MySQL查询性能优化七种武器之链路追踪
MySQL优化器可以生成Explain执行计划,我们可以通过执行计划查看是否使用了索引,使用了哪种索引?
但是到底为什么会使用这个索引,我们却无从得知。
好在MySQL提供了一个好用的工具 — optimizer trace(优化器追踪),可以帮助我们查看优化器生成执行计划的整个过程,以及做出的各种决策,包括访问表的方法、各种开销计算、各种转换等。
1. 查看optimizer trace配置
show variables like '%optimizer_trace%';

输出参数详解:
optimizer_trace 主配置,enabled的on表示开启,off表示关闭,one_line表示是否展示成一行
optimizer_trace_features 表示优化器的可选特性,包括贪心搜索、范围优化等
optimizer_trace_limit 表示优化器追踪最大显示数目,默认是1条
optimizer_trace_max_mem_size 表示优化器追踪占用的最大容量
optimizer_trace_offset 表示显示的第一个优化器追踪的偏移量
2. 开启optimizer trace
optimizer trace默认是关闭,我们可以使用命令手动开启:
SET optimizer_trace="enabled=on";

3. 线上问题复现
先造点数据备用,创建一张用户表:
CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(100) NOT NULL COMMENT '姓名',
`gender` tinyint NOT NULL COMMENT '性别',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`),
KEY `idx_gender_name` (`gender`,`name`)
) ENGINE=InnoDB COMMENT='用户表';
创建了两个索引,分别是(name)和(gender,name)。
执行一条SQL,看到底用到了哪个索引:
select * from user where gender=0 and name='一灯';

跟期望的一致,优先使用了(gender,name)的联合索引,因为where条件中刚好有gender和name两个字段。
我们把这条SQL传参换一下试试:
select * from user where gender=0 and name='张三';

这次竟然用了(name)上面的索引,同一条SQL因为传参不同,而使用了不同的索引。
到这里,使用现有工具,我们已经无法排查分析,MySQL优化器为什么使用了(name)上的索引,而没有使用(gender,name)上的联合索引。
只能请今天的主角 —optimizer trace(优化器追踪)出场了。
3. 使用optimizer trace
使用optimizer trace查看优化器的选择过程:
SELECT * FROM information_schema.OPTIMIZER_TRACE;

输出结果共有4列:
QUERY 表示我们执行的查询语句
TRACE 优化器生成执行计划的过程(重点关注)
MISSING_BYTES_BEYOND_MAX_MEM_SIZE 优化过程其余的信息会被显示在这一列
INSUFFICIENT_PRIVILEGES 表示是否有权限查看优化过程,0是,1否
接下来我们看一下TRACE列的内容,里面的数据很多,我们重点分析一下range_scan_alternatives结果列,这个结果列展示了索引选择的过程。
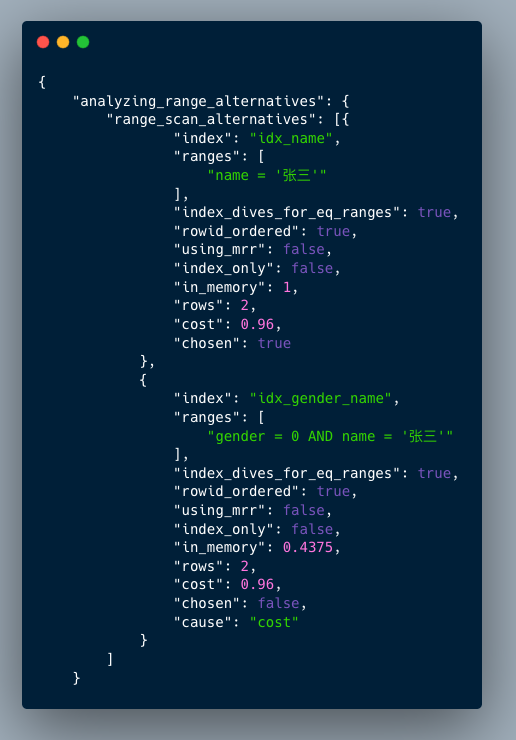
输出结果字段含义:
index 索引名称
ranges 查询范围
index_dives_for_eq_ranges 是否用到索引潜水的优化逻辑
rowid_ordered 是否按主键排序
using_mrr 是否使用mrr
index_only 是否使用了覆盖索引
in_memory 使用内存大小
rows 预估扫描行数
cost 预估成本大小,值越小越好
chosen 是否被选择
cause 没有被选择的原因,cost表示成本过高
从输出结果中,可以看到优化器最终选择了使用(name)索引,而(gender,name)索引因为成本过高没有被使用。
再也不用担心找不到MySQL用错索引的原因,赶紧用起来吧!
文章持续更新,可以微信搜一搜「 一灯架构 」第一时间阅读更多技术干货。

MySQL查询性能优化七种武器之链路追踪的更多相关文章
- MySQL查询性能优化七种武器之索引下推
前面已经讲了MySQL的其他查询性能优化方式,没看过可以去了解一下: MySQL查询性能优化七种武器之索引潜水 MySQL查询性能优化七种武器之链路追踪 今天要讲的是MySQL的另一种查询性能优化方式 ...
- MySQL查询性能优化七种武器之索引潜水
有读者可能会一脸懵逼? 啥是索引潜水? 你给起的名字的吗?有没有索引蛙泳? 这个名字还真不是我起的,今天要讲的知识点就叫索引潜水(Index dive). 先要从一件怪事说起: 我先造点数据复现一下问 ...
- MySQL查询性能优化(精)
MySQL查询性能优化 MySQL查询性能的优化涉及多个方面,其中包括库表结构.建立合理的索引.设计合理的查询.库表结构包括如何设计表之间的关联.表字段的数据类型等.这需要依据具体的场景进行设计.如下 ...
- 170727、MySQL查询性能优化
MySQL查询性能优化 MySQL查询性能的优化涉及多个方面,其中包括库表结构.建立合理的索引.设计合理的查询.库表结构包括如何设计表之间的关联.表字段的数据类型等.这需要依据具体的场景进行设计.如下 ...
- 到底该不该使用存储过程 MySQL查询性能优化一则
到底该不该使用存储过程 看到<阿里巴巴java编码规范>有这样一条 关于这条规范,我说说我个人的看法 用不用存储过程要视所使用的数据库和业务场景而定的,不能因为阿里巴巴的技术牛逼,就视 ...
- MySQL优化技巧之五(mysql查询性能优化)
对于高性能数据库操作,只靠设计最优的库表结构.建立最好的索引是不够的,还需要合理的设计查询.如果查询写得很糟糕,即使库表结构再合理.索引再合适,也无法实现高性能.查询优化.索引优化.库表结构优化需要齐 ...
- MySQL查询性能优化---高性能(二)
转载地址:https://segmentfault.com/a/1190000011330649 避免向数据库请求不需要的数据 在访问数据库时,应该只请求需要的行和列.请求多余的行和列会消耗MySql ...
- 《高性能MySQL》之MySQL查询性能优化
为什么查询会慢? 响应时间过长.如果把查询看做是一个任务,那么它由一系列子任务组成,每个子任务都会消耗一定的时间.如果要优化查询,实际上优化其子任务,要么消除其中一些子任务,要么减少子任务的执行次数, ...
- mysql查询性能优化
mysql查询过程: 客户端发送查询请求. 服务器检查查询缓存,如果命中缓存,则返回结果,否则,继续执行. 服务器进行sql解析,预处理,再由优化器生成执行计划. Mysql调用存储引擎API执行优化 ...
随机推荐
- Python <算法思想集结>之抽丝剥茧聊动态规划
1. 概述 动态规划算法应用非常之广泛. 对于算法学习者而言,不跨过动态规划这道门,不算真正了解算法. 初接触动态规划者,理解其思想精髓会存在一定的难度,本文将通过一个案例,抽丝剥茧般和大家聊聊动态规 ...
- DS18B20数字温度计 (一) 电气特性, 供电和接线方式
目录 DS18B20数字温度计 (一) 电气特性, 供电和接线方式 DS18B20数字温度计 (二) 测温, ROM和CRC校验 DS18B20数字温度计 (三) 1-WIRE总线ROM搜索算法 DS ...
- docker-compose 搭建 Prometheus+Grafana监控系统
有关监控选型之前有写过一篇文章: 监控系统选型,一文轻松搞定! 监控对象 Linux服务器 Docker Redis MySQL 数据采集 1).prometheus: 采集数据 2).node-ex ...
- react native 0.6x 在创建项目时,CocoaPods 的依赖安装步骤卡解决方案
前言 你需要做两件事 gem换源 pod repo 换源 实战 如果你已经成功安装了CocoaPods.那么这里你需要卸载它.gem换源1. 卸载CocoaPods 查看gem安装的东西 gem li ...
- Python Pygal 模块安装和使用你get了吗?
Pygal 是另一个简单易用的数据图库,它以面向对象的方式来创建各种数据图,而且使用 Pygal 可以非常方便地生成各种格式的数据图,包括 PNG.SVG 等.使用 Pygal 也可以生成 XML e ...
- 两分钟解决Python读取matlab的.mat数据
Matlab是学术界非常受欢迎的科学计算平台,matlab提供强大的数据计算以及仿真功能.在Matlab中数据集通常保存为.mat格式.那么如果我们想要在Python中加载.mat数据应该怎么办呢?所 ...
- 『现学现忘』Git后悔药 — 30、版本回退git reset --hard命令说明
git reset --hardcommit-id命令:回退到指定版本.(hard:强硬,严格的回退) 该命令不仅移动了分支中HEAD指针的位置,还将工作区和暂存区中数据也回退到了指定的版本. (提示 ...
- Aborted wiping of zfs_member.1 existing signature left on the device.Aborting pvcreate on /dev/sda
看意思是有什么签名在上面,创建不了逻辑卷,确认数据备份的情况下执行对应的下面命令: wipefs --all --force /dev/sdax
- Reading configuration from: /usr/local/src/zookeeper/apache-zookeeper-3.6.3-bin/bin/../conf/zoo.cfg
2021-04-25 00:15:48,112 [myid:] - INFO [main:QuorumPeerConfig@174] - Reading configuration from: /u ...
- 10 MySQL_字符串函数和数学函数
字符串函数 1. 字符串拼接 concat('aa','bb') ->aabb; 查询emp表中 员工姓名 和工资 工资后面显示单位元 select name,concat(sal,'元') f ...