通过spark-sql快速读取hive中的数据
1 配置并启动
1.1 创建并配置hive-site.xml
在运行Spark SQL CLI中需要使用到Hive Metastore,故需要在Spark中添加其uris。具体方法是将HIVE_CONF/hive-site.xml复制到SPARK_CONF目录下,然后在该配置文件中,添加hive.metastore.uris属性,具体如下:
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop1:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
</configuration>

将mysql的jdbc驱动包拷贝给spark
将 $HIVE_HOME/lib/mysql-connector-java-5.1.12.jar copy或者软链到$SPARK_HOME/lib/
1.2 启动Hive Metastore
在使用Spark SQL CLI之前需要启动Hive Metastore(如果数据存放在HDFS文件系统,还需要启动Hadoop的HDFS),使用如下命令可以使Hive Metastore启动后运行在后台,可以通过jobs查询:
$nohup hive --service metastore > metastore.log 2>&1 &

1.3 启动Spark集群和Spark SQL CLI
通过如下命令启动Spark集群和Spark SQL CLI:
$cd /app/hadoop/spark-1.1.0 $sbin/start-all.sh $bin/spark-sql --master spark://hadoop1:7077 --executor-memory 1g
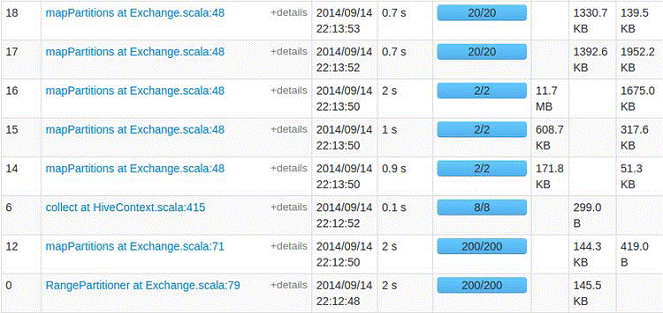
在集群监控页面可以看到启动了SparkSQL应用程序:

这时就可以使用HQL语句对Hive数据进行查询,另外可以使用COMMAND,如使用set进行设置参数:默认情况下,SparkSQL Shuffle的时候是200个partition,可以使用如下命令修改该参数:
SET spark.sql.shuffle.partitions=20;
运行同一个查询语句,参数改变后,Task(partition)的数量就由200变成了20。
通过spark-sql快速读取hive中的数据的更多相关文章
- SparkSQL读取Hive中的数据
由于我Spark采用的是Cloudera公司的CDH,并且安装的时候是在线自动安装和部署的集群.最近在学习SparkSQL,看到SparkSQL on HIVE.下面主要是介绍一下如何通过SparkS ...
- SQL Server 读取CSV中的数据
测试: Script: create table #Test ( Name ), Age int, T ) ) BULK INSERT #Test From 'I:\AAA.csv' with( fi ...
- Spark2.x学习笔记:Spark SQL快速入门
Spark SQL快速入门 本地表 (1)准备数据 [root@node1 ~]# mkdir /tmp/data [root@node1 ~]# cat data/ml-1m/users.dat | ...
- 使用Hive读取ElasticSearch中的数据
本文将介绍如何通过Hive来读取ElasticSearch中的数据,然后我们可以像操作其他正常Hive表一样,使用Hive来直接操作ElasticSearch中的数据,将极大的方便开发人员.本文使用的 ...
- Spark读取Hbase中的数据
大家可能都知道很熟悉Spark的两种常见的数据读取方式(存放到RDD中):(1).调用parallelize函数直接从集合中获取数据,并存入RDD中:Java版本如下: JavaRDD<Inte ...
- sql 读取excel中的数据
select 列名 as 字段名 from openBowSet('MSDASQL.1','driver=Microsoft Excel Driver(*.xls);dbq=文件存放地址','sele ...
- Spark SQL - 对大规模的结构化数据进行批处理和流式处理
Spark SQL - 对大规模的结构化数据进行批处理和流式处理 大体翻译自:https://jaceklaskowski.gitbooks.io/mastering-apache-spark/con ...
- Hive中的数据倾斜
Hive中的数据倾斜 hive 1. 什么是数据倾斜 mapreduce中,相同key的value都给一个reduce,如果个别key的数据过多,而其他key的较少,就会出现数据倾斜.通俗的说,就是我 ...
- 编写SqlHelper使用,在将ExecuteReader方法封装进而读取数据库中的数据时会产生Additional information: 阅读器关闭时尝试调用 Read 无效问题,解决方法与解释
在自学杨中科老师的视频教学时,拓展编写SqlHelper使用,在将ExecuteReader方法封装进而读取数据库中的数据时 会产生Additional information: 阅读器关闭时尝试调用 ...
随机推荐
- C#中的split的基本用法
split的使用: 1.使用char()字符分隔:根据单个的char()类型的进行分隔 代码如下: string str="e2kdk2fjod2fiksf21"; ');//因为 ...
- 解决使用ICsharpCode解压缩时候报错Size MisMatch4294967295;的错误
如果是一个文件夹生成的zip文件,解压缩时候不会报错. 如果是一个文件夹里面包含着两个子文件夹,而且每个子文件夹里面都有着文件.生成的zip文件在解压时候就出报这个错误. 具体的解决办法,通过网上搜索 ...
- 无废话网页重构系列——(2)来套Web重构装备
本篇主要从语言入门.规范.工具.构建.库.框架.版本控制等各方面展开,篇幅会有点长,涉及到的工具类,会另开博文详细介绍. 另外说明Web重构是Web前端的开始,主要侧重Web页面,如实现布局与兼容,符 ...
- Openwrt 远程调试
此文已由作者吴志勐授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 本文以自己的程序WFD为例: 1,为路由器固件刷上gdbserver 在宿主端,使用make menucon ...
- SmartUpload工具上传文件步骤
上传文件的步骤1.实例化SmartUpLoad实例 SmartUpload smart = new SmartUpload();2.初始化上传操作 ServletConfig config ...
- POJ 3468A Simple Problem with Integers(线段树区间更新)
A Simple Problem with Integers Time Limit: 5000MS Memory Limit: 131072K Total Submissions: 112228 ...
- Flask从入门到精通之使用Flask-Migrate实现数据库迁移
在开发程序的过程中,你会发现有时需要修改数据库模型,而且修改之后还需要更新数据库.仅当数据库表不存在时,Flask-SQLAlchemy 才会根据模型进行创建.因此,更新表的唯一方式就是先删除旧表,不 ...
- 使用 spring.profiles.active 及 @profile 注解 动态化配置内部及外部配置
引言:使用 spring.profiles.active 参数,搭配@Profile注解,可以实现不同环境下(开发.测试.生产)配置参数的切换 一.根据springboot的配置文件命名约定,结合ac ...
- 转的很好的前端html 内容
HTML 初识 web服务本质 import socket def main(): sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s ...
- python学习笔记02-编码
ASCII码 255个 每一个占1个字节 8位 解决中文的问题:出现一张扩展表 支持中文的第一张表 gb2312 后来发展为GBK1.0 Gb18030 万国码:unicode 世界统一 存 ...