UniqueMergeTree:支持实时更新删除的 ClickHouse 表引擎
UniqueMergeTree 开发的业务背景
首先,我们看一下哪些场景需要用到实时更新。
我们总结了三类场景:
第一类是业务需要对它的交易类数据进行实时分析,需要把数据流同步到 ClickHouse 这类 OLAP 数据库中。大家知道,业务数据诸如订单数据天生是存在更新的,所以需要 OLAP 数据库去支持实时更新。
第二个场景和第一类比较类似,业务希望把 TP 数据库的表实时同步到 ClickHouse,然后借助 ClickHouse 强大的分析能力进行实时分析,这就需要支持实时的更新和删除。
最后一类场景的数据虽然不存在更新,但需要去重。大家知道在开发实时数据的时候,很难保证数据流里没有重复数据,因此通常需要存储系统支持数据的幂等写入。
我们可以总结一下这三类场景的共同点:
- 从数据的新鲜度看
这三个场景其实都不需要亚秒级的新鲜度,往往做到秒级或者分钟级的数据新鲜度就可以了,因此可以采用 mini-batch 的实时同步方案。
- 从使用上看
这三类场景都可以通过提供基于唯一键的 upsert 功能来实现,不管是更新还是幂等处理的需求。
- 从读写要求上看
因为大家用 OLAP 数据库最核心的诉求是希望查询可以有一个非常低的延迟,所以对读的性能要求是非常高的。对于写,虽然也需要高吞吐,但更多关注 Scalability,即能否通过加资源来提高数据流的写吞吐。
- 从高可用性上看
这三个场景都需要能支持多副本,来避免整个系统存在单点故障。
以上就是我们开发 UniqueMergeTree 的背景。
常见的列存储实时更新方案
下面介绍下在列存储里支持实时更新的常见技术方案。
key-based merge on read
第一个方案叫 key-based merge on read,它的整个思想比较类似 LSMTree。对于写入,数据先根据 key 排序,然后生成对应的列存文件。每个 Batch 写入的文件对应一个版本号,版本号能用来表示数据的写入顺序。
同一批次的数据不包含重复 key,但不同批次的数据包含重复 key,这就需要在读的时候去做合并,对 key 相同的数据返回去最新版本的值,所以叫 merge on read 方案。ClickHouse 的 ReplacingMergeTree 和 Doris 用的就是这种方案。
大家可以看到,它的写路径是非常简单的,是一个很典型的写优化方案。它的问题是读性能比较差,有几方面的原因。首先,key-based merge 通常是单线程的,比较难并行。其次 merge 过程需要非常多的内存比较和内存拷贝。最后这种方案对谓词下推也会有一些限制。大家用过 ReplacingMergeTree 的话,应该对读性能问题深有体会。
这个方案也有一些变种,比如说可以维护一些 index 来加速 merge 过程,不用每次 merge 都去做 key 的比较。
mark-delete + insert
mark-delete + insert 刚好反过来,是一个读优化方案。在这个方案中,更新是通过先删除再插入的方式实现的。
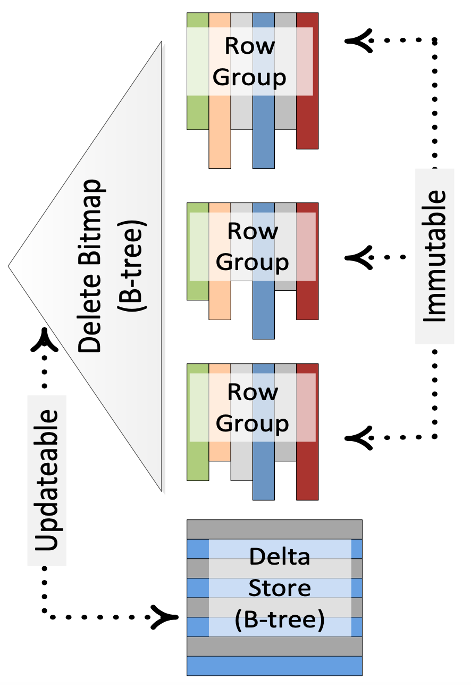
Ref “Enhancements to SQLServer Column Stores”
下面以 SQLServer 的 Column Stores 为例介绍下这个方案。图中,每个 RowGroup 对应一个不可变的列存文件,并用 Bitmap 来记录每个 RowGroup 中被标记删除的行号,即 DeleteBitmap。处理更新的时候,先查找 key 所属的 RowGroup 以及它在 RowGroup 中行号,更新 RowGroup 的 DeleteBitmap,最后将更新后的数据写入 Delta Store。查询的时候,不同 RowGroup 的扫描可以完全并行,只需要基于行号过滤掉属于 DeleteBitmap 的数据即可。
这个方案牺牲了写入性能。一方面写入时需要去定位 key 的具体位置,另一方面需要处理 write-write 冲突问题。
这个方案也有一些变种。比如说写入时先不去查找更新 key 的位置,而是先将这些 key 记录到一个 buffer 中,使用后台任务将这些 key 转成 DeleteBitmap。然后在查询的时候通过 merge on read 的方式处理 buffer 中的增量 key。
由于 ClickHouse 的 ReplacingMergeTree 已经实现了方案一,所以我们希望 UniqueMergeTree 能实现读优化的方案。
UniqueMergeTree 使用与实现
下面介绍 UniqueMergeTree 的具体使用。我们先介绍一下它的特性。
UniqueMergeTree 表引擎特性
首先 UniqueMergeTree 支持通过 UNIQUE KEY 关键词来指定这张表的唯一键,引擎会实现唯一约束。对于 UNIQUE 表的写入,我们会采用 upsert 的语义,即如果写入的是新 key,那就直接插入数据;如果写入的 key 已经存在,那就更新对应的数据。
然后我们也支持,指定 UNIQUE KEY 的 value 来删除数据,满足实时行删除的需求。然后和 ReplacingMergeTree 一样,也支持指定一个版本字段来解决回溯场景可能出现的低版本数据覆盖高版本数据的问题。最后我们也支持数据在多副本的同步。
下面是一个使用示例。首先我们建了一张 UniqueMergeTree 的表,表引擎的参数和 ReplacingMergeTree 是一样的,不同点是可以通过 UNIQUE KEY 关键词来指定这张表的唯一键,它可以是多个字段,可以包含表达式等等。

下面对这张表做写入操作就会用到 upsert 的语义,比如说第 6 行写了四条数据,但只包含 1 和 2 两个 key,所以对于第 7 行的 select,每个 key 只会返回最高版本的数据。对于第 11 行的写入,key 2 是一个已经存在的 key,所以会把 key 2 对应的 name 更新成 B3; key 3 是新 key,所以直接插入。最后对于行删除操作,我们增加了一个 delete flag 的虚拟列,用户可以通过这个虚拟列标记 Batch 中哪些是要删除,哪些是要 upsert。
示例展示的是单 shard 的写入,而生产环境通常包含多个 shard,。多个 shard 写入的时候就涉及到了你要解决数据分片的问题,其实它的主要目的就是我们需要把相同的 key 的数据写到同一个 shard 里,不然如果你的 key 可能存在多个 shard 的话,你的去重开销就非常大。
分布式表写入: 分片方案选择
上面的示例展示了单 shard 的写入,然而生产环境通常包含多个 shard,如何实现相同 key 的数据写往同一个 shard 呢?这里有两种方案。
internal sharding: 即由引擎本身来实现数据的分片。具体来说,可以直接把数据写到 ClickHouse 的分布式表,它会根据 sharding key 实现数据的分片和路由。Internal sharding 的优点是分片方式对用户透明,不容易出错;另外不同表的分片算法是一致的,在做多表关联的时候,可以利用数据的分片特征来优化查询。这是 ByteHouse 云数仓版使用的方式。
external sharding: 由用户或者 SDK 负责数据的分片和路由,这是 ByteHouse 企业版使用的方式。Internal sharding 有个问题是,在实时写入场景,每个微批本身就不大,如果再对它进行分片会产生更多的小文件,影响写入吞吐。External sharding 在外部实现数据的攒批,每个微批只写一个 shard,这样 batch size 更大,整体的写吞吐会更高。它的问题是需要由用户端保证分片的正确性,比较容易出错。External sharding 比较适合 kafka 导入等单一写入场景。如果表有多个写入通道,用户需要保证多个通道采用一致的分片方式,成本更高。
单机版实现: UniqueMergeTree 读写链路
下面介绍下 UniqueMergeTree 在单节点的读写链路。
写链路: 首先要判断写入 key 所属的 part 以及它在 part 中的行号,接着去更新对应 part 的 delete bitmap,将写入 key 从原来的 part 里标记删除掉,最后将新数据写入新 part 里。为了实现上面的逻辑,我们为每个 part 新增了一个 key index,用于加速从唯一键值到行号的查找。另外每个 part 包含多个 delete file,每个 delete file 对应一个特定版本的 delete bitmap。
读链路: 先获取所有 part 的 delete bitmap 快照,然后读取每个 part 的时候使用对应的 delete bitmap 过滤掉标记删除的行。这样就保证了整体的唯一性约束。
此外,还需要考虑并发场景的两种冲突: write-write conflict 和 write-merge conflict。
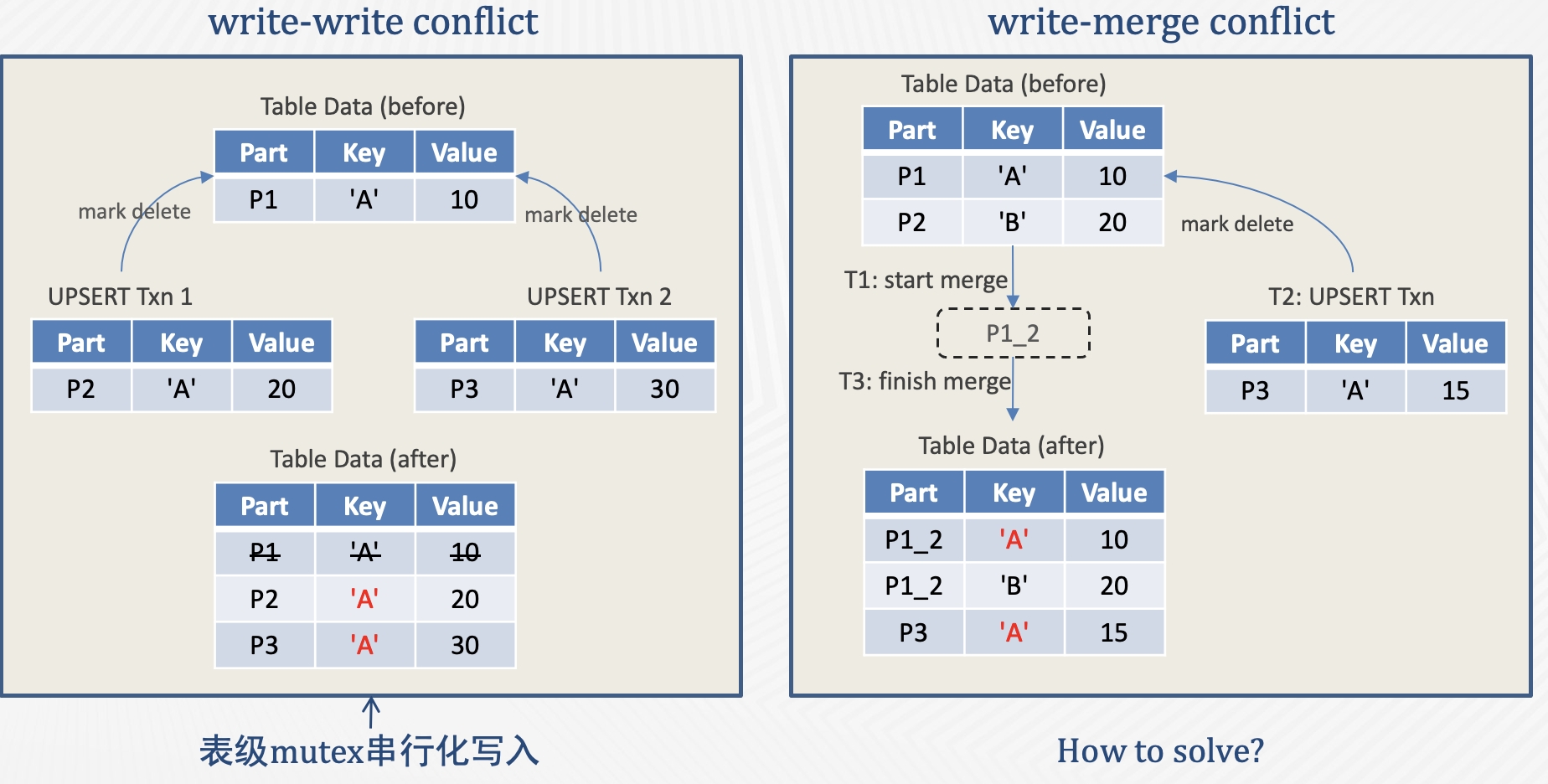
先介绍 write-write conflict。产生该冲突的原因是 write 使用了 upsert 语义,因此当两个并发事务更新同一行的时候会产生冲突。比如左图中的两个并发事务同时更新 P1 的 Key A 行,如果不做并发控制,两个事务可能都去标记删除 P1 中的 Key A 行,然后写出 P2 和 P3,最终 P2 和 P3 就同时包含了 Key A。
TP 数据库一般通过锁或者 OCC 的方式处理 write-write conflict,但在 AP 场景中用行锁或者行级冲突检测的代价是比较高的。考虑到 AP 场景数据都是批量写入,我们采用了更简单的表锁来实现单表的写入串行化。
再来看右图的 write-merge conflict。多个 part 在后台合并过程中,并发的前台写入事务可能会更新 part 的 delete bitmap。如果不做并发控制,就会发生写入事务标记删除的行在 part 合并后“复活”的现象。要解决这个问题,后台合并任务需要感知到合并过程中,前台写入事务更新了哪些 key。
处理 Write-Merge Conflict
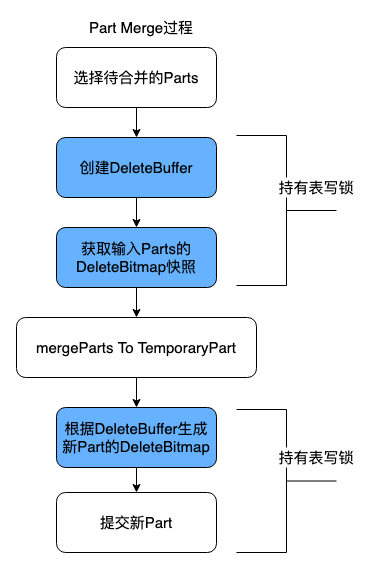
我们给每个 merge task 新增了一个 DeleteBuffer,用于缓存 merge 过程中前台写入任务删除的 key。
Merge task 开始时,先获取表锁创建 DeleteBuffer,并获取 input part 的 delete bitmap 快照。接着读取 input part,过滤掉标记删除的行,生成合并后的临时 part。这个过程中,并发的写入事务如果发现要更新 delete bitmap 的 part 正在被合并,就会将要删除的 key 记录到 merge task 的 DeleteBuffer。Merge task 在提交前会再次获取表锁,将 DeleteBuffer 中的 key 转成新 part 的 delete bitmap。
那么如何限制 DeleteBuffer 的内存使用呢?一种简单有效的方式是,写入事务如果发现 DeleteBuffer 的大小超过了阈值,就直接 abort 对应的 merge 任务,等待下次合并。因为 DeleteBuffer 比较大说明在合并过程中 input part 有很多增量的删除,重试可以减小 merge 后的 part 大小。
性能评估
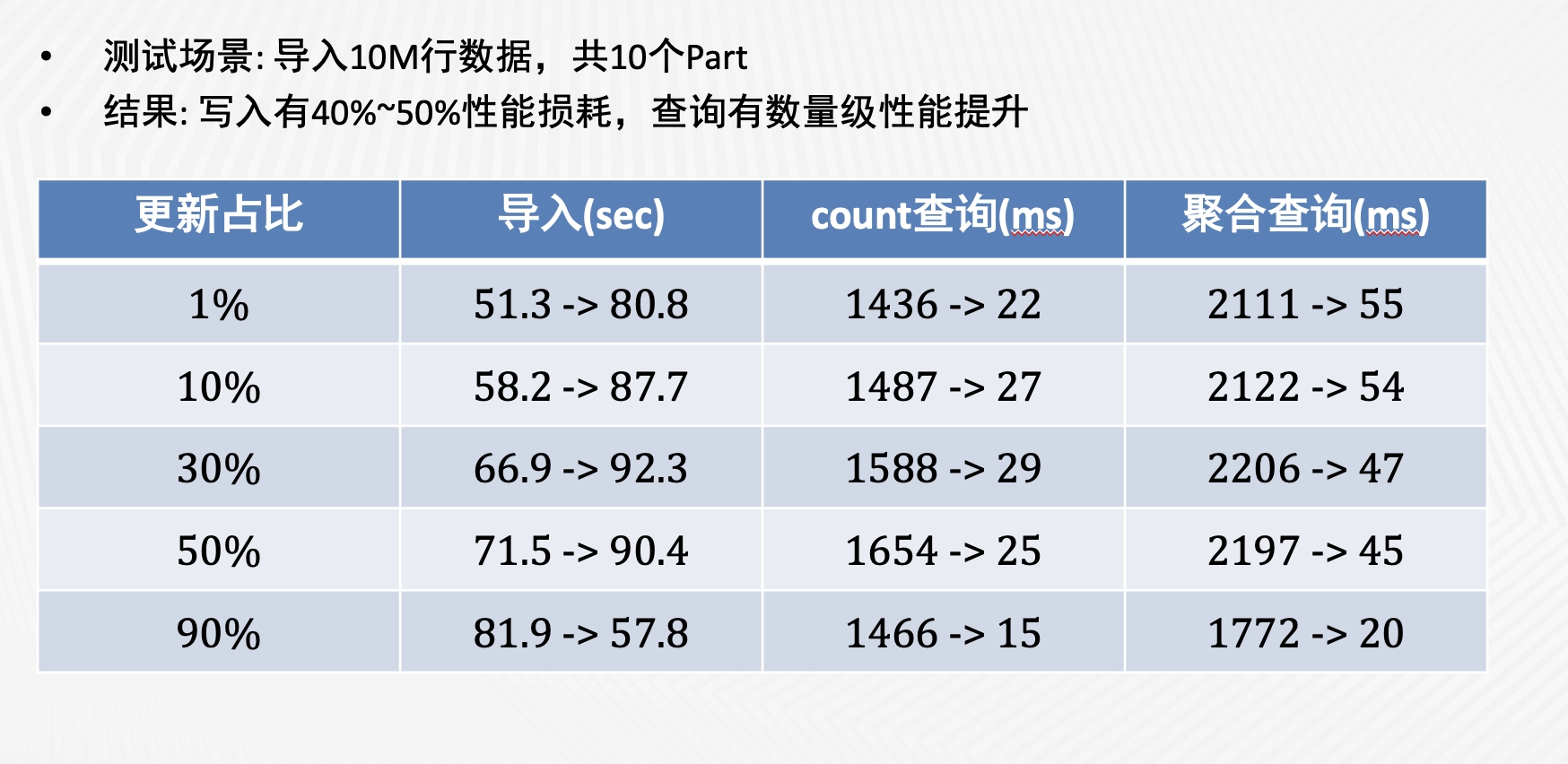
我们使用 YCSB 对 UniqueMergeTree 的写入和查询性能做了性能测试,结果如上图。可以看到,与 ReplacingMergeTree 相比,UniqueMergeTree 的写入性能虽然会有 40%到 50%的下降,但在查询性能上取得了数量级的提升。我们进一步对比了 UniqueMergeTree 和普通 MergeTree 的查询性能,发现两者是非常接近的。查询性能的提升主要归功于以下几点:
避免了单线程的 merge-on-read,流水线完全并行化
DeleteBitmap 的最新版本常驻内存
标记删除的 Mark 可以直接跳过
Combine pre-where filter & delete filter,减少 IColumn::filter 次数
总结:经验与后续规划
我们在 2020 年初上线了 UniqueMergeTree,目前线上应用的表数量超过了 1000,还是非常受业务欢迎的。整个过程中,我认为做的比较对的决策有两点:
在读写权衡方面,牺牲一部分写性能来换取更高的读性能。我们发现很多业务场景的痛点是查询性能。虽然 UniqueMergeTree 的写吞吐不如 MergeTree,但通过增加 shard 横向扩展,已经能满足大部分业务的需求。
设计上没有对表的数据量做太多限制。例如 KeyIndex,一种做法是假设 KeyIndex 可以完全存储在内存中,但我们认为这会限制 UniqueMergeTree 的应用场景。因此虽然我们第一版实现的也是 in-meomry index,但后来比较顺利地演进到了 disk-based index。
对于后续规划,我们会重点尝试两个方向:
部分列更新:有些场景需要多个数据流更新同一张表的不同字段,因此需要部分列更新的能力。
写吞吐优化:写吞吐会直接影响每个集群能接入的实时数据规模。我们在表锁粒度和 KeyIndex 两方面都看到了进一步优化的空间。
基于开源 ClickHouse 的分析型数据库,支持用户交互式分析 PB 级别数据,通过多种自研表引擎,灵活支持各类数据分析和应用。
欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
UniqueMergeTree:支持实时更新删除的 ClickHouse 表引擎的更多相关文章
- 分布式配置系统Apollo如何实时更新配置的?
引言 记得我们那时候刚开始学习Java的时候都只是一个单体项目,项目里面的配置基本都是写在项目里面的properties文件中,比如数据库配置啥的,各种逻辑开关,一旦这些配置修改了,还需要重启项目这修 ...
- ClickHouse(10)ClickHouse合并树MergeTree家族表引擎之ReplacingMergeTree详细解析
目录 建表语法 数据处理策略 资料分享 参考文章 MergeTree拥有主键,但是它的主键却没有唯一键的约束.这意味着即便多行数据的主键相同,它们还是能够被正常写入.在某些使用场合,用户并不希望数据表 ...
- python---django中form组件(2)自定制属性以及表单的各种验证,以及数据源的实时更新,以及和数据库关联使用ModelForm和元类
自定义属性以及各种验证 分析widget: class TestForm(forms.Form): user = fields.CharField( required = True, widget = ...
- MySQL 实现将一个库表里面的数据实时更新到另一个库表里面
MySQL 实现将一个库表里面的数据实时更新到另一个库表里面 需求描述:MySQL 里面有很多的数据库,这些数据库里面都有同一种表结构的表 (tb_warn_log),这张表的数据是实时更新的,现在需 ...
- 我的MYSQL学习心得(八) 插入 更新 删除
我的MYSQL学习心得(八) 插入 更新 删除 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得( ...
- facebook充值实时更新接口文档翻译 希望对做facebook充值的小伙伴有帮助
Realtime Updates for Payments are an essential method by which you are informed of changes to orders ...
- sphinx通过增量索引实现近实时更新
一.sphinx增量索引实现近实时更新设置 数据库中的已有数据很大,又不断有新数据加入到数据库中,也希望能够检索到.全部重新建立索引很消耗资源,因为我们需要更新的数据相比较而言很少. 例如.原来的数据 ...
- sphinx 增量索引 实现近实时更新
一.sphinx增量索引的设置 数据库中的已有数据很大,又不断有新数据加入到数据库中,也希望能够检索到.全部重新建立索引很消耗资源,因为我们需要更新的数据相比较而言很少.例如.原来的数据有几百万条 ...
- mysql查询更新时的锁表机制分析
为了给高并发情况下的mysql进行更好的优化,有必要了解一下mysql查询更新时的锁表机制. 一.概述 MySQL有三种锁的级别:页级.表级.行级.MyISAM和MEMORY存储引擎采用的是表级锁(t ...
随机推荐
- Java/C++实现备忘录模式--撤销操作
改进课堂上的"用户信息操作撤销"实例,使得系统可以实现多次撤销(可以使用HashMap.ArrayList等集合数据结构实现). 类图: Java代码: import java.u ...
- java中如何创建自定义异常Create Custom Exception
9.创建自定义异常 Create Custom Exception 马克-to-win:我们可以创建自己的异常:checked或unchecked异常都可以, 规则如前面我们所介绍,反正如果是chec ...
- python---希尔排序的实现
def shell_sort(alist): """希尔排序""" n = len(alist) gap = n // 2 # 插入算法执行 ...
- 六、IDEA安装
一.IDEA下载与安装 1.1.下载IDEA安装包 博主在这里给大家准备了一个64位操作系统的IDEA以便大家下载(使用的是迅雷) 点击此处下载 提取码:dgiy 如果其他小伙伴的电脑版本不一样,博主 ...
- QQ浏览器X5内核问题汇总 转
常常被人问及微信中使用的X5内核的问题,其实我也不是很清楚,只知道它是基于android 4.2的webkit,版本号是webkit 534.今天正好从X5团队拿到了一份问题汇总,梳理下发出来,给各位 ...
- 《手把手教你》系列基础篇(九十一)-java+ selenium自动化测试-框架设计基础-Logback实现日志输出-下篇(详解教程)
1.简介 为了方便查看和归档:(1)不同包的日志可能要放到不同的文件中,如service层和dao层的日志:(2)不同日志级别:调试.信息.警告和错误等也要分文件输出.所以宏哥今天主要介绍和分享的是: ...
- wireshark、tcpdump使用笔记
最近使用wireshark抓包icmp协议,过滤的命令如下所示: ip.addr eq 192.168.20.54 and ip.addr eq 192.168.50.131 and (icmp) 如 ...
- MySQL备份迁移之mydumper
简介 mydumper 是一款开源的 MySQL 逻辑备份工具,主要由 C 语言编写.与 MySQL 自带的 mysqldump 类似,但是 mydumper 更快更高效. mydumper 的一些优 ...
- Win10系统链接蓝牙设备
1. 进入控制面板,选择 设备 2. 进入设备界面,删除已有蓝牙,如果蓝牙耳机已经链接其他设备,先断开链接 3. 点击添加蓝牙或其他设备 4. 选择蓝牙,选择你的蓝牙耳机名称
- 面试官:我把数据库部署在Docker容器内,你觉得如何?
开源Linux 一个执着于技术的公众号 上一篇:CentOS 7上搭建Zabbix4.0 近2年Docker非常的火热,各位开发者恨不得把所有的应用.软件都部署在Docker容器中,但是您确定也要把数 ...