Kafka(五)Kafka的API操作和拦截器
一 kafka的API操作
1.1 环境准备
1)在eclipse中创建一个java工程
2)在工程的根目录创建一个lib文件夹
3)解压kafka安装包,将安装包libs目录下的jar包拷贝到工程的lib目录下,并build path。
4)启动zk和kafka集群,在kafka集群中打开一个消费者
[root@node21 kafka]$ bin/kafka-console-consumer.sh --zookeeper node21:2181,node22:2181,node23:2181 --topic firstTopic
这里用maven,pom文件引入依赖
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.</artifactId>
<version>1.1.</version>
</dependency>
1.2 生产者Java API
1.2.1创建生产者(过时API)
package com.xyg.kafka.producer; import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import java.util.Properties; public class OldProducer {
@SuppressWarnings("deprecation")
public static void main(String[] args) { Properties properties = new Properties();
properties.put("metadata.broker.list", "node21:9092,node22:9092,node23:9092");
properties.put("request.required.acks", "");
properties.put("serializer.class", "kafka.serializer.StringEncoder");
Producer<Integer, String> producer = new Producer<Integer,String>(new ProducerConfig(properties));
KeyedMessage<Integer, String> message = new KeyedMessage<Integer, String>("firstTopoic", "hello world");
producer.send(message );
}
}
1.2.2 创建生产者(新API)
package com.xyg.kafka.producer; import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord; public class NewProducer { public static void main(String[] args) { Properties props = new Properties();
// Kafka服务端的主机名和端口号
props.put("bootstrap.servers", "node21:9092,node22:9092,node23:9092");
// 等待所有副本节点的应答
props.put("acks", "all");
// 消息发送最大尝试次数
props.put("retries", );
// 一批消息处理大小
props.put("batch.size", );
// 请求延时
props.put("linger.ms", );
// 发送缓存区内存大小
props.put("buffer.memory", );
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = ; i < ; i++) {
ProducerRecord<String, String> record = new ProducerRecord<String, String>("firstTopic", Integer.toString(i), "hello world-" +i);
producer.send(record);
System.out.println(record);
}
producer.close();
}
}
1.2.3 创建生产者带回调函数(新API)
package com.xyg.kafka.producer; import java.util.Properties;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata; public class CallBackProducer { public static void main(String[] args) {
Properties props = new Properties();
// Kafka服务端的主机名和端口号
props.put("bootstrap.servers", "node22:9092,node22:9092,node23:9092");
// 等待所有副本节点的应答
props.put("acks", "all");
// 消息发送最大尝试次数
props.put("retries", );
// 一批消息处理大小
props.put("batch.size", );
// 增加服务端请求延时
props.put("linger.ms", );
// 发送缓存区内存大小
props.put("buffer.memory", );
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(props); for (int i = ; i < ; i++) {
kafkaProducer.send(new ProducerRecord<String, String>("firstTopic", "hello" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (metadata != null) {
System.out.println(metadata.partition() + "---" + metadata.offset());
}
}
});
}
kafkaProducer.close();
}
}
控制台打印输出如下:
---
---
---
---
---
---
---
---
---
--- Process finished with exit code
1.2.4 自定义分区生产者
0)需求:将所有数据存储到topic的第0号分区上
1)定义一个类实现Partitioner接口,重写里面的方法(过时API)
package com.xyg.kafka.producer;
import kafka.producer.Partitioner;
public class OldCustomPartitioner implements Partitioner {
public OldCustomPartitioner() {
super();
}
@Override
public int partition(Object key, int numPartitions) {
// 控制分区
return ;
}
}
2)自定义分区(新API)
package com.xyg.kafka.producer; import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map; public class NewCustomPartitioner implements Partitioner { @Override
public void configure(Map<String, ?> configs) {
}
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 控制分区
return ;
}
@Override
public void close() {
}
}
3)在代码中调用
package com.xyg.kafka.producer; import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties; public class PartitionerProducer { public static void main(String[] args) { Properties props = new Properties();
// Kafka服务端的主机名和端口号
props.put("bootstrap.servers", "node21:9092,node22:9092,node23:9092");
// 等待所有副本节点的应答
props.put("acks", "all");
// 消息发送最大尝试次数
props.put("retries", );
// 一批消息处理大小
props.put("batch.size", );
// 增加服务端请求延时
props.put("linger.ms", );
// 发送缓存区内存大小
props.put("buffer.memory", );
// key序列化
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// value序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 自定义分区
props.put("partitioner.class", "com.xyg.kafka.NewCustomPartitioner");
Producer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<String, String>("firstTopic", "", "kafka"));
System.out.println(new ProducerRecord<String, String>("firstTopic", "", "kafka"));
producer.close();
}
}
(1)在node21上监控/opt/module/kafka/logs/目录下firstTopic主题3个分区的log日志动态变化情况)测试
[admin@node21 firstTopic-0]$ tail -f 00000000000000000000.log
[admin@node21 firstTopic-1]$ tail -f 00000000000000000000.log
[admin@node21 firstTopic-2]$ tail -f 00000000000000000000.log
(2)发现数据都存储到指定的分区了。
1.3 消费者Java API
0)在控制台创建发送者
[root@node21 kafka]$ bin/kafka-console-producer.sh --broker-list node21:9092,node22:9092,node23:9092 --topic firstTopic
>hello world
1.3.1 创建消费者(过时API)
package com.xyg.kafka.consume; import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector; public class CustomOldConsumer { @SuppressWarnings("deprecation")
public static void main(String[] args) { Properties properties = new Properties();
properties.put("zookeeper.connect", "node21:2181,node22:2181,node23:2181");
properties.put("group.id", "g1");
properties.put("zookeeper.session.timeout.ms", "");
properties.put("zookeeper.sync.time.ms", "");
properties.put("auto.commit.interval.ms", "");
// 创建消费者连接器
ConsumerConnector consumer = Consumer.createJavaConsumerConnector(new ConsumerConfig(properties));
HashMap<String, Integer> topicCount = new HashMap<>();
topicCount.put("firstTopic", );
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCount);
KafkaStream<byte[], byte[]> stream = consumerMap.get("firstTopic").get();
ConsumerIterator<byte[], byte[]> it = stream.iterator(); while (it.hasNext()) {
System.out.println(new String(it.next().message()));
}
}
}
1.3.2 创建消费者(新API)
官方提供案例(自动维护消费情况)
ackage com.xyg.kafka.consume; import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer; public class CustomNewConsumer { public static void main(String[] args) { Properties props = new Properties();
// 定义kakfa 服务的地址,不需要将所有broker指定上
props.put("bootstrap.servers", "node21:9092,node22:9092,node23:9092");
// 制定consumer group
props.put("group.id", "test1");
// 是否自动确认offset
props.put("enable.auto.commit", "true");
// 自动确认offset的时间间隔
props.put("auto.commit.interval.ms", "");
// key的序列化类
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// value的序列化类
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 定义consumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 消费者订阅的topic, 可同时订阅多个
consumer.subscribe(Arrays.asList("firstTopic", "second","third"));
while (true) {
// 读取数据,读取超时时间为100ms
ConsumerRecords<String, String> records = consumer.poll();
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
二 Kafka producer拦截器
2.1 拦截器原理
Producer拦截器(interceptor)是在Kafka 0.10版本被引入的,主要用于实现clients端的定制化控制逻辑。
对于producer而言,interceptor使得用户在消息发送前以及producer回调逻辑前有机会对消息做一些定制化需求,比如修改消息等。同时,producer允许用户指定多个interceptor按序作用于同一条消息从而形成一个拦截链(interceptor chain)。Intercetpor的实现接口是org.apache.kafka.clients.producer.ProducerInterceptor,其定义的方法包括:
(1)configure(configs)
获取配置信息和初始化数据时调用。
(2)onSend(ProducerRecord):
该方法封装进KafkaProducer.send方法中,即它运行在用户主线程中。Producer确保在消息被序列化以及计算分区前调用该方法。用户可以在该方法中对消息做任何操作,但最好保证不要修改消息所属的topic和分区,否则会影响目标分区的计算
(3)onAcknowledgement(RecordMetadata, Exception):
该方法会在消息被应答或消息发送失败时调用,并且通常都是在producer回调逻辑触发之前。onAcknowledgement运行在producer的IO线程中,因此不要在该方法中放入很重的逻辑,否则会拖慢producer的消息发送效率
(4)close:
关闭interceptor,主要用于执行一些资源清理工作
如前所述,interceptor可能被运行在多个线程中,因此在具体实现时用户需要自行确保线程安全。另外倘若指定了多个interceptor,则producer将按照指定顺序调用它们,并仅仅是捕获每个interceptor可能抛出的异常记录到错误日志中而非在向上传递。这在使用过程中要特别留意。
2.2 拦截器案例
1)需求:
实现一个简单的双interceptor组成的拦截链。第一个interceptor会在消息发送前将时间戳信息加到消息value的最前部;第二个interceptor会在消息发送后更新成功发送消息数或失败发送消息数。

2)案例实操
(1)增加时间戳拦截器
package com.xyg.kafka.interceptor; import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map; public class TimeInterceptor implements ProducerInterceptor<String, String> { @Override
public void configure(Map<String, ?> map) { }
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
// 创建一个新的record,把时间戳写入消息体的最前部
return new ProducerRecord(record.topic(), record.partition(), record.timestamp(), record.key(),
System.currentTimeMillis() + "," + record.value().toString());
} @Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {
}
@Override
public void close() {
}
}
(2)统计发送消息成功和发送失败消息数,并在producer关闭时打印这两个计数器
package com.xyg.kafka.interceptor; import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map; public class CounterInterceptor implements ProducerInterceptor<String, String> {
private int errorCounter = ;
private int successCounter = ; @Override
public void configure(Map<String, ?> configs) {
}
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
return record;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
// 统计成功和失败的次数
if (exception == null) {
successCounter++;
} else {
errorCounter++;
}
}
@Override
public void close() {
// 保存结果
System.out.println("Successful sent: " + successCounter);
System.out.println("Failed sent: " + errorCounter);
}
}
(3)producer主程序
package com.xyg.kafka.interceptor; import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties; public class InterceptorProducer {
public static void main(String[] args) throws Exception {
// 1 设置配置信息
Properties props = new Properties();
props.put("bootstrap.servers", "node21:9092");
props.put("acks", "all");
props.put("retries", );
props.put("batch.size", );
props.put("linger.ms", );
props.put("buffer.memory", );
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 2 构建拦截链
List<String> interceptors = new ArrayList<>();
interceptors.add("com.xyg.kafka.interceptor.TimeInterceptor");
interceptors.add("com.xyg.kafka.interceptor.CounterInterceptor");
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);
String topic = "firstTopic";
Producer<String, String> producer = new KafkaProducer<>(props);
// 3 发送消息
for (int i = ; i < ; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, "message" + i);
producer.send(record);
}
// 4 一定要关闭producer,这样才会调用interceptor的close方法
producer.close();
}
}
3)测试
(1)在kafka上启动消费者,然后运行客户端java程序。
[root@node21 kafka]$ bin/kafka-console-consumer.sh --zookeeper node21:2181,node22:2181,node23:2181 --from-beginning --topic firstTopic
1533465083631,message0
1533465084092,message3
1533465084092,message6
1533465084093,message9
1533465148033,message1
1533465148043,message4
1533465148044,message7
1533465154264,message0
1533465154650,message3
1533465154651,message6
1533465154651,message9
(2)观察java平台控制台输出数据如下:
Successful sent: 10
Failed sent: 0
三 kafka Streams
3.1 Kafka Streams概述
Kafka Streams是一个客户端库,用于构建任务关键型实时应用程序和微服务,其中输入和/或输出数据存储在Kafka集群中。Kafka Streams结合了在客户端编写和部署标准Java和Scala应用程序的简单性以及Kafka服务器端集群技术的优势,使这些应用程序具有高度可扩展性,弹性,容错性,分布式等等。
3.2 Kafka Streams特点
1)功能强大
高扩展性,弹性,容错
2)轻量级
无需专门的集群
一个库,而不是框架
3)完全集成
100%的Kafka 0.10.0版本兼容
易于集成到现有的应用程序
4)实时性
毫秒级延迟
并非微批处理
窗口允许乱序数据
允许迟到数据
3.3 几种Stream对比
当前已经有非常多的流式处理系统,最知名且应用最多的开源流式处理系统有Spark Streaming和Apache Storm。Apache Storm发展多年,应用广泛,提供记录级别的处理能力,当前也支持SQL on Stream。而Spark Streaming基于Apache Spark,可以非常方便与图计算,SQL处理等集成,功能强大,对于熟悉其它Spark应用开发的用户而言使用门槛低。另外,目前主流的Hadoop发行版,如Cloudera和Hortonworks,都集成了Apache Storm和Apache Spark,使得部署更容易。
既然Apache Spark与Apache Storm拥用如此多的优势,那为何还需要Kafka Stream呢?主要有如下原因。
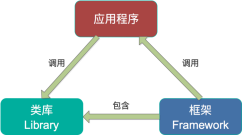
第一,Spark和Storm都是流式处理框架,而Kafka Stream提供的是一个基于Kafka的流式处理类库。框架要求开发者按照特定的方式去开发逻辑部分,供框架调用。开发者很难了解框架的具体运行方式,从而使得调试成本高,并且使用受限。而Kafka Stream作为流式处理类库,直接提供具体的类给开发者调用,整个应用的运行方式主要由开发者控制,方便使用和调试。
第二,虽然Cloudera与Hortonworks方便了Storm和Spark的部署,但是这些框架的部署仍然相对复杂。而Kafka Stream作为类库,可以非常方便的嵌入应用程序中,它对应用的打包和部署基本没有任何要求。
第三,就流式处理系统而言,基本都支持Kafka作为数据源。例如Storm具有专门的kafka-spout,而Spark也提供专门的spark-streaming-kafka模块。事实上,Kafka基本上是主流的流式处理系统的标准数据源。换言之,大部分流式系统中都已部署了Kafka,此时使用Kafka Stream的成本非常低。
第四,使用Storm或Spark Streaming时,需要为框架本身的进程预留资源,如Storm的supervisor和Spark on YARN的node manager。即使对于应用实例而言,框架本身也会占用部分资源,如Spark Streaming需要为shuffle和storage预留内存。但是Kafka作为类库不占用系统资源。
第五,由于Kafka本身提供数据持久化,因此Kafka Stream提供滚动部署和滚动升级以及重新计算的能力。
第六,由于Kafka Consumer Rebalance机制,Kafka Stream可以在线动态调整并行度。
3.4 Stream数据清洗案例
0)需求:
实时处理单词带有”>>>”前缀的内容。例如输入”111>>>hadoop”,最终处理成“hadoop”
1)需求分析:

2)案例实操
(1)创建一个工程,pom文件引入依赖
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-streams -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>1.1.</version>
</dependency>
(2)创建主类(TopologyBuilder是过时的)
package com.xyg.kafka.stream; import java.util.Properties;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorSupplier;
import org.apache.kafka.streams.processor.TopologyBuilder; public class StreamApplication {
public static void main(String[] args) {
// 定义输入的topic
String from = "firstTopic";
// 定义输出的topic
String to = "secondTopic";
// 设置参数
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "logFilter");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "node21:9092");
StreamsConfig config = new StreamsConfig(props);
// 构建拓扑
TopologyBuilder builder = new TopologyBuilder();
builder.addSource("SOURCE", from)
.addProcessor("PROCESS", new ProcessorSupplier<byte[], byte[]>() {
@Override
public Processor<byte[], byte[]> get() {
// 具体分析处理
return new LogProcessor();
}
}, "SOURCE")
.addSink("SINK", to, "PROCESS");
// 创建kafka stream
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}
}
(3)具体业务处理
package com.xyg.kafka.stream; import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorContext; public class LogProcessor implements Processor<byte[], byte[]> { private ProcessorContext context; @Override
public void init(ProcessorContext context) {
this.context = context;
} @Override
public void process(byte[] key, byte[] value) {
String input = new String(value);
// 如果包含“>>>”则只保留该标记后面的内容
if (input.contains(">>>")) {
input = input.split(">>>")[].trim();
// 输出到下一个topic
context.forward("logProcessor".getBytes(), input.getBytes());
}else{
context.forward("logProcessor".getBytes(), input.getBytes());
}
} @Override
public void punctuate(long timestamp) {
} @Override
public void close() {
}
}
(4)运行程序
(5)在node21上启动生产者
[root@node21 kafka]$ bin/kafka-console-producer.sh --broker-list node21:9092,node22:9092,node23:9092 --topic firstTopic
>111>>>hadoop
>222>>>spark
>spark
(6)在node22上启动消费者
[root@node22 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server node21:9092,node22:9092,node23:9092 --from-beginning --topic secondTopic
hadoop
spark
spark
3.5 Stream官方wc案例
参考文档:http://kafka.apache.org/11/documentation/streams/
package com.xyg.kafka.stream; import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.common.utils.Bytes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.Materialized;
import org.apache.kafka.streams.kstream.Produced;
import org.apache.kafka.streams.state.KeyValueStore;
import java.util.Arrays;
import java.util.Properties; public class WordCountApplication { public static void main(final String[] args) throws Exception {
Properties config = new Properties();
config.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "node21:9092");
config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> textLines = builder.stream("TextLinesTopic");
KTable<String, Long> wordCounts = textLines
.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word)
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store"));
wordCounts.toStream().to("WordsWithCountsTopic", Produced.with(Serdes.String(), Serdes.Long())); KafkaStreams streams = new KafkaStreams(builder.build(), config);
streams.start();
} }
Kafka(五)Kafka的API操作和拦截器的更多相关文章
- Kafka系列三 java API操作
使用java API操作kafka 1.pom.xml <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xs ...
- Kafka的接口回调 +自定义分区、拦截器
一.接口回调+自定义分区 1.接口回调:在使用消费者的send方法时添加Callback回调 producer.send(new ProducerRecord<String, String> ...
- 防止未登录用户操作—struts2拦截器简单实现(转)
原文地址:http://blog.csdn.net/zhutulang/article/details/38351629 尊重原创,请访问原地址 一般,我们的web应用都是只有在用户登录之后才允许操作 ...
- struts 用拦截器进行用户权限隔离,未登录用户跳到登录界面 *** 最爱那水货
一般,我们的web应用都是只有在用户登录之后才允许操作的,也就是说我们不允许非登录认证的用户直接访问某些页面或功能菜单项.对于个别页面来说,可能不需要进行拦截,此时,如果项目采用struts view ...
- AOP-方法拦截器-笔记
方法拦截器的继承层次图: 这些拦截器具体长什么样?? 一.MethodBeforeAdviceInterceptor 这个拦截器只有一个属性就是前置通知.需要注意的是前置通知和返回通知的拦截器才会持有 ...
- struts2内置拦截器和自定义拦截器详解(附源码)
一.Struts2内置拦截器 Struts2中内置类许多的拦截器,它们提供了许多Struts2的核心功能和可选的高级特 性.这些内置的拦截器在struts-default.xml中配置.只有配置了拦截 ...
- Struts的拦截器
Struts的拦截器 1.什么是拦截器 Struts的拦截器和Servlet过滤器类似,在执行Action的execute方法之前,Struts会首先执行Struts.xml中引用的拦截器,在执行完所 ...
- Struts2之过滤器和拦截器的区别
刚学习Struts2这个框架不久,心中依然有一个疑惑未解那就是过滤器和拦截器的区别,相信也有不少人跟我一样对于这个问题没有太多的深入了解 那么下面我们就一起来探讨探讨 过滤器,是在java web中, ...
- struts2拦截器与过滤器
转载:http://www.cnblogs.com/JohnLiang/archive/2011/12/15/2288376.html 过滤器,是在java web中,你传入的request,resp ...
随机推荐
- P2054 [AHOI2005]洗牌
P2054 [AHOI2005]洗牌 题目描述 为了表彰小联为Samuel星球的探险所做出的贡献,小联被邀请参加Samuel星球近距离载人探险活动. 由于Samuel星球相当遥远,科学家们要在飞船中度 ...
- 序列内第k小查询(线段树)
最近请教了一下大佬怎么求序列内第k大查询,自己又捣鼓了一下,虽然还没有懂得区间第k大查询,不过姑且做一个记录先吧 因为每个元素大小可能很大而元素之间不连续,所以我们先离散化处理一下,程序中的ori[ ...
- python 中__getitem__ 和 __iter__ 的区别
# -*- coding: utf-8 -*- class Library(object): def __init__(self): self.books = { 'title' : 'a', 'ti ...
- Java基础-进程与线程之Thread类详解
Java基础-进程与线程之Thread类详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.进程与线程的区别 简而言之:一个程序运行后至少有一个进程,一个进程中可以包含多个线程 ...
- Oracle数据库代码指令简介
重大提醒!!!oracle里面的查询,一定要把查询名大写!!!就算你创建的时候是小写字母,查询的时候也一定要大写!!! 这是oracle的课后作业,弄懂这些也差不多了吧,不懂的可以去看我的SQL se ...
- Maven学习一:使用Myeclipse创建Maven项目
使用Myeclipse2014创建Maven项目有如下几种方式: 1.创建Maven Java项目 1.1 选择新建Maven项目 1.2.选择创建简单项目 1.3.填写项目信息 1.4.创建成功后项 ...
- 视音频数据处理入门:PCM音频采样数据处理
===================================================== 视音频数据处理入门系列文章: 视音频数据处理入门:RGB.YUV像素数据处理 视音频数据处理 ...
- 悬浮按钮css
.floating-button { color: #fff; position: absolute; right: 16px; bottom: 88px; width: 56px; height: ...
- C++的一些不错开源框架,可以学习和借鉴
from https://www.cnblogs.com/charlesblc/p/5703557.html [本文系外部转贴,原文地址:http://coolshell.info/c/c++/201 ...
- IEnumerable 与 IQueryable
无论是在ado.net EF或者是在其他的Linq使用中,我们经常会碰到两个重要的静态类Enumerable.Queryable,他们在System.Linq命名空间下.那么这两个类是如何定义的,又是 ...