python3之线程与进程
1、CPU运行原理
我们都知道CPU的根本任务就是执行指令,对计算机来说最终都是一串由“0”和“1”组成的序列。CPU从逻辑上可以划分成3个模块,分别是控制单元、运算单元和存储单元,这三部分由CPU内部总线连接起来:
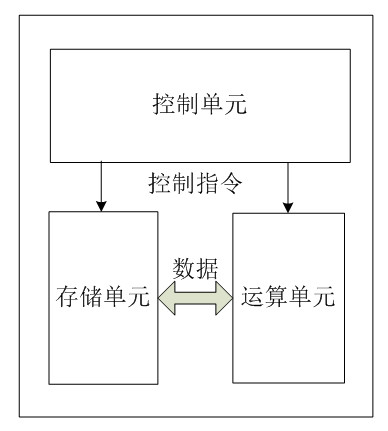
控制单元:控制单元是整个CPU的指挥控制中心,由指令寄存器IR(Instruction Register)、指令译码器ID(Instruction Decoder)和操作控制器OC(Operation Controller)等,对协调整个电脑有序工作极为重要。它根据用户预先编好的程序,依次从存储器中取出各条指令,放在指令寄存器IR中,通过指令译码(分析)确定应该进行什么操作,然后通过操作控制器OC,按确定的时序,向相应的部件发出微操作控制信号。操作控制器OC中主要包括节拍脉冲发生器、控制矩阵、时钟脉冲发生器、复位电路和启停电路等控制逻辑。
运算单元:是运算器的核心。可以执行算术运算(包括加减乘数等基本运算及其附加运算)和逻辑运算(包括移位、逻辑测试或两个值比较)。相对控制单元而言,运算器接受控制单元的命令而进行动作,即运算单元所进行的全部操作都是由控制单元发出的控制信号来指挥的,所以它是执行部件。
存储单元:包括CPU片内缓存和寄存器组,是CPU中暂时存放数据的地方,里面保存着那些等待处理的数据,或已经处理过的数据,CPU访问寄存器所用的时间要比访问内存的时间短。采用寄存器,可以减少CPU访问内存的次数,从而提高了CPU的工作速度。但因为受到芯片面积和集成度所限,寄存器组的容量不可能很大。寄存器组可分为专用寄存器和通用寄存器。专用寄存器的作用是固定的,分别寄存相应的数据。而通用寄存器用途广泛并可由程序员规定其用途,通用寄存器的数目因微处理器而异。
cpu的工作原理:
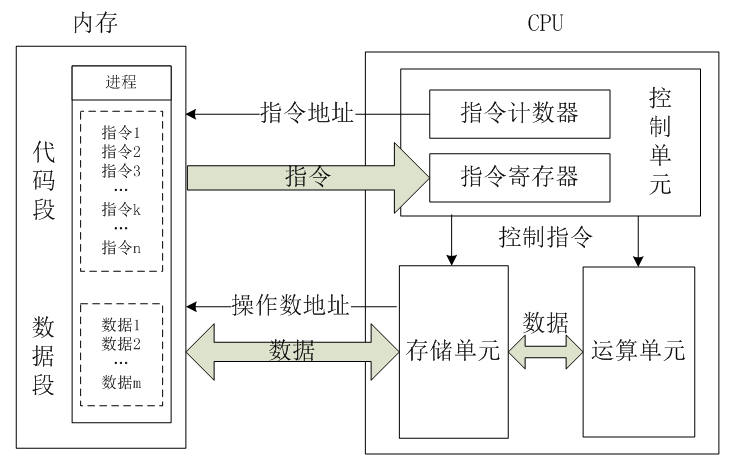
总的来说,CPU从内存中一条一条地取出指令和相应的数据,按指令操作码的规定,对数据进行运算处理,直到程序执行完毕为止。
控制单元在时序脉冲的作用下,将指令计数器里所指向的指令地址(这个地址是在内存里的)送到地址总线上去,然后CPU将这个地址里的指令读到指令寄存器进行译码。对于执行指令过程中所需要用到的数据,会将数据地址也送到地址总线,然后CPU把数据读到CPU的内部存储单元(就是内部寄存器)暂存起来,最后命令运算单元对数据进行处理加工。
cpu的工作效率:
基本上,CPU就是这样去执行读出数据、处理数据和往内存写数据3项基本工作。但在通常情况下,一条指令可以包含按明确顺序执行的许多操作,CPU的工作就是执行这些指令,完成一条指令后,CPU的控制单元又将告诉指令读取器从内存中读取下一条指令来执行。这个过程不断快速地重复,快速地执行一条又一条指令,产生你在显示器上所看到的结果。我们很容易想到,在处理这么多指令和数据的同时,由于数据转移时差和CPU处理时差,肯定会出现混乱处理的情况。为了保证每个操作准时发生,CPU需要一个时钟,时钟控制着CPU所执行的每一个动作。时钟就像一个节拍器,它不停地发出脉冲,决定CPU的步调和处理时间,这就是我们所熟悉的CPU的标称速度,也称为主频。主频数值越高,表明CPU的工作速度越快。
而在执行效率方面,一些厂商通过流水线方式或以几乎并行工作的方式执行指令的方法来提高指令的执行速度。刚才我们提到,指令的执行需要许多独立的操作,诸如取指令和译码等。最初CPU在执行下一条指令之前必须全部执行完上一条指令,而现在则由分布式的电路各自执行操作。也就是说,当这部分的电路完成了一件工作后,第二件工作立即占据了该电路,这样就大大增加了执行方面的效率。
另外,为了让指令与指令之间的连接更加准确,现在的CPU通常会采用多种预测方式来控制指令更高效率地执行。
2、线程与进程的区别
3、python3调用线程
Python3 通过两个标准库 _thread 和 threading 提供对线程的支持。
_thread 提供了低级别的、原始的线程以及一个简单的锁,它相比于 threading 模块的功能还是比较有限的。
threading 模块除了包含 _thread 模块中的所有方法外,还提供的其他方法:
- threading.currentThread(): 返回当前的线程变量。
- threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
- threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法:
- run(): 用以表示线程活动的方法。
- start():启动线程活动。
- join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
- isAlive(): 返回线程是否活动的。
- getName(): 返回线程名。
- setName(): 设置线程名。
- setDaemon():设置为后台线程或前台线程(默认)如果是后台线程,主线程执行过程中,后台线程也在执行,主线程执行完毕后,后台线程不论成功与否,均停止;如果是前台线程,主线程执行过程中,前台线程也在执行,主线程执行完毕后,等待前台线程也执行完成后,程序停止。
直接调用启动线程:
#!/usr/bin/env python
#coding:utf8 import threading #线程模块
import time def sayhi(num): #定义每个线程要运行的函数
print('running on number',num)
time.sleep(3) if __name__ == "__main__":
t1 = threading.Thread(target=sayhi,args=(33,)) #生成一个线程实例
t2 = threading.Thread(target=sayhi,args=(22,)) #生成另一个线程实例 t1.start() #启动线程
t2.start()
print(t1.getName()) #获取线程名
print(t2.getName())
t1.join() #阻塞主线程,等待t1子线程执行完后再执行后面的代码
t2.join() #阻塞主线程,等待t2子线程执行完后再执行后面的代码
print('-----end')
继承式调用启动线程:
#!/usr/bin/env python
#coding:utf8 import threading,time class mythreading(threading.Thread): #写一个类方法继承threading模块
def __init__(self):
#threading.Thread.__init__(self) #金典类重写父类方法
super(mythreading,self).__init__() #重写父类属性
self.name = n+self.name.split('d')[1] def run(self): #运行线程的函数,函数名必须是run名称
super(mythreading,self).run()
print('starting on threading',self.name)
time.sleep(5)
if __name__ == '__main__':
#t1 = mythreading(1) #通过类创建线程
#t2 = mythreading(2)
#t1.start() #启动进程
#t2.start()
ttr = []
for i in range(10): #启动十个线程
t = mythreading()
ttr.append(t)
t.start()
t.setName('hehe-{}'.format(i)) #修改线程名
print(t.getName()) #获取线程名 for item in ttr:
item.join() #阻断线程等待执行完后再执行后续代码 print('-----end')
守护线程:
#!/usr/bin/env python
#coding:utf8 import time
import threading def run(num): #子线程运行函数
print('---starting',num)
time.sleep(2)
print('---done')
def main(): #主线程运行函数
print('开启主线程')
for i in range(4): #在主线程中运行4个子线程
t1 = threading.Thread(target=run,args=(i,))
t1.start()
print('启动线程',t1.getName())
t1.join()
print('结束主线程')
m = threading.Thread(target=main,args=())
m.setDaemon(True) #设置主线程为守护线程
m.start()
m.join(timeout=3) #等待3秒后主线程退出,不管子线程是否运行完
print('------end') #output:
开启主线程
---starting 0
启动线程 Thread-2
---starting 1
启动线程 Thread-3
---starting 2
启动线程 Thread-4
---starting 3
启动线程 Thread-5
---done
---done
---done
---done
结束主线程
------end 进程已结束,退出代码0
(1)线程同步
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。
使用 Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。如下:
多线程的优势在于可以同时运行多个任务(至少感觉起来是这样)。但是当线程需要共享数据时,可能存在数据不同步的问题。
考虑这样一种情况:一个列表里所有元素都是0,线程”set”从后向前把所有元素改成1,而线程”print”负责从前往后读取列表并打印。
那么,可能线程”set”开始改的时候,线程”print”便来打印列表了,输出就成了一半0一半1,这就是数据的不同步。为了避免这种情况,引入了锁的概念。
锁有两种状态——锁定和未锁定。每当一个线程比如”set”要访问共享数据时,必须先获得锁定;如果已经有别的线程比如”print”获得锁定了,那么就让线程”set”暂停,也就是同步阻塞;等到线程”print”访问完毕,释放锁以后,再让线程”set”继续。
经过这样的处理,打印列表时要么全部输出0,要么全部输出1,不会再出现一半0一半1的尴尬场面。
锁提供如下方法:
1.Lock.acquire([blocking])
2.Lock.release()
3.threading.Lock() 加载线程的锁对象,是一个基本的锁对象,一次只能一个锁定,其余锁请求,需等待锁释放后才能获取
4.threading.RLock() 多重锁,在同一线程中可用被多次acquire。如果使用RLock,那么acquire和release必须成对出现, 调用了n次acquire锁请求,则必须调用n次的release才能在线程中释放锁对象。
import threading,time class mythread(threading.Thread):
def __init__(self,threadID,threadName):
super(mythread,self).__init__()
self.threadID = threadID
self.threadName = threadName
def run(self):
print('开启线程:',self.threadName)
threadLock.acquire() #获取线程锁
print_time(time.time(),self.threadName)
threadLock.release() #释放线程锁
def print_time(suntime,threadName):
for i in range(3):
time.sleep(2)
print('%s,,,%s'%(suntime,threadName)) threadLock = threading.Lock() #创建线程锁
t1 = mythread(1,'thread1') #创建线程1
t2 = mythread(2,'thread2')
t1.start() #启动线程
t2.start()
t1.join() #阻塞主线程,等待线程1完成
t2.join()
print('退出程序') #锁住运行线程函数后,会等待线程1执行完成后在执行线程2
#output
开启线程: thread1
开启线程: thread2
1516081515.3328698,,,thread1
1516081515.3328698,,,thread1
1516081515.3328698,,,thread1
1516081521.3341322,,,thread2
1516081521.3341322,,,thread2
1516081521.3341322,,,thread2
退出程序
from threading import Thread,Lock,RLock
import time class mythread(Thread):
def __init__(self,number1,number2):
super(mythread,self).__init__()
self.number1 = number1
self.number2 = number2 def run(self):
print('开启线程',self.name)
lock.acquire()
print('run is:',time.time(),self.number1+self.number2)
arithmetic(self.number1,self.number2)
time.sleep(2)
lock.release() def arithmetic(avg1,avg2):
lock.acquire()
print('arithmetic:',time.time(),avg1+avg2)
time.sleep(2)
lock.release() #创建锁对象时如果使用Lock则会在运行线程2时一直处于等待状态
#如果使用RLock则可正常运行,RLock支持多重锁
lock = RLock() #创建多重锁 if __name__ == "__main__":
t1 = mythread(3,4)
t2 = mythread(5,6)
t1.start()
t2.start()
t1.join()
t2.join()
print('程序结束!') #OUTPUT
开启线程 Thread-1
run is: 1516088282.0478237 7
arithmetic: 1516088282.0478237 7
开启线程 Thread-2
run is: 1516088286.0496652 11
arithmetic: 1516088286.0496652 11
程序结束!
(2)queue同步队列
该queue模块实现多生产者,多用户队列。当在多线程之间必须安全地交换信息时,它在线程编程中特别有用。该Queue模块中的类实现了所有必需的锁定语义
该模块实现三种类型的队列,它们的区别仅在于检索条目的顺序:
在FIFO队列中,第一个添加的任务是第一个被检索的。
在LIFO队列中,最后添加的条目是第一个被检索(像堆栈一样操作)。
使用优先级队列,条目保持排序(使用heapq模块),并且首先检索最低值的条目。
在内部,模块使用锁来暂时阻止竞争的线程; 但是,它不是为了处理线程内的重入而设计的;该queue模块定义了以下类:
- class
queue.Queue(maxsize = 0 ) -
FIFO队列的构造器。 maxsize是一个整数,用于设置可放入队列的项目数的上限。一旦达到此大小,插入将会阻塞,直到队列项被消耗。如果 maxsize小于或等于零,队列大小是无限的。
- class
queue.LifoQueue(maxsize = 0 ) -
LIFO队列的构造器。 maxsize是一个整数,用于设置可放入队列的项目数的上限。一旦达到此大小,插入将会阻塞,直到队列项被消耗。如果 maxsize小于或等于零,队列大小是无限的。
- class
queue.PriorityQueue(maxsize = 0 ) -
优先队列的构造函数。 maxsize是一个整数,用于设置可放入队列的项目数的上限。一旦达到此大小,插入将会阻塞,直到队列项被消耗。如果 maxsize小于或等于零,队列大小是无限的。
首先检索最低值的条目(最低值条目是返回的条目
sorted(list(entries))[0])。对于条目的典型图案的形式是一个元组:。(priority_number, data)
exception queue.Empty-
在空对象上调用非阻塞
get()(或get_nowait())时引发异常Queue。
exception queue.Full-
如果在已满的对象上调用非阻塞
put()(或put_nowait()),则会引发异常Queue。
队列对象(Queue,LifoQueue或PriorityQueue)提供以下的公共方法:
Queue.qsize()-
返回队列的大小。请注意,qsize()> 0并不保证后续的get()不会被阻塞,qsize()也不会保证put()不会被阻塞。
Queue.empty()-
如果队列为空则返回True,否则返回False。如果empty()返回True,则不保证对put()的后续调用不会被阻塞。同样,如果empty()返回False,则不保证后续调用get()不会被阻塞。
Queue.full()-
如果队列已满
则返回True,否则返回Fales。如果full()返回True,则不保证后续的get()调用不会被阻塞。同样,如果full()返回False它并不能保证后续调用put()不会被阻塞。
Queue.put(item,block = True,timeout = None )-
将项目放入队列中。如果可选参数block为True,并且timeout为
None(默认),则根据需要进行阻止,直到空闲插槽可用。如果 timeout是一个正数,则最多会阻塞timeout秒数,Full如果在此时间内没有空闲插槽,则会引发异常。否则(block为false),如果一个空闲插槽立即可用,则在队列中放置一个项目,否则引发Full异常(在这种情况下timeout被忽略)。
Queue.put_nowait(item )-
相当于。
put(item, False)
Queue.get(block = True,timeout = None )-
从队列中移除并返回一个项目。如果可选参数块为真,并且 timeout为
None(默认),则在必要时阻塞,直到项目可用。如果timeout是一个正数,则最多会阻塞timeout秒数,Empty如果在该时间内没有可用项目,则会引发异常。否则(block为false),返回一个项目,如果一个是立即可用的,否则引发Empty异常(在这种情况下timeout被忽略)。
Queue.get_nowait()-
相当于
get(False)。
提供了两种方法来支持跟踪入队任务是否已完全由守护进程消费者线程处理。
Queue.task_done()-
表明以前排队的任务已经完成。由队列消费者线程使用。对于每个
get()用于获取任务的对象,随后的调用都会task_done()告诉队列,任务的处理已完成。如果a
join()当前被阻塞,则在处理所有项目时(意味着task_done()已经接收到已经put()进入队列的每个项目的呼叫),则将恢复。提出了一个
ValueError好象叫更多的时间比中放入队列中的项目。
Queue.join()-
阻塞,直到队列中的所有项目都被获取并处理。
每当将项目添加到队列中时,未完成任务的数量就会增加。只要消费者线程调用
task_done()来指示该项目已被检索,并且所有工作都已完成,计数就会减少。当未完成任务的数量下降到零时,join()取消阻止。
#Queue先进先出队列
import queue
def show(q,i):
if q.empty() or q.qsize() >= 1:
q.put(i) #存队列
elif q.full():
print('queue not size') que = queue.Queue(5) #允许5个队列的队列对象
for i in range(5):
show(que,i)
print('queue is number:',que.qsize()) #队列元素个数
for j in range(5):
print(que.get()) #取队列
print('......end') #output:
queue is number: 5
0
1
2
3
4
......end
#LifoQueue先进后出队列 import queue lifoque = queue.LifoQueue()
lifoque.put('hello1')
lifoque.put('hello2')
lifoque.put('hello3')
print(lifoque.qsize())
print(lifoque.get())
print(lifoque.get())
print(lifoque.get()) #output:
3
hello3
hello2
hello1
#PriorityQueue按数据大小取最小值优先 import queue pque = queue.PriorityQueue() #优先级的队列
pque.put(7) #先存入队列
pque.put(5)
pque.put(3)
print(pque.qsize())
print(pque.get()) #取出最小值的数据
print(pque.get())
print(pque.get()) #output:
3
22
52
71
(3)信号量(Semaphore)
Lock锁是同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据,如一个场所内只有3把椅子给人坐,那么只允许3个人,其它人则排队,只有等里面的人出来后才能进去。
import threading,time
class mythreading(threading.Thread): #写一个类方法继承hreading模块
def run(self): #运行线程的函数,函数名必须是run名称
semaphore.acquire() #获取信号量锁
print('running the thread:',self.getName())
time.sleep(2)
semaphore.release() #释放信号量锁 if __name__ == '__main__':
semaphore = threading.BoundedSemaphore(3) #创建信号量对象,只运行3个进程同时运行
for i in range(20):
t1 = mythreading()
t1.start()
t1.join()
print('---end')
threading模块的Timer方法,在经过一定时间后才能运行的操作,一般只针对函数运行。
import threading def run():
print('is running...') t=threading.Timer(5.0,run) #等待5秒后执行函数
t.start()
(4)事件(event)
python线程的事件用于主线程控制其它线程的执行,事件主要提供了三个方法:
event.wait 线程阻塞
event.set 将全局对象“Flag”设置为False
event.clear 将全局对象"Flag"设置为True
事件处理的机制:全局定义了一个“Flag”,默认为“False”,如果“Flag”值为 False,那么当程序执行 event.wait 方法时就会阻塞,如果“Flag”值为True,那么event.wait 方法时便不再阻塞。
#!/usr/bin/env python
#coding:utf8 import threading
def show(event):
print('start')
event.wait() #阻塞线程执行程序
print('done')
event_obj = threading.Event() #创建event事件对象
for i in range(10):
t1 = threading.Thread(target=show,args=(event_obj,))
t1.start()
inside = input('>>>:')
if inside == '':
event_obj.set() #当用户输入1时,set全局Flag为True,线程不再阻塞,打印"done"
event_obj.clear() #将Flag设置为False
(5)条件(Condition)
使得线程等待,只有满足某条件时,才释放N个线程
import threading
def condition_func():
ret = False
inp = input('>>>:')
if inp == '':
ret = True
return ret def run(n):
con.acquire() #条件锁
con.wait_for(condition_func) #判断条件
print('running...',n)
con.release() #释放锁
print('------------') if __name__ == '__main__':
con = threading.Condition() #建立线程条件对象
for i in range(10):
t = threading.Thread(target=run,args=(i,))
t.start()
t.join()
print('退出程序')
4、python3进程调用
multiprocessing是一个使用类似于threading模块的API来支持多进程。该multiprocessing软件包提供本地和远程并发,通过使用子进程来充分利用服务器上的多个处理器,它可以在Unix和Windows上运行。
class multiprocessing.Process(group = None,target = None,name = None,args =(),kwargs = {},*,daemon = None )
过程对象表示在单独的过程中运行的活动。这个 Process类的所有方法的等价与 threading.Thread。
应始终使用关键字参数调用构造函数。群体 应该永远是None; 它仅仅是为了兼容而存在 threading.Thread。 target是run()方法调用的可调用对象。它默认为None,意味着什么都不叫。name是进程名称(name更多细节见)。 args是目标调用的参数元组。 kwargs是目标调用的关键字参数字典。如果提供,则仅关键字守护进程参数将进程daemon标志设置为True或False。如果None(默认),这个标志将从创建过程继承。
默认情况下,没有参数传递给目标。
如果一个子类重写了构造函数,那么必须确保它Process.__init__()在执行任何其他操作之前调用基类的构造函数()。
在版本3.3中进行了更改:添加了守护进程参数。
run()-
表示进程活动的方法。
您可以在子类中重写此方法。标准
run()方法调用传递给对象构造函数的可调用对象作为目标参数,如果有的话,分别从args和kwargs参数中获取顺序和关键字参数。
start()-
开始进程的活动。
每个进程对象最多只能调用一次。它安排对象的
run()方法在一个单独的进程中被调用。
join([ timeout ] )-
如果可选参数timeout是
None(缺省值),则该方法将阻塞,直到其join()方法被调用的进程终止。如果超时是一个正数,它最多会阻塞超时秒数。请注意,None如果方法终止或方法超时,则方法返回。检查流程exitcode,确定是否终止。一个过程可以连接多次。
进程无法自行加入,因为这会导致死锁。尝试在启动之前加入进程是错误的。
name-
该进程的名称。名称是一个字符串,仅用于识别目的。它没有语义。多个进程可以被赋予相同的名称。
初始名称由构造函数设置。如果没有明确的名字被提供给构造函数,就会构造一个名为“Process-N 1:N 2:...:N k ” 的表单,其中每个N k是其父代的第N个孩子。
is_alive()-
返回进程是否存在;从
start()方法返回的那一刻起,一个进程对象是活着的,直到子进程终止。
daemon-
进程的守护进程标志,一个布尔值。这必须在
start()调用之前设置 。初始值是从创建过程继承的。当进程退出时,它将尝试终止其所有守护进程的子进程。
请注意,守护进程不允许创建子进程。否则,如果父进程退出时被终止,则守护进程将使其子进程成为孤儿。此外,这些不是 Unix守护进程或服务,它们是正常的进程,如果非守护进程已经退出,它将被终止(而不是加入)。
除了 threading.ThreadAPI之外,Process对象还支持以下属性和方法:
pid-
返回进程ID。在这个过程产生之前,这将是
None。
exitcode-
孩子的退出代码。这将是
None如果过程还没有结束。负值-N表示孩子被信号N终止。
authkey-
进程的身份验证密钥(一个字节字符串)。
当
multiprocessing初始化主进程正在使用分配一个随机串os.urandom()。当一个
Process对象被创建时,它会继承父进程的认证密钥,尽管这可以通过设置authkey成另一个字节字符串来改变。请参阅验证密钥。
sentinel-
系统对象的数字句柄,当进程结束时它将变为“就绪”。
如果您想一次使用多个事件,则可以使用此值
multiprocessing.connection.wait()。否则,调用join()更简单。在Windows中,这是与使用的OS手柄
WaitForSingleObject和WaitForMultipleObjects家庭的API调用。在Unix上,这是一个可用于select模块原语的文件描述符。3.3版本中的新功能
terminate()-
终止这个进程。在Unix上,这是使用
SIGTERM信号完成的。在WindowsTerminateProcess()上使用。请注意,退出处理程序和最后的子句等将不会被执行。
需要注意的是start(),join(),is_alive(), terminate()和exitcode方法只能由创建进程对象的过程调用。
异常:
exception multiprocessing.ProcessError-
所有
multiprocessing异常的基类。
exceptionmultiprocessing.BufferTooShort-
Connection.recv_bytes_into()当提供的缓冲区对象太小而不能读取消息时引发异常。如果
e是的一个实例BufferTooShort,然后e.args[0]会给出消息作为字节串。
exception multiprocessing.AuthenticationError-
发生认证错误时引发。
exception multiprocessing.TimeoutError-
当超时到期时由超时方法提出。
创建10个并发进程:
from multiprocessing import Process def proce(pn):
print('hello',pn) if __name__ == '__main__':
for i in range(10): #启动10个进程
p1 = Process(target=proce,args=(i,)) #创建进程
p1.start() #启动进程
#print('nn:',p1.name)
p1.join() #等待进程结束
print('exit project')
打印进程ID:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/1/17 14:15
# @Author : Py.qi
# @File : 进程ID.py
# @Software: PyCharm from multiprocessing import Process
import os def info(title):
print(title)
print('module name',__name__) #是否主程序
print('parent process',os.getppid()) #上层进程号
print('process id:',os.getpid()) #自身进程号 def f(name):
info('function f')
print('hello',name)
if __name__ == '__main__':
info('main line') #通过pycharm进程运行函数
p = Process(target=f,args=('bob',)) #调用子进程运行函数
p.start()
p.join() #output:
main line
module name __main__
parent process 5756 #pycharm进程号
process id: 9864 #自身进程 function f
module name __mp_main__
parent process 9864
process id: 9024 #文件创建的进程号
hello bob
(1)上下文和启动方法
multiprocessing支持三种启动流程的方式:
spawn:
父进程启动一个新鲜的Python解释器进程。子进程只会继承运行进程对象run()方法所必需的资源。特别是父进程中不必要的文件描述符和句柄将不会被继承。与使用fork或forkserver相比,使用此方法启动进程相当慢。
在Unix和Windows上可用。Windows上是默认的。
fork:
父进程使用os.fork()fork来解释Python。子进程在开始时与父进程有效地相同。父进程的所有资源都由子进程继承。请注意,安全分叉多线程的过程是有问题的。
仅在Unix上提供。Unix上是默认的。
forkserver:
当程序启动并选择forkserver启动方法时,启动一个服务器进程。从那时起,无论何时需要一个新的进程,父进程都连接到服务器并请求它分叉一个新的进程。fork服务器进程是单线程的,所以它是安全的使用os.fork()。没有不必要的资源被继承。
在支持通过Unix管道传递文件描述符的Unix平台上可用。
在3.4版中进行了更改:在所有unix平台上添加了spawn,并为某些unix平台添加了forkserver。子进程不再继承Windows上的所有父代继承句柄。
在Unix上,使用spawn或forkserver启动方法也将启动一个信号量跟踪器进程,该进程跟踪程序进程创建的未链接的已命名信号量。当所有进程退出信号量跟踪器时,将取消所有剩余信号量的链接。通常应该没有,但如果一个进程被一个信号杀死,那么可能会有一些“泄漏”的信号量。(取消链接命名的信号量是一个严重的问题,因为系统只允许有限的数量,并且在下一次重新启动之前它们不会自动断开连接。)
在主模块中使用set_start_method()的启动方法:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/1/17 15:44
# @Author : Py.qi
# @File : set_start1.py
# @Software: PyCharm import multiprocessing as mp def foo(q): #传递队列对象给函数
q.put('hello')
q.put('')
q.put('python')
if __name__ == '__main__':
mp.set_start_method('spawn') #设置启动进程方式
q = mp.Queue() #创建队列对象
p = mp.Process(target=foo, args=(q,)) #启动一个进程,传递运行函数和参数
p.start() #启动进程
print(q.get()) #获取队列数据
print(q.qsize())
print(q.get())
p.join()
set_start_method()不能在程序中使用多次,可以使用get_context()获取上下文对象,上下文对象与多处理模块具有相同的API,并允许在同一个程序中使用多个启动方法。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/1/18 13:14
# @Author : Py.qi
# @File : get_context_1.py
# @Software: PyCharm import multiprocessing as mp
import time def foo(q):
for i in range(10):
q.put('python%s'%i)
time.sleep(1)
#q.put('context')
if __name__ == '__main__':
ext = mp.get_context('spawn')
q = ext.Queue()
p = ext.Process(target=foo,args=(q,))
p2 = ext.Process(target=foo,args=(q,))
p.start()
p2.start()
for i in range(10):
print(q.get())
#print(q.get())
#print(q.get())
#print(q.get())
#print(q.get())
p.join()
p2.join() #output:
python0
python0
python1
python1
python2
python2
python3
python3
python4
python4
请注意,与一个上下文相关的对象可能与另一个上下文的进程不兼容。特别是,使用fork上下文创建的锁不能被传递给使用spawn或forkserver启动方法启动的进程 。
想要使用特定启动方法的库应该可以get_context()用来避免干扰库用户的选择。
(1)进程之间交换对象
multiprocessing 支持两种进程之间的通讯通道:
class multiprocessing.Queue([ maxsize ] )
返回使用管道和一些锁/信号量实现的进程共享队列。当一个进程首先把一个项目放到队列中时,一个进给线程被启动,将一个缓冲区中的对象传送到管道中。
Queue实现queue.Queue除了task_done()和之外的 所有方法join()。
qsize()-
返回队列的近似大小。由于多线程/多处理语义,这个数字是不可靠的。
请注意,
NotImplementedError在Mac OS X等Unix平台上可能会出现这种sem_getvalue()情况。
empty()-
True如果队列为空False则返回,否则返回。由于多线程/多处理语义,这是不可靠的。
full()-
True如果队列已满False则返回,否则返回。由于多线程/多处理语义,这是不可靠的。
put(obj [,block [,timeout ] ] )-
将obj放入队列中。如果可选参数块是
True(缺省值)并且超时是None(缺省值),则在需要时禁止,直到空闲插槽可用。如果超时是一个正数,则最多会阻塞超时秒数,queue.Full如果在此时间内没有空闲插槽,则会引发异常。否则(块是False),如果一个空闲插槽立即可用,则在队列中放置一个项目,否则引发queue.Full异常(在这种情况下超时被忽略)。
put_nowait(obj )-
相当于。
put(obj, False)
get([ block [,timeout ] ] )-
从队列中移除并返回一个项目。如果可选ARGS 块是
True(默认值),超时是None(默认),块如有必要,直到一个项目是可用的。如果超时是一个正数,则最多会阻塞超时秒数,queue.Empty如果在该时间内没有可用项目,则会引发异常。否则(块是False),返回一个项目,如果一个是立即可用的,否则引发queue.Empty异常(在这种情况下超时被忽略)。
get_nowait()-
相当于
get(False)。
multiprocessing.Queue有一些其他的方法没有找到 queue.Queue。大多数代码通常不需要这些方法:
close()-
表明当前进程不会有更多的数据放在这个队列中。一旦将所有缓冲的数据刷新到管道,后台线程将退出。当队列被垃圾收集时,这被自动调用。
join_thread()-
加入后台线程。这只能在
close()被调用后才能使用。它阻塞,直到后台线程退出,确保缓冲区中的所有数据已经刷新到管道。默认情况下,如果一个进程不是队列的创建者,那么在退出时它将尝试加入队列的后台线程。该过程可以调用
cancel_join_thread()做出join_thread()什么也不做。
cancel_join_thread()-
防止
join_thread()阻塞。尤其是,这可以防止后台线程在进程退出时自动加入
class multiprocessing.SimpleQueue
empty()-
True如果队列为空False则返回,否则返回。
get()-
从队列中移除并返回一个项目。
put(item )-
将元素放入队列中。
class multiprocessing.JoinableQueue([ maxsize ] )
JoinableQueue,一个Queue子类,是另外有一个队列task_done()和join()方法。
task_done()-
表明以前排队的任务已经完成。由队列使用者使用。对于每个
get()用于获取任务的对象,随后的调用都会task_done()告诉队列,任务的处理已完成。如果a
join()当前被阻塞,则在处理所有项目时(意味着task_done()已经接收到已经put()进入队列的每个项目的呼叫),则将恢复。提出了一个
ValueError好象叫更多的时间比中放入队列中的项目。
join()-
阻塞,直到队列中的所有项目都被获取并处理。
每当将项目添加到队列中时,未完成任务的数量就会增加。每当消费者打电话
task_done()表明该物品已被检索并且所有工作都已完成时,计数就会下降 。当未完成任务的数量下降到零时,join()取消阻止。
multiprocessing.active_children()-
返回当前进程的所有活动的列表。调用这个函数有“加入”已经完成的任何进程的副作用。
multiprocessing.cpu_count()-
返回系统中的CPU数量。可能会提高
NotImplementedError。
multiprocessing.current_process()-
返回
Process当前进程对应的对象。一个类似的threading.current_thread()。
multiprocessing.freeze_support()-
添加对何时使用的程序
multiprocessing进行冻结以产生Windows可执行文件的支持。(已经用py2exe, PyInstaller和cx_Freeze进行了测试。)需要在主模块后面直接调用这个函数:if __name__ == '__main__'freeze_support()在Windows以外的操作系统上调用时,调用不起作用。另外,如果模块正在通过Windows上的Python解释器正常运行(程序还没有被冻结),那么这个模块freeze_support()没有任何作用。
multiprocessing.get_all_start_methods()-
返回支持的启动方法的列表,其中第一个是默认的。可能的启动方法是
'fork','spawn'和'forkserver'。在Windows上只'spawn'可用。在Unix上'fork'并且'spawn'始终受支持,并且'fork'是默认的。3.4版本中的新功能
multiprocessing.get_context(method = None )-
返回与
multiprocessing模块具有相同属性的上下文对象 。如果方法是
None那么返回默认的上下文。否则,方法应该是'fork','spawn','forkserver'。ValueError如果指定的启动方法不可用,则引发。3.4版本中的新功能
multiprocessing.get_start_method(allow_none = False )-
返回用于启动进程的启动方法的名称。
如果start方法没有被修复,并且allow_none为false,那么start方法被固定为默认值,并返回名称。如果start方法没有被修复,并且allow_none 为true,则
None返回。返回值可以是
'fork','spawn','forkserver'或None。'fork'在Unix上是默认的,而'spawn'在Windows上是默认的。3.4版本中的新功能
multiprocessing.set_executable()-
设置启动子进程时使用的Python解释器的路径。(默认
sys.executable使用)。嵌入可能需要做一些事情set_executable (OS ,路径,加入(SYS 。exec_prefix , 'pythonw.exe' ))
才可以创建子进程。在版本3.4中更改:现在在Unix上支持
'spawn'启动方法时使用。
multiprocessing.set_start_method(method)-
设置应该用来启动子进程的方法。 方法可以
'fork','spawn'或者'forkserver'。请注意,这应该至多被调用一次,并且应该在主模块的子句内受到保护。
if __name__ == '__main__'3.4版本中的新功能
Queue(队列):这个Queue类为queue.Queue的克隆
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/1/18 13:40
# @Author : Py.qi
# @File : queue_pbet.py
# @Software: PyCharm from multiprocessing import Process,Queue def f(q):
q.put([42, None, 'hello'])
q.put('python')
q.put('python3')
if __name__ == '__main__':
q = Queue() #创建队列对象
p = Process(target=f, args=(q,)) #新进程
p.start()
print(q.get()) # prints "[42, None, 'hello']"
print(q.get())
print(q.get())
p.join()
Pipes(管道):该Pipe()函数返回一对由默认为双工(双向)的管道连接的连接对象。
连接对象允许发送和接收可选对象或字符串。他们可以被认为是面向消息的连接套接字。
连接对象通常使用创建Pipe()
class multiprocessing.Connection
send(obj )-
将对象发送到应该读取的连接的另一端
recv()。该对象必须是可挑选的。非常大的包(大约32 MB +,虽然取决于操作系统)可能会引发
ValueError异常。
fileno()-
返回连接使用的文件描述符或句柄。
close()-
关闭连接。
当连接被垃圾收集时,这被自动调用。
poll([ timeout ] )
返回是否有可读的数据。
如果没有指定超时,则会立即返回。如果超时是一个数字,那么这指定了以秒为单位的最大时间来阻止。如果timeout,None则使用无限超时。
请注意,可以使用一次轮询多个连接对象multiprocessing.connection.wait()。
send_bytes(buffer [,offset [,size ] ] )
-
从类似字节的对象发送字节数据作为完整的消息。
如果给出偏移量,则从缓冲区中的该位置读取数据。如果 给定大小,那么将从缓冲区中读取多个字节。非常大的缓冲区(大约32 MB +,但取决于操作系统)可能会引发
ValueError异常
recv_bytes([ maxlength ] )-
将连接另一端发送的字节数据的完整消息作为字符串返回。阻止,直到有东西要接收。
EOFError如果没有什么可以接收,而另一端已经关闭,就会引发。如果最大长度被指定并且所述消息是长于最大长度 然后
OSError升至并连接将不再是可读的。
recv_bytes_into(buffer [,offset ] )-
从连接的另一端读取缓冲区中的字节数据的完整消息,并返回消息中的字节数。阻止,直到有东西要接收。提出
EOFError,如果没有什么留下来接收,而另一端被关闭。缓冲区必须是一个可写的字节类对象。如果 给出了偏移量,则消息将从该位置写入缓冲区。偏移量必须是小于缓冲区长度的非负整数(以字节为单位)。
如果缓冲区太短,则
BufferTooShort引发异常,并且完整的消息可用, 异常实例e.args[0]在哪里e。
在版本3.3中更改:现在可以使用Connection.send()和在进程之间传输连接对象本身Connection.recv()。
3.3版本中的新功能:连接对象现在支持上下文管理协议 - 请参阅 上下文管理器类型。 __enter__()返回连接对象,并__exit__()调用close()。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/1/18 13:50
# @Author : Py.qi
# @File : queue_pipes.py
# @Software: PyCharm from multiprocessing import Process,Pipe def f(parent,child):
parent.send('parent1') #父链接写入数据
parent.send('parent2')
child.send('python1') #子链接写入数据
child.send('python2')
parent.close() #关闭管道
child.close() if __name__ == '__main__':
parent_conn, child_conn = Pipe() #创建父和子管道连接
p = Process(target=f, args=(parent_conn,child_conn))
p.start()
print(parent_conn.recv()) #从父链接收的数据是从子链接写入的数据
print(parent_conn.recv())
print(child_conn.recv()) #从子链接收的数据是从父链接写入的数据
print(child_conn.recv())
p.join()
Pipe()返回两个连接对象,表示管道的两端(parent_conn)为头,(child_conn)为尾。这两个连接对象都有send()和recv()方法等。请注意:如果两个或多个进程(线程)试图同时读取或写入管道的同一端,则管道中的数据可能会损坏,可以同时使用管道的头和尾流程式的读取和写入数据就没有问题了。
(2)进程之间的同步
通常,同步原语在多进程程序中并不像在多线程程序中那样必要;也可以使用管理器对象创建同步基元。
- class
multiprocessing.Barrier(parties [,action [,timeout ] ] ) -
屏蔽对象:一个克隆的
threading.Barrier。3.3版本中的新功能
- class
multiprocessing.BoundedSemaphore([ value ] ) -
一个有界的信号量对象
threading.BoundedSemaphore。与其相近的模拟存在单一差异:其acquire方法的第一个参数是命名块,与之一致Lock.acquire()。注意:在Mac OS X上,这是无法区分的,
Semaphore因为sem_getvalue()没有在该平台上实现。
- class
multiprocessing.Condition([ lock ] ) -
一个条件变量:一个别名
threading.Condition。如果指定了锁,那么它应该是一个Lock或一个RLock对象multiprocessing。在版本3.3中更改:该wait_for()方法已添加。
class multiprocessing.Event-
克隆的
threading.Event。
class multiprocessing.Lock-
一个非递归锁对象:一个非常类似的
threading.Lock。一旦一个进程或线程获得一个锁,随后的尝试从任何进程或线程获取它将被阻塞,直到它被释放; 任何进程或线程可能会释放它。threading.Lock应用于线程的概念和行为在 这里被复制,multiprocessing.Lock因为它适用于进程或线程,除非指出。请注意,这
Lock实际上是一个工厂函数,它返回一个multiprocessing.synchronize.Lock使用默认上下文初始化的实例。acquire(block = True,timeout = None )-
获取一个锁,阻塞或不阻塞。
在block参数设置为
True(默认)的情况下,方法调用将被阻塞直到锁处于解锁状态,然后将其设置为锁定并返回True。请注意,这第一个参数的名称不同于threading.Lock.acquire()。将块参数设置为
False,方法调用不会阻止。如果锁目前处于锁定状态,则返回False; 否则将锁设置为锁定状态并返回True。当用正值,浮点值超时调用时,只要无法获取锁定,最多只能阻塞超时指定的秒数。具有负值的超时调用 相当于超时零。超时值
None(默认值)的调用 将超时期限设置为无限。请注意,处理负值或超时None值 与实施的行为不同 。该超时参数有,如果没有实际意义块参数被设置为,并因此忽略。返回threading.Lock.acquire()FalseTrue如果锁已被获取或False超时时间已过。
release()-
释放一个锁。这可以从任何进程或线程调用,不仅是最初获取锁的进程或线程。
threading.Lock.release()除了在解锁的锁上调用a时,行为与其相同ValueError。
class multiprocessing.RLock-
递归锁对象:一个紧密的类比
threading.RLock。递归锁必须由获取它的进程或线程释放。一旦一个进程或线程获得递归锁定,相同的进程或线程可以再次获得它,而不会阻塞; 该进程或线程必须每次释放一次它被获取。请注意,这
RLock实际上是一个工厂函数,它返回一个multiprocessing.synchronize.RLock使用默认上下文初始化的实例。RLock支持上下文管理器协议,因此可以用在with语句中。acquire(block = True,timeout = None )-
获取一个锁,阻塞或不阻塞。
当调用块参数设置为
True,阻塞直到锁处于解锁状态(不属于任何进程或线程),除非该锁已被当前进程或线程所拥有。当前进程或线程接着获取锁的所有权(如果它还没有所有权),并且锁内的递归级别增加1,导致返回值为True。请注意,第一个参数的行为与实现相比有几个不同之处threading.RLock.acquire(),从参数本身的名称开始。当调用块参数设置为
False,不要阻塞。如果锁已经被另一个进程或线程获取(并因此被拥有),则当前进程或线程不获取所有权,并且锁内的递归级别不改变,导致返回值为False。如果锁处于未锁定状态,则当前进程或线程获取所有权,递归级别递增,结果返回值为True。timeout参数的使用和行为与in中的相同
Lock.acquire()。请注意,这些超时行为中的一些 与实施的行为有所不同threading.RLock.acquire()。
release()-
释放一个锁,递减递归级别。如果在递减之后递归级别为零,则将锁重置为解锁(不由任何进程或线程拥有),并且如果有其他进程或线程被阻塞,等待锁解锁,则准许其中的一个继续进行。如果在递减之后递归级别仍然不为零,那么锁保持锁定并由调用进程或线程拥有。
只有在调用进程或线程拥有锁定时才调用此方法。一个
AssertionError如果该方法是通过一个过程调用或线程以外的雇主或升高如果锁处于解锁(无主)的状态。请注意,在这种情况下引发的异常的类型不同于执行的行为threading.RLock.release()。
- class
multiprocessing.Semaphore([ value ] ) -
一个信号量对象:一个接近的类比
threading.Semaphore。与其相近的模拟存在单一差异:其
acquire方法的第一个参数是命名块,与之一致Lock.acquire()。
multiprocessing包含来自所有同步方法等价于threading。例如,可以使用锁来确保一次只有一个进程打印到标准输出:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/1/18 14:16
# @Author : Py.qi
# @File : mult_sync.py
# @Software: PyCharm from multiprocessing import Process, Lock def f(l, i):
l.acquire()
try:
print('hello world', i)
finally:
l.release() if __name__ == '__main__':
lock = Lock()
for num in range(10):
Process(target=f, args=(lock, num)).start() #创建进程并启动
(3)进程之间共享状态
在进行并发编程时,通常最好尽可能避免使用共享状态。使用多个进程时尤其如此。
但是,如果你确实需要使用一些共享数据,那么 multiprocessing提供了一些方法。
可以使用可以由子进程继承的共享内存来创建共享对象。
multiprocessing.Value(typecode_or_type,* args,lock = True )
返回ctypes从共享内存分配的对象。默认情况下,返回值实际上是对象的同步包装器。对象本身可以通过a的value属性来访问Value。
typecode_or_type决定了返回对象的类型:它是一个ctypes类型或array 模块使用的一种字符类型。 *参数传递给类型的构造函数。
如果锁是True(默认),则会创建一个新的递归锁对象来同步对该值的访问。如果锁是一个Lock或一个RLock对象,那么将用于同步访问值。如果是锁,False那么访问返回的对象将不会被锁自动保护,因此它不一定是“过程安全的”。
Shared memory(共享内存):可以使用value或将数据存储在共享内存映射中Array
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/1/18 14:24
# @Author : Py.qi
# @File : mult_sharememory.py
# @Software: PyCharm from multiprocessing import Process, Value, Array
def f(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = i*i if __name__ == '__main__':
num = Value('d', 0.0) #d表示一个双精度浮点数
arr = Array('i', range(10)) #i表示符号整数
p = Process(target=f, args=(num, arr))
p.start()
p.join()
print(num.value)
print(arr[:]) #output:
3.1415927
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
在'd'与'i'创建时使用的参数num和arr被使用的那种的TypeCodes array模块:'d'表示一个双精度浮点数和'i'指示符号整数。这些共享对象将是进程和线程安全的。
为了更灵活地使用共享内存,可以使用multiprocessing.sharedctypes支持创建从共享内存分配的任意ctypes对象的 模块。
Server process(服务器进程):通过Manager()控制一个服务器进程来返回管理器对象,该进程持有Python对象,并允许其他进程使用代理来操作它们。
管理者提供了一种方法来创建可以在不同进程之间共享的数据,包括在不同机器上运行的进程之间通过网络进行共享。管理员对象控制管理共享对象的服务器进程 。其他进程可以通过使用代理来访问共享对象。
multiprocessing.Manager()-
返回
SyncManager可用于在进程之间共享对象的已启动对象。返回的管理对象对应于一个衍生的子进程,并具有创建共享对象并返回相应代理的方法。
Manager进程在垃圾收集或其父进程退出时将立即关闭。管理员类在multiprocessing.managers模块中定义 :
- class
multiprocessing.managers.BaseManager([ address [,authkey ] ] ) -
创建一个BaseManager对象。
一旦创建,应该调用
start()或get_server().serve_forever()确保管理器对象引用已启动的管理器进程。地址是管理进程侦听新连接的地址。如果地址是
None一个任意的选择。authkey是将用于检查到服务器进程的传入连接的有效性的身份验证密钥。如果使用 authkey的
None话current_process().authkey。否则使用authkey,它必须是一个字节字符串。start([ initializer [,initargs ] ] )-
启动一个子流程来启动管理器。如果初始化程序不是,
None那么子进程将initializer(*initargs)在启动时调用。
get_server()-
Server在Manager的控制下返回一个代表实际服务器的对象。该Server对象支持该serve_forever()方法:
connect()
将本地管理器对象连接到远程管理器进程
shutdown()-
停止经理使用的过程。这仅
start()在用于启动服务器进程时才可用 。这可以被多次调用。
register(typeid[,callable[,proxyType [,exposed[,method_to_typeid [,create_method ] ] ] ] ] )-
可用于注册类型或可与经理类一起调用的类方法。
typeid是一个“类型标识符”,用于标识特定类型的共享对象。这必须是一个字符串。
callable是可调用的,用于为这个类型标识符创建对象。如果一个管理器实例将被连接到使用该
connect()方法的服务器,或者如果 create_method参数是,False那么这可以保留为None。proxytype是其中的一个子类,
BaseProxy用于使用此typeid为共享对象创建代理。如果None那么一个代理类是自动创建的。exposed用于指定其中用于此typeid的代理应该被允许使用访问方法的名称序列
BaseProxy._callmethod()。(如果exposed在None随后proxytype._exposed_被用于代替如果它存在)。在其中没有指定暴露列表中的情况下,共享对象的所有“公共方法”将是可访问的。(这里的“公共方法”是指任何具有__call__()方法且名称不以其开头的属性'_')。method_to_typeid是一个映射,用于指定那些应该返回代理的公开方法的返回类型。它将方法名称映射到typeid字符串。(如果method_to_typeid存在,
None则proxytype._method_to_typeid_使用它。)如果一个方法的名称不是这个映射的关键字,或者如果这个映射是None这个方法返回的对象将被值复制。create_method确定是否应该使用名称typeid创建一个方法, 该方法可用于通知服务器进程创建一个新的共享对象并为其返回一个代理。默认情况下是
True。BaseManager实例也有一个只读属性:address manager使用的地址。
版本3.3中更改:管理器对象支持上下文管理协议 - 请参阅 上下文管理器类型。 __enter__()启动服务器进程(如果尚未启动),然后返回管理器对象。 __exit__()来电shutdown()。
在以前的版本__enter__()中,如果尚未启动管理器的服务器进程,则不启动。
通过返回的管理manager()将支持的类型: list,dict,Namespace,Lock, RLock,Semaphore,BoundedSemaphore, Condition,Event,Barrier, Queue,Value和Array。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/1/18 14:40
# @Author : Py.qi
# @File : mult_servprocess.py
# @Software: PyCharm from multiprocessing import Process, Manager def f(d,l,i):
d[i] = i+1 #每个进程添加字典元素
l.append(i) #每个进程启动后将列表添加数据i if __name__ == '__main__':
manager = Manager()
d = manager.dict()
l = manager.list()
pro_list=[]
for i in range(5): #启动5个进程
p = Process(target=f, args=(d,l,i))
p.start()
pro_list.append(p) #将进程都添加到列表
for j in pro_list:
j.join() #等待每个进程执行完成
print(d) #打印字典数据为5个进程操作的后的数据,实现进程间的数据共享
print(l) #output:
{0: 1, 1: 2, 2: 3, 3: 4, 4: 5}
[0, 1, 2, 3, 4]
(4)进程池(Pool)
class multiprocessing.pool.Pool([ processes [,initializer [,initargs [,maxtasksperchild [,context ] ] ] ] ] )
一个进程池对象,用于控制可以提交作业的工作进程池。它支持超时和回调的异步结果,并具有并行映射实现。
进程是要使用的工作进程的数量。如果过程是 None然后通过返回的数字os.cpu_count()被使用。
如果初始化程序不是,None那么每个工作进程将initializer(*initargs)在启动时调用 。
maxtasksperchild是一个工作进程在退出之前可以完成的任务数量,并被一个新的工作进程取代,以便释放未使用的资源。默认的maxtasksperchild是None,这意味着工作进程的生活时间与池一样长。
上下文可用于指定用于启动工作进程的上下文。通常使用函数multiprocessing.Pool()或Pool()上下文对象的方法来创建池。在这两种情况下都适当设置。
请注意,池对象的方法只应由创建池的进程调用。
apply(func [,args [,kwds ] ] )-
呼叫FUNC带参数ARGS和关键字参数kwds。它阻塞,直到结果准备就绪。鉴于这些块,
apply_async()更适合于并行执行工作。此外,func 只能在进程池的一名工作人员中执行。
apply_async(func [,args [,kwds [,callback [,error_callback ] ] ] ] )-
apply()返回结果对象的方法的变体。如果指定了callback,那么它应该是一个可接受的参数。当结果变为就绪callback被应用到它,这是除非调用失败,在这种情况下,error_callback 被应用。
如果指定了error_callback,那么它应该是一个可接受的参数。如果目标函数失败,则使用异常实例调用error_callback。
回调应该立即完成,否则处理结果的线程将被阻塞。
map(func,iterable [,chunksize ] )-
map()内置函数的并行等价物(尽管它只支持一个可迭代的参数)。它阻塞,直到结果准备就绪。这种方法把迭代器切成许多块,它们作为单独的任务提交给进程池。可以通过将chunksize设置为正整数来指定这些块的(近似)大小。
map_async(func,iterable [,chunksize [,callback [,error_callback ] ] ] )-
map()返回结果对象的方法的变体。如果指定了callback,那么它应该是一个可接受的参数。当结果变为就绪callback被应用到它,这是除非调用失败,在这种情况下,error_callback 被应用。
如果指定了error_callback,那么它应该是一个可接受的参数。如果目标函数失败,则使用异常实例调用error_callback。
回调应该立即完成,否则处理结果的线程将被阻塞。
imap(func,iterable [,chunksize ] )-
一个懒惰的版本
map()。所述CHUNKSIZE参数是与由所使用的一个
map()方法。对于使用了一个较大的值很长iterables CHUNKSIZE可以使作业完成的太多比使用的默认值加快1。此外,如果CHUNKSIZE是
1则next()通过返回的迭代器的方法imap()方法有一个可选的timeout参数:next(timeout)将提高multiprocessing.TimeoutError如果结果不能内退回timeout秒。
imap_unordered(func,iterable [,chunksize ] )-
同样
imap(),除了从返回的迭代结果的排序应该考虑随心所欲。(只有当只有一个工作进程时,才是保证“正确”的顺序。)
starmap(func,iterable [,chunksize ] )-
就像
map()除了可迭代的元素被期望是被解包为参数的迭代。因此,一个可迭代的结果。
[(1,2), (3, 4)][func(1,2), func(3,4)]3.3版本中的新功能
starmap_async(func,iterable [,chunksize [,callback [,error_back ] ] ] )-
的组合
starmap()和map_async(),超过迭代 迭代 iterables,并呼吁FUNC与解压缩iterables。返回一个结果对象。3.3版本中的新功能
close()-
防止将更多任务提交到池中。一旦所有任务完成,工作进程将退出。
terminate()-
立即停止工作进程而不完成杰出的工作。当池对象被垃圾收集时
terminate()会立即调用。
join()-
等待工作进程退出。必须打电话
close()或terminate()在使用之前join()。
3.3版新增功能:池对象现在支持上下文管理协议 - 请参阅 上下文管理器类型。 __enter__()返回池对象,并__exit__()调用terminate()。
class multiprocessing.pool.AsyncResult
Pool.apply_async()和 返回的结果的类Pool.map_async()。
get([ timeout ] )-
到达时返回结果。如果timeout不是
None,并且结果没有在超时秒内到达,那么multiprocessing.TimeoutError会引发。如果远程调用引发异常,那么该异常将被重新调整get()。
wait([ timeout ] )-
等到结果可用或timeout秒数通过。
ready()-
返回通话是否完成。
successful()-
返回调用是否完成而不引发异常。
AssertionError如果结果没有准备好,会提高。
Pool类表示一个工作进程池。它具有允许以几种不同方式将任务卸载到工作进程的方法。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/1/19 14:19
# @Author : Py.qi
# @File : mult_Pool_1.py
# @Software: PyCharm from multiprocessing import Pool
import time def f(x):
return x*x if __name__ == '__main__':
with Pool(processes=4) as pool: #4个开始工作进程
result = pool.apply_async(f, (10,)) #异步进程处理
print(result)
print(result.get(timeout=1)) #1秒超时,返回结果 print(pool.map(f, range(10))) #并行阻塞等待结果 it = pool.imap(f, range(10))
print(next(it)) # prints "0"
print(next(it)) # prints "1"
print(it.next(2)) # prints "4" unless your computer is *very* slow result = pool.apply_async(time.sleep, (10,))
print(result.get(timeout=1)) #引发异常multiprocessing.TimeoutError #output:
<multiprocessing.pool.ApplyResult object at 0x0000008BC4E76278>
100
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
0
1
4
Traceback (most recent call last):
File "Z:/python_project/day20/mult_Pool_1.py", line 28, in <module>
print(result.get(timeout=1)) #引发异常multiprocessing.TimeoutError
File "Z:\Program Files\Python35\lib\multiprocessing\pool.py", line 640, in get
raise TimeoutError
multiprocessing.context.TimeoutError
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/1/18 15:28
# @Author : Py.qi
# @File : mult_Pool.py
# @Software: PyCharm from multiprocessing import Pool, TimeoutError
import time
import os def f(x):
return x*x if __name__ == '__main__':
#启动4个工作进程作为进程池
with Pool(processes=4) as pool:
#返回函数参数运行结果列表
print(pool.map(f, range(10)))
#在进程池中以任意顺序打印相同的数字
for i in pool.imap_unordered(f, range(10)):
print(i,end=' ')
#异步评估
res = pool.apply_async(f,(20,)) #在进程池中只有一个进程运行
print('\n',res.get(timeout=1)) #打印结果,超时为1秒
#打印该进程的PID
res = pool.apply_async(os.getpid,()) #在进程池中只有一个进程运行
print(res.get(timeout=1)) #打印进程PID #打印4个进程的PID
multiple_results = [pool.apply_async(os.getpid, ()) for i in range(4)]
print([res.get(timeout=1) for res in multiple_results]) #进程等待10秒,获取数据超时为1秒,将输出异常
res = pool.apply_async(time.sleep, (10,))
try:
print(res.get(timeout=1))
except TimeoutError:
print("We lacked patience and got a multiprocessing.TimeoutError") #output:
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
0 1 4 9 16 25 36 49 64 81
400
2164
[8152, 2032, 2164, 8152]
We lacked patience and got a multiprocessing.TimeoutError
请注意:池的方法只能右创建它的进程使用,包中的功能要求__main__,在交互解释器中将不起作用。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/1/18 16:14
# @Author : Py.qi
# @File : sync_apply.py
# @Software: PyCharm from multiprocessing import Pool,freeze_support
import time
def foo(n):
time.sleep(1)
print(n*n) def back(arg):
print('exec done:',arg) if __name__ == '__main__':
freeze_support() #windows下新启动进程需要先运行此函数
pool = Pool(2) #创建进程池,同时2个进程运行
for i in range(10):
#pool.apply(func=foo, args=(i,)) #创建同步进程
#创建异步进程,传递函数和参数,在函数执行完后执行callback,并将函数foo的结构返回给callback
pool.apply_async(func=foo,args=(i,),callback=back)
pool.close() #此处必须是先关闭进程再join
pool.join()
print('end')
python3之线程与进程的更多相关文章
- 11.python3标准库--使用进程、线程和协程提供并发性
''' python提供了一些复杂的工具用于管理使用进程和线程的并发操作. 通过应用这些计数,使用这些模块并发地运行作业的各个部分,即便是一些相当简单的程序也可以更快的运行 subprocess提供了 ...
- Python3【模块】concurrent.futures模块,线程池进程池
Python标准库为我们提供了threading和multiprocessing模块编写相应的多线程/多进程代码,但是当项目达到一定的规模,频繁创建/销毁进程或者线程是非常消耗资源的,这个时候我们就要 ...
- Python3基础笔记---线程与进程
参考博客:Py西游攻关之多线程(threading模块) 一.并发与并行的区别 并发:交替做不同事的能力并行:同时做不同事的能力 行话解释:并发:不同代码块交替执行的性能并行:不同代码块同时执行的性能 ...
- Python之线程、进程和协程
python之线程.进程和协程 目录: 引言 一.线程 1.1 普通的多线程 1.2 自定义线程类 1.3 线程锁 1.3.1 未使用锁 1.3.2 普通锁Lock和RLock 1.3.3 信号量(S ...
- Python自动化运维之16、线程、进程、协程、queue队列
一.线程 1.什么是线程 线程是操作系统能够进行运算调度的最小单位.它被包含在进程之中,是进程中的实际运作单位. 一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行 ...
- python的线程和进程
1.线程的基本概念 概念 线程是进程中执行运算的最小单位,是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点在运行中必不可少的资源,但它可与同属一个进程的其它线程 ...
- Python并发编程之线程池&进程池
引用 Python标准库为我们提供了threading和multiprocessing模块编写相应的多线程/多进程代码,但是当项目达到一定的规模,频繁创建/销毁进程或者线程是非常消耗资源的,这个时候我 ...
- Python复习笔记(七)线程和进程
1. 多任务 并行:真的多任务 并发:假的多任务 2. 多任务-线程 Python的 Thread模块是比较底层的模块,Python的 Threading模块 是对Thread做了一些包装,可以更加方 ...
- Python并发编程之线程池/进程池--concurrent.futures模块
一.关于concurrent.futures模块 Python标准库为我们提供了threading和multiprocessing模块编写相应的多线程/多进程代码,但是当项目达到一定的规模,频繁创建/ ...
随机推荐
- Eclipse报错Project configuration is not up-to-date with pom.xml
1.问题 Description Resource Path Location Type Project configuration is not up-to-date with pom.xml. S ...
- BZOJ5123 线段树的匹配(树形dp)
线段树的任意一棵子树都相当于节点数与该子树相同的线段树.于是假装在树形dp即可,记忆化搜索实现,有效状态数是logn级别的. #include<iostream> #include< ...
- Java中线程同步的理解 - 其实应该叫做Java线程排队
Java中线程同步的理解 我们可以在计算机上运行各种计算机软件程序.每一个运行的程序可能包括多个独立运行的线程(Thread). 线程(Thread)是一份独立运行的程序,有自己专用的运行栈.线程有可 ...
- 【bzoj2806】 Ctsc2012—Cheat
http://www.lydsy.com/JudgeOnline/problem.php?id=2806 (题目链接) 题意 给出M个字符串组成“标准库”.定义L表示将一个字符串分成若干段,每一段的长 ...
- 【spoj NSUBSTR】 Substrings
http://www.spoj.com/problems/NSUBSTR/ (题目链接) 题意 给出一个字符串S,令${F(x)}$表示S的所有长度为x的子串出现次数的最大值.求${F(1)..... ...
- 【bzoj4264】小C找朋友
题解 $a$和$b$是好*友说明除了这两个人以外的邻接集合相同: 做两次$hash$,分别都处理和$a$相邻的点排序$hash$,①$a$要算进$a$的相邻集合,②$a$不算进: 当两个人不是好*友, ...
- bzoj5016 一个简单的询问
这种不可直接做的问题 数据范围又很小 考虑莫队 但是,l1,l2,r1,r2四维? 考虑把询问二维差分! f(a,b)表示,询问[1,a],[1, b]的答案 所以,ans(l1,r1,l2,y2)= ...
- Spring MVC使用Cors实现跨域
在开发APP过程中,APP调用后端接口有跨域的问题,只要在spring-mvc.xml 文件中加入下面的配置即可: <!-- 解决API接口跨域问题配置 Spring MVC 版本必须是 4.2 ...
- C++ strcat(template版本)
template<unsigned N, unsigned M> inline std::shared_ptr<char> strcat(const char (&p1 ...
- getContentLength() 指为 -1 的解决办法
在这个坑里3个多小时啊.这里不得不抱怨下,国内的资料坑爹,全部copy不说,还是错的. 解决办法: 在服务端加入代码: File file = new File(path); //path为要下载的文 ...