CPU AMX 详解
CPU AMX 详解
概述
2016 年开始,随着 NV GPU AI 能力的不断加强,隐隐感觉到威胁的 Intel 也不断在面向数据中心的至强系列 CPU 上堆砌计算能力,增加 core count 、提高 frequency 、增强向量协处理器计算能力三管其下。几乎每一代 CPU 都在 AI 计算能力上有所增强或拓展,从这个方面来讲,如果我们说它没认识到势,没有采取行动,也是不公平的。
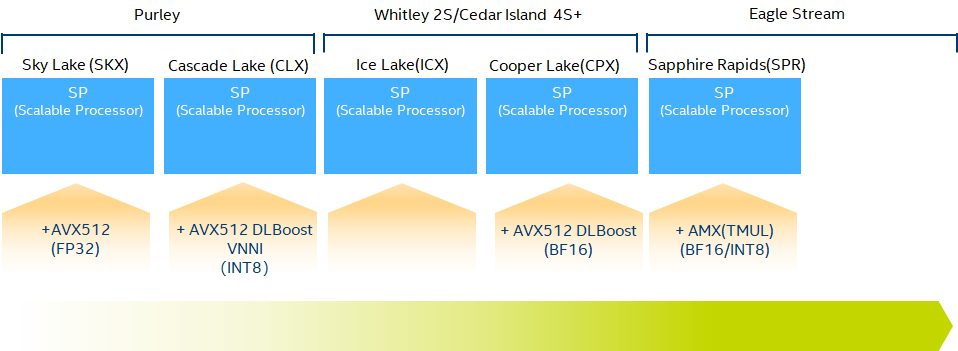
从上图不难看到,2015年的 Sky Lake 首次引入了 AVX-512 (Advanced Vector eXtensions)向量协处理器,与上一代 Broadwell 的 AVX2 相比, 每个向量处理器单元的单精度浮点乘加吞吐翻倍。接着的Cascade Lake 和 Cooper Lake又拓展了 AVX-512 ,增加了对 INT8 和 BF16 精度的支持,奋力想守住 inference 的基本盘。一直到 Sapphire Rapids,被市场和客户用脚投票,前有狼(NVIDIA)后有虎(AMD),都把自己的食盆都快拱翻了,终于意识到在AI的计算能力上不能在按摩尔定律线性发育了,最终也步Google和NVIDIA的后尘,把AVX升一维成了AMX(Advanced Matrix eXtension),即矩阵协处理器了。充分说明一句老话,你永远叫不醒一个装睡的人,要用火烧他。不管怎么样,这下总算是赛道对齐了,终于不是拿长茅对火枪了。
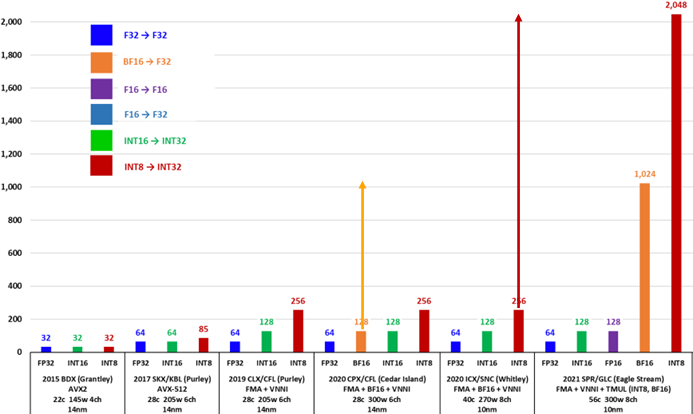
算力如何
AI 工作负载 Top-2 的算子:
Convolution
MatMul/Fully Connected
这俩本质上都是矩阵乘。怎么计算矩阵乘,有两种化归方法:
化归成向量点积的组合,这在CPU中就对应AVX
化过程分块矩阵乘的组合,这在CPU就对应AMX
我们展开讲讲。
问题定义
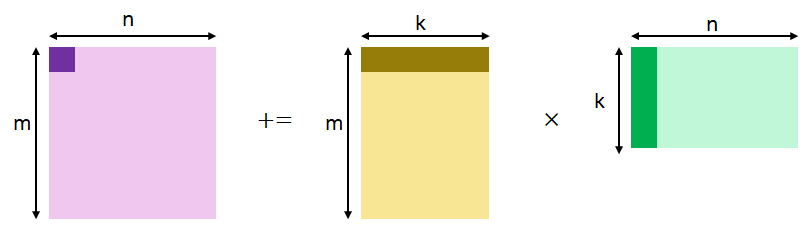
假设有如下矩阵乘问题:
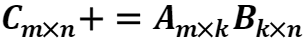
AVX如何解决矩阵乘问题
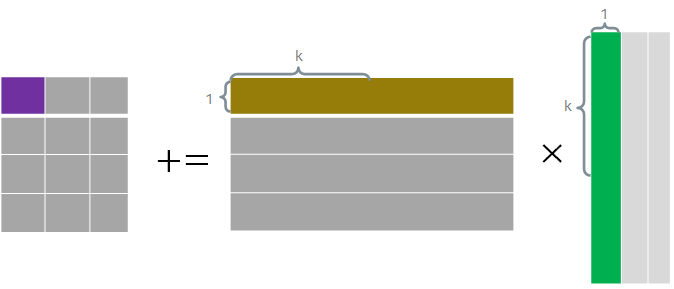
AVX把向量作为一等公民,每次计算一个输出元素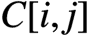 ,而该元素等于
,而该元素等于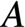 的第
的第 的第
的第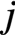 列的点积,即有:
列的点积,即有:

不就化归成向量点积了嘛。那向量的长度是可以任意指定的,但硬件是有固定长度的,怎么办?很简单,就把每个向量切成每个长度为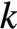 的块,多做几次就好了。这个就是区分AVX各代的主要因素。下面以AVX2为例浅释一下。
的块,多做几次就好了。这个就是区分AVX各代的主要因素。下面以AVX2为例浅释一下。
AVX2 FP32 (k=8)
AVX2使用的寄存器长度为256 bit,也就是8个FP32数,此时。AVX的乘加> 指令操作示意如下:
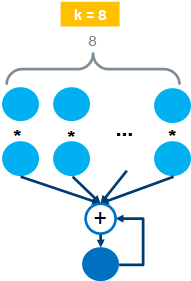
一个时钟周期可以完成两个8维向量的点积操作,也叫FMA(Fused Multiply > Add)操作。因此每个AVX单元的FLOPS为:16 FLOPS/cycle。
以FP32/BF16为例,AVX算力的代际演进如下,可以看出相邻代际增长是平平无奇的2倍。

AMX如何解决矩阵乘问题
以BF16为例,AMX把矩阵乘操作化归为若干个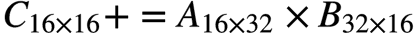 的分块矩阵乘的组合,如下所示。
的分块矩阵乘的组合,如下所示。
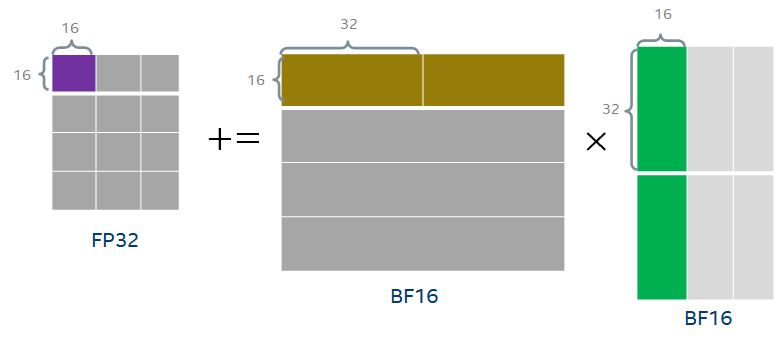
需要注意的是整个操作需要16个cycle完成,因此不难计算每个AMX单元的FLOPS为:1024 OPS/cycle。这下单AMX单元与单AVX单元的每时钟周期的算力提高了16倍,有点像样了。目前Sapphire Rapids每个核有一个AMX单元,而有两个AVX单元,因此每核的每时钟周期算力提高倍数为8倍。
如何计算含有AMX CPU的peak TFLOPS
公式:
假设你有一个56核,每核有1个AMX单元,且AMX频率为1.9 GHz的CPU。其BF16 peak TFLOPS应为:
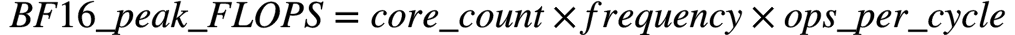
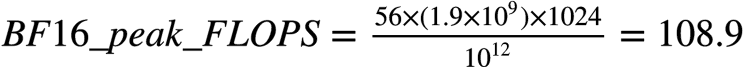
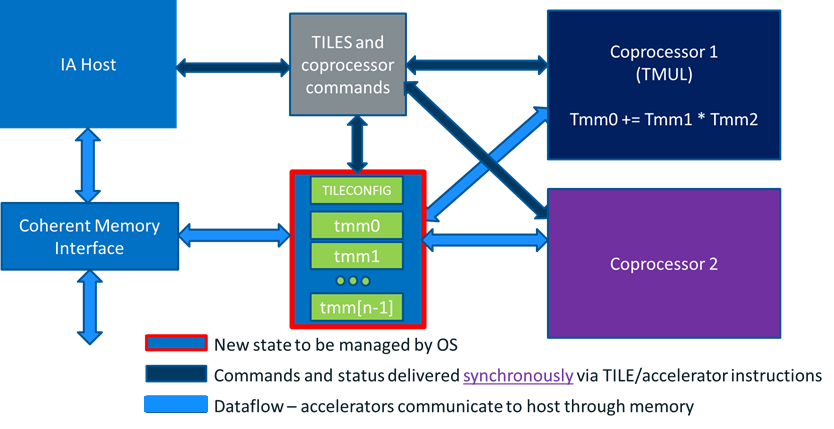
如何实现的
AMX围绕矩阵这一一等公民的支持分为计算和数据两个部分。

计算部分:目前仅有矩阵乘支持,由称为TMUL(Tile Matrix mULtiply Unit)的模块来实现。但也为后面支持其他的矩阵运算留了想像。
数据部分:由一组称为TILES的二维寄存器来承担。
其系统框图如下:
计算部分
TMUL 硬件层面的实现也比较直观,是一个典型的systolic array设计。比较好的是array的每一行都复用了原来的AVX-512 BF16的设计,堆叠了16个AVX-512 BF16单元,在一个cycle内完成了一个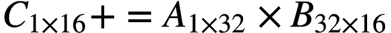 的运算,因此完成整个的计算需要16个cycle。
的运算,因此完成整个的计算需要16个cycle。

Systolic形式的逻辑图,如下。可以看出每个cycle输出 
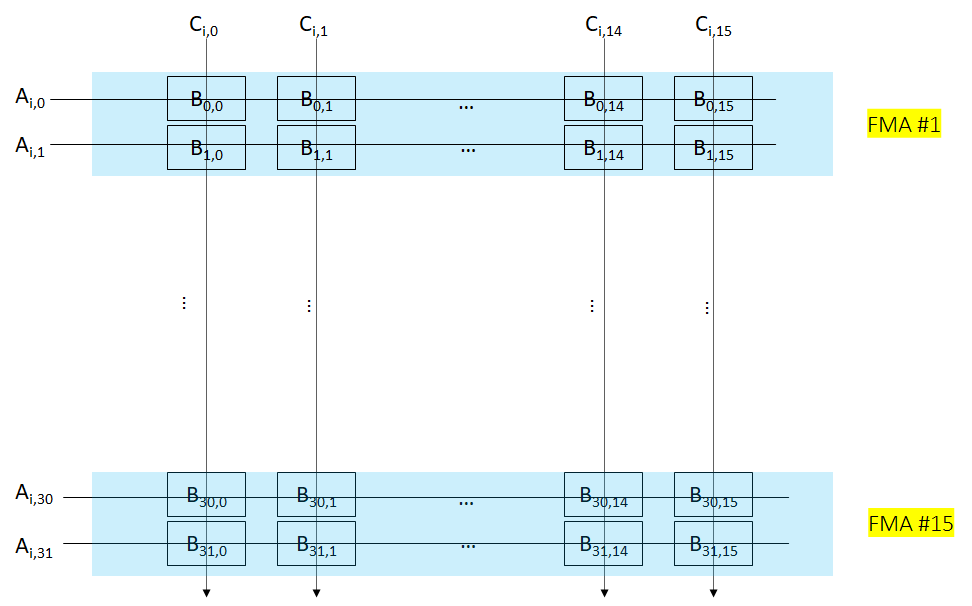
数据部分
每个AMX单元共有8组TILES寄存器,TILE寄存器可以存放一个二维矩阵的子矩阵,有专门的load/store指令。
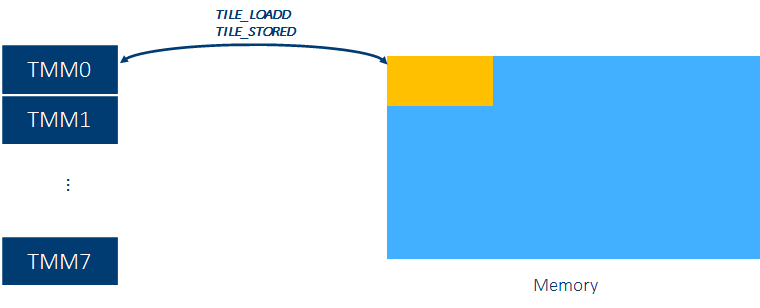
每个TILE寄存器容量为:16行 
 的 FP32 矩阵
的 FP32 矩阵 的 BF16 矩阵
的 BF16 矩阵 的 INT8 矩阵
的 INT8 矩阵
路才开始
迈出脚只是路的开始,而不是结束。后面有的是路(问题):
HW
TILE 和 memory 之间的 load 和 save 带宽与TMUL计算能力的匹配度
AI workload 一般都是矩阵操作(matmul, conv等)与向量操作混杂,而向量操作有分为 element-wise 操作和 reduce 类操作
这3类操作算力的匹配度
矩阵寄存器与向量寄存器之间的 data path 通畅度如何
……
SW
如何提高SW efficiency
如何摆平AI框架要求的plain data layout与AMX硬件要求的data layout之间的re-layout开销
……
让我们边走边看!
CPU AMX 详解的更多相关文章
- CPU上下文切换详解
CPU上下文切换详解 原文地址,译文地址,译者: 董明鑫,校对:郑旭东 上下文切换(有时也称做进程切换或任务切换)是指CPU 从一个进程或线程切换到另一个进程或线程.进程(有时候也称做任务)是指一个程 ...
- linux sysbench (一): CPU性能测试详解
网上sysbench教材众多,但没有一篇中文教材对cpu测试参数和结果进行详解. 本文旨在能够让读者对sysbench的cpu有一定了解. 小慢哥的原创文章,欢迎转载 1.sysbench基础知识 s ...
- Intel CPU编号详解
一.概述 Intel(英特尔)是当前最主流的台式机.笔记本.服务器CPU厂商.和英特尔类似的还有AMD厂商的CPU. Intel生产的CPU型号繁多,每个型号的CPU都有对应的编号.这个编号有特定意义 ...
- CPU卡详解【转】
本文转载自:http://blog.csdn.net/logaa/article/details/7571805 第一部分 CPU基础知识 一.为什么用CPU卡 IC卡从接口方式上分,可以分为接触式I ...
- linux sysbench : CPU性能测试详解
1.sysbench基础知识 sysbench的cpu测试是在指定时间内,循环进行素数计算 素数(也叫质数)就是从1开始的自然数中,无法被整除的数,比如2.3.5.7.11.13.17等.编程公式:对 ...
- Redis INFO CPU 信息详解
一.INFO CPU 通过INFO CPU命令可以查看Redis进程对于CPU的使用情况,如下: 这几个字段的含义如下所示: used_cpu_sys: System CPU consumed by ...
- 物理CPU,物理CPU内核,逻辑CPU概念详解
1.说明 CPU(Central Processing Unit)是中央处理单元, 本文介绍物理CPU,物理CPU内核,逻辑CPU, 以及他们三者之间的关系, 一个物理CPU可以有1个或者多个物理内核 ...
- [CB]Intel 2018架构日详解:新CPU&新GPU齐公布 牙膏时代有望明年结束
Intel 2018架构日详解:新CPU&新GPU齐公布 牙膏时代有望明年结束 北京时间12月12日晚,Intel在圣克拉拉举办了架构日活动.在五个小时的演讲中,Intel揭开了2021年CP ...
- Windows下caffe安装详解(仅CPU)
本文大多转载自 http://blog.csdn.net/guoyk1990/article/details/52909864,加入部分自己实战心得. 1.环境:windows 7\VS2013 2. ...
- Kubernetes K8S之CPU和内存资源限制详解
Kubernetes K8S之CPU和内存资源限制详解 Pod资源限制 备注:CPU单位换算:100m CPU,100 milliCPU 和 0.1 CPU 都相同:精度不能超过 1m.1000m C ...
随机推荐
- springBoot 过滤器去除请求参数前后空格(附源码)
背景 : 用户在前端页面中不小心输入的前后空格,为了防止因为前后空格原因引起业务异常,所以我们需要去除参数的前后空格! 如果我们手动去除参数前后空格,我们可以这样做 @GetMapping(value ...
- python-CSV文件的读写
CSV文件:Comma-Separated Values,中文叫逗号分隔值或者字符分隔值,其文件以纯文本的形式存储表格数据. 可以理解成一个表格,只不过这个 表格是以纯文本的形式显示,单元格与单元格之 ...
- 【每日一题】【递归+int型返回值最后不接收】110. 平衡二叉树-211231/220221
给定一个二叉树,判断它是否是高度平衡的二叉树. 本题中,一棵高度平衡二叉树定义为: 一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 . 答案: public class Solution ...
- PHP-表单传值
一.传值引入 了解传值必须要先知道为什么需要传值? 传值的主要作用是为了实现用户数据的定制化,用户与服务端的互交 二.传值的方式 虽然 http协议中有很多数据传输的方式,但在PHP中只有 POST ...
- Java单例模式的最佳实践?
"读过书,--我便考你一考.茴香豆的茴字,怎样写的?"--鲁迅<孔乙己> 0x00 大纲 目录 0x00 大纲 0x01 前言 0x02 单例的正确性 new关键字 c ...
- Velero 系列文章(一):基础
概述 Velero 是一个开源工具,可以安全地备份和还原,执行灾难恢复以及迁移 Kubernetes 集群资源和持久卷. 灾难恢复 Velero 可以在基础架构丢失,数据损坏和/或服务中断的情况下,减 ...
- 【敏捷研发系列】前端DevOps流水线实践
作者:胡骏 一.背景现状 软件开发从传统的瀑布流方式到敏捷开发,将软件交付过程中开发和测试形成快速的迭代交付,但在软件交付客户之前或者使用过程中,还包括集成.部署.运维等环节需要进一步优化交付效率.因 ...
- DenseNet 论文解读
目录 目录 摘要 网络结构 优点 代码 问题 参考资料 摘要 ResNet 的工作表面,只要建立前面层和后面层之间的"短路连接"(shortcut),就能有助于训练过程中梯度的反向 ...
- 琐碎的想法(五)for 的前世今生
for 起因 记得大学上C语言的课,第一次遇到的问题就是循环结构里面的 for. 选择结构的 if 非常易懂,和日常生活的判断没有区别. 循环结构的 while 同样比较好理解. 本质上是一个判断 如 ...
- [cocos2d-x]registerScriptHandler和registerScriptTapHandler区别
一 .调用registerScriptHandler 的对象不同相应的响应函数和调用方式也不相同 1. 对象为layer时调用方式为: local function onNodeEvent(event ...