深度优先搜索算法-dfs讲解
迷宫问题
有一个迷宫:
S**.
....
***T
(其中字符S表示起点,字符T表示终点,字符*表示墙壁,字符.表示平地。你需要从S出发走到T,每次只能向上下左右相邻的位置移动,不能走出地图,也不能穿过墙壁,每个点只能通过一次。)
现在需要你求出是否可以走出这个迷宫
我们将这个走迷宫过程称为dfs(深度优先搜索)算法。
思路
当我们搜索到了某一个点,有这样3种情况:
1.当前我们所在的格子就是终点。
2.如果不是终点,我们枚举向上、向下、向左、向右四个方向,依次去判断它旁边的四个点是否可以作为下一步合法的目标点,如果可以,那么我们就进行这一步,走到目标点,然后继续进行操作。
3.当然也有可能我们走到了“死胡同”里(上方、下方、左方、右方四个点都不是合法的目标点),那么我们就回退一步,然后从上一步所在的那个格子向其他未尝试的方向继续枚举。
怎样才能算“合法的目标点”?
1.必须在所给定的迷宫范围内
2.不能是迷宫边界或墙。
3.这个点在搜索过程中没有被走过(这样做是因为,如果一个点被允许多次访问,那么肯定会出现死循环的情况——在两个点之间来回走。)
实现代码
#include <iostream>
using namespace std;
int n, m;
string maze[105];
int sx, sy;
bool vis[105][105];
int dir[4][2] = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};//四个方向的方向数组
bool in(int x, int y) {
return 0 <= x && x < n && 0 <= y && y < m;
}
bool dfs(int x, int y) {
vis[x][y] = 1;//点已走过标记
if (maze[x][y] == 'T') {//到达终点
return 1;
}
for (int i = 0; i < 4; ++i) {
int tx = x + dir[i][0];
int ty = y + dir[i][1];
if (in(tx, ty) && !vis[tx][ty] && maze[tx][ty] != '*') {
/*
1.in(tx, ty) : 即将要访问的点在迷宫内
2.!vis[tx][ty] : 点没有走过
3.maze[tx][ty] != '*' : 不是墙
*/
if (dfs(tx, ty)) {
return 1;
}
}
}
return 0;
}
int main() {
cin >> n >> m;
for (int i = 0; i < n; ++i) {
cin >> maze[i];
}
for (int i = 0; i < n; ++i) {
for (int j = 0; j < m; ++j) {
if (maze[i][j] == 'S') {
//记录起点的坐标
sx = i;
sy = j;
}
}
}
if (dfs(sx, sy)) {
puts("Yes");
} else {
puts("No");
}
return 0;
}
深搜的剪枝优化
可行性剪枝
剪枝,顾名思义,就是通过一些判断,砍掉搜索树上不必要的子树。有时候,在搜索过程中我们会发现某个结点对应的子树的状态都不是我们要的结果,那么我们其实没必要对这个分支进行搜索,直接“砍掉”这棵子树(直接 return退出),就是"剪枝"。
我们举一个例子:
给定n个整数,要求选出K个数,使得选出来的K个数的和为sum。
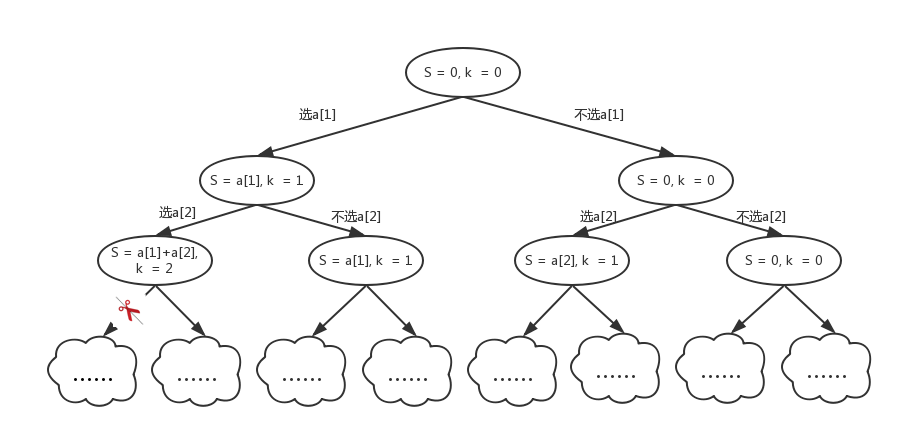
如上图,当k=2的时候,如果已经选了2个数,再往后选更多的数是没有意义的。所以我们可以直接减去这个搜索分支,对应上图中的剪刀减去的那棵子树。
又比如,如果所有的数都是正数,如果一旦发现当前和的值都已经大于sum了,那么之后不管怎么选,选择数的和都不可能是sum了,就可以直接终止这个分支的搜索。
例:从1,2,3,⋯,30这30个数中选8个数,使得和为200。
我们可以加如下剪枝
if (数字个数 > 8) return ;
if (总和 > 200) return ;
经过尝逝后发现:
没有剪枝

加剪枝:

最优性剪枝
我们再看一个问题:
有一个n×m大小的迷宫。其中字符
S表示起点,字符T表示终点,字符*表示墙壁,字符.表示平地。你需要从S出发走到T,每次只能向上下左右相邻的位置移动,并且不能走出地图,也不能走进墙壁。保证迷宫至少存在一种可行的路径,输出S走到T的最少步数。

对于求最优解(从起点到终点的最小步数)这种问题,通常可以用最优性剪枝,比如在求解迷宫最短路的时候,如果发现当前的步数已经超过了当前最优解,那从当前状态开始的搜索都是多余的,因为这样搜索下去永远都搜不到更优的解。通过这样的剪枝,可以省去大量冗余的计算。
此外,在搜索是否有可行解的过程中,一旦找到了一组可行解,后面所有的搜索都不必再进行了,这算是最优性剪枝的一个特例。
现在我们考虑用dfs来解决这个问题,第一个搜到的答案res并不一定是正解,但是正解一定小于等于res。于是如果当前步数大于等于res就直接剪枝。
在dfs函数内加入如下代码
if (目前步数 >= res) return ;
if (目前所处的位置字符 == 'T') {
答案 = 目前步数;//因为我们在刚才已经进行了一次剪枝,所以我们现在是可以保证目前答案大于之前答案的
return ;
}
好啦,到这里就结束了捏~
求赞qwq
深度优先搜索算法-dfs讲解的更多相关文章
- 图的深度优先搜索算法DFS
1.问题描写叙述与理解 深度优先搜索(Depth First Search.DFS)所遵循的策略.如同其名称所云.是在图中尽可能"更深"地进行搜索. 在深度优先搜索中,对最新发现的 ...
- 深度优先搜索算法(DFS)以及leetCode的subsets II
深度优先搜索算法(depth first search),是一个典型的图论算法.所遵循的搜索策略是尽可能“深”地去搜索一个图. 算法思想是: 对于新发现的顶点v,如果它有以点v为起点的未探测的边,则沿 ...
- 深度优先搜索算法(Depth-First-Search,DFS)
深度优先搜索算法的概念 与广度优先搜索算法不同,深度优先搜索算法类似与树的先序遍历.这种搜索算法所遵循的搜索策略是尽可能"深"地搜索一个图.它的基本思想如下:首先访问图中某一个起始 ...
- [数据结构]深度优先搜索算法(Depth-First-Search,DFS)
深度优先搜索算法的概念 与广度优先搜索算法不同,深度优先搜索算法类似与树的先序遍历.这种搜索算法所遵循的搜索策略是尽可能"深"地搜索一个图.它的基本思想如下:首先访问图中某一个起始 ...
- 广度优先遍历-BFS、深度优先遍历-DFS
广度优先遍历-BFS 广度优先遍历类似与二叉树的层序遍历算法,它的基本思想是:首先访问起始顶点v,接着由v出发,依次访问v的各个未访问的顶点w1 w2 w3....wn,然后再依次访问w1 w2 w3 ...
- Python数据结构与算法之图的广度优先与深度优先搜索算法示例
本文实例讲述了Python数据结构与算法之图的广度优先与深度优先搜索算法.分享给大家供大家参考,具体如下: 根据维基百科的伪代码实现: 广度优先BFS: 使用队列,集合 标记初始结点已被发现,放入队列 ...
- 深度优先搜索 DFS 学习笔记
深度优先搜索 学习笔记 引入 深度优先搜索 DFS 是图论中最基础,最重要的算法之一.DFS 是一种盲目搜寻法,也就是在每个点 \(u\) 上,任选一条边 DFS,直到回溯到 \(u\) 时才选择别的 ...
- 深度优先搜索DFS和广度优先搜索BFS简单解析(新手向)
深度优先搜索DFS和广度优先搜索BFS简单解析 与树的遍历类似,图的遍历要求从某一点出发,每个点仅被访问一次,这个过程就是图的遍历.图的遍历常用的有深度优先搜索和广度优先搜索,这两者对于有向图和无向图 ...
- 利用广度优先搜索(BFS)与深度优先搜索(DFS)实现岛屿个数的问题(java)
需要说明一点,要成功运行本贴代码,需要重新复制我第一篇随笔<简单的循环队列>代码(版本有更新). 进入今天的主题. 今天这篇文章主要探讨广度优先搜索(BFS)结合队列和深度优先搜索(DFS ...
- 图的深度优先遍历(DFS)和广度优先遍历(BFS)
body, table{font-family: 微软雅黑; font-size: 13.5pt} table{border-collapse: collapse; border: solid gra ...
随机推荐
- 真正“搞”懂HTTP协议04之搞起来
前两篇文章,我们从空间和时间的角度都对HTTP有了一定的学习和理解,那么基于上一篇的HTTP发展的时间顺序,我会在后面的文章由浅入深,按照HTTP版本内容的更迭,一边介绍相关字段的使用方法,一边讲解其 ...
- .NET二叉树,递归和迭代遍历二叉树
代码随想录: https://programmercarl.com .NET中二叉树的定义 public class TreeNode { public int val; public TreeNod ...
- [排序算法] 直接/折半插入排序 (C++)
插入排序解释 插入排序很好理解,其步骤是 :先将第一个数据元素看作是一个有序序列,后面的 n-1 个数据元素看作是未排序序列.对后面未排序序列中的第一个数据元素在这个有序序列中进行从后往前扫描,找到合 ...
- C++ using 编译指令与名称冲突
using 编译指令:它由名称空间名和它前面的关键字 using namespace 组成,它使名称空间中的所有名称都可用,而不需要使用作用域解析运算符.在全局声明区域中使用 using 编译指令,将 ...
- 修改Listen 1源码的一点心得
注:本文只作为技术交流 首先感谢听1的作者写出这么强大的音乐播放器!! 软件首页地址:点击打开链接 软件的github上上上地址:点击打开链接 软件唯一让我美中不足的就是不能下载,这可能是作者考虑到了 ...
- MySQL进阶实战3,mysql索引详解,上篇
一.索引 索引是存储引擎用于快速查找记录的一种数据结构.我觉得数据库中最重要的知识点,就是索引. 存储引擎以不同的方式使用B-Tree索引,性能也各有不同,各有优劣.例如MyISAM使用前缀压缩技术使 ...
- java面试题-常用框架
Spring Spring 是什么 一个开发框架,一个容器,主要由面向切面AOP 和依赖注入DI两个方面,外加一些工具 AOP和IOC AOP 面向切面 AOP是一种编程思想,主要是逻辑分离, 使业务 ...
- 跟我学Python图像处理丨带你入门OpenGL
摘要:介绍Python和OpenGL的入门知识,包括安装.语法.基本图形绘制等. 本文分享自华为云社区<[Python图像处理] 二十七.OpenGL入门及绘制基本图形(一)>,作者:ea ...
- 利用python数据分析
利用python进行数据分析 本书由Python pandas项目创始人Wes McKinney亲笔撰写,详细介绍利用Python进行操作.处理.清洗和规整数据等方面的具体细节和基本要点.第2版针对P ...
- Graph Neural Network——图神经网络
本文是跟着李沐老师的论文精度系列进行GNN的学习的,详细链接请见:零基础多图详解图神经网络(GNN/GCN)[论文精读] 该论文的标题为<A Gentle Introduction to Gra ...