【拖拽可视化大屏】全流程讲解用python的pyecharts库实现拖拽可视化大屏的背后原理,简单粗暴!
“整篇文章较长,干货很多!建议收藏后,分章节阅读。”
一、设计方案
整体设计方案思维导图:
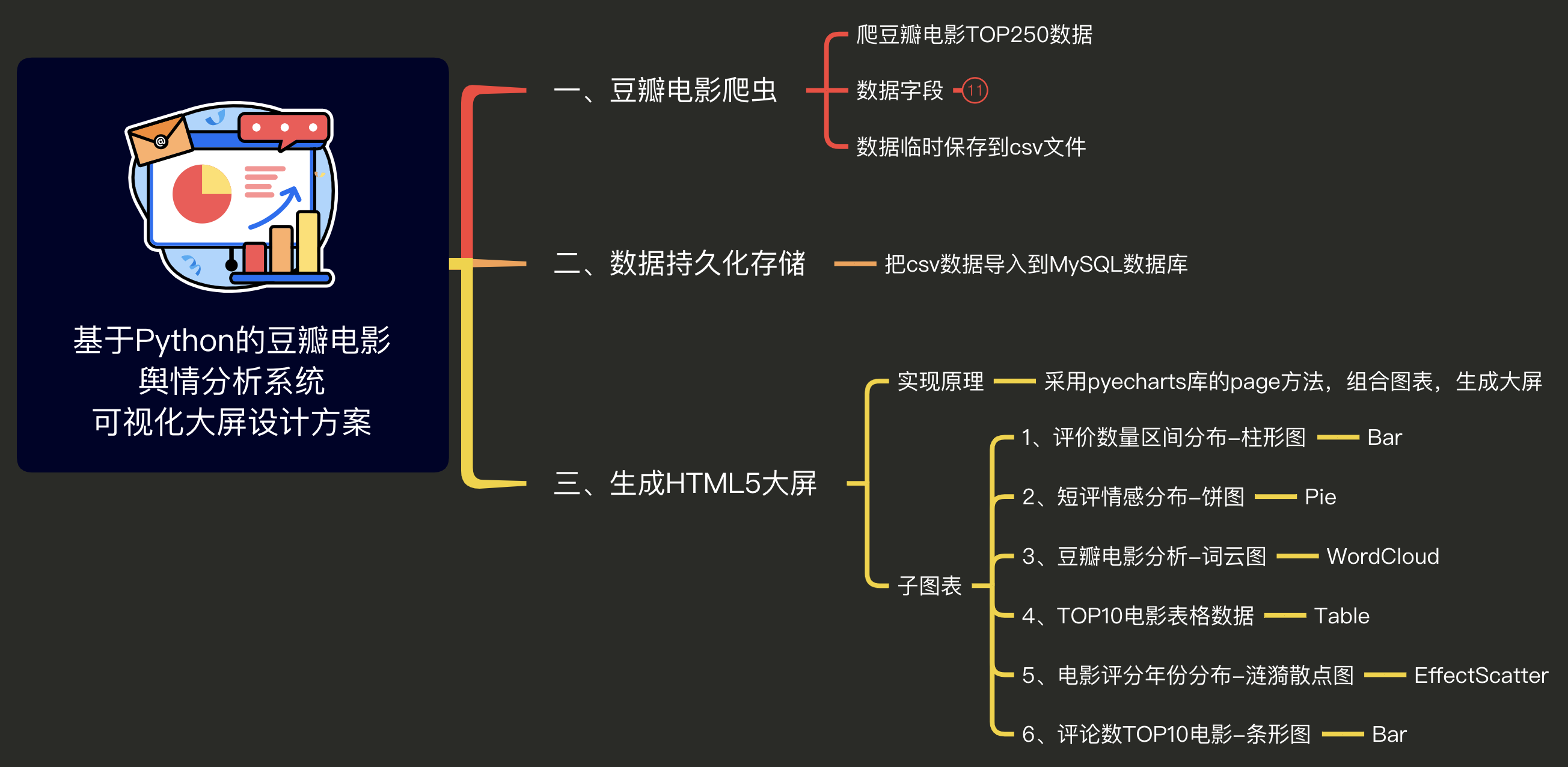
整篇文章,也将按照这个结构来讲解。
若有重点关注部分,可点击章节目录直接跳转!
二、项目背景
针对TOP250排行榜的数据,开发一套可视化数据大屏系统,展示各维度数据分析结果。
TOP250排行榜
三、电影爬虫
3.1 导入库
import requests # 发送请求
from bs4 import BeautifulSoup # 解析网页
import pandas as pd # 存取csv
from time import sleep # 等待时间
from sqlalchemy import create_engine # 连接数据库
3.2 发送请求
定义一些空列表,用于临时存储爬取下的数据:
movie_name = [] # 电影名称
movie_url = [] # 电影链接
movie_star = [] # 电影评分
movie_star_people = [] # 评分人数
movie_director = [] # 导演
movie_actor = [] # 主演
movie_year = [] # 上映年份
movie_country = [] # 国家
movie_type = [] # 类型
short_comment = [] # 一句话短评
向网页发送请求:
res = requests.get(url, headers=headers)
3.3 解析页面
利用BeautifulSoup库解析响应页面:
soup = BeautifulSoup(res.text, 'html.parser')
用BeautifulSoup的select函数,(css解析的方法)编写代码逻辑,部分核心代码:
for movie in soup.select('.item'):
name = movie.select('.hd a')[0].text.replace('\n', '') # 电影名称
movie_name.append(name)
url = movie.select('.hd a')[0]['href'] # 电影链接
movie_url.append(url)
star = movie.select('.rating_num')[0].text # 电影评分
movie_star.append(star)
star_people = movie.select('.star span')[3].text # 评分人数
star_people = star_people.strip().replace('人评价', '')
其中,需要说明的是,《大闹天宫》这部电影和其他电影页面排版不同:

所以,这里特殊处理一下:
if name == '大闹天宫 / 大闹天宫 上下集 / The Monkey King': # 大闹天宫,特殊处理
year0 = movie_infos.split('\n')[1].split('/')[0].strip()
year1 = movie_infos.split('\n')[1].split('/')[1].strip()
year2 = movie_infos.split('\n')[1].split('/')[2].strip()
year = year0 + '/' + year1 + '/' + year2
movie_year.append(year)
country = movie_infos.split('\n')[1].split('/')[3].strip()
movie_country.append(country)
type = movie_infos.split('\n')[1].split('/')[4].strip()
movie_type.append(type)
3.4 存储到csv
最后,将爬取到的数据保存到csv文件中:
def save_to_csv(csv_name):
"""
数据保存到csv
:return: None
"""
df = pd.DataFrame() # 初始化一个DataFrame对象
df['电影名称'] = movie_name
df['电影链接'] = movie_url
df['电影评分'] = movie_star
df['评分人数'] = movie_star_people
df['导演'] = movie_director
df['主演'] = movie_actor
df['上映年份'] = movie_year
df['国家'] = movie_country
df['类型'] = movie_type
df.to_csv(csv_name, encoding='utf_8_sig') # 将数据保存到csv文件
其中,把各个list赋值为DataFrame的各个列,就把list数据转换为了DataFrame数据,然后直接to_csv保存。
3.5 讲解视频
同步讲解视频:
https://www.zhihu.com/zvideo/1465578220191592448
四、数据持久化存储
然后,就可以把csv数据导入到MySQL数据库,做持久化存储了。
4.1 导入库
import pandas as pd # 存取csv
from sqlalchemy import create_engine # 连接数据库
4.2 存入MySQL
最核心的三行代码:
# 把csv导入mysql数据库
engine = create_engine('mysql+pymysql://root:123456@localhost/db_bigscreen')
df = pd.read_csv('Movie250.csv')
df.to_sql(name='t_film', con=engine, chunksize=1000, if_exists='replace', index=None)
用create_engine创建数据库连接,格式为:
create_engine('数据库类型+数据库驱动://用户名:密码@数据库IP地址/数据库名称')
这样,数据库连接就创建好了。
然后,用pandas的read_csv函数读取csv文件。
最后,用pandas的to_sql函数,把数据存入MySQL数据库:
name='college_t2' #mysql数据库中的表名
con=engine # 数据库连接
index=False #不包含索引字段
if_exists='replace' #如果表中存在数据,就替换掉,另外,还支持append(追加数据)
非常方便地完成了反向导入,即:从csv向数据库的导入。
4.3 讲解视频
同步讲解视频:
https://www.zhihu.com/zvideo/1496218294043009024
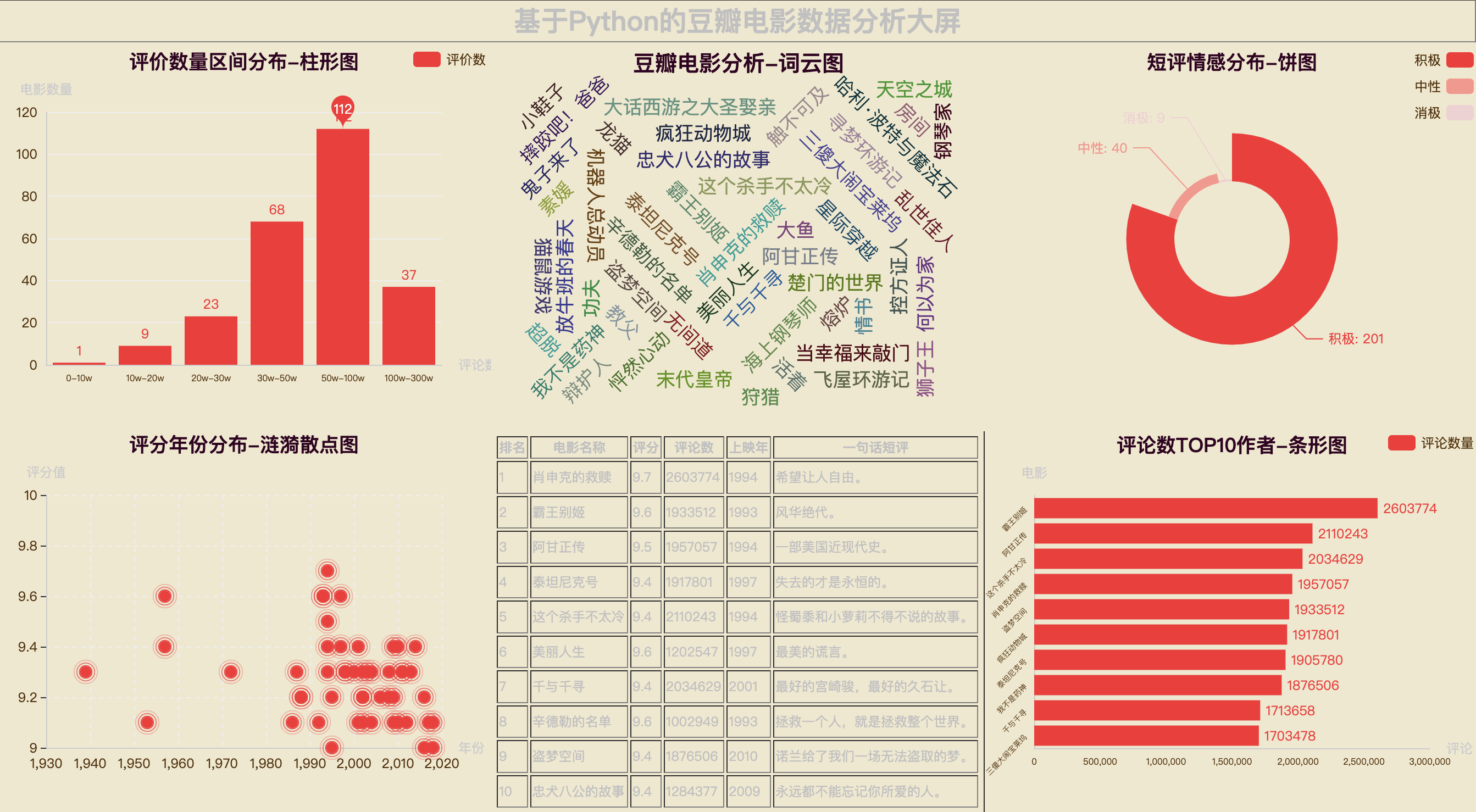
五、开发可视化大屏
如文章开头的思维导图所说,首先把各个子图表开发出来,然后用pyecharts的Page组件,把这些子图表拼装组合起来,形成大屏。
下面,依次讲解每个子图表的实现。
5.1 柱形图
pyecharts官网-柱形图:A Python Echarts Plotting Library built with love.
因为需要实现分段区间统计,所以先定义出一个区间对象:
# 设置分段
bins = [0, 100000, 200000, 300000, 500000, 1000000, 3000000]
# 设置标签
labels = ['0-10w', '10w-20w', '20w-30w', '30w-50w', '50w-100w', '100w-300w']
然后,对数据进行按段切割,并统计个数:
# 按分段离散化数据
segments = pd.cut(cmt_count_list, bins, labels=labels) # 按分段切割数据
counts = pd.value_counts(segments, sort=False).values.tolist() # 统计个数
最后,采用pyecharts里的Bar对象,画出柱形图:
bar = Bar(
init_opts=opts.InitOpts(theme=theme_config, width="450px", height="350px", chart_id='bar_cmt2')) # 初始化条形图
bar.add_xaxis(labels, ) # 增加x轴数据
bar.add_yaxis("评价数", counts) # 增加y轴数据
bar.set_global_opts(
legend_opts=opts.LegendOpts(pos_left='right'),
title_opts=opts.TitleOpts(title="评价数量区间分布-柱形图", pos_left='center'), # 标题
toolbox_opts=opts.ToolboxOpts(is_show=False, ), # 不显示工具箱
xaxis_opts=opts.AxisOpts(name="评论数", # x轴名称
axislabel_opts=opts.LabelOpts(font_size=8)), # 字体大小
yaxis_opts=opts.AxisOpts(name="电影数量",
axislabel_opts={"rotate": 0},
splitline_opts=opts.SplitLineOpts(is_show=True,
linestyle_opts=opts.LineStyleOpts(type_='solid')),
), # y轴名称
)
# 标记最大值
bar.set_series_opts(
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max", name="最大值"), ],
symbol_size=35) # 标记符号大小
)
bar.render("评价数分布-柱形图.html") # 生成html文件
print('生成完毕:评价数分布-柱形图.html')
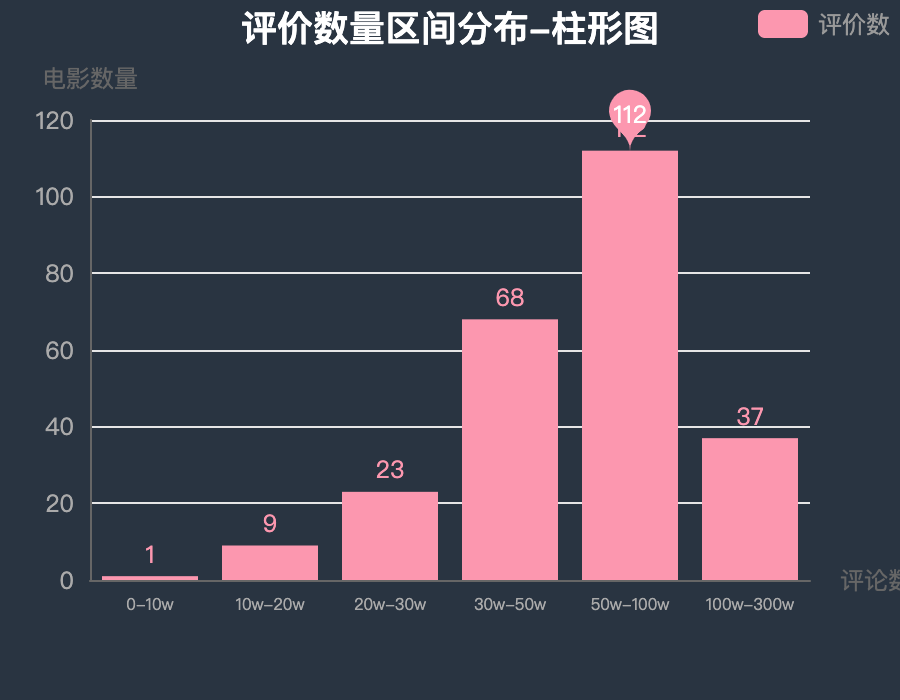
图表效果:
5.2 饼图
pyecharts官网-饼图:A Python Echarts Plotting Library built with love.
绘制情感分布的饼图。所以,首先要对评价数据进行情感分析。
鉴于电影评价内容都是中文文本设计,情感分析采用snownlp技术进行。
score_list = [] # 情感评分值
tag_list = [] # 打标分类结果
pos_count = 0 # 计数器-积极
mid_count = 0 # 计数器-中性
neg_count = 0 # 计数器-消极
for comment in v_cmt_list:
tag = ''
sentiments_score = SnowNLP(comment).sentiments
if sentiments_score < 0.4: # 情感分小于0.4判定为消极
tag = '消极'
neg_count += 1
elif 0.4 <= sentiments_score <= 0.6: # 情感分在[0.4,0.6]直接判定为中性
tag = '中性'
mid_count += 1
else: # 情感分大于0.6判定为积极
tag = '积极'
pos_count += 1
score_list.append(sentiments_score) # 得分值
tag_list.append(tag) # 判定结果
df['情感得分'] = score_list
df['分析结果'] = tag_list
df.to_excel('情感判定结果.xlsx', index=None) # 把情感分析结果保存到excel文件
按照情感得分值划分区间:
情感得分值小于0.4,判定为消极
情感得分值在0.4与0.6之间,判定为中性
情感得分值大于0.6,判定为积极
最终将结果保存到Excel文件中,查看下:

将此结果中的数据,带入到Pie组件中,画出饼图:
# 画饼图
pie = (
Pie(init_opts=opts.InitOpts(theme=theme_config, width="450px", height="350px", chart_id='pie1'))
.add(series_name="评价情感分布", # 系列名称
data_pair=[['积极', pos_count], # 添加数据
['中性', mid_count],
['消极', neg_count]],
rosetype="radius", # 是否展示成南丁格尔图
radius=["30%", "55%"], # 扇区圆心角展现数据的百分比,半径展现数据的大小
) # 加入数据
.set_global_opts( # 全局设置项
title_opts=opts.TitleOpts(title="短评情感分布-饼图", pos_left='center'), # 标题
legend_opts=opts.LegendOpts(pos_left='right', orient='vertical') # 图例设置项,靠右,竖向排列
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))) # 样式设置项
pie.render('情感分布_饼图.html') # 生成html文件
print('生成完毕:情感分布_饼图.html')
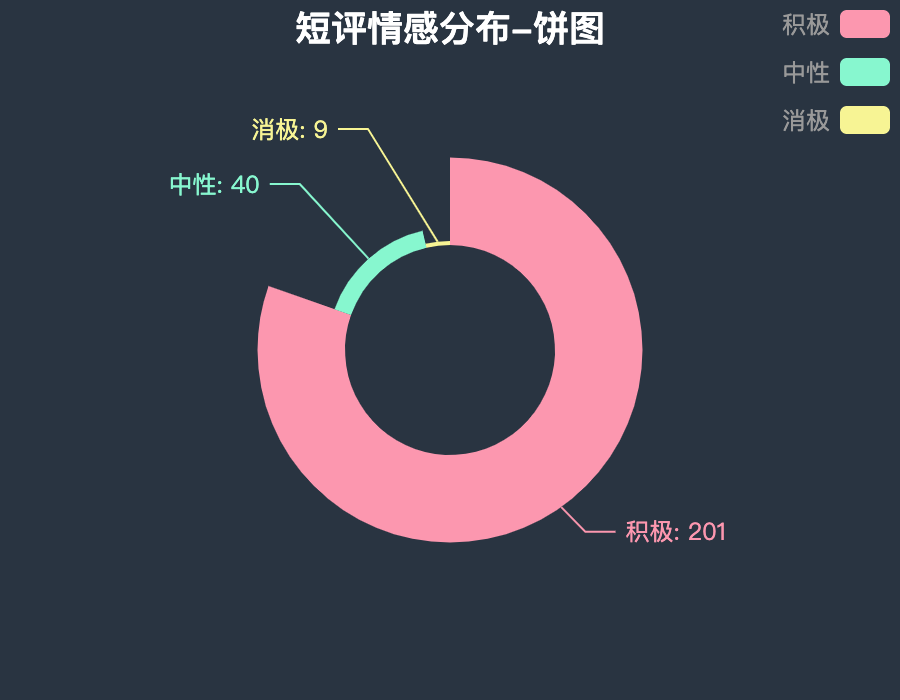
图表效果:
5.3 词云图
pyecharts官网-词云图:A Python Echarts Plotting Library built with love.
针对TOP250的电影名称,绘制出词云图。
先对数据做清洗操作,然后直接画出词云图即可:
wc = WordCloud(init_opts=opts.InitOpts(width="450px", height="350px", theme=theme_config, chart_id='wc1'))
wc.add(series_name="电影名称",
data_pair=data,
word_size_range=[15, 20],
width='400px', # 宽度
height='300px', # 高度
word_gap=5 # 单词间隔
) # 增加数据
wc.set_global_opts(
title_opts=opts.TitleOpts(pos_left='center',
title="电影名称分析-词云图",
title_textstyle_opts=opts.TextStyleOpts(font_size=20) # 设置标题
),
tooltip_opts=opts.TooltipOpts(is_show=True), # 不显示工具箱
)
wc.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
wc.render('电影名称_词云图.html') # 生成html文件
print('生成完毕:电影名称_词云图.html')
图表效果:

5.4 数据表格
pyecharts官网-表格:A Python Echarts Plotting Library built with love.
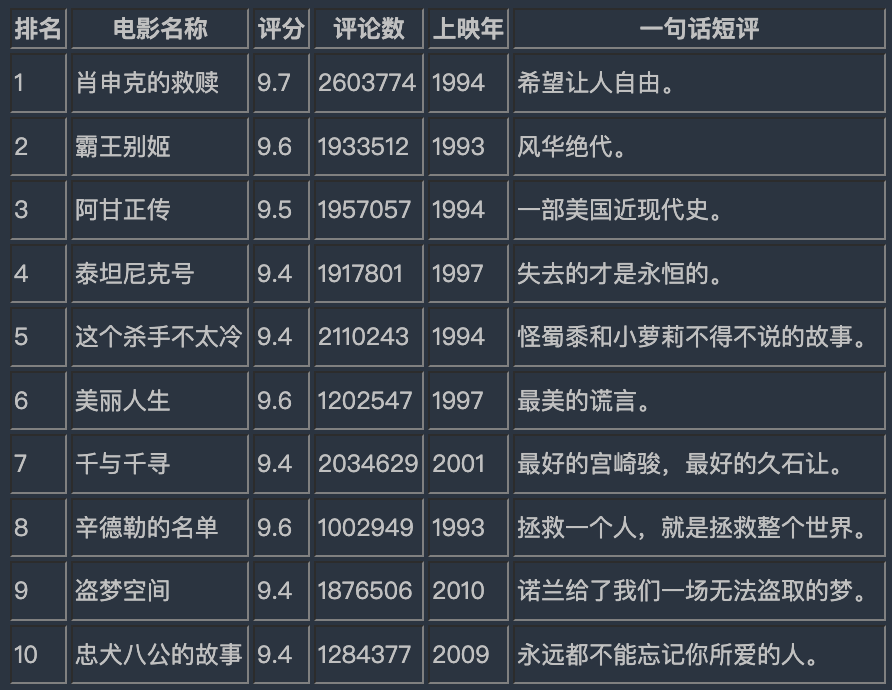
把排名前10的电影详情数据,展现到大屏上,采用pyecharts里的Table组件实现。
从MySQL数据库读取到数据后,直接进行绘制表格:
table = (
Table(page_title='我的表格标题', )
.add(headers=['排名', '电影名称', '评分', '评论数', '上映年', '一句话短评'], rows=data_list, attributes={
"align": "left",
"border": False,
"padding": "20px",
"style": "background:{}; width:450px; height:350px; font-size:10px; color:#C0C0C0;padding:3px;".format(
table_color)
})
.set_global_opts(title_opts=opts.TitleOpts(title='这是表格1'))
)
table.render('电影排名TOP10_数据表格.html')
print('生成完毕:电影排名TOP10_数据表格.html')
图表效果:
5.5 涟漪散点图
pyecharts官网-涟漪散点图:A Python Echarts Plotting Library built with love.
针对电影的上映年份和评分值,两个纬度的数据,绘制出涟漪散点图(涟漪散点图和普通散点图的区别,就是涟漪散点图是动态图,图上的每个点都在闪烁,像水面上的涟漪一样)。
sc = (EffectScatter(init_opts=opts.InitOpts(width="450px", height="350px", theme=theme_config, chart_id='scatter1'))
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="",
y_axis=y_data,
symbol_size=10,
label_opts=opts.LabelOpts(is_show=False),
)
.set_series_opts()
.set_global_opts(
# 忽略部分代码
)
)
sc.render('评分年份分布-散点图.html')
print('生成完毕:散点图.html')
图表效果:
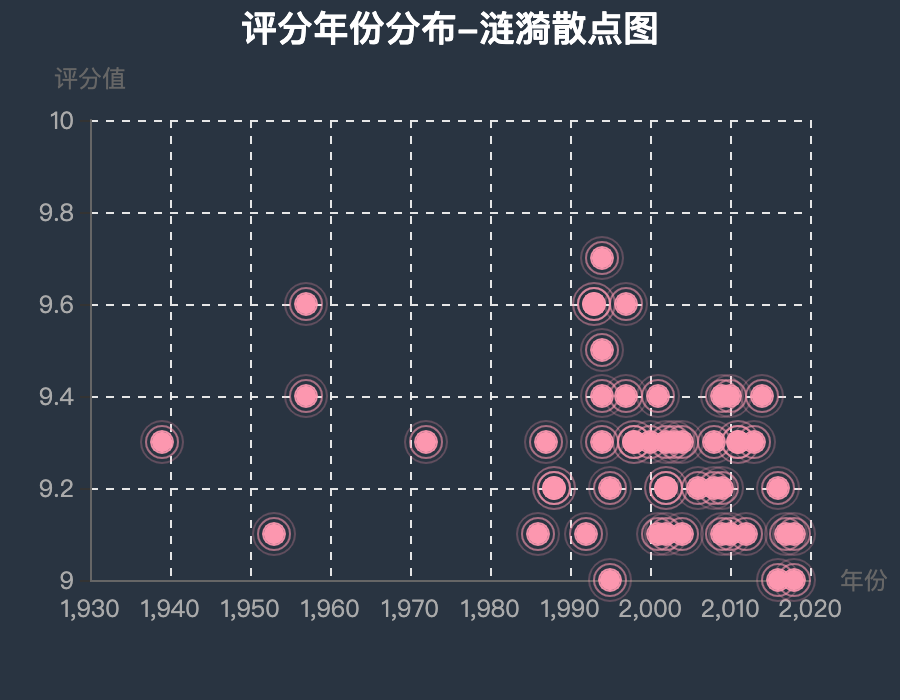
5.6 条形图
pyecharts官网-条形图:A Python Echarts Plotting Library built with love.
针对评论数最多的10个电影名称,绘制出横向条形图。
# 画条形图
bar = Bar(
init_opts=opts.InitOpts(theme=theme_config, width="450px", height="350px", chart_id='bar_cmt1')) # 初始化条形图
bar.add_xaxis(x_data) # 增加x轴数据
bar.add_yaxis("评论数量", y_data) # 增加y轴数据
bar.reversal_axis() # 设置水平方向
bar.set_series_opts(label_opts=opts.LabelOpts(position="right")) # Label出现位置
bar.set_global_opts(
legend_opts=opts.LegendOpts(pos_left='right'),
title_opts=opts.TitleOpts(title="评论数TOP10作者-条形图", pos_left='center'), # 标题
toolbox_opts=opts.ToolboxOpts(is_show=False, ), # 不显示工具箱
xaxis_opts=opts.AxisOpts(name="评论", # x轴名称
axislabel_opts=opts.LabelOpts(font_size=8, rotate=0),
splitline_opts=opts.SplitLineOpts(is_show=False)
),
yaxis_opts=opts.AxisOpts(name="电影", # y轴名称
axislabel_opts=opts.LabelOpts(font_size=7, rotate=45), # y轴名称
)
)
bar.render("评论数TOP10_条形图.html") # 生成html文件
print('生成完毕:评论数TOP10_条形图.html')
图表效果:

5.7 大标题
由于pyecharts组件没有专门用作标题的图表,我决定灵活运用Table组件实现大标题。即,让Table只有标题header,没有数据行row,再针对header做一些样式调整(字体增大等),即可实现一行大标题。
table = Table()
table.add(headers=[v_title], rows=[], attributes={
"align": "center",
"border": False,
"padding": "2px",
"style": "background:{}; width:1350px; height:50px; font-size:25px; color:#C0C0C0;".format(table_color)
})
table.render('大标题.html')
print('生成完毕:大标题.html')
图表效果:

5.8 Page组合
最后,也是最关键的一步,把以上所有图表组合到一起,用Page组件,并且选用DraggablePageLayout方法,即拖拽的方式,组合图表:
# 绘制:整个页面
page = Page(
page_title="基于Python的电影数据分析大屏",
layout=Page.DraggablePageLayout, # 拖拽方式
)
page.add(
# 增加:大标题
make_title(v_title='基于Python的电影数据分析大屏'),
# 绘制:中下方数据表格
make_table(v_df=df_table),
# 绘制:电影名称词云图
filmname_wordcloud(v_str=film_all_list),
# 绘制:TOP10评论数-条形图
make_top10_comment_bar(v_df=df),
# 绘制情感分布饼图
make_analyse_pie(v_cmt_list=comment_all_list),
# 绘制:评价数分段统计-柱形图
make_cmt_count_bar(v_df=df),
# 绘制:散点图
make_scatter(x_data=year_list, y_data=score_list)
)
page.render('大屏_临时.html') # 执行完毕后,打开临时html并排版,排版完点击Save Config,把json文件放到本目录下
print('生成完毕:大屏_临时.html')
本代码执行完毕后,打开临时html并排版,排版完点击SaveConfig,把json文件放到本目录下。
再执行最后一步,调用json配置文件,生成最终大屏文件。
# 执行之前,请确保:1、已经把json文件放到本目录下 2、把json中的title和table的id替换掉
Page.save_resize_html(
source="大屏_临时.html",
cfg_file="chart_config.json",
dest="大屏_最终_0426.html"
)
拖拽过程的演示视频:
https://www.zhihu.com/zvideo/1502249430140616704
至此,所有代码执行完毕,生成了最终大屏html文件。
六、彩蛋-多种主题
为了实现不同颜色主题的大屏可视化效果,我开发了一个实现逻辑,只需修改一个参数,即可展示不同颜色主题。
全局设置主题颜色
theme_config = ThemeType.CHALK # 颜色方案
由于Table组件是不能设置颜色主题的,所以我手写了一个逻辑(用取色器获取的RGB值,又转成十六进制的颜色!),如下:
# 表格和标题的颜色
table_color = ""
if theme_config == ThemeType.DARK:
table_color = '#333333'
elif theme_config == ThemeType.CHALK:
table_color = '#293441'
elif theme_config == ThemeType.PURPLE_PASSION:
table_color = '#5B5C6E'
elif theme_config == ThemeType.ROMANTIC:
table_color = '#F0E8CD'
elif theme_config == ThemeType.ESSOS:
table_color = '#FDFCF5'
else:
table_color = ''
最终实现了多种颜色主题,包含以下。
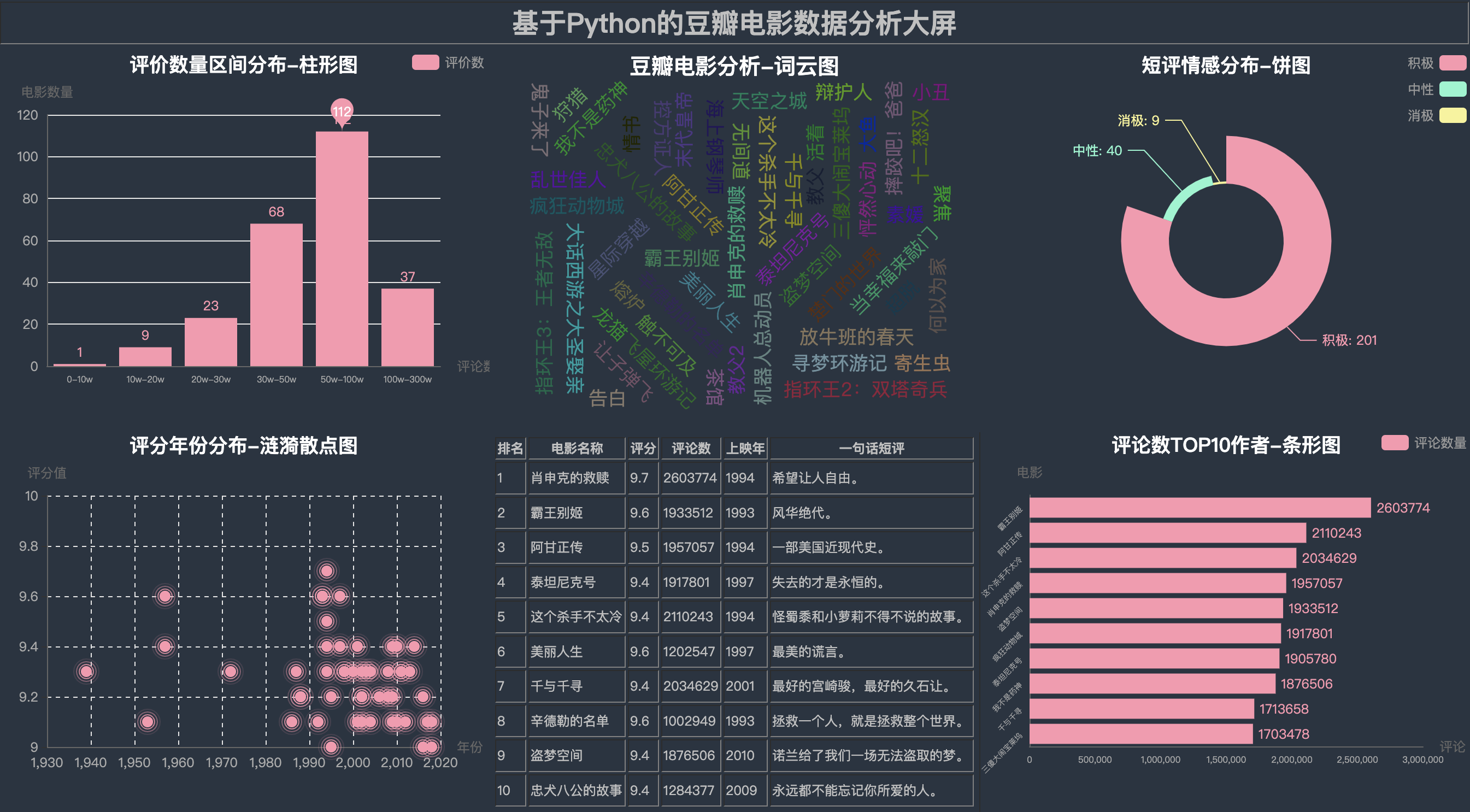
6.1 CHALK主题
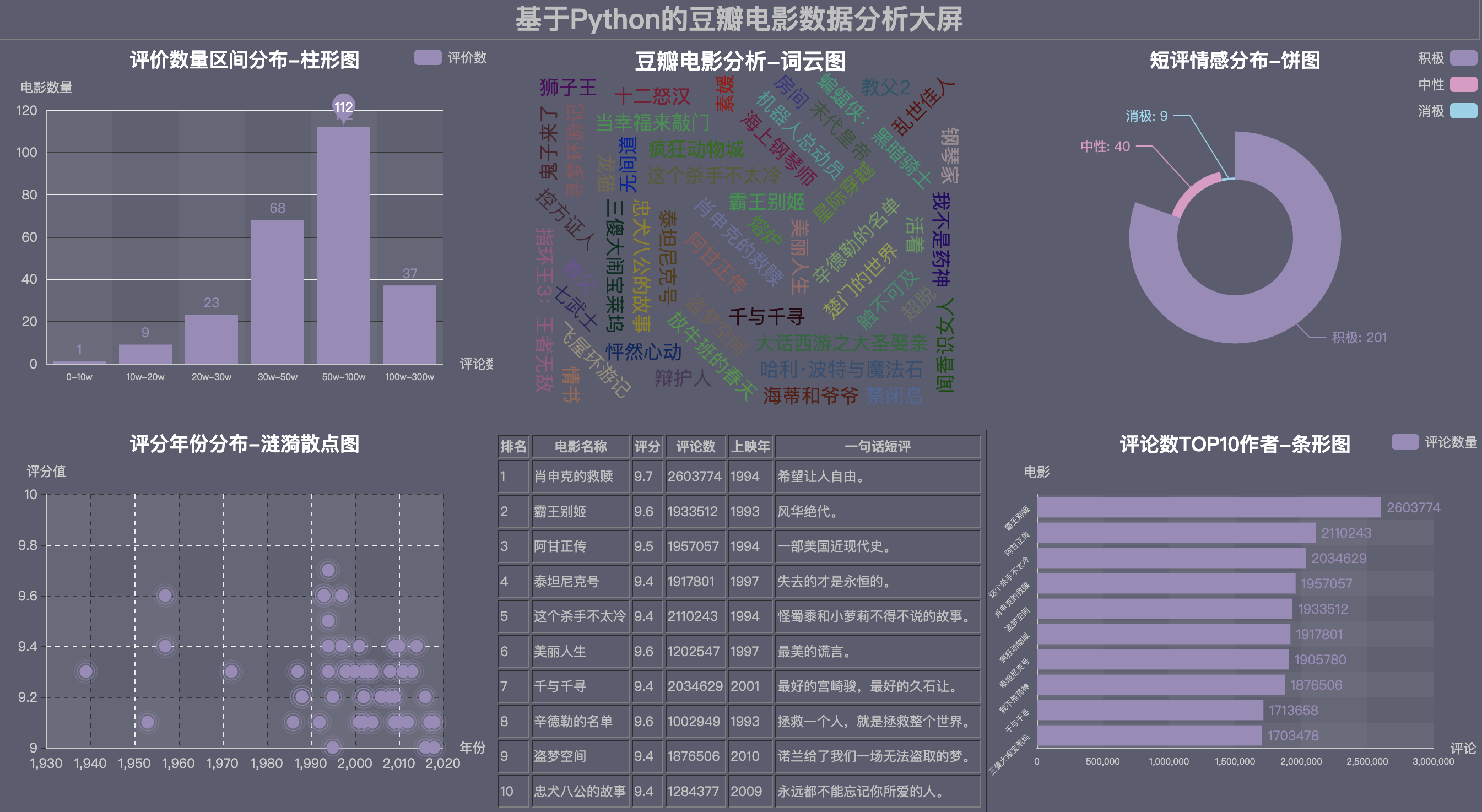
6.2 PURPLE主题
6.3 ESSOS主题
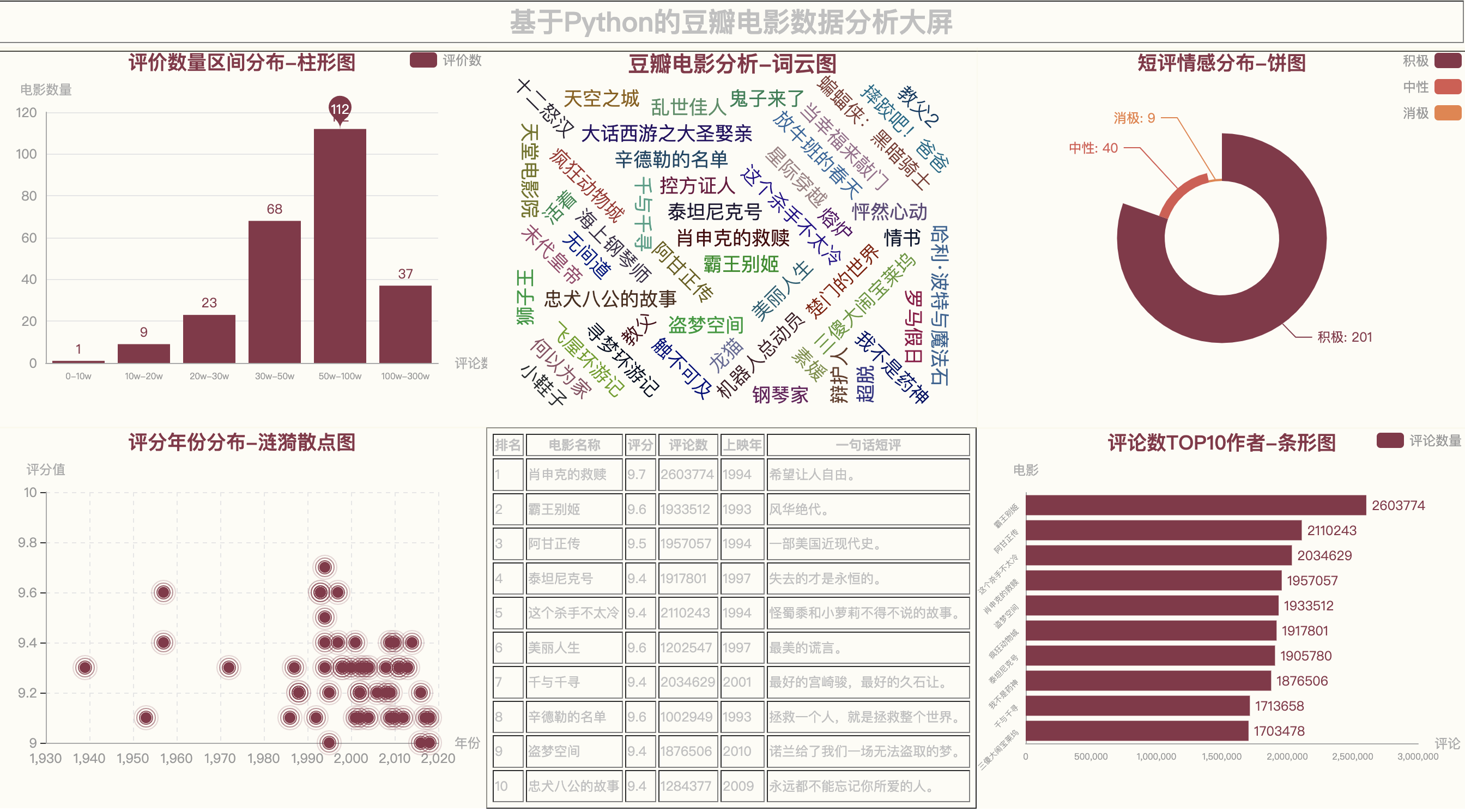
6.4 ROMANTIC主题
6.5 DARK主题

通过5种主题颜色,展示同一个大屏效果,有被炫到嘛?
七、拖拽演示视频
拖拽过程演示视频:
https://www.zhihu.com/zvideo/1502249430140616704
八、全流程讲解视频
全流程讲解:
https://www.zhihu.com/zvideo/1503013679826690048
by 马哥python说
【拖拽可视化大屏】全流程讲解用python的pyecharts库实现拖拽可视化大屏的背后原理,简单粗暴!的更多相关文章
- 阿里巴巴年薪800k大数据全栈工程师成长记
大数据全栈工程师一词,最早出现于Facebook工程师Calos Bueno的一篇文章 - Full Stack (需fanqiang).他把全栈工程师定义为对性能影响有着深入理解的技术通才.自那以后 ...
- 全球首个全流程跨平台界面开发套件,PowerUI分析
一. 首个全流程跨平台界面开发套件,PowerUI正式发布 UIPower在DirectUI的基础上,自主研发全球首个全流程跨平台界面开发套件PowerUI(PUI)正式发布,PowerU ...
- MindStudio模型训练场景精度比对全流程和结果分析
摘要:MindStudio是一套基于华为昇腾AI处理器开发的AI全栈开发平台 本文分享自华为云社区<MindStudio模型训练场景精度比对全流程和结果分析>,作者:yd_24730208 ...
- ANDROID内存优化(大汇总——全)
写在最前: 本文的思路主要借鉴了2014年AnDevCon开发者大会的一个演讲PPT,加上把网上搜集的各种内存零散知识点进行汇总.挑选.简化后整理而成. 所以我将本文定义为一个工具类的文章,如果你在A ...
- 【CKB.DEV 茶话会】第二期:聊聊 CKB 钱包和 Nervos DAO 全流程
CKB.DEV 茶话会第二期:聊聊 CKB 钱包和 Nervos DAO 全流程 为了鼓励更多优秀的开发者和研究人员参与到 CKB 的开发和生态建设中去,我们希望组织一系列 CKB Developer ...
- 基于Jenkins的开发测试全流程持续集成实践
今年一直在公司实践CI,本文将近半年来的一些实践总结一下,可能不太完善或优美,但的确初步解决了我目前所在项目组的一些痛点.当然这仅是一家之言也不够完整,后续还会深入实践和引入Kubernetes进行容 ...
- 数据分析电子商务B2C全流程_数据分析师
数据分析电子商务B2C全流程_数据分析师 目前,绝大多数B2C的转化率都在1%以下,做的最好的也只能到3.5%左右(比如以卖图书为主的当当) 我想,所有的B2C都会关心三个问题:究竟那97%去了哪里? ...
- AI全流程开发难题破解之钥
摘要:通过对ModelArts.盘古大模型.ModelBox产品技术的解读,帮助开发者更好的了解AI开发生产线. 本文分享自华为云社区<[大厂内参]第16期:华为云AI开发生产线,破解AI全流程 ...
- python 网络爬虫全流程教学,从入门到实战(requests+bs4+存储文件)
python 网络爬虫全流程教学,从入门到实战(requests+bs4+存储文件) requests是一个Python第三方库,用于向URL地址发起请求 bs4 全名 BeautifulSoup4, ...
随机推荐
- Mybatis 开发 dao 的方法
1.分析SqlSession使用范围 1.1.SqlSessionFactoryBuilder 通过 SqlSessionFactoryBuilder 创建会话工厂 SqlSessionFactory ...
- Matplotlib is currently using agg, which is a non-GUI backend 和 ImportError: No module named 'Tkinter' [closed]
跑maskrcnn报错:UserWarning: Matplotlib is currently using agg, which is a non-GUI backend, so cannot sh ...
- C# Coding Conventions, Coding Standards & Best Practices
C# Coding Conventions, Coding Standards & Best Practices Cui, Chikun Overview Introduction This ...
- HTML5摇一摇(上)—如何判断设备摇动
刚刚过去的一年里基于微信的H5营销可谓是十分火爆,通过转发朋友圈带来的病毒式传播效果相信大家都不太陌生吧,刚好最近农历新年将至,我就拿一个"摇签"的小例子来谈一谈HTML5中如何调 ...
- 该如何选择 background-image 和 img 标签
用img标签 如果你希望别人打印页面时候包含这张图片请使用 img 标签 当这张图片有非常有意义的语义,比如警告图标,请使用img标签及它的alt属性.这样意味着你可以向所有的用户终端现实他的意义. ...
- react开发教程(六)React与DOM
ReactDOM findeDOMNode 语法:DOMElement findDOMNode(ReactComponent component)描述:获取改组件实例相对应的DOM节点 案例: imp ...
- String能变化吗?和StringBuffer的区别是什么
[新手可忽略不影响继续学习]看 过上面例子的童鞋一定会觉得很奇怪,s = s + s1.charAt(i); 马克-to-win, s不是老在变化吗?其实s = "";时,虚拟机会 ...
- JSDOM基础
JavaScript 通过 HTML DOM,可访问 JavaScript HTML 文档的所有元素. HTML DOM 模型被构造为对象的树: HTML DOM 树 JavaScript 能够改变页 ...
- Svelte3聊天室|svelte+svelteKit仿微信聊天实例|svelte.js开发App
基于svelte3.x+svelteKit构建仿微信App聊天应用svelte-chatroom. svelte-chatroom 基于svelte.js+svelteKit+mescroll.js+ ...
- 性能优化之html、css、js三者的加载顺序
前言 我们知道一个页面通常由,html,css,js三部分组成,一般我们会把css文件放在head头部加载,而js文件则放在页面的最底部加载,想要知道为什么大家都会不约而同的按照这个标准进行构建页面, ...