Kubernetes 监控--Grafana
前面我们使用 Prometheus 采集了 Kubernetes 集群中的一些监控数据指标,我们也尝试使用 promQL 语句查询出了一些数据,并且在 Prometheus 的 Dashboard 中进行了展示,但是明显可以感觉到 Prometheus 的图表功能相对较弱,所以一般情况下我们会一个第三方的工具来展示这些数据,今天我们要和大家使用到的就是 Grafana。
Grafana 是一个可视化面板,有着非常漂亮的图表和布局展示,功能齐全的度量仪表盘和图形编辑器,支持 Graphite、zabbix、InfluxDB、Prometheus、OpenTSDB、Elasticsearch 等作为数据源,比 Prometheus 自带的图表展示功能强大太多,更加灵活,有丰富的插件,功能更加强大。
本文使用的yaml文件地址:https://files.cnblogs.com/files/sanduzxcvbnm/Grafana_yaml.zip?t=1654065153
安装
同样的我们将 grafana 安装到 Kubernetes 集群中,第一步去查看 grafana 的 docker 镜像的介绍,我们可以在 dockerhub 上去搜索,也可以在官网去查看相关资料,镜像地址如下:https://hub.docker.com/r/grafana/grafana/,我们可以看到介绍中运行 grafana 容器的命令非常简单:
$ docker run -d --name=grafana -p 3000:3000 grafana/grafana
但是还有一个需要注意的是 Changelog 中v5.1.0版本的更新介绍:
Major restructuring of the container
Usage of chown removed
File permissions incompatibility with previous versions
user id changed from 104 to 472
group id changed from 107 to 472
Runs as the grafana user by default (instead of root)
All default volumes removed
特别需要注意第3条,userid 和 groupid 都有所变化,所以我们在运行的容器的时候需要注意这个变化。现在我们将这个容器转化成 Kubernetes 中的 Pod:(grafana.yaml)
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: kube-mon
spec:
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
volumes:
- name: storage
hostPath:
path: /data/grafana/
nodeSelector:
monitor: prometheus
securityContext:
runAsUser: 0
containers:
- name: grafana
image: grafana/grafana:6.7.1 # 使用8.5.4版本在用插件devopsprodigy-kubegraf-app添加集群信息的时候会报404
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
name: grafana
env:
- name: GF_SECURITY_ADMIN_USER
value: admin
- name: GF_SECURITY_ADMIN_PASSWORD
value: admin321
readinessProbe:
failureThreshold: 10
httpGet:
path: /api/health
port: 3000
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 30
livenessProbe:
failureThreshold: 3
httpGet:
path: /api/health
port: 3000
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
limits:
cpu: 150m
memory: 512Mi
requests:
cpu: 150m
memory: 512Mi
volumeMounts:
- mountPath: /var/lib/grafana
name: storage
---
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: kube-mon
spec:
type: NodePort
ports:
- port: 3000
selector:
app: grafana
我们使用了最新的镜像 grafana/grafana:6.7.1,然后添加了健康检查、资源声明,另外两个比较重要的环境变量GF_SECURITY_ADMIN_USER 和 GF_SECURITY_ADMIN_PASSWORD,用来配置 grafana 的管理员用户和密码的,由于 grafana 将 dashboard、插件这些数据保存在 /var/lib/grafana 这个目录下面的,所以我们这里如果需要做数据持久化的话,就需要针对这个目录进行 volume 挂载声明,和 Prometheus 一样,我们将 grafana 固定在一个具有 monitor: prometheus 标签的节点,由于上面我们刚刚提到的 Changelog 中 grafana 的 userid 和 groupid 有所变化,所以我们这里增加一个 securityContext 的声明来进行声明使用 root 用户运行。最后,我们需要对外暴露 grafana 这个服务,所以我们需要一个对应的 Service 对象,当然用 NodePort 或者再建立一个 ingress 对象都是可行的。
现在我们直接创建上面的这些资源对象:
$ kubectl apply -f grafana.yaml
deployment.apps "grafana" created
service "grafana" created
创建完成后,我们可以查看 grafana 对应的 Pod 是否正常:
$ kubectl get pods -n kube-mon -l app=grafana
NAME READY STATUS RESTARTS AGE
grafana-5579769f64-vfn7q 1/1 Running 0 77s
$ kubectl logs -f grafana-5579769f64-vfn7q -n kube-mon
......
logger=settings var="GF_SECURITY_ADMIN_USER=admin"
t=2019-12-13T06:35:08+0000 lvl=info msg="Config overridden from Environment variable"
......
t=2019-12-13T06:35:08+0000 lvl=info msg="Initializing Stream Manager"
t=2019-12-13T06:35:08+0000 lvl=info msg="HTTP Server Listen" logger=http.server address=[::]:3000 protocol=http subUrl= socket=
看到上面的日志信息就证明我们的 grafana 的 Pod 已经正常启动起来了。这个时候我们可以查看 Service 对象:
$ kubectl get svc -n kube-mon
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana NodePort 10.104.116.58 <none> 3000:31548/TCP 12m
......
现在我们就可以在浏览器中使用 http://<任意节点IP:31548> 来访问 grafana 这个服务了:

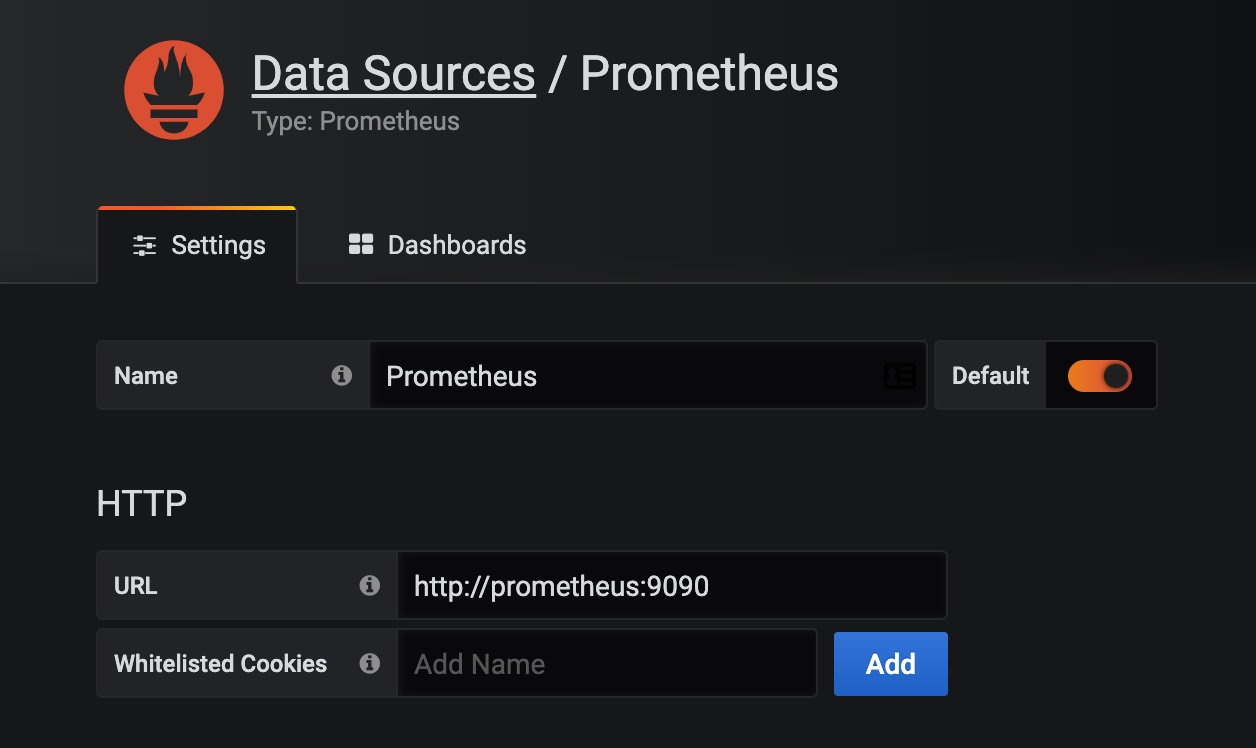
由于上面我们配置了管理员的,所以第一次打开的时候会跳转到登录界面,然后就可以用上面我们配置的两个环境变量的值来进行登录了,登录完成后就可以进入到下面 Grafana 的首页,然后点击Add data source进入添加数据源界面。
我们这个地方配置的数据源是 Prometheus,我们这里 Prometheus 和 Grafana 都处于 kube-mon 这同一个 namespace 下面,所以我们这里的数据源地址:http://prometheus:9090(因为在同一个 namespace 下面所以直接用 Service 名也可以),然后其他的配置信息就根据实际情况了,比如 Auth 认证,我们这里没有,所以跳过即可,点击最下方的 Save & Test 提示成功证明我们的数据源配置正确:
插件
我们也可以安装一些其他插件,比如 grafana 就有一个专门针对 Kubernetes 集群监控的插件:grafana-kubernetes-app,但是该插件很久没有更新了,这里我们介绍一个功能更加强大的插件 DevOpsProdigy KubeGraf,它是 Grafana 官方的 Kubernetes 插件 的升级版本,该插件可以用来可视化和分析 Kubernetes 集群的性能,通过各种图形直观的展示了 Kubernetes 集群的主要服务的指标和特征,还可以用于检查应用程序的生命周期和错误日志。
要安装这个插件,需要到 grafana 的 Pod 里面去执行安装命令:
$ kubectl exec -it grafana-5579769f64-7729f -n kube-mon /bin/bash
bash-5.0# grafana-cli plugins install devopsprodigy-kubegraf-app
installing devopsprodigy-kubegraf-app @ 1.3.0
from: https://grafana.com/api/plugins/devopsprodigy-kubegraf-app/versions/1.3.0/download
into: /var/lib/grafana/plugins
Installed devopsprodigy-kubegraf-app successfully
Restart grafana after installing plugins . <service grafana-server restart>
# 由于该插件依赖另外一个 Grafana-piechart-panel 插件,所以如果没有安装,同样需要先安装该插件。
bash-5.0# grafana-cli plugins install Grafana-piechart-panel
......
注意事项:
有可能会存在如下情况:先安装好grafana-piechart-panel插件后,再安装插件devopsprodigy-kubegraf-app提示报错:
/usr/share/grafana # grafana-cli plugins install grafana-piechart-panel
Downloaded grafana-piechart-panel v1.6.2 zip successfully
Please restart Grafana after installing plugins. Refer to Grafana documentation for instructions if necessary.
/usr/share/grafana # grafana-cli plugins install devopsprodigy-kubegraf-app
Downloaded devopsprodigy-kubegraf-app v1.5.2 zip successfully
Fetching devopsprodigy-kubegraf-app dependencies...
Error: ✗ failed to install plugin grafana-piechart-panel: grafana-piechart-panel v>=1.3.7 either does not exist or is not supported on your system (Grafana v8.5.4 linux-amd64)
此时需要进入到grafana pod调度的主机上,进入到/data/grafana/plugins/(具体路径看grafana.yaml文件中的hostpath)目录下,查看是否有这俩插件,且插件目录里是已安装好的文件。
若是这样,可以不用管上面的报错,直接删除pod,然后自动会创建一个新的pod,然后登陆,搜索选择插件并启用
安装完成后需要重启 grafana 才会生效,我们这里直接删除 Pod,重建即可。Pod 删除重建完成后插件就安装成功了。然后通过浏览器打开 Grafana 找到该插件,点击 enable 启用插件。

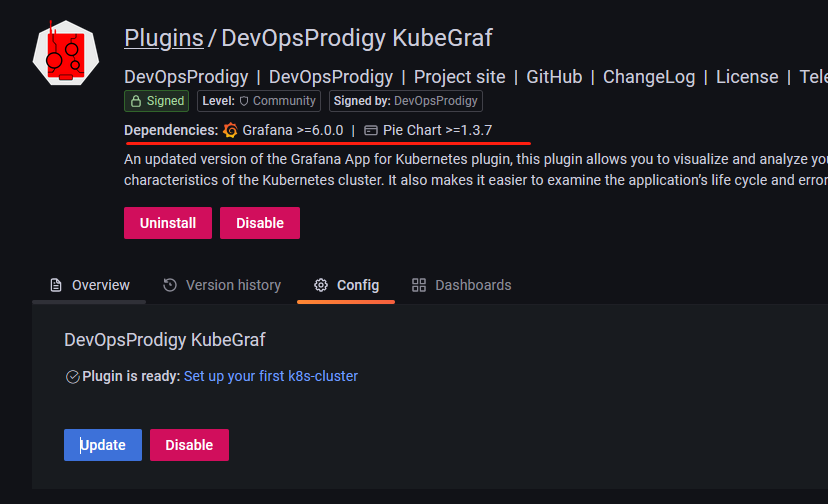
点击 Set up your first k8s-cluster 创建一个新的 Kubernetes 集群:
- URL 使用 Kubernetes Service 地址即可:https://kubernetes.default:443 (端口号根据实际情况来定)
- Access 访问模式使用:Server(default)
- 由于插件访问 Kubernetes 集群的各种资源对象信息,所以我们需要配置访问权限,这里我们可以简单使用 kubectl 的 kubeconfig 来进行配置即可。
- 勾选 Auth 下面的 TLS Client Auth 和 With CA Cert 两个选项
- 其中 TLS Auth Details 下面的值就对应 kubeconfig 里面的证书信息。比如我们这里的 kubeconfig 文件格式如下所示: (查看地址:/root/.kube/config)
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: <certificate-authority-data>
server: https://ydzs-master:6443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kubernetes-admin
name: kubernetes-admin@kubernetes
current-context: 'kubernetes-admin@kubernetes'
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: <client-certificate-data>
client-key-data: <client-key-data>
那么 CA Cert 的值就对应 kubeconfig 里面的 <certificate-authority-data> 进行 base64 解码过后的值;Client Cert 的值对应 <client-certificate-data> 进行 base64 解码过后的值;Client Key 的值就对应 <client-key-data> 进行 base64 解码过后的值。
base64 解码: 对于 base64 解码推荐使用一些在线的服务,比如 https://www.base64decode.org/
- 最后在 additional datasources 下拉列表中选择 prometheus 的数据源。
- 点击 Save & Test 正常就可以保存成功了。
插件配置完成后,在左侧侧边栏就会出现 DevOpsProdigy KubeGraf 插件的入口,通过插件页面可以查看整个集群的状态。
还有几个漂亮的 Dashboard 可以供我们来进行监控图表的展示:
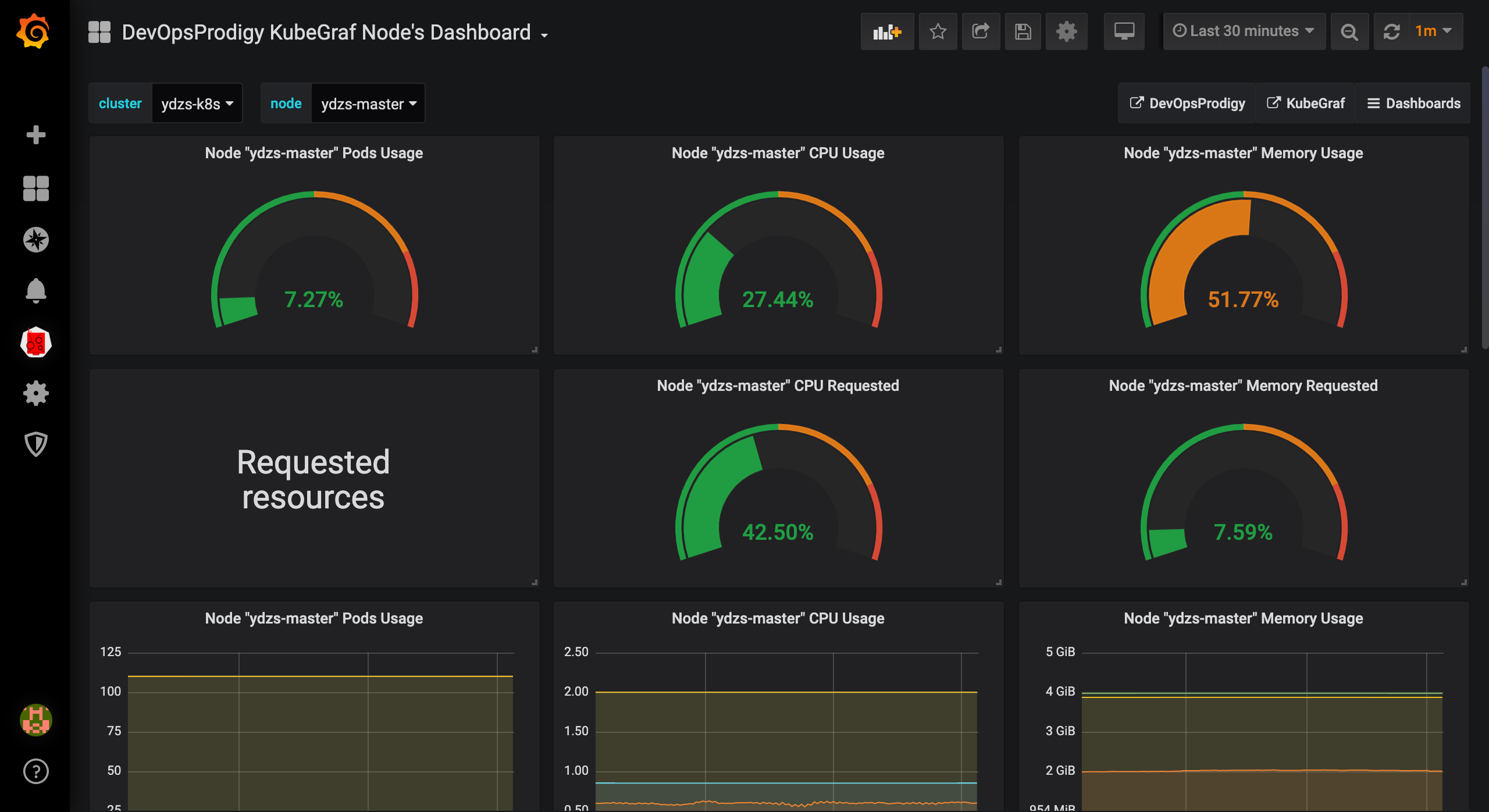
该插件默认提供的几个图表,这几个足够用的了,下面的步骤感觉没必要再添加额外的Dashboard了
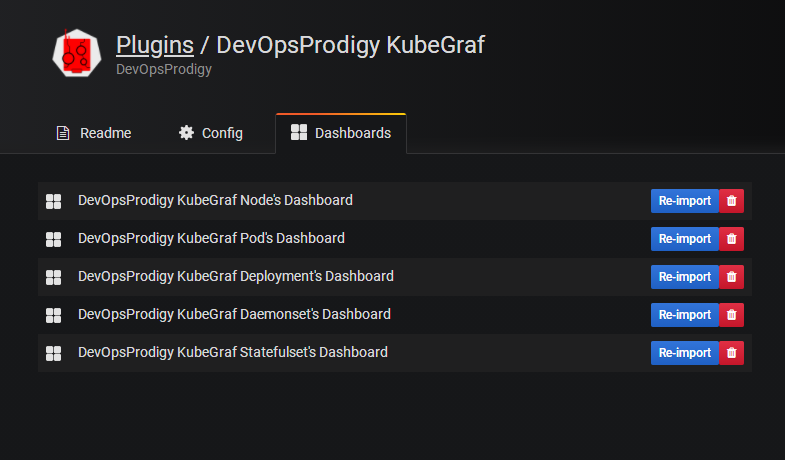
导入 Dashboard
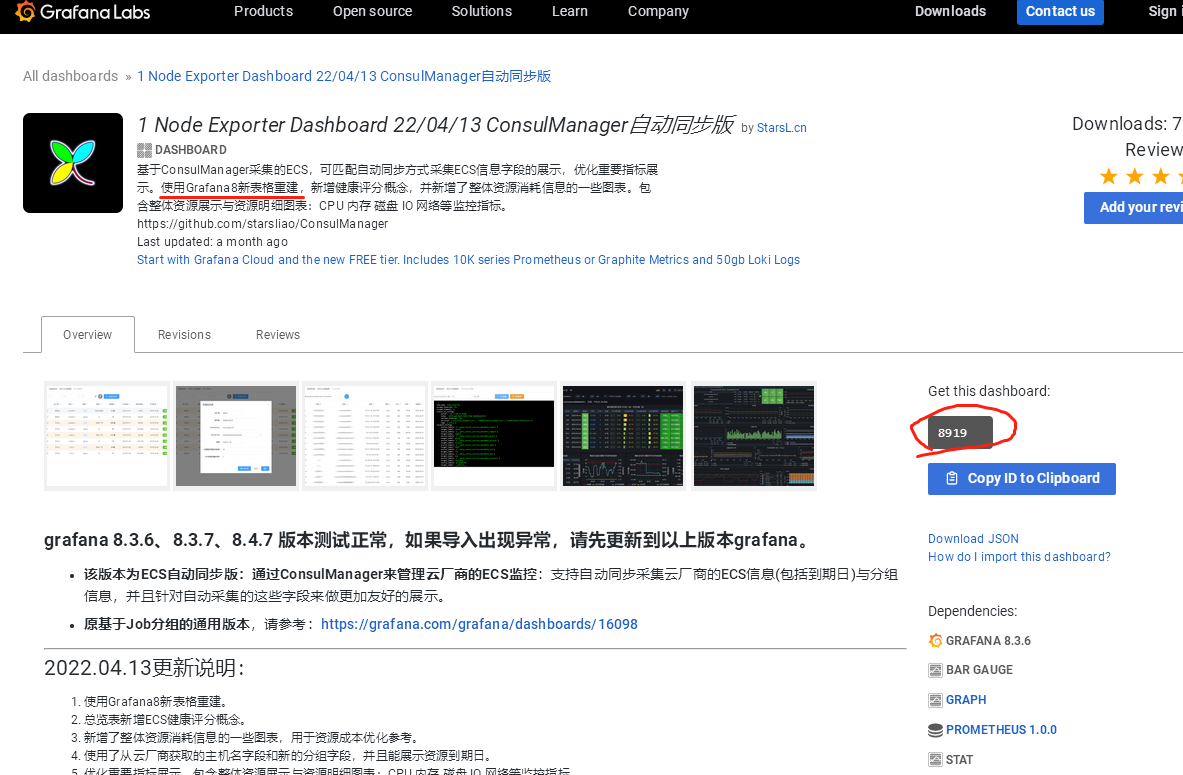
为了能够快速对系统进行监控,我们可以直接复用别人的 Grafana Dashboard,在 Grafana 的官方网站上就有很多非常优秀的第三方 Dashboard,我们完全可以直接导入进来即可。比如我们想要对所有的集群节点进行监控,也就是 node-exporter 采集的数据进行展示,这里我们就可以导入 https://grafana.com/grafana/dashboards/8919 这个 Dashboard。
8919匹配的是Grafana8版本,但是安装的Grafana版本是6.7.1,因此不能使用这个Dashboard,导入后使用会报错:

在侧边栏点击 "+",选择 Import,在 Grafana Dashboard 的文本框中输入 8919 即可导入:
进入导入 Dashboard 的页面,可以编辑名称,选择 Prometheus 的数据源:
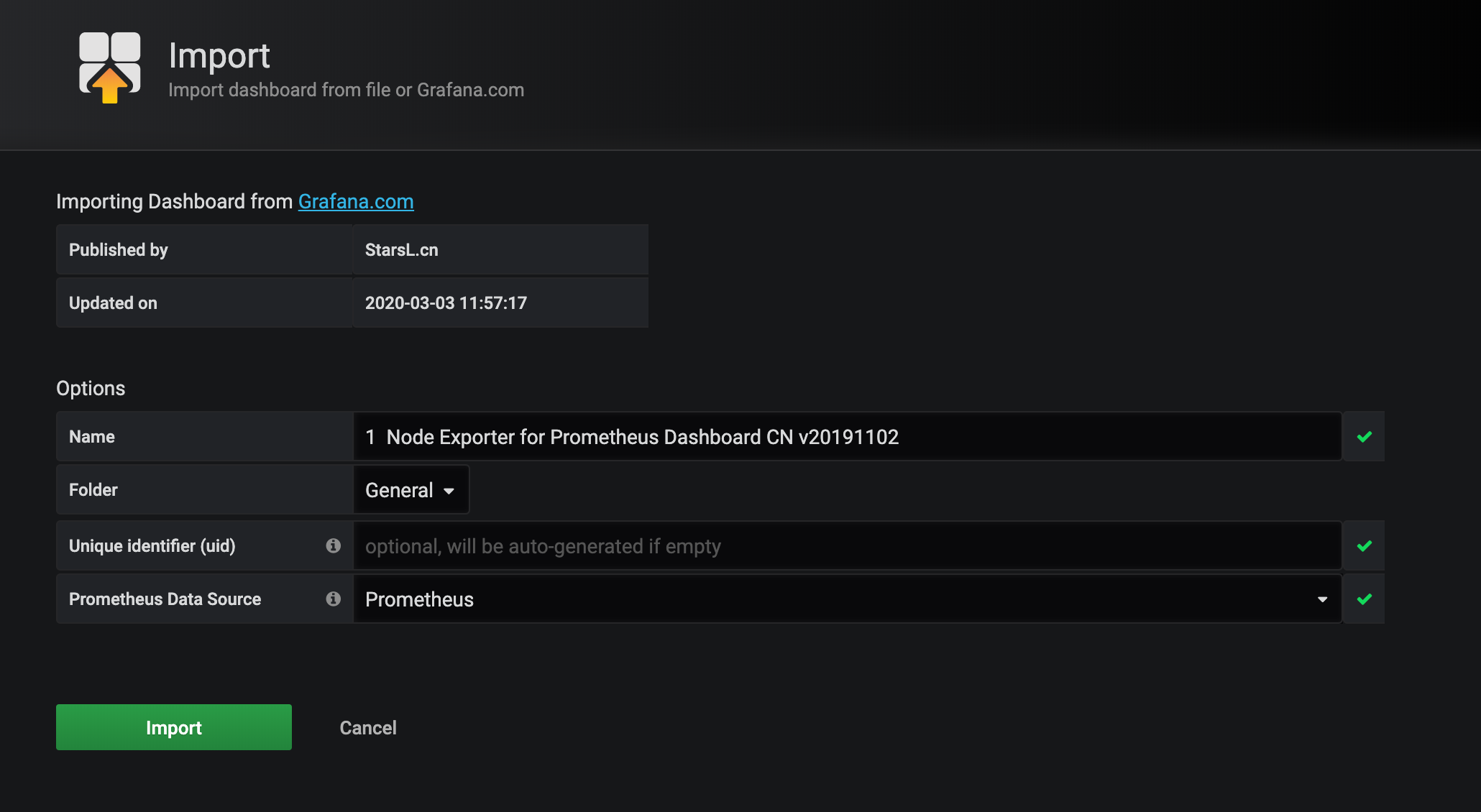
保存后即可进入导入的 Dashboard 页面。由于该 Dashboard 更新比较及时,所以基本上导入进来就可以直接使用了,我们也可以对页面进行一些调整,如果有的图表没有出现对应的图形,则可以编辑根据查询语句去 DEBUG。
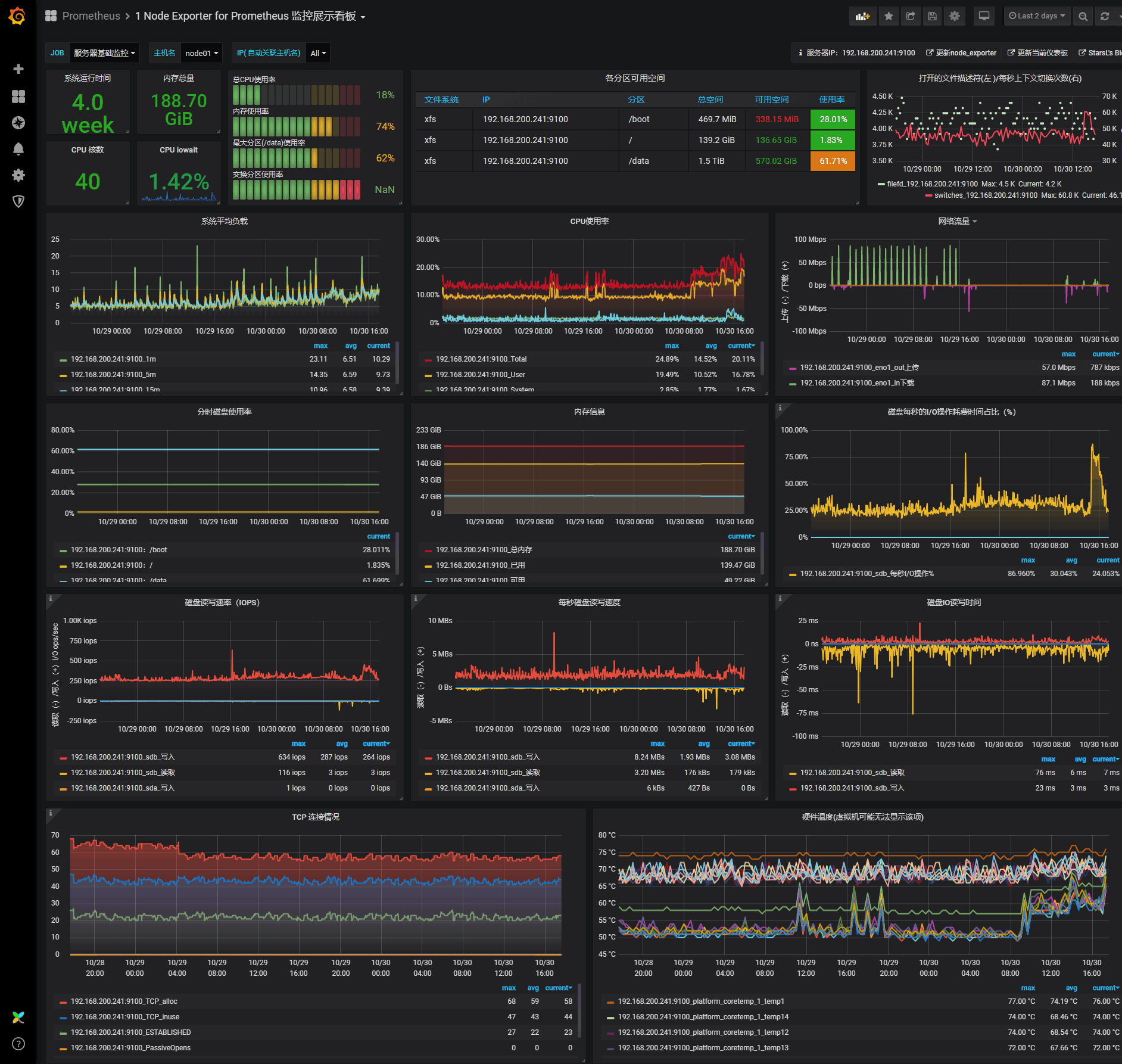
自定义图表
导入现成的第三方 Dashboard 或许能解决我们大部分问题,但是毕竟还会有需要定制图表的时候,这个时候就需要了解如何去自定义图表了。
同样在侧边栏点击 "+",选择 Dashboard,然后选择 Choose Visualization 创建一个可视化的图表:
可以根据需要选择各种类型的图表,比如我们这里选择一个 Graph 类型的:
然后选择左侧图标中的第一个 Queries tab,然后选择 Prometheus 这个数据源:
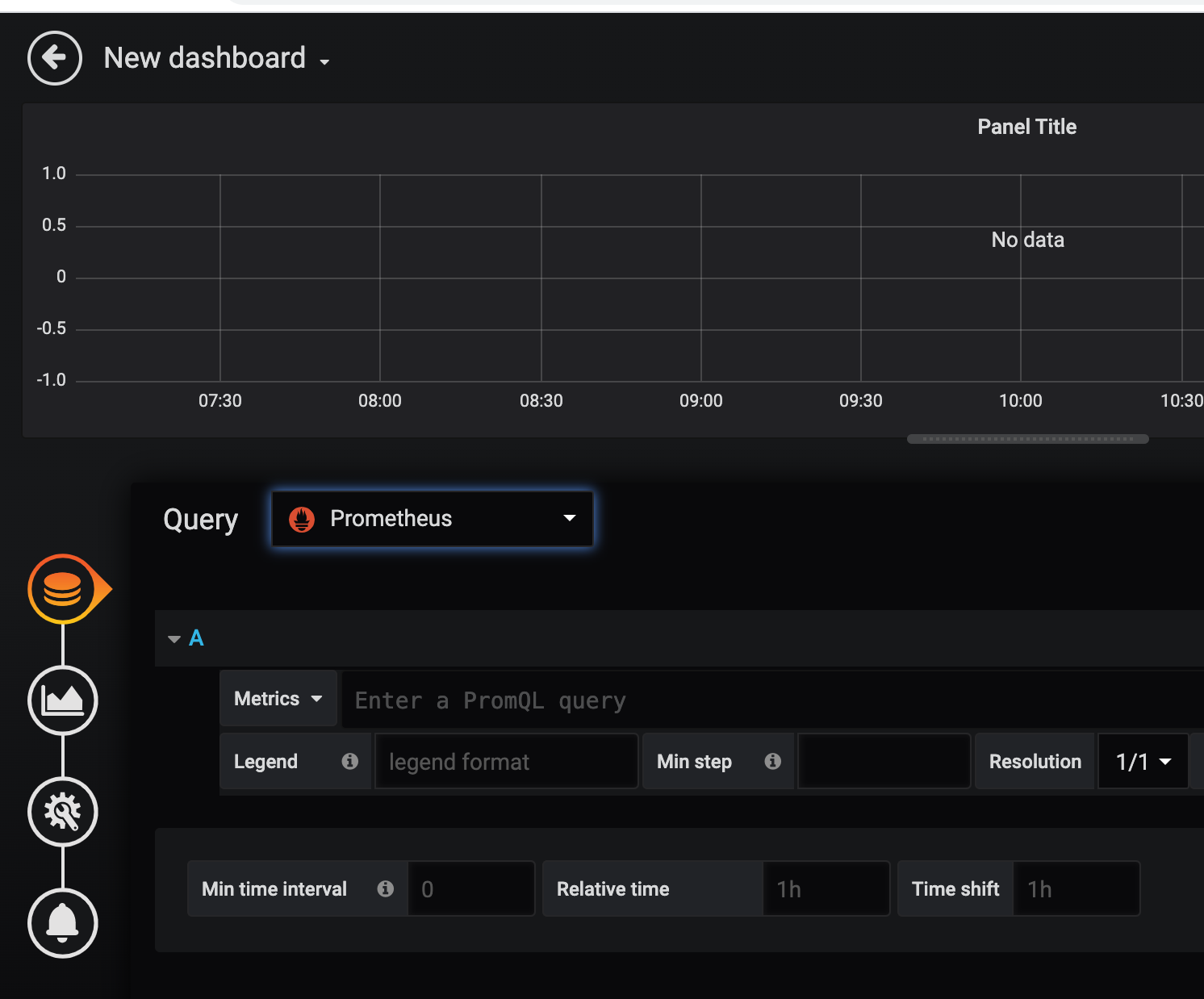
然后在 Metrics 区域输入我们要查询的监控 PromQL 语句,比如我们这里想要查询集群节点 CPU 的使用率:
(1 - sum(increase(node_cpu_seconds_total{mode="idle", instance=~"$node"}[1m])) by (instance) / sum(increase(node_cpu_seconds_total{instance=~"$node"}[1m])) by (instance)) * 100
虽然我们现在还没有具体的学习过 PromQL 语句,但其实我们仔细分析上面的语句也不是很困难,集群节点的 CPU 使用率实际上就相当于排除空闲 CPU 的使用率,所以我们可以优先计算空闲 CPU 的使用时长,除以总的 CPU 时长就是使用率了,用 1 减掉过后就是 CPU 的使用率了,如果想用百分比来表示的话则乘以 100 即可。
这里有一个需要注意的地方是在 PromQL 语句中有一个 install=~"$node" 的标签,其实意思就是根据 $node 这个参数来进行过滤,也就是我们希望在 Grafana 里面通过参数化来控制每一次计算哪一个节点的 CPU 使用率。
所以这里就涉及到 Grafana 里面的参数使用。点击页面顶部的 Dashboard Settings 按钮进入配置页面:
在左侧 tab 栏点击 Variables 进入参数配置页面,如果还没有任何参数,可以通过点击 Add Variable 添加一个新的变量:
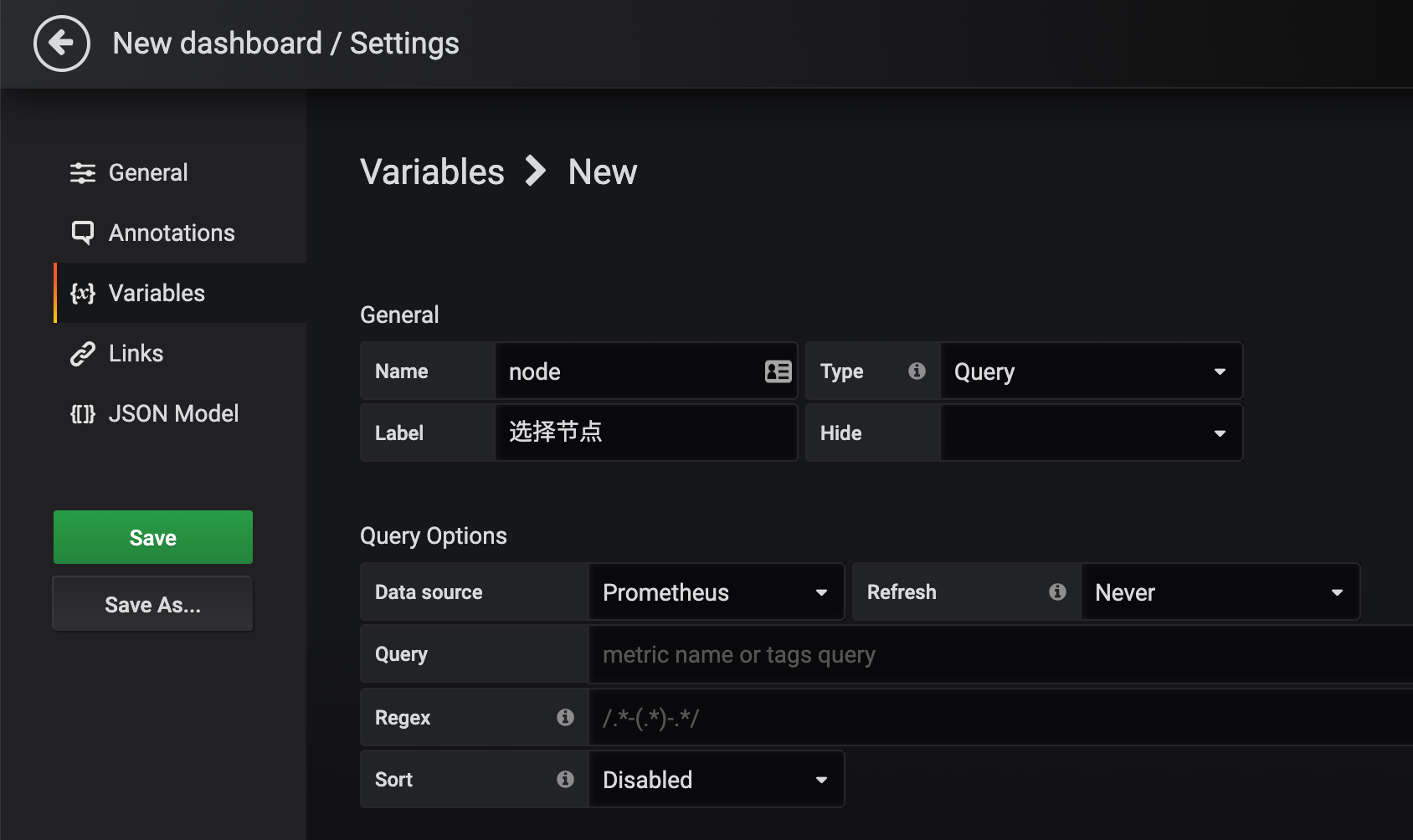
这里需要注意的是变量的名称 node 就是上面我们在 PromQL 语句里面使用的 $node 这个参数,这两个地方必须保持一致,然后最重要的就是参数的获取方式了,比如我们可以通过 Prometheus 这个数据源,通过 kubelet_node_name 这个指标来获取,在 Prometheus 里面我们可以查询该指标获取到的值为:
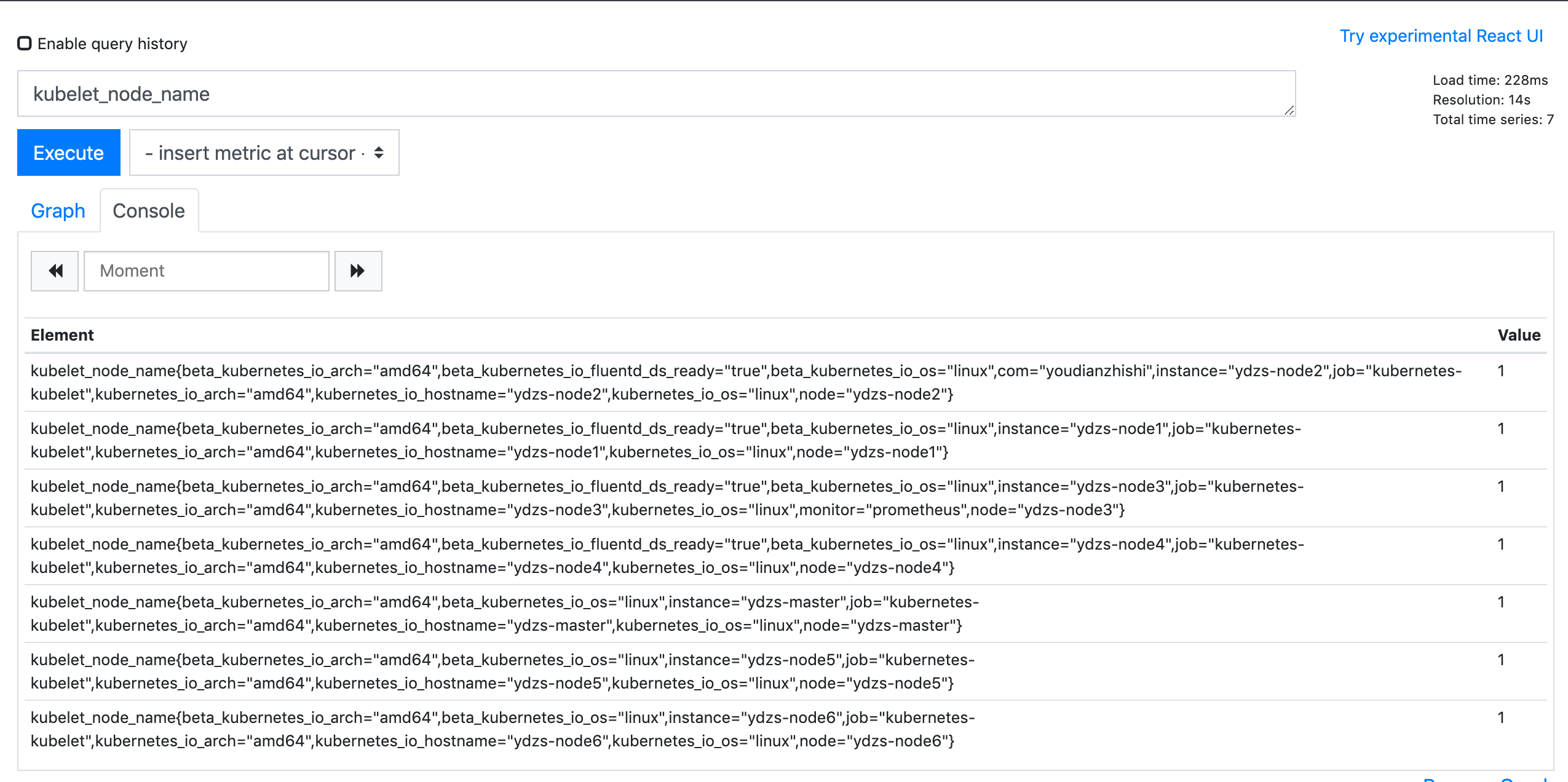
我们其实只是想要获取节点的名称,所以我们可以用正则表达式去匹配 node=xxx 这个标签,将匹配的值作为参数的值即可:
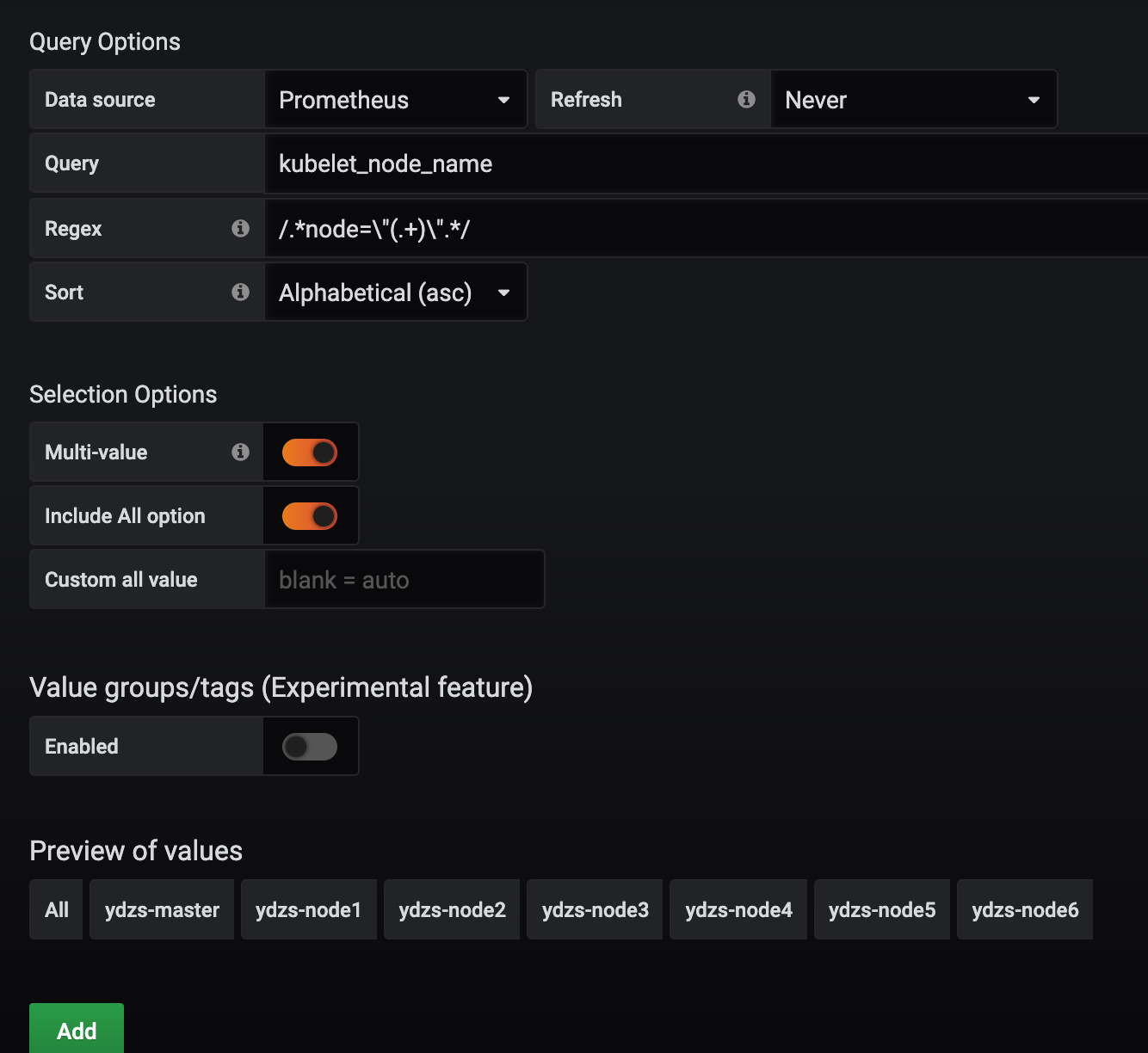
在最下面的 Preview of values 里面会有获取的参数值的预览结果。除此之外,我们还可以使用一个更方便的 labe_values 函数来获取,该函数可以用来直接获取某个指标的 label 值:
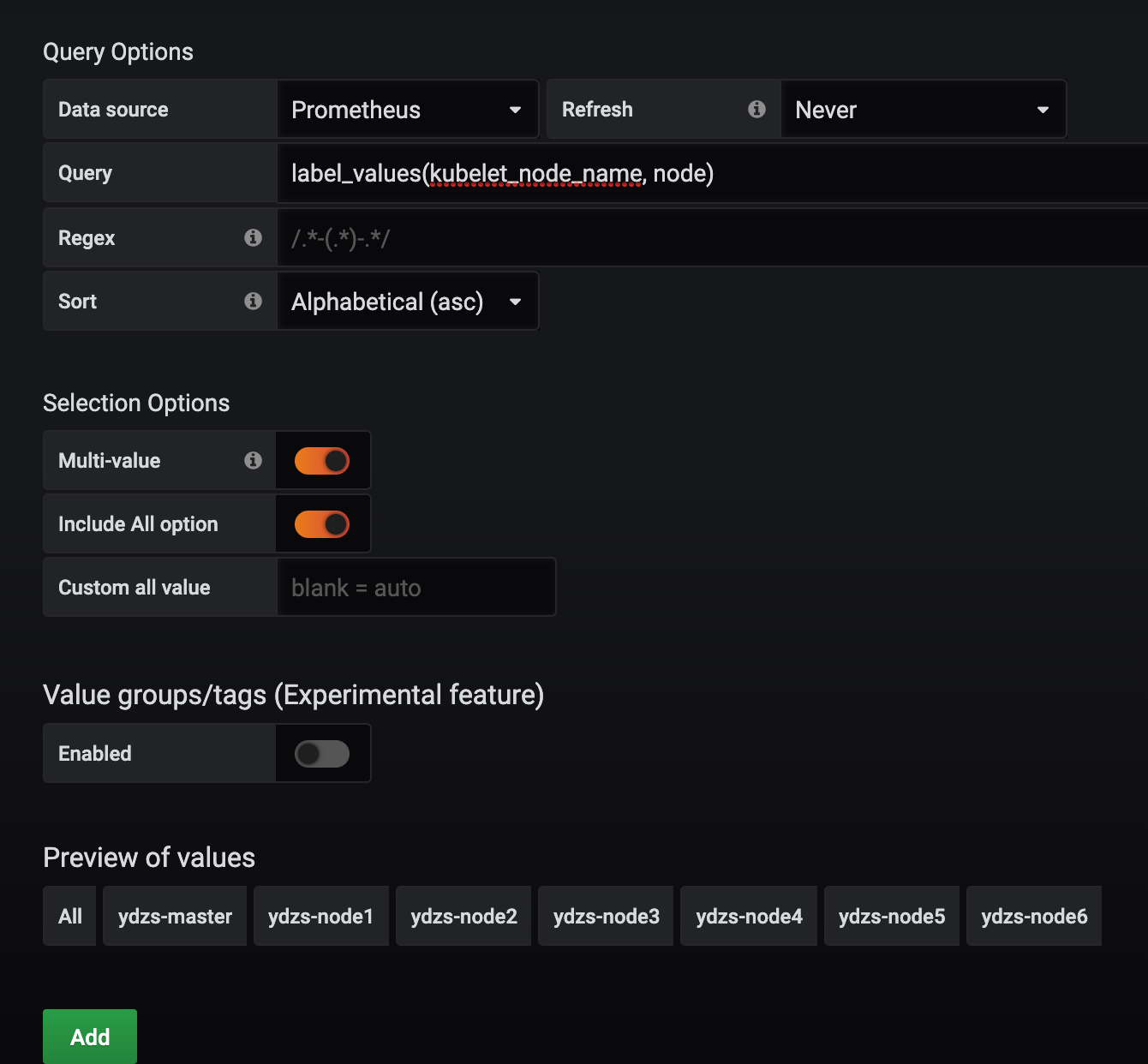
另外由于我们希望能够让用户自由选择一次性可以查询多少个节点的数据,所以我们将 Multi-value 以及 Include All option 都勾选上了,最后记得保存,保存后跳转到 Dashboard 页面就可以看到我们自定义的图表信息:
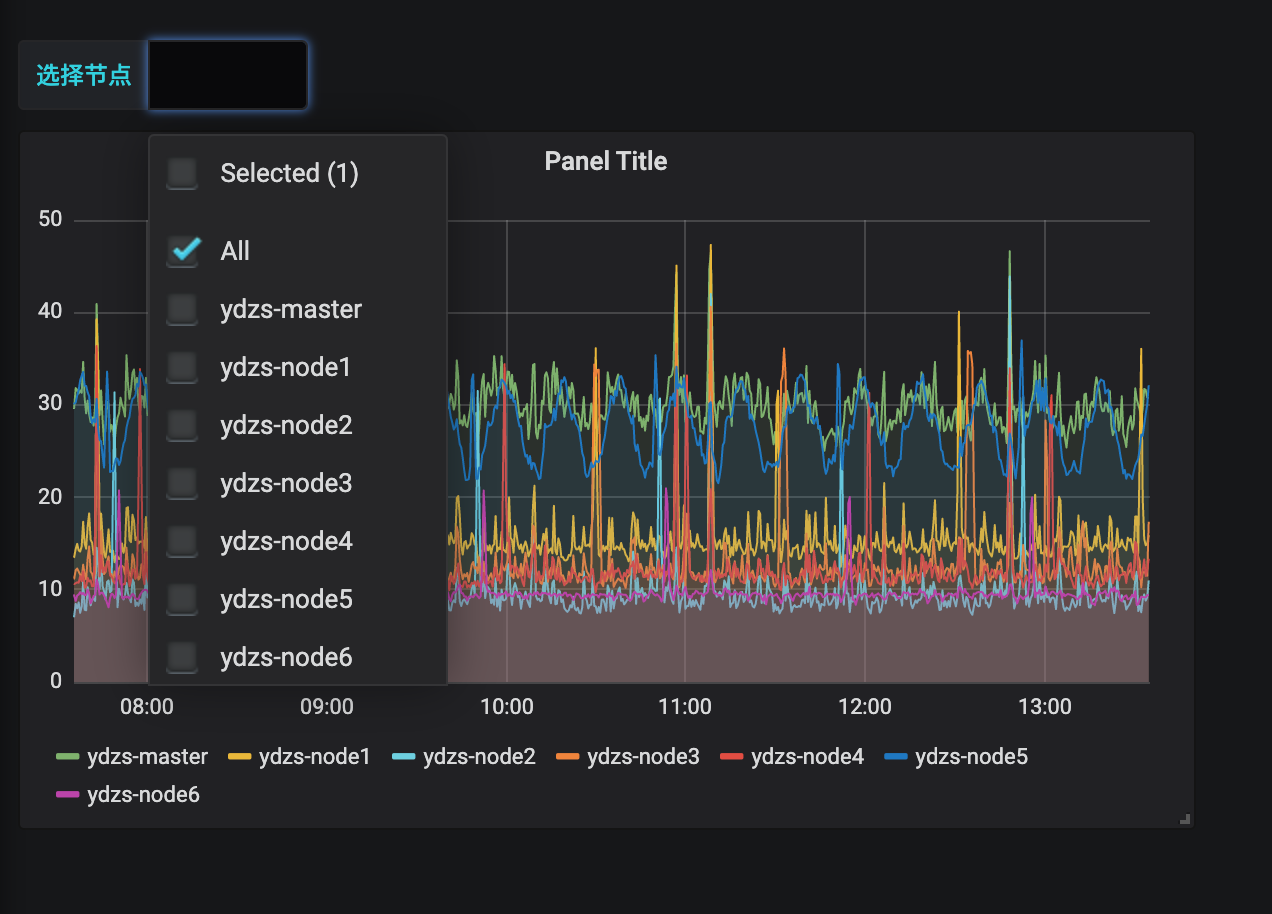
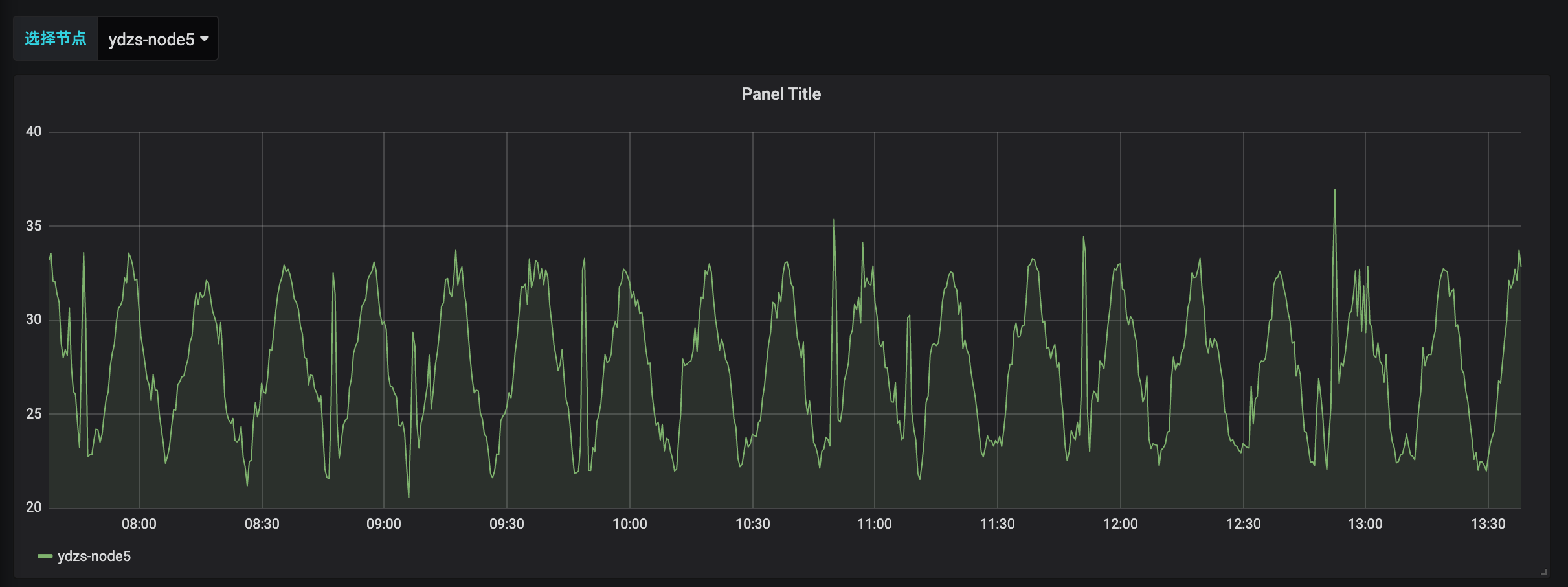
而且还可以根据参数选择一个或者多个节点,当然图表的标题和大小都可以自由去更改:
Kubernetes 监控--Grafana的更多相关文章
- Kubernetes监控:部署Heapster、InfluxDB和Grafana
本节内容: Kubernetes 监控方案 Heapster.InfluxDB和Grafana介绍 安装配置Heapster.InfluxDB和Grafana 访问 grafana 访问 influx ...
- 【译】Kubernetes监控实践(2):可行监控方案之Prometheus和Sensu
本文介绍两个可行的K8s监控方案:Prometheus和Sensu.两个方案都能全面提供系统级的监控数据,帮助开发人员跟踪K8s关键组件的性能.定位故障.接收预警. 拓展阅读:Kubernetes监控 ...
- Kubernetes 监控方案之 Prometheus Operator(十九)
目录 一.Prometheus 介绍 1.1.Prometheus 架构 1.2.Prometheus Operator 架构 二.Helm 安装部署 2.1.Helm 客户端安装 2.2.Tille ...
- 云原生应用 Kubernetes 监控与弹性实践
前言 云原生应用的设计理念已经被越来越多的开发者接受与认可,而Kubernetes做为云原生的标准接口实现,已经成为了整个stack的中心,云服务的能力可以通过Cloud Provider.CRD C ...
- 通过Kubernetes监控探索应用架构,发现预期外的流量
大家好,我是阿里云云原生应用平台的炎寻,很高兴能和大家一起在 Kubernetes 监控系列公开课上进行交流.本次公开课期望能够给大家在 Kubernetes 容器化环境中快速发现和定位问题带来新的解 ...
- kubernetes监控-Heapster+InfluxDB+Grafana(十五)
cAdvisor+InfluxDB+Grafana cAdvisor:是谷歌开源的一个容器监控工具,采集主机上容器相关的性能指标数据.比如CPU.内存.网络.文件系统等. Heapster是谷歌开源的 ...
- kubernetes 监控方案之:heapster+influxdb+grafana(十八)
目录 一.Heapster 介绍 二.部署 三.使用 heapster 已经 deprecated 了:https://github.com/kubernetes/heapster,所以下面的演示主要 ...
- kubernetes监控和性能分析工具:heapster+influxdb+grafana
1.部署heapster 下载 heapster 相关 yaml 文件 [root@master dashboard]# wget https://raw.githubusercontent.com/ ...
- Kubernetes prometheus+grafana k8s 监控
参考: https://www.cnblogs.com/terrycy/p/10058944.html https://www.cnblogs.com/weiBlog/p/10629966.html ...
随机推荐
- 基于.NetCore开发博客项目 StarBlog - (15) 生成随机尺寸图片
系列文章 基于.NetCore开发博客项目 StarBlog - (1) 为什么需要自己写一个博客? 基于.NetCore开发博客项目 StarBlog - (2) 环境准备和创建项目 基于.NetC ...
- 一键部署bash脚本怎么写
因为我开源的一键部署应用到linux服务器的AntDeploy, 在linux部署是需要安装一个agent服务(systemctl服务) 如果是手动第一次安装的话 需要敲 下载 wget 解压 tar ...
- DNS 系列(三):如何免受 DNS 欺骗的侵害
互联网上每一台设备都会有一个 IP 地址,我们在访问网站或发送信息时,其实都是通过 IP 地址达成准确请求的.但是这个 IP 地址由很长一串数字组成,记忆起来相当困难,所以我们创造了更实用的域名来代替 ...
- 阈值PSI代码
阈值PSI 若交集数量超过某个给定阈值时,允许分布式的各个参与方在自己集合中找到交集,且除了交集外,得不到其他额外信息. 实现论文: Multi-Party Threshold Private Set ...
- IDEA 开发工具-插件{[转载]
00 idea 开发工具使用技巧 01 idea插件推荐-- 02 IDEA插件 03 IDEA值得推荐的20款优秀的插件 04 IDEA插件精选」安利一个IDEA骚操作:一键生成方法的序列图
- nginx概述及配置
Nginx是什么? Nginx是一个高性能的 HTTP 和 反向代理 服务器,也是一个 IMAP/POP3/SMTP 代理服务器.因它的稳定性.丰富的功能集.示例配置文件和低系统资源的消耗而闻名.20 ...
- golang面试-代码编写题1-14
目录 1.代码编写题--统计文本行数-bufio 2.代码编写题--多协程收集错误信息-channel 3.代码编写题--超时控制,内存泄露 4.代码编写题--单例模式 5.代码编写题--九九乘法表 ...
- 循环队列(严3.30)--------西工大NOJ习题.9
#define _CRT_SECURE_NO_WARNINGS #include <stdio.h> #include <stdlib.h> typedef struct _Q ...
- Azure Devops(十五) 使用Azure的私有Maven仓库
上一篇文章中,我们介绍了如何使用Azure的nuget仓库,今天我们来研究一下如何使用azure给我们提供的maven仓库. 首先,我们打开azureDevops,点击到制品界面,然后选择maven. ...
- Vue 父组件传递给子组件,设置默认值为数组或者对象时
在vue 父子组件传参过程中,传递对象或者数组时,设置默认值为{}或者[] 错误写法: props: { pos: { type: [Object, Array], default: []//这是错误 ...