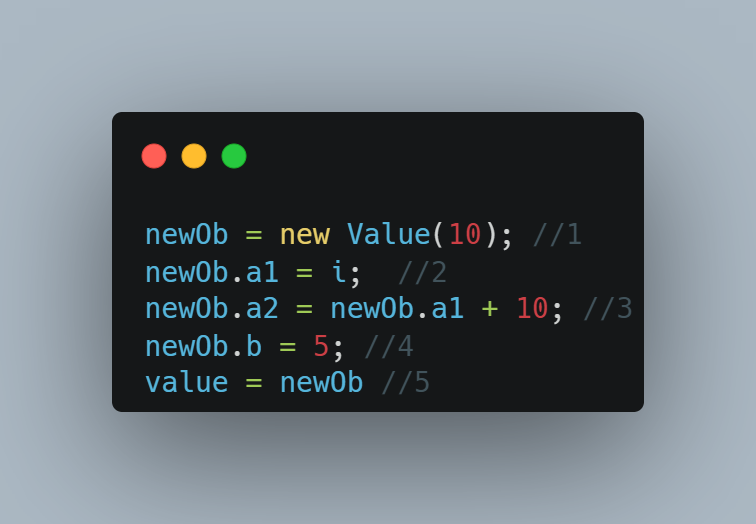
这中间没有任何内存屏障,根据语义分析,1 与 5 之间有依赖关系,因为 5 依赖于 1 的结果,必须先执行 1 再执行 5。 2 与 3 之间也是有依赖关系的,因为 3 依赖 2 的结果。但是,2和3,与 4,以及 5 这三个之间没有依赖关系,是可以乱序的。我们使用使用代码测试下这个乱序:

虽然在注释中写出了这么编写代码的原因,但是这里还是想强调下这么写的原因:
- jcstress 的 @Actor 是使用一个线程执行这个方法中的代码,在测试中,每次会用不同的 JVM 启动参数让这段代码解释执行,C1编译执行,C2编译执行,同时对于 JIT 编译还会修改编译参数让它的编译代码效果不一样。这样我们就可以看到在不同的执行方式下是否会有不同的编译器乱序效果。
- jcstress 的 @Actor 是使用一个线程执行这个方法中的代码,在每次使用不同的 JVM 测试启动时,会将这个 @Actor 绑定到一个 CPU 执行,这样保证在测试的过程中,这个方法只会在这个 CPU 上执行, CPU 缓存由这个方法的代码独占,这样才能更容易的测试出 CPU 缓存不一致导致的乱序。所以,我们的 @Actor 注解方法的数量需要小于 CPU 个数。
- 我们测试机这里只有两个 CPU,那么只能有两个线程,如果都执行原始代码的话,那么很可能都执行到 synchronized 同步块等待,synchronized 本身有内存屏障的作用(后面会提到)。为了更容易测试出没有走 synchronized 同步块的情况,我们第二个 @Actor 注解的方法直接去掉同步块逻辑,并且如果 value 为 null,我们就设置结果都是 -1 用来区分
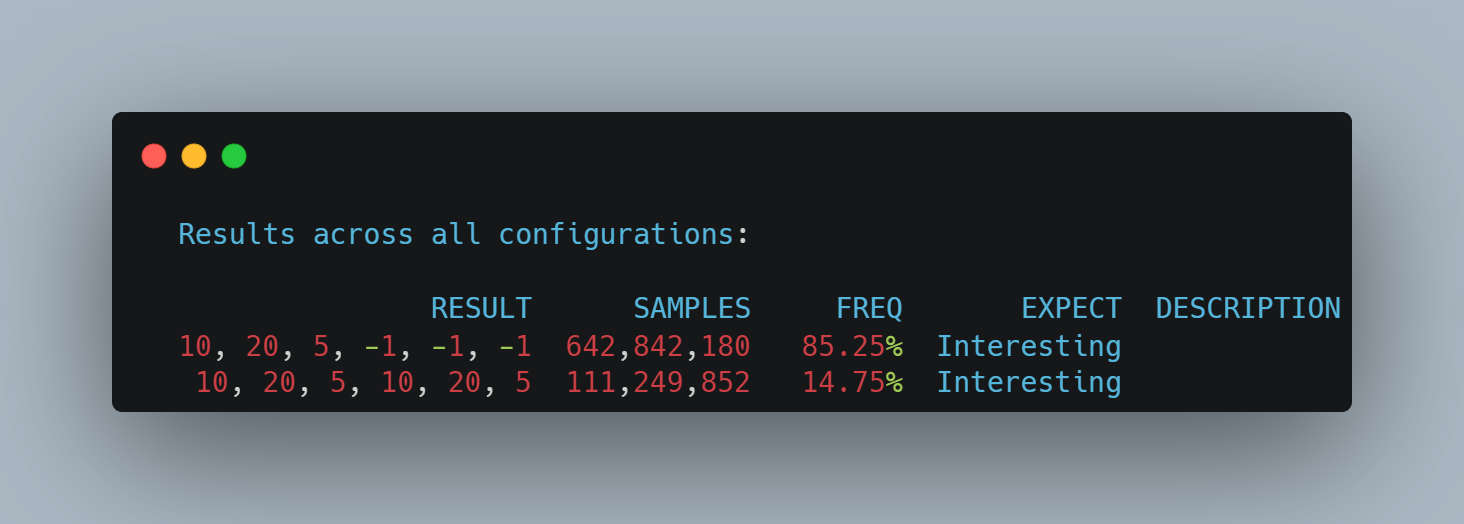
我分别在 x86 和 arm CPU 上测试了这个程序,结果分别是:
x86 - AMD64:
arm - aarch64:
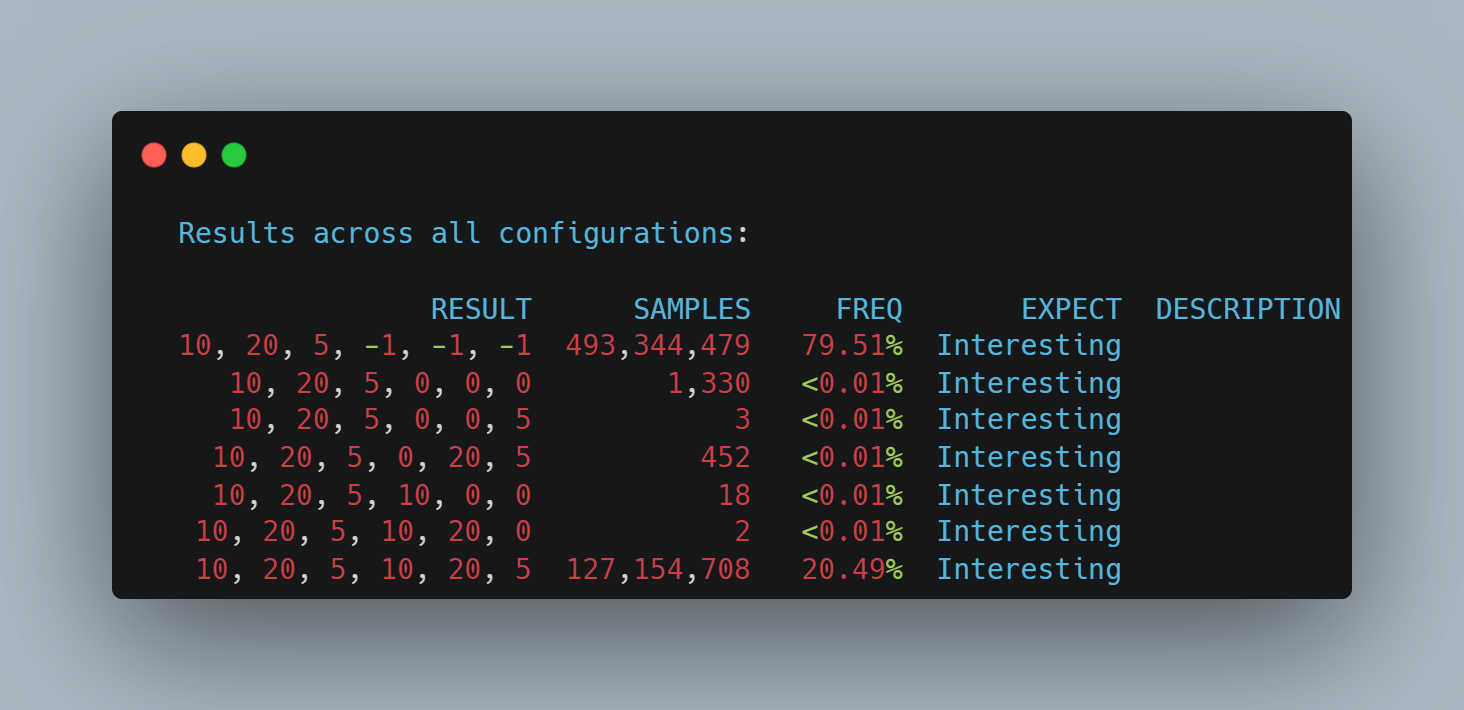
我们可以看到,在比较强一致性的 CPU 如 x86 中,是没有看到未初始化的字段值的,但是在 arm 这种弱一致性的 CPU 上面,我们就看到了未初始化的值。在我的另一个系列 - 全网最硬核 Java 新内存模型解析与实验中,我们也多次提到了这个 CPU 乱序表格:
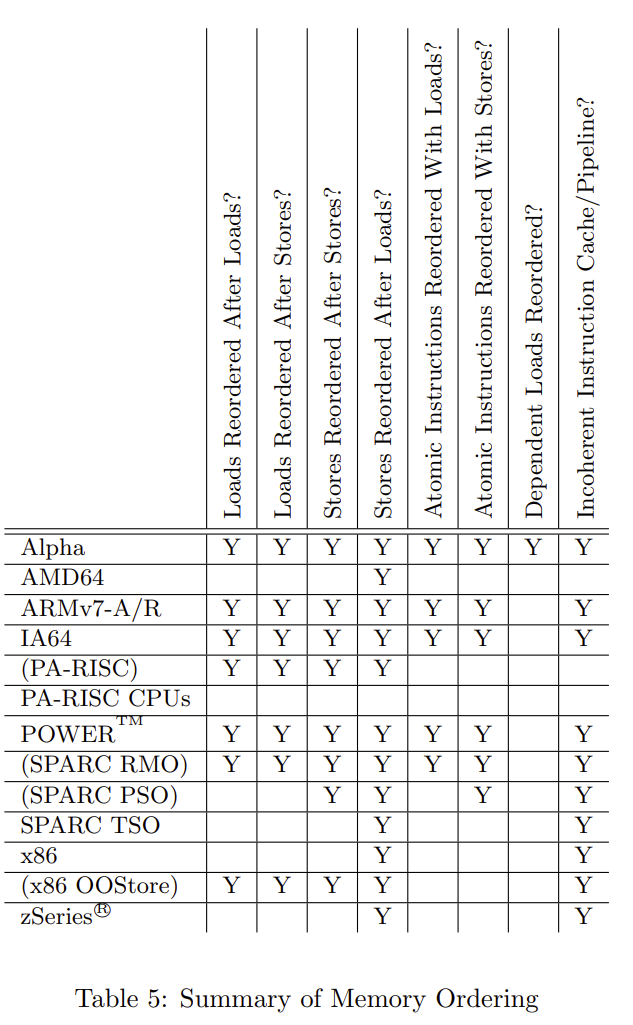
在这里,我们需要的内存屏障是 StoreStore(同时我们也从上面的表格看出,x86 天生不需要 StoreStore,只要没有编译器乱序的话,CPU 层面是不会乱序的,而 arm 需要内存屏障保证 Store 与 Store 不会乱序),只要这个内存屏障保证我们前面伪代码中第 2,3 步在第 5 步前,第 4 步在第 5 步之前即可,那么我们可以怎么做呢?参考我的那篇全网最硬核 Java 新内存模型解析与实验中各种内存屏障对应关系,我们可以有如下做法,每种做法我们都会对比其内存屏障消耗:
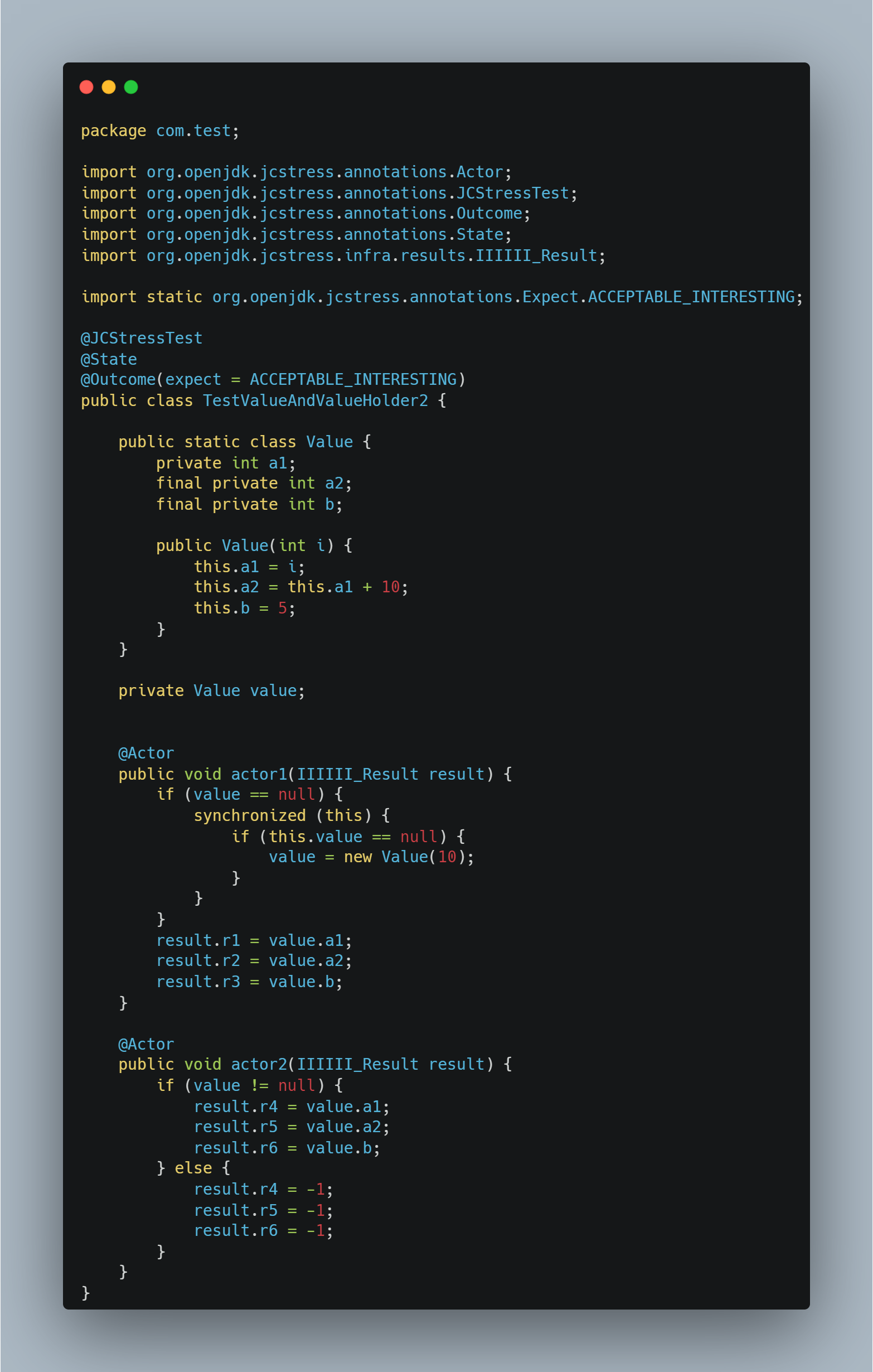
1.使用 final
final 是在赋值语句末尾添加 StoreStore 内存屏障,所以我们只需要在第 2,3 步以及第 4 步末尾添加 StoreStore 内存屏障即把 a2 和 b 设置成 final 即可,如下所示:

对应伪代码:

我们测试下:
这次在 arm 上的结果是:
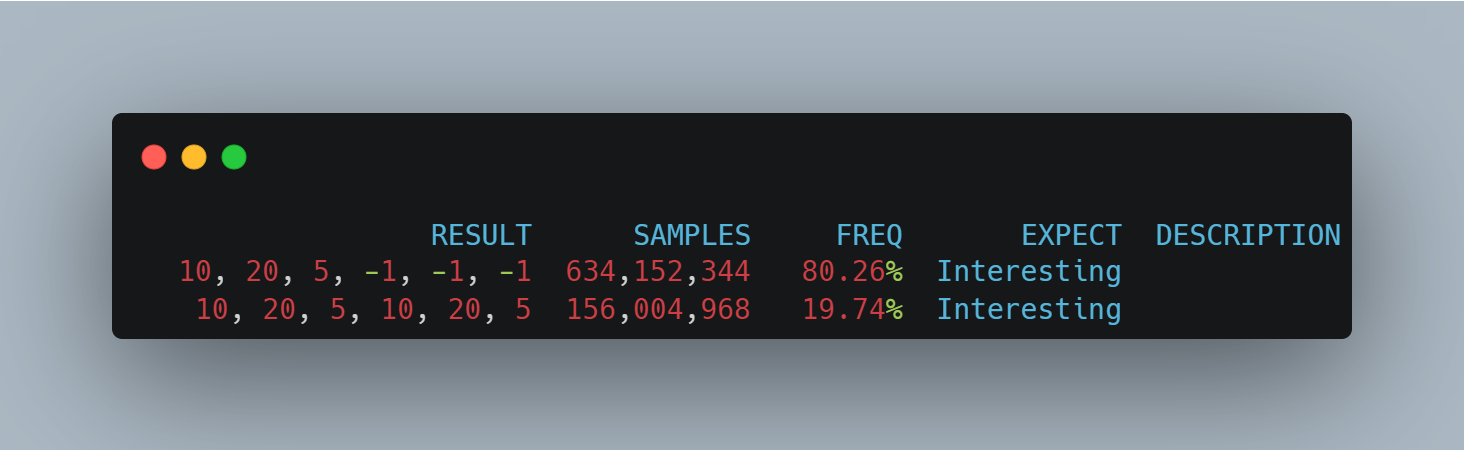
如你所见,这次 arm CPU 上也没有看到未初始化的值了。
这里 a1 不需要设置成 final,因为前面我们说过,2 与 3 之间是有依赖的,可以把他们看成一个整体,只需要整体后面添加好内存屏障即可。但是这个并不可靠!!!!因为在某些 JDK 中可能会把这个代码:

优化成这样:

这样 a1, a2 之间就没有依赖了!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!所以最好还是所有的变量都设置为 final
但是,这在我们不能将字段设置为 final 的时候,就不好使了。
2. 使用 volatile,这是大家常用以及官方推荐的做法
将 value 设置为 volatile 的,在我的另一系列文章 全网最硬核 Java 新内存模型解析与实验中,我们知道对于 volatile 写入,我们通过在写入之前加入 LoadStore + StoreStore 内存屏障,在写入之后加入 StoreLoad 内存屏障实现的,如果把 value 设置为 volatile 的,那么前面的伪代码就变成了:
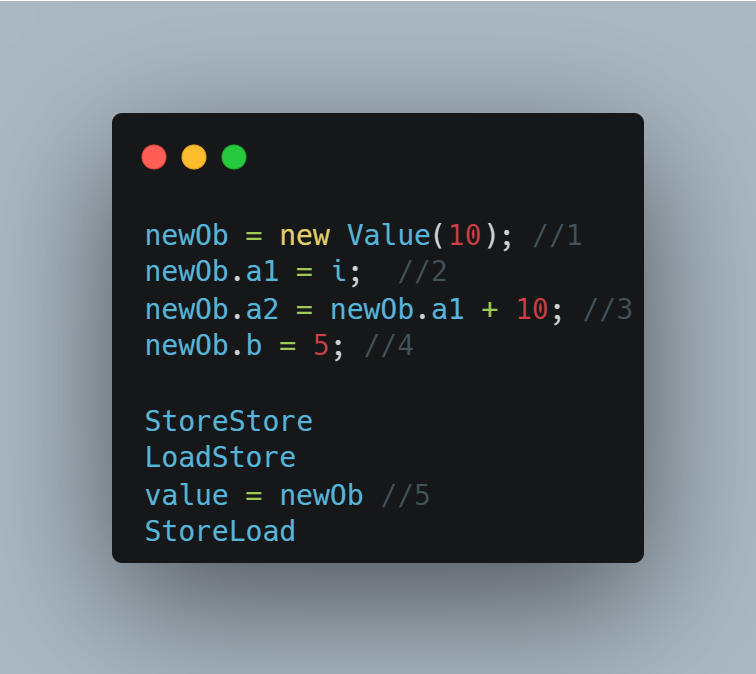
我们通过下面的代码测试下:
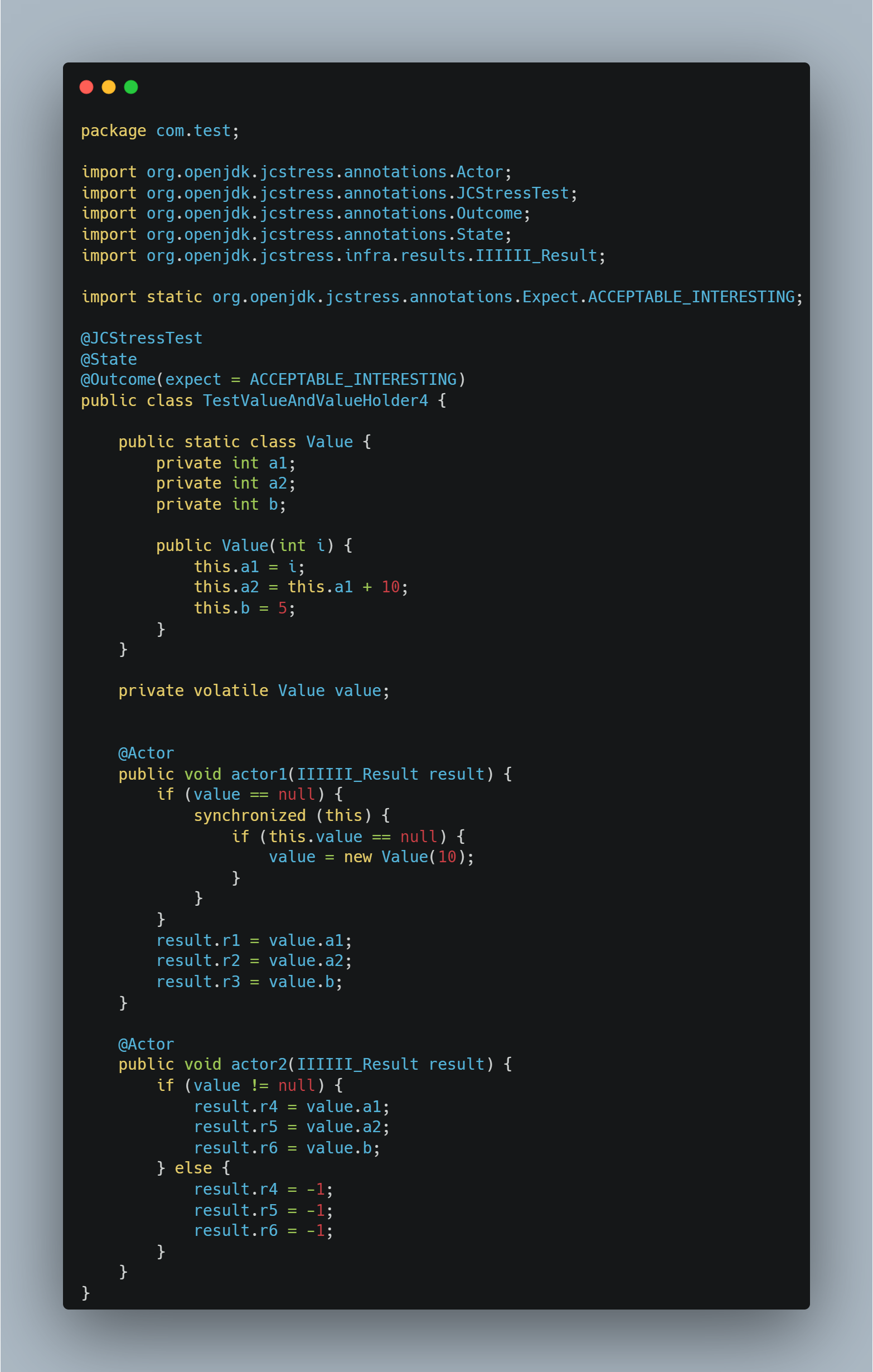
依旧在 arm 机器上面测试,结果是:
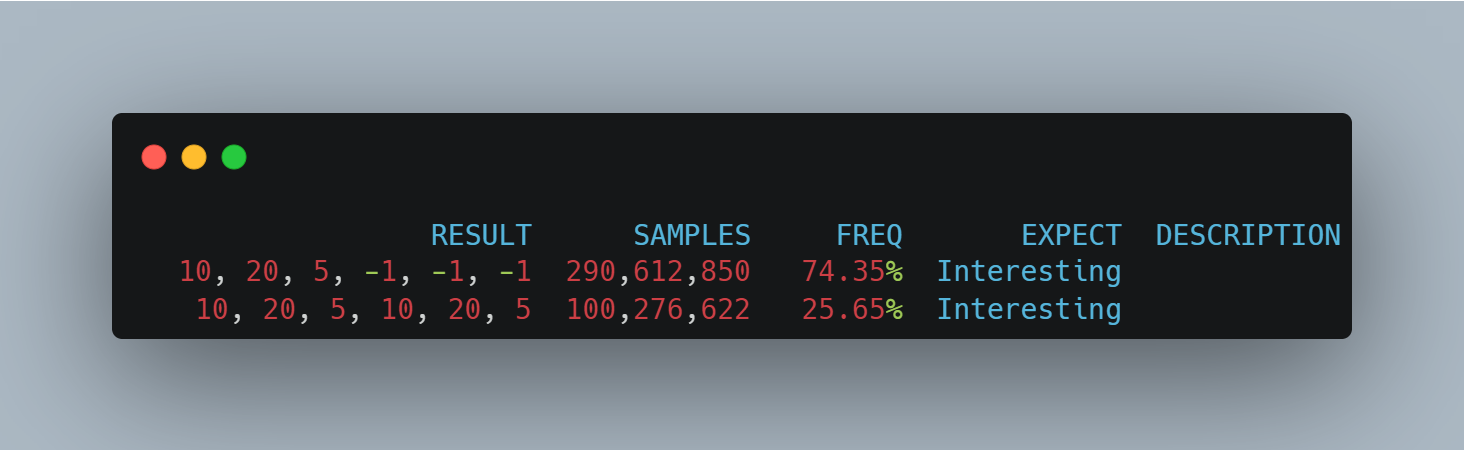
没有看到未初始化值了
3. 对于 Java 9+ 可以使用 Varhandle 的 acquire/release
前面分析,我们其实只需要保证在伪代码第五步之前保证有 StoreStore 内存屏障即可,所以 volatile 其实有点重,我们可以通过使用 Varhandle 的 acquire/release 这一级别的可见性 api 实现,这样伪代码就变成了:

我们的测试代码变成了:
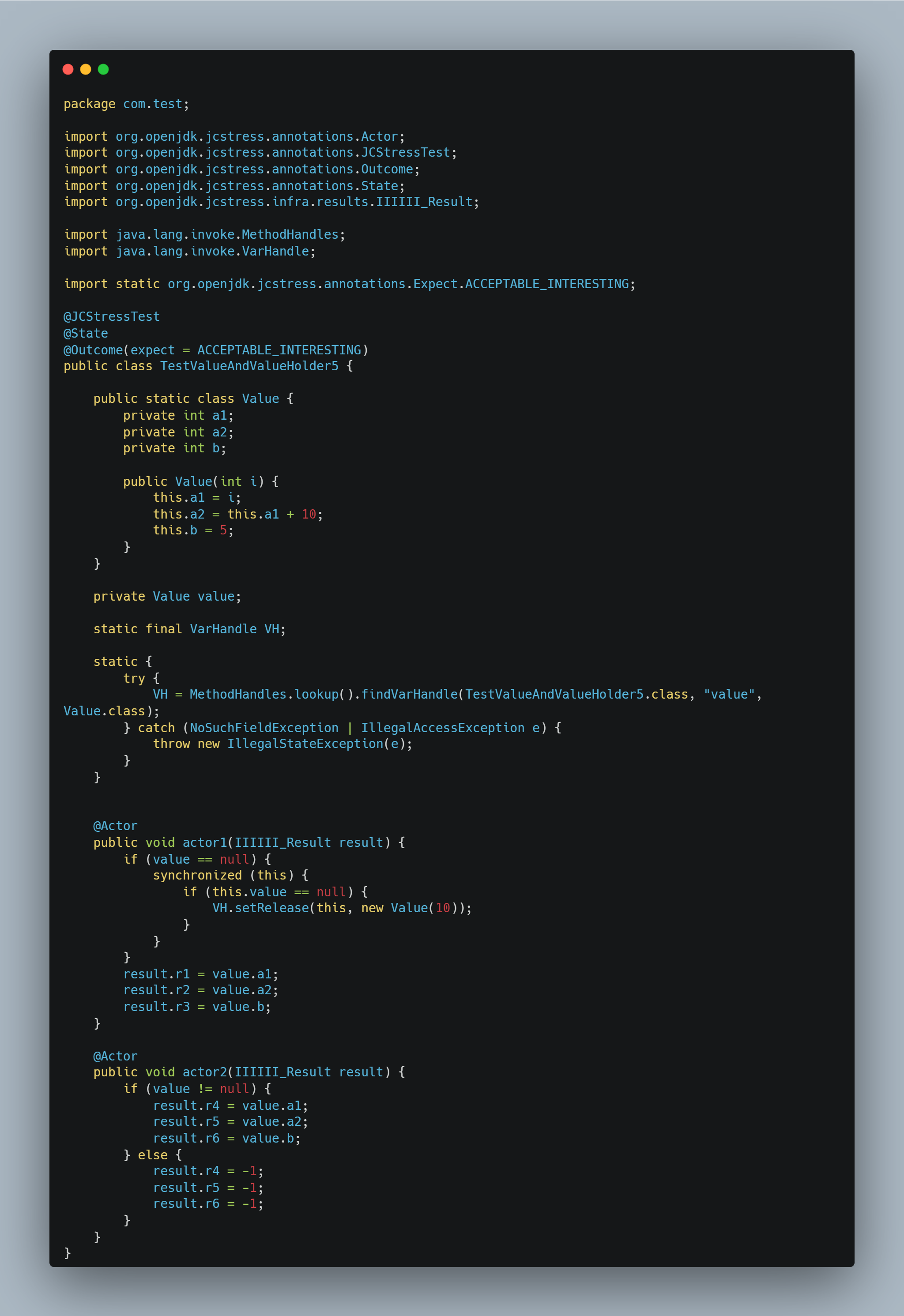
测试结果是:
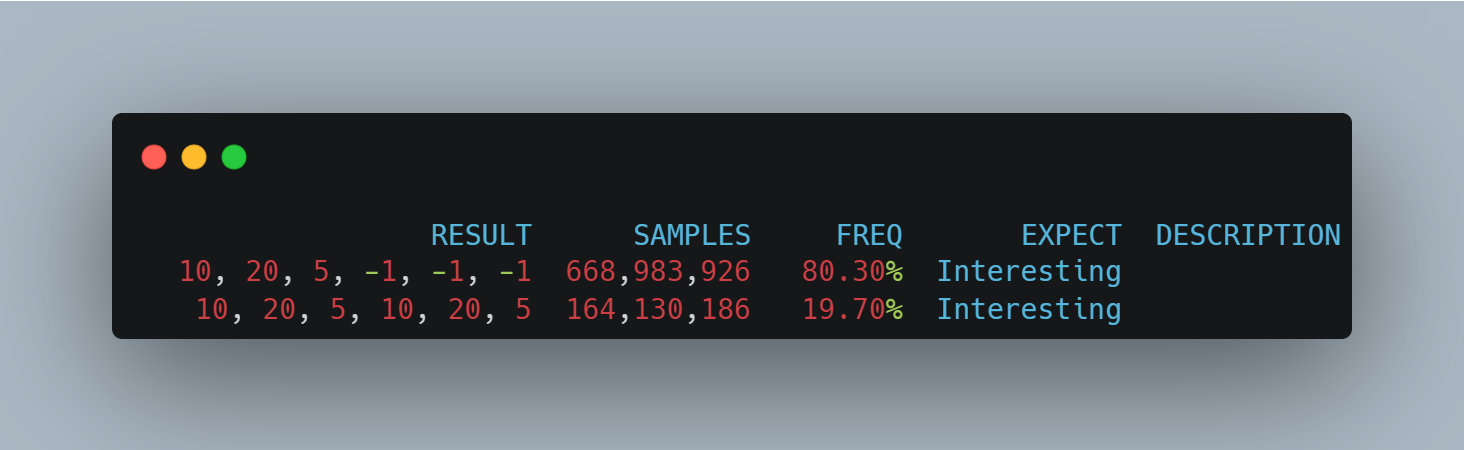
也是没有看到未初始化值了。这种方式是用内存屏障最少,同时不用限制目标类型里面不必使用 final 字段的方式。
4. 一种有趣但是没啥用的思路 - 如果是静态方法,可以通过类加载器机制实现很简便的写法
如果我们,ValueHolder 里面的方法以及字段可以是 static 的,例如:

将 ValueHolder 作为一个单独的类,或者一个内部类,这样也是能保证 Value 里面字段的可见性的,这是通过类加载器机制实现的,在加载同一个类的时候(类加载的过程中会初始化 static 字段并且运行 static 块代码),是通过 synchronized 关键字同步块保护的,参考其中类加载器(ClassLoader.java)的源码:
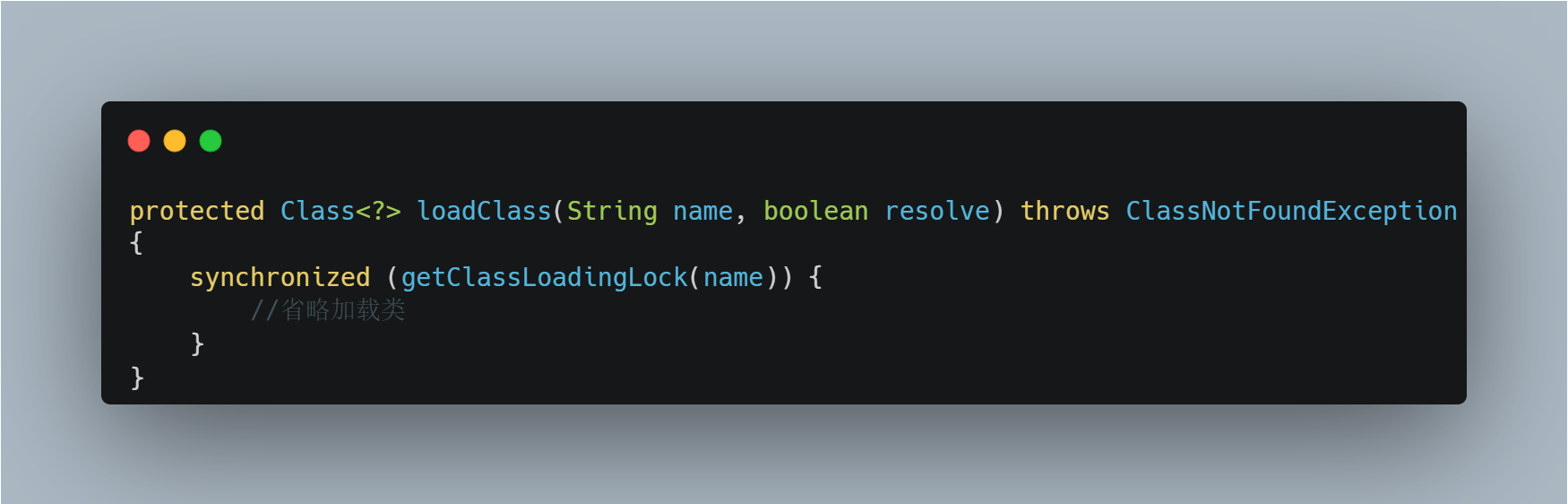
对于 syncrhonized 底层对应的 monitorenter 和 monitorexit,monitorenter 与 volatile 读有一样的内存屏障,即在操作之后加入 LoadLoad 和 LoadStore,monitorexit 与 volatile 写有一样的内存屏障,在操作之前加入 LoadStore + StoreStore 内存屏障,在操作之后加入 StoreLoad 内存屏障。所以,也是能保证可见性的。但是这样虽然写起来貌似很简便,效率上更加低(低了很多,类加载需要更多事情)并且不够灵活,只是作为一种扩展知识知道就好。
总结
- DCL 是一种常见的编程模式,对于锁保护的字段 value 会有两种字段可见性问题:
- 如果根据 Java 内存模型的定义,不考虑实际 JVM 的实现,那么 getValue 是有可能返回 null 的。但是这个一般都被现在 JVM 设计避免了,这一点我们在实际编程的时候可以不考虑。
- 可能读取到没有初始化完成的 Value 的字段值,这个可以通过在构造器完成与赋值给变量之间添加 StoreStore 内存屏障解决。可以通过将 Value 的字段设置为 final 解决,但是不够灵活。
- 最简单的方式是将 value 字段设置为 volatile 的,这也是 JDK 中使用的方式,官方也推荐这种。
- 效率最高的方式是使用 VarHandle 的 release 模式,这个模式只会引入 StoreStore 与 LoadStore 内存屏障,相对于 volatile 写的内存屏障要少很多(少了 StoreLoad,对于 x86 相当于没有内存屏障,因为 x86 天然有 LoadLoad,LoadStore,StoreStore,x86 仅仅不能天然保证 StoreLoad)
微信搜索“我的编程喵”关注公众号,加作者微信,每日一刷,轻松提升技术,斩获各种offer:
我会经常发一些很好的各种框架的官方社区的新闻视频资料并加上个人翻译字幕到如下地址(也包括上面的公众号),欢迎关注:

通过实例程序验证与优化谈谈网上很多对于Java DCL的一些误解以及为何要理解Java内存模型的更多相关文章
- jvm-java内存模型与锁优化
java内存模型与锁优化 参考: https://blog.csdn.net/xiaoxiaoyusheng2012/article/details/53143355 https://blog.csd ...
- 三星I9308(移动版)正确Root的方法,进入正确的recovery的关键(网上很多方法是误导)
三星I9308(移动版)正确Root的方法,进入正确的recovery的关键(网上很多方法是误导) 1)首先在电脑上安装手机驱动:下载地址:点击这里下载 2)手机设置USB调试 方法1:设置- ...
- (OPC Client .NET 开发类库)网上很多网友都有提过,.NET开发OPC Client不外乎下面三种方法
1. 背景 OPC Data Access 规范是基于COM/DCOM定义的,因此大多数的OPC DA Server和client都是基于C++开发的,因为C++对COM/DCOM有最好的支持.现在, ...
- JVM内存模型和性能优化 转
JVM内存模型和性能优化 JVM内存模型优点 内置基于内存的并发模型: 多线程机制 同步锁Synchronization 大量线程安全型库包支持 基于内存的并发机制,粒度灵活控制,灵活度高于 ...
- JVM内存模型和性能优化
JVM内存模型优点 内置基于内存的并发模型: 多线程机制 同步锁Synchronization 大量线程安全型库包支持 基于内存的并发机制,粒度灵活控制,灵活度高于数据库锁. 多核并行计算模 ...
- 《深入理解java虚拟机》学习笔记之编译优化技术
郑重声明:本片博客是学习<深入理解Java虚拟机>一书所记录的笔记,内容基本为书中知识. Java程序员有一个共识,以编译方式执行本地代码比解释方式更快,之所以有这样的共识,除去虚拟机解释 ...
- 《深入理解Java虚拟机》-----第13章 线程安全与锁优化
概述 在软件业发展的初期,程序编写都是以算法为核心的,程序员会把数据和过程分别作为独立的部分来考虑,数据代表问题空间中的客体,程序代码则用于处理这些数据,这种思维方式直接站在计算机的角度去抽象问题和解 ...
- Java内存模型及性能优化
最近在做一个项目的性能优化,遇到好多以前没有关注过的性能问题,一头雾水,今天做个笔记,简单记录下JVM相关的参数设置. 一.JVM内存模型 首先介绍下Java程序具体执行的过程: Java源代码文件( ...
- 《深入理解Java虚拟机》-----第10章 程序编译与代码优化-早期(编译期)优化
概述 Java语言的“编译期”其实是一段“不确定”的操作过程,因为它可能是指一个前端编译器(其实叫“编译器的前端”更准确一些)把*.java文件转变成*.class文件的过程;也可能是指虚拟机的后端运 ...
随机推荐
- eclipse新建maven项目:'Building' has encountered a problem. Errors occurred during the build.
二.eclipse 新建maven 项目报错(因为没有配置maven环境) 1.问题: ① 出现的问题1: Could not calculate build plan:Plugin org.apac ...
- IDEA导入第三方jar包
IDEA导入第三方jar包 在Module下新建一个Directory,命名为lib或者libs,然后直接将目标jar包文件复制到这个新建的Directory中. 右键选中导入的jar包,选择Add ...
- IDEA 配置Tomcat乱码解决方法
问题:页面没有乱码,但是通过http请求的js文件会乱码,原因是由于 CharacterEncodingFilter 只会处理Servlet请求,不会处理静态文件的响应编码,所以这里需要进一步的配置. ...
- 一个".java"源文件中是否可以包含多个类(不是内部类)?有什么限制?
可以,但一个源文件中最多只能有一个公开类(public class)而且文件名必须和公开类的类名完全保持一致.
- docker-compose安装和使用
安装:https://my.oschina.net/thinwonton/blog/2985886 docker-compose和Dockerfile结合使用,创建django项目和postgres数 ...
- 如何运行exe文件
有三种方式 第一种:找到所在文件双击运行. 第二种:在命令行里面运行所在文件夹的位置,在输入文件名. 第三种:加到环境变量里面执行
- piwik安装部署
1.piwik介绍 Piwik是一个PHP和MySQL的开放源代码的Web统计软件,它给你一些关于你的网站的实用统计报告,比如网页浏览人数,访问最多的页面,搜索引擎关键词等等. Piwik拥有众多不同 ...
- BMZCTF WEB_ezeval
WEB_ezeval 进入环境,源码给出 <?php highlight_file(__FILE__); $cmd=$_POST['cmd']; $cmd=htmlspecialchars($c ...
- pandas数据读取
02. Pandas读取数据 本代码演示: pandas读取纯文本文件 读取csv文件 读取txt文件 pandas读取xlsx格式excel文件 pandas读取mysql数据表 1.读取纯文本文件 ...
- Altium Designer PCB文件的绘制(下:PCB布线和检查)
在完成电路板的布局工作后,就可以开始布线操作了.在PCB的设计中,布线是完成产品设计的最重要的步骤,其要求最高.技术最细.工作量最大.PCB布线可分为单面布线.双面布线.多层布线.布线的方式有自动布线 ...