推荐系统[一]:超详细知识介绍,一份完整的入门指南,解答推荐系统相关算法流程、衡量指标和应用,以及如何使用jieba分词库进行相似推荐
1. 推荐算法的初步理解
如果说互联网的目标就是连接一切,那么推荐系统的作用就是建立更加有效率的连接,推荐系统可以更有效率的连接用户与内容和服务,节约了大量的时间和成本。
1.1 推荐系统主要解决问题
- 任务一:挖掘长尾:帮助用户找到想要的物品(音乐、商品、新闻),挖掘长尾效应中的非流行市场。
我们在网上冲浪时,常常被大量的物品信息所淹没。从海量信息中找到自己想要的信息,实属不易(如面对淘宝各种各样的打折活动不知所措)。在经济学上,有一个经典的名词叫“长尾效应”,该效应的内容是:从人们需求的角度上看,大多数的需求会集中在某一小部分,而这部分我们可以称之为流行,而分布在剩余部分的需求是个性化的、零散的和小量的需求。这就意味着,有大量资源是鲜有人问津的,这不仅造成了资源利用上的浪费,也会使口味偏小众的用户被流行的内容所淹没。
- 任务二:降低信息过载
进入互联网时代后,信息量已处于爆炸的状态。如果把所有内容都展示出来,用户肯定无法全部接收,这必然会造成信息过载,信息的利用率将十分低下。因此就需要推荐系统来帮我们把低价值的信息给筛选掉。
- 任务三:提高站点的点击率、转化率
好的推荐系统总是能给用户推荐出想要的内容,让用户更频繁地访问站点,增强用户黏度。
- 任务四:加深对用户的了解,为用户提供个性化的定制服务
当系统成功推荐了一个用户感兴趣的内容后,我们对该用户的兴趣爱好就越清晰。当我们精准地描绘出每个用户的形象后(精准的用户画像),就可以为他们定制出一系列个性化的定制服务,让拥有各种各样需求的用户都能在我们平台上得到满足。
如果把推荐系统简单拆开来看,推荐系统主要是由数据、算法、架构三个方面组成。
- 数据提供了信息。数据储存了信息,包括用户与内容的属性,用户的行为偏好例如对新闻的点击、玩过的英雄、购买的物品等等。这些数据特征非常关键,甚至可以说它们决定了一个算法的上限。
- 算法提供了逻辑。数据通过不断的积累,存储了巨量的信息。在巨大的数据量与数据维度下,人已经无法通过人工策略进行分析干预,因此需要基于一套复杂的信息处理逻辑,基于逻辑返回推荐的内容或服务。
- 架构解放了双手。架构保证整个推荐自动化、实时性的运行。架构包含了接收用户请求,收集、处理,存储用户数据,推荐算法计算,返回推荐结果等。有了架构之后算法不再依赖于手动计算,可以进行实时化、自动化的运行。例如在淘宝推荐中,对于数据实时性的处理,就保证了用户在点击一个物品后,后续返回的推荐结果就可以立刻根据该点击而改变。一个推荐系统的实时性要求越高、访问量越大那么这个推荐系统的架构就会越复杂。
1.2推荐系统的整体框架
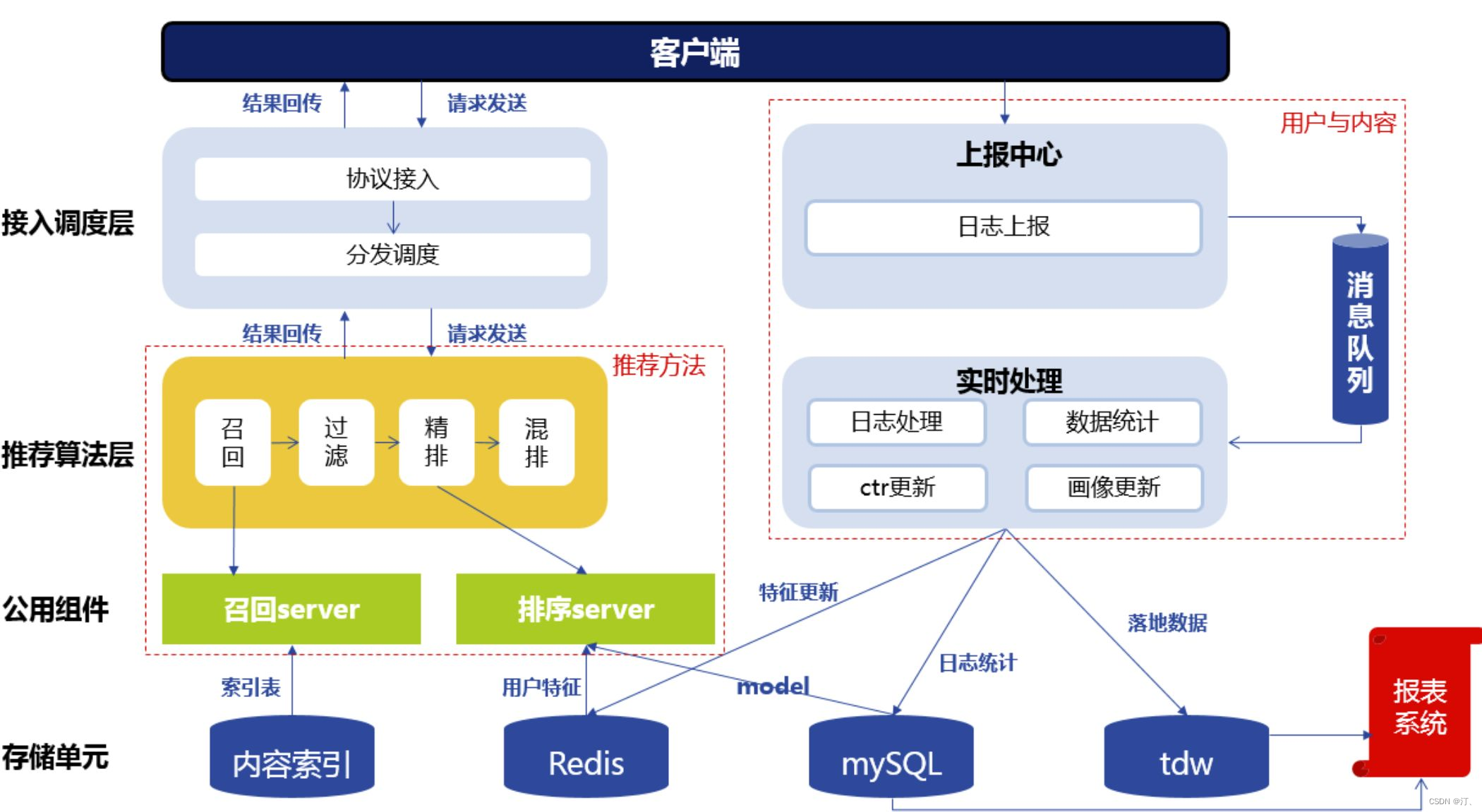
推荐的框架主要有以下几个模块
- 协议调度:请求的发送和结果的回传。在请求中,用户会发送自己的 ID,地理位置等信息。结果回传中会返回推荐系统给用户推荐的结果。
- 推荐算法:算法按照一定的逻辑为用户产生最终的推荐结果。不同的推荐算法基于不同的逻辑与数据运算过程。
- 消息队列:数据的上报与处理。根据用户的 ID,拉取例如用户的性别、之前的点击、收藏等用户信息。而用户在 APP 中产生的新行为,例如新的点击会储存在存储单元里面。
- 存储单元:不同的数据类型和用途会储存在不同的存储单元中,例如内容标签与内容的索引存储在 mysql 里,实时性数据存储在 redis 里,需要进行数据统计的数据存储在 TDW 里。
2.推荐系统
2.1 推荐算法流程介绍
推荐算法其实本质上是一种信息处理逻辑,当获取了用户与内容的信息之后,按照一定的逻辑处理信息后,产生推荐结果。热度排行榜就是最简单的一种推荐方法,它依赖的逻辑就是当一个内容被大多数用户喜欢,那大概率其他用户也会喜欢。但是基于粗放的推荐往往会不够精确,想要挖掘用户个性化的,小众化的兴趣,需要制定复杂的规则运算逻辑,并由机器完成。
推荐算法主要分为以下几步:
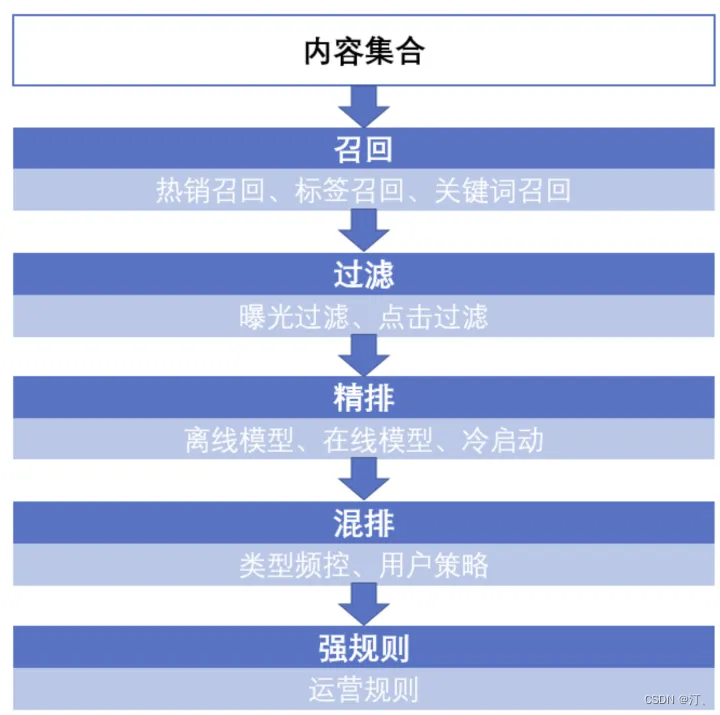
- 召回:当用户以及内容量比较大的时候,往往先通过召回策略,将百万量级的内容先缩小到百量级。
- 过滤:对于内容不可重复消费的领域,例如实时性比较强的新闻等,在用户已经曝光和点击后不会再推送到用户面前。
- 精排:对于召回并过滤后的内容进行排序,将百量级的内容并按照顺序推送。
- 混排:为避免内容越推越窄,将精排后的推荐结果进行一定修改,例如控制某一类型的频次。
- 强规则:根据业务规则进行修改,例如在活动时将某些文章置顶。
例如在抖音与快手的分发中:抖音强平台基于内容质量分发,快手轻平台基于社交和兴趣分发,抖音:内容质量>关系>双向互动。快手:内容质量 约等于 关系 > 双向互动。抖音基于将内容从小流量开始,其中表现优质的内容将不断的进入更大的流量池中,最终进入推荐池,形成 90 天+精品召回池,最终的结果也是优质内容的热度随着时间推移逐渐累积增加,头部内容的集中度很高。
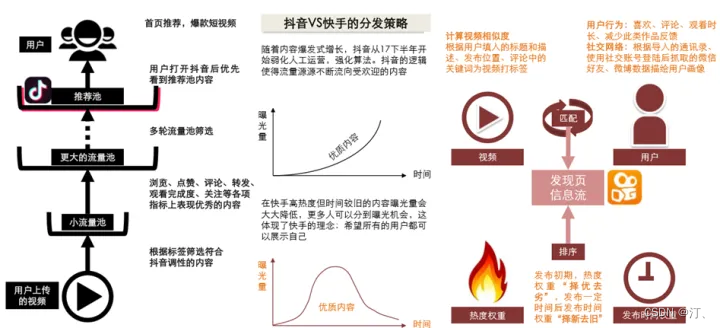
来源:方正证券《抖音 vs 快手深度复盘与前瞻-短视频 130 页分析框架》
2.1.1 召回策略
- 召回的目的:当用户与内容的量级比较大,例如对百万量级的用户与内容计算概率,就会产生百万*百万量级的计算量。但同时,大量内容中真正的精品只是少数,对所有内容进行一次计算将非常的低效,会浪费大量的资源和时间。因此采用召回策略,例如热销召回,召回一段时间内最热门的 100 个内容,只需进行一次计算动作,就可以对所有用户应用。
- 召回的重要性:虽然精排模型一直是优化的重点,但召回模型也非常的重要,因为如果召回的内容不对,怎么精排都是错误的。
- 召回方法:召回的策略不应该是简单的策略堆砌,而应该是方法的相互补充。
- 热销召回:将一段时间内的热门内容召回。
- 协同召回:基于用户与用户行为的相似性推荐,可以很好的突破一定的限制,发现用户潜在的兴趣偏好。
- 标签召回:根据每个用户的行为,构建标签,并根据标签召回内容。
- 时间召回:将一段时间内最新的内容召回,在新闻视频等有时效性的领域常用。是常见的几种召回方法。
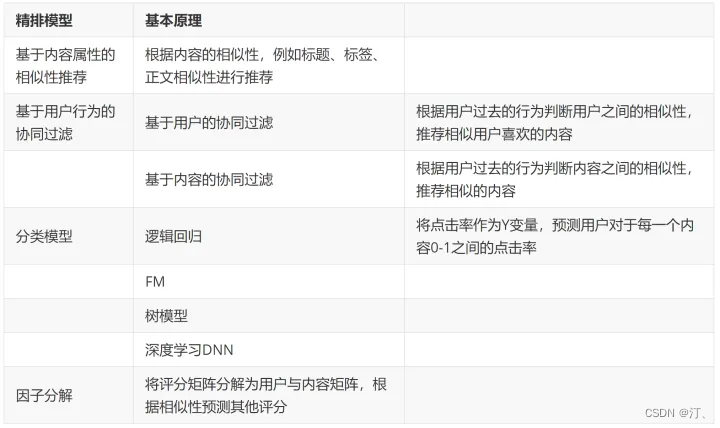
2.1.2 精排策略
精排模型的不同类别
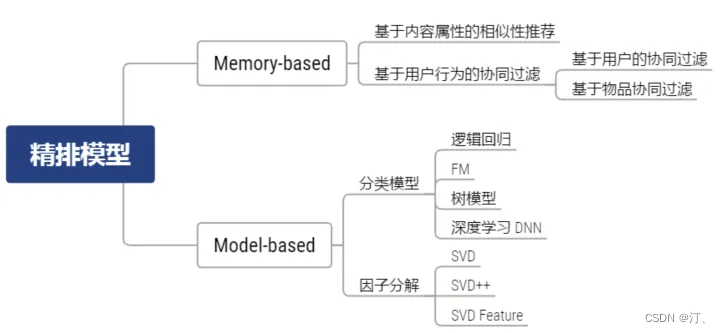
精排模型的基本原理
2.2 常见推荐算法介绍
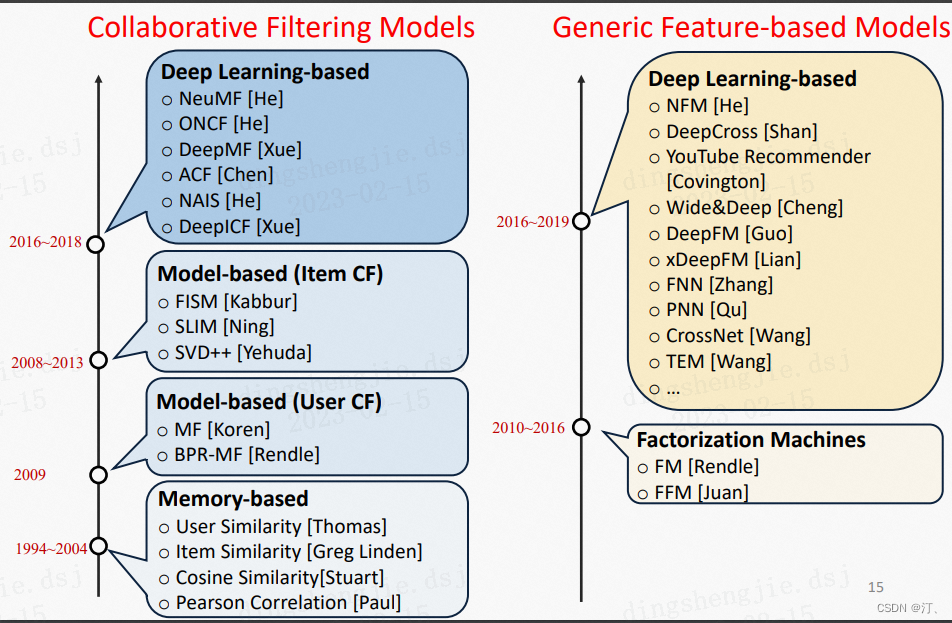
参考:Learning and Reasoning on Graph for Recommendation
http://staff.ustc.edu.cn/~hexn/slides/cikm19-tutorial-graph-rec.pdf
推荐算法大致可以分为以下几种类型:
基于流行度的算法
协同过滤算法(collaborative filtering)
基于内容的算法
基于模型的算法
混合算法
基于流行度的算法
更多内容查看
项目原链接:https://blog.csdn.net/sinat_39620217/article/details/129046810
专栏链接:https://blog.csdn.net/sinat_39620217/category_12205194.html
2.2.1 基于流行度的算法
基于流行度的算法非常简单粗暴,直接根据内容的PV(Page View,访问量)和UV(Unique Visitor,独立访客)等数据来进行热度排序来推荐给用户。常见场景有热歌榜、微博热门话题、知乎热榜等等。
这种类型的算法特点是简单,适用于刚注册不久的用户(冷启动)。但是其缺点也很明显,无法针对特定的用户进行个性化的推荐,也就意味着一百个读者只能读出同一个哈姆雷特。当然,也可以进一步对基于流行度的算法进行改进,使推荐内容拥有一定程度的个性化,例如加入用户分群特性,只把热榜上的体育新闻推荐给体育迷,只把热榜上的娱乐新闻推荐给喜欢看八卦新闻的用户。
2.2.2 协同过滤算法
协同过滤算法(Collaborative Filtering)是一种十分常用的算法,在很多购物平台中都会用到。协同过滤算法有两种类型,分别是基于用户(User)和基于物品(Item)的协同过滤算法。
a.基于用户的协同过滤算法
步骤一:获得每个用户对各个物品的评价或喜爱程度(可通过浏览、收藏和购买等记录来计算)。
步骤二:依据用户对物品的评价计算出所有用户之间的相似度。(也就是利用用户对所有物品的评价来形容用户)
步骤三:选出与当前用户最相似的K个用户。
步骤四:将这K个用户评价最高并且当前用户又没有浏览过的N个物品推荐给当前用户。
b.基于物品的协同过滤算法
步骤一:与基于用户的算法一样,获得获得每个用户对各个物品的评价或喜爱程度。
步骤二:依据用户对物品的评价计算出所有物品之间的相似度。(也就是用所有用户对物品的评价来形容物品)
步骤三:对于当前用户评价高的物品,找出与之相似度最高的N个物品。
步骤四:把这相似度最高的N个物品推荐给当前用户。
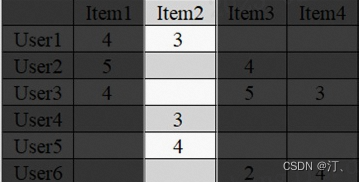
一个简单的基于用户的协同过滤算法例子。首先我们根据用户对物品的评价构建出一个用户和物品的关联矩阵,如下:
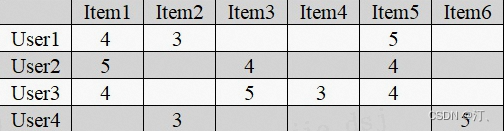
图中的行是不同的用户,列是不同的物品,单元格(x,y)的值则是x用户对y物品的评价(或喜爱程度)。我们可以把某一行视为某一个用户对所有物品偏好的向量,这样把用户向量化后,就可以计算出每两个用户之间的向量距离了,这里我们使用余弦相似度来作为向量距离。
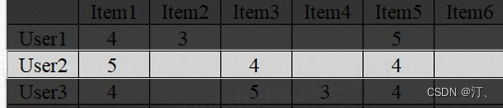

如果我们要为用户1推荐物品,则需要找出与用户1相似度最高的K名用户(设K=2)评价的物品,并且去掉用户1已经评价过的物品,最后按照评价大小进行排序,推荐出N个物品(设N=2)给用户1。

同样地,接下来举一个简单的基于物品的协同过滤算法例子。
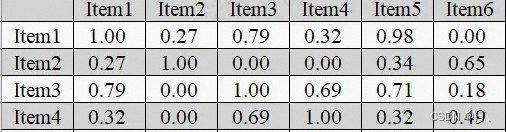
基于物品的计算方式大致相同,把用户和物品的关联矩阵中的某一列视为所有用户对该物品的评价,这样把物品向量化后,就可以计算出物品之间的相似度矩阵。
 计算出所有物品之间的相似度如下。
计算出所有物品之间的相似度如下。
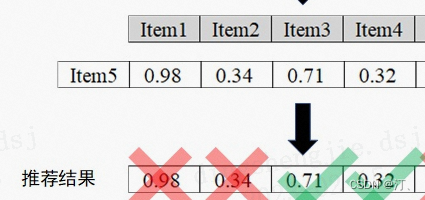
最后,如果我们要为用户1推荐物品,则需要先找到用户1评价最高的物品。然后找到与该物品相似度最高且用户1未有评价过的N(设N=2)个物品,将其推荐给用户1。
2.2.3 基于内容的算法
- 地位:最早被使用的推荐算法,年代久远,但当今仍然被广泛使用,效果良好
- 定义:给用户X推荐和之前喜欢过的物品相似的物品,即U2I2I,U2Tag2I
上面提到的两种算法看起来很好很强大,通过进一步改进也能克服各种缺陷。但是有一个问题是,如果我是《哈利波特》的粉丝,我曾经在商城买过一本《哈利波特与魔法石》。这时商城的书库又上架了一本《哈利波特与死亡圣器》,显然,我应该会很感兴趣。然而上面提到的算法这时候就都不太好使了,因此基于内容的推荐算法就因运而生了。
- 这里举一个简单的例子,现在系统里有一个用户和一条新闻。通过分析用户最近的行为(可以是该用户最近看过什么新闻)和新闻的文本内容,提取出数个关键字,
- 将这些关键字作为属性,也就可以把用户和新闻向量化:
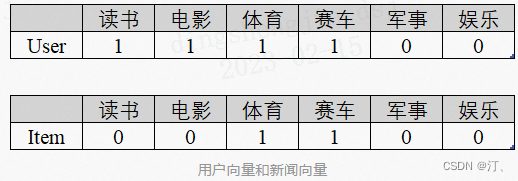
- 接着计算向量距离,得出用户和该新闻的相似度,再根据相似度进行推荐。在向量化的时候,我们也可以进一步地改进。如,在为一名喜欢看英超联赛的足球迷推荐新闻时,如果有某一条新闻里存在体育、足球、英超关键词,显然前两个词都不如英超这个词来得准确。那么我们如何在系统里突显这种“重要性”呢?这时候我们可以不再简单地用0,1或者词频来进行向量化,而是为每个词都赋予权重。这个权重可以从整个新闻语料库中计算出来(如TF-IDF算法),在向量化时引入权重的影响,可以获得更准确的效果。
- 然而,又有一个问题出现了。要是用户的关键词是足球,而新闻的关键词是德甲、英超,那么按照上面方法计算出的相似度为0。显然这不符合常理,在此,我们引入主题聚类:
- 我们可以通过预训练好的Word2Vec对关键词进行表征,然后再聚类出多个主题,最后用主题代替关键词来向量化文本。这样,足球和德甲、英超等关键词就可以通过主题来关联在一起了。
基于内容的推荐算法能够很好地解决冷启动问题,同时也不会受热度的限制,因为它是直接基于内容进行匹配的。然而,它也会存在一些缺陷,如过度专业化(over-specialisation),该缺陷会一直给用户推荐内容相关的物品,而失去了推荐内容的多样性和让用户接触新内容的机会。
c.基于内容的推荐系统demo
更多内容查看
项目原链接:https://blog.csdn.net/sinat_39620217/article/details/129046810
专栏链接:https://blog.csdn.net/sinat_39620217/category_12205194.html
2.2.4 精排模型——逻辑回归为例
2.2.5 融合算法
实际上,现实世界的推荐系统往往都不会只用某一种算法来构建。一些比较大型的系统甚至会融合数十种算法。我们可以通过加权、变换、层叠等多种方法来综合不同算法的推荐结果,或者是在不同的计算环节(如召回,排序等)中运用不同的算法来混合,达到更贴合实际业务的需要。
2.3 算法衡量指标以及获得推荐效果
2.3.2 推荐效果评估
3.用户画像(提高推荐算法效果的大杀器)
3.1 原始数据
3.2 事实标签
3.3 模型标签
3.4 内容画像
更多内容查看
项目原链接:https://blog.csdn.net/sinat_39620217/article/details/129046810
专栏链接:https://blog.csdn.net/sinat_39620217/category_12205194.html
4.结巴分词用于内容相似推荐
计算物品最相似的其他物品,直接用于I2I相似推荐,或者U2I2I推荐
以文章为例,进行内容相似推荐,一般需要以下几个步骤:
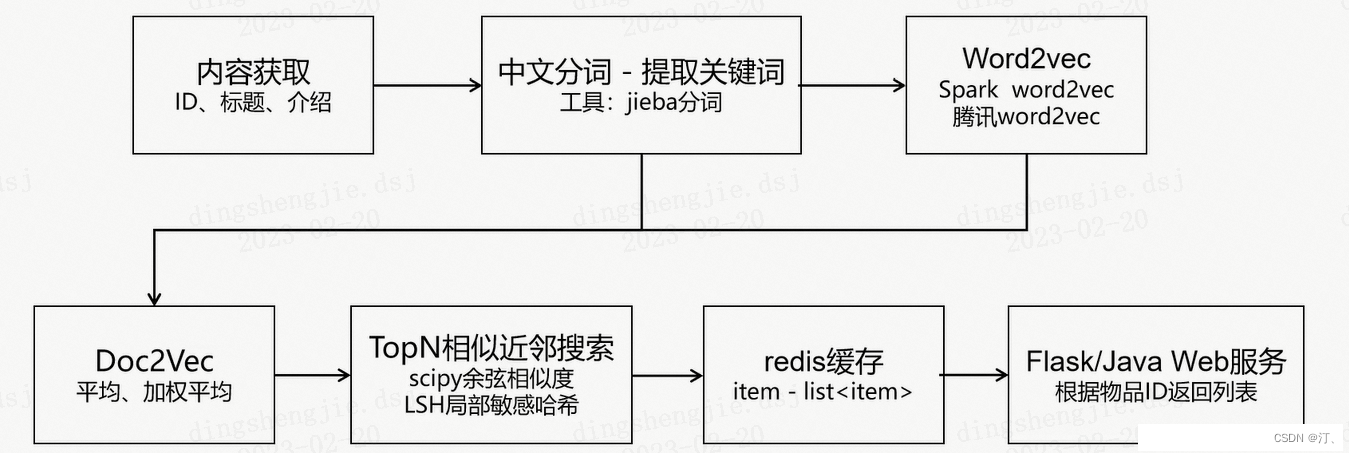
4.1 内容获取
4.2 中文分词:提取关键词
4.3 Doc2Vec:平均、加权平均
4.3 Word2vec:语意扩展
4.4 TopN相似近邻搜索
4.5 redis缓存
4.6Flask/Java Web服务
必看!!
更多内容查看
项目原链接:https://blog.csdn.net/sinat_39620217/article/details/129046810
专栏链接:https://blog.csdn.net/sinat_39620217/category_12205194.html
推荐系统[一]:超详细知识介绍,一份完整的入门指南,解答推荐系统相关算法流程、衡量指标和应用,以及如何使用jieba分词库进行相似推荐的更多相关文章
- 原来你是这样的BERT,i了i了! —— 超详细BERT介绍(一)BERT主模型的结构及其组件
原来你是这样的BERT,i了i了! -- 超详细BERT介绍(一)BERT主模型的结构及其组件 BERT(Bidirectional Encoder Representations from Tran ...
- 超详细的 Redis Cluster 官方集群搭建指南
今天从 0 开始搭建 Redis Cluster 官方集群,解决搭建过程中遇到的问题,超详细. 安装ruby环境 因为官方提供的创建集群的工具是用ruby写的,需要ruby2.2.2+版本支持,rub ...
- 超详细的网络抓包神器 tcpdump 使用指南
原文链接:Tcpdump 示例教程 本文主要内容翻译自<Tcpdump Examples>. tcpdump 是一款强大的网络抓包工具,它使用 libpcap 库来抓取网络数据包,这个库在 ...
- 最新MATLAB R2021b超详细安装教程(附完整安装文件)
摘要:本文详细介绍Matlab R2021b的安装步骤,为方便安装这里提供了完整安装文件的百度网盘下载链接供大家使用.从文件下载到证书安装本文都给出了每个步骤的截图,按照图示进行即可轻松完成安装使用. ...
- 最新MATLAB R2020b超详细安装教程(附完整安装文件)
摘要:本文详细介绍Matlab R2020b的安装步骤,为方便安装这里提供了完整安装文件的百度网盘下载链接供大家使用.从文件下载到证书安装本文都给出了每个步骤的截图,按照图示进行即可轻松完成安装使用. ...
- MATLAB R2019b超详细安装教程(附完整安装文件)
摘要:本文详细介绍Matlab的安装步骤,为方便安装这里提供了完整安装文件的百度网盘下载链接供大家使用.从文件下载到证书安装本文都给出了每个步骤的截图,按照图示进行即可轻松完成安装使用.本文目录如首页 ...
- PHP yield 分析,以及协程的实现,超详细版(上)
参考资料 http://www.laruence.com/2015/05/28/3038.html http://php.net/manual/zh/class.generator.php http: ...
- VMwear安装Centos7超详细过程
本篇文章主要介绍了VMware安装Centos7超详细过程(图文),具有一定的参考价值,感兴趣的小伙伴们可以参考一下 1.软硬件准备 软件:推荐使用VMwear,我用的是VMwear 12 镜像:Ce ...
- 非常详细的 (VMware安装Centos7超详细过程)
本篇文章主要介绍了VMware安装Centos7超详细过程(图文),具有一定的参考价值,感兴趣的小伙伴们可以参考一下 1.软硬件准备 软件:推荐使用VMwear,我用的是VMwear 12 镜像:Ce ...
- VMware15安装Centos7超详细过程
本篇文章主要介绍了VMware安装Centos7超详细过程(图文),具有一定的参考价值,感兴趣的小伙伴们可以参考一下 1.软硬件准备 软件:推荐使用VMwear15,我用的是VMwear 15 镜像: ...
随机推荐
- day14 I/O流——序列化与反序列化 & 计算机网络五层架构 & TCP的建立连接与断开连接
day 14 序列化与反序列化 序列化 将对象转化成特定格式的字符串文件(字节文件)叫做序列化 1.一个类要想实现序列化,必须实现serializable接口 2.序列化用途 1)把对象的字节序列 ...
- Tkinter根据屏幕分辨率最大化适应屏幕
还不能够实现所有组件随分辨率自动变化 # 实现的是界面覆盖整个屏幕 from tkinter import * import win32api, win32con # 获取屏幕的分辨率 width = ...
- 【Java并发入门】03 互斥锁(上):解决原子性问题
原子性问题的源头是线程切换 Q:如果禁用 CPU 线程切换是不是就解决这个问题了? A:单核 CPU 可行,但到了多核 CPU 的时候,有可能是不同的核在处理同一个变量,即便不切换线程,也有问题. 所 ...
- 【实时数仓】Day06-数据可视化接口:接口介绍、Sugar大屏、成交金额、不同维度交易额(品牌、品类、商品spu)、分省的热力图 、新老顾客流量统计、字符云
一.数据可视化接口介绍 1.设计思路 后把轻度聚合的结果保存到 ClickHouse 中后,提供即时的查询.统计.分析 展现形式:用于数据分析的BI工具[商业智能(Business Intellige ...
- 【企业流行新数仓】Day03:SuperSet图表,Ranger权限、脱敏、行级别过滤,Atlas元数据、查询和查看全表/字段血缘依赖,Zabbix告警
一.SuperSet-图表展示 1.概念 (1)概念 通过dashboard(仪表盘)对图表中的数据进行展示 BI工具:根据配置的要求,进行数据源的配置即可 是准商业级别的BI web应用 (2)原理 ...
- Redis Zset实现统计模块
1. 背景 公司有一个配置中心系统,使用MySQL存储了大量的配置,但现在不清楚哪些配置正在线上使用,哪些已经废弃了,所以需要实现一个统计模块,实现以下两个功能: 查看总体配置的数量以及活跃的数量 查 ...
- openpyxl写数据
import osimport openpyxlos.chdir(r'D:/openpyxl') wb = openpyxl.Workbook() sht = wb.create_sheet('dat ...
- 4.1IDA基础设置--《恶意代码分析实战》
1.加载一个可执行文件 ① 选项一:当加载一个文件(如PE文件),IDA像操作系统加载器一样将文件映射到内存中. ② 选项三:Binary File:将文件作为一个原始的二进制文件进行反汇编,例如文件 ...
- 安装es可视化软件Kibana
一 Kibana介绍 Kibana 是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,设计用于和 Elasticsearch 协作. 您.可以使用 Kibana 对 Ela ...
- 《STL源码剖析》STL迭代器分类
input迭代器:只能向前移动,一次一步,用户只能读取,不能修改它们所指向的东西,而且只能读取一次. output迭代器情况类似,但一切只为输出:它们只能向前移动,一次一步,用户只可以修改它们所指向的 ...