Netty源码分析第5章(ByteBuf)---->第4节: PooledByteBufAllocator简述
Netty源码分析第五章: ByteBuf
第四节: PooledByteBufAllocator简述
上一小节简单介绍了ByteBufAllocator以及其子类UnPooledByteBufAllocator的缓冲区分类的逻辑, 这一小节开始带大家剖析更为复杂的PooledByteBufAllocator, 我们知道PooledByteBufAllocator是通过自己取一块连续的内存进行ByteBuf的封装, 所以这里更为复杂, 在这一小节简单讲解有关PooledByteBufAllocator分配逻辑
友情提示: 从这一节开始难度开始加大, 请各位战友做好心理准备
PooledByteBufAllocator同样也重写了AbstractByteBuf的newDirectBuffer和newHeapBuffer两个抽象方法, 我们这一小节以newDirectBuffer为例, 先简述一下其逻辑
首先看UnPooledByteBufAllocator中newDirectBuffer这个方法:
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = threadCache.get();
PoolArena<ByteBuffer> directArena = cache.directArena;
ByteBuf buf;
if (directArena != null) {
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
} else {
if (PlatformDependent.hasUnsafe()) {
buf = UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity);
} else {
buf = new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
}
return toLeakAwareBuffer(buf);
}
首先 PoolThreadCache cache = threadCache.get() 这一步是拿到一个线程局部缓存对象, 线程局部缓存, 顾明思议, 就是同一个线程共享的一个缓存
threadCache是PooledByteBufAllocator类的一个成员变量, 类型是PoolThreadLocalCache(这两个非常容易混淆, 切记):
private final PoolThreadLocalCache threadCache;
再看其类型PoolThreadLocalCache的定义:
final class PoolThreadLocalCache extends FastThreadLocal<PoolThreadCache> {
@Override
protected synchronized PoolThreadCache initialValue() {
final PoolArena<byte[]> heapArena = leastUsedArena(heapArenas);
final PoolArena<ByteBuffer> directArena = leastUsedArena(directArenas);
return new PoolThreadCache(
heapArena, directArena, tinyCacheSize, smallCacheSize, normalCacheSize,
DEFAULT_MAX_CACHED_BUFFER_CAPACITY, DEFAULT_CACHE_TRIM_INTERVAL);
}
//代码省略
}
这里继承了一个FastThreadLocal类, 这个类相当于jdk的ThreadLocal, 只是性能更快, 有关FastThreadLocal, 我们在后面的章节会详细剖析, 这里我们只要知道, 继承FastThreadLocal类并且重写了initialValue方法, 则通过其get方法就能获得initialValue返回的对象, 并且这个对象是线程共享的
在这里我们看到, 在重写的initialValue方法中, 初始化了heapArena和directArena两个属性之后, 通过new PoolThreadCache()这种方式创建了PoolThreadCache对象
这里注意, PoolThreadLocalCache是一个FastThreadLocal, 而PoolThreadCache才是线程局部缓存, 这两个类名非常非常像, 千万别搞混了(我当初读这段代码时因为搞混所以懵逼了)
其中heapArena和directArena是分别是用来分配堆和堆外内存用的两个对象, 以directArena为例, 我们看到是通过leastUsedArena(directArenas)这种方式获得的, directArenas是一个directArena类型的数组, leastUsedArena(directArenas)这个方法是用来获取数组中一个使用最少的directArena对象
directArenas是PooledByteBufAllocator的成员变量, 是在其构造方法中初始化的:
public PooledByteBufAllocator(boolean preferDirect, int nHeapArena, int nDirectArena, int pageSize, int maxOrder,
int tinyCacheSize, int smallCacheSize, int normalCacheSize) { //代码省略
if (nDirectArena > 0) {
directArenas = newArenaArray(nDirectArena);
List<PoolArenaMetric> metrics = new ArrayList<PoolArenaMetric>(directArenas.length);
for (int i = 0; i < directArenas.length; i ++) {
PoolArena.DirectArena arena = new PoolArena.DirectArena(
this, pageSize, maxOrder, pageShifts, chunkSize);
directArenas[i] = arena;
metrics.add(arena);
}
directArenaMetrics = Collections.unmodifiableList(metrics);
} else {
directArenas = null;
directArenaMetrics = Collections.emptyList();
}
}
我们看到这里通过directArenas = newArenaArray(nDirectArena)初始化了directArenas, 其中nDirectArena, 默认是cpu核心数的2倍, 这点我们可以跟踪构造方法的调用链可以分析到
这样保证了每一个线程会有一个独享的arena
我们看newArenaArray(nDirectArena)这个方法:
private static <T> PoolArena<T>[] newArenaArray(int size) {
return new PoolArena[size];
}
这里只是创建了一个数组, 默认长度为nDirectArena
继续跟PooledByteBufAllocator的构造方法, 创建完了数组, 后面在for循环中为数组赋值:
首先通过new PoolArena.DirectArena创建一个DirectArena实例, 然后再为新创建的directArenas数组赋值
再回到PoolThreadLocalCache的构造方法中:
final class PoolThreadLocalCache extends FastThreadLocal<PoolThreadCache> {
@Override
protected synchronized PoolThreadCache initialValue() {
final PoolArena<byte[]> heapArena = leastUsedArena(heapArenas);
final PoolArena<ByteBuffer> directArena = leastUsedArena(directArenas);
return new PoolThreadCache(
heapArena, directArena, tinyCacheSize, smallCacheSize, normalCacheSize,
DEFAULT_MAX_CACHED_BUFFER_CAPACITY, DEFAULT_CACHE_TRIM_INTERVAL);
}
//代码省略
}
方法最后, 创建PoolThreadCache的一个对象, 我们跟进构造方法中:
PoolThreadCache(PoolArena<byte[]> heapArena, PoolArena<ByteBuffer> directArena,
int tinyCacheSize, int smallCacheSize, int normalCacheSize,
int maxCachedBufferCapacity, int freeSweepAllocationThreshold) {
//代码省略
//保存成两个成员变量
this.heapArena = heapArena;
this.directArena = directArena;
//代码省略
}
这里省略了大段代码, 只需要关注这里将两个值保存在PoolThreadCache的成员变量中
我们回到newDirectBuffer中:
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = threadCache.get();
PoolArena<ByteBuffer> directArena = cache.directArena;
ByteBuf buf;
if (directArena != null) {
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
} else {
if (PlatformDependent.hasUnsafe()) {
buf = UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity);
} else {
buf = new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
}
return toLeakAwareBuffer(buf);
}
简单分析的线程局部缓存初始化相关逻辑, 我们再往下跟:
PoolArena<ByteBuffer> directArena = cache.directArena;
通过上面的分析, 这步我们应该不陌生, 在PoolThreadCache构造方法中将directArena和heapArena中保存在成员变量中, 这样就可以直接通过cache.directArena这种方式拿到其成员变量的内容
从以上逻辑, 我们可以大概的分析一下流程, 通常会创建和线程数量相等的arena, 并以数组的形式存储在PooledByteBufAllocator的成员变量中, 每一个PoolThreadCache创建的时候, 都会在当前线程拿到一个arena, 并保存在自身的成员变量中
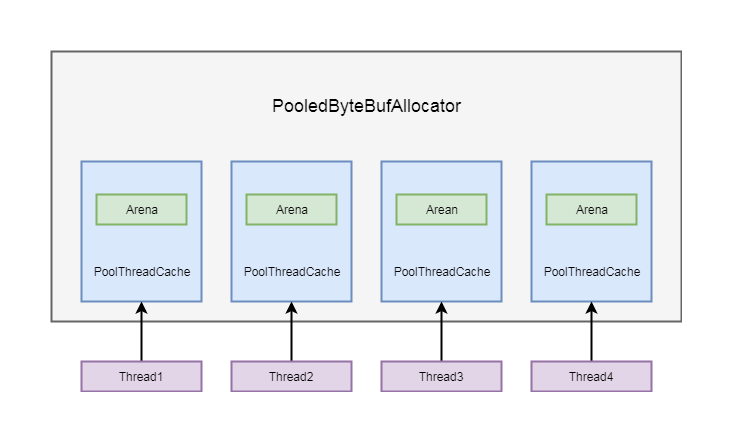
5-4-1
PoolThreadCache除了维护了一个arena之外, 还维护了一个缓存列表, 我们在重复分配ByteBuf的时候, 并不需要每次都通过arena进行分配, 可以直接从缓存列表中拿一个ByteBuf
有关缓存列表, 我们循序渐进的往下看:
在PooledByteBufAllocator中维护了三个值:
1. tinyCacheSize
2. smallCacheSize
3. normalCacheSize
tinyCacheSize代表tiny类型的ByteBuf能缓存多少个
smallCacheSize代表small类型的ByteBuf能缓存多少个
normalCacheSize代表normal类型的ByteBuf能缓存多少个
具体tiny类型, small类型, normal是什么意思, 我们会在后面讲解
我们回到PoolThreadLocalCache类中看其构造方法:
final class PoolThreadLocalCache extends FastThreadLocal<PoolThreadCache> {
@Override
protected synchronized PoolThreadCache initialValue() {
final PoolArena<byte[]> heapArena = leastUsedArena(heapArenas);
final PoolArena<ByteBuffer> directArena = leastUsedArena(directArenas);
return new PoolThreadCache(
heapArena, directArena, tinyCacheSize, smallCacheSize, normalCacheSize,
DEFAULT_MAX_CACHED_BUFFER_CAPACITY, DEFAULT_CACHE_TRIM_INTERVAL);
}
//代码省略
}
我们看到这三个属性是在PoolThreadCache的构造方法中传入的
这三个属性是通过PooledByteBufAllocator的构造方法中初始化的, 跟随构造方法的调用链会走到这个构造方法:
public PooledByteBufAllocator(boolean preferDirect, int nHeapArena, int nDirectArena, int pageSize, int maxOrder) {
this(preferDirect, nHeapArena, nDirectArena, pageSize, maxOrder,
DEFAULT_TINY_CACHE_SIZE, DEFAULT_SMALL_CACHE_SIZE, DEFAULT_NORMAL_CACHE_SIZE);
}
这里仍然调用了一个重载的构造方法, 这里我们关注这几个参数:
DEFAULT_TINY_CACHE_SIZE, DEFAULT_SMALL_CACHE_SIZE, DEFAULT_NORMAL_CACHE_SIZE
这里对应着几个静态的成员变量:
private static final int DEFAULT_TINY_CACHE_SIZE;
private static final int DEFAULT_SMALL_CACHE_SIZE;
private static final int DEFAULT_NORMAL_CACHE_SIZE;
我们在static块中看其初始化过程:
static{
//代码省略
DEFAULT_TINY_CACHE_SIZE = SystemPropertyUtil.getInt("io.netty.allocator.tinyCacheSize", 512);
DEFAULT_SMALL_CACHE_SIZE = SystemPropertyUtil.getInt("io.netty.allocator.smallCacheSize", 256);
DEFAULT_NORMAL_CACHE_SIZE = SystemPropertyUtil.getInt("io.netty.allocator.normalCacheSize", 64);
//代码省略
}
在这里我们看到, 这三个属性分别初始化的大小是512, 256, 64, 这三个属性就对应了PooledByteBufAllocator另外的几个成员变量, tinyCacheSize, smallCacheSize, normalCacheSize
也就是说, tiny类型的ByteBuf在每个缓存中默认缓存的数量是512个, small类型的ByteBuf在每个缓存中默认缓存的数量是256个, normal类型的ByteBuf在每个缓存中默认缓存的数量是64个
我们再到PooledByteBufAllocator中重载的构造方法中:
public PooledByteBufAllocator(boolean preferDirect, int nHeapArena, int nDirectArena, int pageSize, int maxOrder,
int tinyCacheSize, int smallCacheSize, int normalCacheSize) {
super(preferDirect);
threadCache = new PoolThreadLocalCache();
this.tinyCacheSize = tinyCacheSize;
this.smallCacheSize = smallCacheSize;
this.normalCacheSize = normalCacheSize; //代码省略
}
篇幅原因, 这里也省略了大段代码, 大家可以通过构造方法参数找到源码中相对的位置进行阅读
我们关注这段代码:
this.tinyCacheSize = tinyCacheSize;
this.smallCacheSize = smallCacheSize;
this.normalCacheSize = normalCacheSize;
在这里将将参数的DEFAULT_TINY_CACHE_SIZE, DEFAULT_SMALL_CACHE_SIZE, DEFAULT_NORMAL_CACHE_SIZE的三个值保存到了成员变量tinyCacheSize, smallCacheSize, normalCacheSize
PooledByteBufAllocator中将这三个成员变量初始化之后, 在PoolThreadLocalCache的initialValue方法中就可以使用这三个成员变量的值了
我们再次跟到initialValue方法中:
final class PoolThreadLocalCache extends FastThreadLocal<PoolThreadCache> {
@Override
protected synchronized PoolThreadCache initialValue() {
final PoolArena<byte[]> heapArena = leastUsedArena(heapArenas);
final PoolArena<ByteBuffer> directArena = leastUsedArena(directArenas);
return new PoolThreadCache(
heapArena, directArena, tinyCacheSize, smallCacheSize, normalCacheSize,
DEFAULT_MAX_CACHED_BUFFER_CAPACITY, DEFAULT_CACHE_TRIM_INTERVAL);
}
//代码省略
}
这里就可以在创建PoolThreadCache对象的的构造方法中传入tinyCacheSize, smallCacheSize, normalCacheSize这三个成员变量了
我们再跟到PoolThreadCache的构造方法中:
PoolThreadCache(PoolArena<byte[]> heapArena, PoolArena<ByteBuffer> directArena,
int tinyCacheSize, int smallCacheSize, int normalCacheSize,
int maxCachedBufferCapacity, int freeSweepAllocationThreshold) {
//代码省略
this.freeSweepAllocationThreshold = freeSweepAllocationThreshold;
this.heapArena = heapArena;
this.directArena = directArena;
if (directArena != null) {
tinySubPageDirectCaches = createSubPageCaches(
tinyCacheSize, PoolArena.numTinySubpagePools, SizeClass.Tiny);
smallSubPageDirectCaches = createSubPageCaches(
smallCacheSize, directArena.numSmallSubpagePools, SizeClass.Small); numShiftsNormalDirect = log2(directArena.pageSize);
normalDirectCaches = createNormalCaches(
normalCacheSize, maxCachedBufferCapacity, directArena); directArena.numThreadCaches.getAndIncrement();
} else {
//代码省略
}
//代码省略
ThreadDeathWatcher.watch(thread, freeTask);
}
其中tinySubPageDirectCaches, smallSubPageDirectCaches, 和normalDirectCaches就代表了三种类型的缓存数组, 数组元素是MemoryRegionCache类型的对象, MemoryRegionCache就代表一个ByeBuf的缓存
以tinySubPageDirectCaches为例, 我们看到tiny类型的缓存是通过createSubPageCaches这个方法创建的
这里传入了三个参数tinyCacheSize我们之前分析过是512, PoolArena.numTinySubpagePools这里是32(这里不同类型的缓存大小不一样, small类型是4, normal类型是3) , SizeClass.Tiny代表其类型是tiny类型
我们跟到createSubPageCaches这个方法中:
private static <T> MemoryRegionCache<T>[] createSubPageCaches(
int cacheSize, int numCaches, SizeClass sizeClass) {
if (cacheSize > 0) {
//创建数组, 长度为32
@SuppressWarnings("unchecked")
MemoryRegionCache<T>[] cache = new MemoryRegionCache[numCaches];
for (int i = 0; i < cache.length; i++) {
//每一个节点是ubPageMemoryRegionCache对象
cache[i] = new SubPageMemoryRegionCache<T>(cacheSize, sizeClass);
}
return cache;
} else {
return null;
}
}
这里首先创建了MemoryRegionCache, 长度是我们刚才分析过的32
然后通过for循环, 为数组赋值, 赋值的对象是SubPageMemoryRegionCache类型的, SubPageMemoryRegionCache就是MemoryRegionCache类型的子类, 同样也是一个缓存对象, 构造方法中, cacheSize, 就是其中缓存对象的数量, 如果是tiny类型就是512, sizeClass, 代表其类型, 比如tiny, small或者normal
再简单跟到其构造方法:
SubPageMemoryRegionCache(int size, SizeClass sizeClass) {
super(size, sizeClass);
}
这里调用了父类的构造方法, 我们继续跟进去:
MemoryRegionCache(int size, SizeClass sizeClass) {
//size会进行规格化
this.size = MathUtil.safeFindNextPositivePowerOfTwo(size);
//队列大小
queue = PlatformDependent.newFixedMpscQueue(this.size);
this.sizeClass = sizeClass;
}
首先会对其进行规格化, 其实就是查找大于等于当前size的2的幂次方的数, 这里如果是512那么规格化之后还是512, 然后初始化一个队列, 队列大小就是传入的大小, 如果是tiny, 这里大小就是512
最后并保存其类型
这里我们不难看出, 其实每个缓存的对象, 里面是通过一个队列保存的, 有关缓存队列和ByteBuf之间的逻辑, 后面的小节会进行剖析
从上面剖析我们不难看出, PoolThreadCache中维护了三种类型的缓存数组, 每个缓存数组中的每个值中, 又通过一个队列进行对象的存储

5-4-2
当然这里只举了Direct类型的对象关系, heap类型其实都是一样的, 这里不再赘述
这一小节逻辑较为复杂, 同学们可以自己在源码中跟踪一遍加深印象
Netty源码分析第5章(ByteBuf)---->第4节: PooledByteBufAllocator简述的更多相关文章
- Netty源码分析第5章(ByteBuf)---->第5节: directArena分配缓冲区概述
Netty源码分析第五章: ByteBuf 第五节: directArena分配缓冲区概述 上一小节简单分析了PooledByteBufAllocator中, 线程局部缓存和arean的相关逻辑, 这 ...
- Netty源码分析第5章(ByteBuf)---->第6节: 命中缓存的分配
Netty源码分析第6章: ByteBuf 第六节: 命中缓存的分配 上一小节简单分析了directArena内存分配大概流程, 知道其先命中缓存, 如果命中不到, 则区分配一款连续内存, 这一小节带 ...
- Netty源码分析第5章(ByteBuf)---->第7节: page级别的内存分配
Netty源码分析第五章: ByteBuf 第六节: page级别的内存分配 前面小节我们剖析过命中缓存的内存分配逻辑, 前提是如果缓存中有数据, 那么缓存中没有数据, netty是如何开辟一块内存进 ...
- Netty源码分析第5章(ByteBuf)---->第10节: SocketChannel读取数据过程
Netty源码分析第五章: ByteBuf 第十节: SocketChannel读取数据过程 我们第三章分析过客户端接入的流程, 这一小节带大家剖析客户端发送数据, Server读取数据的流程: 首先 ...
- Netty源码分析第5章(ByteBuf)---->第1节: AbstractByteBuf
Netty源码分析第五章: ByteBuf 概述: 熟悉Nio的小伙伴应该对jdk底层byteBuffer不会陌生, 也就是字节缓冲区, 主要用于对网络底层io进行读写, 当channel中有数据时, ...
- Netty源码分析第5章(ByteBuf)---->第2节: ByteBuf的分类
Netty源码分析第五章: ByteBuf 第二节: ByteBuf的分类 上一小节简单介绍了AbstractByteBuf这个抽象类, 这一小节对其子类的分类做一个简单的介绍 ByteBuf根据不同 ...
- Netty源码分析第5章(ByteBuf)---->第3节: 缓冲区分配器
Netty源码分析第五章: ByteBuf 第三节: 缓冲区分配器 缓冲区分配器, 顾明思议就是分配缓冲区的工具, 在netty中, 缓冲区分配器的顶级抽象是接口ByteBufAllocator, 里 ...
- Netty源码分析第5章(ByteBuf)---->第8节: subPage级别的内存分配
Netty源码分析第五章: ByteBuf 第八节: subPage级别的内存分配 上一小节我们剖析了page级别的内存分配逻辑, 这一小节带大家剖析有关subPage级别的内存分配 通过之前的学习我 ...
- Netty源码分析第5章(ByteBuf)---->第9节: ByteBuf回收
Netty源码分析第五章: ByteBuf 第九节: ByteBuf回收 之前的章节我们提到过, 堆外内存是不受jvm垃圾回收机制控制的, 所以我们分配一块堆外内存进行ByteBuf操作时, 使用完毕 ...
随机推荐
- python第十三课——嵌套循环
2.嵌套循环: 概念:循环中再定义循环,称为嵌套循环: [注意]嵌套循环可能有多层,但是一般我们实际开发最多两层就可以搞定了(99%的情况) 格式: 1).while中套while常用 2).whil ...
- 代理错误[WinError 10061]
操作过程: import urllib.request from urllib.error import URLError,HTTPError proxy_handler = urllib.reque ...
- struts2中的文件上传和下载
天下大事,必做于细.天下难事,必作于易. 以前见过某些人,基础的知识还不扎实就去学习更难的事,这样必定在学习新的知识会非常迷惑结果 再回来又一次学习一下没有搞懂的知识,这必定会导致学习效率的下降!我写 ...
- Java并发编程--3.Lock
Lock接口 它提供3个常用的锁 lock() : 获不到锁就就一直阻塞 trylock() :获不到锁就立刻放回 或者 定时的,轮询的获取锁 lockInterruptibly() : 获不到锁时阻 ...
- Java基础加强之集合
集合整体框架图 各集合框架的概述 1. Collection(常用List和Set,不常用Queue和Vector),单元素集合. 2. Map(常用HashMap和TreeMap,不常用HashTa ...
- etherlime-1-Quick Start
https://etherlime.readthedocs.io/en/latest/getting-started.html Quick Start Installing全局安装 npm i -g ...
- CSS属性之word-break:break-all强制性换行
一般情况下,元素拥有默认的white-space:normal(自动换行,PS:不换行是white-space:nowrap),当录入的文字超过定义的宽度后会自动换行,但当录入的数据是一堆没有空 ...
- HDU 1203 01背包变形题,(新思路)
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=1203 I NEED A OFFER! Time Limit: 2000/1000 MS (Java/ ...
- iOS开发-Object-C获取手机设备信息(UIDevice)
一.获取UiDevice设备信息 // 获取设备名称 NSString *name = [[UIDevice currentDevice] name]; // 获取设备系统名称 NSString *s ...
- 深度学习框架caffe在ubuntu下的环境搭建
深度学习实验室服务器系统配置手册 目录: 一,显卡安装 二,U盘启动盘制作 三,系统安装 四,系统的基本配置 五,安装Nvidia驱动 六,安装cuda ...