SEO优化上首页之搜索引擎蜘蛛Spider原理
Spider,蜘蛛,又名网页网络爬虫、网络机器人,是按照一定策略不断抓取互联网网页的特定程序。蜘蛛抓回的页面创建索引后参与排名,等待用户检索。为了网站优化自然排名上首页,精灵儿工作室下面详细剖析Spider原理。

蜘蛛分类
目前网络上的蜘蛛根据其作用及特征主要可分4类:批量型蜘蛛、增量型蜘蛛、垂直型蜘蛛和Deep Web型蜘蛛。
1. 批量型蜘蛛
该类蜘蛛有确切的抓取范围和目标,一般是一次具体的任务而出发,用于批量采集指定的数据项,达到预定目标后就会停止。数据采集工具或程序,就是这类蜘蛛。
2. 增量型蜘蛛
该类蜘蛛没有限定抓取范围和目标,一直永无休止的抓取下去,增量型蜘蛛增量提现在两方面,一是抓取尽可能全的网页,二是对已经抓取到的网页进行再次抓取和更新。
另外有一种说法“通用型蜘蛛”,这种蜘蛛业内有两种定义,都是永无休止的抓取网页,他们的区别在于是否包含增量更新,如果包含则与增量型蜘蛛是一种。
3.垂直型蜘蛛
也叫聚焦蜘蛛,该类蜘蛛抓取指定类型的内容,覆盖面没有通用的增量型蜘蛛抓取的广,可以说是增量型蜘蛛的特定子类。淘宝搜索、优酷搜索、微信搜索等蜘蛛属于垂直型蜘蛛。
4. Deep Web型蜘蛛
互联网里,有海量的网页与表层网络是脱钩的,普通的蜘蛛抓取不到这些页面,他们就是"暗网",另外一些需要注册登录才能访问的页面,蜘蛛也无法抓取到,目前各搜索引擎正在努力研究自己对这些内容进行抓取,它就是Deep Web型蜘蛛。目前来说,对于暗网数据的获取主要思路仍然是通过开放平台采用数据提交的方式来解决,例如“百度站长平台”“百度开放平台”等等。
百度、谷歌、搜狗、360搜索、神马等大型搜索引擎同时多个蜘蛛异步并发工作,以增量型蜘蛛为主,垂直型蜘蛛和Deep Web型蜘蛛为辅。
抓取入口
蜘蛛抓取数据都需要起点,也就是入口,它们从指定的入口开启全网永不停止的抓取之旅。
蜘蛛抓取入口主要有:
(1)平台人工录入的种子网站。初始种子站一般是大全高权重站、知名导航站、大型DNS服务器站等,如网易官网、人民网、hao123。
(2)网站站长主动提交的网址。新网站可以把网址主动告诉搜索引擎,可以提高被抓取速度。百度、360、搜狗、谷歌等搜索引擎都有专门的提交入口。对一些专网暗网,搜索引起也只能等待主动提交入口。
百度链接提交入口:
http://zhanzhang.baidu.com/linksubmit/url
360搜索引擎登录入口:
http://info.so.360.cn/site_submit.html
搜狗网站收录提交入口:http://fankui.help.sogou.com/index.php/web/web/index?
Google网站收录提交入口:
https://www.google.com/webmasters/tools/submit-url
抓取策略
互联网页面几乎是无限的,为了在有限的服务器资源下尽量高效的实现网页抓取,蜘蛛会采取多种策略。在蜘蛛眼中,网络上的页面分为已抓取页面、待抓取页面、未抓取页面和无法抓取页面。
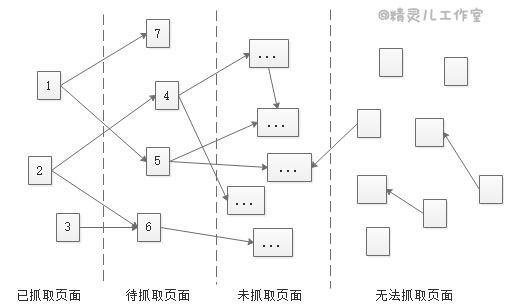
为了提高工作效率,蜘蛛程序会建立已抓取页面列表和待抓取页面列表,已被抓取的页面进入已抓取列表,新发现的页面进入待抓取页面列表。未抓取页面,指暂未发现的页面,但链路是通的,迟早能被抓取的页面。无法抓取的页面,指链路不通,永远到达不了的页面,比如暗网。
当蜘蛛分析一个页面时,发现了很多新的链接,这是面对一个选择:是先进入新发现的第一个页面,还是在本页继续登记新发现的第2,3,4...个页面。

深度优先策略是一直沿着纵深抓取,知道无法走下去,回溯到上一级兄弟页面。广度优先策略是分层一批批抓取。如果服务器资源无限,理论上两种策略最终结果一样,但现实服务器资源优先,需要尽快高效的抓取,一般采取广度+深度综合方式抓取策略。
除了深度优先策略、广度优先策略,还有pr优先策略、反链策略、社会化分享指导策略等等。每个策略各有优劣,在实际情况中往往是多种策略结合使用以达到最优的抓取效果。
从功能和重要性角度分析,蜘蛛会优先抓取权重高的网站和网站的重要页面。权重高的网站一般有丰富的内容、良好的结构、权威值得信赖等,被特殊照顾利于全网抓取效率。网站的重要页面是指首页、目录页,它们相对比内容详情页更有优势。
::本节知识点得出优化经验,(1)多发外链,特别是高质量的外链可以建立并缩短蜘蛛爬行路径,提高网页优化效率;(2)网站首页和目录比内容详情页重要、流量更大,seo优化上首页的落地页尽量放在首页其次目录页。
更新策略
蜘蛛除了不断抓取新页面,另一个任务是更新已抓取页面。蜘蛛再次抓取,更新策略主要依据有哪些?
1. 用户行为体验
用户行为体验指页面结构、点击率、回看率、评论数等。界面结构清洁,加载速度快更具优势;点击率高,用户回看率高,解决用户需求概率大更具优势;评论数多、点赞收藏等互动多更有优势。
2. 网站内容质量
搜索引擎非常重视用户体验,非常喜欢持续生产原创内容网站,因为这对网络价值贡献大。
3. 历史更新频率
蜘蛛每次访问页面会记录页面更新情况,如果页面长期不更新,几次之后蜘蛛就基本不再光顾。如果蜘蛛每次访问页面,该页面内容更新了,并且是有规律的更新,那么蜘蛛适应这种更新规律,尽量匹配规律抓取,提高其工作效率。
4. 网页权重
内容丰富的大站、权威网站会被重点照顾,另外政府部门网站、认证的品牌官方网站、甚至已备案网站一般更新频率高。搜索引起是基于网址链接的权重信任传导,高质量网站的外链效果非常好。
5. 网页类型
全网的网页类型很有限,蜘蛛很容易识别各网页类型。网页类型包括网站首页、目录页、专题页、内容详情页,蜘蛛对他们的更新频率依次降低。
::本节是SEO优化的重要内容,掌握了才能做好网站排名优化。另外,对应更新特别慢的页面,可以通过主动推送、sitemap、手工提交和自动推送提交链接,也可以尝试使用百度站长平台的”抓取诊断“工具抓取,有利于百度快速更新。
蜘蛛和正常用户的区别
虽然搜索引起的蜘蛛尽量模拟像正常用户访问网页,但还是有些区别,熟悉他们之间的区别对SEO优化很有帮助。
1. 蜘蛛可以识别网页是否隐藏信息、是否挂黑链接等,而正常用户一般无法识别。
2. 蜘蛛目前无法读取和识别JS、Iframe、Ajax、图片和Flash内容,而正常用户可以。
3. 蜘蛛访问没有Cookie,而正常用户有。
4. 蜘蛛不会注册网址,无法访问注册后才能使用的页面(比如下单支付),而正常用户会。
5. 蜘蛛不会读取网址robots配置屏蔽的页面,而正常用户会。
6. 蜘蛛抓取动态动态参数的界面可能会陷入死循环(比如万年历),而正常用户不会。
7. 蜘蛛对网页直接访问,不会Referer,而正常用户除了会直接访问,还会Referer。
Referer允许由客户端指定资源的 URI 来自于哪一个请求地址,Referer 请求头让服务器能够拿到请求资源的来源,可以用于分析用户的兴趣爱好、收集日志、优化缓存等等。同时也让服务器能够发现过时的和错误的链接并及时维护。通过Referer找到你网站上的死链、追踪错误或者找到用户是通过哪些搜索条件找到你的网站的。它也可以被用来增强安全性:检查 Referer 头是一个阻止跨站请求伪造的办法。
::熟悉本节内容,可以极大提高网络安全性,掌握了这些技术,理论上攻守都可以,精灵儿工作室呼吁大家遵守网络行为规范,用正规的SEO优化方法自然排名上首页,只要能把握关键点,有基础(有内容正规,有更新),2~7天seo优化上首页问题不大。
SEO优化上首页之搜索引擎蜘蛛Spider原理的更多相关文章
- SEO优化上首页之搜索引擎用户需求理解
经过前面<搜索引擎原理SEO优化上首页之网络蜘蛛Spider>和<搜索引擎原理SEO优化上首页之内容处理与创建索引>介绍,搜索引擎已经完成页面抓取和分析,并把原始页面.索引等信 ...
- SEO优化上首页之搜索引擎原理内容处理与索引
上文<搜索引擎原理SEO优化上首页之蜘蛛Spider>详细介绍了蜘蛛的分类.抓取入口.抓取策略和更新策略.搜索引擎已把页面抓取回来,接下来是解析页面内容,主要包含判断页面类型.提取页面主题 ...
- SEO优化上首页之搜索引擎原理简要
搜索引擎(Search Engine)是特定的计算机程序,它根据一定的策略.从互联网上搜集信息,对信息进行处理后,为用户提供检索服务,并将用户结果展示给用户. 搜索引擎优化(Search Engine ...
- SEO优化上首页之搜索引擎作弊案例与反作弊原理
搜索引擎流量价值巨大,有不少人专门研究排名机制,利用搜索引擎漏洞作弊,寻求快速提高网站排名,进而获取更多的流量和利益,甚至有的网站优化公司专门提供作弊服务.搜索引擎为了杜绝这种情况,必须能过滤大量垃圾 ...
- SEO优化上首页之搜索引擎排名规则
搜索引擎建立索引的网页数以万亿计,用户搜索的关键词也是海量,如果每个用户提交搜索请求后,搜索引擎都去数以万亿的索引中重新排名网页,效率将非常低下.根据2-8法则,80%是查询是集中在相同的20%内容上 ...
- 网站SEO优化如何让百度搜索引擎绝的你的网站更有抓取和收录价值呢?_孙森SEO
今天孙森SEO为大家唠唠网站到底该如何优化才会让百度搜索引擎绝的你的网站更有抓取和收录价值呢? 第一方面:网站创造高品质的内容,可以为用户提供独特的价值. 1.百度作为搜索引擎,网站内容必须满足 搜索 ...
- 网站seo优化教你如何引蜘蛛爬行网站
1. 网站和页面的权重 这个是咱们都知道的,网站和页面的权重越高的话,蜘蛛一般会匍匐的越深,被蜘蛛录入的页面也更多一些.可是一个新的网站,权重到达1的话是相对简单的,可是假如想要把权重再网上添加则会越 ...
- 82.使用vue后怎么针对搜索引擎做SEO优化?
什么是SEO 搜索引擎优化(Search engine optimization,简称SEO),指为了提升网页在搜索引擎自然搜索结果中(非商业性推广结果)的收录数量以及排序位置而做的优化行为,是为了从 ...
- 【百度SEO优化】如何让蜘蛛爬行你的网站
大家都知道,现在做网站简单,但是推广就比较困难了,可能一些商家引入投资,直接烧钱做广告来推广,但是对于一些小站长,是没有那么多资金的.因此我们就要懂得一些SEO优化的知识了,简单介绍一下: 怎么让百度 ...
随机推荐
- Django之模型注册
接着上一篇:Django之创建项目 目的:一个空项目创建好了,我们在models.py中新增3张表并在admin界面中显示,并能操作它们. 示例models 编辑models.py # -*- cod ...
- SQLSERVER的 筛选索引(Fiter Index)
fiter index(筛选索引)是SQL Server的一项功能,可使此数据库与众不同. 筛选索引的概念 SQL Server中常用的索引是一种物理结构,它包含来自所有行的一组选定列的值 在一张桌子 ...
- MySQL Group Replication配置
MySQL Group Replication简述 MySQL 组复制实现了基于复制协议的多主更新(单主模式). 复制组由多个 server成员构成,并且组中的每个 server 成员可以独立地执行事 ...
- [翻译] UIColor-uiGradientsAdditions
UIColor-uiGradientsAdditions https://github.com/kaiinui/UIColor-uiGradientsAdditions Beautiful color ...
- WDS使用捕获映像制作企业自定义映像
来源:http://www.07net01.com/linux/WDSshiyongbuhuoyingxiangzhizuoqiyezidingyiyingxiang_545749_137448761 ...
- 利用jTessBoxEditor工具进行Tesseract3.02.02样本训练,提高验证码识别率
1.背景 前文已经简要介绍tesseract ocr引擎的安装及基本使用,其中提到使用-l eng参数来限定语言库,可以提高识别准确率及识别效率. 本文将针对某个网站的验证码进行样本训练,形成自己的语 ...
- Apache源码安装--httpd-2.2.34
一.下载源码包 二.将源码包移动/usr/src/目录 三.解压源码包,并进入目录:tar -xzvf httpd-2.2.34.tar.gz,cd httpd-2.2.34 四.安装依赖包:yum ...
- python 统计学的各种检验
1.使用python中的Numpy进行t检验 http://www.atyun.com/7476.html 2.scipy中的卡方检验 http://wiki.mbalib.com/wiki/%E5% ...
- C#综合揭秘——分部类和分部方法
在面向对象的“封装闭合性”开发原则中,一向提倡的是把独立的功能封装在一个类里面的!但从Visual Studio 2005开发,系统提供了一个分部类的开发方式一直受到争议,很多人认为把同一类的功能分布 ...
- php功能模块学习笔记
字符串处理: explode爆炸 implode聚爆explode() 把字符串打散为数组.语法:explode(separator,string,limit) 本函数返回由字符串组成的数组, ...