MySQL · 数据恢复 · undrop-for-innodb
Ref:https://www.aliyun.com/jiaocheng/1109809.html
摘要: 简介 undrop-for-innodb 是针对 innodb 的一套数据恢复工具,可以从文件级别恢复诸如:DROP/TRUNCATE table, 删除表中某些记录,innodb 文件被删除,文件系统损坏,磁盘 corruption 等几种情况。
简介
undrop-for-innodb 是针对 innodb 的一套数据恢复工具,可以从文件级别恢复诸如:DROP/TRUNCATE table, 删除表中某些记录,innodb 文件被删除,文件系统损坏,磁盘 corruption 等几种情况。本文简单介绍下使用方法和原理浅析。
准备
git clone https://github.com/twindb/undrop-for-innodb.git
make
需要联合 MySQL 的安装路径编译工具 sys_parser,
gcc `$basedir/bin/mysql_config --cflags` `$basedir/bin/mysql_config --libs` -o sys_parser sys_parser.c
需要的工具都已经完备:

- 重要的工具:
c_parser && stream_parser && sys_parser - 其中
test.sh && recover_dictionary.sh && fetch_data.sh是测试的脚本,可以看下里面的逻辑理解工具的用法。 - 三个目录
- dictionary 里面是模拟 innodb 系统表结构写的 CREATE TABLE 语句,innodb 的系统表对用户不可见,可以在 informatioin_schema 表中找到一些值,但实际上系统表是保存在 ibdata 固定的页上的。
- sakila 是一些 SQL 语句,用来测试用。
- include 是从 innodb 拿出来的一些用到的头文件和源文件。
DROP TABLE
表结构恢复
一般情况下表结构是存储在 frm 文件中,drop table 会删除 frm 文件,还好我们可以从 innodb 系统表里读取一些信息恢复表结构。innodb 系统表有
SYS_COLUMNS | SYS_FIELDS | SYS_INDEXES | SYS_TABLES
关于系统表结构的具体介绍可以参考 系统表 , 这几个表对于恢复非常重要,下面以一个恢复表结构的例子来说明。
使用目录 sakila/actor.sql 中的例子:
CREATE TABLE `actor` (
`actor_id` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`first_name` varchar(45) NOT NULL,
`last_name` varchar(45) NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`actor_id`),
KEY `idx_actor_last_name` (`last_name`)
) ENGINE=InnoDB AUTO_INCREMENT=201 DEFAULT CHARSET=utf8; insert into actor(first_name, last_name) values('zhang', 'jian'); insert into actor(first_name, last_name) values('zhan', 'jian'); insert into actor(first_name, last_name) values('zha', 'jian'); insert into actor(first_name, last_name) values('zh', 'jian'); insert into actor(first_name, last_name) values('z', 'jian');
mysql> checksum table actor;
+-----------+------------+
| Table | Checksum |
+-----------+------------+
| per.actor | 2184463059 |
+-----------+------------+ 1 row in set (0.00 sec)
DROP TABLE actor
需要从系统表中恢复,而系统表是保存在 $datadir/ibdata1 文件中的,使用工具 stream_parser 解析文件内容。
$./stream_parser -f /home/zj118228/rds_5616/data/ibdata1
执行完毕后会在当前目录下生成文件夹 pages-ibdata1 , 目录下按照每个页为一个文件,分为索引页和数据较大的 BLOB 页,我们访问系统表的话,是存在索引页中的。使用另外一个重要的工具 c_parser 来解析页的内容。
$./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000001.page -t dictionary/SYS_TABLES.sql | grep 'sakila/actor' 000000005927 24000001C809C6 SYS_TABLES "sakila/actor" 52 4 1 0 80 "" 38 参数解析:
- 4 表示文件格式是 REDUNDANT,系统表的格式默认值。另外可以取值 5 表示 COMPACT 格式,6 表示 MySQL 5.6 格式。
- D 表示只恢复被删除的记录。
- f 后面跟着文件。
- t 后面跟着 CREATE TABLE 语句,需要根据表的格式来解析文件。
得到的结果 ‘SYS_TABLES’ 字段后面的就是系统表 SYS_TABLE 中对应存的记录。 同样的恢复其它三个系统表:
/* --- SYS_INDEXES 'grep 52' 是对应 SYS_TABLE 的 TALE ID --- */
$./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000003.page -t dictionary/SYS_INDEXES.sql | grep '52' 000000005927 24000001C807FF SYS_INDEXES 52 57 "PRIMARY" 1 3 38 4294967295 000000005927 24000001C80871 SYS_INDEXES 52 58 "idx\_actor\_last\_name" 1 0 38 4294967295 /* --- SYS_COLUMNS --- */
./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000002.page -t dictionary/SYS_COLUMNS.sql | grep 52 000000005927 24000001C808F2 SYS_COLUMNS 52 0 "actor\_id" 6 1794 2 0 000000005927 24000001C80927 SYS_COLUMNS 52 1 "first\_name" 12 2162959 135 0 000000005927 24000001C8095C SYS_COLUMNS 52 2 "last\_name" 12 2162959 135 0 000000005927 24000001C80991 SYS_COLUMNS 52 3 "last\_update" 3 525575 4 0 /* --- SYS_FIELD 'grep 57\|58' 对应 SYS_INDEXES 的 ID 列 --- */
$./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000004.page -t dictionary/SYS_FIELDS.sql | grep '57\|58' 000000005927 24000001C807CA SYS_FIELDS 57 0 "actor\_id" 000000005927 24000001C8083C SYS_FIELDS 58 0 "last\_name" 我们恢复表结构的数据都在这四张系统表中了,SYS_COLUMNS 后面几列的表示 MySQL 内部对于数据类型的编号。
接下来是恢复阶段
- 使用目录 dictionary 下的四个文件创建四张表(这里数据库名为 recover )。
- 把上面恢复出来的数据分别导入到对应的表中(注意相同的行去重)。
- 使用工具 sys_parser 恢复 CREATE TABLE 语句。
$./sys_parser -h 127.0.0.1 -u root -P 56160 -d recover sakila/actor
CREATE TABLE `actor`(
`actor_id` SMALLINT UNSIGNED NOT NULL,
`first_name` VARCHAR(45) CHARACTER SET 'utf8' COLLATE 'utf8_general_ci' NOT NULL,
`last_name` VARCHAR(45) CHARACTER SET 'utf8' COLLATE 'utf8_general_ci' NOT NULL,
`last_update` TIMESTAMP NOT NULL,
PRIMARY KEY (`actor_id`)
) ENGINE=InnoDB; 对比发现,恢复出来的 CREATE TABLE 语句相比原来创建的语句信息量有点缺少,因为 innodb 系统表里面存的数据相比 frm 文件是不足的,比如 AUTO_INCREMENT, DECIMAL 类型的精度信息都会缺失,也不会恢复二级索引,外建等。可以看成是表存储结构的恢复。如果有 frm 文件就可以完完整整的恢复了,这篇文章介绍了恢复方法:Get Create Table From frm
表数据恢复
innodb_file_per_table off
这种情况表中的数据是保存在 ibdata 文件中的,虽然表的数据在数据库中被删除了,但是如果没有被重写,数据还在保存在文件中的,执行下列步骤来恢复:
- 使用 stream_parser 分析 ibdata 文件,分别得到每个页的文件。
$./stream_parser -f /home/zj118228/rds_5616/data/ibdata1
- 如表结构分析小节中所示,使用
c_parser分析系统表 SYS_TABLES 和 SYS_INDEXES ,根据表名得到 TABLE ID, 根据 TABLE ID 得到 INDEX ID。(INDEX ID 就是上述例子的第 5 列,值为 57 和 58) - 根据得到的 INDEX ID,到目录 pages-ibdata1 下去找对应的页号,这就是对应的索引表数据所在的数据页。
- 使用 c_parser 读取第 3 步得到的页文件,得到数据。
$./c_parser -6f pages-ibdata1/FIL_PAGE_INDEX/0000000000000065.page -t actor.sql
-- Page id: 579, Format: COMPACT, Records list: Valid, Expected records: (5 5)
000000005D95 E5000001960110 actor 201 "zhang" "jian" "2017-11-04 12:30:07" 000000005D96 E6000001970110 actor 202 "zhan" "jian" "2017-11-04 12:30:07" 000000005D98 E80000019A0110 actor 203 "zha" "jian" "2017-11-04 12:30:07" 000000005D99 E90000019B0110 actor 204 "zh" "jian" "2017-11-04 12:30:07" 000000005DA9 F1000002480110 actor 205 "z" "jian" "2017-11-04 12:30:08" 数据看起来没什么问题,表结构和数据都有了,导进去即可,看一下 checksum 也相同。
mysql> checksum table actor;
+-----------+------------+
| Table | Checksum |
+-----------+------------+
| per.actor | 2184463059 |
+-----------+------------+
1 row in set (0.00 sec)innodb_file_per_table on
这种情况下表是保存在各自的 ibd 文件中的,当 drop table 之后 ,ibd 文件会被删除,此时最好能够设置磁盘整体只读,避免有其它进程重写文件块。整体的恢复步骤和上一个小节(innodb_file_per_table off) 相同,只是无法从 pages-ibdata1 目录下面找到对应的 page 号。 假设已经完成了前两步,拿到了 INDEX ID。
stream_parser 这个工具不但可以读文件,还可以读磁盘,会根据 innodb 数据格式把数据页读出来。为了恢复 68 号数据页,我们执行下面几个步骤:
找到被删除的 ibd 文件的挂载磁盘 /dev/sda5:
$df
Filesystem 1K-blocks Used Available Use% Mounted on /dev/sda2 52327276 47003636 2702200 95% /
tmpfs 99225896 9741300 89484596 10% /dev/shm
/dev/sda1 258576 55291 190229 23% /boot
/dev/sda5 1350345636 1142208356 208137280 85% /home
/dev/sdb1 3278622264 2277365092 1001257172 70% /disk1
根据 INDEX ID , 磁盘大小执行
stream_parser,-t 表示磁盘的大小。$./stream_parser -f /dev/sda5 -s 1G -t 1142G
- 在目录 pages—sda5 下找到 68 号页,像上一个小节第 4 步一样恢复数据即可。
- <划重点> 测试了三次,有两次是恢复不出来的,因为文件很可能被其它进程重写,这取决于文件系统调度还有整体服务器的负载。
- 如果挂载的磁盘上还有其它 mysqld 的数据目录,那么很可能一个 page 文件会很大,监测到其它 ibd 文件的数据,同一个页号的综合在一起,这样辨别出我们需要的数据就比较麻烦。
文件页脏写
MySQL 每次从磁盘读取数据的时候都会进行 checksum 校验,如果校验失败,整个进程就会重启或者退出,校验失败很可能是文件页被脏写了。使用恢复工具直接读取文件很可能可以把未被脏写的行或者页读取出来,损失降到最低。
模拟脏写
同样使用目录 sakila/actor.sql 中的例子,innodb_per_file_table = on:
CREATE TABLE `actor` (
`actor_id` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`first_name` varchar(45) NOT NULL,
`last_name` varchar(45) NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`actor_id`),
KEY `idx_actor_last_name` (`last_name`)
) ENGINE=InnoDB AUTO_INCREMENT=201 DEFAULT CHARSET=utf8; insert into actor(first_name, last_name) values('zhang', 'jian'); insert into actor(first_name, last_name) values('zhan', 'jian'); insert into actor(first_name, last_name) values('zha', 'jian'); insert into actor(first_name, last_name) values('zh', 'jian'); insert into actor(first_name, last_name) values('z', 'jian'); 模拟脏写,打开 actor.ibd 文件, 使用 ‘#’ 覆盖其中一行数据,
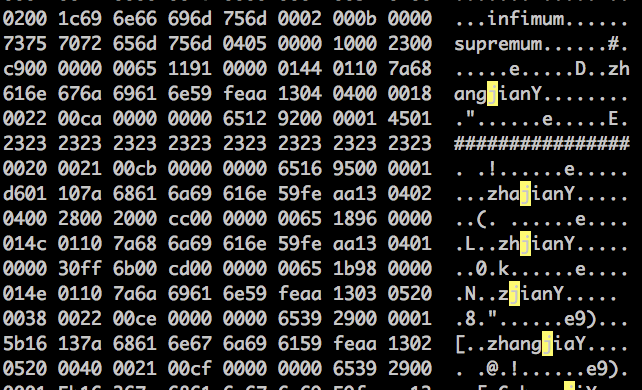
从系统表空间确定 INDEX ID (参考 表结构恢复 小节)
$./stream_parser -f /home/zj118228/rds_5616/data/ibdata1
$./stream_parser -f ~/rds_5616/data/per/actor.ibd
$./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000001.page -t dictionary/SYS_TABLES.sql
$./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000003.page -t dictionary/SYS_INDEXES.sql
INDEX ID 为 76,读取数据:
$./c_parser -6f pages-actor.ibd/FIL_PAGE_INDEX/0000000000000076.page -t sakila/actor.sql
看到有一行数据被 # 号覆盖,然后丢失了一行。
脏写之后数据库是起不来的,因为 ibd 文件已经损坏了,但此时我们已经拿到了恢复之后的数据,需要把恢复之后的数据导入到数据库里。导入之前删除 actor.ibd 文件,然后启动数据库后执行 drop table actor, 然后再重新创建表,导入数据即可。如果不小心把 frm 文件也删掉了,是没法 drop table 的,可以在其它数据库里建一个同名,结构相同的表生成 frm 文件,然后拷贝到被删除的目录下,然后再执行 drop table。参考:Troubleshooting
原理浅析
c_parser
恢复工具 c_parser 其实是按照 innodb 存储数据的格式来分析哪些是我们需要的数据本身,所以页上的数据可以分为两类:1. 用户数据 2. 元数据。而元数据的功能其实并不相同,有些损坏无伤大雅,有些损坏却可能导致整个页无法恢复。这里有几篇介绍Innodb 行记录格式1 and Innodb 行记录格式2 ,上一个小节中行记录格式是 Compact,来分析一下为什么会丢了一行数据。
这是完好的数据页,上面是脏写是把第 12 行数据全部覆盖了,根据 Compact 类型的格式,12 行末尾的 04 03 表示下一行变长数据类型(‘zha’ ‘jian’)的长度倒序,被覆盖之后当然无法解析,于是就丢了一行。那么为什么没有影响后续的行数据呢?第 13 行第 2 列的数据 21 表示下行数据的偏移,幸运的没有被覆盖。如果这个字节被覆盖,那么整个格式就乱了,无法解析。
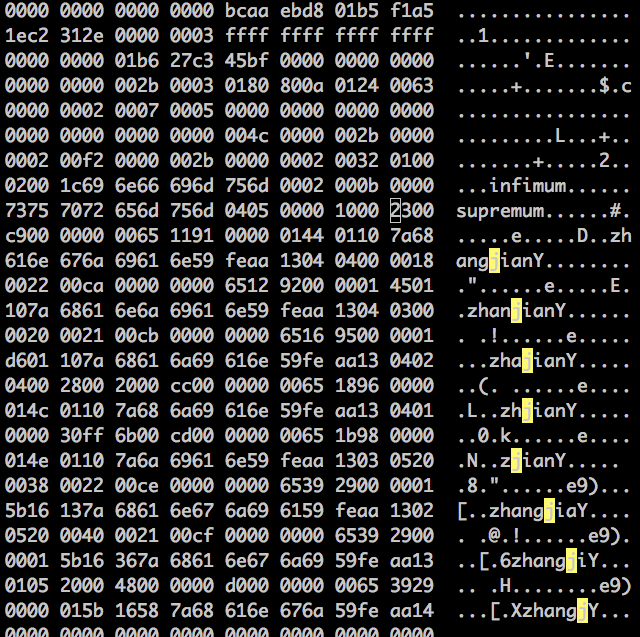
试了其它几种情况:
- 第六行第五列 004C 表示 page 的号,破坏之后 stream 出来的页号会变,所以从 Innodb 系统表得到的主键索引页号就不对了。
infimum和supremum破坏之后 stream 无法检测出页,所以根本产生不了可恢复的数据。
stream_parser
c_parser 是分析页面中用户的行数据,从参数中传入 CREATE TABLE 语句,根据定义的数据格式逐行解析,得到最终恢复的数据。而 stream_parser 是分析 ibd/ibdata 文件(或者挂载的磁盘),得到每一个数据页的。根据数据页的元数据,如果满足下列条件,就被认为是一个合法的 Innodb Index 数据页:
- 页面最开始前四个字节(checksum)不为 0
- 页面 5-8 字节(页面在 tablespace 中的偏移)不为零,且小于 (ib_size / UNIV_PAGE_SIZE) 最大偏移量,ibd 文件大小除以 Innodb 页大小。
- 在固定偏移处找到
infimum和supremum
参考 stream_parser.c 中的函数 valid_innodb_page, 关于 Blob page 判定条件略有不同,详细参考 valid_blob_page,这里以 Index page 为例。
得到一个合法的页后就以 UNIV_PAGE_SIZE 为大小写入到以 index_id 命名的文件中(也就是 c_parser 读入的页号判断标准)。
页数据格式
这里引用下登博画的大图:
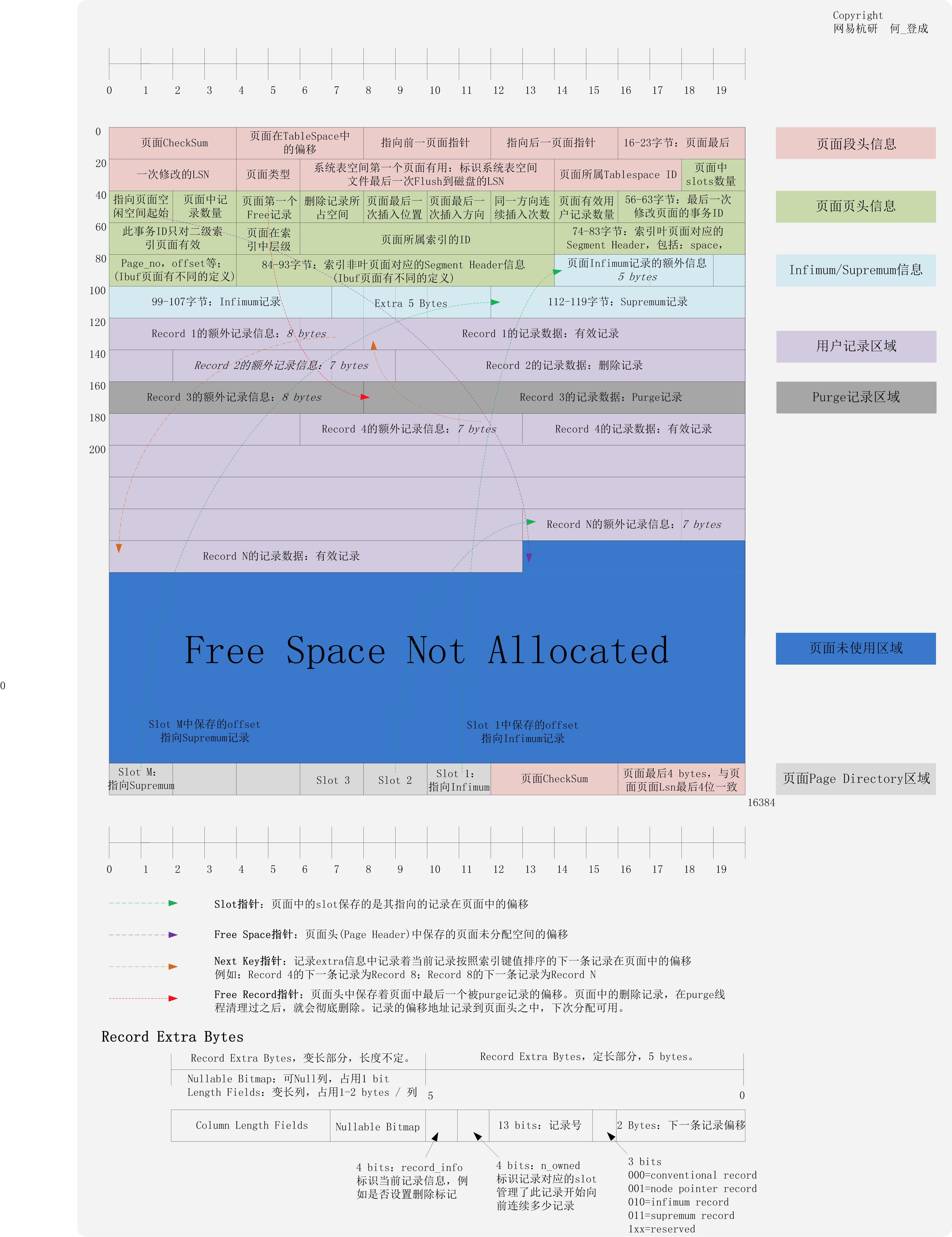
根据图中数据格式,如果页面前 8 字节被重写为 0 ,infimum 和 supremum 被写坏,stream_parser 无法检测出有效页。如果图中 Page_no 被写坏,那么我们从 Innodb 数据字典中获得的需要解析的文件页号恐怕就不对了,也不知道从那里去恢复。
所以这种恢复方式是寄托在重要页元数据和行元数据没有被脏写的前提下的,上述分析过后,重要的元数据所占比例较小,如果每个字节被脏写的概率相同,那么数据的可恢复性还是比较可观的。
最后,对于文件系统损坏或者磁盘 corruption,最重要的把数据拷贝出来,而不是去恢复文件系统或者磁盘,因为上述工具的恢复是基于数据的,参考这篇文章,第一时间使用 dd 命令制作磁盘镜像,再走上述的恢复流程即可。
原文地址: https://yq.aliyun.com/articles/281230?utm_content=m_37044
MySQL · 数据恢复 · undrop-for-innodb的更多相关文章
- 记一次揪心的MySQL数据恢复过程
https://blog.csdn.net/poxiaonie/article/details/78304699 === 先说下背景,公司其中一个项目所有服务都部署在客户的机房内,机房较小,没有UPS ...
- 《MySQL技术内幕:InnoDB存储引擎(第2版)》书摘
MySQL技术内幕:InnoDB存储引擎(第2版) 姜承尧 第1章 MySQL体系结构和存储引擎 >> 在上述例子中使用了mysqld_safe命令来启动数据库,当然启动MySQL实例的方 ...
- 重新学习MySQL数据库9:Innodb中的事务隔离级别和锁的关系
重新学习MySQL数据库9:Innodb中的事务隔离级别和锁的关系 Innodb中的事务隔离级别和锁的关系 前言: 我们都知道事务的几种性质,数据库为了维护这些性质,尤其是一致性和隔离性,一般使用加锁 ...
- mysql数据恢复:.frm和.ibd,恢复表结构和数据
mysql数据恢复:.frm和.ibd,恢复表结构和数据 一.恢复表结构 二.恢复表数据 相关内容原文地址: CSDN:她说巷尾的樱花开了:mysql根据.frm和.ibd文件恢复表结构和数据 博客园 ...
- [MySQL Reference Manual]14 InnoDB存储引擎
14 InnoDB存储引擎 14 InnoDB存储引擎 14.1 InnoDB说明 14.1.1 InnoDB作为默认存储引擎 14.1.1.1 存储引擎的趋势 14.1.1.2 InnoDB变成默认 ...
- 【mysql中myisam和innodb的区别】
单击进入源网页 要点摘要: 1.查看mysql存储引擎的状态mysql> show engines; 2.查看mysql默认的存储引擎mysql> show variables like ...
- mysql之show engine innodb status解读
注:以下内容为根据<高性能mysql第三版>和<mysql技术内幕innodb存储引擎>的innodb status部分的个人理解,如果有错误,还望指正!! innodb存 ...
- [mysql] mysql 5.6.27 innodb 相关参数
mysql> show variables like '%innodb%';+------------------------------------------+--------------- ...
- 关于MySQL的Myisam和Innodb的一些比较总结
总结一下MySQL的Myisam和Innodb引擎的一些差别,权当复习了. 首先二者在文件构成上: Myisam会存储三个文件:.frm 存储表结构,.MYD存储表的数据,.MYI文件存储表的索引:所 ...
- MySQL 5.5 禁用 innodb
MySQL 5.5 禁用 innodb 编辑: my.ini 添加: default-storage-engine=MYISAM skip-innodb
随机推荐
- docker仓库--使用tenxcloud
上传镜像 1. 在本地 docker 环境中输入以下命令进行登录 sudo docker login index.tenxcloud.com 2. 然后,对本地需要 push 的 image 进行标记 ...
- MapReduce几种提交方式
本地模式运行 1.在Windows里的IDE直接运行main方法,会将job提交给本地执行器localjobrunner执行 ---本地存放Hadoop安装包 ---输入输出数据可以放在本地路径下(c ...
- android开发学习笔记系列(1)-android起航
前言 在学习安卓的过程中,我觉得非常有必要将自己所学的东西进行整理,因为每每当我知道我应该是如何去实现功能的时候,有许多细节问题我总是会遗漏,因此我也萌生了写一系列博客来描述自己学习的路线,让我的an ...
- JavaScript unshift()函数移入数据到数组第一位
你不仅可以 shift(移出)数组中的第一个元素,你也可以 unshift(移入)一个元素到数组的头部. .unshift() 函数用起来就像 .push() 函数一样, 但不是在数组的末尾添加元素, ...
- 算法 - Catalan数 (卡特兰)
http://blog.csdn.net/linhuanmars/article/details/24761459 https://zh.wikipedia.org/wiki/%E5%8D%A1%E5 ...
- vue+element ui 的时间控件选择 年月日时分
前言:工作中用到 vue+element ui 的前端框架,需要选择年月日时分,但element ui官网demo有没有,所以记录一下.转载请注明出处:https://www.cnblogs.com/ ...
- AE三维点击查询(3D Identify)的实现(转)
AE三维点击查询(3D Identify)的实现,类似ArcGIS的Identify对话框/////////////////////////////////////////////////////// ...
- shiro标签的使用
guest标签 用户没有身份验证时显示相应信息,即游客访问信息. user标签 用户已经身份验证/记住我登录后显示相应的信息. authenticated标签 用户已经身份验证通过, ...
- 3D旋转效果
<!doctype html><html lang="en"><head> <meta charset="UTF-8&qu ...
- C# 新建文档CreateNewDocument
// Copyright 2010 ESRI// // All rights reserved under the copyright laws of the United States// and ...