[Python爬虫] 之二十六:Selenium +phantomjs 利用 pyquery抓取智能电视网站图片信息
一、介绍
本例子用Selenium +phantomjs爬取智能电视网站(http://www.tvhome.com/news/)的资讯信息,输入给定关键字抓取图片信息。
给定关键字:数字;融合;电视
二、网站信息
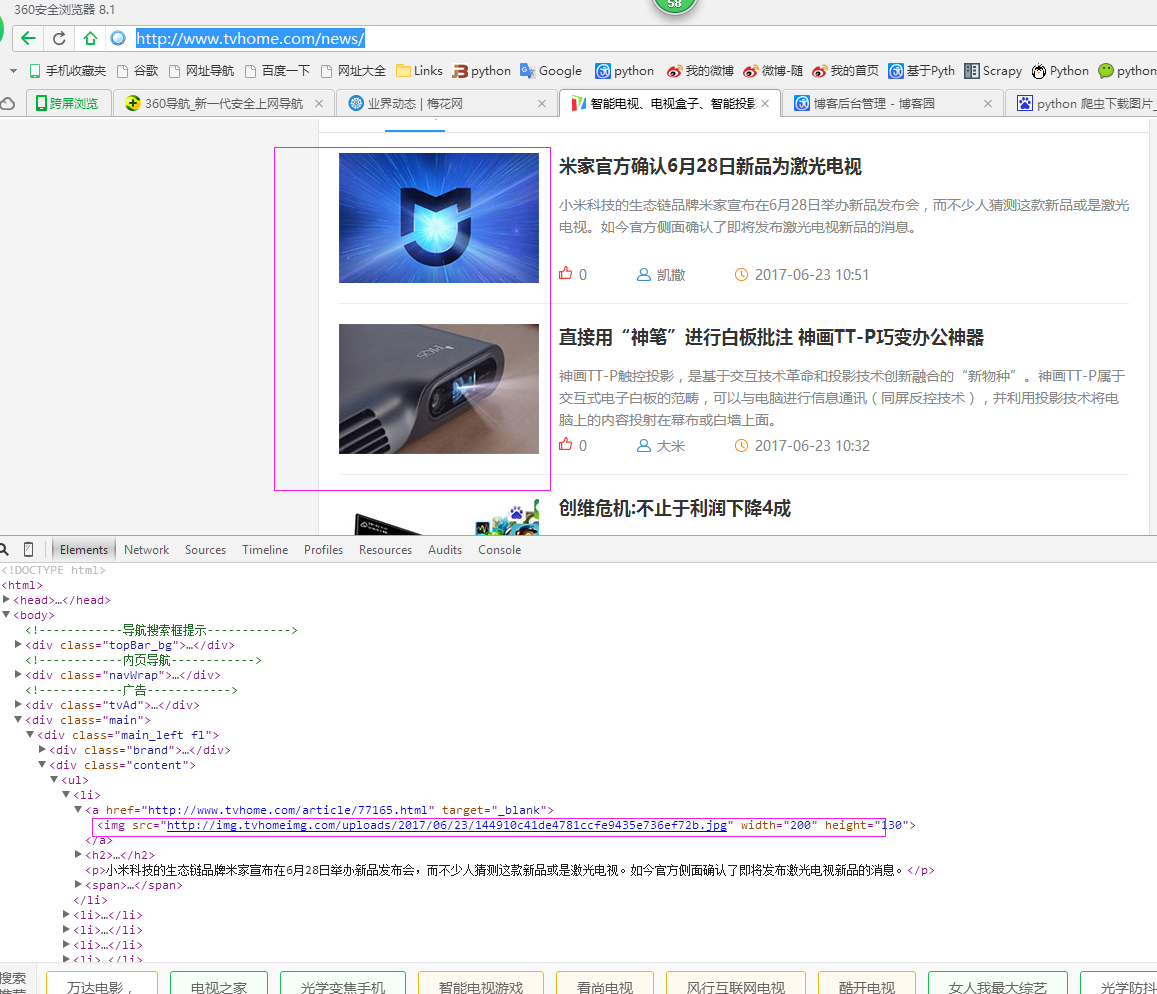
三、数据抓取
针对上面的网站信息,来进行抓取
1、首先抓取信息列表
抓取代码:Elements = doc('div[class="main_left fl"]').find('div[class="content"]').find('ul').find('li')
2、抓取图片
抓取代码:imgurl = element('a').find('img').attr('src');
self.down_picture(imgurl)
四、完整代码
def down_picture(self, imgurl):
"""
下载图片到本地
:param imgurl: 图片url
"""
# http://img.tvhomeimg.com/uploads/2017/06/23/144910c41de4781ccfe9435e736ef72b.jpg
if len(imgurl)>0:
fileName = ''
if imgurl.rfind('/')>0:
fileName = imgurl[imgurl.rfind('/') + 1:]
u = urllib.urlopen(imgurl)
data = u.read() strpath = os.path.dirname(os.getcwd())+'\picture'
with open(os.path.join(strpath, fileName), 'wb') as f:
f.write(data)
[Python爬虫] 之二十六:Selenium +phantomjs 利用 pyquery抓取智能电视网站图片信息的更多相关文章
- [Python爬虫] 之二十三:Selenium +phantomjs 利用 pyquery抓取智能电视网数据
一.介绍 本例子用Selenium +phantomjs爬取智能电视网(http://news.znds.com/article/news/)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字 ...
- [Python爬虫] 之二十一:Selenium +phantomjs 利用 pyquery抓取36氪网站数据
一.介绍 本例子用Selenium +phantomjs爬取36氪网站(http://36kr.com/search/articles/电视?page=1)的资讯信息,输入给定关键字抓取资讯信息. 给 ...
- [Python爬虫] 之二十七:Selenium +phantomjs 利用 pyquery抓取今日头条视频
一.介绍 本例子用Selenium +phantomjs爬取今天头条视频(http://www.tvhome.com/news/)的信息,输入给定关键字抓取图片信息. 给定关键字:视频:融合:电视 二 ...
- [Python爬虫] 之二十:Selenium +phantomjs 利用 pyquery通过搜狗搜索引擎数据
一.介绍 本例子用Selenium +phantomjs 利用 pyquery通过搜狗搜索引擎数据()的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字:融合:电视 抓取信息内如下: 1.资讯 ...
- [Python爬虫] 之三十:Selenium +phantomjs 利用 pyquery抓取栏目
一.介绍 本例子用Selenium +phantomjs爬取栏目(http://tv.cctv.com/lm/)的信息 二.网站信息 三.数据抓取 首先抓取所有要抓取网页链接,共39页,保存到数据库里 ...
- [Python爬虫] 之二十九:Selenium +phantomjs 利用 pyquery抓取节目信息信息
一.介绍 本例子用Selenium +phantomjs爬取节目(http://tv.cctv.com/epg/index.shtml?date=2018-03-25)的信息 二.网站信息 三.数据抓 ...
- [Python爬虫] 之二十八:Selenium +phantomjs 利用 pyquery抓取网站排名信息
一.介绍 本例子用Selenium +phantomjs爬取中文网站总排名(http://top.chinaz.com/all/index.html,http://top.chinaz.com/han ...
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一.介绍 本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息. 给定 ...
- [Python爬虫] 之二十四:Selenium +phantomjs 利用 pyquery抓取中广互联网数据
一.介绍 本例子用Selenium +phantomjs爬取中广互联网(http://www.tvoao.com/select.html)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字:融 ...
随机推荐
- linux基础编程 套接字socket 完整的服务器端多线程socket程序【转】
转自:http://blog.csdn.net/ghostyu/article/details/7737203 此段程序来自我的一个项目中,稍微做了些修改,运行稳定,客户端程序比较简单所以未编写,可以 ...
- vue学习记录:vue引入,validator验证,数据信息,vuex数据共享
最近在学习vue,关于学习过程中所遇到的问题进行记录,包含vue引入,validator验证,数据信息,vuex数据共享,传值问题记录 1.vue 引入vue vue的大致形式如下: <temp ...
- Spring MVC 基础篇4
Spring MVC Controller中返回数据到页面 1.使用ModelAndView 进行数据返回到请求页面 2.利用Map类型的入参进行Controller返回到页面上 3.将数据放到Ses ...
- solr in action 第三章
document: 每个document由一个或者多个域(field)组成,每个域都有自己的类型:string, text, etc. 理论上域的类型有无限多个,因为一个域的类型可以由零个或多个分析阶 ...
- 更改yum源为网易的
更改yum源为网易的. mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup cd /etc/yu ...
- UTF-8编码中BOM的检测与删除[linux下命令]
Posted on 2011-05-14 所谓BOM,全称是Byte Order Mark,它是一个Unicode字符,通常出现在文本的开头,用来标识字节序(Big/Little Endian),除此 ...
- AC日记——病毒侵袭持续中 hdu 3065
3065 思路: 好题: 代码: #include <queue> #include <cstdio> #include <cstring> using names ...
- win上配置nginx
win上配置nginx 网上配置nginx的教程大多都是linux上的,今天贴出来nginx在win上的配置,在此篇配置中,nginx代理了Tomcat以及node服务.配置如下: 注意:根据实际经验 ...
- NAT+穿洞基础知识梳理
参考:https://www.cnblogs.com/shilxfly/p/6589255.html https://blog.csdn.net/phoenix06/article/details/7 ...
- Codeforces 608 A. Saitama Destroys Hotel
A. Saitama Destroys Hotel time limit per test 1 second memory limit per test 256 megabytes input ...