spark数据清洗
spark数据清洗
1.Scala常用语法
运用maven创建项目,需要导入如下依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
main方法:
def main(args:Array[String]):Unit={ }
变量
var i:Int=1 //在类中自带get和set功能
val a:Int=2 //常量,在类中只有get功能
var arr:Array[String]=Array("abc","bcd","cde")
类型转换
var num:Int=20
var str:String=num.toString
var num2:Int=str.toInt
条件判断
var score:Int=88
if(score==100){
println("优秀")
}else if (score>=90){
println("良好")
}else{
println("继续加油")
}
循环:
//遍历arr
var arr=Array("java","python","scala")
//方式1
for(a<-arr){
println(a)
}
//方式2
arr.foreach(println) //循环1到1(包括1和10)
for(a<-1 to 10){
println(a)
}
元组
//声明赋值:
var t=(4.13,"hello",44)
//取值:
println(t._1) //4.13
println(t._2) //hello
函数:
def test(x:Int,y:Int):Int={
x+y //返回值时不需要加return
}
RDD的创建
//使用集合、数组创建RDD
val arr = Array(1,2,3,4,5)
val rdd = sc.parallelize(arr) 或者 val rdd = sc.makeRDD(arr)
rdd.collect() 转为数组
//通过外部存储创建RDD
//Hdfs上:
sc.textFile(“hdfs://master:9000/wordcount.txt”)
//本地测试
sc.textFile(“data/xxx.csv”)
//通过其他RDD得到新的RDD
val rdd = sc.parallielize(Array(1,2,3,4,5))
arl rdd2 = rdd.map(_*2)
2.常用方法
计数器:
//定义累加器:
val longAccum=sc.longAccumulator("count")
//累加器增加:
longAccum.add(1)//每次增加1
//获取累加器数据
print("累加器结果是:"+longAccum.value)
去重:distinct()
文本行数:count()
package com.xyz import org.apache.spark.{SparkConf, SparkContext} /**
* @author 小勇子start
* @create 2021-10-12 14:03
*/
object DistinctDemo {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("test1")
val sc=new SparkContext(sparkConf)
val rdd=sc.textFile("data/distinct.txt")
val count1:Long=rdd.count();
val rdd2=rdd.distinct()
val count2:Long=rdd2.count()
println("清除的数据条数有:"+(count1-count2)) //
rdd2.saveAsTextFile("data/out1")
sc.stop()
}
}
过滤:filter :false删除,true保留
package com.xyz import org.apache.spark.{SparkConf, SparkContext} /**
* @author 小勇子start
* @create 2021-10-12 14:03
*/
object FilterDemo {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("test1")
val sc = new SparkContext(sparkConf)
val longAccum=sc.longAccumulator("count")
val rdd = sc.textFile("data/test.txt")
val rdd2 = rdd.filter(!_.startsWith("id")) //过滤表头
//val rdd2=rdd.filter(!_.endsWith("e")) //过滤以“e”结尾的数据
val rdd3 = rdd2.filter(x => {//过滤分数小于50的科目
val str = x.split(",")
val score = str(2).toInt
if (score > 50)
true
else{
longAccum.add(1)
false
} })
rdd3.saveAsTextFile("data/out3")
print("分数小于50的数据条数是:"+longAccum.value)
sc.stop()
}
}
map() :适合用来格式化输出格式
package com.xyz import org.apache.spark.{SparkConf, SparkContext} /**
* @author 小勇子start
* @create 2021-10-12 14:03
*/
object MapDemo {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("test1")
val sc = new SparkContext(sparkConf)
val rdd = sc.textFile("data/test.txt")
val rdd2 = rdd.filter(!_.startsWith("id")) //过滤表头
val rdd3=rdd2.map(x=>{
val str=x.split(",")
val name=str(3)
val score=str(2)
val kc=str(1)
val newStr=name+","+score+","+kc
newStr
})
rdd3.saveAsTextFile("data/out4")
sc.stop()
}
}
排序:sortBy() ,填两个值,前一个填根据排序的字段,后一个填升降序,默认升序
package com.xyz import org.apache.spark.{SparkConf, SparkContext} /**
* @author 小勇子start
* @create 2021-10-12 14:03
*/
object sortByDemo {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("test1")
val sc = new SparkContext(sparkConf)
val rdd = sc.textFile("data/test.txt")
val rdd2 = rdd.filter(!_.startsWith("id"))
val rdd3=rdd2.map(x=>{
val str=x.split(",")
val name=str(3)
val score=str(2)
val kc=str(1)
val newStr=name+","+score+","+kc
newStr
}).sortBy(x=>x.split(",")(1),ascending = false)//降序,默认为true
rdd3.saveAsTextFile("data/out5")
sc.stop()
}
}
3.单词计数案例
package com.xyz
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 小勇子start
* @create 2021-10-12 21:22
*/
object WordCount {
def main(args: Array[String]): Unit = {
val sparkConf=new SparkConf().setMaster("local").setAppName("test")
val sc=new SparkContext(sparkConf)
val rdd=sc.textFile("data/test2.txt")
val rdd2=rdd.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_)
//flatMap能把数据一次性读取出来,并按"," 分成若干个数据
//reduceByKey(_+_)表示每一个相同的key的value相加 _:代表key,1 :是value
//格式必须是:(k,v)才能使用该方法
rdd2.saveAsTextFile("data/out1")
}
}
4.求科目平均值案例
package com.xyz
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 小勇子start
* @create 2021-10-13 17:16
*/
object GroupByKeyDemo {
def main(args: Array[String]): Unit = {
val sparkConf=new SparkConf().setMaster("local").setAppName("test2")
val sc= new SparkContext(sparkConf)
val rdd=sc.textFile("data/test.txt")
val rdd2=rdd.map(x=>{
val str=x.split(",")
val km=str(1)
val score=str(2).toFloat
(km,score)
}).groupByKey().map(x=>{
val km=x._1
var allScore:Float=0;
for(i<-x._2){
allScore+=i
}
km+"的平均分为:"+allScore/x._2.size
})
rdd2.saveAsTextFile("data/out2")
}
}
//groupByKey 根据(k,v)中的k分组,将所有k相同的v都放入同一个iterate中保存起来,返回一个(k,iterate(v1,v2,v3))
5.join案例
package com.xyz
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 小勇子start
* @create 2021-10-13 18:41
*/
object JoinDemo{
def main(args: Array[String]): Unit = {
val sparkConf=new SparkConf().setMaster("local").setAppName("test4")
val sc= new SparkContext(sparkConf)
val rdd1=sc.textFile("data/test.txt")
val rdd2=sc.textFile("data/test_2.txt")
val rdd1_2=rdd1.map(x=>{
val str=x.split(",")
val id=str(5).toInt
(id,x)
})
val rdd2_2=rdd2.map(x=>{
val str=x.split(",")
val id=str(0).toInt
(id,x)
})
rdd2_2.join(rdd1_2).map(x=>{
val str=x._2._2.replace(","+x._1,"")
x._2._1+","+str
}).saveAsTextFile("data/out4")
}
}
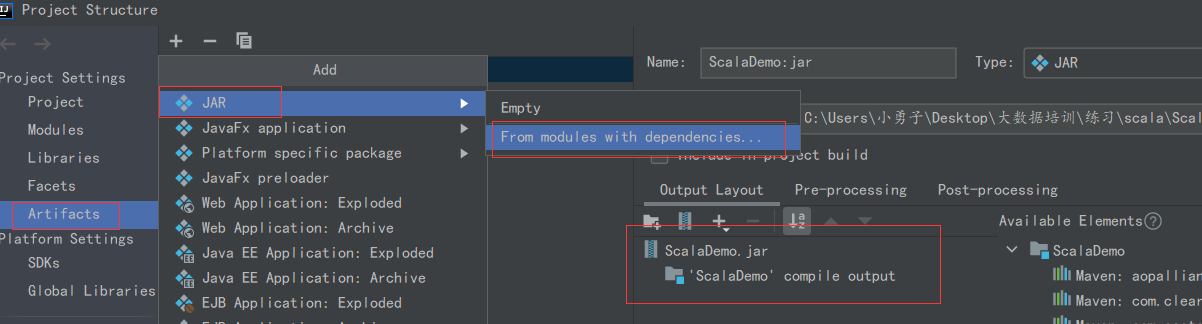
6.spark项目打jar包
7.运行jar包
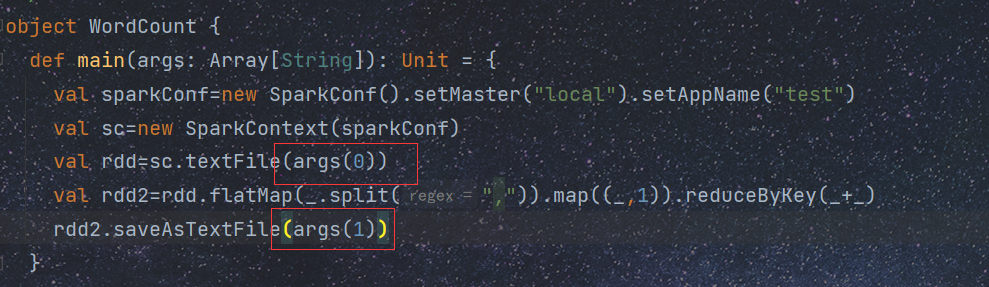
以单词计数为例
[root@master bin]# pwd
/usr/local/src/spark/bin
[root@master bin]#spark-submit --master spark:master:7707 --class com.xyz.WordCount /opt/test/ScalaDemo.jar hdfs://master:9000/test/test2.txt hdfs://master:9000/test/out1
--master 后面可以填 local 、spark等等
--class 后面填要运行的主类
/opt/test/ScalaDemo.jar 表示jar包位置
hdfs://master:9000/test/test2.txt 文件输入位置 不能写成 http://master:50070
hdfs://master:9000/test/out1 文件存储位置
输入输出位置与下面对应
spark数据清洗的更多相关文章
- ETL实践--Spark做数据清洗
ETL实践--Spark做数据清洗 上篇博客,说的是用hive代替kettle的表关联.是为了提高效率. 本文要说的spark就不光是为了效率的问题. 1.用spark的原因 (如果是一个sql能搞定 ...
- 2-Spark高级数据分析-第二章 用Scala和Spark进行数据分析
数据清洗时数据科学项目的第一步,往往也是最重要的一步. 本章主要做数据统计(总数.最大值.最小值.平均值.标准偏差)和判断记录匹配程度. Spark编程模型 编写Spark程序通常包括一系列相关步骤: ...
- [spark案例学习] WEB日志分析
数据准备 数据下载:美国宇航局肯尼迪航天中心WEB日志 我们先来看看数据:首先将日志加载到RDD,并显示出前20行(默认). import sys import os log_file_path =' ...
- Spark Streaming揭秘 Day29 深入理解Spark2.x中的Structured Streaming
Spark Streaming揭秘 Day29 深入理解Spark2.x中的Structured Streaming 在Spark2.x中,Spark Streaming获得了比较全面的升级,称为St ...
- zhihu spark集群,书籍,论文
spark集群中的节点可以只处理自身独立数据库里的数据,然后汇总吗? 修改 我将spark搭建在两台机器上,其中一台既是master又是slave,另一台是slave,两台机器上均装有独立的mongo ...
- 使用 Spark MLlib 做 K-means 聚类分析[转]
原文地址:https://www.ibm.com/developerworks/cn/opensource/os-cn-spark-practice4/ 引言 提起机器学习 (Machine Lear ...
- [Big Data]从Hadoop到Spark的架构实践
摘要:本文则主要介绍TalkingData在大数据平台建设过程中,逐渐引入Spark,并且以Hadoop YARN和Spark为基础来构建移动大数据平台的过程. 当下,Spark已经在国内得到了广泛的 ...
- Spark ML下实现的多分类adaboost+naivebayes算法在文本分类上的应用
1. Naive Bayes算法 朴素贝叶斯算法算是生成模型中一个最经典的分类算法之一了,常用的有Bernoulli和Multinomial两种.在文本分类上经常会用到这两种方法.在词袋模型中,对于一 ...
- [转载] 从Hadoop到Spark的架构实践
转载自http://www.csdn.net/article/2015-06-08/2824889 http://www.zhihu.com/question/26568496 当下,Spark已经在 ...
- 以慕课网日志分析为例-进入大数据Spark SQL的世界
下载地址.请联系群主 第1章 初探大数据 本章将介绍为什么要学习大数据.如何学好大数据.如何快速转型大数据岗位.本项目实战课程的内容安排.本项目实战课程的前置内容介绍.开发环境介绍.同时为大家介绍项目 ...
随机推荐
- 6 STL-vector
重新系统学习c++语言,并将学习过程中的知识在这里抄录.总结.沉淀.同时希望对刷到的朋友有所帮助,一起加油哦! 生命就像一朵花,要拼尽全力绽放!死磕自个儿,身心愉悦! 写在前面,本篇章主要介绍S ...
- 协程- gevent模块
协程 1.什么是协助:在单线程下实现并发效果 2.协程的原理: 通过代码监听IO操作一旦遇到 IO 操作就立刻切换下一个程序 让cpu一直在工作 这样就可以一直占用CPU的效率 提高程序执行效率 切换 ...
- 1分钟理清楚C++类模板和模板类区别
1.定义区别 类模板和模板类主要关注点是后一个单词. 类模板:主要描述的是模板,这个模板是类的模板.可以理解为一个通用的类,这个类中的数据成员,成员函数的形参类型以及成员函数的返回值类型不用具体的指定 ...
- 从0到1学Python丨图像平滑方法的两种非线性滤波:中值滤波、双边滤波
摘要:常用于消除噪声的图像平滑方法包括三种线性滤波(均值滤波.方框滤波.高斯滤波)和两种非线性滤波(中值滤波.双边滤波),本文将详细讲解两种非线性滤波方法. 本文分享自华为云社区<[Python ...
- week_11
Andrew Ng 机器学习笔记 ---By Orangestar Week_11(the Last Week!!!!) Congratulations on making it to the ele ...
- uniapp中请求接口问题
在main.js文件中配置: //Vue.prototype.$baseUrl="http://192.168.1.164/api" //线下接口 Vue.prototype.$b ...
- gin模板语法
输出数据: 语句:{{.}} 用法: 在html文件中调用 输出里面的结果 多个目录下定义模板: 语句:{{ define "xxx目录/xxx文件.html"}} ...
- 模仿 vscode-server 把本地代码目录映射到外网
目录 概述 分析 解决方案 准备一台VM 创建容器 SmartIDE 创建 直接使用 docker 创建 SSH 远程转发 内网穿透 ngrok frp 服务端 客户端 本文模仿 vscode-ser ...
- 百度智能云 API调用PythonSDK
百度智能云 API调用PythonSDK 这是一个用于百度云部分开放AI功能的Python库.主要为ORC功能,可以对各种图像文件进行文字识别,包括车牌.手写文字.通用文字.人脸发现.人脸比对和人流量 ...
- Rust-01 启航
安装 所谓工欲善其事必先利其器,我们学习Rust当然需要安装Rust.我们可以从Rust官网下载rustup工具进行rust的安装.安装完成后,我们在命令行中输入rustc --version便可以查 ...