Elasticsearch 主从同步之跨集群复制
文章转载自:https://mp.weixin.qq.com/s/alHHxXont6XFm_m9PfsGfw
1、什么是跨集群复制?
跨集群复制(Cross-cluster replication,简称:CCR)指的是:索引数据从一个 Elasticsearch 集群复制到另一个 Elasticsearch 集群。
对于主集群的索引数据的任何修改都会直接复制同步到从索引集群。
2、跨集群复制最早发布版本
Elasticsearch 6.7 版本。
3、跨集群复制的好处?
3.1 支持灾难恢复(DR)、确保高可用性(HA)
跨集群复制确保了不间断的服务可用性,能够承受住数据中心或区域服务中断的影响,降低了复杂性、节省了成本。
3.2 降低延迟
将数据复制到更靠近应用程序用户的集群可以最大限度地减少查询延迟。
3.3 水平可扩展性
跨多个副本集群拆分查询繁重的工作负载可提高应用程序可用性。
3.4 集中式汇报
企业客户可以将属于不同业务线的较小集群(数百个分支银行中心)中的报告不断汇总到一个中央集群(大型全球银行)中,以用于整合报告、方便可视化呈现。
PS:关于高可用,读者可能会有疑惑?
● 副本的目的是高可用,集群的快照和恢复和功能是高可用,怎么又来个跨集群复制呢?
副本主要体现在分片层面,可以看做分片的复制,一般集群至少设置一个副本,当主副本故障时,副本分片会提升为主分片。
● 快照和恢复主要体现在:集群级别和索引层面,可以全量或者增量。但,做不到实时备份和恢复。也就是说,快照会设定一个时间间隔,比如每 5 分钟备份一次。
当集群出现故障需要恢复时,极有可能会少备份最近 5 分钟的数据,
综上,才会有了跨集群复制的概念。
4、跨集群复制的核心概念
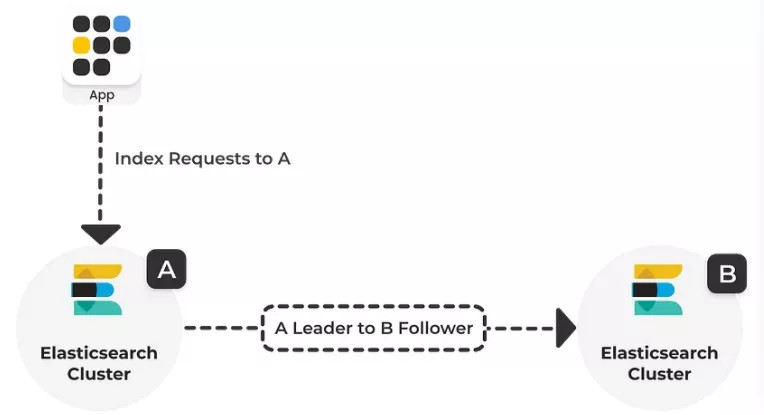
跨集群复制使用主动-被动模型(active-passive model)。
数据索引到一个领导者索引(leader index),并且数据被复制到一个或多个只读跟随者索引(read-only follower indices)。在向集群添加跟随者索引之前,必须配置包含领导者索引的远程集群。
leader-follower 模式在 kafka、zookeeper等中都有涉及,我认为翻译为:主、从模型比较契合。
核心释义解读如下:
- active-passive model:主动-被动模型。
- leader index:主索引或领导者索引。
- read-only follower indices:从索引或跟随者索引。
5、跨集群复制的设计原则
5.1 高安全性
跨集群复制应该为所有数据流和 API 提供强大的安全控制。
5.2 准确性
跟随者索引和领导者索引的预期内容之间必须没有差异。
5.3 高性能
复制不应影响领导集群的索引率(数据写入速率)。
5.4 最终一致性
领导者和跟随者集群之间的复制延迟应该在几秒钟之内。
5.5 资源使用率低
复制应该使用最少的资源。
6、跨集群复制的实战一把
6.1 必备前置条件
6.1.1 前置条件1:激活License

CCR 是白金版付费功能,需要激活 30 天的 License,如果仅学习了解功能,建议先试用。
6.1.2 前置条件2:备好至少 2 个集群
跨集群复制,核心是“跨”和“复制”。
“跨”体现在至少得两个集群,否则没有意义。
最简单模型如图所示,我们用一台宿主机搭建两套集群环境,如下所示:
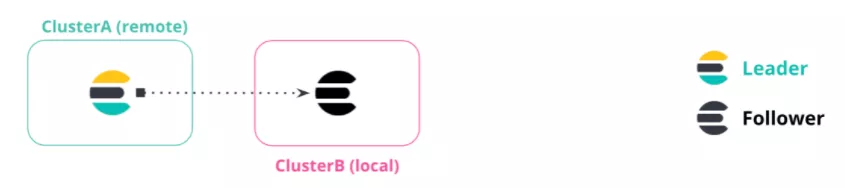
● 集群A:远端集群,remote cluster leader
Elasticsearch: 172.21.0.14:19203
kibana:172.21.0.14:5613
● 集群B:本地集群,local cluster follower
Elasticsearch: 172.21.0.14:19202
kibana:172.21.0.14:5612
6.1.3前置配置:开启软删除
7.0+之后版本已默认开启,无需单独配置。
早期版本,需参考官方文档进行静态配置,需要修改配置文件实现。
index.soft_deletes.enabled:true
跨集群复制的工作原理是:重放对 leader 索引分片执行的单个写入操作的历史记录。
Elasticsearch 需要在 leader 分片上保留这些操作的历史记录,以便它们可以被 follower 分片任务拉取。用于保留这些操作的底层机制是软删除。
6.1.4 前置配置:xpack 设置true
因为需要配置角色、权限等,Elasitcsearch 设置了xpack,就意味着 kibana 端需要设置账号、密码。
在 elasticsearch.yml 文件中添加如下配置。
xpack.security.enabled: true
通过:./elasticsearch-setup-passwords 命令行工具实现用户名和密码的设置。
auto 自动设置的结果参考如下:
./elasticsearch-setup-passwords auto
Changed password for user apm_system
PASSWORD apm_system = m5ob2a8OvoKuYpPPsiRd
Changed password for user kibana_system
PASSWORD kibana_system = xwdrhpVPSsbxxY1l0b50
Changed password for user kibana
PASSWORD kibana = xwdrhpVPSsbxxY1l0b50
Changed password for user logstash_system
PASSWORD logstash_system = 1zweZhAVEnqwh1flHBkz
Changed password for user beats_system
PASSWORD beats_system = 7Fo3bvmLISshjvHXTqAY
Changed password for user remote_monitoring_user
PASSWORD remote_monitoring_user = EvB4FkFs88gsCP073YGt
Changed password for user elastic
PASSWORD elastic = c7KmLqGTm6cyl2ABJPBY
否则会报错如下:
{
"error" : {
"root_cause" : [
{
"type" : "exception",
"reason" : "Security must be explicitly enabled when using a [trial] license. Enable security by setting [xpack.security.enabled] to [true] in the elasticsearch.yml file and restart the node."
}
],
"type" : "exception",
"reason" : "Security must be explicitly enabled when using a [trial] license. Enable security by setting [xpack.security.enabled] to [true] in the elasticsearch.yml file and restart the node."
},
"status" : 500
}
6.2 跨集群复制完整设置步骤
6.2.1 步骤1:从集群设置 remote cluster
在从集群上配置包含主索引的远程集群(remote cluster)
其实看到:remote cluster,第一时间要想到:跨集群检索(CCR)也需要配置它。
从集群配置主集群 leader,参考如下:
PUT /_cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"leader": {
"seeds": [
"172.21.0.14:19303"
]
}
}
}
}
}
从集群监测一下remote配置是否成功。
GET /_remote/info
检测是否配置成功。
6.2.2 步骤2:配置权限
为跨集群复制配置权限。
跨集群复制用户在远程集群和本地集群上需要不同的集群和索引权限。
使用以下请求在本地和远程集群上创建单独的角色,然后创建具有所需角色的用户。
6.2.2.1 remote 集群配置权限
前置条件:设置 xpack 为 true,kibana 端配置账号和密码。
POST /_security/role/remote-replication
{
"cluster": [
"read_ccr"
],
"indices": [
{
"names": [
"kibana_sample_data_logs"
],
"privileges": [
"monitor",
"read"
]
}
]
}
6.2.2.2 local 集群配置权限
在本地集群上创建从索引。
POST /_security/role/remote-replication
{
"cluster": [
"manage_ccr"
],
"indices": [
{
"names": [
"kibana_sample_data_logs_follower"
],
"privileges": [
"monitor",
"read",
"write",
"manage_follow_index"
]
}
]
}
6.2.3 步骤3:创建自动跟踪模式以自动跟踪在远程集群中创建的索引
可以使用 Kibana 图形化界面配置或者命令行配置。
位置:Stack Management->Data->Cross-Cluster Replication。
步骤1:创建 follower index。
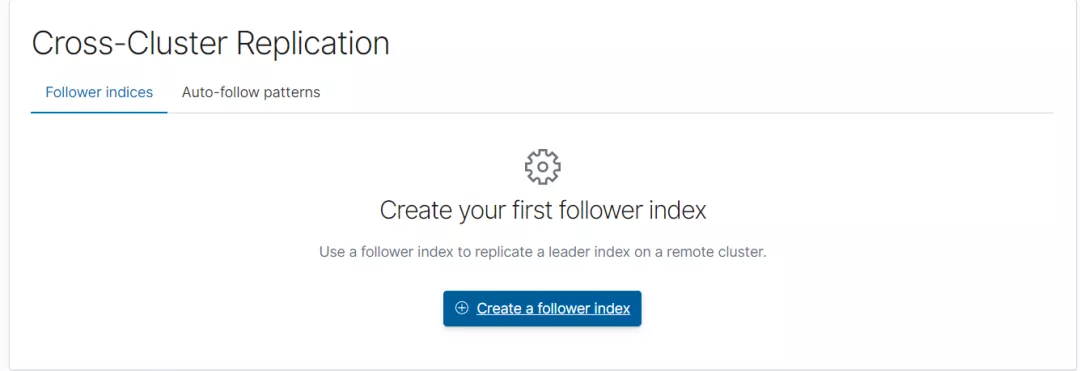
步骤2:配置 follower index。

需要设置如下:
- Remote cluster, 从集群对leader 的设置。
- Leader index,主集群的索引。
- Follower index,从集群的索引名称,与 Leader index 是一一对应的关系,是从 Leader 索引复制过来的数据。
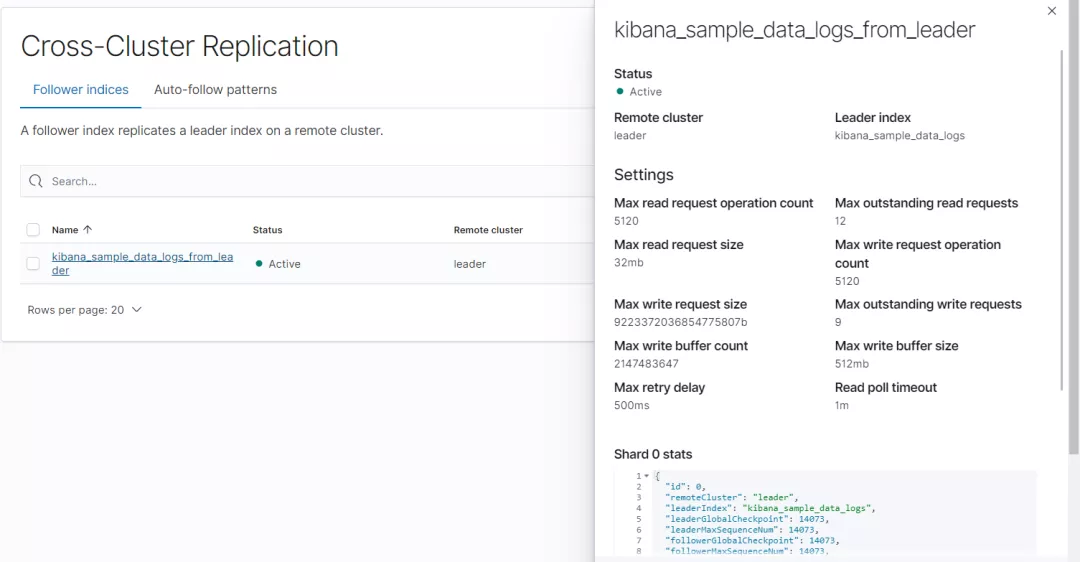
执行成功后截图如下:
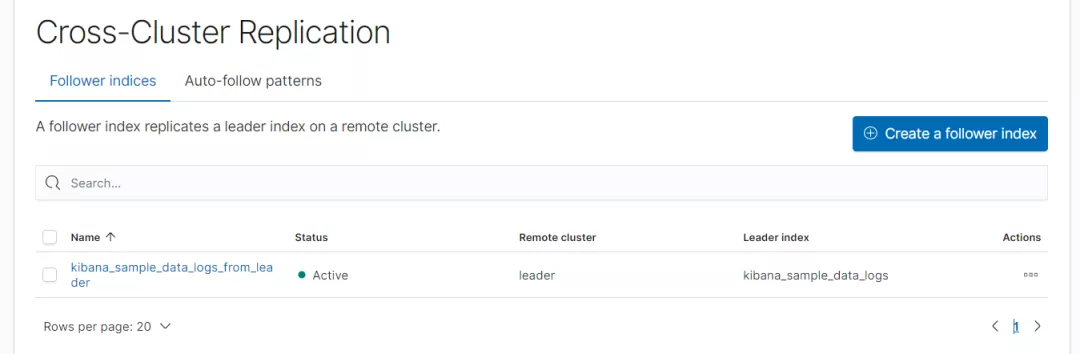
检查是否成功:
GET /kibana_sample_data_logs_from_leader/_ccr/stats
``
以上,跨集群同步设置成功之后,可以进一步做很多验证。
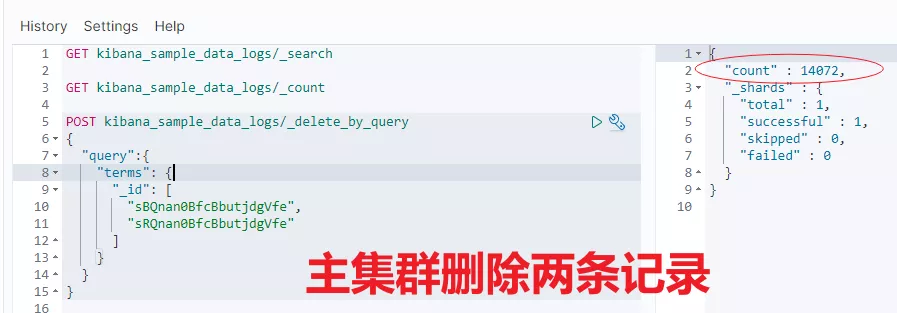
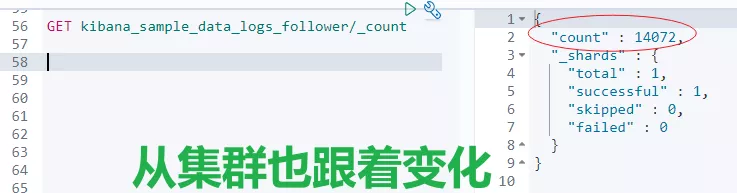
比如:主集群 leader 索引删除两条数据,从集群查看结果。对比发现,从集群也会跟着变化,这说明了跨集群复制已生效。
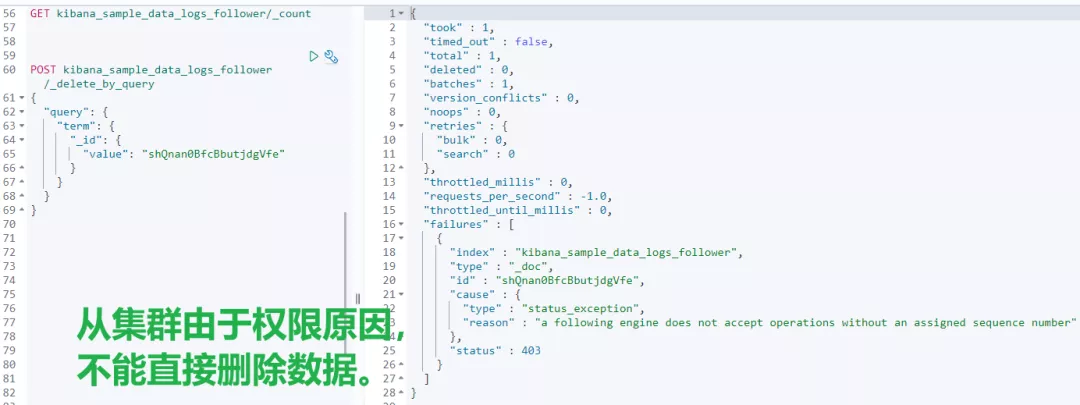
# 7、跨集群复制常用命令清单
包含但不限于:检查复制进度、暂停和恢复复制、重新创建跟随者索引和终止复制。
## 7.1 检查复制进度
GET /kibana_sample_data_logs_from_leader/_ccr/stats
## 7.2 暂停和恢复复制
POST kibana_sample_data_logs_from_leader/_ccr/pause_follow
POST kibana_sample_data_logs_from_leader/_ccr/resume_follow
{
}

## 7.3 重新创建跟随者索引
分三步骤:
暂停
POST /follower_index/_ccr/pause_follow
关闭
POST /follower_index/_close?wait_for_active_shards=0
重建
PUT /follower_index/_ccr/follow?wait_for_active_shards=1
{
"remote_cluster" : "remote_cluster",
"leader_index" : "leader_index"
}
## 7.4 终止复制
需要先暂停、然后关闭,最后终止复制。
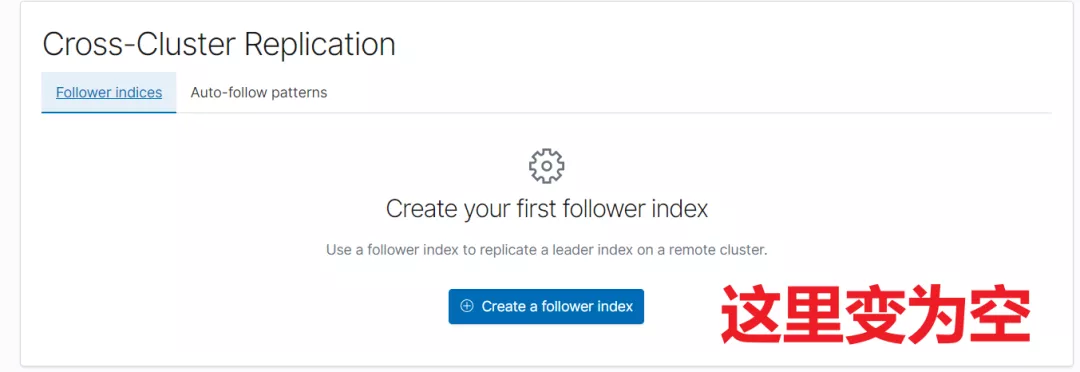
POST kibana_sample_data_logs_from_leader/_ccr/unfollow
# 8、小结
实战出真知,由于这部分是收费功能,可能会用的少。这块一直是新知盲点,实战一把,才知道究竟!
针对data stream 数据流的处理,跨集群也是支持的,限于篇幅原因,本文没有展开,更多内容推荐阅读官方文档。
耗时12小时+,希望对你有帮助!Elasticsearch 主从同步之跨集群复制的更多相关文章
- redis主从同步故障切换及集群配置
一.redis是一中高性能的缓存数据库, 原理:1. 从服务器向主服务器发送 SYNC 命令.2. 接到 SYNC 命令的主服务器会调用BGSAVE 命令,创建一个 RDB 文件,并使用缓冲区记录接下 ...
- Elasticsearch:跨集群复制 Cross-cluster replication(CCR)
- Elasticsearch跨集群搜索(Cross Cluster Search)
1.简介 Elasticsearch在5.3版本中引入了Cross Cluster Search(CCS 跨集群搜索)功能,用来替换掉要被废弃的Tribe Node.类似Tribe Node,Cros ...
- elasticsearch跨集群数据迁移
写这篇文章,主要是目前公司要把ES从2.4.1升级到最新版本7.8,不过现在是7.9了,官方的文档:https://www.elastic.co/guide/en/elasticsearch/refe ...
- Elasticsearch:跨集群搜索 Cross-cluster search (CCS)
转载自:https://blog.csdn.net/UbuntuTouch/article/details/104588232 跨集群搜索(cross-cluster search)使您可以针对一个或 ...
- 关于redis的主从、哨兵、集群
关于redis主从.哨兵.集群的介绍网上很多,这里就不赘述了. 一.主从 通过持久化功能,Redis保证了即使在服务器重启的情况下也不会损失(或少量损失)数据,因为持久化会把内存中数据保存到硬盘上,重 ...
- 关于redis主从|哨兵|集群模式
关于redis主从.哨兵.集群的介绍网上很多,这里就不赘述了. 一.主从 通过持久化功能,Redis保证了即使在服务器重启的情况下也不会损失(或少量损失)数据,因为持久化会把内存中数据保存到硬盘上,重 ...
- redis主从|哨兵|集群模式
关于redis主从.哨兵.集群的介绍网上很多,这里就不赘述了. 一.主从 通过持久化功能,Redis保证了即使在服务器重启的情况下也不会损失(或少量损失)数据,因为持久化会把内存中数据保存到硬盘上,重 ...
- ElasticSearch 深入理解 三:集群部署设计
ElasticSearch 深入理解 三:集群部署设计 ElasticSearch从名字中也可以知道,它的Elastic跟Search是同等重要的,甚至以Elastic为主要导向. Elastic即可 ...
随机推荐
- 005_面试题 Java_传递方式
面试题: 问:java是值传递还是引用传递? 答:java只有值传递,基本类型传递的是具体的数,引用类型传递的是具体的地址
- VIM编辑器的宏操作
这两天看到一个小练习,要求如下: 在GVIM下,将下面这张图的内容 改成下面这样 并且指出,要用批量操作的方式,不能一行一行的键入 其实第一反应是利用正则表达式来操作,但是让用正则表达式以外的操作方式 ...
- Centos7 安装mysql服务器并开启远程访问功能
大二的暑假,波波老师送了一个华为云的服务器给我作测试用,这是我程序员生涯里第一次以root身份拥有一台真实的云服务器 而之前学习的linux知识在这时也派上了用场,自己的物理机用的是ubuntu系统, ...
- 使用Python3.7配合协同过滤算法(base on user,基于人)构建一套简单的精准推荐系统(个性化推荐)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_136 时至2020年,个性化推荐可谓风生水起,Youtube,Netflix,甚至于Pornhub,这些在互联网上叱咤风云的流媒体 ...
- 3.26省选模拟+NOI-ONLINE
今日趣闻: 这三个人都是同机房的,卡最优解(大常数选手不参与)....以至于最优解第一页都是我们机房的(有图为证,共三人) $NOI\ online$ $T1$ 首先模拟一遍记录这个点当前单调栈前面位 ...
- Vnc自动登录器-多国语言绿色版
推荐:介绍一个VNC连接工具:iis7服务器管理工具.IIs7服务器管理工具可以批量连接并管理VNC服务器.作为服务器集成管理器,它最优秀的功能就是批量管理windows与linux系统服务器.vps ...
- BZOJ3037 创世纪(基环树DP)
基环树DP,攻的当受的儿子,f表选,g表不选.并查集维护攻受关系.若有环则记录,DP受的后把它当祖宗,再DP攻的. #include <cstdio> #include <iostr ...
- 前端须知的 Cookie 知识
文章已收录到我的 GitHub 中,欢迎 star cookie 是什么和使用场景 cookie 是服务器端保存在浏览器的一小段文本信息,浏览器每次向服务器端发出请求,都会附带上这段信息(不是所有都带 ...
- Java开发学习(二十五)----使用PostMan完成不同类型参数传递
一.请求参数 请求路径设置好后,只要确保页面发送请求地址和后台Controller类中配置的路径一致,就可以接收到前端的请求,接收到请求后,如何接收页面传递的参数? 关于请求参数的传递与接收是和请求方 ...
- 使用VitePress搭建及部署vue组件库文档
每个组件库都有它们自己的文档.所以当我们开发完成我们自己的组件库必须也需要一个组件库文档.如果你还不了解如何搭建自己的组件库可以看这里->从零搭建Vue3组件库.看完这篇文章你就会发现原来搭建和 ...