Hadoop基础-HDFS的读取与写入过程
Hadoop基础-HDFS的读取与写入过程
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
为了了解客户端及与之交互的HDFS,NameNode和DataNode之间的数据流是什么样的,我们需要详细介绍一下HDFS的读取以及写入过程,本篇博客的观点是在我读《Hadoop权威指南,大数据的存储与分析》整理的笔记。
一.剖析HDFS文件读取
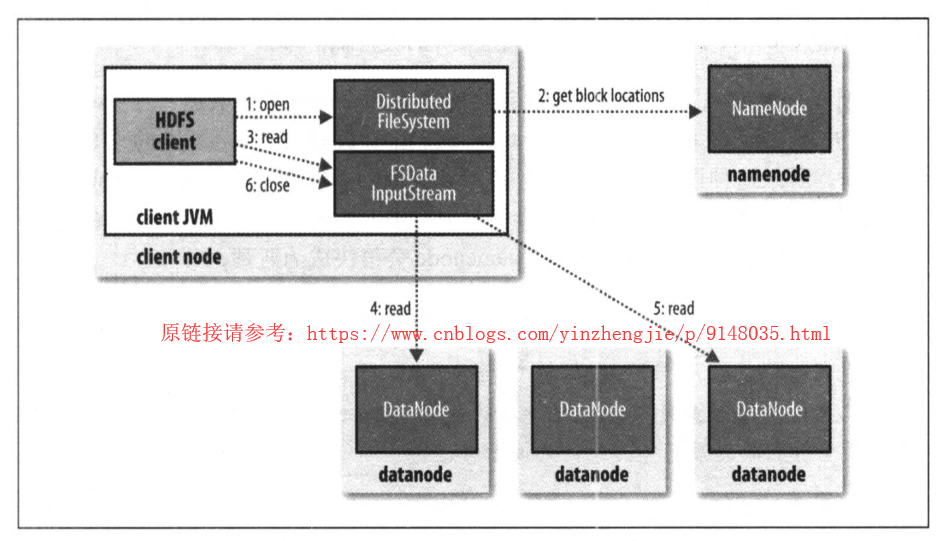
上图显示了HDFS在读取文件时事件的发生顺序。大致总结为以下几个步骤:
1>.客户端通过调用FileSystem对象的open()放啊来打开希望读取的文件,对于HDFS来说,这个对象DistributedFileSystem的一个实例;
2>.DistributedFileSystem通过使用远程过程调用(RPC)来调用namenode,以确定文件起始块的位置;对于每一个块,NameNode返回存有该块的副本的DataNode地址。此外,这些DataNode根据它们与客户端的距离来排序(根据集群的网络拓扑,详情请参考:https://www.cnblogs.com/yinzhengjie/p/9142230.html)。如果该客户端本身就是一个DataNode(比如,在一个MapReduce任务中),那么该客户端将会从保存有相应的数据块副本的本地DataNode读取数据;
3>.DistributedFileSystem类返回一个FSDataInputStream对象(一个支持文件定位的输入流)给客户端以便读取数据。FSDataInputStream类转而封装DFSInputStream对象,对该对象管理着DataNode和NameNode的I/O,接着,客户端对这个输入流调用read()方法;
4>.存储着文件起始几个块的DataNode地址的DFSInputStream随即连接距离最近的文件中第一个块所在的DataNode。通过对数据流反复调用read()方法,可以将数据从DataNode传输到客户端;
5>.到达块末端时,DFSInputStream关闭该DataNode的连接,然后找寻下一个块的最佳DataNode。所有这些对于客户端都是透明的,在客户看来它一直在读取一个连续的流;
6>.客户端从流中读取数据时,块是按照打开DFSInputStream与DataNode新建连接的顺序读取的。他也会根据需要询问NameNode来检索下一批数据块的DataNode的位置。一旦客户端完成读取,就对FSDataInputStream调用close()方法;
在读取数据的时候,如果DFSInputStream在与DataNode通信时遇到错误,会尝试这个块的另一个最近DataNode读取数据。他也会记住那个故障DataNode,以保证以后不会反复读取该节点上后续的块。DFSInputStream也会通过校验和确认从DataNode发来的数据是否完整。如果发现有损失的块,DFSInputStream会试图从其它DataNode读取其副本,也会将抒怀的块通知给NameNode。
这个设计一个重点是,客户端可以直接链接到DataNode检索数据,且NameNode告知客户端每个块所在的最佳DataNode。由于数据流分散在集群中所有DataNode,所以这种设计能够使HDFS扩展到大量的并发客户端。同时,NameNode只需要相应块位置的请求(这些信息存储的在内存中,因而非常高效),无需相应数据请求,否则随着科幻数量的增长,NameNode会很快称为瓶颈。
二.剖析HDFS文件写入
 、
、
接下来我们看看文件是如何写入HDFS的,尽管比较详细,但对于理解数据流还是很有用的,因为它清楚说明了HDFS的一致模型。我们要考虑是如何新建一个文件,把数据写入该文件,最后关闭该文件。上图显示了HDFS在写入文件时事件的发生顺序,大致总结为以下几个步骤:
1>.客户端通过对DistributedFileSystem对象调用create()来新建文件;
2>.DistributedFileSystem对NameNode创建一个RPC调用,在文件系统的命名空间中新建一个文件,此时该文件中还没有形影的数据块。NameNode执行各种不同的检查以确保这个文件不存在以及客户端有新建该文件的权限。如果这个检查均通过,NameNode就会创建新文件记录一条记录;否则,文件创建失败并向客户端抛出一个IOException 异常。DistributedFileSystem向客户端返回一个FSDataOutputStream对象,由此客户端可以开始写入数据。就像读取事件一样,FSDataOutputStream封装一个DFSoutPutStream对象,该对象负责处理DataNode和NameNode之间的通信;
3>.在客户端写入数据时吗,DFSOutputStream将它分为一个个的数据包(每个packet大小为64k),当包满了之后,也就是数据大于64k,数据会并写入内部队列,称为“数据队列”(data queue)。DataStreamer 处理数据队列,它的责任是挑选出适合存储数据副本的一组DataNode,并据此来要求NameNode分配新的数据块。这一组DataNode构成一个管线,我我们假设副本数为3,所有管线中有3个节点。
4>.DataStream将数据包流式传输到管线中第一个DataNode,该DataNode存储数据包并将它发送到管线中的第二个DataNode。同样,第二个DataNode存储该数据包并且发送给管线中的第三个(也是最后一个)DataNode;
5>.DFSOutputSteam也维护着一个内部数据包队列来等待DataNode的收到确认回执,称为“确认队列”(ack queue)。收到管道中所有DataNode确认信息后,该数据包才会从确认队列删除。如果任何DataNode在数据写入期间发生故障,则执行一下操作(对写入数据的客户单是透明的,也就是说客户端根本体验不到这个过程)。首先关闭管线,确认把队列中的所有数据包都添加回数据队列的前端,以确保故障节点下游的DataNode不会漏掉任何一个数据包。为存储在另一正DataNode的当前数据块指定一个新的标识,并将该标识传送给NameNode,以便挂账DataNode在恢复后可以删除存储的部分数据块。从管线中删除故障DataNode,基于两个正常DataNode构建一条新管线。余下的数据块写入管线中正常的DataNode。NameNode注意到块副本量不足时,会在另一个节点上穿件一个新的复本。后续的数据块继续正常接受处理。在一个块被写入期间可能会有多个DataNode同时发生故障,但非常少见。只要写入了“dfs.namenode.repliocation.min”的副本数(默认为1),写操作就会成功,并且这个块在集群中异步复制,直到达到其目标副本数(dfs.replication的默认值为3)。
6>.客户端完成数据的写入后,对数据流调用close()方法。
7>.该操作将剩余的所有数据包写入DataNode管线,对数据流调用close()方法。该操作将剩余的所有数据包写入DataNode管线,并在联系到NameNode告知其文件写入完成之前,等待确认。NameNode已经知道文件由哪些块组成(因为Datastreamer请求分配数据块),所以他在返回成功前只需要等待数据块进行最小量的复制。
三.写入过程代码调试片段
1>.DFSPacket的格式说明
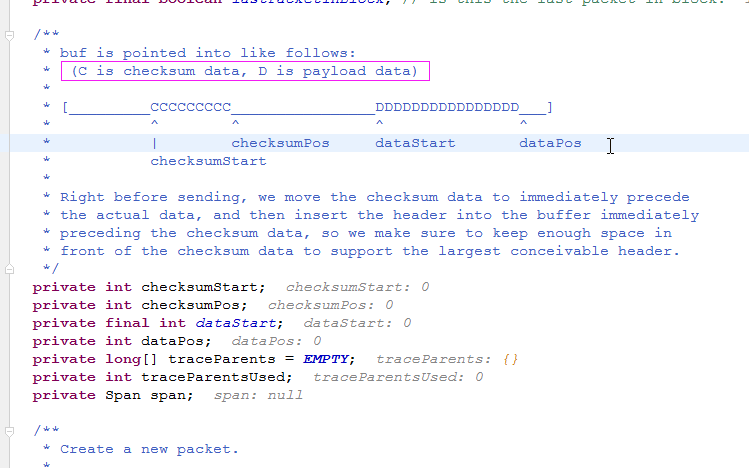
上图是调试代码时Hadoop的部分源码注释,为了方便理解,我们可以大致画一个DFSPacket结构图,如下:
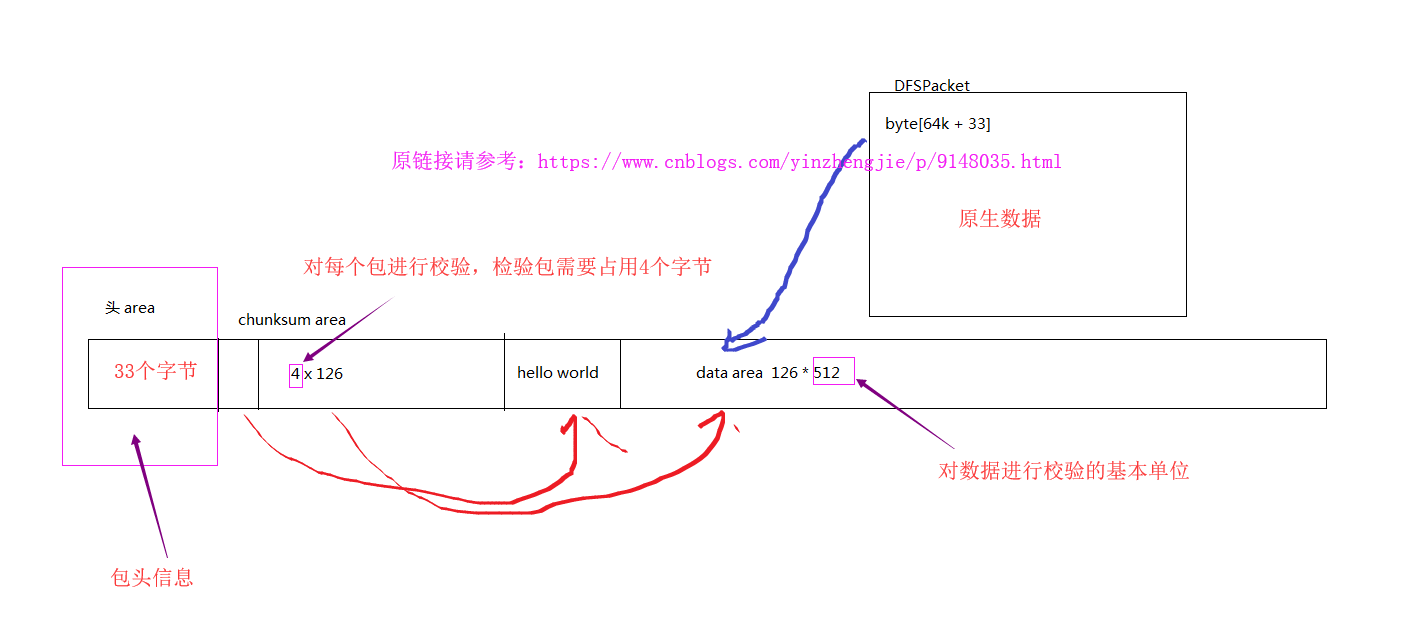
上图你可能会问126是怎么来的?其实用一个计算公式算出来的,一个包的大小是64k,换算成字节则为:65536字节,而一个chunk的大小为512字节,每个chunk都会进行依次校验,而每个循环冗余校验大小为4个字节,包头信息会占用33个字节,因此我们就得到了一个计算DFSPacket个数的公式:(65536 - 33)/(512 + 4) = 126.9437984496124 ,很显然一个packet装不下127个chunk,故一个包中,最多能存储126个chunk。
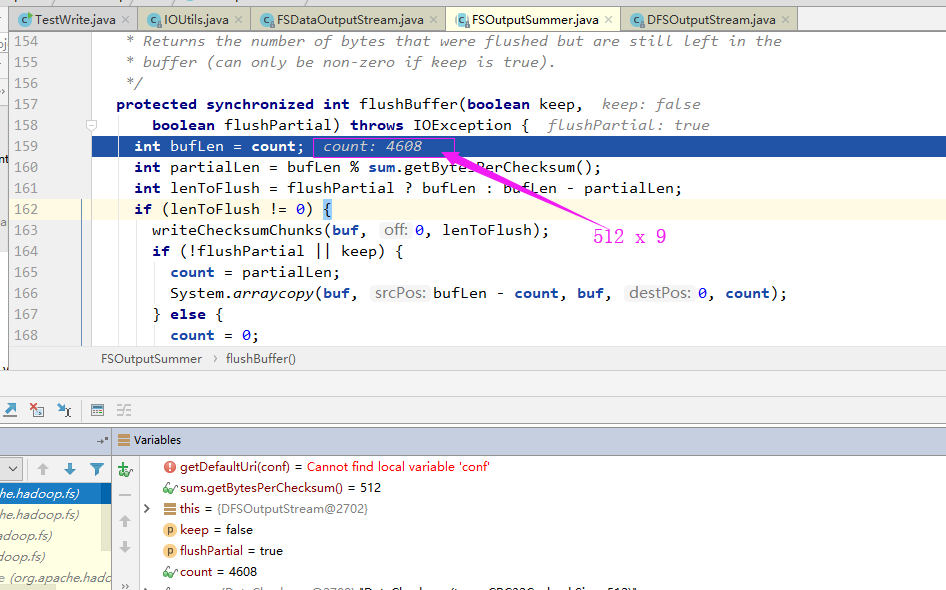
2>.flushBuffer
我们在FSOutputSummer中的flushBuffer中可以看到writeChecksumChunks(4608)的字样,说明它是每隔4608字节进行一次flushBuffer,这个4608是怎么来的呢?4608=512x9,而512是对数据进行校验的基本单位。
四.副本的存储选择
NameNode如何选择在哪个DataNode存储副本(replica)?我们要从以下三个角度考虑:
1>.可靠性;
2>.写入带宽;
3>.读取带宽;
接下来我们举两个极端的例子,把所有的副本都存储在一个节点上,损失的写入写入带宽最小,因为复制管线都是在同一个节点上运行。但这个并不提供给真实的冗余,如果节点发生故障,那么该块中的数据会丢失。同时,同一机架服务器键的读取带宽是很高的。另一个极端,把复本放在不同的数据中心可能最大限度的提高冗余,但带宽的损耗非常大。即使在同一个数据中心。到目前为止,所有Hadoop集群军郧县在同一个数据中心内,也有很多可能数据布局策略。
Hadoop的默认布局策略是在运行客户端的节点上放第一个复本(如果客户端运行在集群之外,就随机选择一个节点,不过系统会避免挑选那些存储太满或太忙的节点)。第二个复本放在与第一个不同且随机另外选择的机架中节点上(离架)。第3个副本与第二个副本放在同一个机架上,且随机选择另一个节点。其它副本放在集群中随机选择的节点上,不过系统会尽量避免在同一个机架上放太多的副本。一旦选定副本的存放位置,就根据网络拓扑创建一个管线,如果副本数为3,则如下图所示的管线。
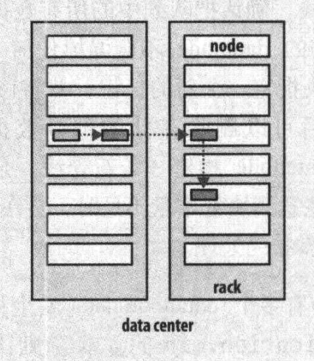
总的来说,这一方法不仅提供很好的稳定性(数据块存储在两个机架中)并实现很好的负载均衡,包括写入带宽(写入操作只需要遍历一个交换机),读取性能(可以从两个机架中选择读取)和集群中块中均匀分布(客户端只在本地机架上写入一个块)。
Hadoop基础-HDFS的读取与写入过程的更多相关文章
- Hadoop基础-HDFS的读取与写入过程剖析
Hadoop基础-HDFS的读取与写入过程剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客会简要介绍hadoop的写入过程,并不会设计到源码,我会用图和文字来描述hdf ...
- Hadoop基础-HDFS数据清理过程之校验过程代码分析
Hadoop基础-HDFS数据清理过程之校验过程代码分析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想称为一名高级大数据开发工程师,不但需要了解hadoop内部的运行机制,还需 ...
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
- Hadoop基础-HDFS的API实现增删改查
Hadoop基础-HDFS的API实现增删改查 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客开发IDE使用的是Idea,如果没有安装Idea软件的可以去下载安装,如何安装 ...
- Hadoop基础-HDFS分布式文件系统的存储
Hadoop基础-HDFS分布式文件系统的存储 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS数据块 1>.磁盘中的数据块 每个磁盘都有默认的数据块大小,这个磁盘 ...
- Hadoop基础-HDFS递归列出文件系统-FileStatus与listFiles两种方法
Hadoop基础-HDFS递归列出文件系统-FileStatus与listFiles两种方法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. fs.listFiles方法,返回Loc ...
- Hadoop基础-HDFS安全管家之Kerberos实战篇
Hadoop基础-HDFS安全管家之Kerberos实战篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们都知道hadoop有很多不同的发行版,比如:Apache Hadoop ...
- Hadoop基础-HDFS集群中大数据开发常用的命令总结
Hadoop基础-HDFS集群中大数据开发常用的命令总结 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本盘博客仅仅列出了我们在实际生成环境中常用的hdfs命令,如果想要了解更多, ...
- Hadoop基础-HDFS的API常见操作
Hadoop基础-HDFS的API常见操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习HDFS时的一些琐碎的学习笔记, 方便自己以后查看.在调用API ...
随机推荐
- C++:友元
前言:友元对于我来说一直是一个难点,最近看了一些有关友元的课程与博客,故在此将自己的学习收获做一个简单的总结 一.什么是友元 在C++的自定义类中,一个常规的成员函数声明往往意味着: • 该成员函数能 ...
- Task 6.4 冲刺Two之站立会议6
今天对视频的画面质量进行了优化,又把所有的界面更换了一些比较美观的图片和背景.使界面看起来更加地合理,易于接受.
- 特别好用的eclipse快捷键
alt+/ 提示 alt+shift+r重命名 alt+shift+j添加文档注释 Ctrl+shift+y小写 Ctrl+shift+x大写 ctrl+shift+f格式化代码(需要取消输入法的简繁 ...
- struts2 Action生命周期
Struts2.0中的对象既然都是线程安全的,都不是单例模式,那么它究竟何时创建,何时销毁呢? 这个和struts2.0中的配置有关,我们来看struts.properties ### if spec ...
- java的(PO,VO,TO,BO,DAO,POJO)类名包名解释
VO:值对象.视图对象 PO:持久对象 QO:查询对象 DAO:数据访问对象——同时还有DAO模式 DTO:数据传输对象——同时还有DTO模式 PO:全称是persistant object持久对象最 ...
- Week2-作业1 《构建之法》1、2、16章观后感
这几天阅读了<构建之法>中的几章,受益匪浅,刷新了很多我对软件工程的认知.这本书让我很惊喜,阅读起来不像其他书一样枯燥,有很多人物的设计,以及对话的形式,非常有趣. 第一章.概述 读完第一 ...
- Linux内核0.11 bootsect文件说明
一.总体功能介绍 这是关于Linux-kernel-0.11中boot文件夹下bootsect.s源文件的说明,其中涉及到了一些基础知识可以参考这两篇文章. 操作系统启动过程 软盘相关知识和通过BIO ...
- linux 下安装 nodejs
1. linux 下下载 wget http://cdn.npm.taobao.org/dist/node/v10.14.1/node-v10.14.1-linux-x64.tar.xz 2. 解压缩 ...
- C#中重写(override)和覆盖(new)的区别
重写 用关键字 virtual 修饰的方法,叫虚方法.可以在子类中用override 声明同名的方法,这叫“重写”.相应的没有用virtual修饰的方法,我们叫它实方法.重写会改变父类方法的功能.看下 ...
- CodeForces - 988D(思维STL)
原文地址:https://blog.csdn.net/weixin_39453270/article/details/80548442 博主已经讲的很好了 题意: 从一个序列中,选出一个集合,使得集合 ...