SQLAlchemy加载数据到数据库
SQLAlchemy加载数据到数据库
最近在研究基于知识图谱的问答系统,想要参考网上分享的关于NLPCC 2016 KBQA任务的经验帖,自己实现一个原型。不少博客都有提到,nlpcc-kbqa训练数据只提供了问题和答案,没有标注三元组,因此需要根据答案(尾实体)从知识图谱中反向查找头实体和关系,进而构建一条训练样例的(头实体,关系,尾实体)三元组标注。由于知识图谱规模比较大,三元组的数量超过了4000万条,直接根据文件进行查询不方便,因此考虑用数据库来管理这些三元组。本文记录了通过SQLAlchemy加载数据到MySQL数据库中的过程,主要内容包括建立数据连接、定义数据库表模式等。
连接数据库
其实加载数据(尤其是表格型数据)到数据库不一定需要自己写代码,一些工具比如SQL Server连接到平面数据源,或者Navicat的导入向导,完全能胜任这样的工作,但是观察到知识图谱存在比较多的噪声数据,想要在导入数据库前做一些预处理,所以才选用Python+SQLAlchemy的方式来实现导入数据到数据库的需求。
准备工作
# 安装SQLAlchemy和MySQL驱动
conda install sqlalchemy
conda install mysql-connector
# 导入需要用到的类或函数
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
建立数据库连接
# 注意指定字符集为`utf8mb4`
engine = create_engine('mysql+mysqlconnector://****:******@***.***.***.***:3306/kbqa?charset=utf8mb4', echo=False)
Base = declarative_base()
Session = sessionmaker(bind=engine)
session = Session()
定义数据库表模式
SQLALchemy提供了易用的ORM接口,可以把关系型数据库的表结构映射到对象上,同样我们可以通过定义Python的类来指定数据库的表模式。考虑到后面会有根据头实体、关系名、尾实体查询数据库的需求,为了提升查询效率,这里为这三个字段都设置了索引;类属性__table_args__可以指定编码、存储引擎等配置项。
定义表模式
Base = declarative_base() class KnowledgeTuple(Base):
"""定义知识库三元组的数据库模式"""
__tablename__ = 'knowledge_tuples'
__tableargs__ = {
'mysql_charset': 'utf8mb4'
} id = Column(Integer, primary_key=True, comment='三元组id')
entity = Column(String(250), nullable=False, index=True, comment='头实体')
attribute = Column(String(250), nullable=False, index=True, comment='关系')
value = Column(String(250), nullable=False, index=True, comment='尾实体')
数据库中的表
SHOW CREATE TABLE knowledge_tuples; CREATE TABLE `knowledge_tuples` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '三元组id',
`entity` varchar(250) NOT NULL COMMENT '头实体',
`attribute` varchar(250) NOT NULL COMMENT '关系',
`value` varchar(250) NOT NULL COMMENT '尾实体',
PRIMARY KEY (`id`),
KEY `ix_knowledge_tuples_entity` (`entity`),
KEY `ix_knowledge_tuples_attribute` (`attribute`),
KEY `ix_knowledge_tuples_value` (`value`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb
数据清洗
通过简单规则的方式统计,发现有超过10万条的三元组的关系名包含空格、特殊字符或引用(中括号夹一个数字),因此考虑在把数据加载到数据库前对数据进行清洗。
import re
BLANK_PATTERN = re.compile(r'\s')
REFERENCE_PATTERN = re.compile(r'\[[0-9]*\]')
def remove_special_characters(field: str) -> str:
"""过滤含特殊字符的前缀、后缀"""
return field.strip(' 。,、·•-:!!#$%&*+,-./:;=?@\\^_`|')
def remove_blank(field: str) -> str:
"""去掉空格"""
return BLANK_PATTERN.sub('', field)
def remove_reference(field: str) -> str:
"""去掉引用(中括号+数字)"""
return REFERENCE_PATTERN.sub('', field)
def is_illegal_relation(tpl: str) -> bool:
"""测试关系名长度是否过长以及关系名和尾实体是否相同"""
sub, relation, obj = tpl.split(' ||| ')
if len(relation) > 20 or (relation == obj):
return True
else: return False
加载数据到数据库
考虑到知识图谱的数据量比较大,只通过单个进程加载数据效率不高,这里populate_database函数接收一个范围(start到stop)作为参数,这样就可以对数据集进行分片,再创建多个进程,不同进程处理数据的不同范围(或区间),多进程并行能够在一定程度上提高任务的效率。
from itertools import islice
from pathlib import Path
from tqdm import tqdm # 用于显示进度条
basedir = Path(r'D:\Datasets\nlpcc2018\nlpcc-kbqa')
kb_file = basedir / 'knowledge' / 'nlpcc-iccpol-2016.kbqa.kb'
def populate_database(start: int, stop: int, buffer_size: int):
if stop < start:
raise ValueError(f'Invalid arguments: (start={start}, stop={stop})')
num_knowledge_tpls = stop - start
session = Session()
knowlege_buffer = []
old_count, new_count = 0, 0
with tqdm(total=num_knowledge_tpls) as pbar, \
kb_file.open(encoding='utf8') as fp:
for line in islice(fp, start, stop):
entity, attribute, value = line.strip().split(' ||| ')
# 清洗数据
new_attribute = remove_special_characters(attribute)
new_attribute = remove_blank(new_attribute)
new_attribute = remove_reference(new_attribute)
new_entity = remove_reference(entity.strip())
new_value = remove_reference(value.strip())
if is_illegal_relation(line) or len(new_entity) > 250 or len(new_value) > 250:
pbar.update(1)
continue
knowledge_tpl = KnowledgeTuple(entity=new_entity, attribute=new_attribute, value=new_value)
knowlege_buffer.append(knowledge_tpl)
if len(knowlege_buffer) > buffer_size:
# 达到缓冲区容量的上限后,通过一次事务提交所有的三元组
session.add_all(knowlege_buffer)
session.commit()
knowlege_buffer = []
new_count += buffer_size
pbar.update(new_count - old_count)
old_count = new_count
session.add_all(knowlege_buffer)
session.commit()
new_count += len(knowlege_buffer)
session.close()
engine.dispose() # !important
print(f'数据库`{KnowledgeTuple.__tablename__}`: 新增{new_count}条记录')
# 提供命令行接口
import argparse
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--start", required=True, type=int, help="The start argument of slice")
parser.add_argument("--stop", required=True, type=int, help="The end argument of slice")
parser.add_argument("--buffer_size", default=20000, type=int, help="Number of records in one transaction")
args = parser.parse_args()
populate_database(args.start, args.stop, args.buffer_size)
遇到的问题
Incorrect string value异常
KBQA数据集一方面规模大、信息全,另一方面由于是通过异构数据源(爬虫,人工标注,其他知识库)进行构建的,包含了大量的噪声。在加载数据到数据库的过程中,我遇到了
Incorrect string value: '...' for cloumn...的异常。通过观察错误信息可以发现,三元组中包含了不常用的字符'',它的Unicode编码是U+2620F,位于中日韩统一表意文字扩充B区,占4个字节。>>> len(''.encode())
4
>>> len('婚'.encode())
3
UTF-8最大的一个特点,就是它是一种变长的编码方式,可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。在MySQL中,字符集指定为UTF-8、字段类型是字符串的字段只能存储最多三个字节的字符,而存不了包含四个字节的字符。 要在MySQL中保存4字节长度的UTF-8字符,需要使用utf8mb4('mb4'指most bytes 4)字符集。
# 1. 创建数据库连接时指定编码方式为'utf8mb4'
engine = create_engine('dialect+driver://username:password@host:port/database?charset=utf8mb4')
# 或engine = create_engine('dialect+driver://username:password@host:port/database', encoding='utf8mb4') # 2. 定义数据库表模式时,通过类属性`__table_args__`指定编码方式
class KnowledgeTuple(Base):
__tableargs__ = {
'mysql_charset': 'utf8mb4'
}
Text类型的字段不能设置索引
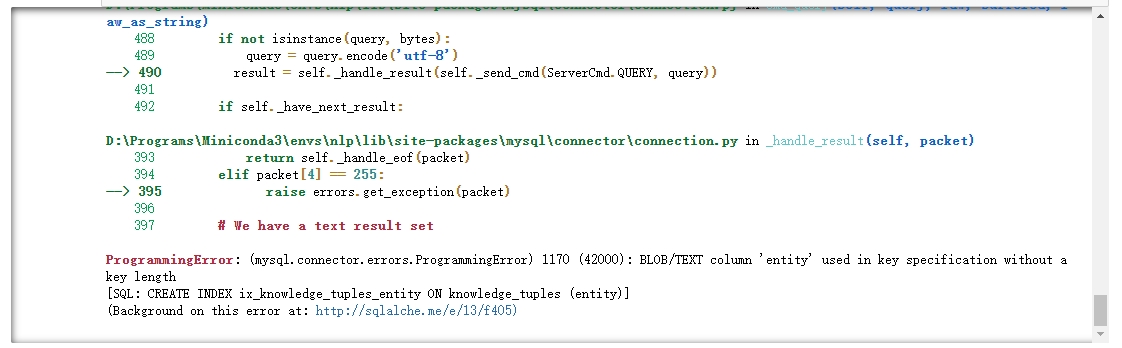
我遇到的第二个问题是不能为Text类型的字段创建索引
SQLAlchemy关闭数据库连接
尽管我在使用完数据库连接后,都显式地调用
session.close()关闭了会话,但是只是这样实际上并没有断开数据库连接,通过执行SHOW STATUS LIKE '%Connection%';能看到还有大量的数据库连接存在。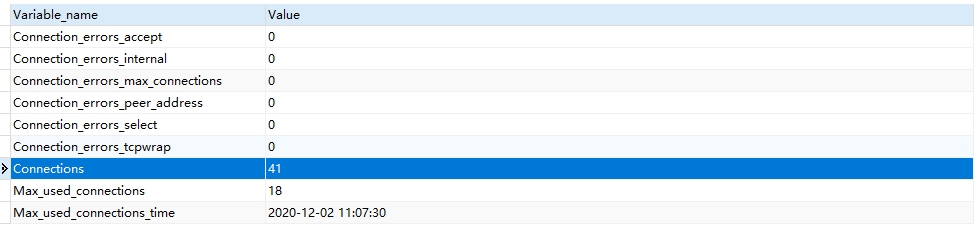
That is, the Engine is a factory for connections as well as a pool of connections, not the connection itself. When you say conn.close(), the connection is returned to the connection pool within the Engine, not actually closed.
# 通过以下方式断开数据库连接
session.close()
engine.dispose() # !important
参考材料
- How to close sqlalchemy connection in MySQL
- MySQL千万级数据量根据索引优化查询速度
- MySQL经典案例分析:Specified key was too long
- MySQL-锁机制及MyISAM表锁
- Sqlalchemy,操作mysql数据库报错Incorrect string value,怎么处理?
SQLAlchemy加载数据到数据库的更多相关文章
- 时间序列数据库——索引用ES、聚合分析时加载数据用什么?docvalues的列存储貌似更优优势一些
加载 如何利用索引和主存储,是一种两难的选择. 选择不使用索引,只使用主存储:除非查询的字段就是主存储的排序字段,否则就需要顺序扫描整个主存储. 选择使用索引,然后用找到的row id去主存储加载数据 ...
- Tomcat启动时加载数据到缓存---web.xml中listener加载顺序(例如顺序:1、初始化spring容器,2、初始化线程池,3、加载业务代码,将数据库中数据加载到内存中)
最近公司要做功能迁移,原来的后台使用的Netty,现在要迁移到在uap上,也就是说所有后台的代码不能通过netty写的加载顺序加载了. 问题就来了,怎样让迁移到tomcat的代码按照原来的加载顺序进行 ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
- 使用 jQuery Ajax 在页面滚动时从服务器加载数据
简介 文本将演示怎么在滚动滚动条时从服务器端下载数据.用AJAX技术从服务器端加载数据有助于改善任何web应用的性能表现,因为在打开页面时,只有一屏的数据从服务器端加载了,需要更多的数据时,可以随着用 ...
- 淘宝购物车页面 智能搜索框Ajax异步加载数据
如果有朋友对本篇文章的一些知识点不了解的话,可以先阅读此篇文章.在这篇文章中,我大概介绍了一下构建淘宝购物车页面需要的基础知识. 这篇文章主要探讨的是智能搜索框Ajax异步加载数据.jQuery的社区 ...
- DevExpress的GridControl的实时加载数据解决方案(取代分页)
http://blog.csdn.net/educast/article/details/4769457 evExpress是一套第三方控件 其中有类似DataGridView的控件 今天把针对Dev ...
- D3树状图异步按需加载数据
D3.js这个绘图工具,功能强大不必多说,完全一个Data Driven Document的绘图工具,用户可以按照自己的数据以及希望实现的图形,随心所欲的绘图. 图形绘制,D3默认采用的是异步加载,但 ...
- java攻城狮之路(Android篇)--widget_webview_metadata_popupwindow_tabhost_分页加载数据_菜单
一.widget:桌面小控件1 写一个类extends AppWidgetProvider 2 在清单文件件中注册: <receiver android:name=".ExampleA ...
- ArcGIS Engine中加载数据
ArcGIS Engine中加载数据 http://blog.csdn.net/gisstar/article/details/4206822 分类: AE开发积累2009-05-21 16:49 ...
随机推荐
- bat加mimikatz一键获取密码
1 @echo off 2 >nul 2>&1 "%SYSTEMROOT%\system32\cacls.exe" "%SYSTEMROOT%\sys ...
- [应用软件] VMware Workstation 12.0.0 Pro 正式版下载【附注册机+注册码】
软件信息 软件名称: VMware Workstation 软件版本: 12 软件大小: 300 MB 软件语言: 简体中文 更新时间: - 软件授权: 免费 软件类别: 安装版 运行环境: WinX ...
- error C4996: 'std::_Copy_impl'
以下代码段在VS2008编译可以通过,只是会提示不安全: std::vector<unsigned char> fileData ="asdfsfsfsfsdf";// ...
- Oracle 11G DBMS包和类型参考
参阅:https://docs.oracle.com/cd/E11882_01/appdev.112/e40758/d_lob.htm#ARPLS66712
- LCS&&LRC&&LIS问题
注:最近笔试题经常碰到DP动态规划的问题,但是由于本人没有接触过DP,笔试后看到别人家的答案简洁又漂亮,真的羡慕:难的DP自己可能不会,那再见到常见的LCS和LRS以及LIS为问题总该会吧: 资料参考 ...
- springcloud如何实现服务的注册?
1.服务发布时,指定对应的服务名,将服务注册到 注册中心(eureka zookeeper)2.注册中心加@EnableEurekaServer,服务用@EnableDiscoveryClient,然 ...
- Java 语言如何进行异常处理,关键字:throws、throw、 try、catch、finally 分别如何使用?
Java 通过面向对象的方法进行异常处理,把各种不同的异常进行分类,并提供了良好的接口.在 Java 中,每个异常都是一个对象,它是 Throwable 类或其子类的实例.当一个方法出现异常后便抛出一 ...
- mysql的cpu飙升原因及处理
Mysql 批量杀死进程 正常情况下kill id,即可,但是有时候某一异常连接特别多的时候如此操作会让人抓狂,下面记录下小方法: use information_schema; select co ...
- springboot项目中的日志输出
#修改默认输出级别,trace < debug < info < warn < errorlogging.level.com.lagou=trace#控制台输出logging. ...
- ACM - 最短路 - CodeForces 295B Greg and Graph
CodeForces 295B Greg and Graph 题解 \(Floyd\) 算法是一种基于动态规划的算法,以此题为例介绍最短路算法中的 \(Floyd\) 算法. 我们考虑给定一个图,要找 ...