Redis 源码解析之通用双向链表(adlist)
Redis 源码解析之通用双向链表(adlist)
概述
Redis源码中广泛使用 adlist(A generic doubly linked list),作为一种通用的双向链表,用于简单的数据集合操作。adlist提供了基本的增删改查能力,并支持用户自定义深拷贝、释放和匹配操作来维护数据集合中的泛化数据 value。
adlist 的数据结构
- 链表节点
listNode, 作为双向链表,prev,next指针分别指向前序和后序节点。void*指针类型的value用于存放泛化的数据类型(如果数据类型的 size 小于sizeof(void*), 则可直接存放在value中。 否则value存放指向该泛化类型的指针)。
// in adlist.h
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
- 链表迭代器
listIter, 其中next指针指向下一次访问的链表节点。direction标识当前迭代器的方向是AL_START_HEAD(从头到尾遍历)还是AL_START_TAIL(从尾到头遍历)。
// in adlist.h
typedef struct listIter {
listNode *next;
int direction;
} listIter;
/* Directions for iterators */
#define AL_START_HEAD 0
#define AL_START_TAIL 1
- 双向链表结构
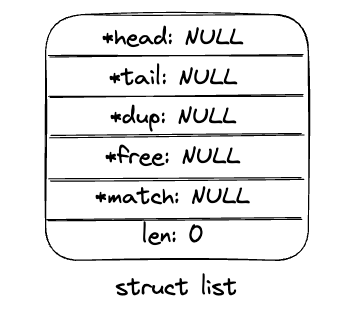
list。 其中,head和tail指针分别指向链表的首节点和尾节点。len记录当前链表的长度。函数指针dup,free和match分别代表业务注册的对泛化类型value进行深拷贝,释放和匹配操作的函数。(如果没有注册dup, 则默认进行浅拷贝。 如果没有注册free, 则不对value进行释放。如果没有注册match则直接比较value的字面值)
// in adlist.h
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
adlist 的基本操作
- 创建:
listCreate初始化相关字段为零值。可以通过listSetDupMethod,listSetFreeMethod,listSetMatchMethod来注册该链表泛化类型value的dup,free和match函数。
/* Create a new list. The created list can be freed with
* listRelease(), but private value of every node need to be freed
* by the user before to call listRelease(), or by setting a free method using
* listSetFreeMethod.
*
* On error, NULL is returned. Otherwise the pointer to the new list. */
list *listCreate(void)
{
struct list *list;
if ((list = zmalloc(sizeof(*list))) == NULL)
return NULL;
list->head = list->tail = NULL;
list->len = 0;
list->dup = NULL;
list->free = NULL;
list->match = NULL;
return list;
}
#define listSetDupMethod(l,m) ((l)->dup = (m))
#define listSetFreeMethod(l,m) ((l)->free = (m))
#define listSetMatchMethod(l,m) ((l)->match = (m))
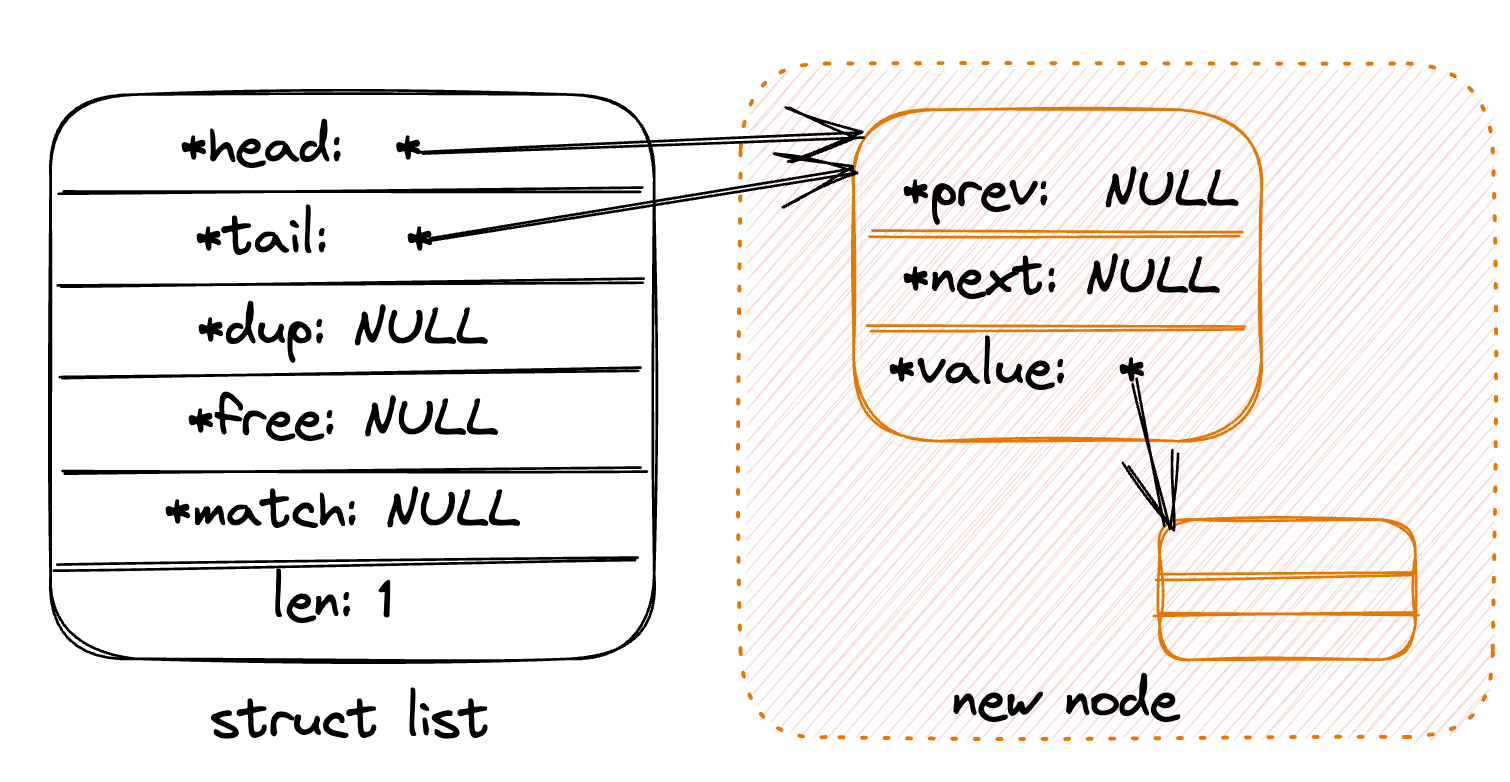
- 在链表首插入新节点:
listAddNodeHead
在空链表插入新节点: 为
value创建新节点,并让list的head和tail都指向新节点。
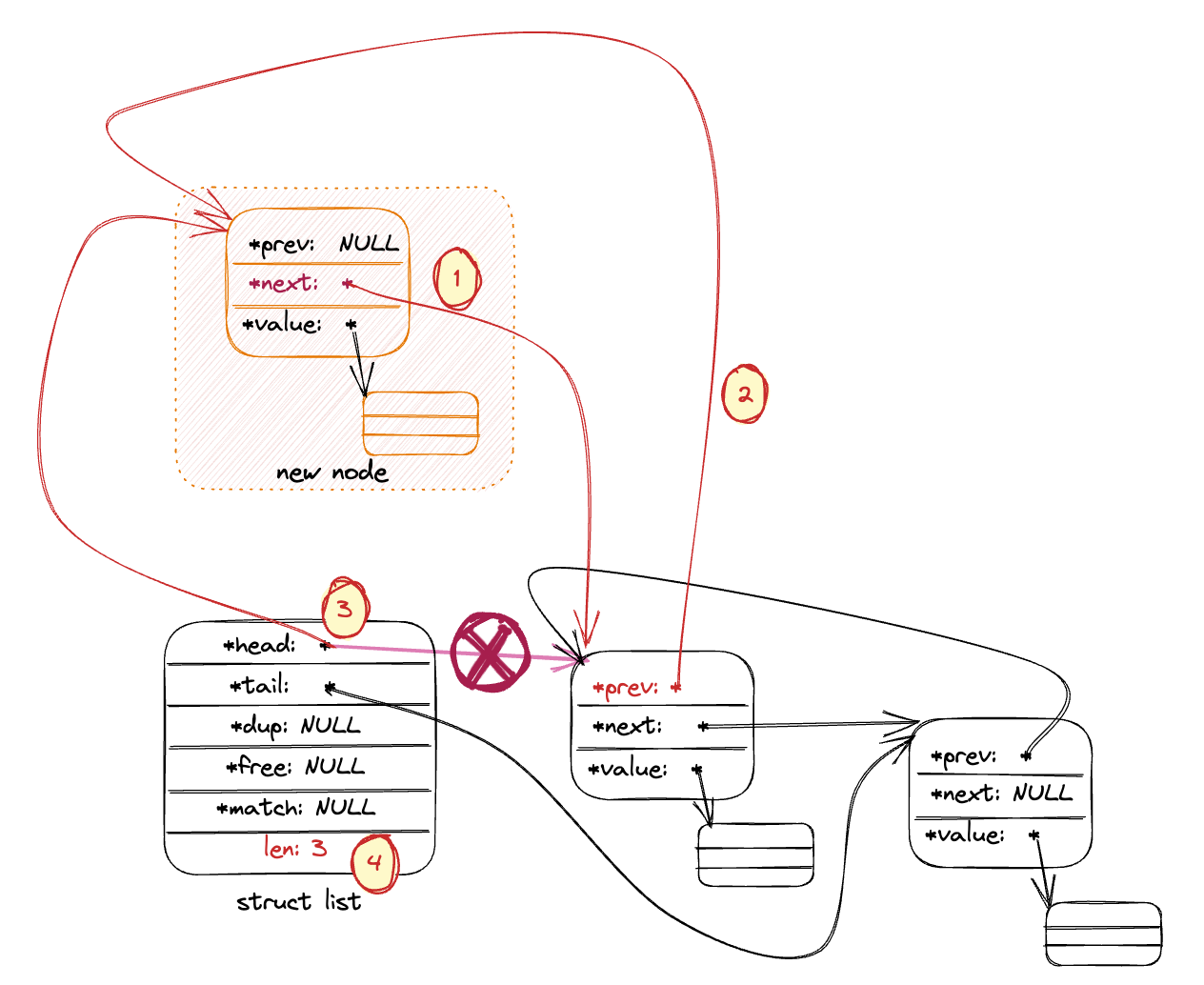
在非空链表插入新节点:
(1) 将新节点的next指向当前首节点(当前首节点将成为第二节点, 将会是新节点的后继节点)
(2) 将当前节点的prev指向新节点, 新节点作为新的首节点将成为原首节点的前驱节点。
(3) 将head从原本指向旧的首节点改为指向新节点, 将新节点作为链表首。
(4) 链表总计数加一
/* Add a new node to the list, to head, containing the specified 'value'
* pointer as value.
*
* On error, NULL is returned and no operation is performed (i.e. the
* list remains unaltered).
* On success the 'list' pointer you pass to the function is returned. */
list *listAddNodeHead(list *list, void *value)
{
listNode *node;
if ((node = zmalloc(sizeof(*node))) == NULL)
return NULL;
node->value = value;
listLinkNodeHead(list, node);
return list;
}
/*
* Add a node that has already been allocated to the head of list
*/
void listLinkNodeHead(list* list, listNode *node) {
if (list->len == 0) {
list->head = list->tail = node;
node->prev = node->next = NULL;
} else {
node->prev = NULL;
node->next = list->head;
list->head->prev = node;
list->head = node;
}
list->len++;
}
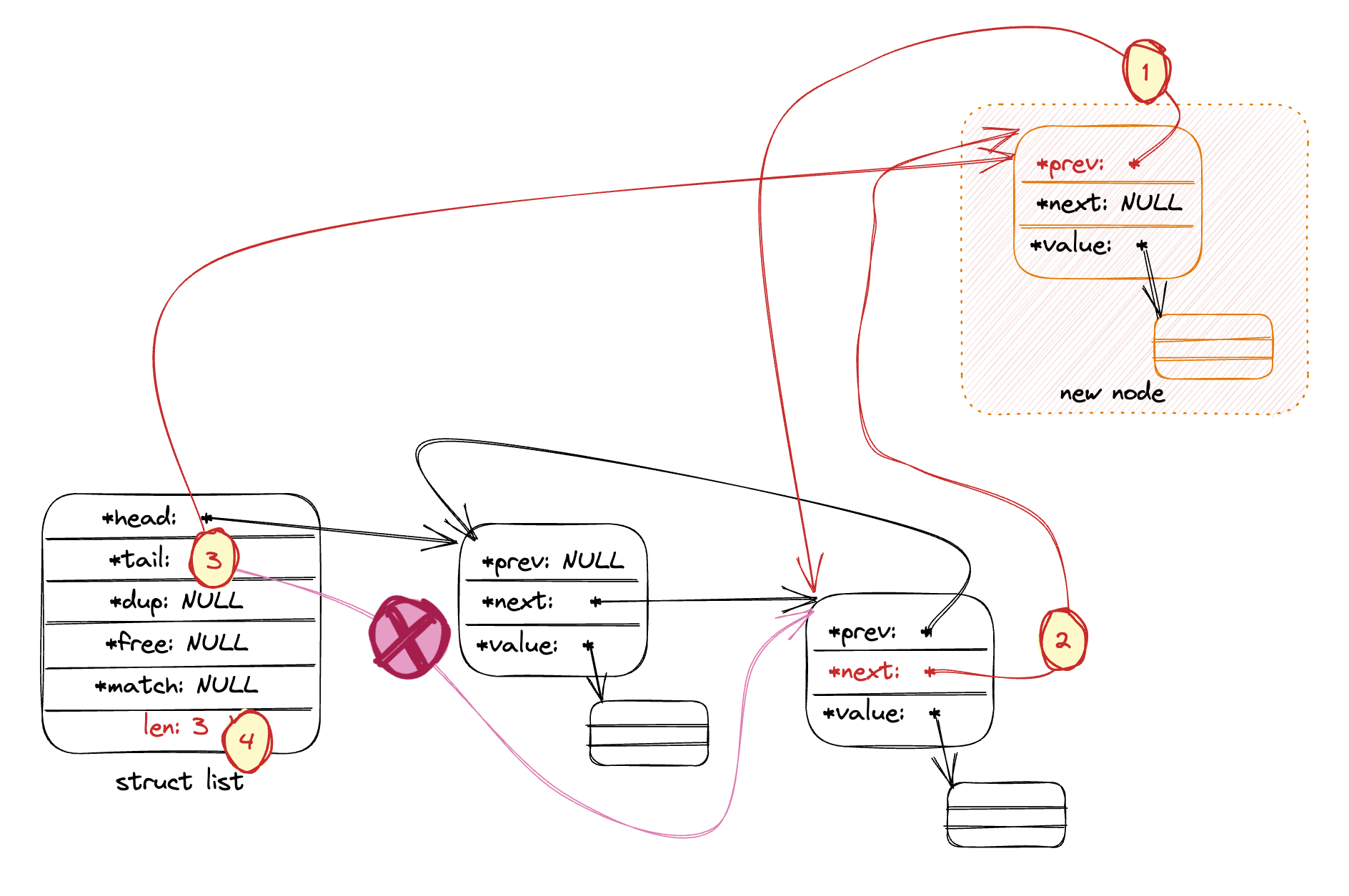
- 在链表尾插入新节点:
listAddNodeTail
- 在空链表插入新节点: 逻辑与
listAddNodeHead实现一致。 - 在非空链表插入新节点:
(1) 将新节点的prev指向当前首节点(当前尾节点将成为倒数第二节点, 将会是新节点的前驱节点)
(2) 将当前节点的next指向新节点, 新节点作为新的尾节点将成为原尾节点的后继节点。
(3) 将tail从原本指向旧的尾节点改为指向新节点, 将新节点作为链表尾。
(4) 链表总计数加一
/* Add a new node to the list, to tail, containing the specified 'value'
* pointer as value.
*
* On error, NULL is returned and no operation is performed (i.e. the
* list remains unaltered).
* On success the 'list' pointer you pass to the function is returned. */
list *listAddNodeTail(list *list, void *value)
{
listNode *node;
if ((node = zmalloc(sizeof(*node))) == NULL)
return NULL;
node->value = value;
listLinkNodeTail(list, node);
return list;
}
/*
* Add a node that has already been allocated to the tail of list
*/
void listLinkNodeTail(list *list, listNode *node) {
if (list->len == 0) {
list->head = list->tail = node;
node->prev = node->next = NULL;
} else {
node->prev = list->tail;
node->next = NULL;
list->tail->next = node;
list->tail = node;
}
list->len++;
}
- 在链表指定位置插入
value:listInsertNode。如果after为非零, 则将新节点作为old_node后继节点。否则,新节点作为old_node前驱节点。下图以after为非零作为例子, 描述了这部分的代码逻辑。
(1) 将新节点的prev指向old_node(新节点插入在old_node之后);
(2) 将新节点的next指向old_node的后继节点(old_node的后继节点将成为新节点的后继节点);
(3) 将old_node的next指向新节点;
(4) 将新节点的后继节点的prev指向新节点(old_node的原后继节点现在成为了新节点的后继节点) 。
(5) 链表总计数加一
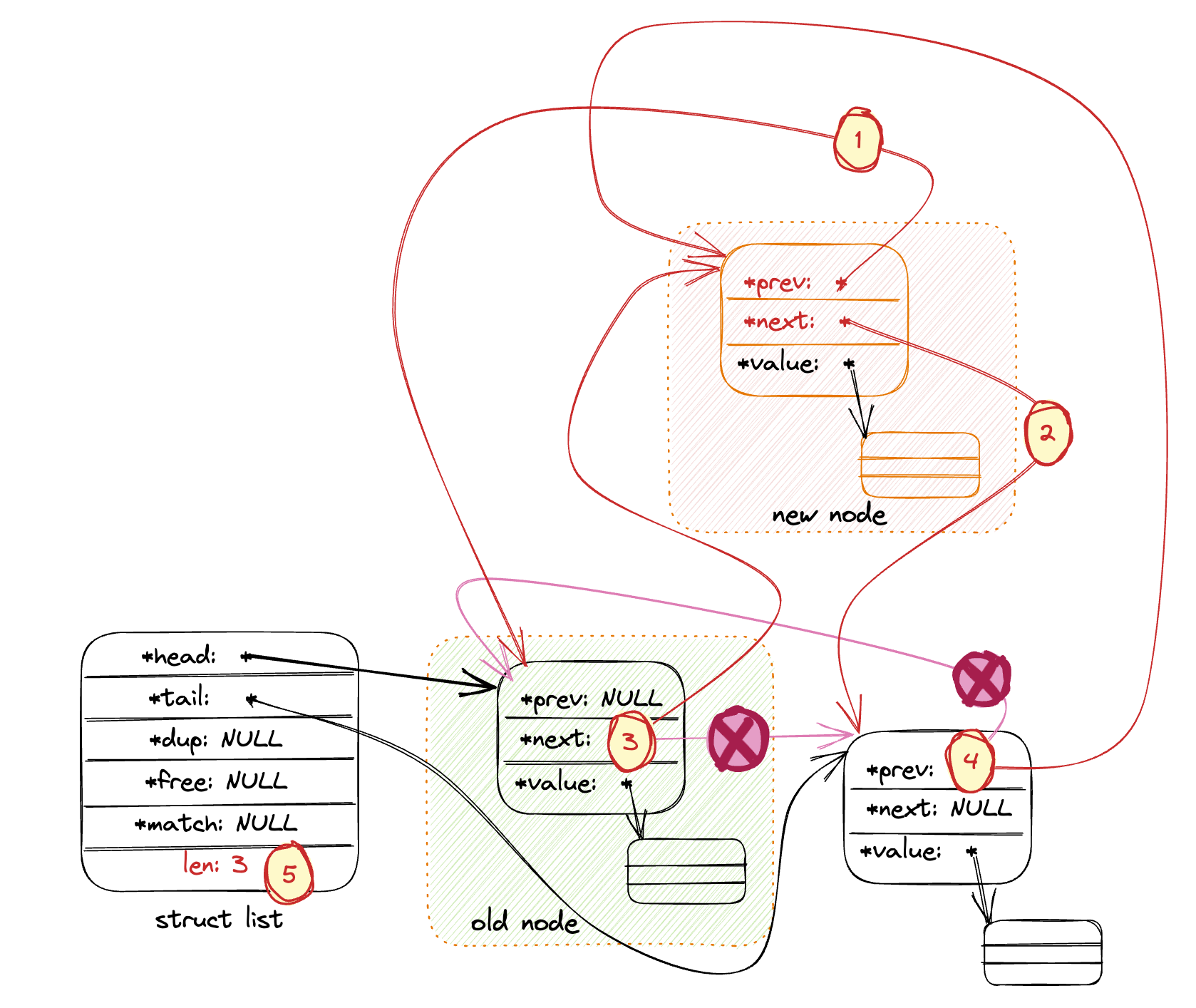
list *listInsertNode(list *list, listNode *old_node, void *value, int after) {
listNode *node;
if ((node = zmalloc(sizeof(*node))) == NULL)
return NULL;
node->value = value;
if (after) {
node->prev = old_node;
node->next = old_node->next;
if (list->tail == old_node) {
list->tail = node;
}
} else {
node->next = old_node;
node->prev = old_node->prev;
if (list->head == old_node) {
list->head = node;
}
}
if (node->prev != NULL) {
node->prev->next = node;
}
if (node->next != NULL) {
node->next->prev = node;
}
list->len++;
return list;
}
- 删除链表指定节点:
listDelNode。 下图以删除中间节点为例,展示了删除的流程。
(1) 待删除节点的前驱节点的next指向待删除节点的后继节点;
(2) 待删除节点的后继节点的prev指向待删除节点的前驱节点;
(3) 待删除节点的next和prev都置为NULL;
(4) 链表总计数减一
(5) 如果有注册free函数,则用free函数释放待删除节点的value。然后释放待删除节点。
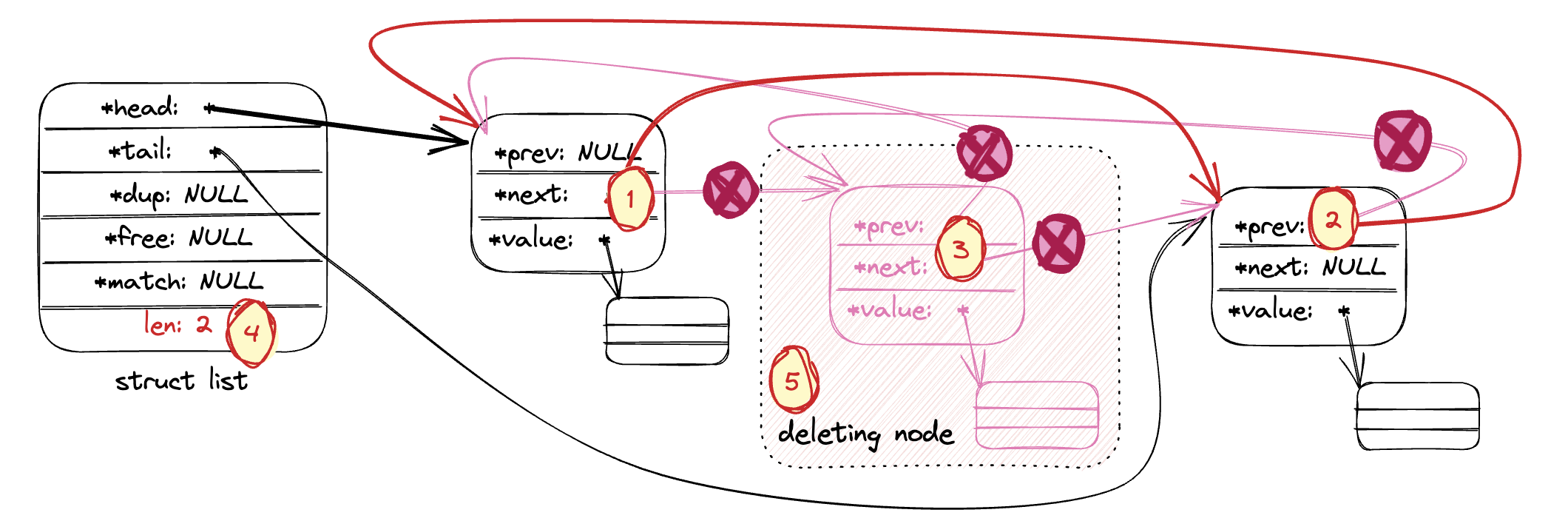
/* Remove the specified node from the specified list.
* The node is freed. If free callback is provided the value is freed as well.
*
* This function can't fail. */
void listDelNode(list *list, listNode *node)
{
listUnlinkNode(list, node);
if (list->free) list->free(node->value);
zfree(node);
}
/*
* Remove the specified node from the list without freeing it.
*/
void listUnlinkNode(list *list, listNode *node) {
if (node->prev)
node->prev->next = node->next;
else
list->head = node->next;
if (node->next)
node->next->prev = node->prev;
else
list->tail = node->prev;
node->next = NULL;
node->prev = NULL;
list->len--;
}
5.链表的 Join 操作: listJoin 在链表l的末尾添加列表o的所有元素。 下图以两个链表都不为 NULL 的场景为例。
(1) o 的首部节点的 prev 指向 l 的尾部节点;
(2) l 的尾部节点的 next 指向 o 的首部节点(1,2 步将两个链表链接起来);
(3) l 的 tail 指向 o 的 tail(o 的 tail作为新链表的尾部);
(4) l 链表总计数加一;
(5) (6) 清空 o 链表的信息;
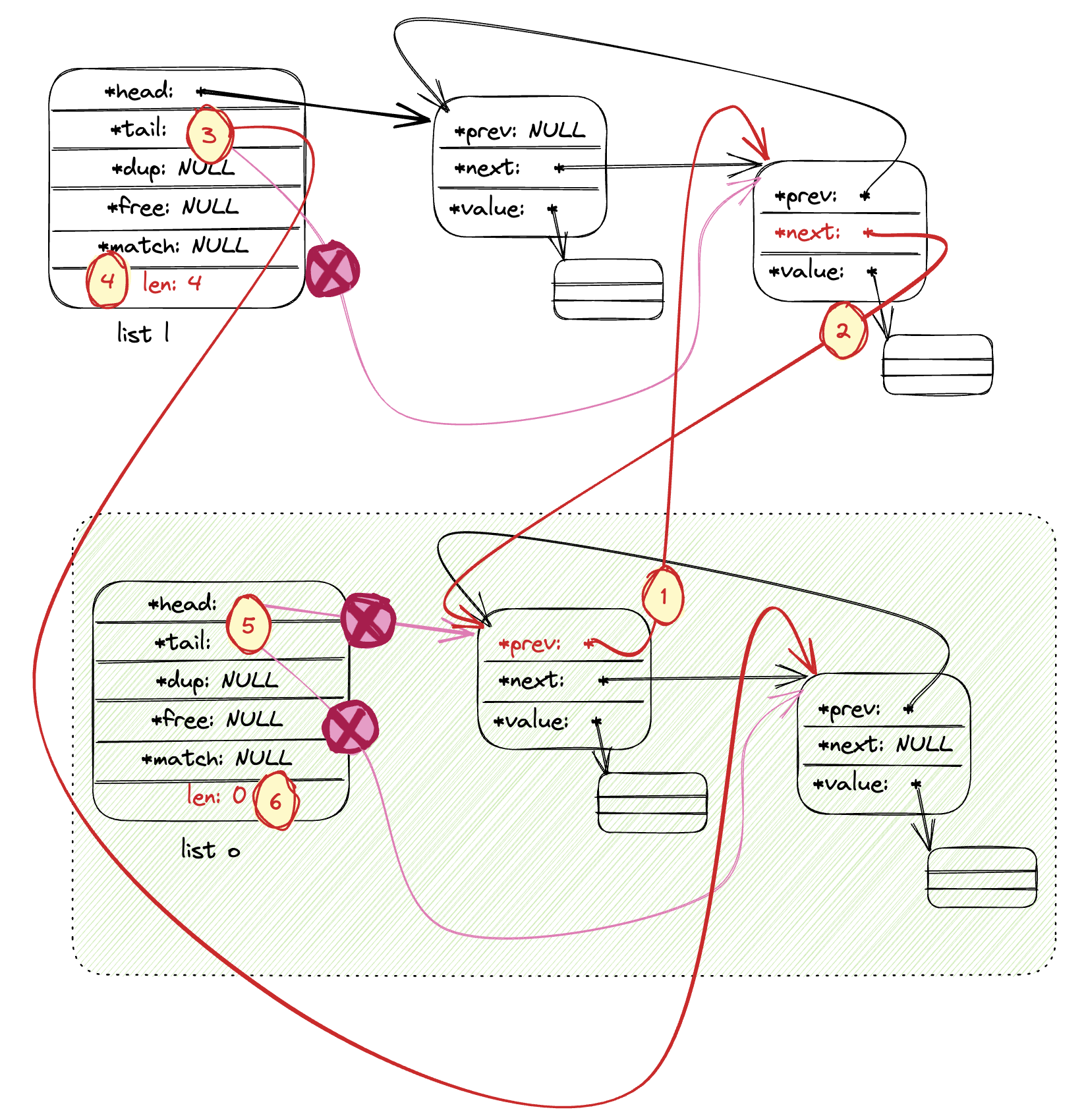
/* Add all the elements of the list 'o' at the end of the
* list 'l'. The list 'other' remains empty but otherwise valid. */
void listJoin(list *l, list *o) {
if (o->len == 0) return;
o->head->prev = l->tail;
if (l->tail)
l->tail->next = o->head;
else
l->head = o->head;
l->tail = o->tail;
l->len += o->len;
/* Setup other as an empty list. */
o->head = o->tail = NULL;
o->len = 0;
}
- 其他函数: 其他函数实现较为简单,这里简单罗列一下,感兴趣的可以去看下源码。
// 获取 list 的迭代器
listIter *listGetIterator(list *list, int direction);
// 返回迭代器的下一个元素,并将迭代器移动一位。如果已遍历完成, 则返回 NULL
listNode *listNext(listIter *iter);
// 释放迭代器资源
void listReleaseIterator(listIter *iter);
// 拷贝链表
list *listDup(list *orig);
// 在链表中查找与 key 匹配的 value 所在的第一个节点。
// 如果不存在,则返回 NULL。
// 匹配操作由 list->match 函数提供。
// 如果没有注册 match 函数, 则直接比较 key 是否与 value 相等。
listNode *listSearchKey(list *list, void *key);
// 返回指定的索引的元素。 如果超过了链表范围, 则返回 NULL。
// 正整数表示从首部开始计算。
// 0 表示第一个元素, 1 表示第二个元素, 以此类推。
// 负整数表示从尾部开始计算。
// -1 表示倒数第一个元素, -2 表示倒数第二个元素,以此类推。
listNode *listIndex(list *list, long index);
// 返回链表初始化的正向迭代器
void listRewind(list *list, listIter *li);
// 返回链表初始化的反向迭代器
void listRewindTail(list *list, listIter *li);
// 将链表尾部节点移到首部
void listRotateTailToHead(list *list);
// 将链表首部节点移到尾部
void listRotateHeadToTail(list *list);
// 用 value 初始化节点
void listInitNode(listNode *node, void *value);
adlist 的使用 demo
git@github.com:younglionwell/redis-adlist-example.git
关注公众号了解更多 redis 源码细节和其他技术内容。 你的关注是我最大的动力。

Redis 源码解析之通用双向链表(adlist)的更多相关文章
- .Net Core缓存组件(Redis)源码解析
上一篇文章已经介绍了MemoryCache,MemoryCache存储的数据类型是Object,也说了Redis支持五中数据类型的存储,但是微软的Redis缓存组件只实现了Hash类型的存储.在分析源 ...
- Redis源码解析:15Resis主从复制之从节点流程
Redis的主从复制功能,可以实现Redis实例的高可用,避免单个Redis 服务器的单点故障,并且可以实现负载均衡. 一:主从复制过程 Redis的复制功能分为同步(sync)和命令传播(comma ...
- Redis源码解析之跳跃表(三)
我们再来学习如何从跳跃表中查询数据,跳跃表本质上是一个链表,但它允许我们像数组一样定位某个索引区间内的节点,并且与数组不同的是,跳跃表允许我们将头节点L0层的前驱节点(即跳跃表分值最小的节点)zsl- ...
- Redis源码解析:13Redis中的事件驱动机制
Redis中,处理网络IO时,采用的是事件驱动机制.但它没有使用libevent或者libev这样的库,而是自己实现了一个非常简单明了的事件驱动库ae_event,主要代码仅仅400行左右. 没有选择 ...
- Redis源码解析:02链表
链表提供了高效的节点重排能力,以及顺序性的节点访问方式,因为Redis使用的C语言并没有内置这种数据结构,所以Redis自己实现了链表. 链表在Redis中的应用非常广泛,比如列表的底层实现之一就是链 ...
- Redis源码解析之ziplist
Ziplist是用字符串来实现的双向链表,对于容量较小的键值对,为其创建一个结构复杂的哈希表太浪费内存,所以redis 创建了ziplist来存放这些键值对,这可以减少存放节点指针的空间,因此它被用来 ...
- Redis源码解析
一.src/server.c 中的redisCommandTable列出的所有redis支持的命令,其中字符串命令包括从get到mget:列表命令从rpush到rpoplpush:集合命令包括从sad ...
- Redis源码解析:26集群(二)键的分配与迁移
Redis集群通过分片的方式来保存数据库中的键值对:一个集群中,每个键都通过哈希函数映射到一个槽位,整个集群共分16384个槽位,集群中每个主节点负责其中的一部分槽位. 当数据库中的16384个槽位都 ...
- Redis源码解析:25集群(一)握手、心跳消息以及下线检测
Redis集群是Redis提供的分布式数据库方案,通过分片来进行数据共享,并提供复制和故障转移功能. 一:初始化 1:数据结构 在源码中,通过server.cluster记录整个集群当前的状态,比如集 ...
- jedis的publish/subscribe[转]含有redis源码解析
首先使用redis客户端来进行publish与subscribe的功能是否能够正常运行. 打开redis服务器 [root@localhost ~]# redis-server /opt/redis- ...
随机推荐
- Day02 差点水掉 欸呀呀
Java狂神6.17星期四 知识行 冯诺依曼+图灵 软件+硬件 .......... 快捷键 ctrl+a 全选 ctrl+x 剪切 alt+F4 关闭窗口 win+r 运行 +cmd命令行 win+ ...
- ant build 报 warning modified in the future
错误原因:在测试项目时,修改了系统时间,之后保存了文件,再将系统时间改回来,会报这个错误 解决方法:复制改过的文件到记事本,然后回退下文件,再将记事本的内容覆盖下文件,重新build下就可以了.
- Jquery ajax参数设置(转)
参数名 类型 描述 url String (默认: 当前页地址) 发送请求的地址. type String (默认: "GET") 请求方式 ("POST" 或 ...
- 搭建Angular基础项目学习
https://stackblitz.com/借助StackBlitz网站可快速开始搭建一个angular项目 一个angular的component包含三项东西 A component class ...
- ARMV8 short notes
offset addressing pre-index addressing define like: load the compass content of the operand 2 to ope ...
- 重写org.springframework.beans.BeanUtils的copyProperties方法,能在实体映射的时候把纯数字格式的日期转格式
就是在拷贝的时候加个正则的校验,如果是纯数字的日期 就转成yyyy-MM-dd HH:mm:ss的格式原本想直接用注解在实体转格式,但是那样实体会变成日期格式,所以放弃了,直接重写拷贝的方法比较简单 ...
- EF 操作实例
一.Linq语法 List操作 1.1 有参 public List<GoodsInfo> ShowInfo(string GName,int?Gid) { //true ...
- win服务项因各种原因出问题,删除注册表服务项
win7系统,可以cmd–>sc delete 服务名称win10计算机\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services 删除相关服务即 ...
- Matlab:4维、单目标、约束、粒子群优化算法
% 主调用函数(求最大值) clc; clear; close all; % 初始化种群 N = 100; % 初始种群个数 D = 4; % 空间维数 iter = 50; % 迭代次数 x_lim ...
- 【Python】pcap抓MySQL网络包
pcap # -*- coding:utf-8 -*- # yum install libpcap-devel python-devel # pip install pypcap hexdump -i ...