海量数据存储ClickHouse
ClickHouse介绍
ClickHouse的由来和应用场景
- 俄罗斯Yandex在2016年开源,使用C++编写的列式存储数据库,近几年在OLAP领域大范围应用
- 官网:https://clickhouse.com/
- GitHub: https://github.com/ClickHouse/ClickHouse
docker安装
docker run -d --name ybchen_clickhouse --ulimit nofile=262144:262144 \
-p 8123:8123 -p 9000:9000 -p 9009:9009 --privileged=true \
-v /mydata/docker/clickhouse/log:/var/log/clickhouse-server \
-v /mydata/docker/clickhouse/data:/var/lib/clickhouse clickhouse/clickhouse-server:22.2.3.5
默认http端口是8123,tcp端口是9000, 同步端口9009
进入容器内部查看
web可视化界面:http://ip:8123/play
命令
- 查看数据库 SHOW DATABASES
- 查看某个库下面的全部表 SHOW TABLES IN system
- 系统数据库是 ClickHouse 存储有关 ClickHouse 部署的详细信息的地方
默认数据库最初为空,用于执行未指定数据库的命令
可视化工具
创建库
CREATE DATABASE shop
创建表
CREATE TABLE shop.clickstream (
customer_id String,
time_stamp Date,
click_event_type String,
page_code FixedString(20),
source_id UInt64
)
ENGINE = MergeTree()
ORDER BY (time_stamp)
- ClickHouse 有自己的数据类型,每个表都必须指定一个Engine引擎属性来确定要创建的表的类型
- 引擎决定了数据的存储方式和存储位置、支持哪些查询、对并发的支持
插入数据
INSERT INTO shop.clickstream
VALUES ('customer1', '2021-10-02', 'add_to_cart', 'home_enter', 568239 )
查询数据
SELECT * FROM shop.clickstream
SELECT * FROM shop.clickstream WHERE time_stamp >= '2001-11-01'
数据类型
数值类型(整形,浮点数,定点数)
整型
- 固定长度的整型,包括有符号整型或无符号整型 IntX X是位的意思,1Byte字节=8bit位
有符号整型范围
Int8 — [-128 : 127] Int16 — [-32768 : 32767] Int32 — [-2147483648 : 2147483647] Int64 — [-9223372036854775808 : 9223372036854775807] Int128 — [-170141183460469231731687303715884105728 : 170141183460469231731687303715884105727] Int256 — [-57896044618658097711785492504343953926634992332820282019728792003956564819968 : 57896044618658097711785492504343953926634992332820282019728792003956564819967] 无符号整型范围
UInt8 — [0 : 255] UInt16 — [0 : 65535] UInt32 — [0 : 4294967295] UInt64 — [0 : 18446744073709551615] UInt128 — [0 : 340282366920938463463374607431768211455] UInt256 — [0 : 115792089237316195423570985008687907853269984665640564039457584007913129639935]
浮点型(存在精度损失问题)
- 建议尽可能以整型形式存储数据
- Float32 - mysql里面的float类型
- Float64 - mysql里面的double类型
Decimal类型
需要要求更高的精度的数值运算,则需要使用定点数
一般金额字段、汇率、利率等字段为了保证小数点精度,都使用 Decimal
Clickhouse提供了Decimal32,Decimal64,Decimal128三种精度的定点数
用Decimal(P,S)来定义:
- P代表精度(Precise),表示总位数(整数部分 + 小数部分)
- S代表规模(Scale),表示小数位数
例子:Decimal(10,2) 小数部分2位,整数部分 8位(10-2)
也可以使用Decimal32(S)、Decimal64(S)和Decimal128(S)的方式来表示
CREATE TABLE shop.clickstream1 (
customer_id String,
time_stamp Date,
click_event_type String,
page_code FixedString(20),
source_id UInt64,
money Decimal(2,1)
)
ENGINE = MergeTree()
ORDER BY (time_stamp) INSERT INTO shop.clickstream1
VALUES ('customer1', '2021-10-02', 'add_to_cart', 'home_enter', 568239,2.11 )
字符串类型
UUID
- 通用唯一标识符(UUID)是由一组32位数的16进制数字所构成,用于标识记录
61f0c404-5cb3-11e7-907b-a6006ad3dba0
要生成UUID值,ClickHouse提供了 generateuidv4 函数。
如果在插入新记录时未指定UUID列的值,则UUID值将用零填充
00000000-0000-0000-0000-000000000000
- 建表和插入例子
CREATE TABLE t_uuid (x UUID, y String) ENGINE=TinyLog INSERT INTO t_uuid SELECT generateUUIDv4(), 'Example 1'
FixedString固定字符串类型(相对少用)
类似MySQL的Char类型,属于定长字符,固定长度 N 的字符串(N 必须是严格的正自然数)
如果字符串包含的字节数少于`N’,将对字符串末尾进行空字节填充。
如果字符串包含的字节数大于
N,将抛出Too large value for FixedString(N)异常。当数据的长度恰好为N个字节时,
FixedString类型是高效的,在其他情况下,这可能会降低效率应用场景
- ip地址二进制表示的IP地址
- 语言代码(ru_RU, en_US … )
- 货币代码(USD, RUB …
String 字符串类型
- 字符串可以任意长度的。它可以包含任意的字节集,包含空字节
- 字符串类型可以代替其他 DBMSs中的 VARCHAR、BLOB、CLOB 等类型
- ClickHouse 没有编码的概念,字符串可以是任意的字节集,按它们原本的方式进行存储和输出
时间类型
Date
- 日期类型,用两个字节存储,表示从 1970-01-01 (无符号) 到当前的日期值,支持字符串形式写入
- 上限是2106年,但最终完全支持的年份为2105
DateTime
- 时间戳类型。用四个字节(无符号的)存储 Unix 时间戳,支持字符串形式写入
- 时间戳类型值精确到秒
- 值的范围: [1970-01-01 00:00:00, 2106-02-07 06:28:15]
DateTime64
- 此类型允许以日期(date)加时间(time)的形式来存储一个时刻的时间值,具有定义的亚秒精度
- 值的范围: [1925-01-01 00:00:00, 2283-11-11 23:59:59.99999999] (注意: 最大值的精度是8)
枚举类型
包括
Enum8和Enum16类型,Enum保存'string'= integer的对应关系在 ClickHouse 中,尽管用户使用的是字符串常量,但所有含有
Enum数据类型的操作都是按照包含整数的值来执行。这在性能方面比使用String数据类型更有效。Enum8用'String'= Int8对描述。Enum16用'String'= Int16对描述。
创建一个带有一个枚举
Enum8('home' = 1, 'detail' = 2, 'pay'=3)类型的列
CREATE TABLE t_enum
(
page_code Enum8('home' = 1, 'detail' = 2,'pay'=3)
)
ENGINE = TinyLog
- 插入, page_code 这列只能存储类型定义中列出的值:
'home'或`'detail' 或 'pay'。如果您尝试保存任何其他值,ClickHouse 抛出异常
#插入成功
INSERT INTO t_enum VALUES ('home'), ('detail') #插入报错
INSERT INTO t_enum VALUES ('home1') #查询
SELECT * FROM t_enum
布尔值
- 旧版以前没有单独的类型来存储布尔值。可以使用 UInt8 类型,取值限制为 0 或 1
- 新增里面新增了Bool
CREATE TABLE shop.clickstream2 (
customer_id String,
time_stamp Date,
click_event_type String,
page_code FixedString(20),
source_id UInt64,
money Decimal(2,1),
is_new Bool
)
ENGINE = MergeTree()
ORDER BY (time_stamp) DESCRIBE shop.clickstream2 INSERT INTO shop.clickstream2
VALUES ('customer1', '2021-10-02', 'add_to_cart', 'home_enter', 568239, 3.8,1)
查看当前版本支持的数据类型
select * from system.data_type_families
- case_insensitive 选项为1 表示大小写不敏感,字段类型不区分大小写
- 为0 表示大小写敏感,即字段类型需要严格区分大小写
- 里面很多数据类型,记住常用的即可

Mysql数据类型对比
| ClickHouse | Mysql | 说明 |
|---|---|---|
| UInt8 | UNSIGNED TINYINT | |
| Int8 | TINYINT | |
| UInt16 | UNSIGNED SMALLINT | |
| Int16 | SMALLINT | |
| UInt32 | UNSIGNED INT, UNSIGNED MEDIUMINT | |
| Int32 | INT, MEDIUMINT | |
| UInt64 | UNSIGNED BIGINT | |
| Int64 | BIGINT | |
| Float32 | FLOAT | |
| Float64 | DOUBLE | |
| Date | DATE | |
| DateTime | DATETIME, TIMESTAMP | |
| FixedString | BINARY |
常见SQL语法和注意事项
官方文档
ClickHouse语法和常规SQL语法类似,多数都是支持的
创建表
CREATE TABLE shop.clickstream3 (
customer_id String,
time_stamp Date,
click_event_type String,
page_code FixedString(20),
source_id UInt64,
money Decimal(2,1),
is_new Bool
)
ENGINE = MergeTree()
ORDER BY (time_stamp)
查看表结构
DESCRIBE shop.clickstream3
查询
SELECT * FROM shop.clickstream3
插入
INSERT INTO shop.clickstream3
VALUES ('customer2', '2021-10-02', 'add_to_cart', 'home_enter', 568239,2.1, False )
更新和删除
在OLAP数据库中,可变数据(Mutable data)通常是不被欢迎的,早期ClickHouse是不支持,后来版本才有
不支持事务,建议批量操作,不要高频率小数据量更新删除
删除和更新是一个异步操作的过程,语句提交立刻返回,但不一定已经完成了
- 判断是否完成
SELECT database, table, command, create_time, is_done FROM system.mutations LIMIT 20

更新
ALTER TABLE shop.clickstream3 UPDATE click_event_type = 'pay' where customer_id = 'customer2';
删除
ALTER TABLE shop.clickstream3 delete where customer_id = 'customer2';
分片-分区-副本
什么是ClickHouse的分区
分区是表的分区,把一张表的数据分成N多个区块,分区后的表还是一张表,数据处理还是由自己来完成
PARTITION BY,指的是一个表按照某一列数据(比如日期)进行分区,不同分区的数据会写入不同的文件中
建表时加入partition概念,可以按照对应的分区字段,允许查询在指定了分区键的条件下,尽可能的少读取数据
create table shop.order_merge_tree(
id UInt32,
sku_id String,
out_trade_no String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree()
partition by toYYYYMMDD(create_time)
order by (id,sku_id)
primary key (id);
注意
- 不是所有的表引擎都可以分区,合并树(MergeTree) 系列的表引擎才支持数据分区,Log系列引擎不支持
什么是ClickHouse的分片
- Shard 分片是把数据库横向扩展(Scale Out)到多个物理节点上的一种有效的方式
- 复用了数据库的分区概念,相当于在原有的分区下作为第二层分区,ClickHouse会将数据分为多个分片,并且分布到不同节点上,再通过 Distributed 表引擎把数据拼接起来一同使用
- Sharding机制使得ClickHouse可以横向线性拓展,构建大规模分布式集群,但需要避免数据倾斜问题
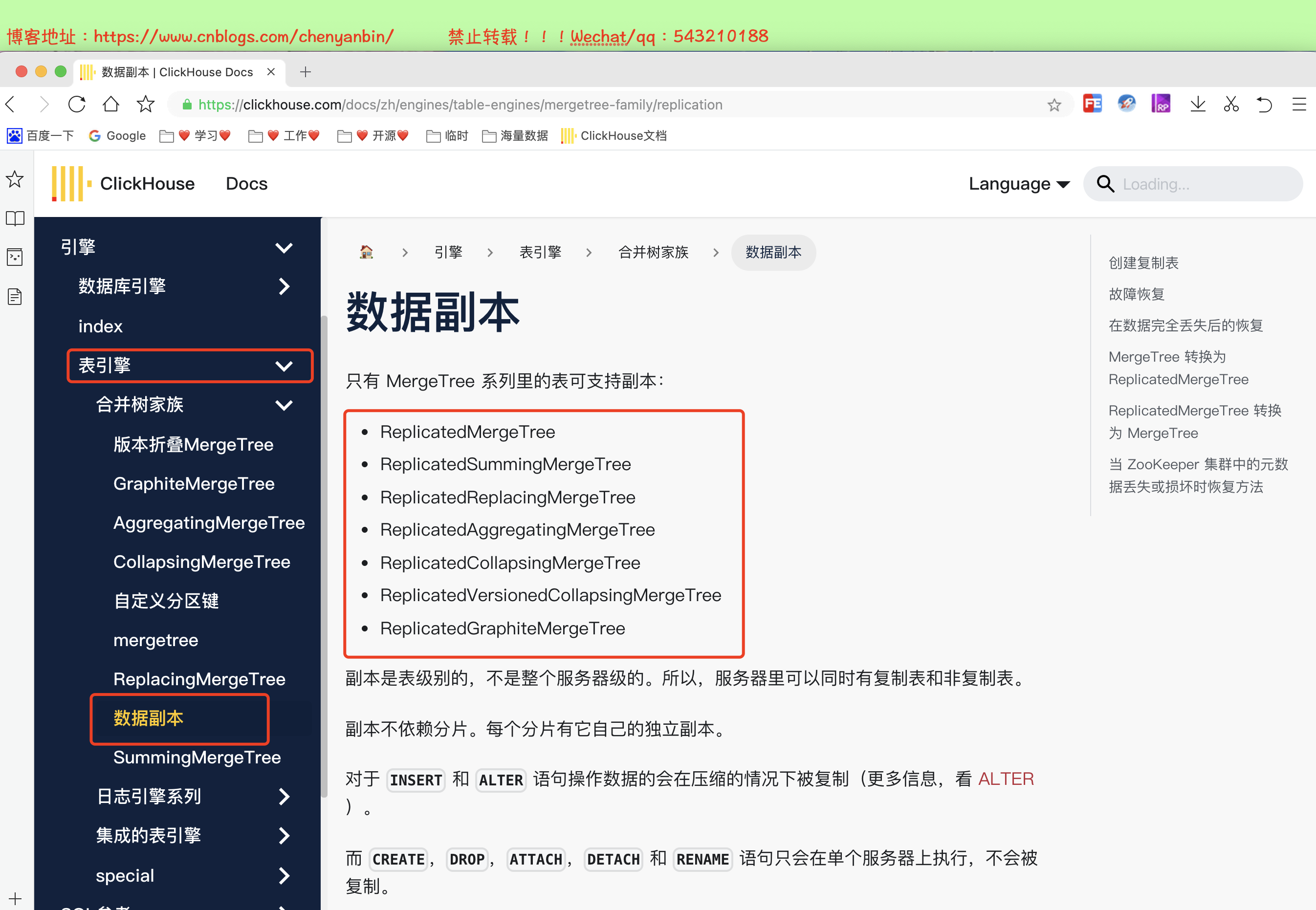
什么是ClickHouse的副本
- 两个相同数据的表, 作用是为了数据备份与安全,保障数据的高可用性,
- 即使一台 ClickHouse 节点宕机,那么也可以从其他服务器获得相同的数据
- 类似Mysql主从架构,主节点宕机,从节点也能提供服务
总结
- 数据分区-允许查询在指定了分区键的条件下,尽可能的少读取数据
- 数据分片-允许多台机器/节点同并行执行查询,实现了分布式并行计算
ClickHouse常见引擎
Log系列
最小功能的轻量级引擎,当需要快速写入许多小表并在以后整体读取它们时效果最佳,一次写入多次查询
种类
- TinyLog、StripLog、Log
MergeTree系列
CLickhouse最强大的表引擎,有多个不同的种类
适用于高负载任务的最通用和功能最强大的表引擎,可以快速插入数据并进行后续的后台数据处理
支持主键索引、数据分区、数据副本等功能特性和一些其他引擎不支持的其他功能
种类
- MergeTree、ReplacingMergeTree
- SummingMergeTree、AggregatingMergeTree
- CollapsingMergeTree、VersionedCollapsingMergeTree、GraphiteMergeTree
外部存储引擎系列
能够直接从其它的存储系统读取数据,例如直接读取 HDFS 的文件或者 MySQL 数据库的表,这些表引擎只负责元数据管理和数据查询
种类
- HDFS、Mysql
- Kafka、JDBC
其他特定引擎
Memory
- 原生数据直接存储内存,性能高,重启则消失,读写不会阻塞,不支持索引,主要是测试使用
Distributed
- 分布式引擎本身不存储数据, 但可以在多个服务器上进行分布式查询。 读是自动并行的。读取时,远程服务器表的索引(如果有的话)会被使用
File
- 数据源是以 Clickhouse 支持的一种输入格式(TabSeparated,Native等)存储数据的文件
- 从 ClickHouse 导出数据到文件,将数据从一种格式转换为另一种格式
Merge
- Merge 引擎 (不要跟 MergeTree 引擎混淆) 本身不存储数据,但可用于同时从任意多个其他的表中读取数据。读是自动并行的,不支持写入,读取时,那些被真正读取到数据的表的索引(如果有的话)会被使用
Set、Buffer、Dictionary等
ClickHouse的MergeTree表引擎
特点
ClickHouse 不要求主键唯一,所以可以插入多条具有相同主键的行。
如果指定了【分区键】则可以使用【分区】,可以通过PARTITION 语句指定分区字段,合理使用数据分区,可以有效减少查询时数据文件的扫描范围
在相同数据集的情况下 ClickHouse 中某些带分区的操作会比普通操作更快,查询中指定了分区键时 ClickHouse 会自动截取分区数据,这也有效增加了查询性能
支持数据副本和数据采样
- 副本是表级别的不是整个服务器级的,所以服务器里可以同时有复制表和非复制表。
- 副本不依赖分片,每个分片有它自己的独立副本
语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
语法解析
- 【必填】
ENGINE- 引擎名和参数。ENGINE = MergeTree().MergeTree引擎没有参数
【必填】
ORDER BY— 排序键,可以是一组列的元组或任意的表达式- 例如:
ORDER BY (CounterID, EventDate)。如果没有使用PRIMARY KEY显式指定的主键,ClickHouse 会使用排序键作为主键 - 如果不需要排序,可以使用
ORDER BY tuple()
- 例如:
【选填】
PARTITION BY— 分区键 ,可选项- 要按月分区,可以使用表达式
toYYYYMM(date_column),这里的date_column是一个 Date 类型的列, 分区名的格式会是"YYYYMM" - 分区的好处是降低扫描范围提升速度,不填写默认就使用一个分区
- 要按月分区,可以使用表达式
【选填】
PRIMARY KEY-主键,作为数据的一级索引,但是不是唯一约束,和其他数据库区分- 如果要 选择与排序键不同的主键,在这里指定,可选项,
- 默认情况下主键跟排序键(由
ORDER BY子句指定)相同。 - 大部分情况下不需要再专门指定一个
PRIMARY KEY
PRIMARY KEY 主键必须是 order by 字段的前缀字段。
- 主键和排序字段这两个属性只设置一个时,另一个默认与它相同, 当两个都设置时,PRIMARY KEY必须为ORDER BY的前缀
- 比如ORDER BY (CounterID, EventDate),那主键需要是(CounterID )或 (CounterID, EventDate)
合并树MergeTree实战
建表
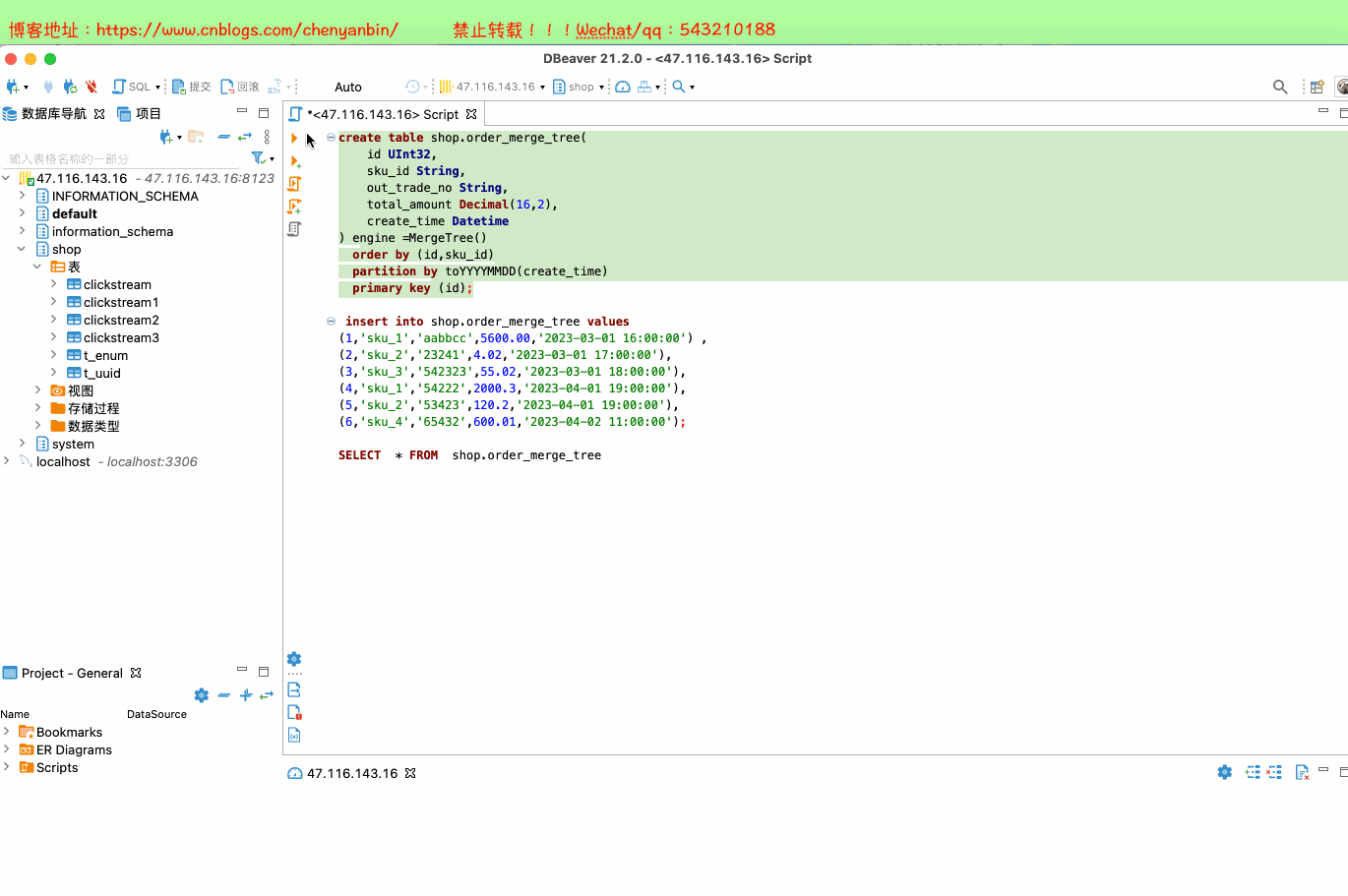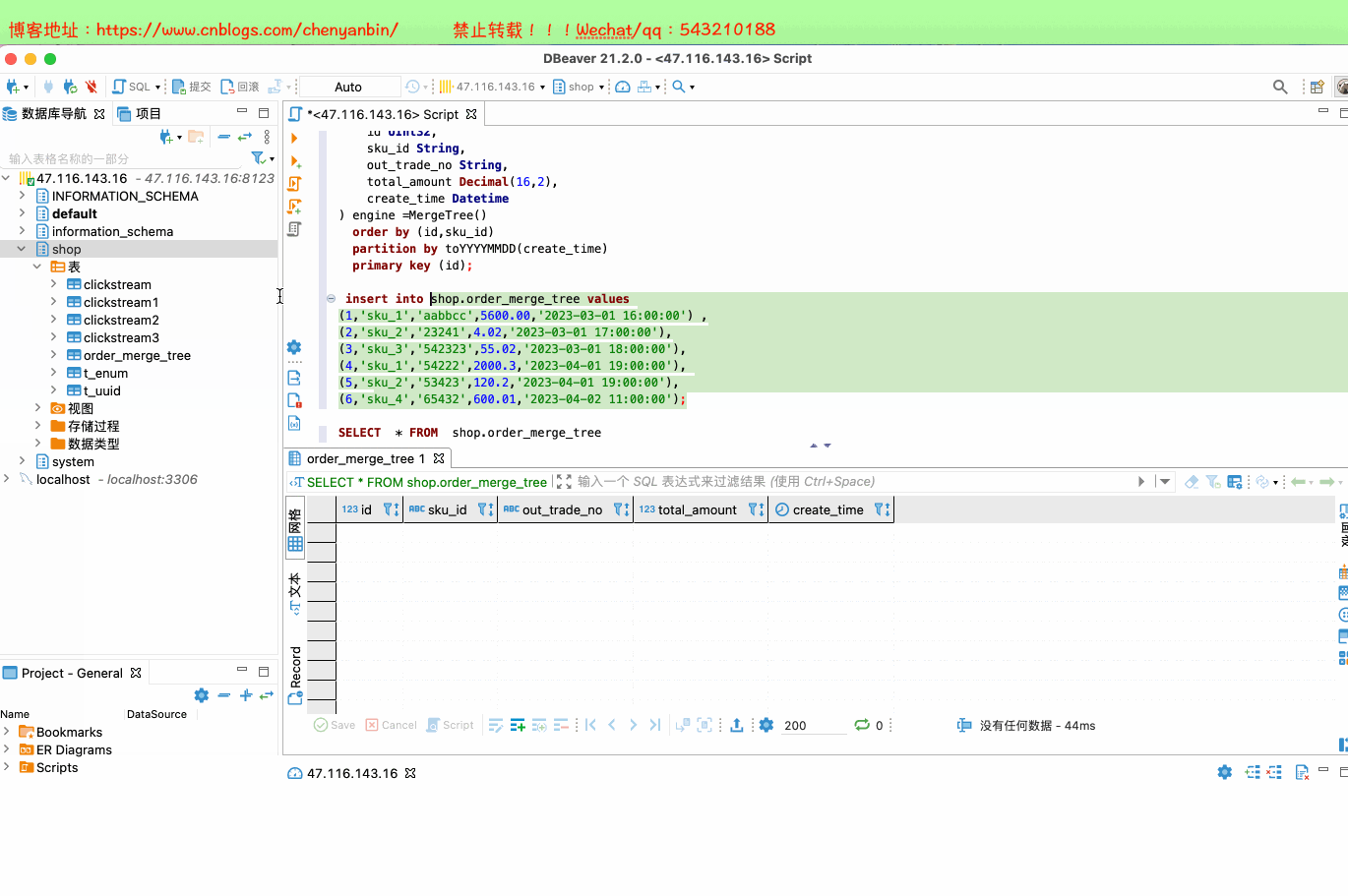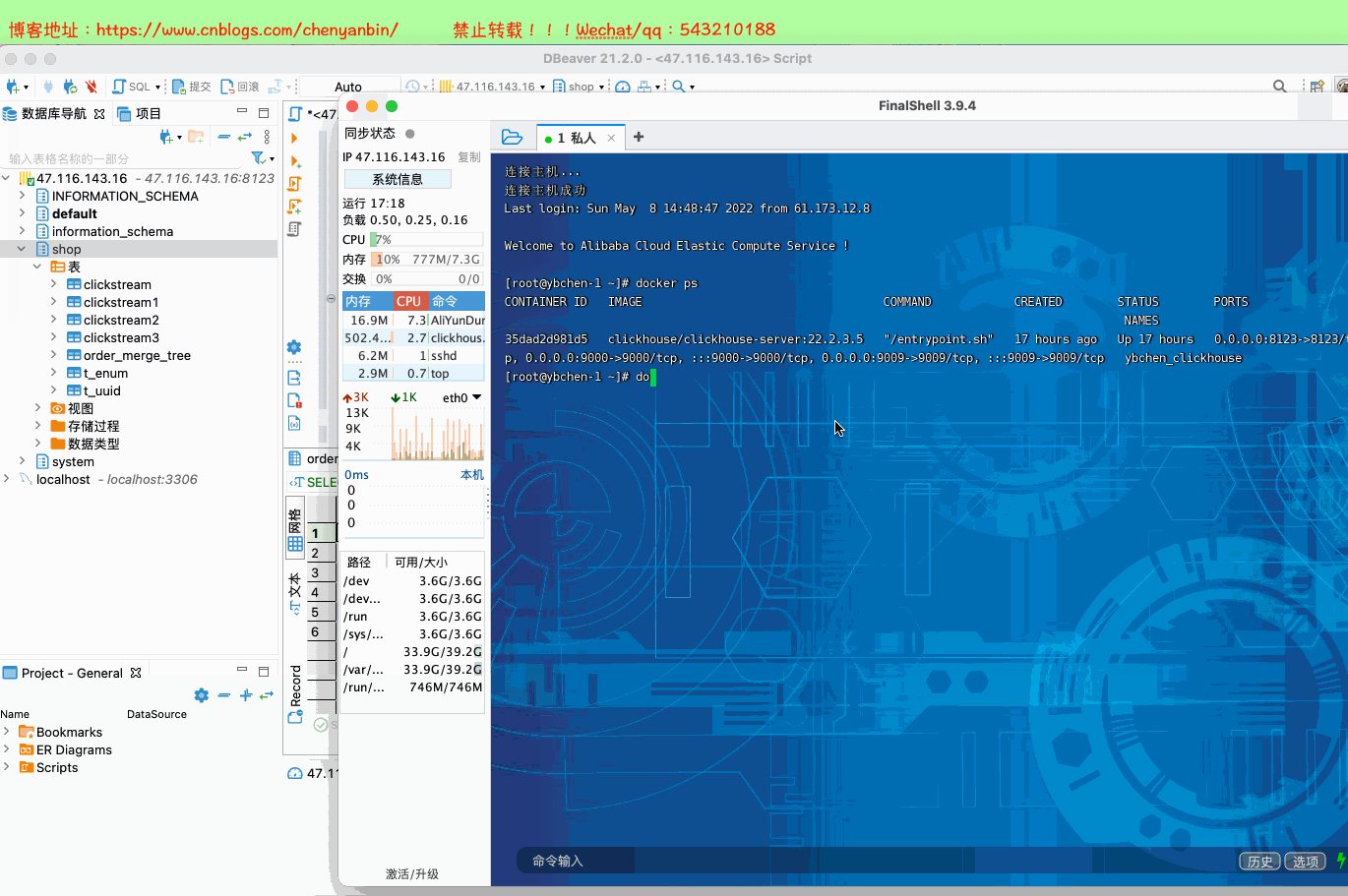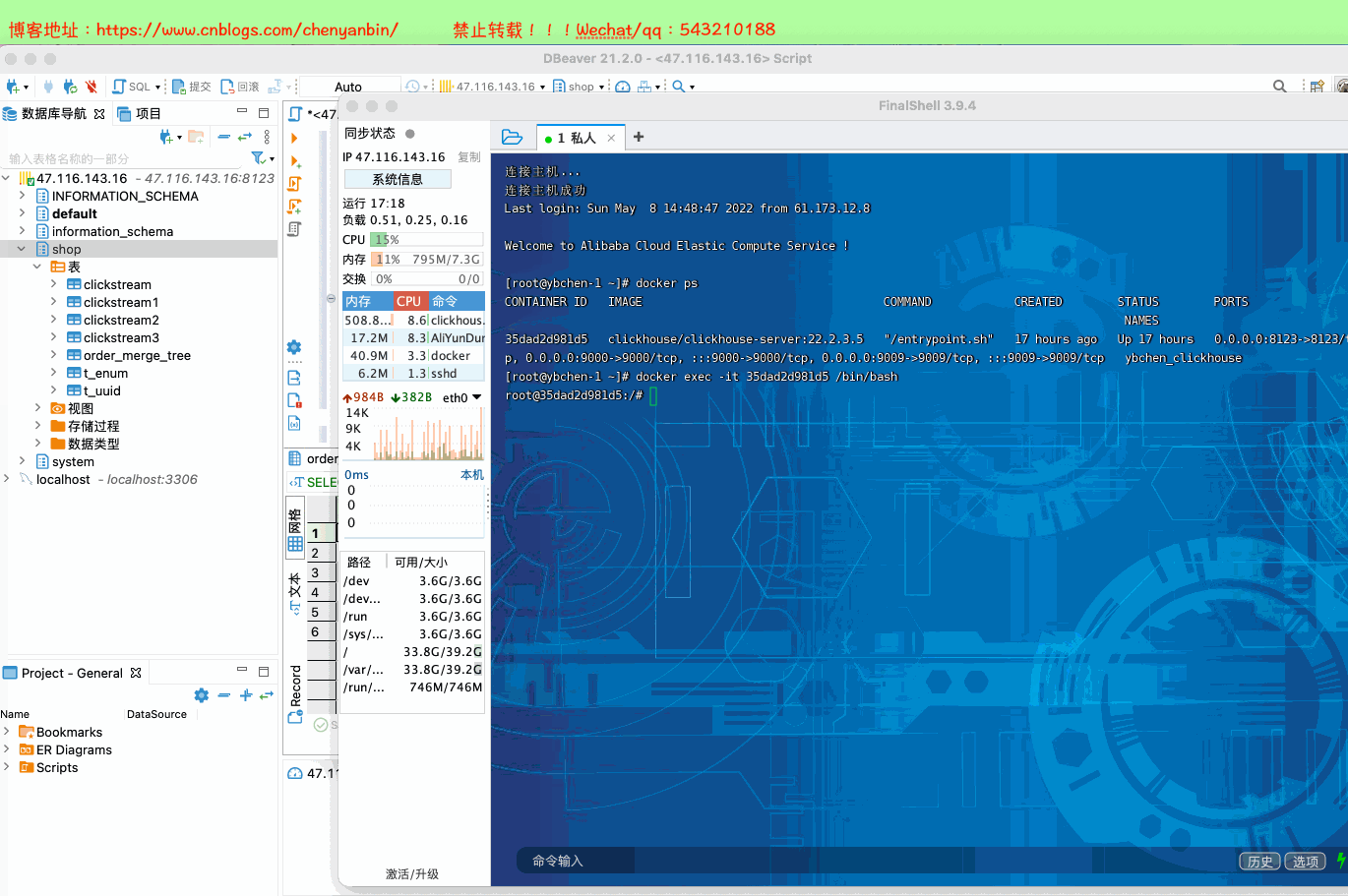
create table shop.order_merge_tree(
id UInt32,
sku_id String,
out_trade_no String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree()
order by (id,sku_id)
partition by toYYYYMMDD(create_time)
primary key (id);
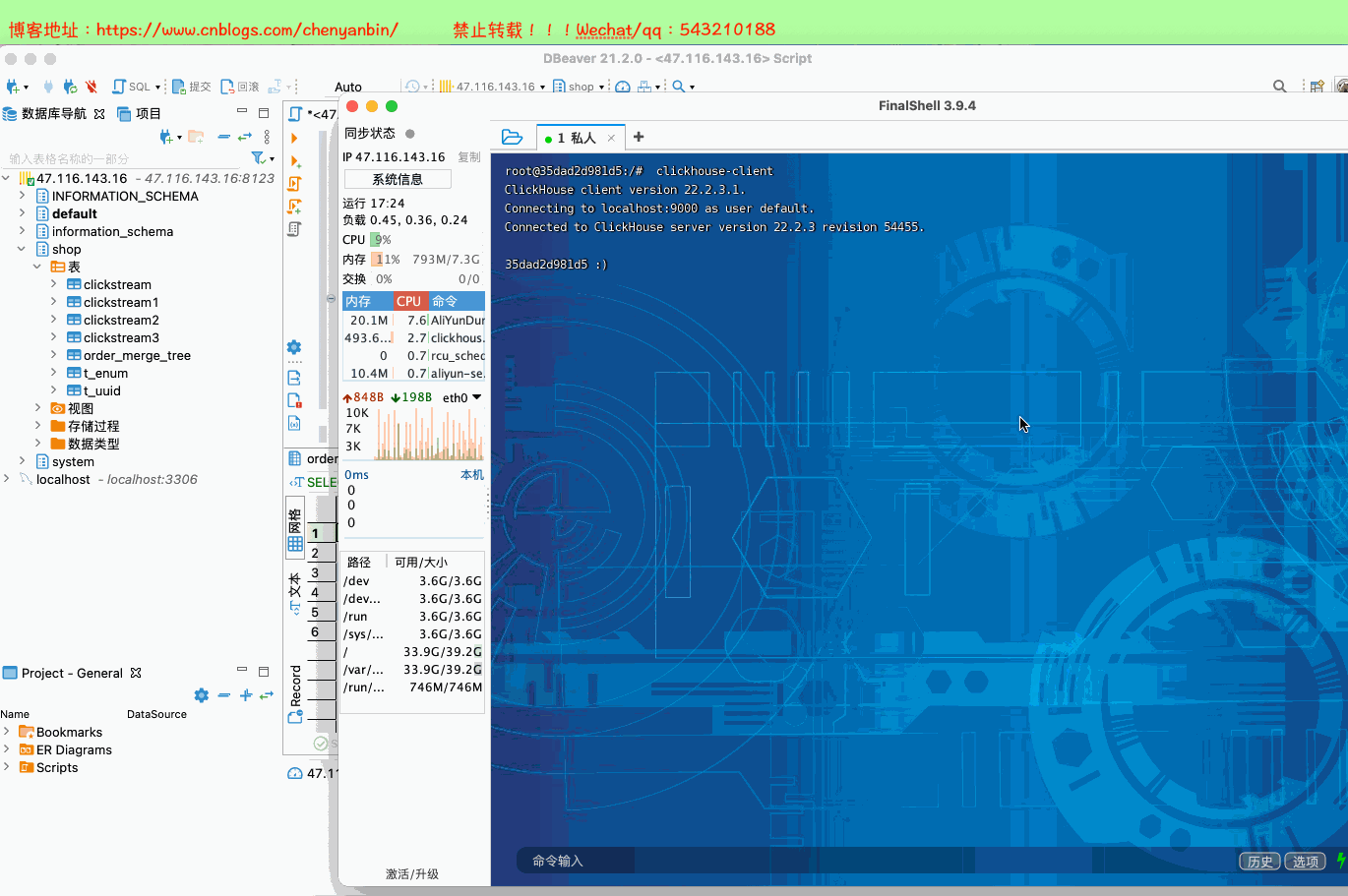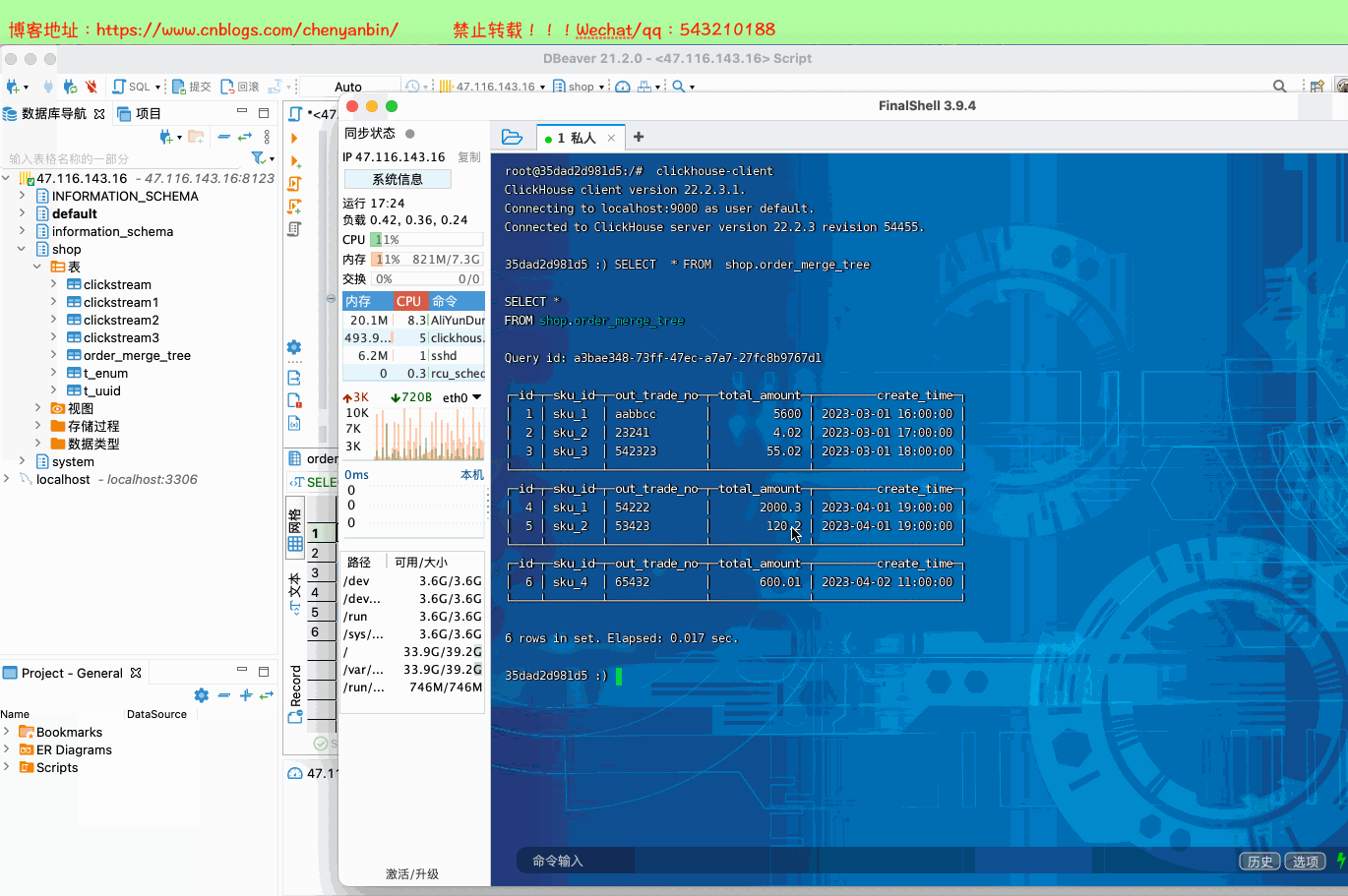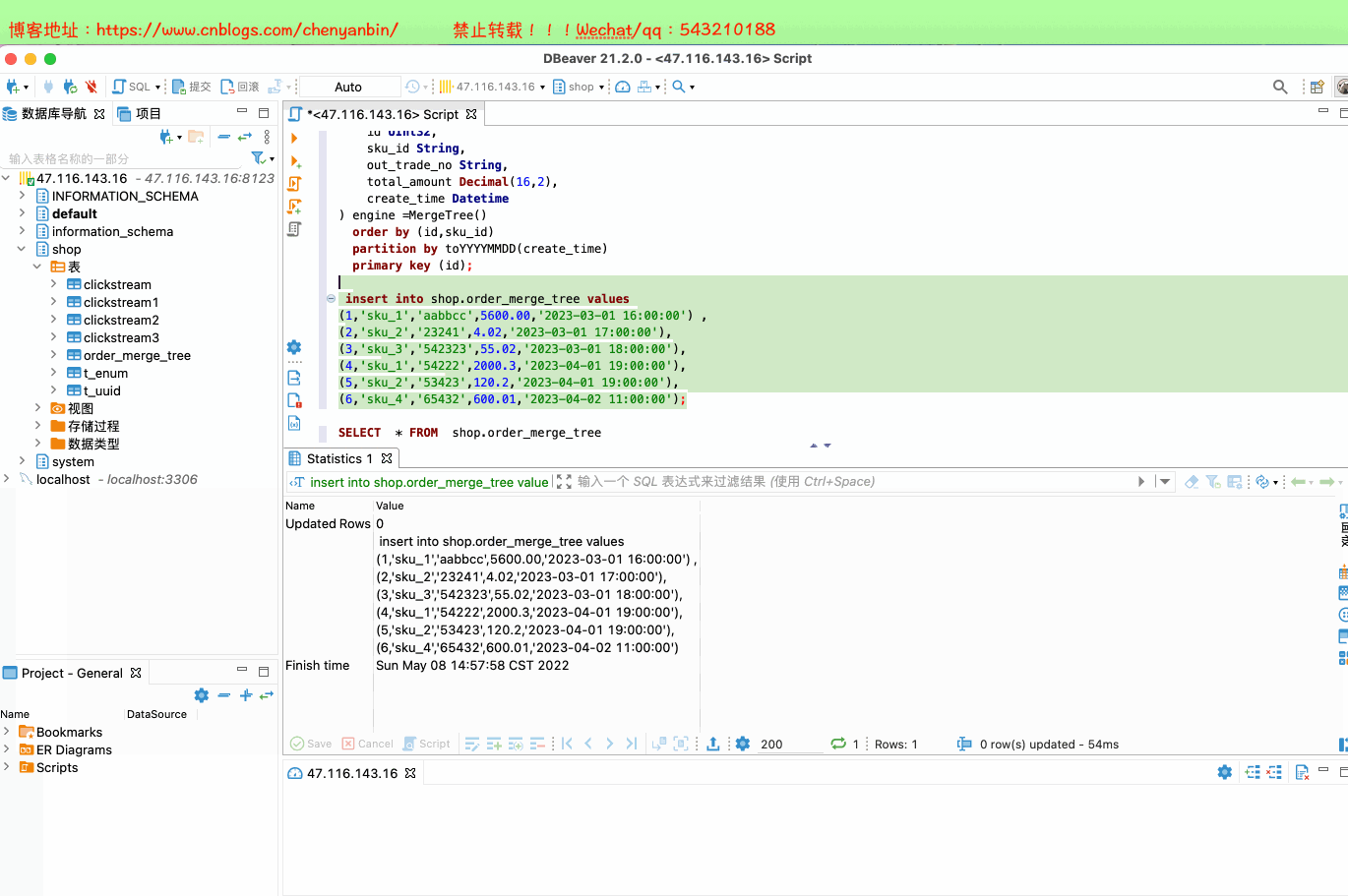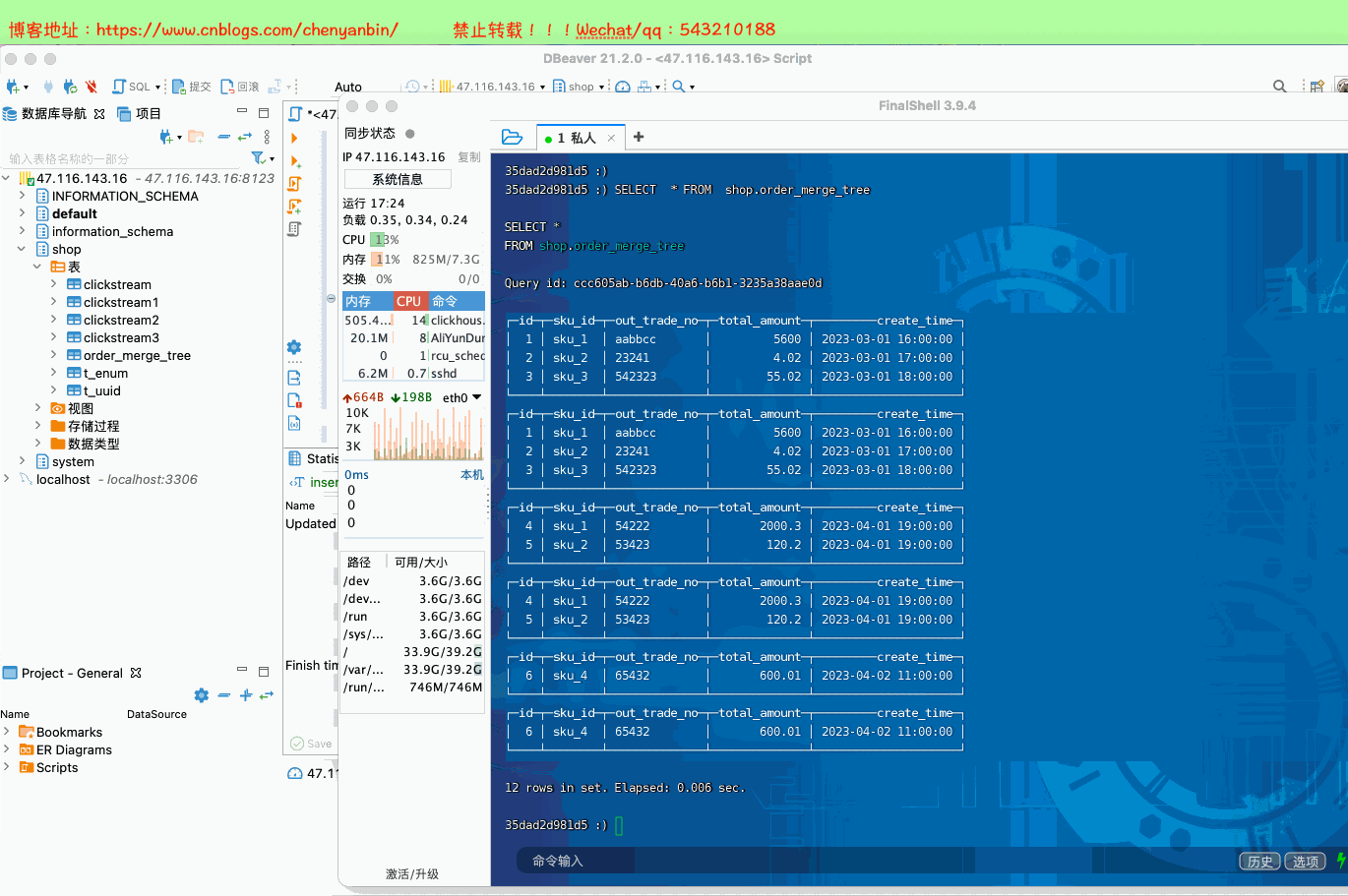
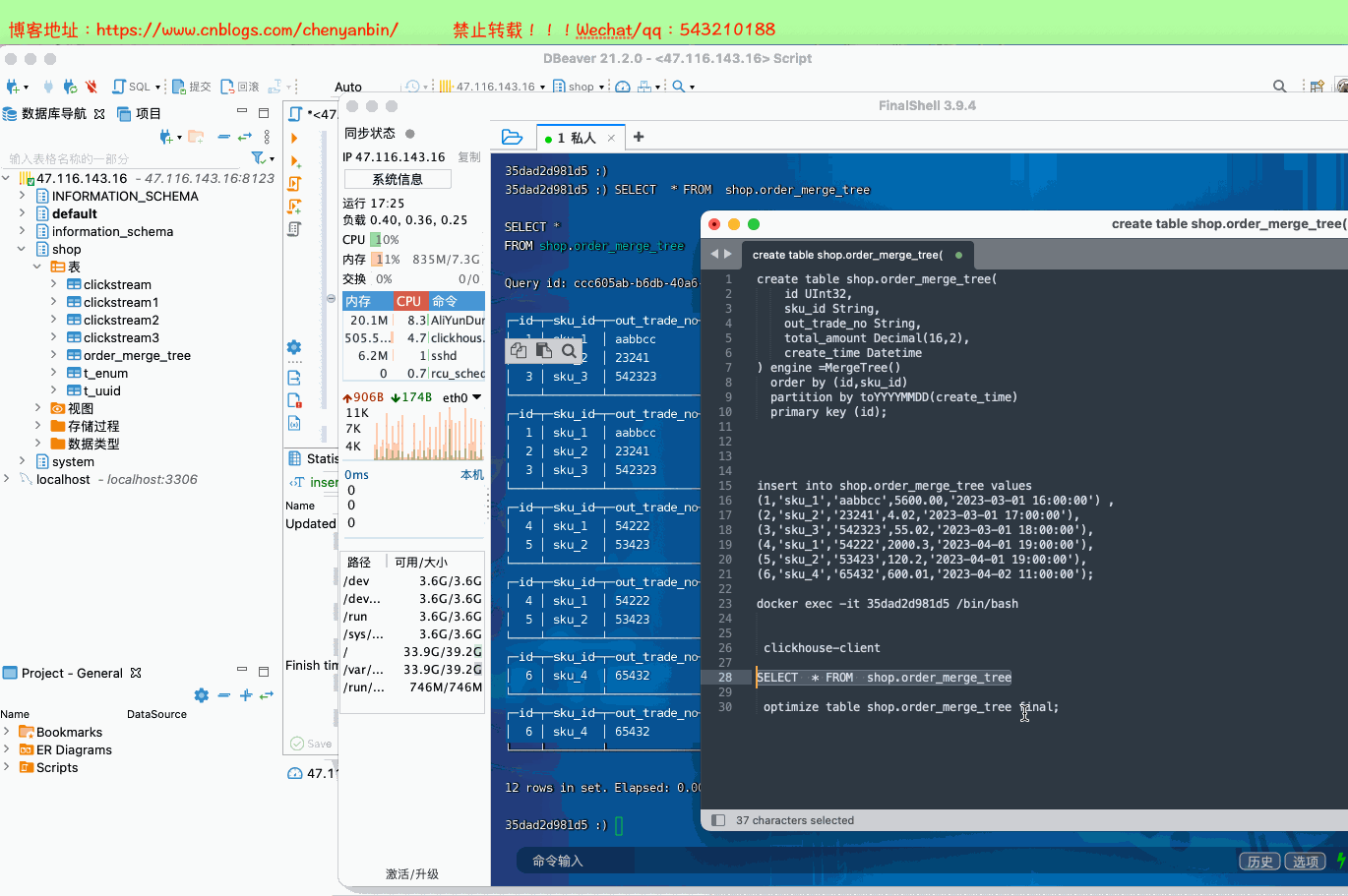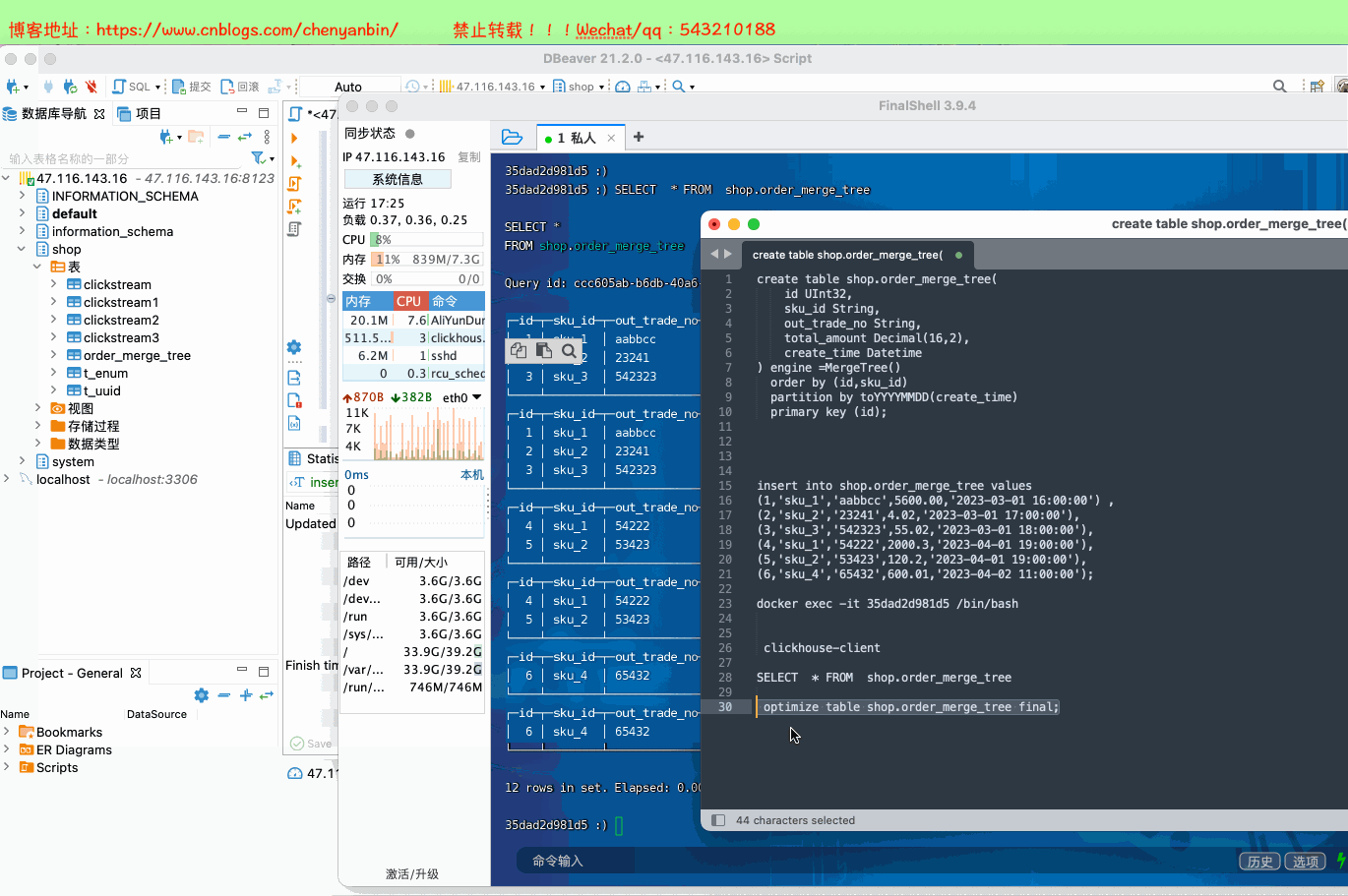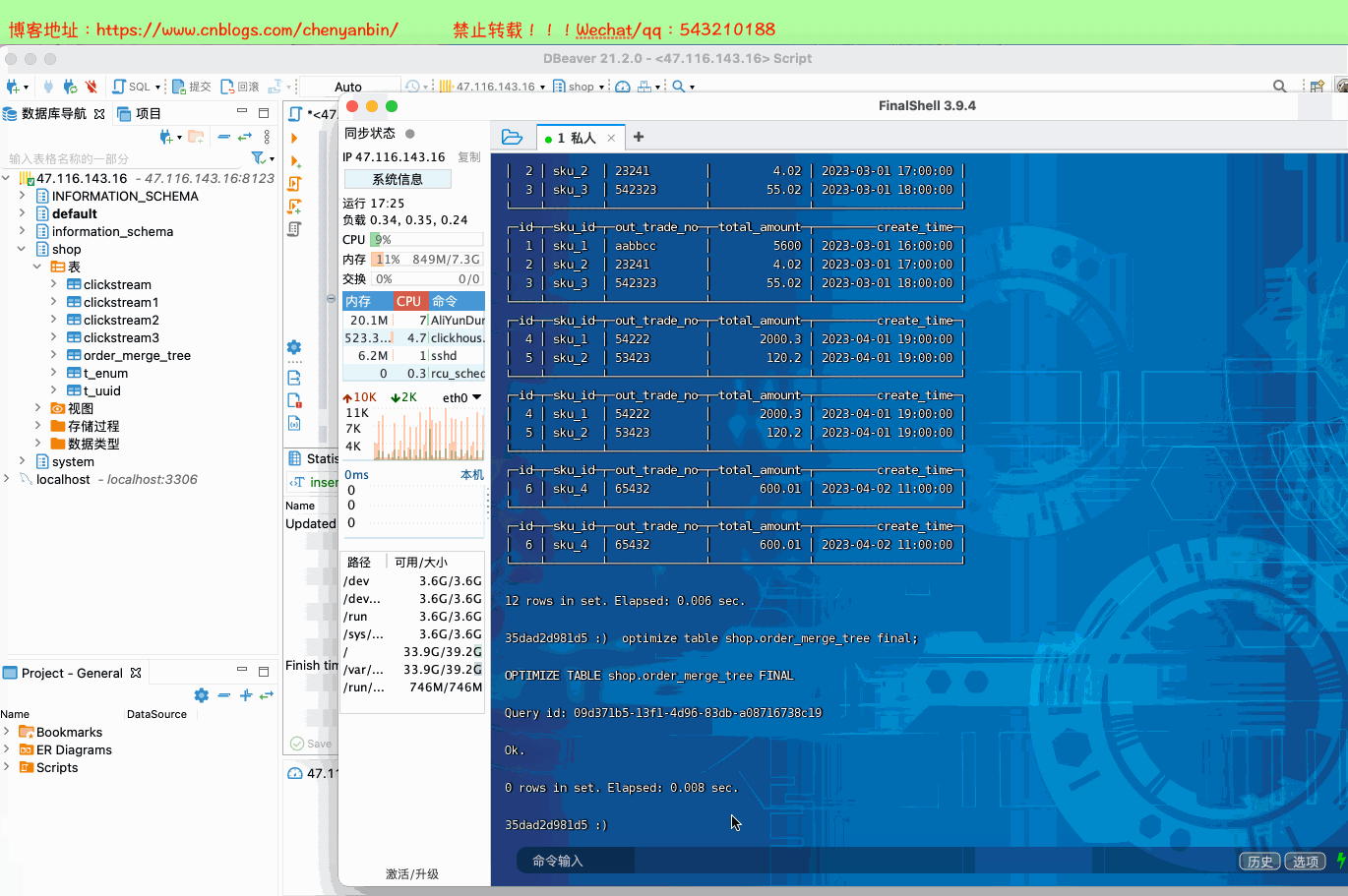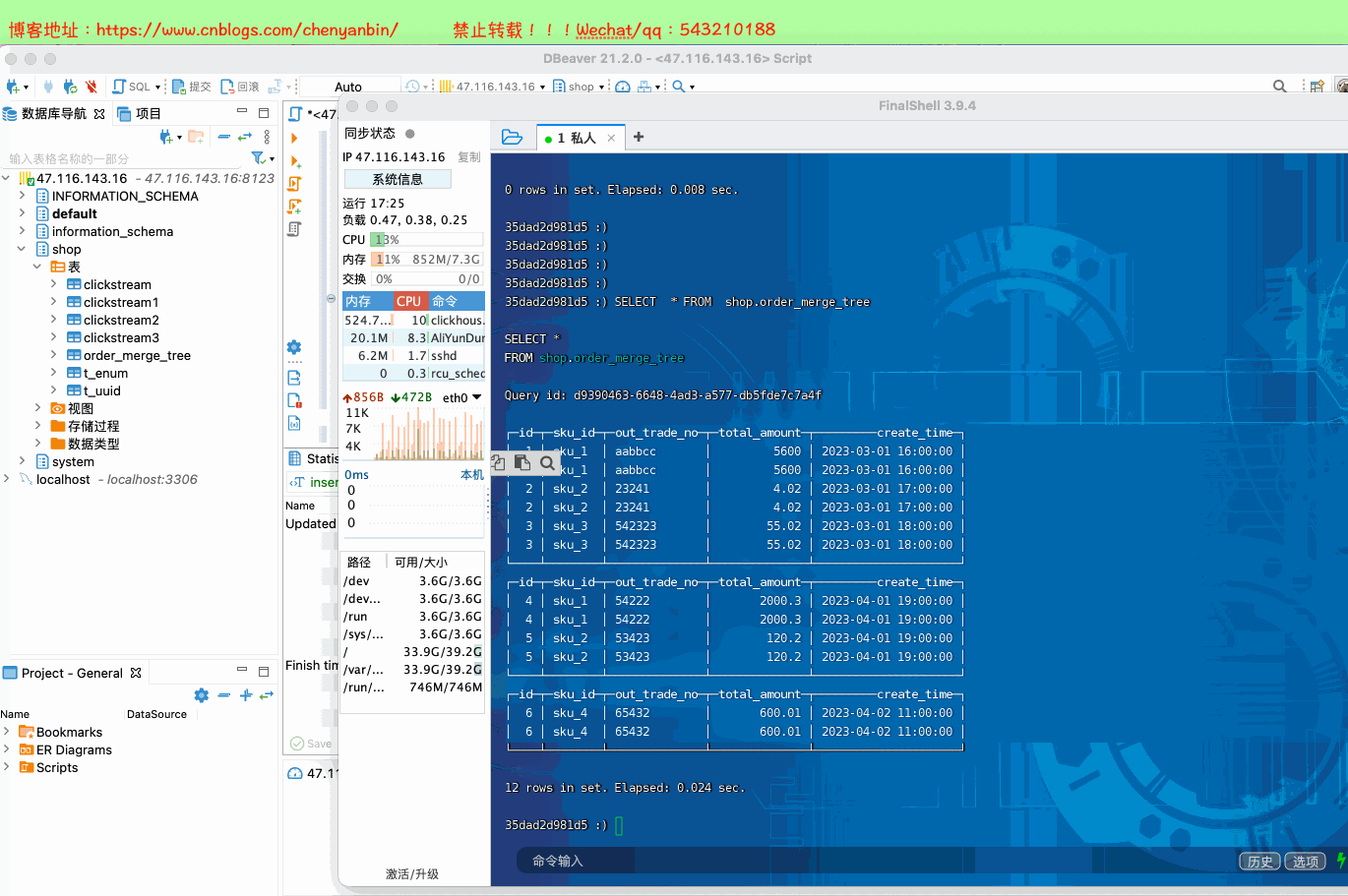
insert into shop.order_merge_tree values
(1,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,
(2,'sku_2','23241',4.02,'2023-03-01 17:00:00'),
(3,'sku_3','542323',55.02,'2023-03-01 18:00:00'),
(4,'sku_1','54222',2000.3,'2023-04-01 19:00:00'),
(5,'sku_2','53423',120.2,'2023-04-01 19:00:00'),
(6,'sku_4','65432',600.01,'2023-04-02 11:00:00');
进入容器
docker exec -it 35dad2d981d5 /bin/bash
分区合并验证
新的数据写入会有临时分区产生,不之间加入已有分区 写入完成后经过一定时间(10到15分钟),ClickHouse会自动化执行合并操作,将临时分区的数据合并到已有分区当中 optimize的合并操作是在后台执行的,无法预测具体执行时间点,除非是手动执行 通过手工合并( optimize table xxx final; ) 在数据量比较大的情况,尽量不要使用该命令,执行optimize要消耗大量时间
create table shop.order_merge_tree(
id UInt32,
sku_id String,
out_trade_no String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree()
order by (id,sku_id)
partition by toYYYYMMDD(create_time)
primary key (id); insert into shop.order_merge_tree values
(1,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,
(2,'sku_2','23241',4.02,'2023-03-01 17:00:00'),
(3,'sku_3','542323',55.02,'2023-03-01 18:00:00'),
(4,'sku_1','54222',2000.3,'2023-04-01 19:00:00'),
(5,'sku_2','53423',120.2,'2023-04-01 19:00:00'),
(6,'sku_4','65432',600.01,'2023-04-02 11:00:00'); docker exec -it 35dad2d981d5 /bin/bash clickhouse-client optimize table shop.order_merge_tree final;
不使用分区演示

create table shop.order_merge_tree22(
id UInt32,
sku_id String,
out_trade_no String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree()
order by (id,sku_id) primary key (id); insert into shop.order_merge_tree22 values
(1,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,
(2,'sku_2','23241',4.02,'2023-03-01 17:00:00'),
(3,'sku_3','542323',55.02,'2023-03-01 18:00:00'),
(4,'sku_1','54222',2000.3,'2023-04-01 19:00:00'),
(5,'sku_2','53423',120.2,'2023-04-01 19:00:00'),
(6,'sku_4','65432',600.01,'2023-04-02 11:00:00');
总结
- 使用过分区键,会通过分区键,将数据落到不同分区中,提升查询效率
- 没使用过分区键,数据全部落一个分区中
合并树ReplacingMergeTree实战

介绍
MergeTree的拓展,该引擎和 MergeTree 的不同之处在它会删除【排序键值】相同重复项,根据OrderBy字段
数据的去重只会在数据合并期间进行。合并会在后台一个不确定的时间进行,因此你无法预先作出计划。
有一些数据可能仍未被处理,尽管可以调用 OPTIMIZE 语句发起计划外的合并,但请不要依靠它,因为 OPTIMIZE 语句会引发对数据的大量读写
因此,ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现
注意去重访问
如果是有多个分区表,只在分区内部进行去重,不会跨分区
语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = ReplacingMergeTree([ver])
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
参数
ver— 版本列。类型为UInt*,Date或DateTime。可选参数。在数据合并的时候,
ReplacingMergeTree从所有具有相同排序键的行中选择一行留下:- 如果
ver列未指定,保留最后一条。 - 如果
ver列已指定,保留ver值最大的版本
- 如果
如何判断数据重复
- 在去除重复数据时,是以ORDER BY排序键为基准的,而不是PRIMARY KEY
- 若排序字段为两个,则两个字段都相同时才会去重
何时删除重复数据
- 在执行分区合并时触发删除重复数据,optimize的合并操作是在后台执行的,无法预测具体执行时间点,除非是手动执行
不同分区的重复数据不会被去重
- ReplacingMergeTree是以分区为单位删除重复数据的,在相同的数据分区内重复的数据才会被删除,而不同数据分区之间的重复数据依然不能被删除的
删除策略
- ReplacingMergeTree() 填入的参数为版本字段,重复数据就会保留版本字段值最大的。
- 如果不填写版本字段,默认保留插入顺序的最后一条数据
建表
ver表示的列只能是UInt*,Date和DateTime 类型
删除策略
- ReplacingMergeTree() 填入的参数为版本字段,重复数据就会保留版本字段值最大的。
- 如果不填写版本字段,默认保留插入顺序的最后一条数据
create table shop.order_relace_merge_tree(
id UInt32,
sku_id String,
out_trade_no String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplacingMergeTree(id)
order by (sku_id)
partition by toYYYYMMDD(create_time)
primary key (sku_id);
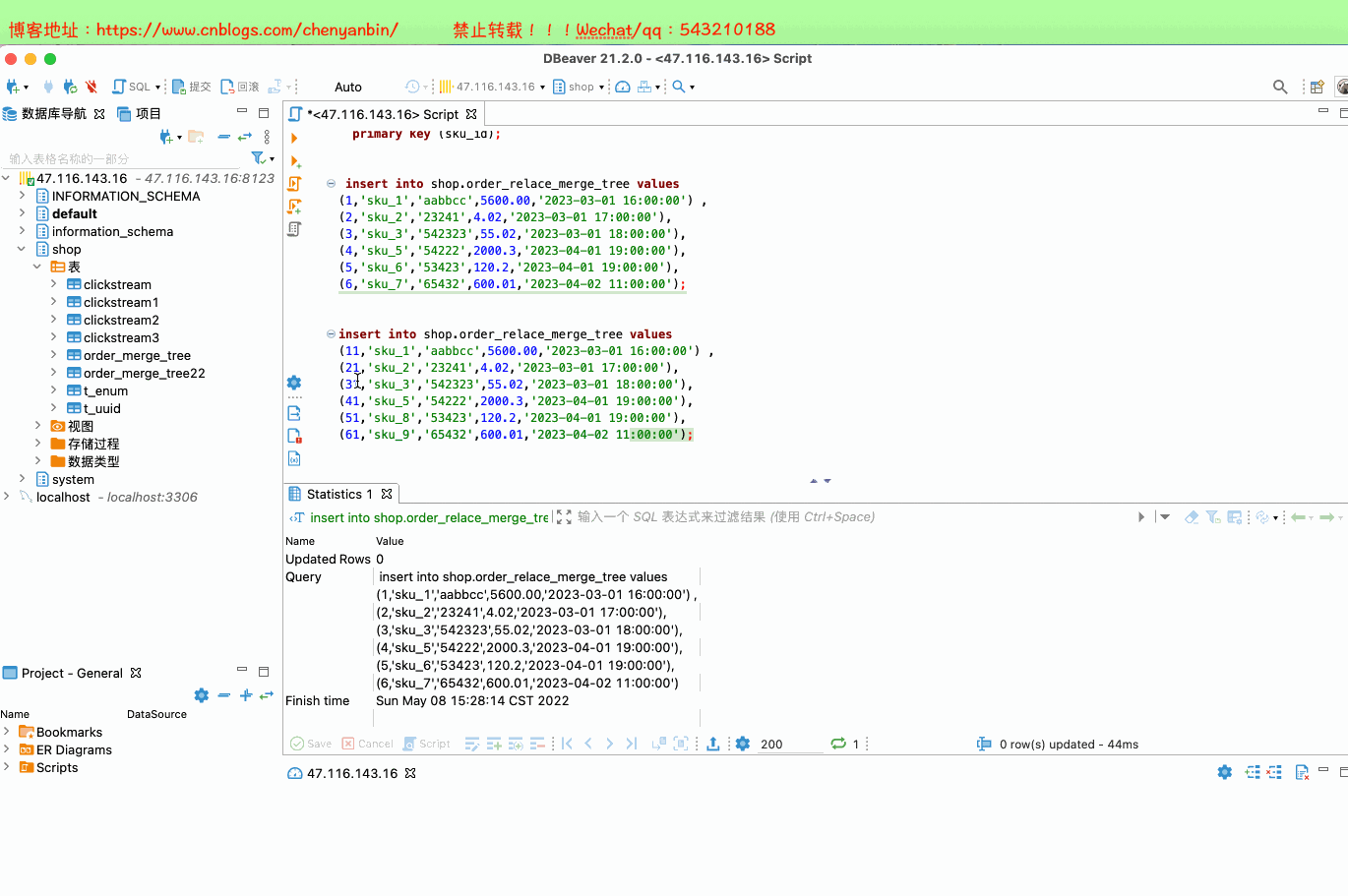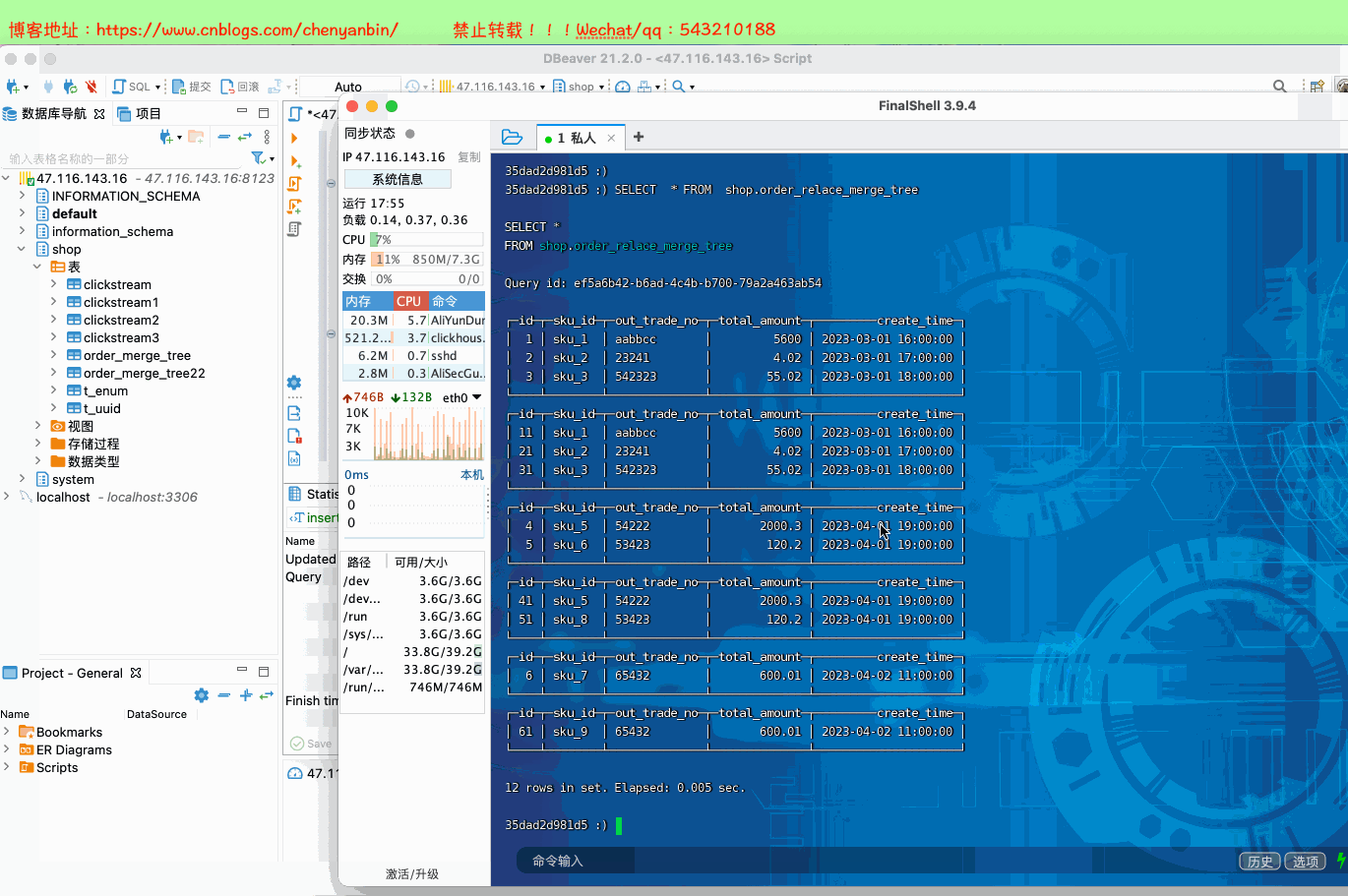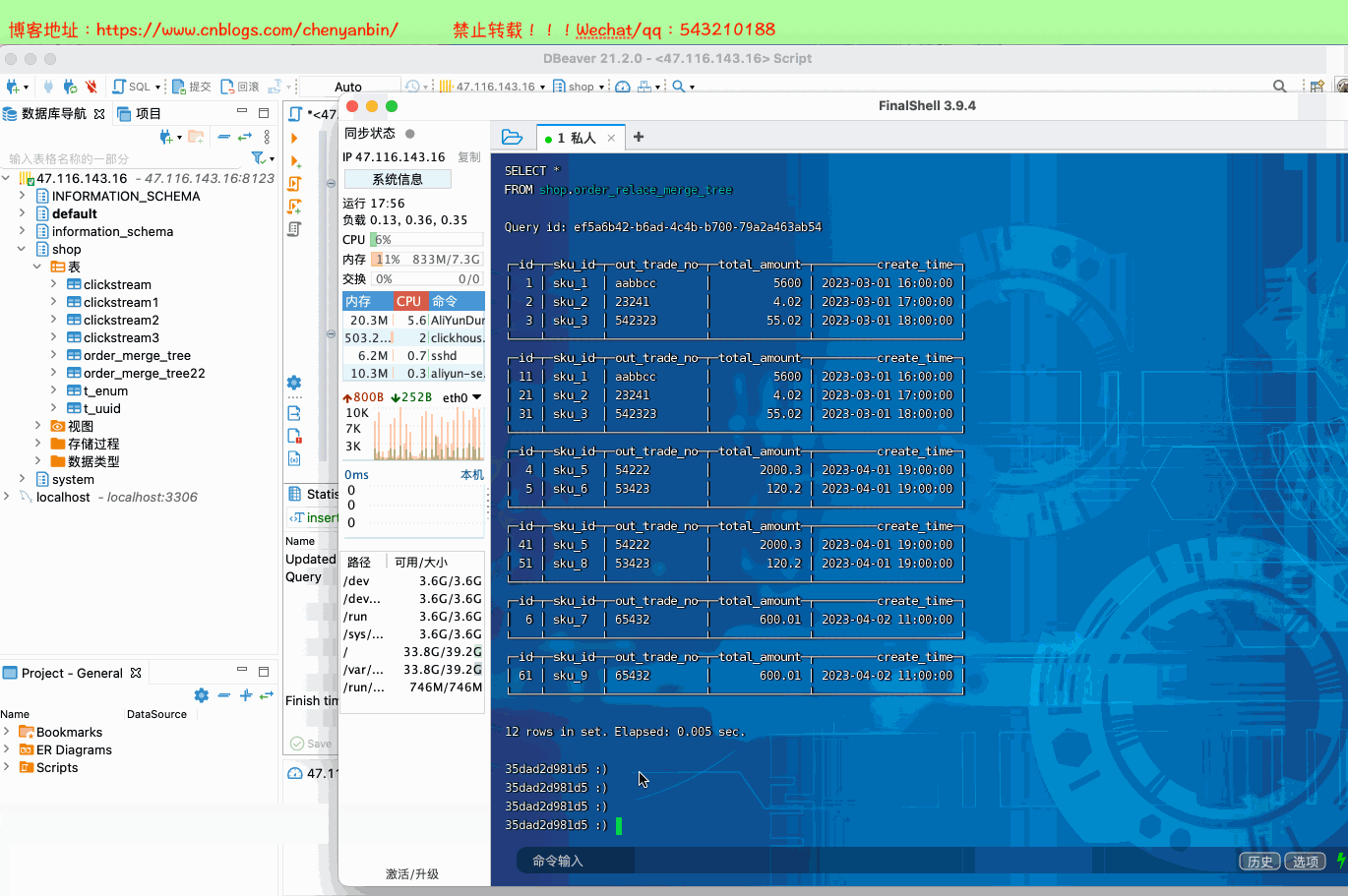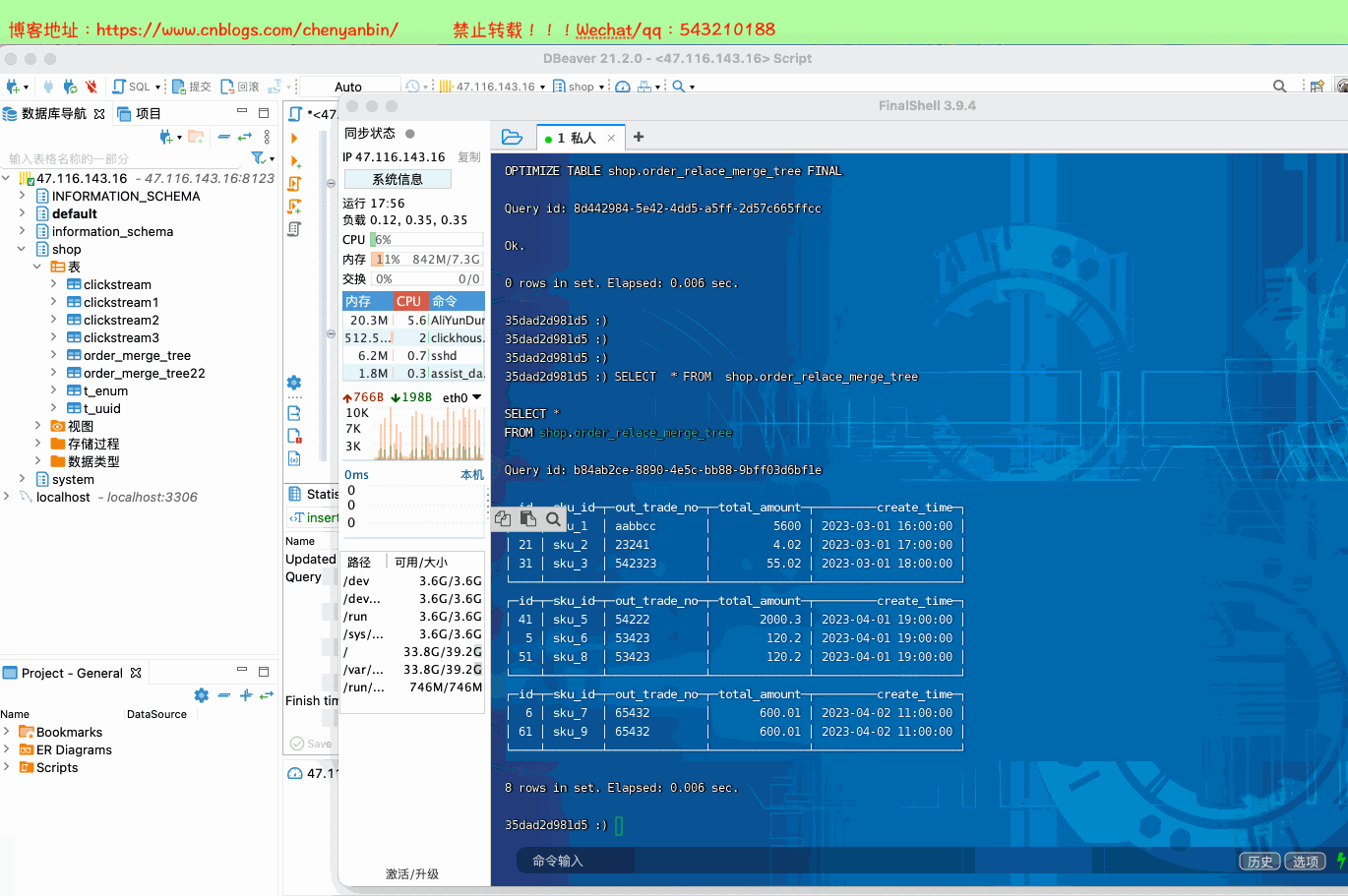
insert into shop.order_relace_merge_tree values
(1,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,
(2,'sku_2','23241',4.02,'2023-03-01 17:00:00'),
(3,'sku_3','542323',55.02,'2023-03-01 18:00:00'),
(4,'sku_5','54222',2000.3,'2023-04-01 19:00:00'),
(5,'sku_6','53423',120.2,'2023-04-01 19:00:00'),
(6,'sku_7','65432',600.01,'2023-04-02 11:00:00'); insert into shop.order_relace_merge_tree values
(11,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,
(21,'sku_2','23241',4.02,'2023-03-01 17:00:00'),
(31,'sku_3','542323',55.02,'2023-03-01 18:00:00'),
(41,'sku_5','54222',2000.3,'2023-04-01 19:00:00'),
(51,'sku_8','53423',120.2,'2023-04-01 19:00:00'),
(61,'sku_9','65432',600.01,'2023-04-02 11:00:00');
docker exec -it 35dad2d981d5 /bin/bash clickhouse-client SELECT * FROM shop.order_relace_merge_tree optimize table shop.order_relace_merge_tree final;
演示

create table shop.order_relace_merge_tree(
id UInt32,
sku_id String,
out_trade_no String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplacingMergeTree(id)
order by (sku_id)
partition by toYYYYMMDD(create_time)
primary key (sku_id); insert into shop.order_relace_merge_tree values
(1,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,
(2,'sku_2','23241',4.02,'2023-03-01 17:00:00'),
(3,'sku_3','542323',55.02,'2023-03-01 18:00:00'),
(4,'sku_5','54222',2000.3,'2023-04-01 19:00:00'),
(5,'sku_6','53423',120.2,'2023-04-01 19:00:00'),
(6,'sku_7','65432',600.01,'2023-04-02 11:00:00'); insert into shop.order_relace_merge_tree values
(11,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,
(21,'sku_2','23241',4.02,'2023-03-01 17:00:00'),
(31,'sku_3','542323',55.02,'2023-03-01 18:00:00'),
(41,'sku_5','54222',2000.3,'2023-04-01 19:00:00'),
(51,'sku_8','53423',120.2,'2023-04-01 19:00:00'),
(61,'sku_9','65432',600.01,'2023-04-02 11:00:00'); docker exec -it 35dad2d981d5 /bin/bash clickhouse-client SELECT * FROM shop.order_relace_merge_tree optimize table shop.order_relace_merge_tree final;
合并树SummingMergeTree实战

介绍
该引擎继承自 MergeTree,区别在于,当合并 SummingMergeTree 表的数据片段时,ClickHouse 会把所有具有 相同OrderBy排序键 的行合并为一行,该行包含了被合并的行中具有数值类型的列的汇总值。
类似group by的效果,这个可以显著的减少存储空间并加快数据查询的速度
推荐将该引擎和 MergeTree 一起使用。例如在准备做数据报表的时候,将完整的数据存储在 MergeTree 表中,并且使用 SummingMergeTree 来存储聚合数据,可以使避免因为使用不正确的 排序健组合方式而丢失有价值的数据
只需要查询汇总结果,不关心明细数据
设计聚合统计表,字段全部是维度、度量或者时间戳即可,非相关的字段可以不添加
获取汇总值,不能直接 select 对应的字段,而需要使用 sum 进行聚合,因为自动合并的部分可能没进行,会导致一些还没来得及聚合的临时明细数据少
语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = SummingMergeTree([columns])
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
参数
- columns 包含了将要被汇总的列的列名的元组。可选参数。
- 所选的【列必须是数值类型】,具有 相同OrderBy排序键 的行合并为一行
- 如果没有指定
columns,ClickHouse 会把非维度列且是【数值类型的列】都进行汇总
建表
create table shop.order_summing_merge_tree(
id UInt32,
sku_id String,
out_trade_no String,
total_amount Decimal(16,2),
create_time Datetime
) engine =SummingMergeTree(total_amount)
order by (id,sku_id)
partition by toYYYYMMDD(create_time)
primary key (id);
insert into shop.order_summing_merge_tree values
(1,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,
(2,'sku_2','23241',4.02,'2023-03-01 17:00:00'),
(3,'sku_3','542323',55.02,'2023-03-01 18:00:00'),
(4,'sku_5','54222',2000.3,'2023-04-01 19:00:00'),
(5,'sku_6','53423',120.2,'2023-04-01 19:00:00'),
(6,'sku_7','65432',600.01,'2023-04-02 11:00:00'); insert into shop.order_summing_merge_tree values
(1,'sku_1','aabbccbb',5600.00,'2023-03-01 23:09:00')
select sku_id,sum(total_amount) from shop.order_summing_merge_tree group by sku_id
optimize table shop.order_summing_merge_tree final;
演示
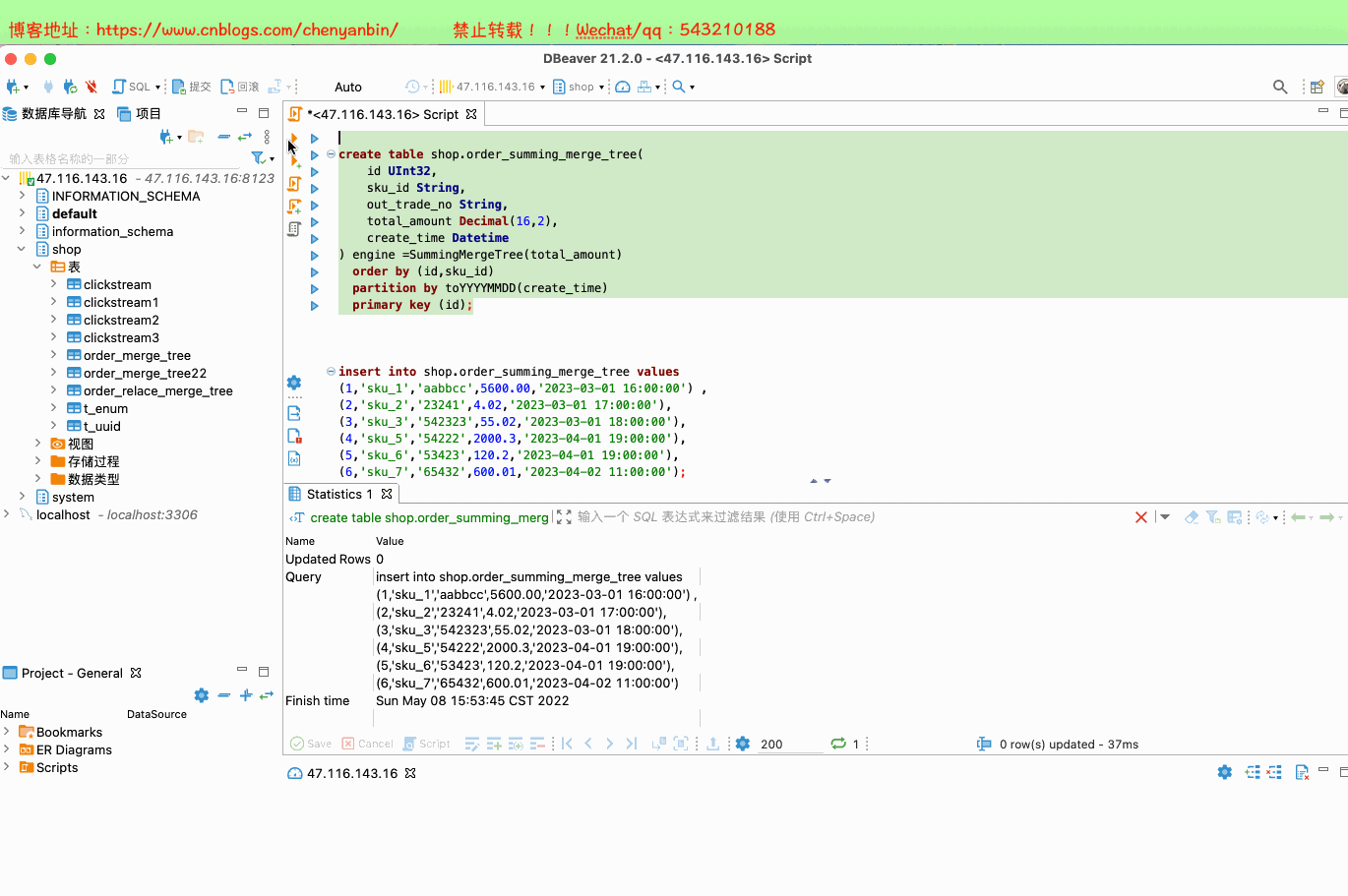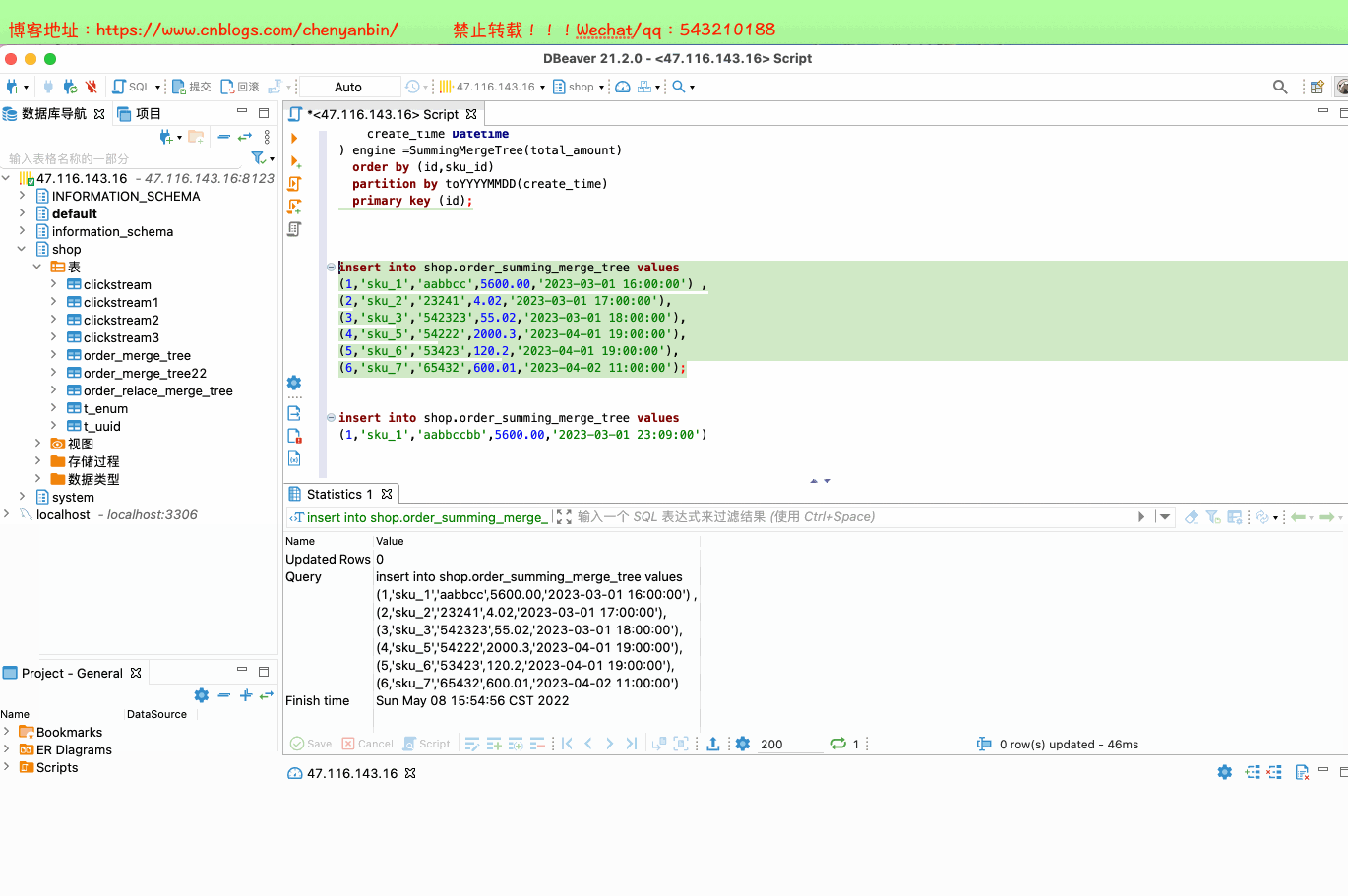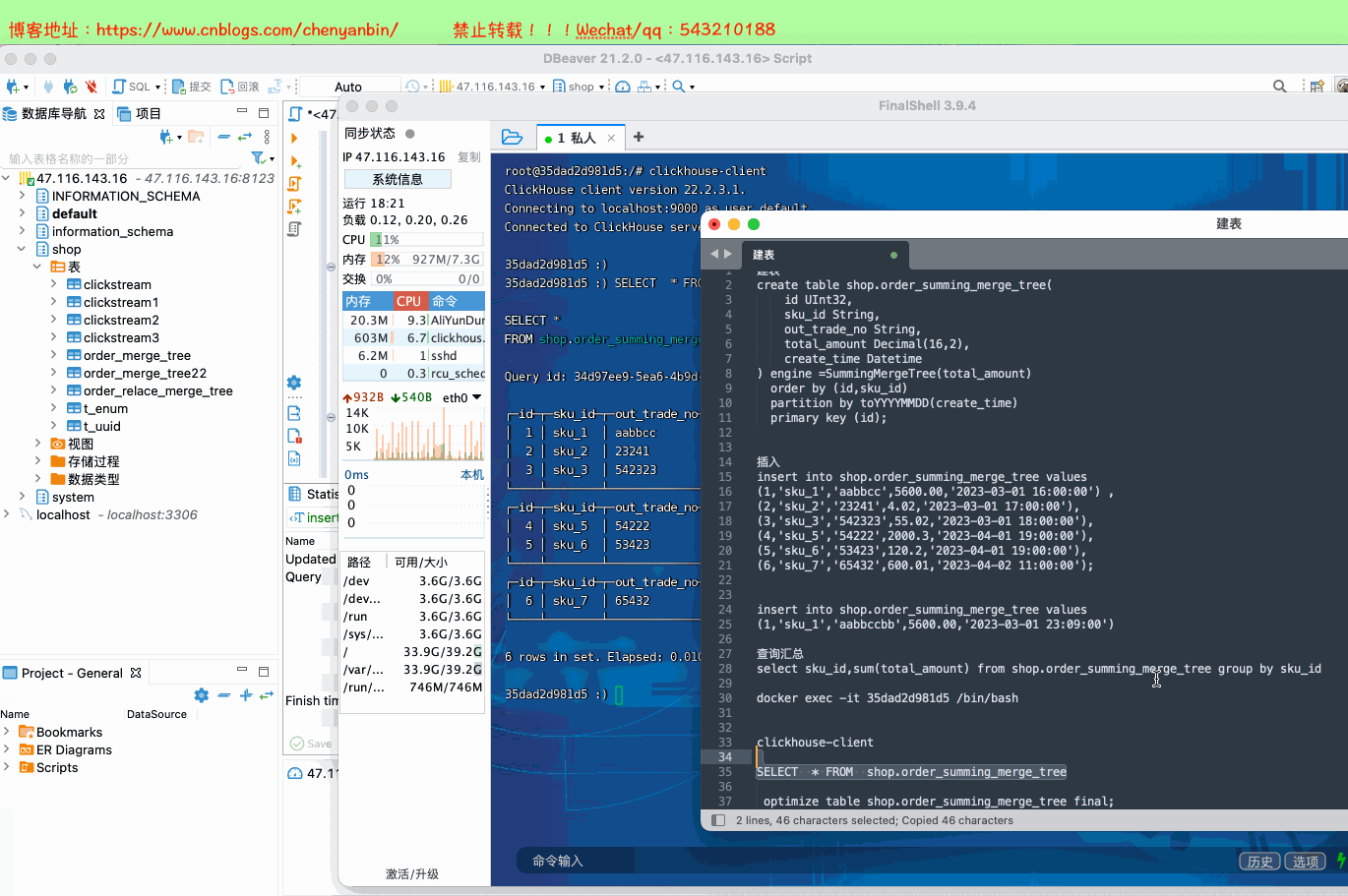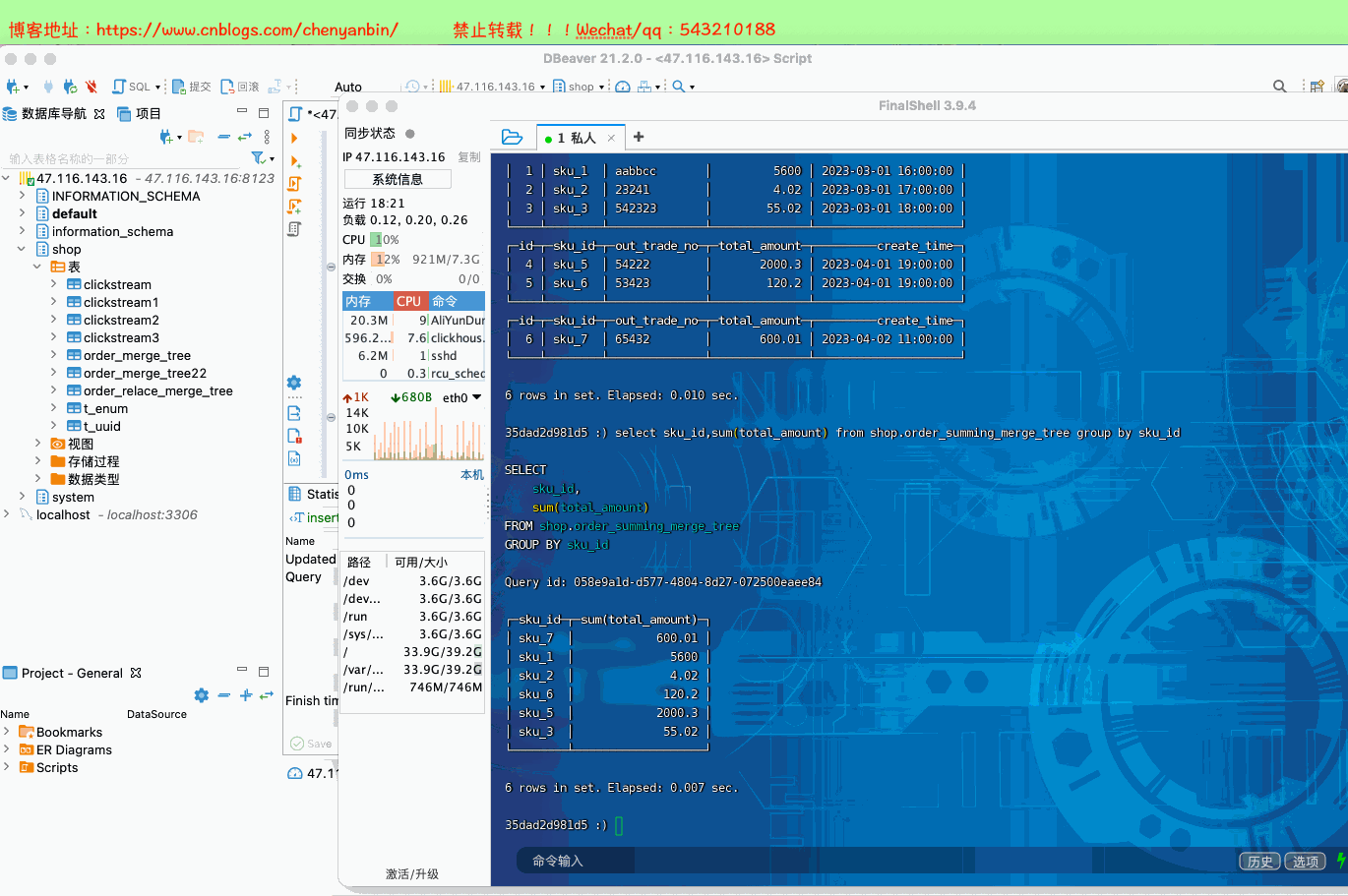

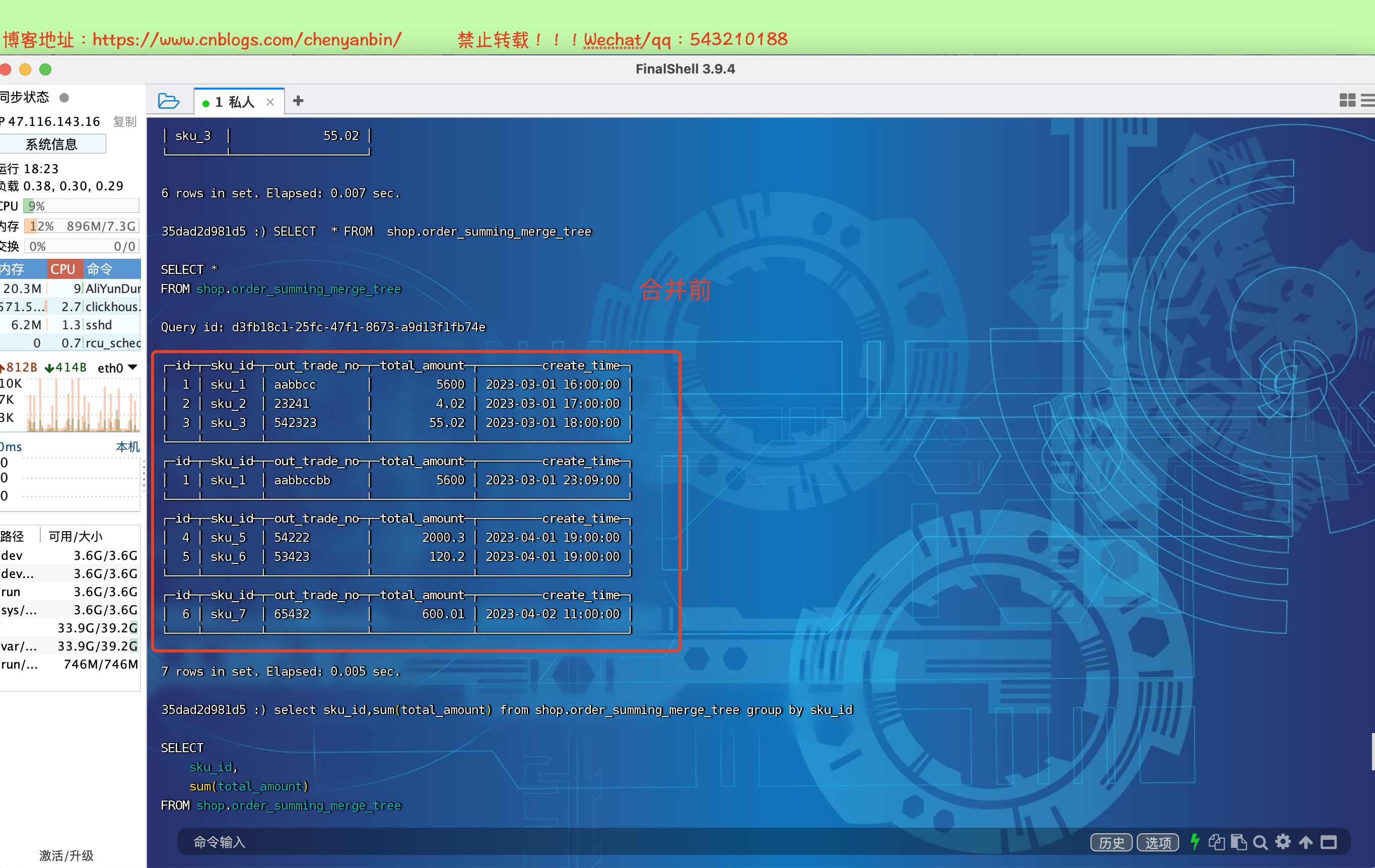

总结
SummingMergeTree是根据什么对数据进行合并的
- 【ORBER BY排序键相同】作为聚合数据的条件Key的行中的列进行汇总,将这些行替换为包含汇总数据的一行记录
** 跨分区内的相同排序key的数据是否会进行合并**
- 以数据分区为单位来聚合数据,同一数据分区内相同ORBER BY排序键的数据会被合并汇总,而不同分区之间的数据不会被汇总
如果没有指定聚合字段,会怎么聚合
- 如果没有指定聚合字段,则会用非维度列,且是数值类型字段进行聚合
对于非汇总字段的数据,该保留哪一条
- 如果两行数据除了【ORBER BY排序键】相同,其他的非聚合字段不相同,在聚合时会【保留最初】的那条数据,新插入的数据对应的那个字段值会被舍弃
在合并分区的时候按照预先定义的条件聚合汇总数据,将同一分区下的【相同排序】的多行数据汇总合并成一行,既减少了数据行节省空间,又降低了后续汇总查询的开销
Clickhouse高可用集群搭建
部署zookeeper
- 副本同步需要借助zookeeper实现数据的同步, 副本节点会在zk上进行监听,但数据同步过程是不经过zk的
- zookeeper要求3.4.5以及以上版本
docker run -d --name ybchen_zookeeper -p 2181:2181 -t zookeeper:3.7.0
部署Clickhouse
| 机器 | 公网 | 私网 | hostname |
| 机器-1 | 47.116.143.16 | 172.16.0.103 | ybchen-1 |
| 机器-2 | 101.132.27.2 | 172.16.0.108 | ybchen-2 |
Linux机器安装ClickHouse,版本:ClickHouse 22.1.2.2-2
文档地址:https://clickhouse.com/docs/zh/getting-started/install

#各个节点上传到新建文件夹
/usr/local/software/* #安装
sudo rpm -ivh *.rpm #启动
systemctl start clickhouse-server #停止
systemctl stop clickhouse-server #重启
systemctl restart clickhouse-server #状态查看
sudo systemctl status clickhouse-server #查看端口占用,如果命令不存在 yum install -y lsof
lsof -i :8123 #查看日志
tail -f /var/log/clickhouse-server/clickhouse-server.log
tail -f /var/log/clickhouse-server/clickhouse-server.err.log #开启远程访问,取消下面的注释
vim /etc/clickhouse-server/config.xml #编辑配置文件
<listen_host>0.0.0.0</listen_host> #重启
systemctl restart clickhouse-server # 增加dns解析
sudo vim /etc/hosts 172.16.0.103 ybchen-1
172.16.0.108 ybchen-2
- 网络安全组记得开放http端口是8123,tcp端口是9000, 同步端口9009
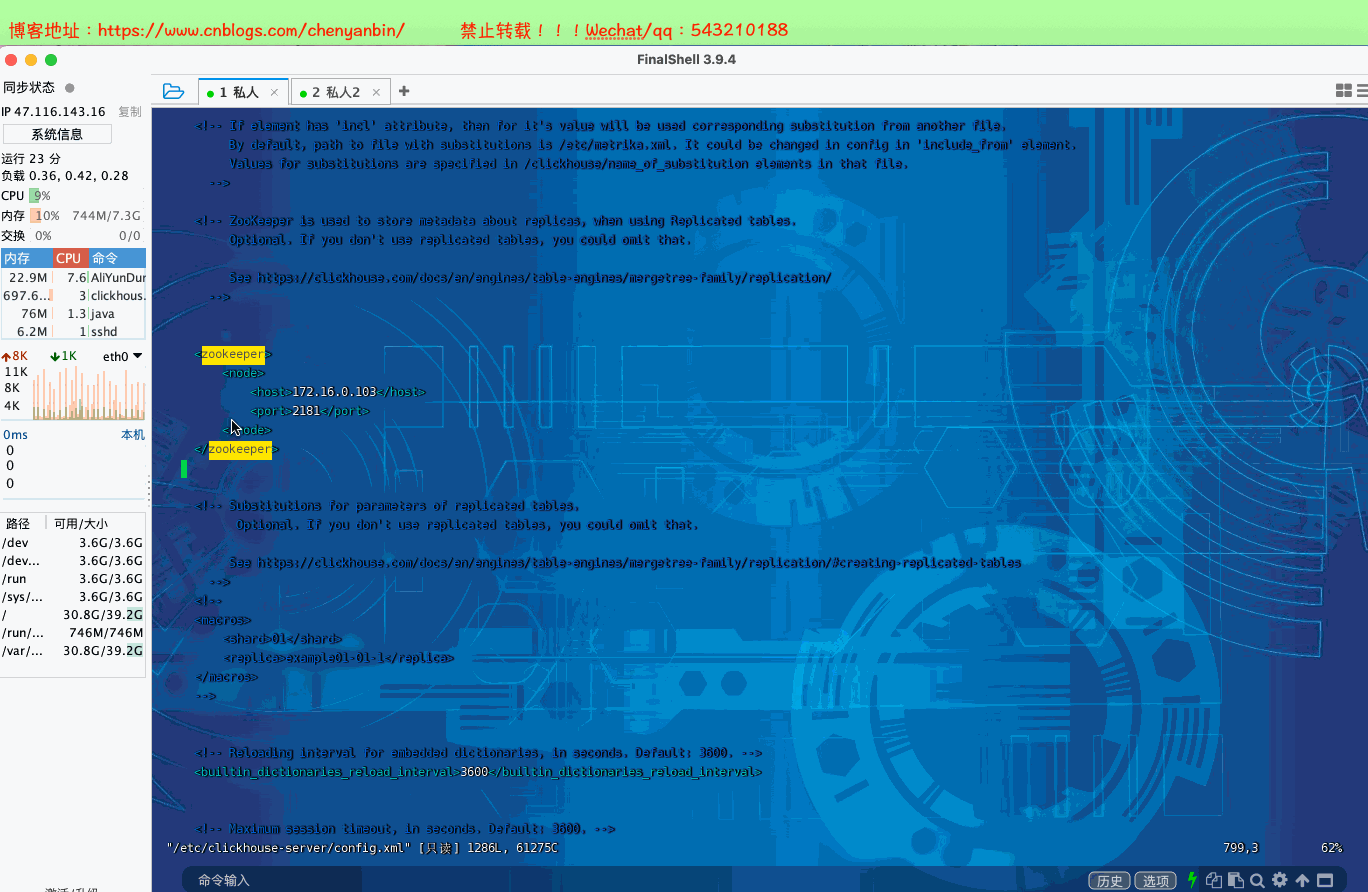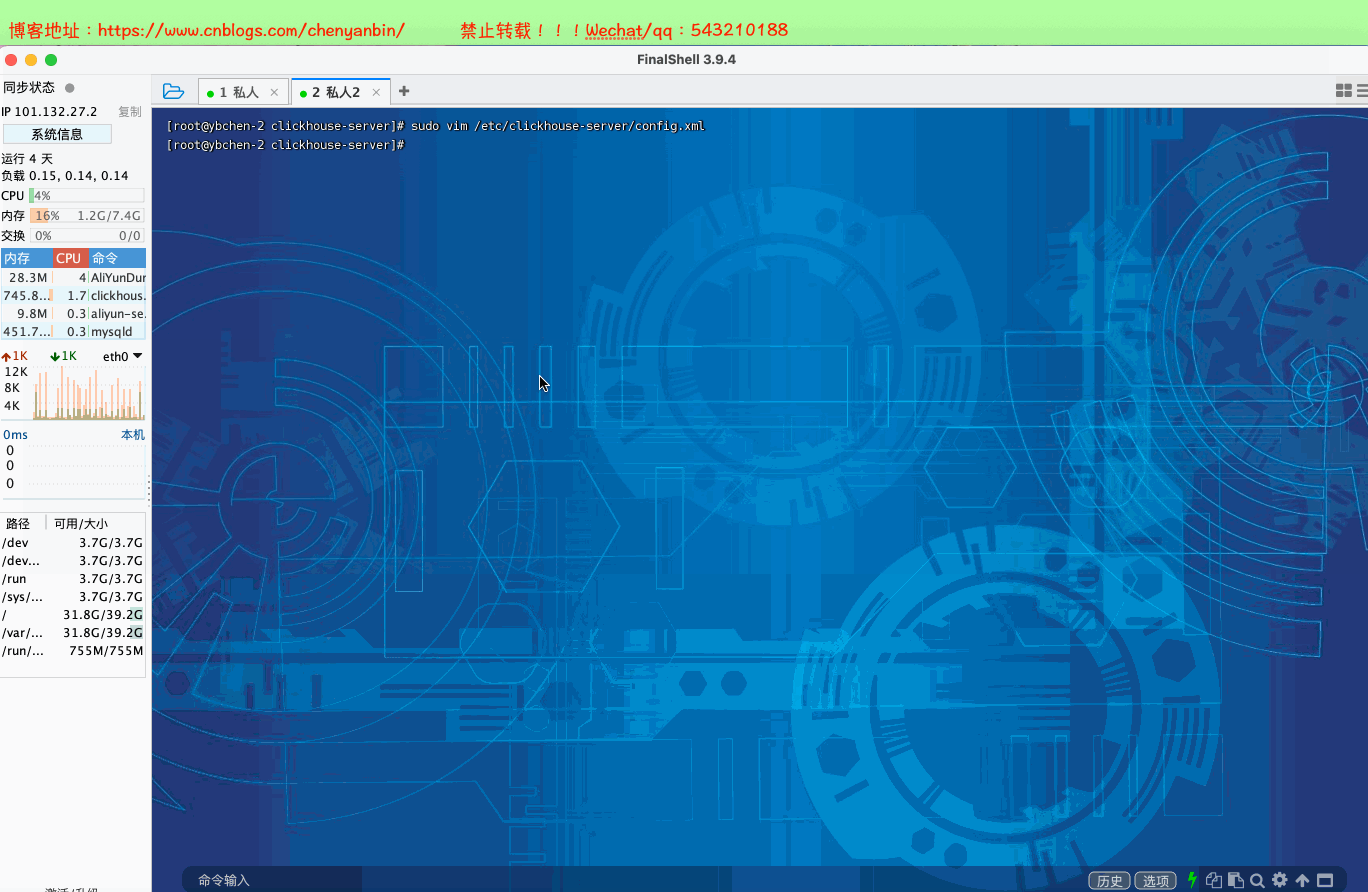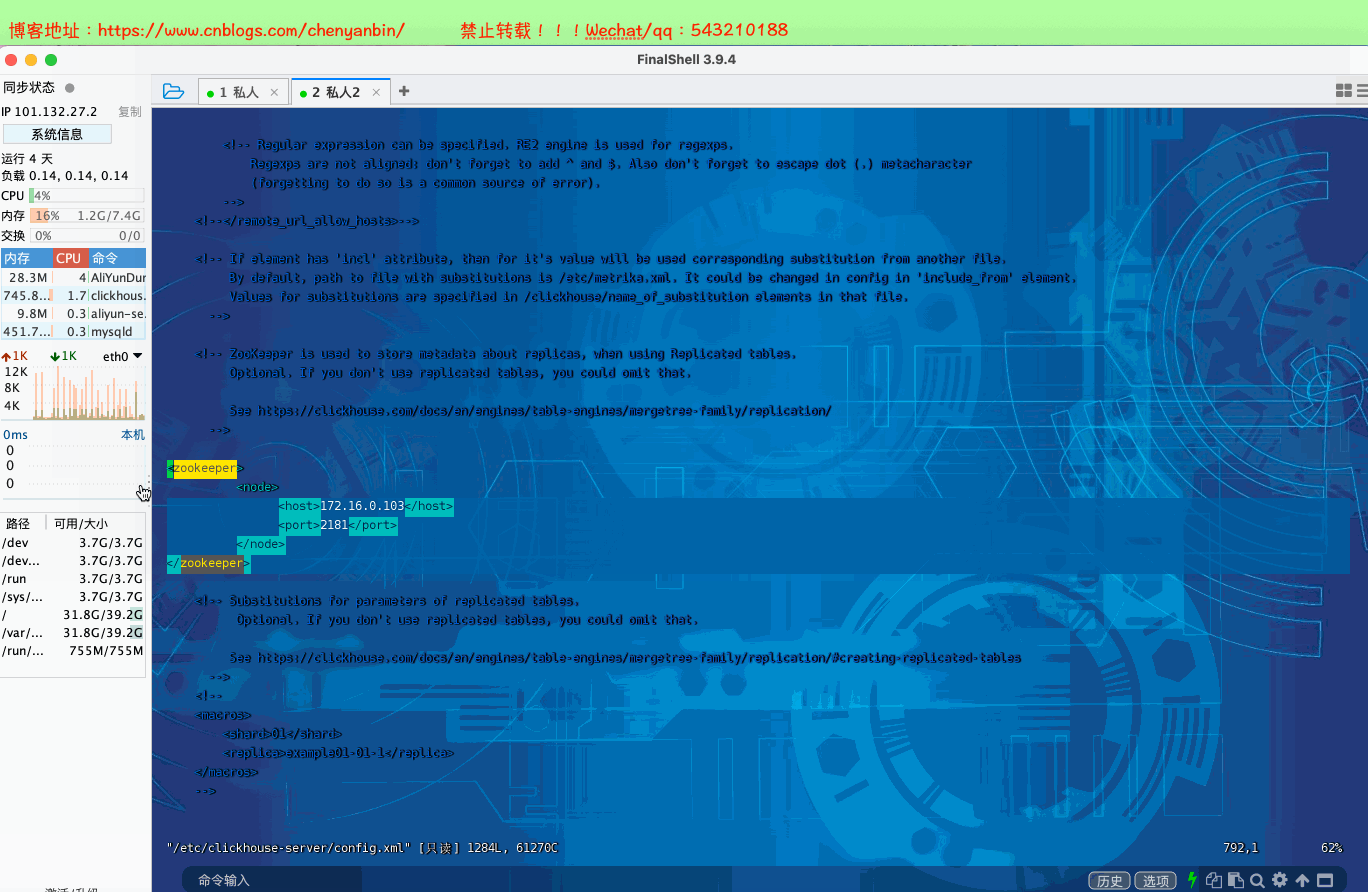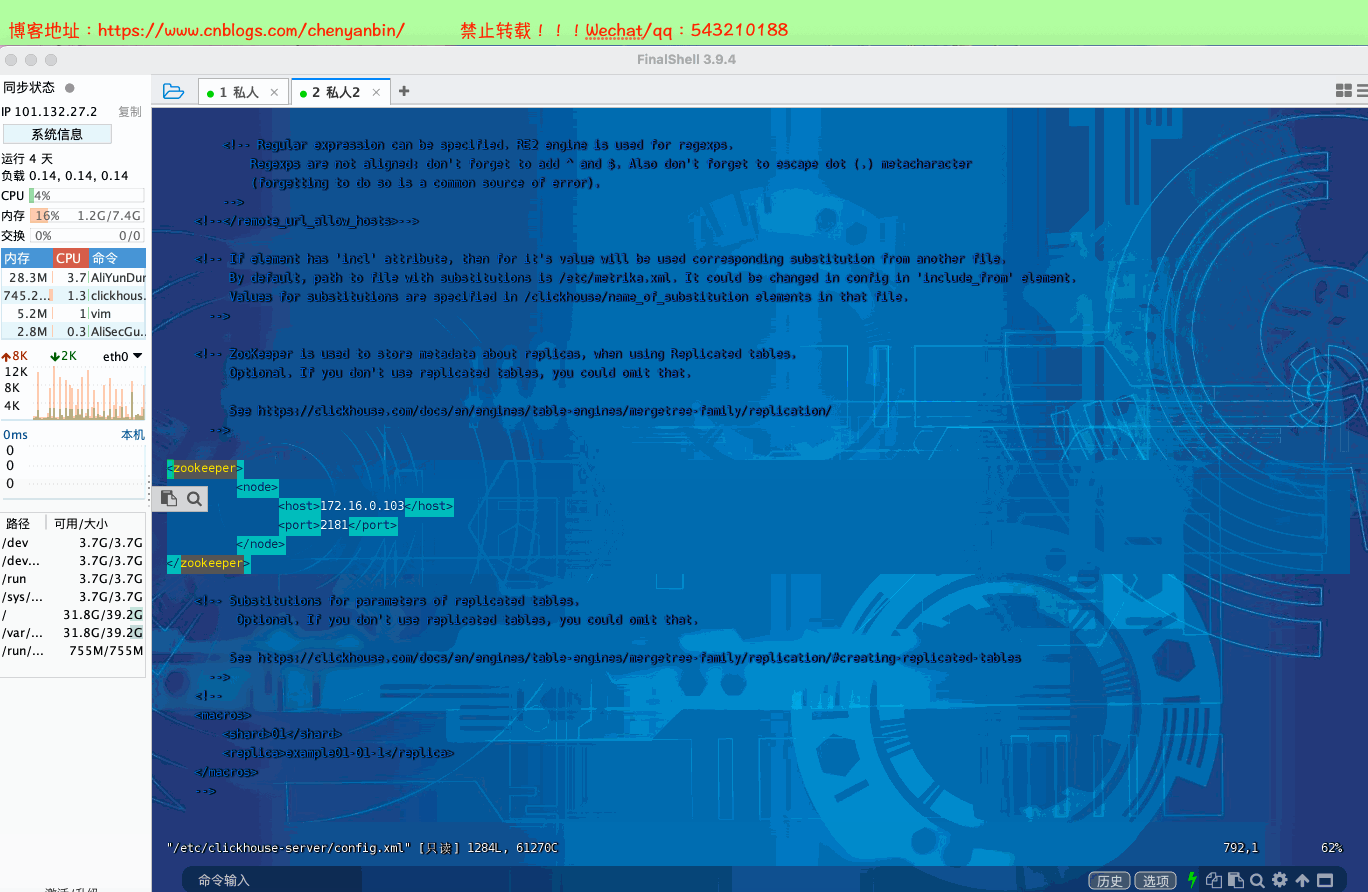
高可用集群架构-ClickHouse副本配置
#进入配置目录
cd /etc/clickhouse-server #编辑配置文件
sudo vim config.xml #找到zookeeper节点,增加下面的,如果有多个zk则按照顺序加即可 <zookeeper>
<node>
<host>172.16.0.103</host>
<port>2181</port>
</node>
</zookeeper> #重启
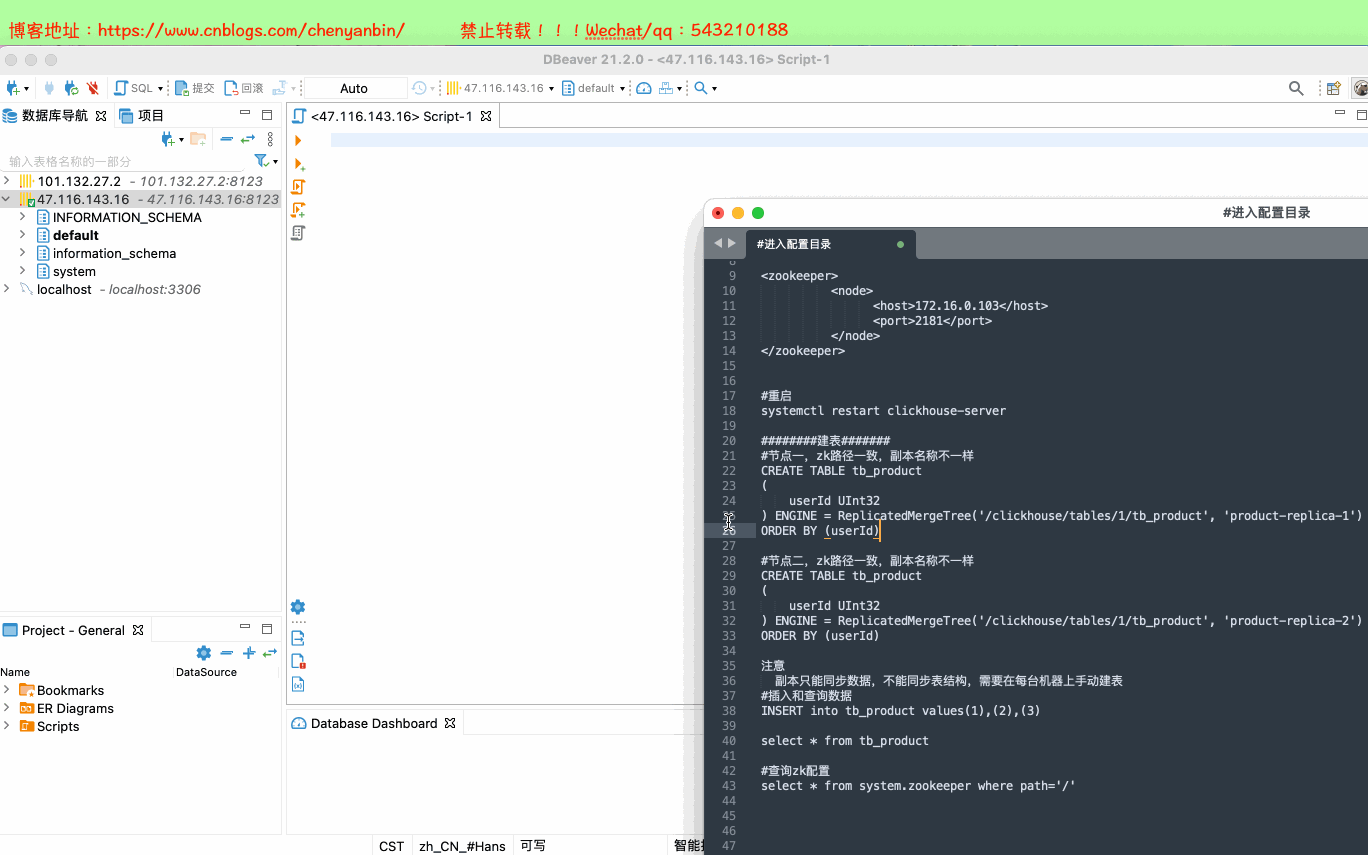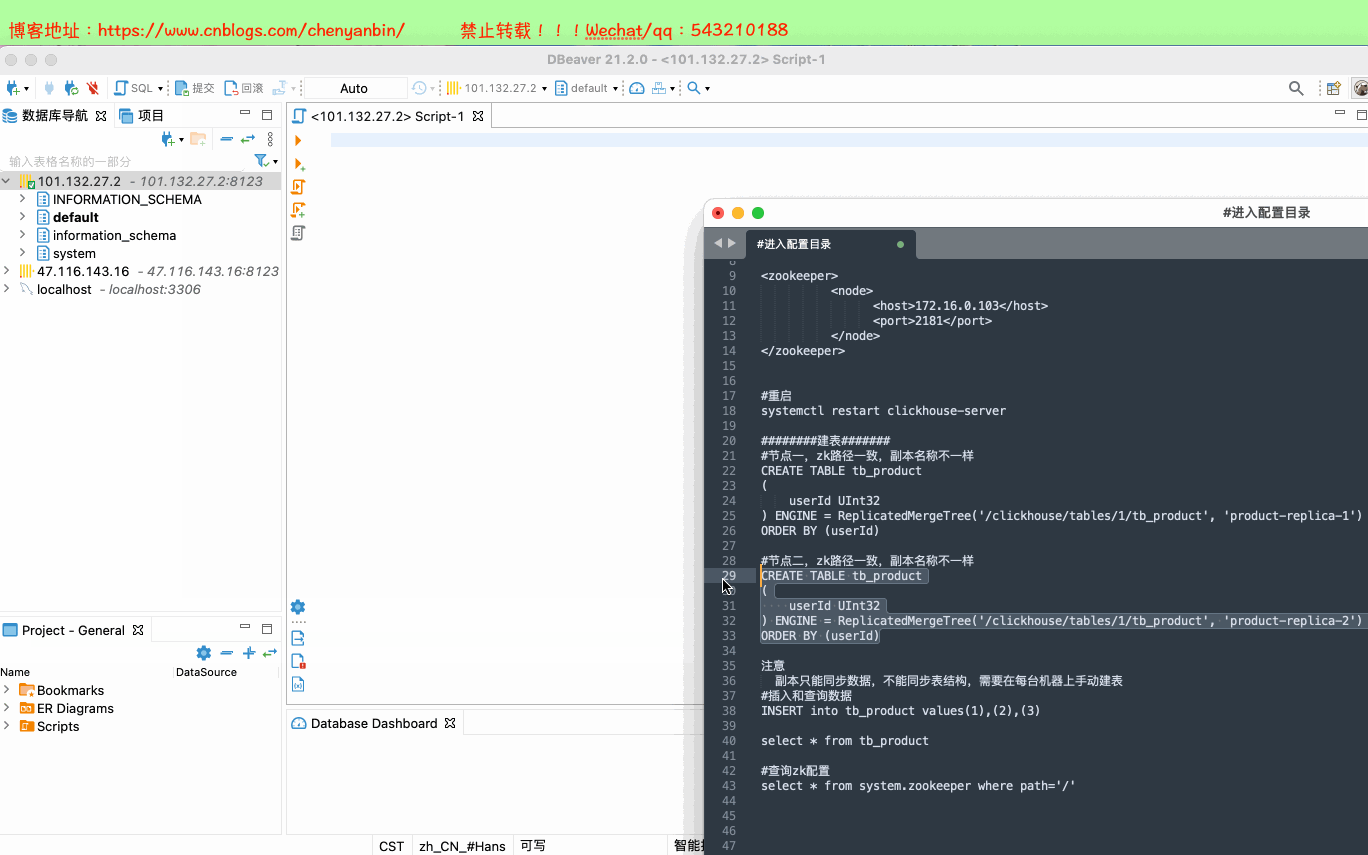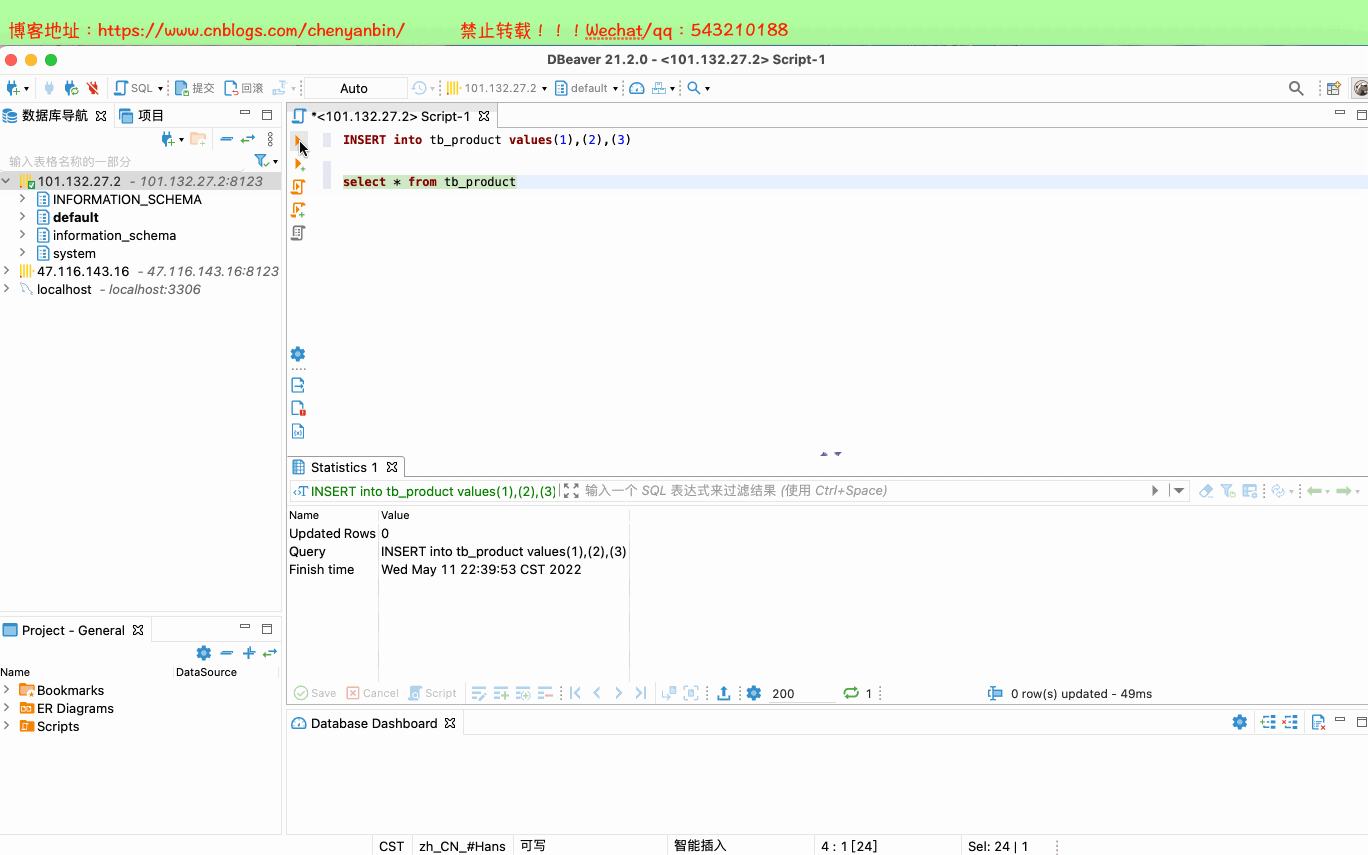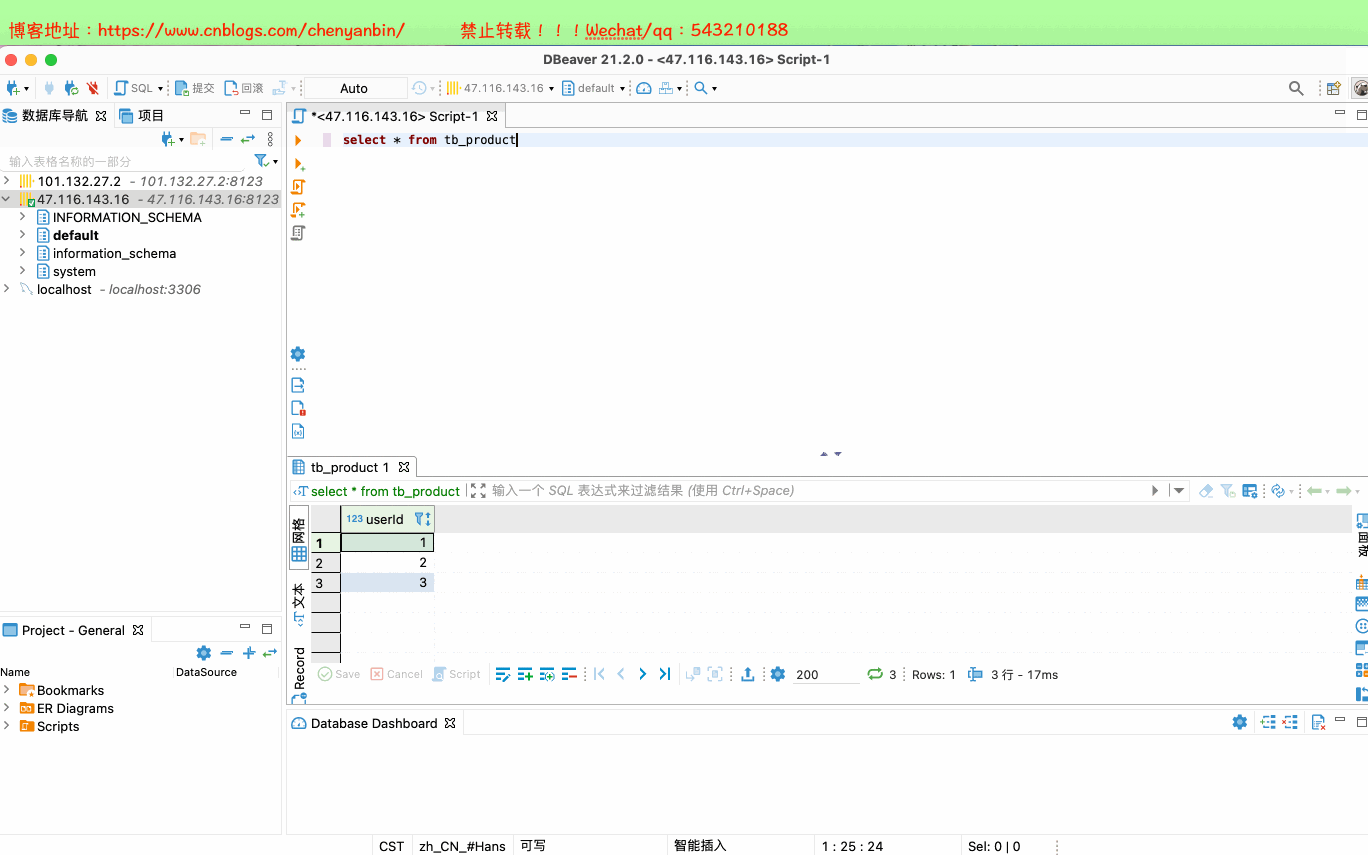
systemctl restart clickhouse-server ########建表#######
#节点一,zk路径一致,副本名称不一样
CREATE TABLE tb_product
(
userId UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/1/tb_product', 'product-replica-1')
ORDER BY (userId) #节点二,zk路径一致,副本名称不一样
CREATE TABLE tb_product
(
userId UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/1/tb_product', 'product-replica-2')
ORDER BY (userId) 注意
副本只能同步数据,不能同步表结构,需要在每台机器上手动建表
#插入和查询数据
INSERT into tb_product values(1),(2),(3) select * from tb_product #查询zk配置
select * from system.zookeeper where path='/'
表引擎-数据副本
ReplicatedMergeTree
语法
zoo_path— zk 中该表的路径,可自定义名称,同一张表的同一分片的不同副本,要定义相同的路径replica_name— zk 中的该表的副本名称,同一张表的同一分片的不同副本,要定义不同的名称
CREATE TABLE tb_order
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/tb_order', 'tb_order_01')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)
表引擎-分布式引擎

语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
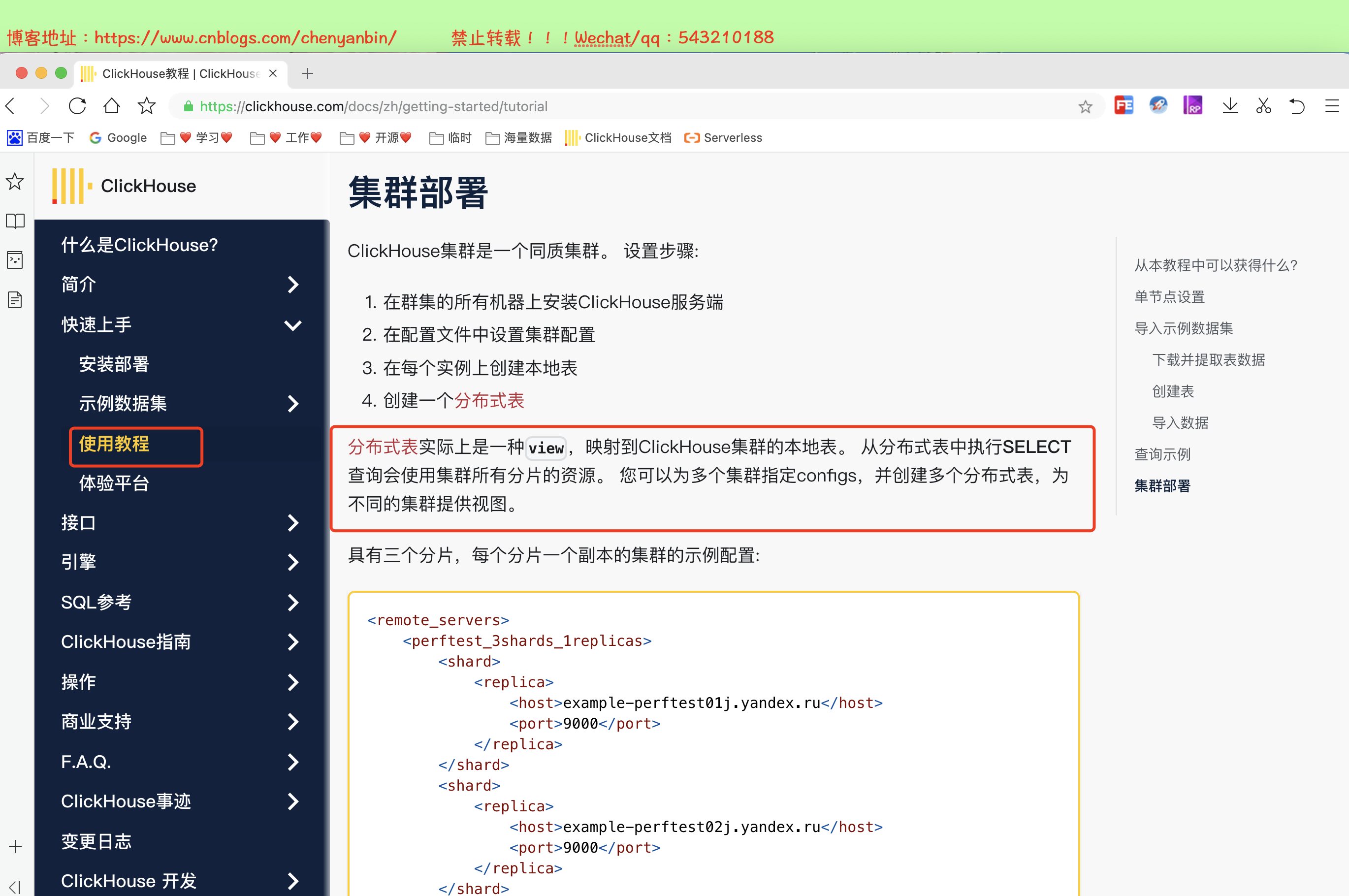
) ENGINE = Distributed(cluster, database, table[, sharding_key[, policy_name]])
[SETTINGS name=value, ...]
cluster:集群名称,与集群配置中的自定义名称相对应,比如 xdclass_shard。
database:数据库名称
table:本地表名称
sharding_key:可选参数,用于分片的key值,在写入的数据Distributed表引擎会依据分片key的规则,将数据分布到各个节点的本地表
- user_id等业务字段、rand()随机函数等规则
分片配置 config.xml
<remote_servers>
<logs>
<!-- 分布式查询的服务器间集群密码
默认值:无密码(将不执行身份验证) 如果设置了,那么分布式查询将在分片上验证,所以至少:
- 这样的集群应该存在于shard上
- 这样的集群应该有相同的密码。 而且(这是更重要的),initial_user将作为查询的当前用户使用。
-->
<!-- <secret></secret> -->
<shard>
<!-- 可选的。写数据时分片权重。 默认: 1. -->
<weight>1</weight>
<!-- 可选的。是否只将数据写入其中一个副本。默认值:false(将数据写入所有副本)。 -->
<internal_replication>false</internal_replication>
<replica>
<!-- 可选的。负载均衡副本的优先级,请参见(load_balancing 设置)。默认值:1(值越小优先级越高)。 -->
<priority>1</priority>
<host>example01-01-1</host>
<port>9000</port>
</replica>
<replica>
<host>example01-01-2</host>
<port>9000</port>
</replica>
</shard>
<shard>
<weight>2</weight>
<internal_replication>false</internal_replication>
<replica>
<host>example01-02-1</host>
<port>9000</port>
</replica>
<replica>
<host>example01-02-2</host>
<secure>1</secure>
<port>9440</port>
</replica>
</shard>
</logs>
</remote_servers>
这里定义了一个名为’logs’的集群,它由两个分片组成,每个分片包含两个副本。 分片是指包含数据不同部分的服务器(要读取所有数据,必须访问所有分片)。 副本是存储复制数据的服务器(要读取所有数据,访问任一副本上的数据即可)。
集群名称不能包含点号。
每个服务器需要指定 host,port,和可选的 user,password,secure,compression 的参数:
host– 远程服务器地址。可以域名、IPv4或IPv6。如果指定域名,则服务在启动时发起一个 DNS 请求,并且请求结果会在服务器运行期间一直被记录。如果 DNS 请求失败,则服务不会启动。如果你修改了 DNS 记录,则需要重启服务。port– 消息传递的 TCP 端口(「tcp_port」配置通常设为 9000)。不要跟 http_port 混淆。user– 用于连接远程服务器的用户名。默认值:default。该用户必须有权限访问该远程服务器。访问权限配置在 users.xml 文件中。更多信息,请查看«访问权限»部分。password– 用于连接远程服务器的密码。默认值:空字符串。secure– 是否使用ssl进行连接,设为true时,通常也应该设置port= 9440。服务器也要监听<tcp_port_secure>9440</tcp_port_secure>并有正确的证书。compression- 是否使用数据压缩。默认值:true。
配置实战
机器
| 服务类型 | 公网 | 私网 | hostname |
| clickhouse-1 | 47.116.143.16 | 172.16.0.103 | ybchen-1 |
| clickhouse-2 | 101.132.27.2 | 172.16.0.108 | ybchen-2 |
| zookeeper | 47.116.143.16 | 172.16.0.103 | ybchen-1 |
每台机器上的配置
#进入配置目录
cd /etc/clickhouse-server #编辑配置文件
sudo vim config.xml <!-- 2shard 1replica -->
<cluster_2shards_1replicas>
<!-- shard1 -->
<shard>
<replica>
<host>172.16.0.103</host>
<port>9000</port>
</replica>
</shard> <!-- shard2 -->
<shard>
<replica>
<host>172.16.0.108</host>
<port> 9000</port>
</replica>
</shard> </cluster_2shards_1replicas> <zookeeper>
<node >
<host>172.16.0.103</host>
<port>2181</port>
</node>
</zookeeper>
重启
systemctl restart clickhouse-server
判断是否配置成功
- 重启ClickHouse前查询,查不到对应的集群名称,重启ClickHouse后能查询到
select * from system.clusters

建表
#【选一个节点】创建好本地表后,在1个节点创建,会在其他节点都存在
create table default.ybchen_order on cluster cluster_2shards_1replicas
(id Int8,name String) engine =MergeTree order by id; #【选一个节点】创建分布式表名 ybchen_order_all,在1个节点创建,会在其他节点都存在
create table ybchen_order_all on cluster cluster_2shards_1replicas (
id Int8,name String
)engine = Distributed(cluster_2shards_1replicas,default, ybchen_order,hiveHash(id)); #分布式表插入
insert into ybchen_order_all values(1,'老陈'),(2,'老王'),(3,'老李'),(4,'老赵'); #【任意节点查询-分布式,全部数据】
SELECT * from ybchen_order_all #【任意本地节点查询,部分数据】
SELECT * from ybchen_order

SpringBoot整合Clickhouse
数据准备
CREATE TABLE default.visit_stats
(
`product_id` UInt64,
`is_new` UInt16,
`province` String,
`city` String,
`pv` UInt32,
`visit_time` DateTime
)
ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(visit_time)
ORDER BY (
product_id,
is_new,
province,
city
);
创建工程
添加依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.13</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.ybchen</groupId>
<artifactId>ybchen-clickhouse</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>ybchen-clickhouse</name>
<description>SpringBoot整合Clickhouse</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency> <!-- lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency> <!-- clickhouse -->
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.3.2</version>
</dependency> <!--mybatis plus-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
</dependencies> <build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build> </project>
配置类
server.port=8888
spring.datasource.driver-class-name=ru.yandex.clickhouse.ClickHouseDriver
spring.datasource.url=jdbc:clickhouse://47.116.143.16:8123/default
# 账号
#spring.datasource.username=
# 密码
#spring.datasource.password= mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
logging.level.root=INFO
实体类
package com.ybchen.model; import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data; /**
* @Description:
* @Author:chenyanbin
* @CreateTime: 2022-05-14 21:51
* @Version:1.0.0
*/
@Data
@TableName("visit_stats")
public class VisitStatsDO {
/**
* 商品
*/
private Long productId; /**
* 1是新访客,0是老访客
*/
private Integer isNew; /**
* 省份
*/
private String province; /**
* 城市
*/
private String city; /**
* 访问量
*/
private Integer pv; /**
* 访问时间
*/
private String visitTime;
}
Mapper
package com.ybchen.mapper; import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.ybchen.model.VisitStatsDO; public interface VisitStatsMapper extends BaseMapper<VisitStatsDO> {
}
Controller
package com.ybchen.controller; import com.ybchen.request.VisitRecordListRequest;
import com.ybchen.service.VisitService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController; import java.util.Map; /**
* @Description:
* @Author:chenyanbin
* @CreateTime: 2022-05-14 21:53
* @Version:1.0.0
*/
@RestController
@RequestMapping("/api/v1/data")
public class DataController {
@Autowired
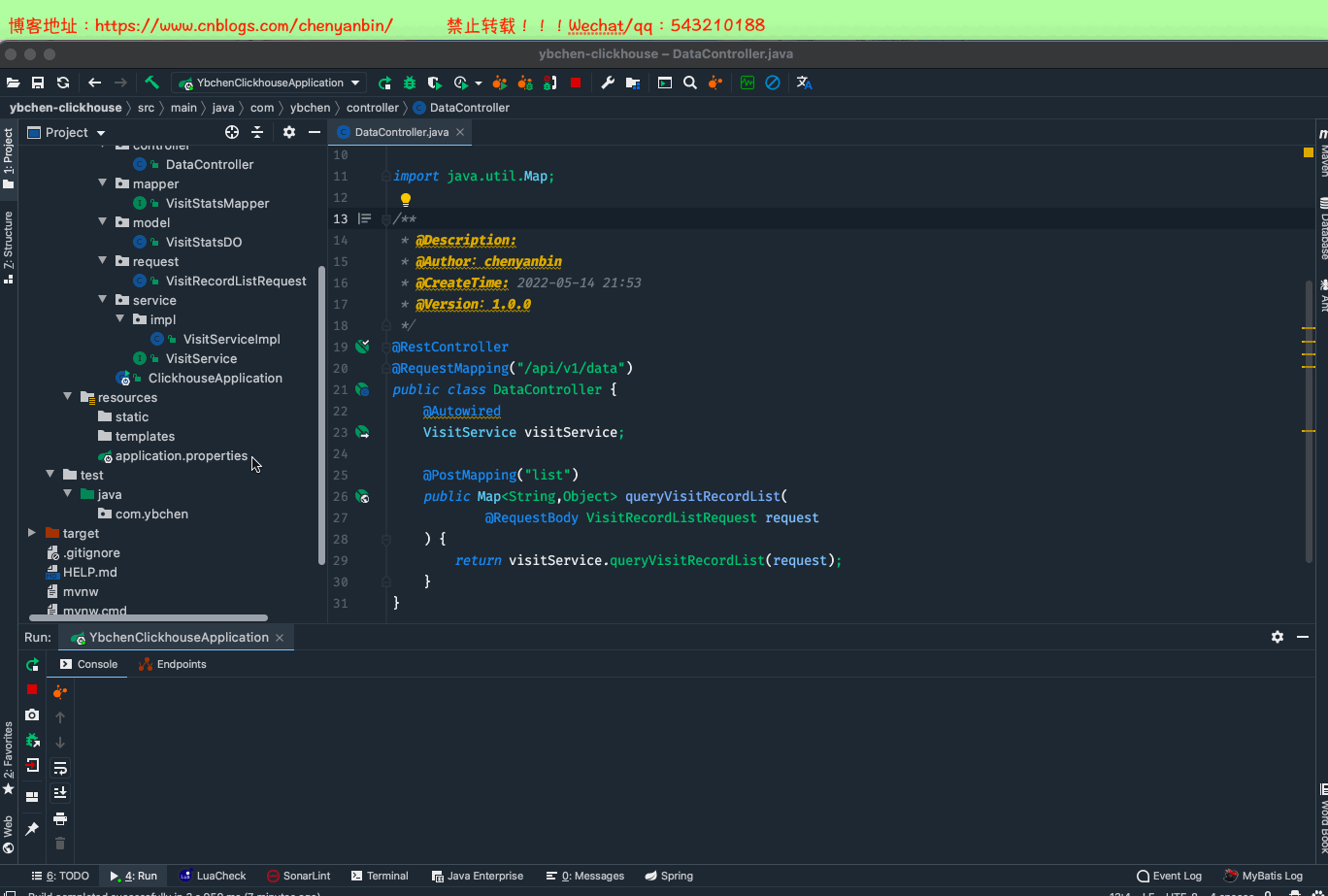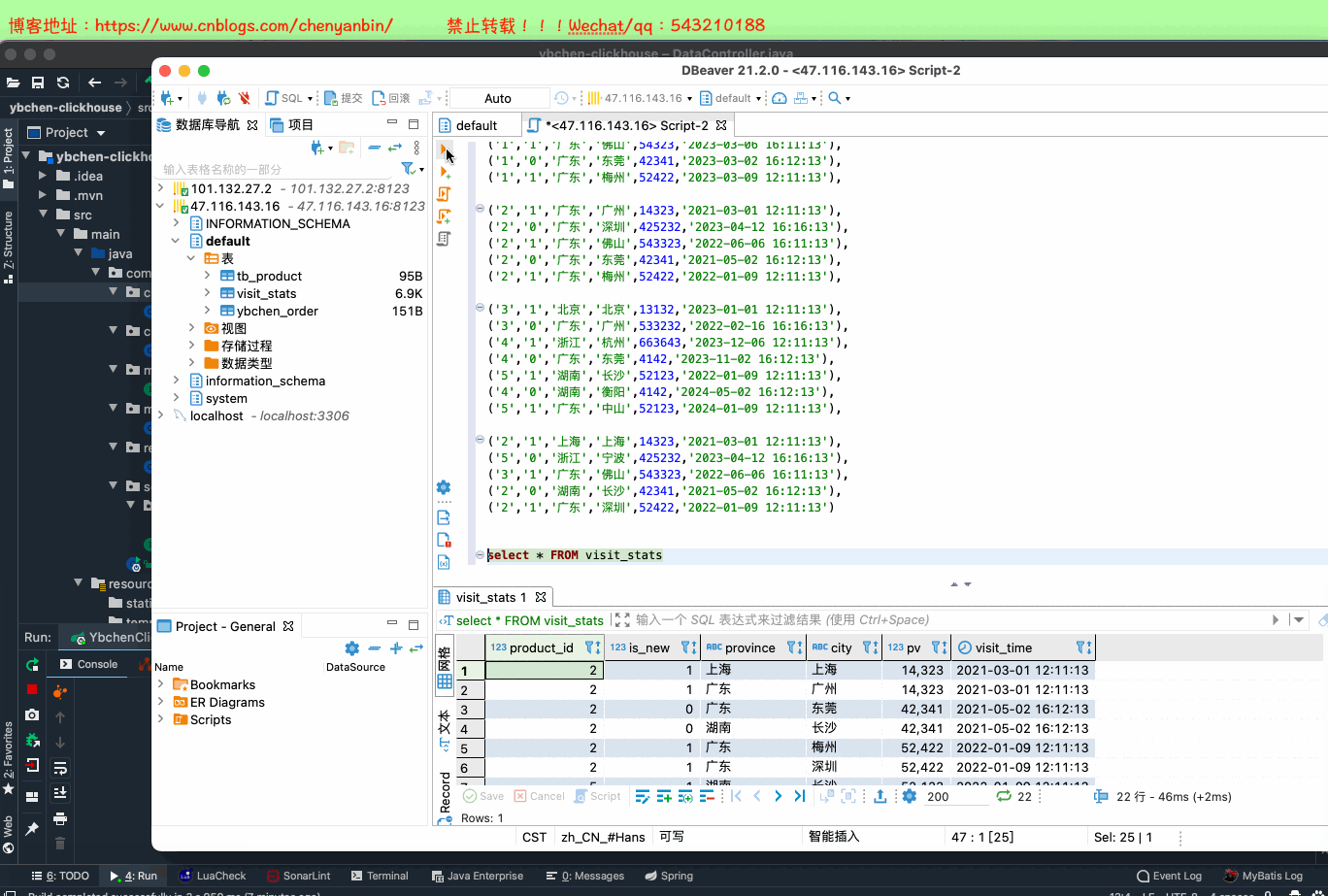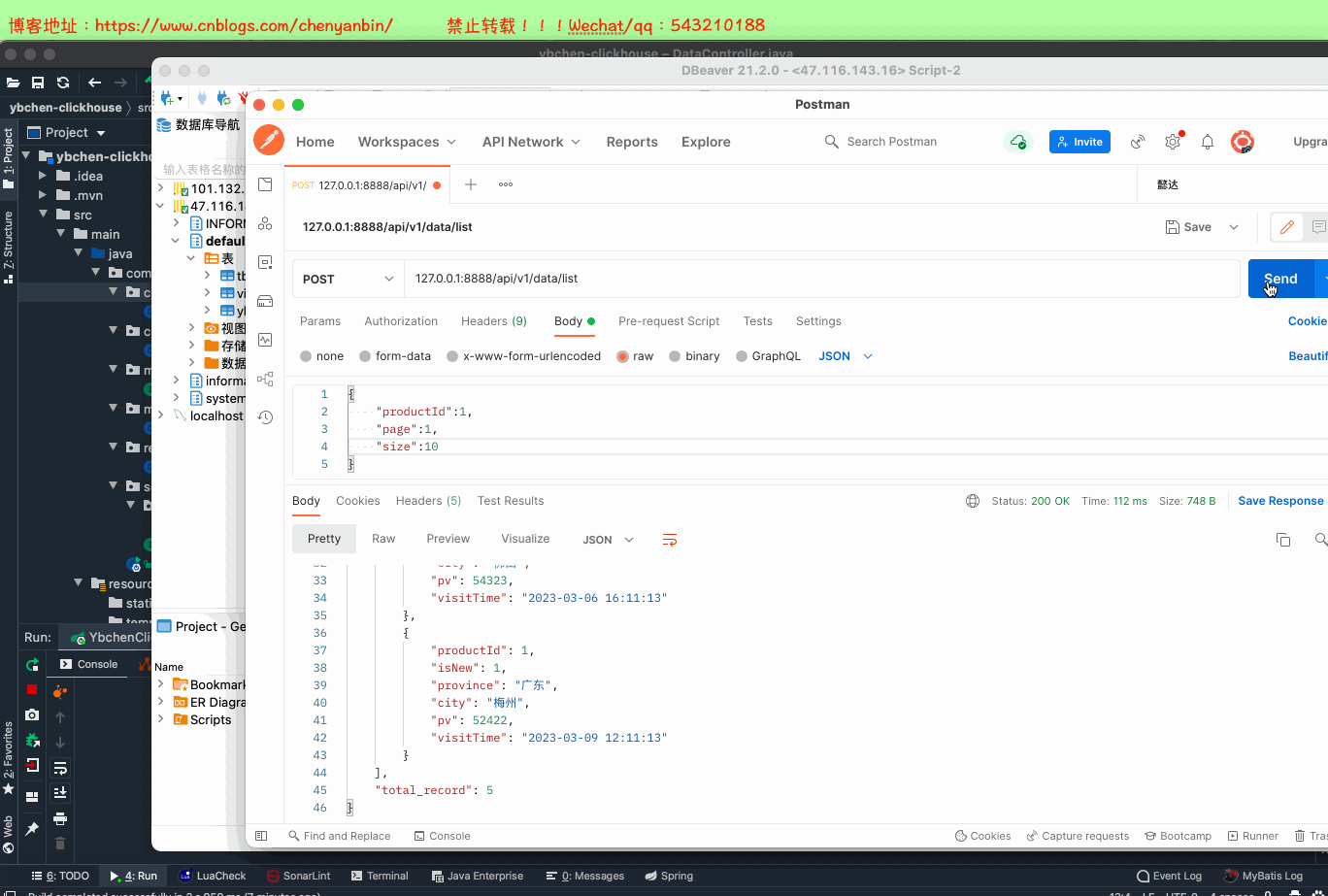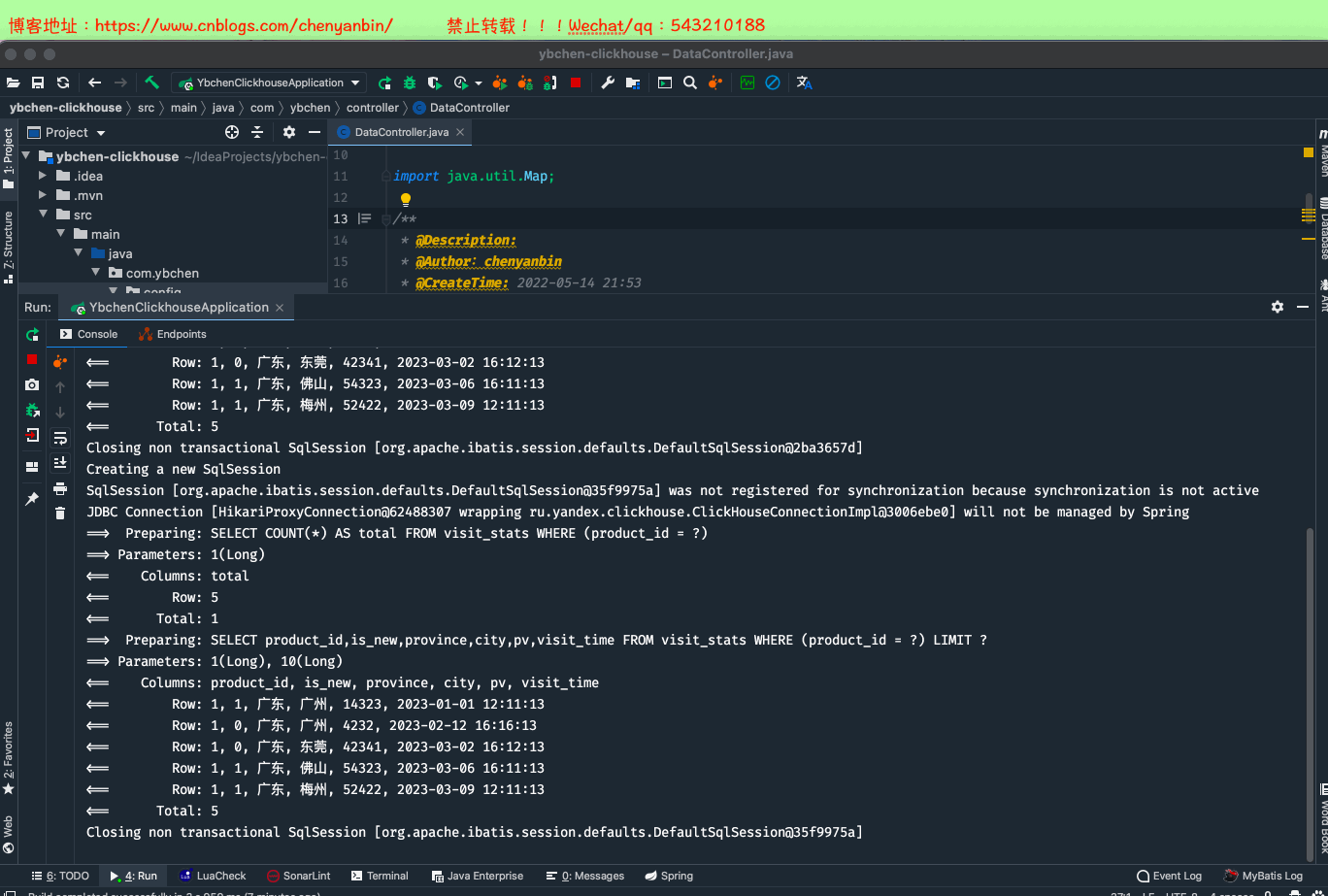
VisitService visitService; @PostMapping("list")
public Map<String,Object> queryVisitRecordList(
@RequestBody VisitRecordListRequest request
) {
return visitService.queryVisitRecordList(request);
}
}
package com.ybchen.request; import lombok.Data; /**
* @Description:
* @Author:chenyanbin
* @CreateTime: 2022-05-14 21:54
* @Version:1.0.0
*/
@Data
public class VisitRecordListRequest {
private Long productId;
private int page;
private int size;
}
Service
package com.ybchen.service;
import com.ybchen.request.VisitRecordListRequest;
import java.util.Map;
public interface VisitService {
/**
* 查询访问记录
* @param request
* @return
*/
Map<String, Object> queryVisitRecordList(VisitRecordListRequest request);
}
package com.ybchen.service.impl; import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.ybchen.mapper.VisitStatsMapper;
import com.ybchen.model.VisitStatsDO;
import com.ybchen.request.VisitRecordListRequest;
import com.ybchen.service.VisitService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service; import java.util.HashMap;
import java.util.Map; /**
* @Description:
* @Author:chenyanbin
* @CreateTime: 2022-05-14 21:55
* @Version:1.0.0
*/
@Service
@Slf4j
public class VisitServiceImpl implements VisitService {
@Autowired
VisitStatsMapper visitStatsMapper; @Override
public Map<String, Object> queryVisitRecordList(VisitRecordListRequest request) {
Map<String, Object> dataMap = new HashMap<>(3);
IPage<VisitStatsDO> pageInfo = new Page<>(request.getPage(), request.getSize());
IPage<VisitStatsDO> visitStatsDOIPage = visitStatsMapper.selectPage(
pageInfo,
new LambdaQueryWrapper<VisitStatsDO>()
.eq(VisitStatsDO::getProductId, request.getProductId())
);
/**
* 分页记录列表
*/
dataMap.put("current_data",visitStatsDOIPage.getRecords());
/**
* 当前分页总页数
*/
dataMap.put("total_page",visitStatsDOIPage.getPages());
/**
* 总记录数
*/
dataMap.put("total_record",visitStatsDOIPage.getTotal());
return dataMap;
}
}
测试
Clickhouse语法
Clickhouse语法和mysql差不多,只不过Clickhouse提供了更加丰富的函数,具体请查阅官网文档:点我直达

海量数据存储ClickHouse的更多相关文章
- 浅析MongoDB数据库的海量数据存储应用
[摘要]当今已进入大数据时代,特别是大规模互联网web2.0应用不断发展及云计算所需要的海量存储和海量计算发展,传统的关系型数据库已无法满足这方面的需求.随着NoSQL数据库的不断发展和成熟,可以较好 ...
- 海量数据存储之Key-Value存储简介
Key-value存储简介 具备高可靠性及可扩展性的海量数据存储对互联网公司来说是一个巨大的挑战,传统的数据库往往很难满足该需求,并且很多时候对于特定的系统绝大部分的检索都是基于主键的的查询,在这种情 ...
- HBase海量数据存储
1.简介 HBase是一个基于HDFS的.分布式的.面向列的非关系型数据库. HBase的特点 1.海量数据存储,HBase表中的数据能够容纳上百亿行*上百万列. 2.面向列的存储,数据在表中是按照列 ...
- 海量数据存储之nosql教程(转)
add by zhj: 不错的系列,作者介绍了NoSQL数据库,并重点研究了Memcached和Redis,不知道后续是否还有其它NoSQL数据库的文章 海量数据存储之nosql教程之-01基础理论 ...
- [转]Mysql海量数据存储和解决方案之一—分布式DB方案
1) 分布式DB水平切分中用到的主要关键技术:分库,分表,M-S,集群,负载均衡 2) 需求分析:一个大型互联网应用每天几十亿的PV对DB造成了相当高的负载,对系统的稳定性的扩展性带来极大挑战. 3 ...
- 论文学习 - 《Hadoop平台下的海量数据存储技术研究》
摘要 研究背景: 1. 互联网的图片数据急剧膨胀 2. Hadoop平台下的Hdfs分布式文件系统能够很好的处理海量数据 研究内容: 1. Hadoop平台工作原理 2. Hadoop平台下图片存储系 ...
- Mysql海量数据存储和解决方案之一—分布式DB方案
1) 分布式DB水平切分中用到的主要关键技术:分库,分表,M-S,集群,负载均衡 2) 需求分析:一个大型互联网应用每天几十亿的PV对DB造成了相当高的负载,对系统的稳定性的扩展性带来极大挑战. 3 ...
- Hbase(1)-MySQL海量数据存储的启发
宽表拆分 有一张user表,记录了用户的信息,,如果表中的列有很多,就称之为宽表,为了提升效率,会进行垂直拆分 拆分后 将用户的信息分为基本信息和其他信息,页面一开打就需要展示的信息为基本信息,其他信 ...
- 应运而生! 双11当天处理数据5PB—HiStore助力打造全球最大列存储数据库
阿里巴巴电商业务中历史数据存储与查询相关业务, 大量采用基于列存储技术的HiStore数据库,双11当天HiStore引擎处理数据记录超过6万亿条.原始存储数据量超过5PB.从单日数据处理量上看,该系 ...
随机推荐
- Tomcat安装流程(无图简易)
笔记:web->3小结
- VueJs单页应用实现微信网页授权及微信分享功能
在实际开发中,无论是做PC端.WebApp端还是微信公众号等类型的项目的时候,或多或少都会涉及到微信相关的开发,最近公司项目要求实现微信网页授权,并获取微信用户基本信息的功能及微信分享的功能,现在总算 ...
- 论文解读(XR-Transformer)Fast Multi-Resolution Transformer Fine-tuning for Extreme Multi-label Text Classification
Paper Information Title:Fast Multi-Resolution Transformer Fine-tuning for Extreme Multi-label Text C ...
- 【Android开发】用WebView访问证书有问题的SSL网页
Android系统的碎片化很严重,并且手机日期不正确.手机根证书异常.com.google.android.webview BUG等各种原因,都会导致WebViewClient无法访问HTTPS站点. ...
- 【每日日报】第五十三天---安装My SQL
1 2今天安装了My SQL并学习了一些基础的命令 mysql下载及安装教程 2 没有成功安装SQL Server,误删了一些文件 3 明天继续看视频 ------------------------ ...
- java的命令行参数到底怎么用,请给截图和实际的例子
8.2 命令行参数示例(实验) public class Test { public static void main(String[] args){ if(args.length ...
- 将java的对象或集合转成json形式字符串
将java的对象或集合转成json形式字符串: json的转换插件是通过java的一些工具,直接将java对象或集合转换成json字符串. 常用的json转换工具有如下几种: 1)jsonlib 需要 ...
- 在Nginx或Tengine服务器上安装证书
阿里云SSL证书服务支持下载证书并安装到Nginx.Tengine服务器上,本文介绍了证书安装的具体操作. 前提条件 已准备远程登录工具,例如PuTTY或者Xshell. 背景信息 本文档以CentO ...
- 微信小程序列表拖动排序Demo
wxml页面编写 <view class="container"> <view bindtap="box" class="box&q ...
- iwdg和wwdg
一.什么是看门狗? 在单片机工作的时候经常会出现受到外界电磁场的干扰导致程序跑飞,而陷入死循环,而使整个系统陷入无法正常工作的状态. "看门狗"是一种专门用于监测单片机程序运行状态 ...