Go语言实现分布式对象存储系统
实现一个可扩展的,简易的,分布式对象存储系统
存储系统介绍
先谈谈传统的网络存储,传统的网络存储主要分为两类:
NAS,即Newtwork Attached Storage,是一个提供了存储功能和文件系统的网络服务器,客户端可以访问NAS上的文件系统,可以上传和下载文件,NAS客户端和服务端之间使用的协议有SMB、NFS以及AFS等网络文件系统协议。
对于客户端来说,NAS是一个网络上的文件服务器。SAN即Storage Area Network,SAN只提供了块存储,而把文件系统的抽象交给客户端来管理。对于客户端来说,SAN就是一块磁盘,可以对其格式化、创建文件系统并挂载。
数据管理方式
对象存储对数据管理方式不同于传统网络存储,对于网络文件系统,数据是以一个个文件的形似来管理的,对于块存储,数据是以数据块的形式来管理,每个数据块都有它自己的地址,但是没有额外的背景信息,对象存储则是以对象的方式来管理数据。
一个对象通常包含3个部分:对象的数据、对象的元数据以及一个唯一的标识符ID,对象的数据就是该对象中存储的数据本身,一个对象可以用来保存大量无结构的数据,比如一张图片或者一个在线文档。对象的元数据是对象的描述信息,为了和对象的数据本身区分开来,称其为元数据。对象的标识符具有全局唯一性,一般用对象的散列值。
数据访问方式
网络文件系统的客户端通过NFS等网络协议访问某个远程服务器上存储的文件,块存储的客户端通过数据块的地址访问SAN上数据块,对象存储则通过REST网络服务访问对象。REST即Representational Sate Transfer,REST网络服务通过标准HTTP服务对网络资源提供一套预先定义的无状态操作。客户端向REST网络服务发起请求并接收响应,以确认网络资源发生了某种变化。
HTTP预定义的请求方法通常包括GET、POST、PUT、DELETE等,分别对应不同的处理方式: GET方法在REST标准中通常用来获取某个网络资源,PUT通常用于创建或替换某个网络资源,POST通常用于创建某个网络资源,DELETE通常用于删除某个网络资源。
对象存储优势
对象存储提升了存储系统的扩展性。当一个存储系统中保存的数据越来越多时,存储系统也需要同步扩展,然而由于存储架构的硬性限制,传统网络存储系统的管理开销会不断上升,而对象存储架构只要添加新的存储节点即可。
另一大优势在于以更低的代价提供了数据冗余的能力,在分布式对象存储系统中一个或多个节点失效的情况下,对象依然可用,且大多数情况下客户都不会意识到有节点出了问题
单点对象存储
先实现一个在单机的对象存储系统,基于HTTP提供的REST接口,目录结构:
.├── go.mod├── main│ └── main.go└── objects└── server.go
main包作为程序的入口,objects包来实现主要的逻辑
main方法的实现:
package mainimport ("log""net/http""os""storage/objects")func main() {http.HandleFunc("/objects/", objects.Handler)addr := os.Getenv("LISTEN_ADDRESS")err := http.ListenAndServe(addr, nil)if err != nil {log.Fatalln(err)}}
main函数中使用HandleFunc注册一个handler,并调用ListenAndServe开始监听端口,监听的地址将在环境变量中定义,handler方法将在objects包中实现
正常情况下ListenAndServe是不会返回的,将会一直监听在指定端口,除非外部将其中断,非正常情况下会返回错误信息
objects包的实现:
package objectsimport ("io""log""net/http""os""strings")func Handler(w http.ResponseWriter, r *http.Request) {method := r.Methodif method == http.MethodPut {if err := put(w, r); err != nil {log.Println(err)}return}if method == http.MethodGet {if err := get(w, r); err != nil {log.Println(err)}return}w.WriteHeader(http.StatusMethodNotAllowed)}func put(w http.ResponseWriter, r *http.Request) error {f, err := os.Create(os.Getenv("STORAGE_ROOT") +"/objects/" + strings.Split(r.URL.EscapedPath(), "/")[2])defer f.Close()if err != nil {w.WriteHeader(http.StatusInternalServerError)return err}_, err = io.Copy(f, r.Body)if err != nil {w.WriteHeader(http.StatusInternalServerError)}return err}func get(w http.ResponseWriter, r *http.Request) error {f, err := os.Open(os.Getenv("STORAGE_ROOT") +"/objects/" + strings.Split(r.URL.EscapedPath(), "/")[2])defer f.Close()if err != nil {w.WriteHeader(http.StatusNotFound)return err}_, err = io.Copy(w, f)if err != nil {w.WriteHeader(http.StatusInternalServerError)}return err}
Handler函数只处理GET请求和PUT请求,收到GET请求就调用get方法,收到PUT请求就调用put方法
io.Copy用于传输数据,地一个参数是写入的io.Writer,第二个参数是用于读取的io.Reader,put函数中首先创建指定的文件,如果创建失败则返回500状态码,创建成功则将Body数据写入文件,get函数同理,只不过先打开一个本地的文件,然后将文件数据写入response
运行测试:
设置环境变量
$ export LISTEN_ADDRESS=:8080$ export STORAGE_ROOT=/tmp
使用curl发起请求:
$ curl -v 127.0.0.1:8080/objects/test* Uses proxy env variable no_proxy == 'localhost,127.0.0.0/8,::1'* Uses proxy env variable http_proxy == 'http://127.0.0.1:7890/'* Trying 127.0.0.1:7890...* TCP_NODELAY set* Connected to 127.0.0.1 (127.0.0.1) port 7890 (#0)> GET http://127.0.0.1:8080/objects/test HTTP/1.1> Host: 127.0.0.1:8080> User-Agent: curl/7.68.0> Accept: */*> Proxy-Connection: Keep-Alive>* Mark bundle as not supporting multiuse< HTTP/1.1 404 Not Found< Connection: keep-alive< Date: Fri, 26 Aug 2022 06:17:29 GMT< Keep-Alive: timeout=4< Proxy-Connection: keep-alive< Content-Length: 0<* Connection #0 to host 127.0.0.1 left intact
发送请求,服务器给出了404回复,下面使用PUT添加数据:
$ curl -v 127.0.0.1:8080/objects/test -XPUT -d"this is a test objects"* Uses proxy env variable no_proxy == 'localhost,127.0.0.0/8,::1'* Uses proxy env variable http_proxy == 'http://127.0.0.1:7890/'* Trying 127.0.0.1:7890...* TCP_NODELAY set* Connected to 127.0.0.1 (127.0.0.1) port 7890 (#0)> PUT http://127.0.0.1:8080/objects/test HTTP/1.1> Host: 127.0.0.1:8080> User-Agent: curl/7.68.0> Accept: */*> Proxy-Connection: Keep-Alive> Content-Length: 22> Content-Type: application/x-www-form-urlencoded>* upload completely sent off: 22 out of 22 bytes* Mark bundle as not supporting multiuse< HTTP/1.1 200 OK< Content-Length: 0< Connection: keep-alive< Date: Fri, 26 Aug 2022 06:37:57 GMT< Keep-Alive: timeout=4< Proxy-Connection: keep-alive<* Connection #0 to host 127.0.0.1 left intact
用curl命令PUT了一个名为test的对象,该对象的内容为"this is a test object",服务器返回"200 OK",表示PUT成功
GET这个对象:
$ curl -v 127.0.0.1:8080/objects/test* Uses proxy env variable no_proxy == 'localhost,127.0.0.0/8,::1'* Uses proxy env variable http_proxy == 'http://127.0.0.1:7890/'* Trying 127.0.0.1:7890...* TCP_NODELAY set* Connected to 127.0.0.1 (127.0.0.1) port 7890 (#0)> GET http://127.0.0.1:8080/objects/test HTTP/1.1> Host: 127.0.0.1:8080> User-Agent: curl/7.68.0> Accept: */*> Proxy-Connection: Keep-Alive>* Mark bundle as not supporting multiuse< HTTP/1.1 200 OK< Content-Length: 22< Connection: keep-alive< Content-Type: text/plain; charset=utf-8< Date: Fri, 26 Aug 2022 06:40:02 GMT< Keep-Alive: timeout=4< Proxy-Connection: keep-alive<* Connection #0 to host 127.0.0.1 left intactthis is a test objects
获取到了内容
单机的对象存储缺乏可扩展性,接口和数据存储耦合度高,分布式对象存储应该是可扩展的
可扩展分布式系统
一个分布式系统要求各节点分布在网络上,通过消息传递来合作完成一个共同目标,分布式系统的三大关键特征是: 节点之间并发工作,没有全局锁以及某个节点上发生的错误不影响其他节点,只要加入新的节点就可以自由扩展集群的性能。相比单机的对象存储,下面要将接口和数据类型解耦合,让接口和数据存储成为相互独立的服务节点,两者互相合作提供对象存储服务
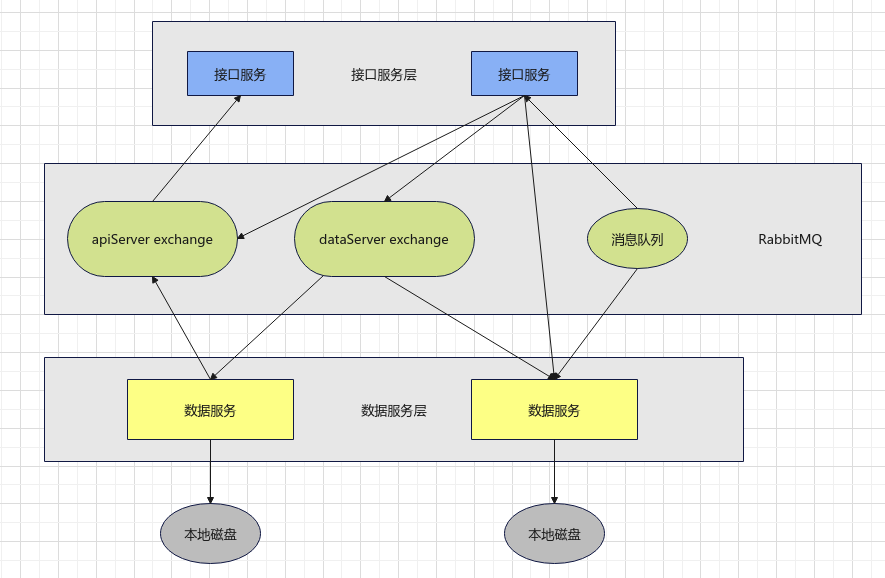
如上是架构图,接口服务层对外提供了REST接口,而数据服务层则提供数据的存储服务。接口服务处理客户端的请求,然后向数据服务存取对象,数据服务处理来自接口服务的请求并在本地磁盘上存取对象,数据服务处理来自接口服务的请求并在本地磁盘上存取对象
接口服务和数据服务之间的接口有两种,一种是接口实现对象的存取,对象的存取使用REST接口,此时接口服务节点作为HTTP客户端向数据服务请求对象,还有一种接口通过RabbitMQ消息队列进行通信,这里对RabbitMQ的使用分为两种模式,一种模式是向某个exchange进行一对多的消息群发,另一种模式是向某个消息队列进行一对一的消息单发
使用RabbitMQ
为了使用RabbitMQ,须要下载RabbitMQ提供的Go语言包:go get github.com/streadway/amqp
相关文档: https://pkg.go.dev/github.com/streadway/amqp@v1.0.0
创建rabbitmq包:
package rabbitmqimport ("encoding/json""github.com/streadway/amqp")type RabbitMQ struct {channel *amqp.ChannelName stringexchange string}func New(s string) *RabbitMQ {conn, err := amqp.Dial(s)if err != nil {panic(err)}ch, err := conn.Channel()if err != nil {panic(err)}queue, err := ch.QueueDeclare("", false, true,false, false, nil)if err != nil {panic(err)}mq := new(RabbitMQ)mq.channel = chmq.Name = queue.Namereturn mq}func (q *RabbitMQ) Bind(exchange string) {err := q.channel.QueueBind(q.Name, "", exchange,false, nil)if err != nil {panic(err)}q.exchange = exchange}func (q *RabbitMQ) Send(queue string, body interface{}) {s, err := json.Marshal(body)if err != nil {panic(err)}err = q.channel.Publish("", queue,false, false,amqp.Publishing{ReplyTo: q.Name,Body: []byte(s),})if err != nil {panic(err)}}func (q *RabbitMQ) Publish(exchange string, body interface{}) {s, err := json.Marshal(body)if err != nil {panic(err)}err = q.channel.Publish(exchange, "", false,false, amqp.Publishing{ReplyTo: q.Name, Body: []byte(s),})if err != nil {panic(err)}}func (q *RabbitMQ) Consume() <-chan amqp.Delivery {c, err := q.channel.Consume(q.Name, "", true, false,false, false, nil)if err != nil {panic(err)}return c}func (q *RabbitMQ) Close() {q.channel.Close()}
首先是New函数用于创建一个新的结构体:
func New(s string) *RabbitMQ {conn, err := amqp.Dial(s)if err != nil {panic(err)}ch, err := conn.Channel()if err != nil {panic(err)}queue, err := ch.QueueDeclare("", false, true,false, false, nil)if err != nil {panic(err)}mq := new(RabbitMQ)mq.channel = chmq.Name = queue.Namereturn mq}
调用amqp.Dial创建一个连接,调用Channel方法创建一个通道,调用QueueDeclare方法创建一个队列,赋值后返回RabbitMQ结构体,之后定义的Bind方法:
func (q *RabbitMQ) Bind(exchange string) {err := q.channel.QueueBind(q.Name, "", exchange,false, nil)if err != nil {panic(err)}q.exchange = exchange}
该方法可以将消息队列和一个exchange绑定,调用QueueBind方法,传入队列名称和exchange
Send方法可以往某个消息队列发送消息:
func (q *RabbitMQ) Send(queue string, body interface{}) {s, err := json.Marshal(body)if err != nil {panic(err)}err = q.channel.Publish("", queue,false, false,amqp.Publishing{ReplyTo: q.Name,Body: []byte(s),})if err != nil {panic(err)}}
Publish方法可以往某个exchange发送消息:
func (q *RabbitMQ) Publish(exchange string, body interface{}) {s, err := json.Marshal(body)if err != nil {panic(err)}err = q.channel.Publish(exchange, "", false,false, amqp.Publishing{ReplyTo: q.Name, Body: []byte(s),})if err != nil {panic(err)}}
Consume方法用于生成一个可接收消息的go channel,使客户程序可以通过Go语言的原生机制接收队列中的消息:
func (q *RabbitMQ) Consume() <-chan amqp.Delivery {c, err := q.channel.Consume(q.Name, "", true, false,false, false, nil)if err != nil {panic(err)}return c}
Close方法用于关闭消息队列:
func (q *RabbitMQ) Close() {q.channel.Close()}
实现数据服务
创建dataserver文件夹,下面是数据服务的实现,数据服务的REST接口与单击版本一致,但实现上有所变化
数据服务程序入口,main函数:
package mainimport ("distributed-storge/dataserver/heartbeat""distributed-storge/dataserver/locate""log""net/http""os")func main() {go heartbeat.StartHeartbeat()go locate.StartLocate()http.HandleFunc("/objects/", objects.Handler)address := os.Getenv("LISTEN_ADDRESS")err := http.ListenAndServe(address, nil)if err != nil {log.Println(err)}}
这里先用了两个goroutine,第一个goroutine执行heartbeat.StartHeartbeat函数,heartbeat还未实现,正如其名,与心跳请求相关,第二个goroutine执行locate.StartLocate函数,用于实际定位对象
实现heartbeat
这个包中只实现一个StartHeartbeat,该函数每5s向apiServers exchange发送一条消息
package heartbeatimport ("distributed-storge/rabbitmq""os""time")func StartHeartbeat() {server := os.Getenv("RABBITMQ_SERVER")q := rabbitmq.New(server)defer q.Close()for {address := os.Getenv("LISTEN_ADDRESS")q.Publish("apiServers", address)time.Sleep(5 * time.Second)}}
heartbeat.StartHeartbeat调用rabbitmq.New创建一个rabbitmq.RabbitMQ结构体,并不停循环调用Publish方法,向apiServer exchange发送本节点的监听地址,由于该函数在一个goroutine中执行,所以不返回也不影响功能
实现locate包
有两个函数,分别用于实际定位对象的Locate函数和用于监听定位消息的StartLocate函数
package locateimport ("distributed-storge/rabbitmq""os""strconv")func Locate(name string) bool {_, err := os.Stat(name)return !os.IsNotExist(err)}func StartLocate() {server := os.Getenv("RABBITMQ_SERVER")q := rabbitmq.New(server)defer q.Close()q.Bind("dataServers")c := q.Consume()for msg := range c {object, err := strconv.Unquote(string(msg.Body))if err != nil {panic(err)}root := os.Getenv("STORAGE_ROOT") + "/objects/" + objectaddress := os.Getenv("LISTEN_ADDRESS")if Locate(root) {q.Send(msg.ReplyTo, address)}}}
Locate函数用os.Stat访问磁盘上对应的文件名,用os.IsNotExist判断文件名是否存在,如果存在则定位成功true,否则定位失败返回false
StartLocate函数会创建一个rabbitmq.RabbitMQ结构体,并调用其Bind方法绑定dataService exchange,rabbitmq.RabbitMQ结构体的Consume方法会返回一个Go语言的通道,遍历这个通道可以接收消息,消息的正文内容是接受服务发送过来要做定位的对象名字,经过了JSON编码。在对象名字前加上相应的存储目录并以此作为文件名,然后调用locate函数检查文件是否存在,如果存在则调用Send方法向消息的发送方返回本服务节点的监听地址,表示该对象存在于本服务节点上
实现接口服务
创建apiserver文件夹
提供REST接口和locate功能,main函数入口:
package apiserverimport ("distributed-storge/apiserver/heartbeat""log""net/http""os")func main() {go heartbeat.ListenHeartbeat()http.HandleFunc("/objects/", objects.Handler)http.HandleFunc("/locate/", locate.Handler)address := os.Getenv("LISTEN_ADDRESS")err := http.ListenAndServe(address, nil)if err != nil {log.Println(err)}}
接口服务的main函数启动一个goroutine来执行heartbeat.ListenHeartbeat函数,接口服务除了需要objects.Handler处理URL,以/objects/开头的对象以外,还要有一个locate.Handler函数处理URL以/locate/开头的定位请求
实现heartbeat
接口服务的heartbeat用于接收数据服务节点的心跳消息,定义了4个函数用于接收和处理来自数据服务节点的心跳消息:
package heartbeatimport ("distributed-storge/rabbitmq""math/rand""os""strconv""sync""time")var dataServers = make(map[string]time.Time)var mutex sync.Mutexfunc ListenHeartbeat() {server := os.Getenv("RABBIT_SERVER")q := rabbitmq.New(server)defer q.Close()q.Bind("apiServer")c := q.Consume()go removeExpiredDataServer()for msg := range c {dataServer, err := strconv.Unquote(string(msg.Body))if err != nil {panic(err)}mutex.Lock()dataServers[dataServer] = time.Now()mutex.Unlock()}}func removeExpiredDataServer() {for {time.Sleep(5 * time.Second)mutex.Lock()for s, t := range dataServers {if t.Add(10 * time.Second).Before(time.Now()) {delete(dataServers, s)}}mutex.Unlock()}}func GetDataServers() []string {mutex.Lock()defer mutex.Unlock()ds := make([]string, 0)for s, _ := range dataServers {ds = append(ds, s)}return ds}func ChooseRandomDataServer() string {ds := GetDataServers()n := len(ds)if n == 0 {return ""}return ds[rand.Intn(n)]}
开头定义了一个map即dataServers,用于缓存所有的数据服务节点,记录了最近一次心跳消息的时间,这里对dataServers的读写全部都需要mutex保护,以防止多个goroutine并发读写map造成错误,Go语言的map可以支持多个goroutine同时读,但不能支持多个goroutine同时既读又写,所以要使用一个互斥锁保护map的并发读写,mutex的类型是sync.Mutex,无论读写都只允许一个goroutine操作map
ListenHeartbeat函数创建消息队列来绑定apiServers exchange并通过通道监听每一个来自数据服务节点的心跳消息,将该消息的正文内容,即数据服务的监听地址作为map的键,收到消息的时间作为值存入dataServers
func ListenHeartbeat() {server := os.Getenv("RABBIT_SERVER")q := rabbitmq.New(server)defer q.Close()q.Bind("apiServer")c := q.Consume()go removeExpiredDataServer()for msg := range c {dataServer, err := strconv.Unquote(string(msg.Body))if err != nil {panic(err)}mutex.Lock()dataServers[dataServer] = time.Now()mutex.Unlock()}}
removeExpiredDataServer函数在一个goroutine中运行,每隔5s遍历一遍dataServers,并清除其中超过10s没收到心跳消息的数据服务节点
func removeExpiredDataServer() {for {time.Sleep(5 * time.Second)mutex.Lock()for s, t := range dataServers {if t.Add(10 * time.Second).Before(time.Now()) {delete(dataServers, s)}}mutex.Unlock()}}
通过调用Add方法为时间加上10秒,通过Before方法来比较时间
GetDataServers遍历dataServers并返回当前所有的数据服务节点
func GetDataServers() []string {mutex.Lock()defer mutex.Unlock()ds := make([]string, 0)for s, _ := range dataServers {ds = append(ds, s)}return ds}
ChooseRandomDataServer函数会在当前所有的数据服务节点随机选出一个节点并返回,如果当前数据服务节点为空,则返回空字符串:
func ChooseRandomDataServer() string {ds := GetDataServers()n := len(ds)if n == 0 {return ""}return ds[rand.Intn(n)]}
实现locate
向数据服务节点群发定位消息并接收反馈:
package locateimport ("distributed-storge/rabbitmq""encoding/json""net/http""os""strconv""strings""time")func Handler(w http.ResponseWriter, r *http.Request) {m := r.Methodif m != http.MethodGet {w.WriteHeader(http.StatusMethodNotAllowed)return}info := Locate(strings.Split(r.URL.EscapedPath(), "/")[2])if len(info) == 0 {w.WriteHeader(http.StatusNotFound)return}b, _ := json.Marshal(info)w.Write(b)}func Locate(name string) string {server := os.Getenv("RABBITMQ_SERVER")q := rabbitmq.New(server)q.Publish("dataServers", name)c := q.Consume()go func() {time.Sleep(time.Second)q.Close()}()msg := <-cs, _ := strconv.Unquote(string(msg.Body))return s}func Exist(name string) bool {return Locate(name) != ""}
Handler函数用于处理HTTP请求,如果请求方法不为GET,则返回405,如果请求方法为GET,截取出Object名称再传给Locate来定位这个对象
Locate接收的是需要定位的对象的名字,会创建一个新的消息队列,并向dataServers exchange群发这个对象名字的定位信息,随后启用一个goroutine调用匿名函数,用于在1s后关闭这个临时消息队列,这是为了设置一个超时机制,避免无限等待
Exist函数通过检查Locate结果是否为空字符串来判定对象是否存在
实现objectstream
这个包是对http包的一个封装,用来把一些http函数的调用转换成读写流的形式,方便处理
package objectstreamimport ("fmt""io""net/http")type PutStream struct {writer *io.PipeWriterc chan error}func NewPutStream(server, object string) *PutStream {reader, writer := io.Pipe()c := make(chan error)go func() {request, _ := http.NewRequest("PUT", "http://"+server+"/objects/"+object, reader)client := http.Client{}resp, err := client.Do(request)if err != nil && resp.StatusCode != http.StatusOK {err = fmt.Errorf("dataserver return http code %d", resp.StatusCode)}c <- err}()return &PutStream{writer, c}}func (w *PutStream) Write(p []byte) (int, error) {return w.writer.Write(p)}func (w *PutStream) Close() error {w.writer.Close()return <-w.c}type GetStream struct {reader io.Reader}func newGetStream(url string) (*GetStream, error) {resp, err := http.Get(url)if err != nil {return nil, err}if resp.StatusCode != http.StatusOK {return nil, fmt.Errorf("dataServer return http code %d", resp.StatusCode)}return &GetStream{resp.Body}, nil}func NewGetStream(server, object string) (*GetStream, error) {if server == "" || object == "" {return nil, fmt.Errorf("invalid server %s object %s", server, object)}return newGetStream("http://" + server + "/objects" + object)}func (r *GetStream) Read(p []byte) (int, error) {return r.reader.Read(p)}
如下是关于PutStream的定义:
type PutStream struct {writer *io.PipeWriterc chan error}func NewPutStream(server, object string) *PutStream {reader, writer := io.Pipe()c := make(chan error)go func() {request, _ := http.NewRequest("PUT", "http://"+server+"/objects/"+object, reader)client := http.Client{}resp, err := client.Do(request)if err != nil && resp.StatusCode != http.StatusOK {err = fmt.Errorf("dataserver return http code %d", resp.StatusCode)}c <- err}()return &PutStream{writer, c}}func (w *PutStream) Write(p []byte) (int, error) {return w.writer.Write(p)}func (w *PutStream) Close() error {w.writer.Close()return <-w.c}
首先定义了一个结构体PutStream,内含一个io.PipeWriter的指针writer和一个error的通道,这个通道用于把一个goroutine传输数据的过程中发生的错误传回主线程
NewPutStream函数用于生成一个PutStream结构体,用io.Pipe创建了一对reader和writer,类型分别是*io.PipeReader和*io.PipeWriter,他们是管道互联的,写入writer的内容可以从reader中读出来,这一对管道用于以写入数据流的方式操作HTTP的PUT请求。Go语言的HTTP包在生成一个PUT请求时要求提供一个io.Reader作为http.NewRequest的参数,由一个类型为http.Client的client的负责读取要PUT的内容,通过这对管道就可以在满足http.NewRequest的参数要求时用写入writer的方式实现PutStream的Write方法,由于管道是阻塞的,所以要调用一个goroutine来调用client.Do方法
Close方法用于关闭管道,否则Reader将会被一直阻塞
如下是关于GetStream的定义:
type GetStream struct {reader io.Reader}func newGetStream(url string) (*GetStream, error) {resp, err := http.Get(url)if err != nil {return nil, err}if resp.StatusCode != http.StatusOK {return nil, fmt.Errorf("dataServer return http code %d", resp.StatusCode)}return &GetStream{resp.Body}, nil}func NewGetStream(server, object string) (*GetStream, error) {if server == "" || object == "" {return nil, fmt.Errorf("invalid server %s object %s", server, object)}return newGetStream("http://" + server + "/objects" + object)}func (r *GetStream) Read(p []byte) (int, error) {return r.reader.Read(p)}
GetStream只需要一个成员reader用于记录http返回的io.Reader
newGetStream的函数的输入参数URL是一个字符串,表示用于获取数据流的HTTP服务地址,之后发起一个Get请求得到响应Body,传入结构体返回
Read方法用于读取reader成员,只要实现了该方法,就实现了io.Reader接口
实现objects
实现REST接口,负责将HTTP请求转发给数据服务
package objectsimport ("distributed-storge/apiserver/heartbeat""distributed-storge/apiserver/locate""distributed-storge/apiserver/objectstream""fmt""io""log""net/http""strings")func Handler(w http.ResponseWriter, r *http.Request) {method := r.Methodif method == http.MethodPut {put(w, r)}if method == http.MethodGet {get(w, r)}w.WriteHeader(http.StatusMethodNotAllowed)}func put(w http.ResponseWriter, r *http.Request) {object := strings.Split(r.URL.EscapedPath(), "/")[2]c, err := storeObject(r.Body, object)if err != nil {log.Println(err)}w.WriteHeader(c)}func storeObject(r io.Reader, object string) (int, error) {stream, err := putStream(object)if err != nil {return http.StatusServiceUnavailable, err}io.Copy(stream, r)err = stream.Close()if err != nil {return http.StatusInternalServerError, err}return http.StatusOK, nil}func putStream(object string) (*objectstream.PutStream, error) {server := heartbeat.ChooseRandomDataServer()if server == "" {return nil, fmt.Errorf("cannot find any dataserver")}return objectstream.NewPutStream(server, object), nil}func get(w http.ResponseWriter, r *http.Request) {object := strings.Split(r.URL.EscapedPath(), "/")[2]stream, err := getStream(object)if err != nil {log.Println(err)w.WriteHeader(http.StatusNotFound)return}io.Copy(w, stream)}func getStream(object string) (io.Reader, error) {server := locate.Locate(object)if server == "" {return nil, fmt.Errorf("object %s locate fail", object)}return objectstream.NewGetStream(server, object)}
put截取出object名称,并和请求的Body一起传给storeObject函数,storeObject函数中先调用putStream函数生成了stream,此时就已经发起了HTTP请求,随后将请求正文写入这个stream后关闭,putStream函数首先调用heartbeat.ChooseRandomDataServer函数获得一个随机数据服务节点地址server,如果server为空字符串,则意味着当前没有可用的数据服务节点,客户端会收到HTTP错误代码503
get同样获得object名称,然后以之为参数调用getStream生成stream,其参数object是一个字符串,代表对象名称,调用locate定位这个对象
Go语言实现分布式对象存储系统的更多相关文章
- go语言实现分布式对象存储系统之单体对象存储
对象存储 基本概念 主流存储类型分为三种:块存储.文件存储以及对象存储 NAS(文件存储):Network Attached storage,提供了存储功能和文件系统的网络服务器,客户端可以访问NAS ...
- 三种分布式对象主流技术——COM、Java和COBRA
既上一遍,看到还有一遍将关于 对象的, 分布式对象, 故摘抄入下: 目前国际上,分布式对象技术有三大流派——COBRA.COM/DCOM和Java.CORBA技术是最早出现的,1991年OMG颁布了C ...
- 用asp.net core结合fastdfs打造分布式文件存储系统
最近被安排开发文件存储微服务,要求是能够通过配置来无缝切换我们公司内部研发的文件存储系统,FastDFS,MongDb GridFS,阿里云OSS,腾讯云OSS等.根据任务紧急度暂时先完成了通过配置来 ...
- 淘宝分布式文件存储系统:TFS
TFS ——分布式文件存储系统 TFS(Taobao File System)是淘宝针对海量非结构化数据存储设计的分布式系统,构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问. ...
- 分布式 Key-Value 存储系统:Cassandra 入门
Apache Cassandra 是一套开源分布式 Key-Value 存储系统.它最初由 Facebook 开发,用于储存特别大的数据. Cassandra 不是一个数据库,它是一个混合型的非关系的 ...
- Swift是一个提供RESTful HTTP接口的对象存储系统
Swift是一个提供RESTful HTTP接口的对象存储系统,最初起源于Rackspace的Cloud Files,目的是为了提供一个和AWS S3竞争的服务. Swift于2010年开源,是Ope ...
- 一图看懂hadoop分布式文件存储系统HDFS工作原理
一图看懂hadoop分布式文件存储系统HDFS工作原理
- Swift是一个提供RESTful HTTP接口的对象存储系统,目的是为了提供一个和AWS S3竞争的服务
Swift是一个提供RESTful HTTP接口的对象存储系统,最初起源于Rackspace的Cloud Files,目的是为了提供一个和AWS S3竞争的服务. Swift于2010年开源,是Ope ...
- 腾讯重磅开源分布式NoSQL存储系统DCache
当你在电商平台秒杀商品或者在社交网络刷热门话题的时候,可以很明显感受到当前网络数据流量的恐怖,几十万商品刚开抢,一秒都不到就售罄:哪个大明星出轨的消息一出现,瞬间阅读与转发次数可以达到上亿.作为终端用 ...
- 必须掌握的分布式文件存储系统—HDFS
HDFS(Hadoop Distributed File System)分布式文件存储系统,主要为各类分布式计算框架如Spark.MapReduce等提供海量数据存储服务,同时HBase.Hive底层 ...
随机推荐
- Android Native Code 手动调试
调试启动过程中的 Android Native Code Crash 记录一下,最后成功使用的工具是 lldb + lldb-server,不需要 root 权限.我最先尝试使用的是,gdb + gd ...
- 关于JSP无法使用静态引用的问题案例
问题描述: 在写项目时,对于头部信息,尾部信息,分页信息等出现频率高,又很雷同的部分进行抽取时,使用到了jsp的静态引用功能,但之前我每次使用,都会导致程序报错,甚至出现tomcat无法正常启动的情况 ...
- 持续集成环境(5)-Maven安装和配置
在Jenkins集成服务器上,我们需要安装Maven来编译和打包项目. 安装Maven 1.下载Maven软件到jenkins服务器上 wget https://mirrors.aliyun.com/ ...
- 如何优化if--else
1.现状代码 public interface IPay { void pay(); } package com.test.zyj.note.service.impl; import com.test ...
- docker基本操作 备忘
docker 基本操作 通过镜像运行容器 - docker run -d -it -p 5555:5555 镜像名 启动容器,并将进入容器中的bash命令行 进入容器 - docker attach ...
- clion环境配置
如果是学生:直接使用学校的邮箱,可以直接注册使用 环境配置:下载:https://sourceforge.net/projects/mingw-w64/
- Axios的相关应用
Axios 的案例应用 要求利用axios实现之前利用AJAX实现的验证用户是否登录的案例 鉴于这两种语法的相似性,只需要在AJAX里面的注册界面里面的script标签里面包含的代码修改为如下代码即可 ...
- Python通过ssh登录实现报文监听
Python自动化ssh登录目标主机,实现报文长度length 0监听,并根据反馈信息弹窗报警: 代码比较简陋,后续记得优化改进. #_*_coding:utf-8 _*_ #!/usr/bin/py ...
- IDEA-日志管理神器
Grep Console-插件的好处就在于能使控制台输出日志时,可以直接修改插件中定义好的规则,也可以根据自己定义的规则,输出不同的颜色.这样就可以将错误信息标记成显眼的颜色,方便查看,提高bug寻找 ...
- Teamcenter_NX集成开发:使用NX、SOA连接Teamcenter
最近工作中经常使用Teamcenter.NX集成开发的情况,因此在这里记录使用NX.SOA连接到Teamcenter的连接方式. 主要操作: 1-初始化UGMGR环境成功后就可以连接到Teamcent ...