Hive学习之路 (二十)Hive 执行过程实例分析
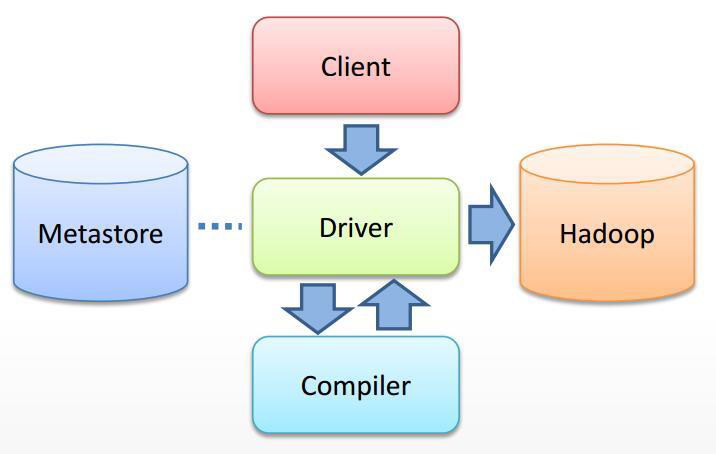
一、Hive 执行过程概述
1、概述
(1) Hive 将 HQL 转换成一组操作符(Operator),比如 GroupByOperator, JoinOperator 等
(2)操作符 Operator 是 Hive 的最小处理单元
(3)每个操作符代表一个 HDFS 操作或者 MapReduce 作业
(4)Hive 通过 ExecMapper 和 ExecReducer 执行 MapReduce 程序,执行模式有本地模式和分 布式两种模式
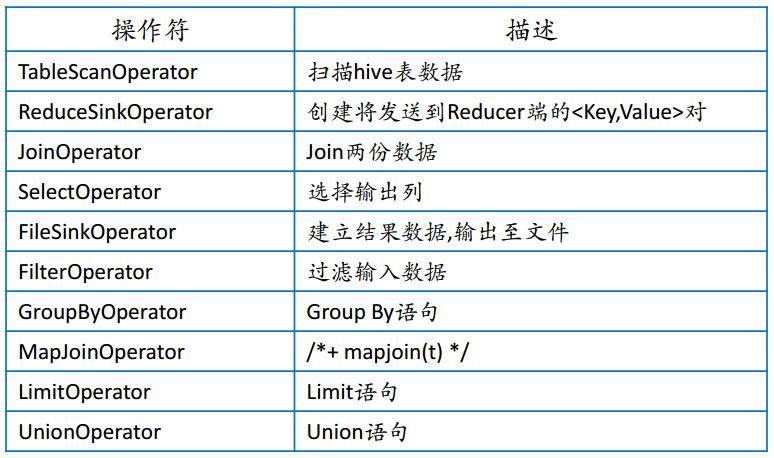
2、Hive 操作符列表
3、Hive 编译器的工作职责
(1)Parser:将 HQL 语句转换成抽象语法树(AST:Abstract Syntax Tree)
(2)Semantic Analyzer:将抽象语法树转换成查询块
(3)Logic Plan Generator:将查询块转换成逻辑查询计划
(4)Logic Optimizer:重写逻辑查询计划,优化逻辑执行计划
(5)Physical Plan Gernerator:将逻辑计划转化成物理计划(MapReduce Jobs)
(6)Physical Optimizer:选择最佳的 Join 策略,优化物理执行计划
4、优化器类型
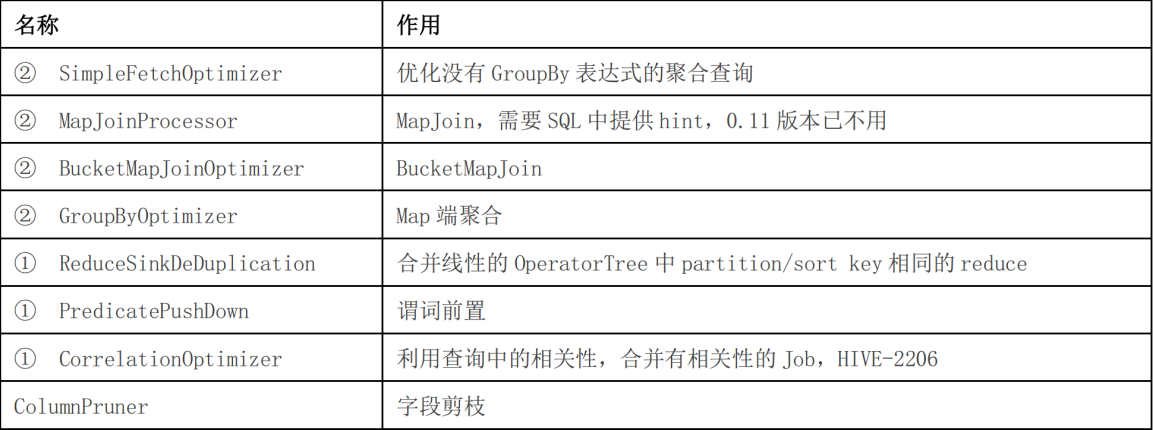
上表中带①符号的,优化目的都是尽量将任务合并到一个 Job 中,以减少 Job 数量,带②的 优化目的是尽量减少 shuffle 数据量
二、join
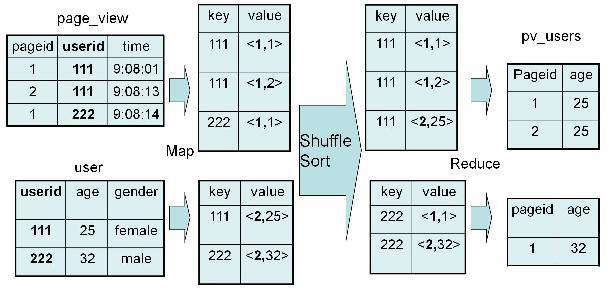
1、对于 join 操作
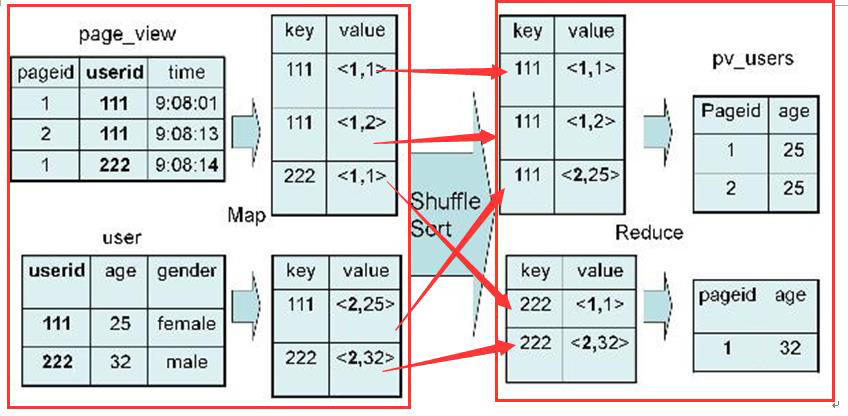
SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON pv.userid = u.userid;
2、实现过程
Map:
1、以 JOIN ON 条件中的列作为 Key,如果有多个列,则 Key 是这些列的组合
2、以 JOIN 之后所关心的列作为 Value,当有多个列时,Value 是这些列的组合。在 Value 中还会包含表的 Tag 信息,用于标明此 Value 对应于哪个表
3、按照 Key 进行排序
Shuffle:
1、根据 Key 的值进行 Hash,并将 Key/Value 对按照 Hash 值推至不同对 Reduce 中
Reduce:
1、 Reducer 根据 Key 值进行 Join 操作,并且通过 Tag 来识别不同的表中的数据
3、具体实现过程
三、Group By
1、对于 group by操作
SELECT pageid, age, count(1) FROM pv_users GROUP BY pageid, age;
2、实现过程
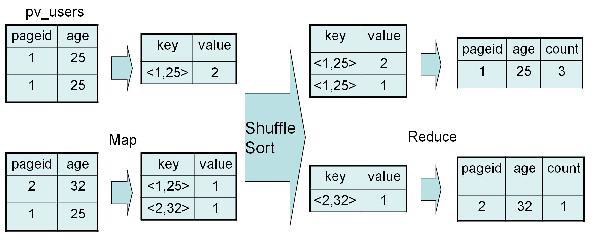
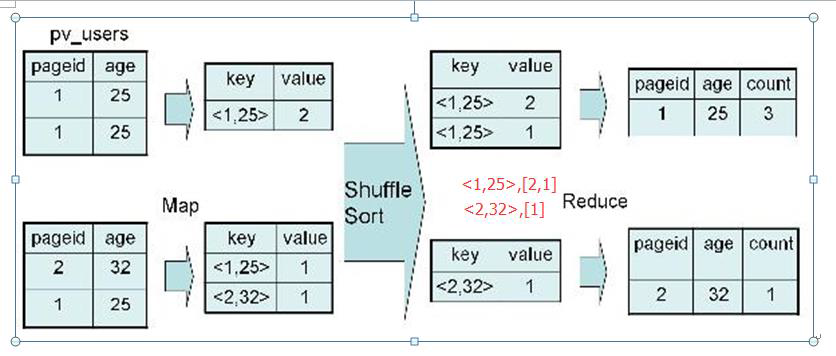
四、Distinct
1、对于 distinct的操作
按照 age 分组,然后统计每个分组里面的不重复的 pageid 有多少个
SELECT age, count(distinct pageid) FROM pv_users GROUP BY age;
2、实现过程
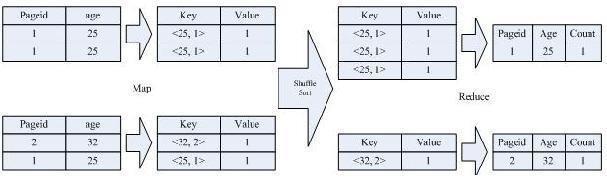
3、详细过程解释
该 SQL 语句会按照 age 和 pageid 预先分组,进行 distinct 操作。然后会再按 照 age 进行分组,再进行一次 distinct 操作
Hive学习之路 (二十)Hive 执行过程实例分析的更多相关文章
- Hive(六)hive执行过程实例分析与hive优化策略
一.Hive 执行过程实例分析 1.join 对于 join 操作:SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON (pv.useri ...
- Hive学习之路 (十八)Hive的Shell操作
一.Hive的命令行 1.Hive支持的一些命令 Command Description quit Use quit or exit to leave the interactive shell. s ...
- Hive(九)Hive 执行过程实例分析
一.Hive 执行过程概述 1.概述 (1) Hive 将 HQL 转换成一组操作符(Operator),比如 GroupByOperator, JoinOperator 等 (2)操作符 Opera ...
- Hadoop MapReduce执行过程实例分析
1.MapReduce是如何执行任务的?2.Mapper任务是怎样的一个过程?3.Reduce是如何执行任务的?4.键值对是如何编号的?5.实例,如何计算没见最高气温? 分析MapReduce执行过程 ...
- Hive学习之路 (十二)Hive SQL练习之影评案例
案例说明 现有如此三份数据:1.users.dat 数据格式为: 2::M::56::16::70072, 共有6040条数据对应字段为:UserID BigInt, Gender String, A ...
- Hive学习之路 (十四)Hive分析窗口函数(二) NTILE,ROW_NUMBER,RANK,DENSE_RANK
概述 本文中介绍前几个序列函数,NTILE,ROW_NUMBER,RANK,DENSE_RANK,下面会一一解释各自的用途. 注意: 序列函数不支持WINDOW子句.(ROWS BETWEEN) 数据 ...
- Hive学习之路 (十)Hive的高级操作
一.负责数据类型 1.array 现有数据如下: 1 huangbo guangzhou,xianggang,shenzhen a1:30,a2:20,a3:100 beijing,112233,13 ...
- Hive学习之路 (十九)Hive的数据倾斜
1.什么是数据倾斜? 由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点 2.Hadoop 框架的特性 A.不怕数据大,怕数据倾斜 B.Jobs 数比较多的作业运行效率相对比较低,如子查询比较 ...
- Hive学习之路 (十六)Hive分析窗口函数(四) LAG、LEAD、FIRST_VALUE和LAST_VALUE
数据准备 数据格式 cookie4.txt cookie1, ::,url2 cookie1, ::,url1 cookie1, ::,1url3 cookie1, ::,url6 cookie1, ...
随机推荐
- hdu Rescue 1242
Rescue Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Subm ...
- Java的工厂模式(一)
Java的工厂模式在框架中是用的到很多的,所谓的工厂模式,其实也就是用一个接口来创建对象,把实例化的工作推迟到子类去实现.这样在主函数中就可以直接创建一个工厂类,再通过这个工厂类实现操作. 假设有一个 ...
- js 数组删除元素,并获得真实长度
前言:js数组删除一般采用数组的 splice 方法和 delete 方法,但是采用 delete 方法后直接数组.kength 来获取数组长度是获取不了真实长度的,下面详细讲解一下. 一.splic ...
- IDEA 中将已有项目放到 GitHub 上去
前言:公司用的都是 idea+svn 来管理代码,所以家里尝试一下 idea+github 来管理.我的本地仓库是配置过ssh key,所以此处没有再次配置ssh key,如需配置可以参考 https ...
- kubernetes学习资源
参考文章: 1.kubernetes学习资源 1. <Kubernetes与云原生应用>系列之Kubernetes的系统架构与设计理念 2.[docker专业介绍的网站dockerinfo ...
- XML序列化与REST WCF Data Contract匹配时遇到的2个问题
问题一: XML序列化与RESTful WCF Data Contract不能匹配,无法传递类的值. 现象: 给类加上[Serializable]Attribute,可以成功序列化,但是WCF Ser ...
- vue的v-html插值样式问题
content使用html插入文本和图片 使用scoped样式,渲染失败. 原因: 解决方案: 采用全局样式 或另外再加style标签单独渲染
- nginx正确服务react-router应用
如今React应用普遍使用react-router作为路由管理,在开发端webpack自带的express服务器下运行和测试表现均正常,部署到线上的nginx服务器后,还需要对该应用在nginx的配置 ...
- HTML5之新增的属性和废除的属性 (声明:内容节选自《HTML 5从入门到精通》)
新增的属性 1.表单相关的属性 ———————————————————————————————————————————————————————— •autocomplete 属性 autocomple ...
- 从零开始学习html(四)认识标签(第三部分)
一.使用<a>标签,链接到另一个页面 <!DOCTYPE HTML> <html> <head> <meta http-equiv="C ...