whylogs工具库的工业实践!机器学习模型流程与效果监控 ⛵

作者:韩信子@ShowMeAI
机器学习实战系列:https://www.showmeai.tech/tutorials/41
本文地址:https://www.showmeai.tech/article-detail/395
声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容
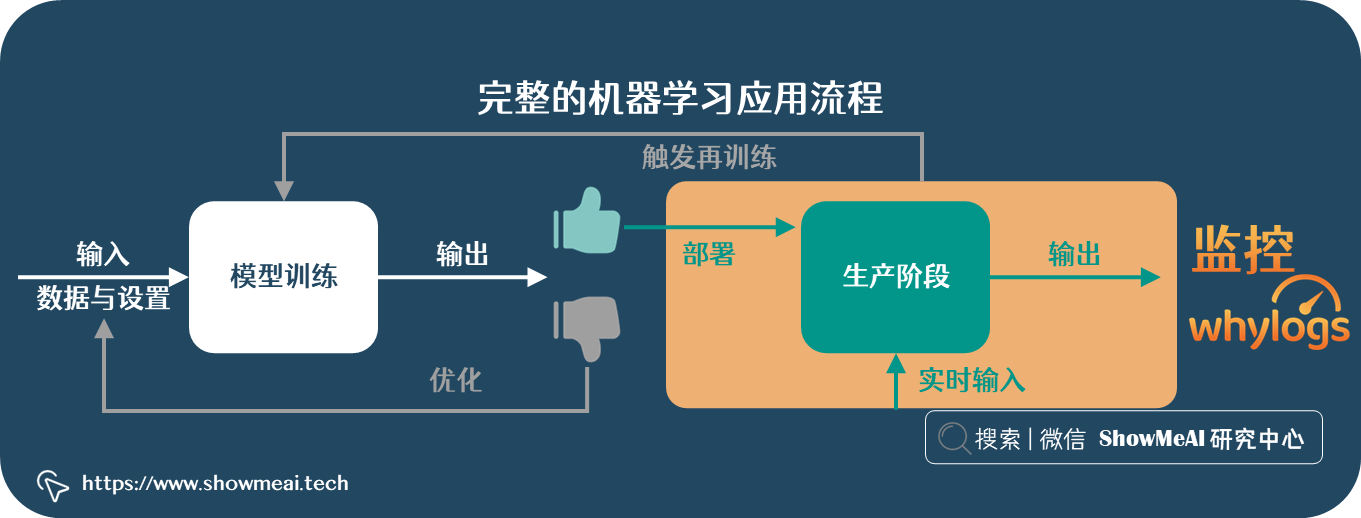
完整的机器学习应用过程,除了数据处理、建模优化及模型部署,也需要进行后续的效果验证跟踪和ML模型监控——它能保证模型和场景是保持匹配且有优异效果的。
模型上线后,可能会存在效果下降等问题,面临数据漂移等问题。详见ShowMeAI的文章 机器学习数据漂移问题与解决方案。

ShowMeAI在这篇文章中,将给大家展示如何使用开源工具库 whylogs 构建详尽的 AI 日志平台并监控 ML 模型。

日志系统&模型监控
环境配置
要构建日志系统并进行模型监控,会使用到开源数据日志库whylogs,它可以用于捕获数据的关键统计属性。安装方式很简单,执行下列 pip 命令即可
pip install "whylogs[whylabs]"
接下来,导入所用的工具库whylogs、pandas和os。我们也创建一份 Dataframe 数据集进行分析。
import whylogs as why
import pandas as pd
import os
# create dataframe with dataset
dataset = pd.read_csv("https://whylabs-public.s3.us-west-2.amazonaws.com/datasets/tour/current.csv")
使用 whylogs 创建的数据配置文件可以单独用于数据验证和数据漂移可视化,简单的示例如下:
import whylogs as why
import pandas as pd
#dataframe
df = pd.read_csv("path/to/file.csv")
results = why.log(df)
这里也讲解一下云端环境,即把配置文件写入 WhyLabs Observatory 以执行 ML 监控。
为了向 WhyLabs 写入配置文件,我们将 创建一个帐户(免费)并获取组织 ID、Key和项目 ID,以将它们设置为项目中的环境变量。
# Set WhyLabs access keys
os.environ["WHYLABS_DEFAULT_ORG_ID"] = 'YOURORGID'
os.environ["WHYLABS_API_KEY"] = 'YOURACCESSTOKEN'
os.environ["WHYLABS_DEFAULT_DATASET_ID"] = 'PROJECTID'
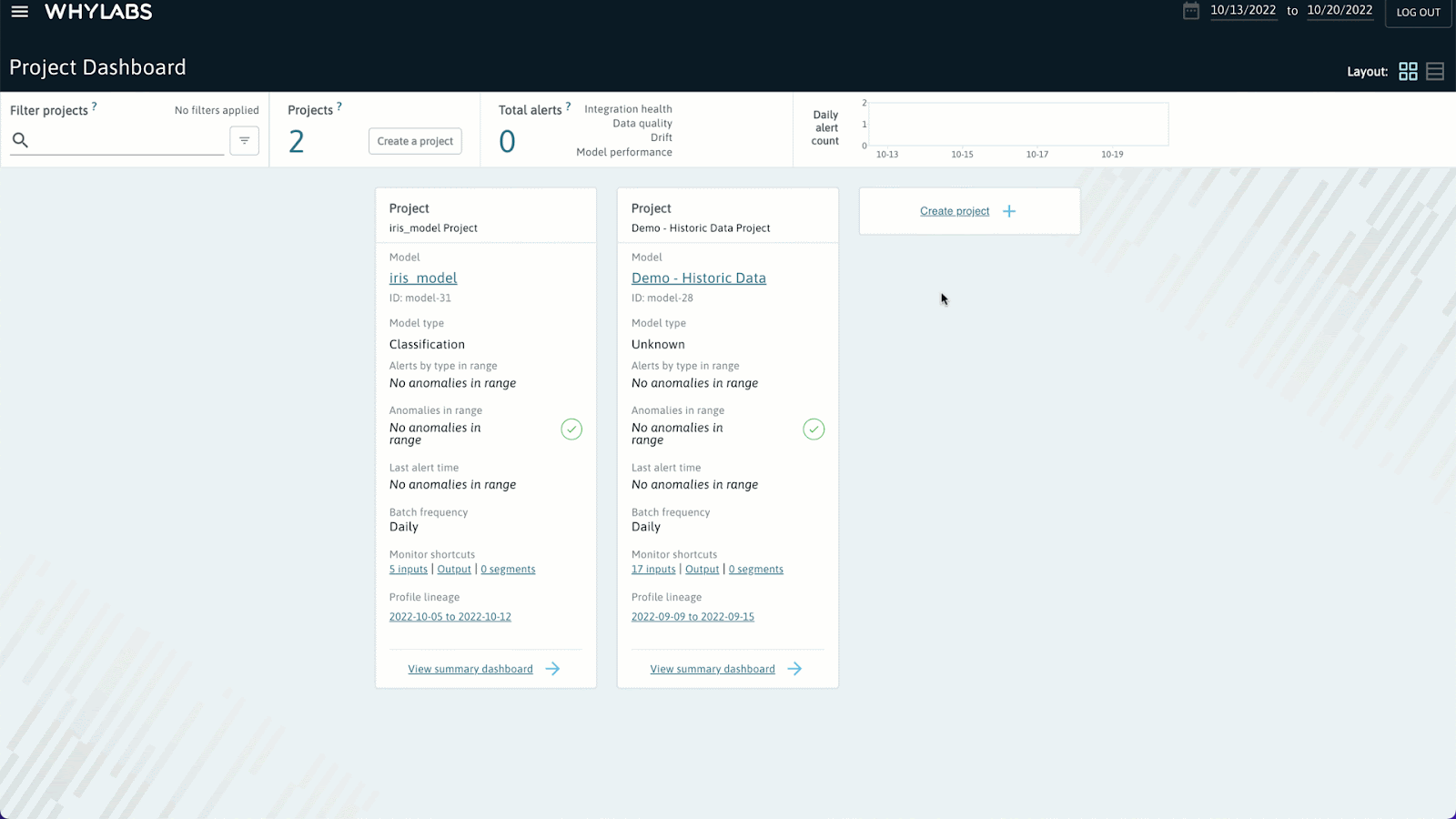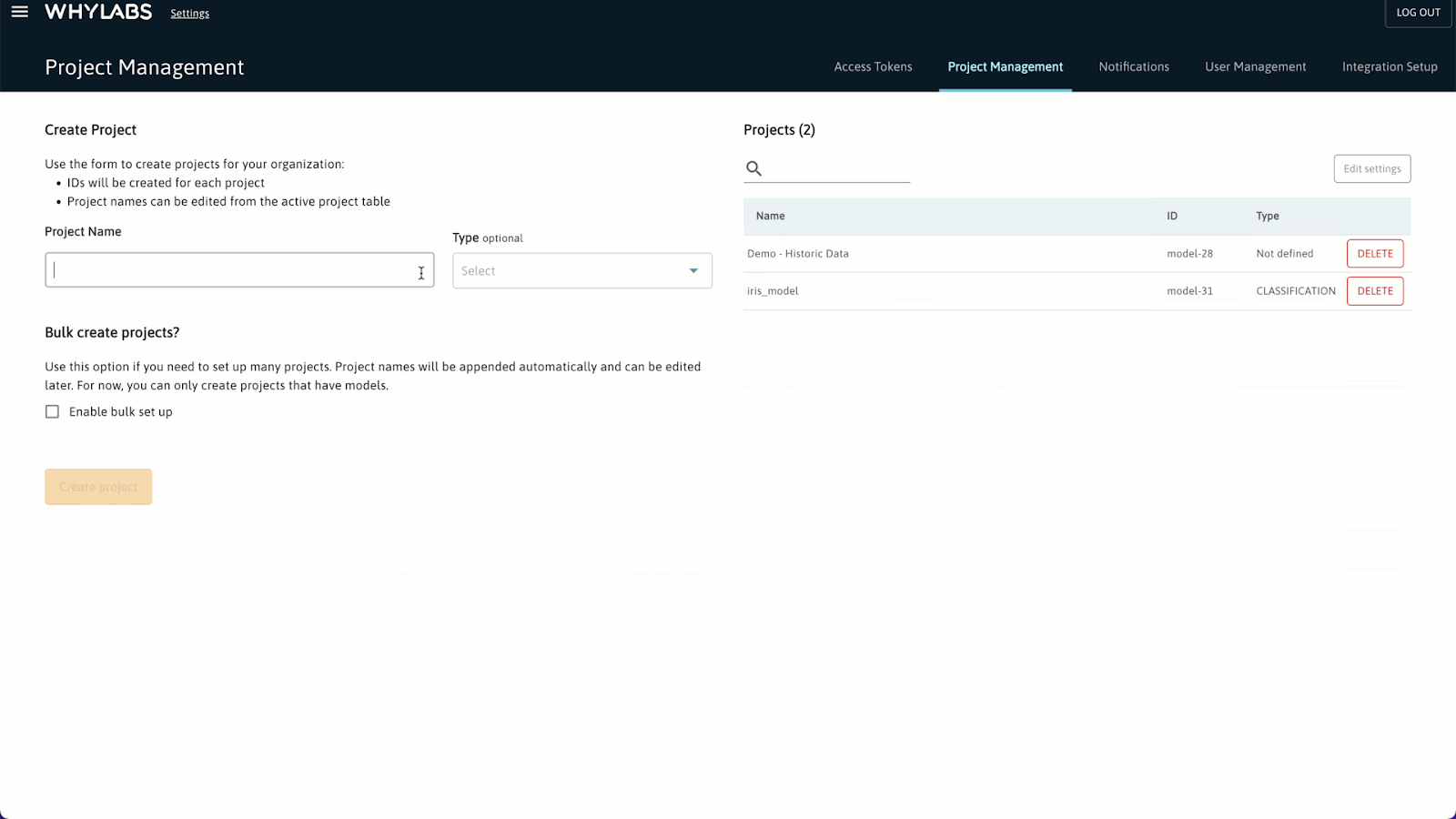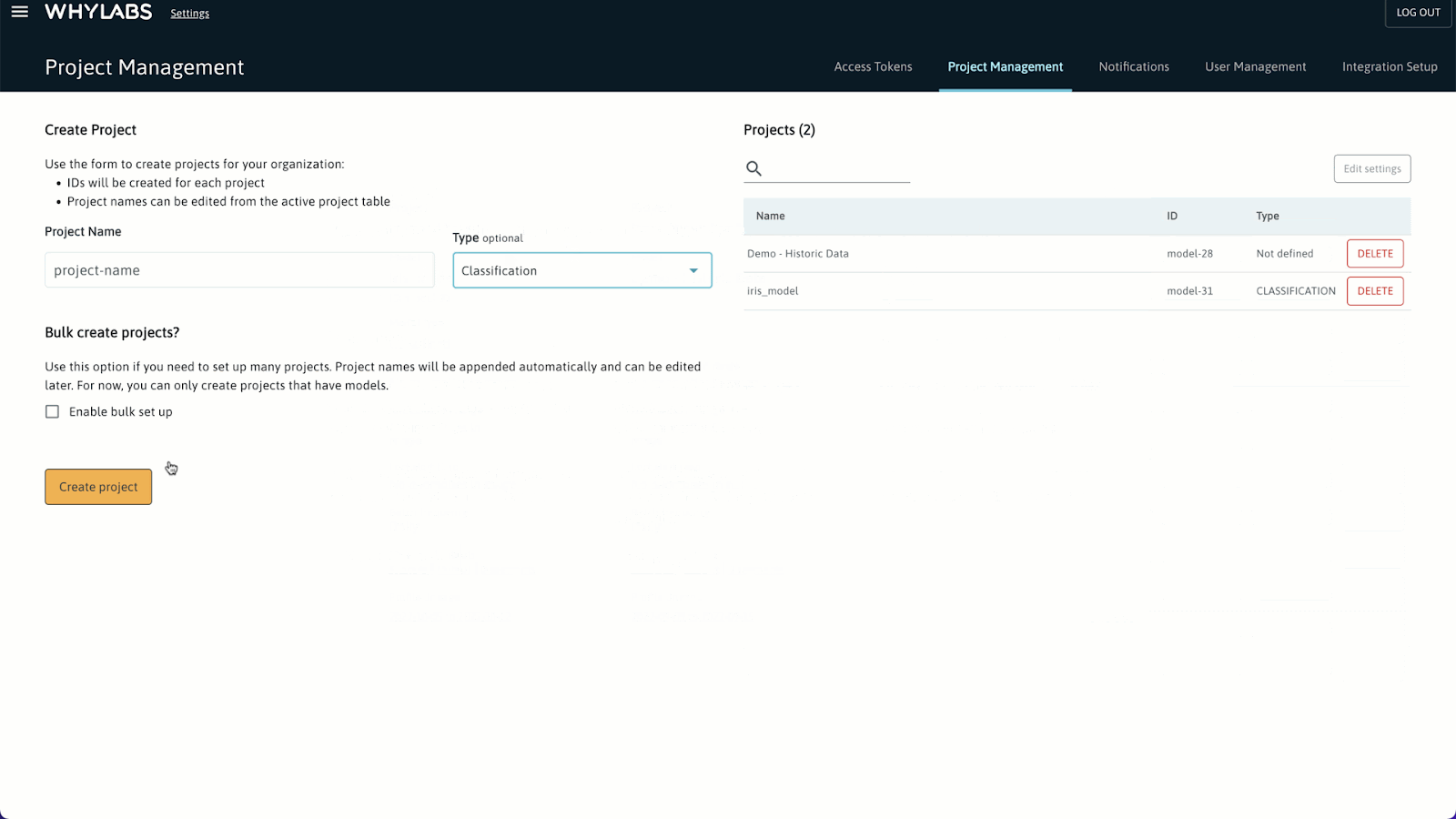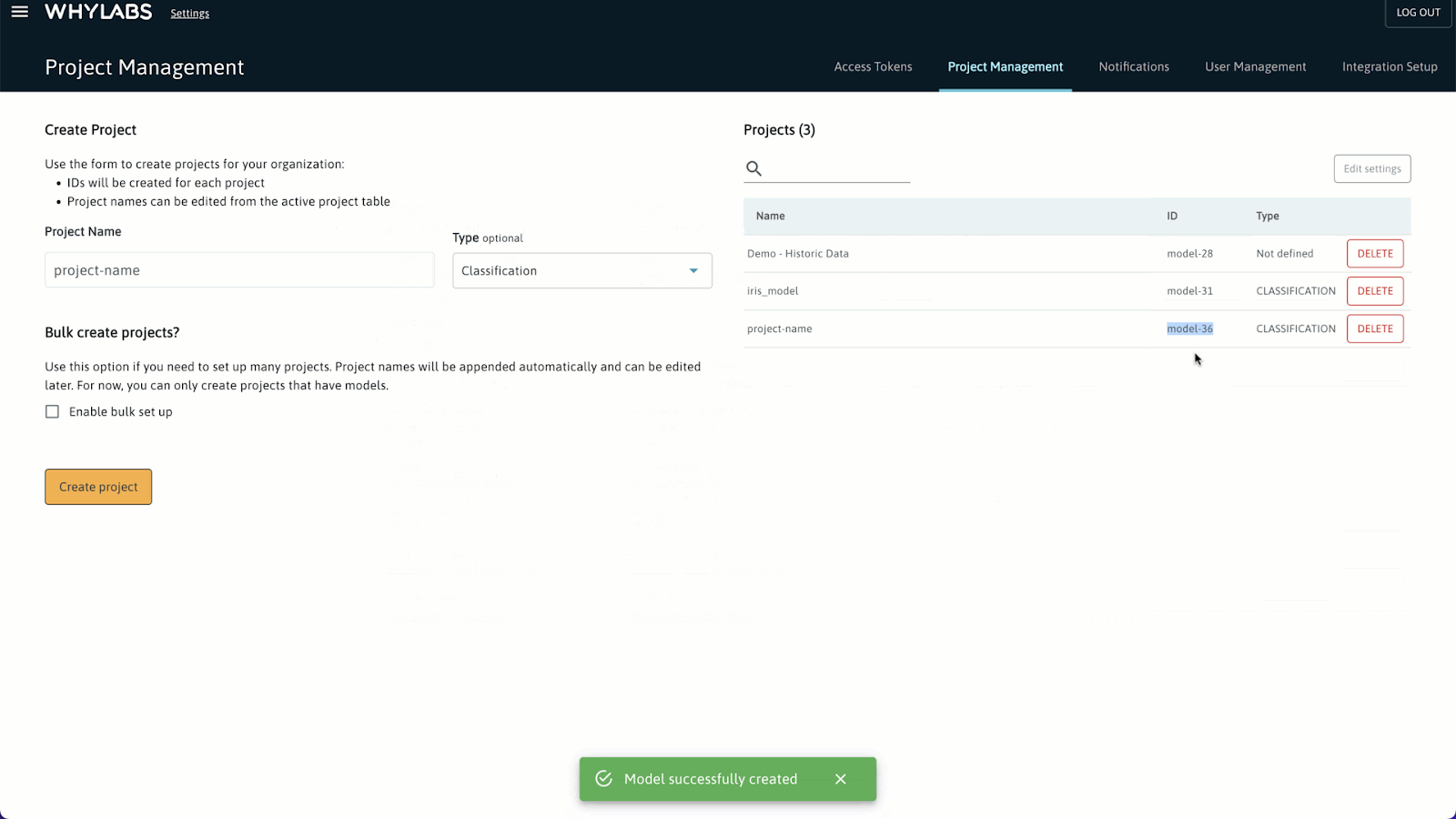
新建项目并获取 ID
Create Project > Set up model > Create Project,整个操作过程如下图所示:
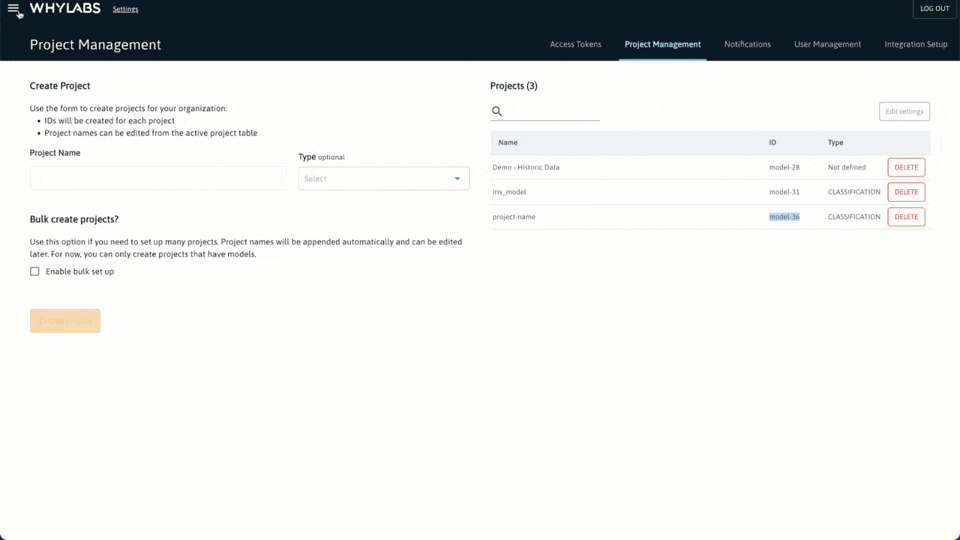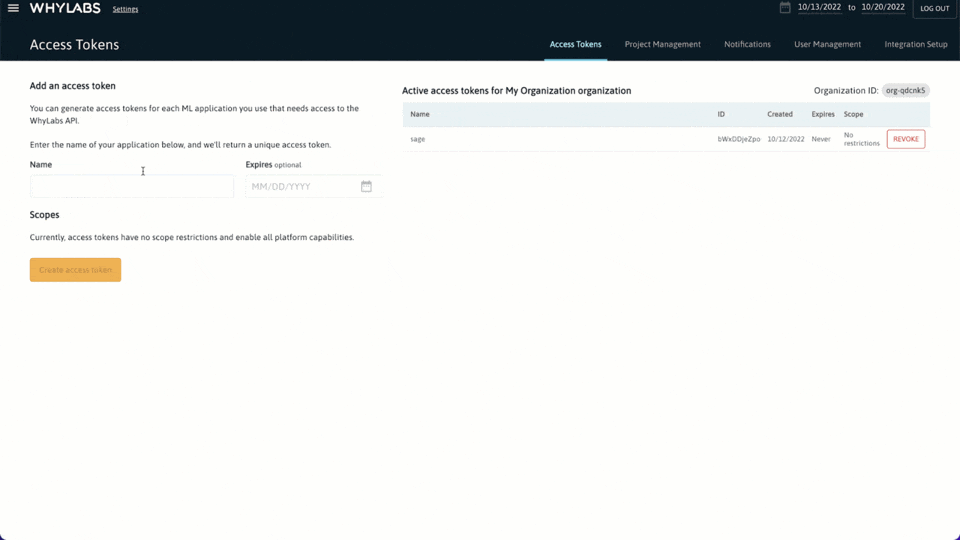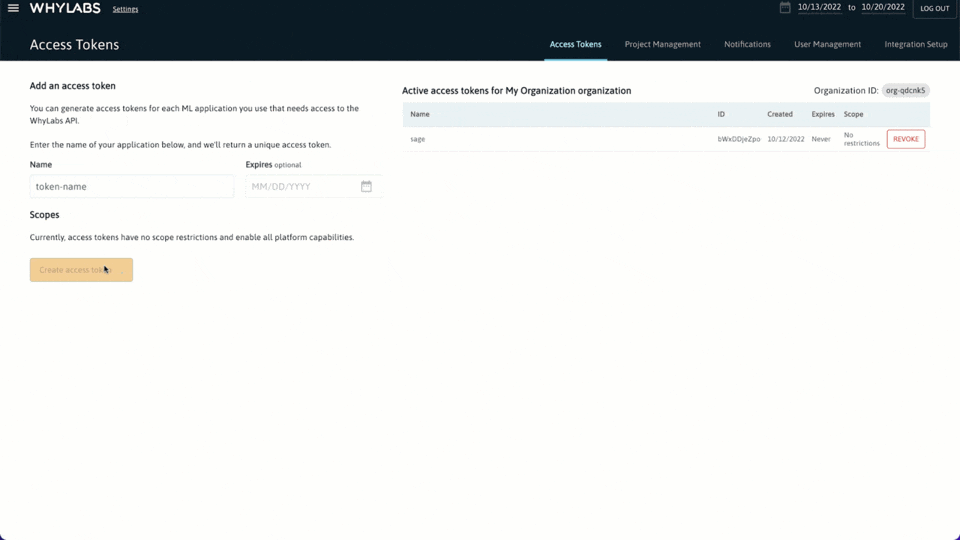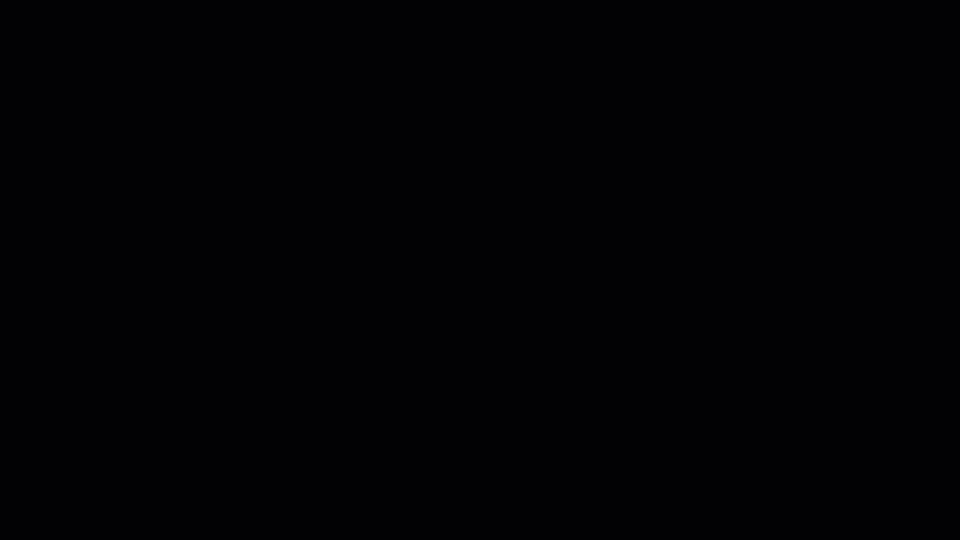
获取组织 ID 和访问 Key
菜单 > 设置 > 访问令牌 > 创建访问令牌,如下图所示:
经过这个配置,接下来就可以将数据配置文件写入 WhyLabs。
将配置文件写入 WhyLabs 以进行 ML 监控
设置访问密钥后,可以轻松创建数据集的配置文件并将其写入 WhyLabs。这使我们只需几行代码即可监控输入数据和模型预测!
# initial WhyLabs writer, Create whylogs profile, write profile to WhyLabs
writer = WhyLabsWriter()
profile= why.log(dataset)
writer.write(file=profile.view())
我们可以在 pipeline 管道的任何阶段创建配置文件,也就是说可以对每个步骤的数据进行监控。一旦完成将配置文件写入 WhyLabs,就可以检查、比较和监控数据质量和数据漂移。
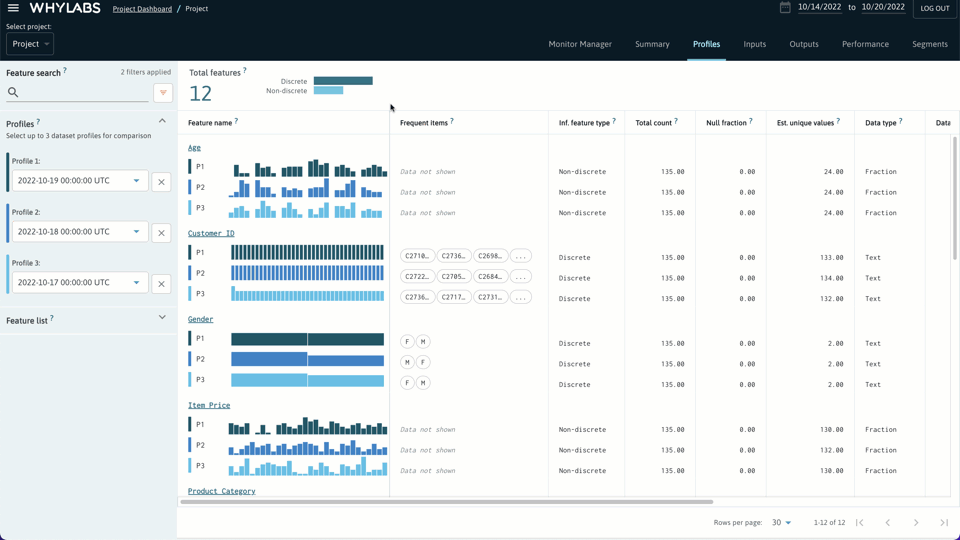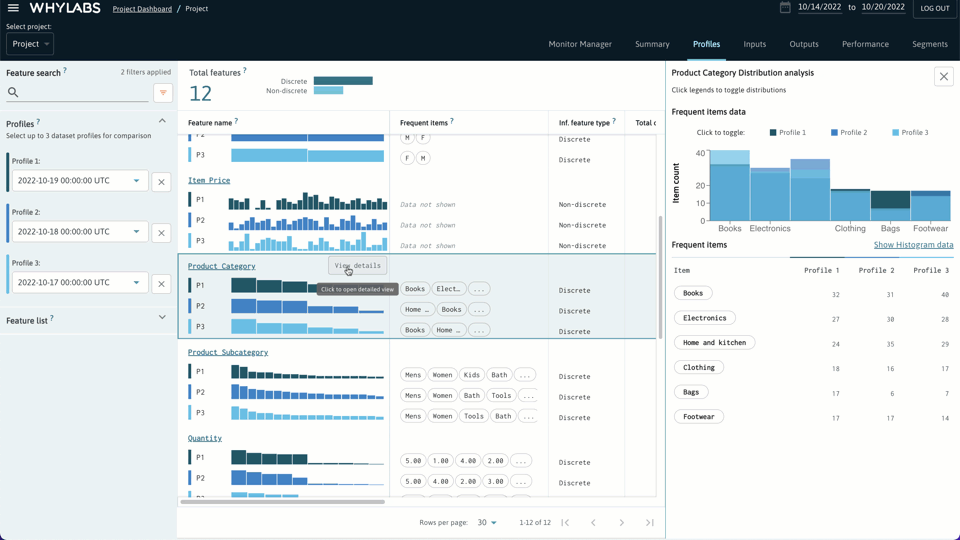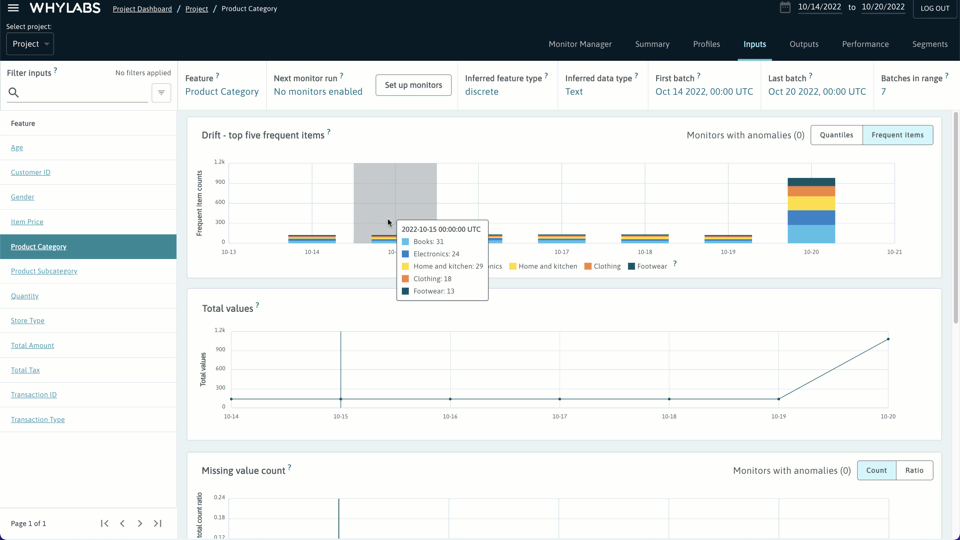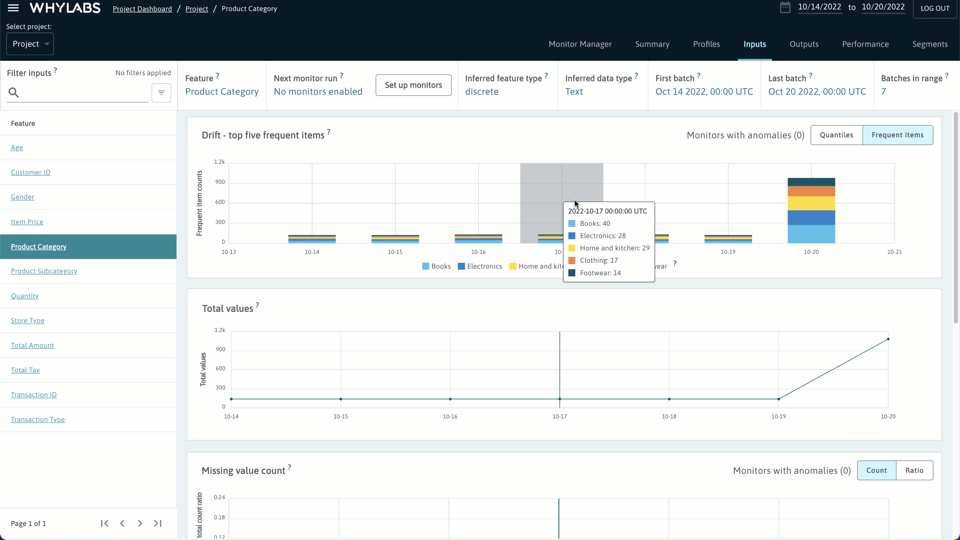
上述步骤过后,只需单击一下(或创建自定义监视器)即可启用预配置的监视器,检测数据配置文件中的异常情况。设置常见的监控任务是非常容易的,也可以很清晰快捷地检测数据漂移、数据质量问题和模型性能。
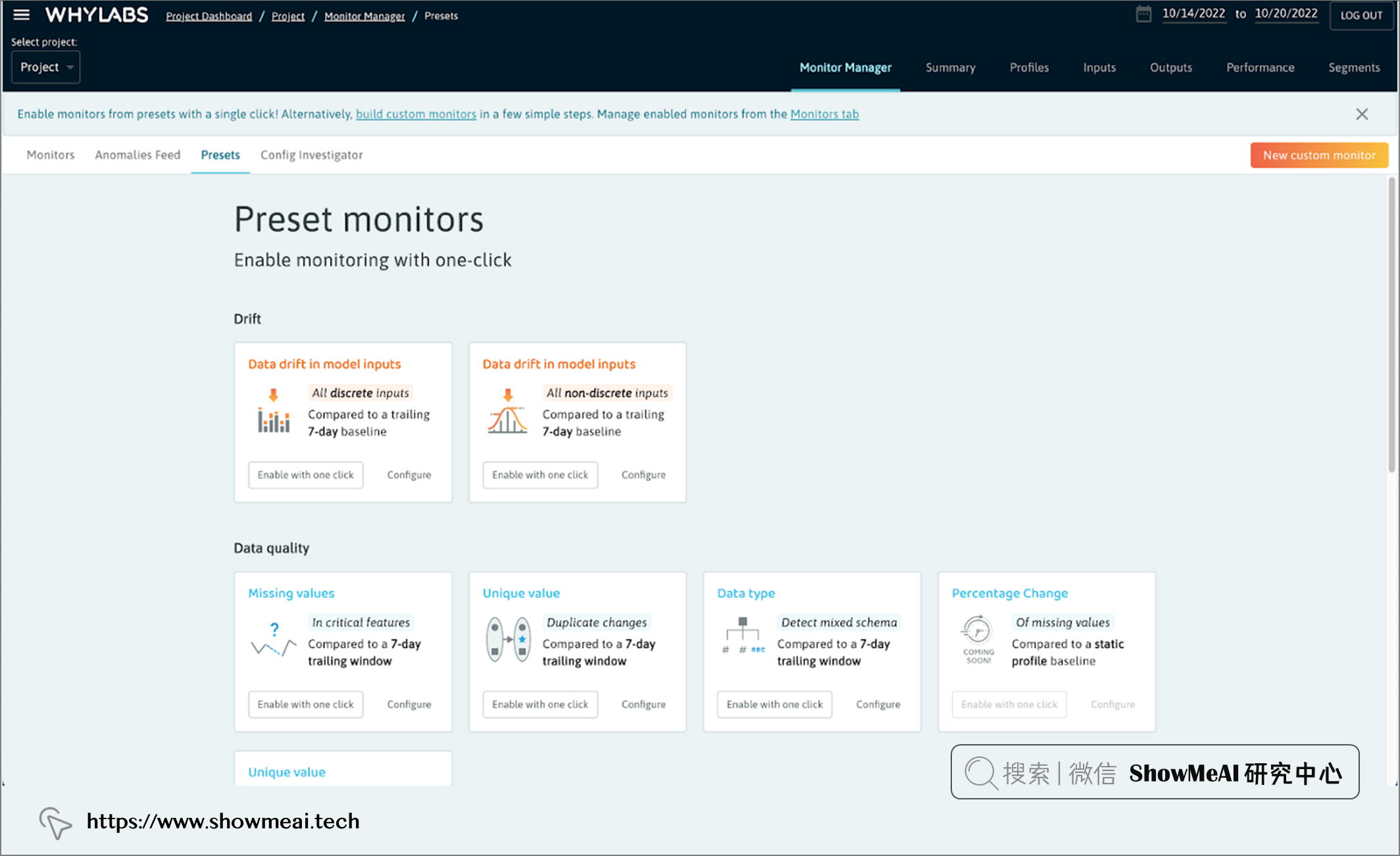
配置监视器后,可以在检查输入功能时对其进行预览。
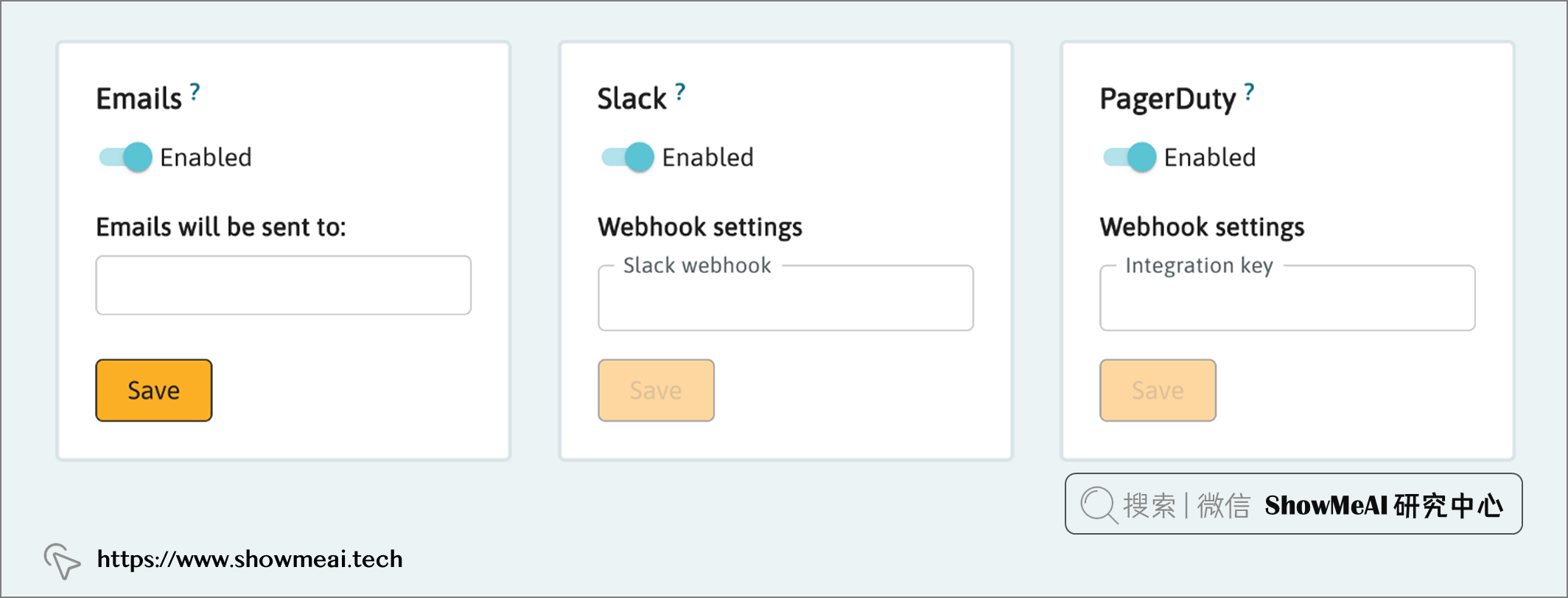
当检测到异常时,可以通过电子邮件、Slack 或 PagerDuty 发送通知。在设置 > 通知和摘要设置中设置通知首选项。
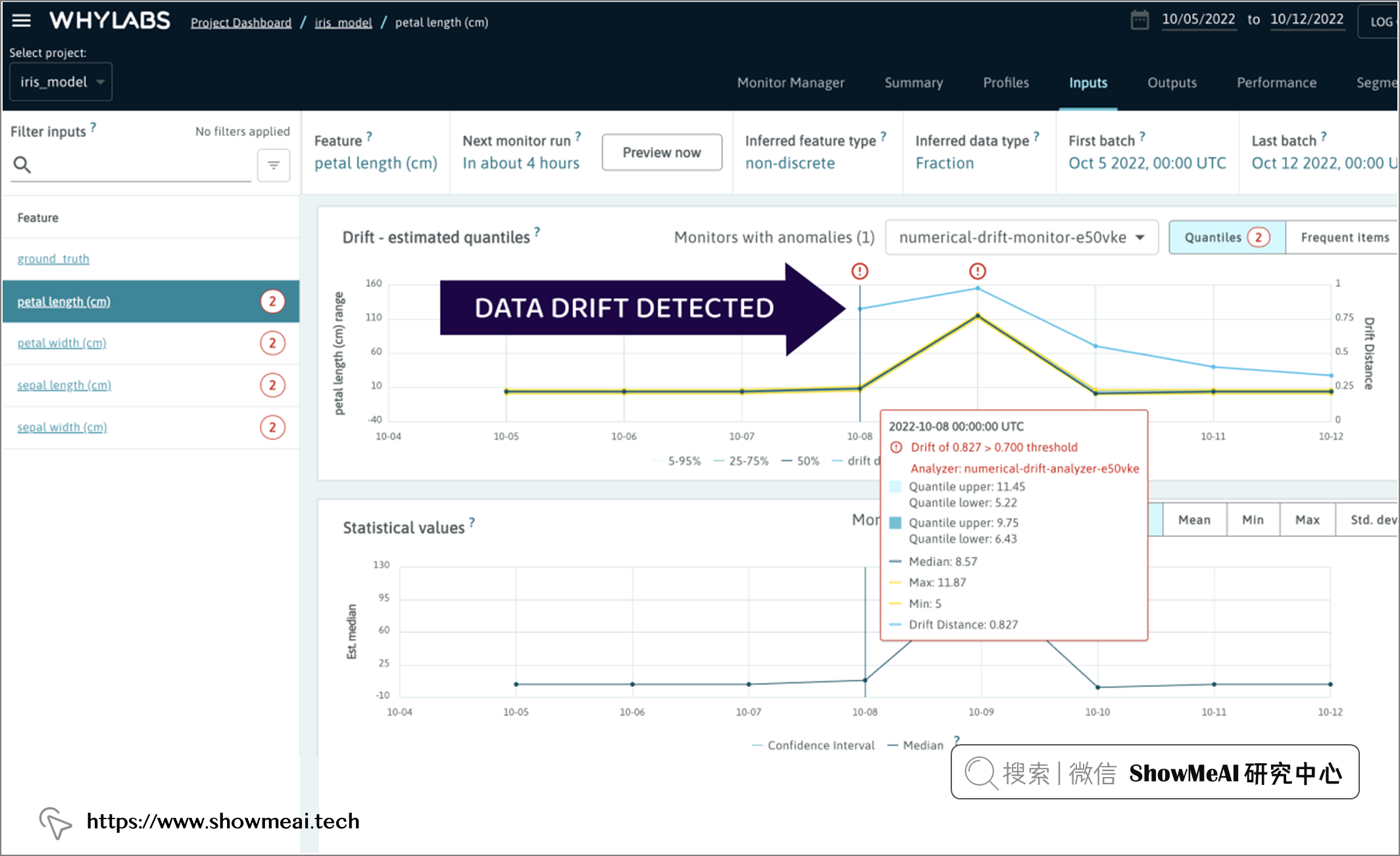
上述这些简单的步骤,我们已经完成了从 ML 管道中的任何步骤提取数据、构建日志和监控分析,并在发生异常时得到通知。
监控模型性能指标
前面看到了如何监控模型输入和输出数据,我们还可以通过在预测结果来监控性能指标,例如准确度、精确度等。
要记录用于监控的性能指标,可以使用why.log_classification_metrics或why.log_regression_metrics并传入包含模型输出结果的 Dataframe。
results = why.log_classification_metrics(
df,
target_column = "ground_truth",
prediction_column = "cls_output",
score_column="prob_output"
)
profile = results.profile()
results.writer("whylabs").write()
注意:确保您的项目在设置中配置为分类或回归模型。
在下面的示例笔记本中查看用于性能监控的数据示例。
大家想获得更多关于监控的示例 notebook 笔记本,可以查看官方 GitHub 关于 分类和 回归的代码。
参考资料
- 机器学习数据漂移问题与解决方案:https://www.showmeai.tech/article-detail/331
- whylogs:https://github.com/whylabs/whylogs
推荐阅读
- 数据分析实战系列 :https://www.showmeai.tech/tutorials/40
- 机器学习数据分析实战系列:https://www.showmeai.tech/tutorials/41
- 深度学习数据分析实战系列:https://www.showmeai.tech/tutorials/42
- TensorFlow数据分析实战系列:https://www.showmeai.tech/tutorials/43
- PyTorch数据分析实战系列:https://www.showmeai.tech/tutorials/44
- NLP实战数据分析实战系列:https://www.showmeai.tech/tutorials/45
- CV实战数据分析实战系列:https://www.showmeai.tech/tutorials/46
- AI 面试题库系列:https://www.showmeai.tech/tutorials/48
whylogs工具库的工业实践!机器学习模型流程与效果监控 ⛵的更多相关文章
- 25个Java机器学习工具&库--转载
本列表总结了25个Java机器学习工具&库: 1. Weka集成了数据挖掘工作的机器学习算法.这些算法可以直接应用于一个数据集上或者你可以自己编写代码来调用.Weka包括一系列的工具,如数据预 ...
- 【转】.NET(C#):浅谈程序集清单资源和RESX资源 关于单元测试的思考--Asp.Net Core单元测试最佳实践 封装自己的dapper lambda扩展-设计篇 编写自己的dapper lambda扩展-使用篇 正确理解CAP定理 Quartz.NET的使用(附源码) 整理自己的.net工具库 GC的前世与今生 Visual Studio Package 插件开发之自动生
[转].NET(C#):浅谈程序集清单资源和RESX资源 目录 程序集清单资源 RESX资源文件 使用ResourceReader和ResourceSet解析二进制资源文件 使用ResourceM ...
- java25个Java机器学习工具&库
本列表总结了25个Java机器学习工具&库: 1. Weka集成了数据挖掘工作的机器学习算法.这些算法可以直接应用于一个数据集上或者你可以自己编写代码来调用.Weka包括一系列的工具,如数据预 ...
- 机器学习模型解释工具-Lime
本篇文章转载于LIME:一种解释机器学习模型的方法 该文章介绍了一种模型对单个样本解释分类结果的方法,区别于对整体测试样本的评价指标准确率.召回率等,Lime为具体某个样本的分类结果做出解释,直观地表 ...
- scikit-learn系列之如何存储和导入机器学习模型
scikit-learn系列之如何存储和导入机器学习模型 如何存储和导入机器学习模型 找到一个准确的机器学习模型,你的项目并没有完成.本文中你将学习如何使用scikit-learn来存储和导入机器 ...
- Java第三方工具库/包汇总
一.科学计算或矩阵运算库 科学计算包: JMathLib是一个用于计算复杂数学表达式并能够图形化显示计算结果的Java开源类库.它是Matlab.Octave.FreeMat.Scilab的一个克隆, ...
- 斯坦福经典AI课程CS 221官方笔记来了!机器学习模型、贝叶斯网络等重点速查...
[导读]斯坦福大学的人工智能课程"CS 221"至今仍然是人工智能学习课程的经典之一.为了方便广大不能亲临现场听讲的同学,课程官方推出了课程笔记CheatSheet,涵盖4大类模型 ...
- TensorFlow?PyTorch?Paddle?AI工具库生态之争:ONNX将一统天下
作者:韩信子@ShowMeAI 深度学习实战系列:https://www.showmeai.tech/tutorials/42 本文地址:https://www.showmeai.tech/artic ...
- [转]Android开源项目第二篇——工具库篇
本文为那些不错的Android开源项目第二篇--开发工具库篇,主要介绍常用的开发库,包括依赖注入框架.图片缓存.网络相关.数据库ORM建模.Android公共库.Android 高版本向低版本兼容.多 ...
- Android开源项目第二篇——工具库篇
本文为那些不错的Android开源项目第二篇——开发工具库篇,**主要介绍常用的开发库,包括依赖注入框架.图片缓存.网络相关.数据库ORM建模.Android公共库.Android 高版本向低版本兼容 ...
随机推荐
- 在Ubuntu上安装Odoo时遇到的问题
这两天开始看<Odoo快速入门与实践 Python开发ERP指南>(刘金亮 2019年5月第1版 机械工业出版社).试着在Ubuntu上安装Odoo,遇到很多问题,通过在网上查找,都已解 ...
- 前端 vue表格数据导出Excel 文件实现
实现思路 使用json2csv将后台json数据转化为csv格式数据 采用创建Blob(二进制大对象)的方式来存放缓存数据: 生成下载链接: 创建一个a标签,设置href和download属性 触发a ...
- 12.第十一篇 安装docker引擎
文章转载自:https://mp.weixin.qq.com/s?__biz=MzI1MDgwNzQ1MQ==&mid=2247483838&idx=1&sn=5a13aed5 ...
- CentOS7部署FastDFS+nginx模块
软件下载 # 已经事先把所需软件下载好并上传到/usr/local/src目录了 https://github.com/happyfish100/libfastcommon/archive/V1.0. ...
- tcp_tw_recycle参数引发的系统问题
文章转载自: https://blog.csdn.net/zhuyiquan/article/details/68925707
- Linux恢复误删除的文件或者目录
文章转载自:https://www.jianshu.com/p/662293f12a47 linux不像windows有个回收站,使用rm -rf *基本上文件是找不回来的. 那么问题来了: 对于li ...
- PVC-U排水管及管件
- AgileBoot - 基于SpringBoot + Vue3的前后端快速开发脚手架
AgileBoot 仓库 后端地址:https://github.com/valarchie/AgileBoot-Back-End 技术栈:Springboot / Spring Security / ...
- day10-习题
习题 1.Homework01 (1) D -- 没有在别名上加引号(ps:别名的as可以省略) (2) B -- 判断null或非空不能用不等于号 (3) C 2.Homework02 写出查看de ...
- TCP 序列号和确认号是如何变化的?
大家好,我是小林. 在网站上回答了很多人的问题,我发现很多人对 TCP 序列号和确认号的变化都是懵懵懂懂的,只知道三次握手和四次挥手过程中,ACK 报文中确认号要 +1,然后数据传输中 TCP 序列号 ...