【Spark】Day05-内核解析:组件、流程、部署、运行模式、通讯架构、任务调度(Stage、task级)、两种Shuffle机制、内存管理、核心组件
一、内核概述
内核:核心组件的运行机制、任务调度、内存管理、运行原理
1、核心组件
(1)Driver驱动器节点:执行main方法,将程序转化为作业job,在executor中调度任务task,跟踪并执行任务运行情况
(2)Executor:运行具体任务task,使用块管理器对RDD提供内存式存储
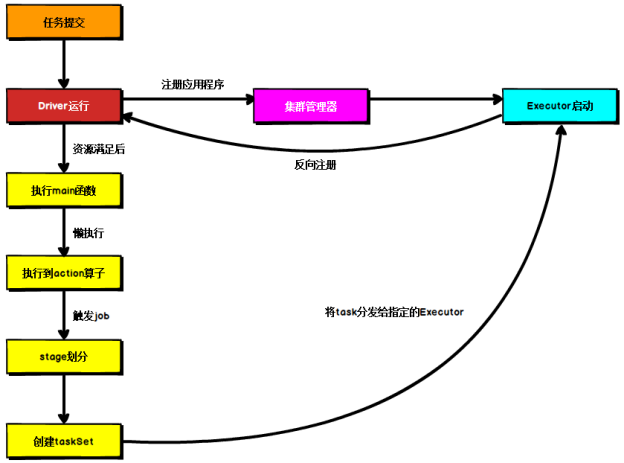
2、运行流程
提交任务、启动Driver进程、注册程序、分配Executor、执行main函数、懒执行到action算子时按照宽依赖对stage进行划分
一个stage对应一个taskset,将task分发到指定的Executor执行
二、Spark部署模式
三种集群管理器(Cluster Manager):Standalone(独立)、Mesos(分布式资源管理框架)、Yarn(统一的资源管理方式)
取决于传递给 SparkContext 的 MASTER 环境变量的值
–master MASTER_URL :决定了 Spark 任务提交给哪种集群处理(local本地运行、spark://HOST:PORT、mesos://HOST:PORT、yarn-client)
–deploy-mode DEPLOY_MODE:决定了 Driver 的运行方式,可选值为 Client 或者 Cluster。
1、Standalone模式运行机制
组成:Driver、Master(RM)、Work(NM)【存储RDD+启动Executor,执行计算】、Executor
Standalone Clint模式:Driver 在任务提交的本地机器上运行
Standalone Cluster模式:Master 会找到一个 Worker 启动 Driver
2、Yarn模式运行机制
Clint模式:Driver在任务提交的本地机器上运行,向ResourceManager申请资源,通知NodeManager分配Executor
Cluster模式:任务提交后会和ResourceManager通讯申请启动ApplicationMaster,RM分配容器,ApplicationMaster就是Driver
三、Spark通讯架构
1、概述
spark 基于netty的rpc框架基于Actor模型
独立实体之间通过消息来进行通信
Endpoint端点(Client/Master/Worker)有1个InBox和N个OutBox
(N>=1,N 取 决于当前 Endpoint 与多少其他的 Endpoint 进行通信,一个与其通讯的其他 Endpoint对应一个 OutBox)
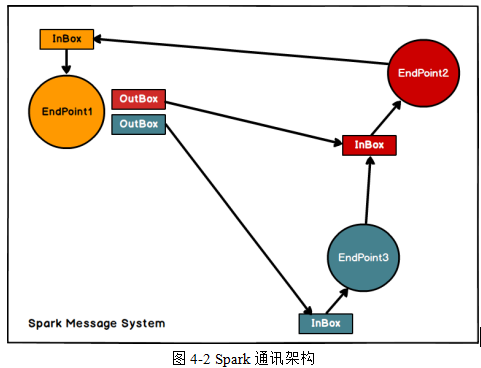
Endpoint 接收到的消息被写入 InBox,发送出去的消息写入 OutBox 并被发送到其他 Endpoint 的 InBox 中。
2、解析
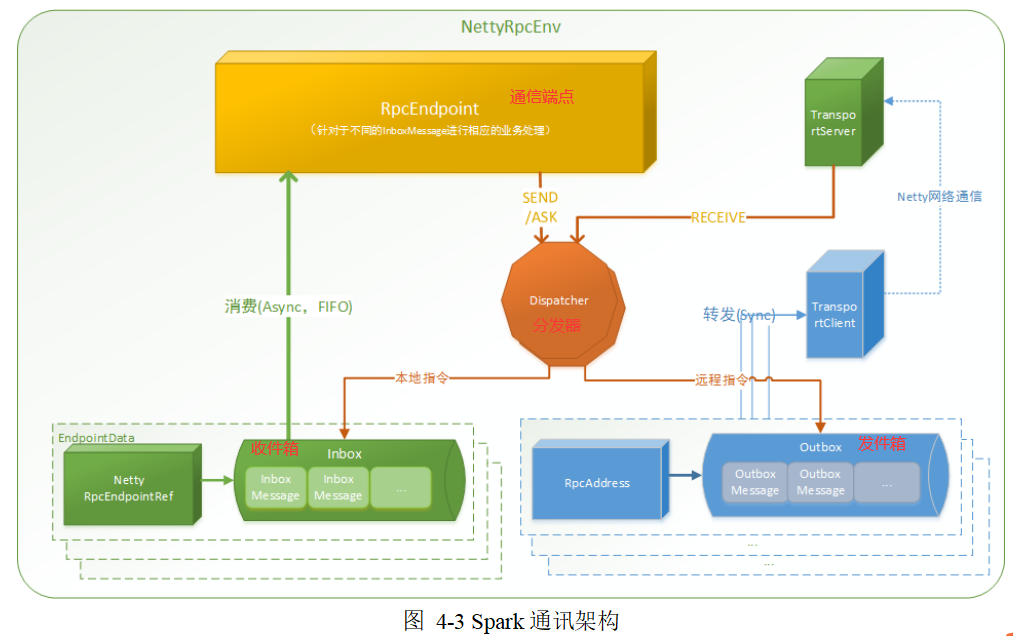
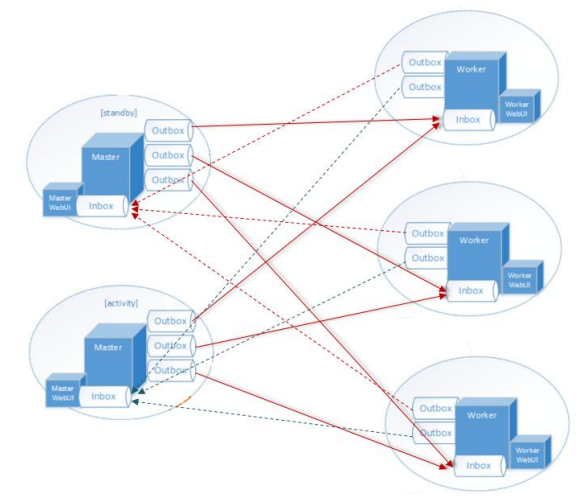
通信框架高层视图
四、Spark任务调度机制
默认集群的部署方式为YARN-Cluster模式
1、任务提交流程
Driver线程(1)初始化SparkContext对象,准备运行所需的上下文,(2)保持与ApplicationMaster的RPC连接,通过ApplicationMaster申请资源,(3)根据用户业务逻辑开始调度任务,将任务下发到已有的空闲Executor上。
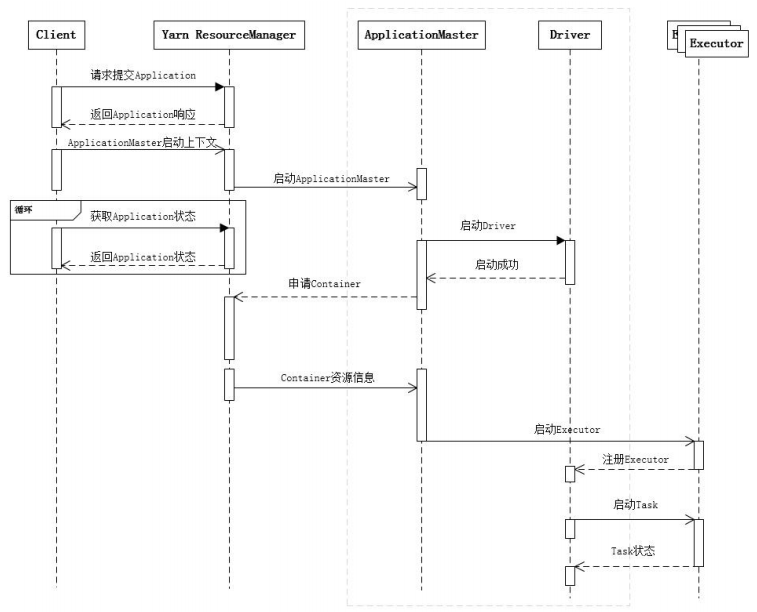
2、任务调度概述
Driver会根据用户程序逻辑准备任务,并根据Executor资源情况逐步分发任务
一个Spark应用程序包括Job、Stage以及Task三个概念
Stage 是 Job 的子集,以 RDD 宽依赖(即 Shuffle)为界
Task是Stage的子集,以并行度(分区数)来衡量,分区数是多少,则有多少个task。
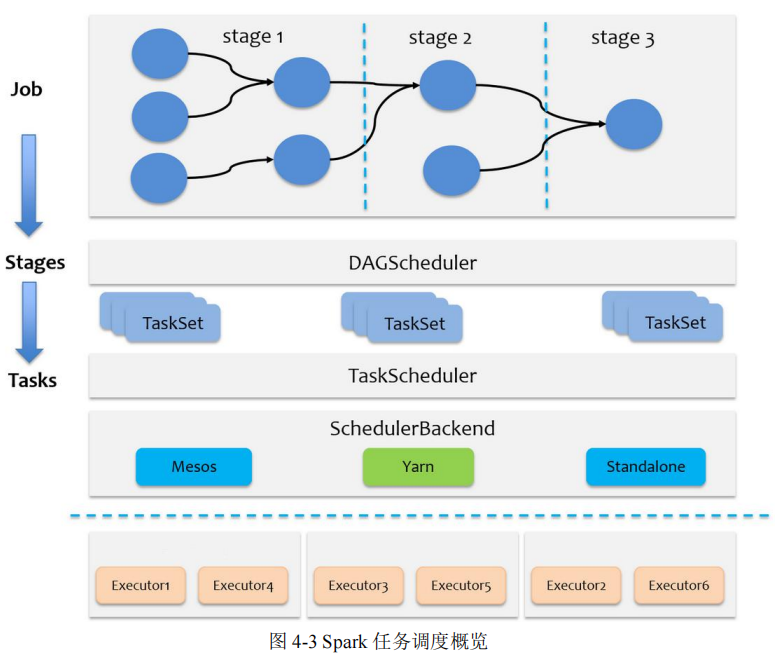
Spark的任务调度分为Stage级的调度,以及Task级的调度
Spark RDD通过其Transactions操作,形成了RDD血缘关系图,即DAG
DAGScheduler负责Stage级的调度,TaskScheduler负责Task级的调度
调度过程中SchedulerBackend负责提供可用资源,其中SchedulerBackend有多种实现,分别对接不同的资源管理系统
ApplicationMaster、Driver以及Executor内部模块的交互过程:
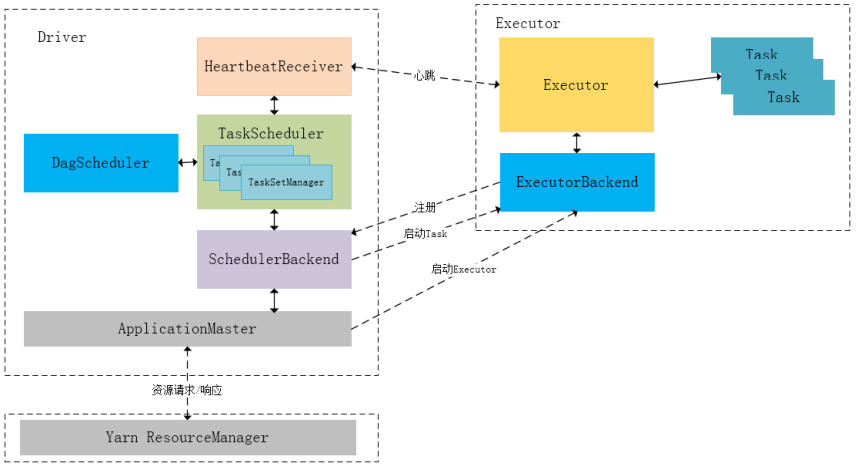
Driver初始化SparkContext过程中,会分别初始化DAGScheduler、TaskScheduler、SchedulerBackend以及HeartbeatReceiver,并启动SchedulerBackend以及HeartbeatReceiver
3、Spark Stage 级调度
从DAG切割开始,主要是由DAGScheduler来完成。当遇到一个Action操作后就会触发一个Job的计算,并交给DAGScheduler来提交

4、Task级调度
(1)调度方式
Spark Task的调度是由TaskScheduler来完成
TaskSetManager 负责监控管理同一个 Stage 中的 Tasks
(2)调度策略
TaskScheduler 支持两种调度策略,一种是 FIFO(TaskSetManager),也是默认的调度策略,另一 种是 FAIR。
FAIR 模式中有一个 rootPool 和多个子 Pool,各个子 Pool 中存储着所有待分配 的 TaskSetMagager,公平的排序算法
通过 minShare 和 weight 这两个参数控制比较过程,可以做到 让 minShare 使用率和权重使用率少(实际运行 task 比例较少)的先运行。
(3)本地化调度
根据task位置,确定locality本地化存放级别(task和数据分别在什么位置):进程、节点、机架等【task优先位置与其对应的partition对应的优先位置一致】
(4)失败重试与黑名单机制
TaskSetManager知道Task的失败与成功状态,未超过最大重试次数,放回待调度的Task池子
黑名单:记录task失败时的Executor Id 和 Host
五、Spark Shuffle机制
1、核心要点
(1)ShuffleMapStage (结束对应写磁盘)与 ResultStage(结束对应job结束)
执行到 Shuffle 操作时,map 端的 task 个数和 partition 个数一致,即 map task 为 N 个
(2)Shuffle 中的任务个数:取 spark.default.parallelism 这个配置项的值作为分区数;
如果不配置,分区数就决定了reduce端的task的个数
(3)reduce 端数据的读取:map task 位于 ShuffleMapStage,reduce task 位于 ResultStage
map时,本进程中的 MapOutputTrackerWorker 向 Driver 进程中的 MapoutPutTrakcerMaster 请求磁盘小文件的位置信息
Map task执行完毕后,MapOutPutTrackerMaster会告诉MapOutPutTrackerWorker磁盘小文件的位置信息
2、HashShuffle 解析
未经优化时:先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。
spark.shuffle. consolidateFiles开启优化设置
优化后:
每 个 shuffleFileGroup 会对应一批磁盘文件,磁盘文件的数量与下游 stage 的 task 数量是 相同的。
新task复用复用之前已有的 shuffleFileGroup,将多个task的磁盘文件合并
3、SortShuffle 解析
(1)普通运行机制:根据key排序后merge临时文件,最后依次写入磁盘
每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值
到达阈值后会先根据key对内存数据结构中已有的数据进行排序,然后再溢写到磁盘
(2)bypass运行机制:
spark.shuffle.sort. bypassMergeThreshold 参数的值时(默认为 200)且不是聚合类的 shuffle 算子
每个 task 会为每个下游 task 都创建一个临时磁盘文件,并将数据按 key 进行 hash 然后根据 key 的 hash 值,将 key 写入对应的磁盘文件之中
为每个下游task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中
运行机制的不同在于:第一,磁盘写机制 不同;第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write 过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
六、Spark内存管理
Driver负责创建 Spark 上下文,提交 Spark 作业(Job), 并将作业转化为计算任务(Task),在各个 Executor 进程间协调任务的调度
Executor执行具体的计算任务,并将结果返回给 Driver,同时为需要持 久化的 RDD 提供存储功能。
1、堆内和堆外内存规划
堆内:申请释放(删除引用或等待GC)由JVM完成
堆外:直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据。
申请释放不再通过JVM,降低了GC难度
通过配置 spark.memory.offHeap.enabled 参 数启用,并由 spark.memory.offHeap.size 参数设定堆外空间的大小
2、内存空间分配
静态分配:启动前配置,运行期间固定(存储内存和执行内存分开)
统一内存管理:存储内存 和执行内存共享同一块空间,可以动态占用对方的空闲区域
3、存储内存管理
RDD的持久化机制(7种存储级别)
Spark 的 Storage 模块完成RDD的持久化
以 Block 为基本存储单位,RDD 的每个 Partition 经 过处理后唯一对应一个 Block
具有7种持久化级别
RDD的缓存过程
将 Partition 由不连续的存储空间转换为连续存储空间的过程,Spark 称之为"展开"(Unroll)
淘汰与落盘
被淘汰的 Block 如果其存储级别中同时包 含存储到磁盘的要求,则要对其进行落盘(Drop)
4、执行内存管理
Shuffle Write:普通排序和Tungsten序列化形式排序
Shuffle Read:Aggregator聚合、最终使用ExternalSorter
七、Spark核心组件解析
1、BlockManager 数据存储与管理机制
包含组件:磁盘、内存、链接
2、Spark 共享变量底层实现
广播变量:每个均拷贝一份
累加变量:共同操作,只有 Driver 程序可以读取 Accumulator 的值
【Spark】Day05-内核解析:组件、流程、部署、运行模式、通讯架构、任务调度(Stage、task级)、两种Shuffle机制、内存管理、核心组件的更多相关文章
- Spark安装部署| 运行模式
Spark 一种基于内存的快速.通用.可扩展的大数据分析引擎: 内置模块: Spark Core(封装了rdd.任务调度.内存管理.错误恢复.与存储系统交互): Spark SQL(处理结构化数据). ...
- spark之scala程序开发(集群运行模式):单词出现次数统计
准备工作: 将运行Scala-Eclipse的机器节点(CloudDeskTop)内存调整至4G,因为需要在该节点上跑本地(local)Spark程序,本地Spark程序会启动Worker进程耗用大量 ...
- Gravitational Teleport docker-compose组件独立部署运行
Gravitational Teleport 可以作为堡垒机进行使用,上次写过一个all in one 的,这次参考官方 的配置运行一个proxy node auth 分离的应用 备注: 基于dock ...
- spark(四)yarn上的运行模式
架构图 yarn-cluster yarn-client 区别 Yarn-cluster spark的driver运行在applicationMaster内,启动流程为: 这张图可能比较直观 Yarn ...
- 运行SPL Streams debugger(sdb)的两种方法
You can use the SPL Streams Debugger in InfoSphere® Streams Studio to help you debug your SPL applic ...
- Nginx部署静态页面及引用图片有效访问的两种方式
nginx安装百度一下有很多,直接正题: 静态文件目录结构 file#文件位置 /home/service/file/ css js images html fonts 配置nginx.conf核心代 ...
- 【原】Spark不同运行模式下资源分配源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Task的提交源码解读 http://www.cnblogs.com/yourarebest/p/5423906.html Sch ...
- Spark的 运行模式详解
Spark的运行模式是多种多样的,那么在这篇博客中谈一下Spark的运行模式 一:Spark On Local 此种模式下,我们只需要在安装Spark时不进行hadoop和Yarn的环境配置,只要将S ...
- 【转载】Spark系列之运行原理和架构
参考 http://www.cnblogs.com/shishanyuan/p/4721326.html 1. Spark运行架构 1.1 术语定义 lApplication:Spark Applic ...
- [转帖]kubernetes ingress 在物理机上的nodePort和hostNetwork两种部署方式解析及比较
kubernetes ingress 在物理机上的nodePort和hostNetwork两种部署方式解析及比较 https://www.cnblogs.com/xuxinkun/p/11052646 ...
随机推荐
- 5.云原生之Docker容器网络介绍与实践
转载自:https://www.bilibili.com/read/cv15185166/?from=readlist 例如, 当在一台未经过特殊网络配置的centos 或 ubuntu机器上安装完d ...
- 胎压监测系统(DWS)
胎压监测系统(DWS)通过监测和比较行驶时各车轮和轮胎的滚动半径和旋转特性,以确定是否一个或多个轮胎明显充气不足,而非直接测量各轮胎的压力. 系统监测到异常时指示灯将点亮,且仪表上出现信息. 必须校准 ...
- 使用supervisor管理tomcat,nginx等进程详解
1,介绍 官网:http://supervisord.org Supervisor是用Python开发的一套通用的进程管理程序,能将一个普通的命令行进程变为后台daemon,并监控进程状态,异常退出时 ...
- 01_Typora学习
Typora学习 使用Typora 编辑器 一. 标题 一个#后加空格表示一级标题(快捷键Ctrl+1) 两个#后加空格表示二级标题(快捷键Ctrl+2) 以此类推,目前最多到六级标题(快捷键Ctrl ...
- 右击存放项目的文件夹出现 open with Visual Studio Code 的打开方式
最终效果 步骤1: 找到 Visual Studio Code 的安装位置 (右击桌面Visual Studio Code 图标-->属性-->打开文件夹所在位置) 新建一个可以编辑的 c ...
- Kafka之概述
Kafka之概述 一.消息队列内部实现原理 (1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除) 点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消 ...
- PHP微信支付功能
百度网盘:http://pan.baidu.com/s/1sl5GeVr l5ud 先下载一份sdk ,引入到自己的项目中,我用的是TP5,配置好namespace 然后在项目中引入: 之后,在去配 ...
- 你应该知道的数仓安全:都是同名Schema惹的祸
摘要:我是管理员账号,怎么还没有权限?当小伙伴询问的时候,我第一时间就会想到都是用户同名Schema惹的祸 本文分享自华为云社区<你应该知道的数仓安全--都是同名Schema惹的祸>,作者 ...
- 长文梳理muduo网络库核心代码、剖析优秀编程细节
前言 muduo库是陈硕个人开发的tcp网络编程库,支持Reactor模型,推荐大家阅读陈硕写的<Linux多线程服务端编程:使用muduo C++网络库>.本人前段时间出于个人学习.找工 ...
- 云数据库时代,DBA将走向何方?
摘要:伴随云计算的迅猛发展,数据库也进入了云时代.云数据库不断涌现,产品越来越成熟和智能,作为数据库管理员的DBA将面临哪些机遇和挑战?又应该具备什么能力,才能应对未来的不确定性? 本文分享自华为云社 ...