【APUE】Chapter5 Standard I/O Library
5.1 Introduction
这章介绍的standard I/O都是ISOC标准的。用这些standard I/O可以不用考虑一些buffer allocation、I/O optimal-sized的细节,增加了易用性。但是也有一些问题。
5.2 Streams and FILE Objects
1. Chapter3中提到的I/O routines的核心是file descriptor;而在standard I/O背景下,相应的概念换成了stream。
2. standard I/O可以设置signle character和multi character的不同模式。
5.3 Standard Inpupt, Standard Output, and Standard Error
STDIN_FILENO, STDOUT_FILENO, STDERR_FILENO 也在standard I/O中有定义。头文件在<stdio.h>中
5.4 Buffering
standard I/O中调用了read和write这样的calls。而standard I/O的设计目的,有一条就是尽量减小调用read和write的次数。
buffering的方式分为以下三种:
1. Fully buffered
把buffer写满了就往外输出。如果强制往外输出,可以调用fflush函数。
2. Line buffered
根绝是否出现newline character判断是否往外输出buffer的内容。
但是,有些时候Line buffered等不到newline character也会被动刷新输出:
(1)standard I/O留给Line buffer的容量写满了,等不到newline character出现就刷新输出。这个比较好理解,满了就输出了。
(2)当有来自unbuffered stream或line-buffered的input请求,会强制刷新输出。这个书上讲的没理解,具体看到例子再说。
3. Unbuffered
这个比较好理解,不用buffer直接输出。例子,一般的error stream都是unbuffered的方式。
另,介绍了一个函数fflush(FILE *fp) 当fp==NULL的时候,刷新全部的output stream。
5.5 Opening a Stream
记住俩函数:
fopen(const char *restrict pathname, const char *restrict type) (char *restrict意思是参数只能是受限制的字符串,这里只能是'w','r'这类的限制的几个字符串)
fclose(FILE *fp)
5.6 Reading and Writing a Stream
读单个字符的三个函数:
int getc(FILE *fp)
int fgetc(FILE *fp)
int getchar(void)
三个函数的返回值有如下几种情况:
(1)如果执行成功且没有到末尾,则返回next character
(2)如果执行到文件末尾了,则返回EOF
(3)如果出错了,则返回error
书上关于返回值有这样的陈述“These three functions return the next character as an unsigned char converted to an int”。
读的是字符为什么返回值要采用整数的形式?
因为,可以区分正常字符、文件末尾、出错三种情况。如果是正常字符,转换成int后都是正的;如果是EOF和error则都是负的。
有的系统上EOF和error都是-1,那么还怎么区分是出错了还是读到文件末尾了呢?
还有以下两个函数,判断到底是error为真,还是eof为真:
int ferror(FILE *fp)
int feof(FILE *fp)
如果是真的,则返回非零;否则,返回零。
5.7 Line-at-a-Time
char *fgets(char *restrict buf, int n, FILE *restrict fp)
一次读一行,最多读n-1个字符;超过n-1个字符的部分就被抹掉了。n-1的原因是buffer必须是以null结束的
int fputs(const char*restrict str, FILE *restrict fp)
注意是否用补上换行符。
5.8 Standard I/O Efficiency
比较两种读写模式的效率,读一个500M大小的文件,然后在写到同样的文件中;比较这一读一写的效率。
代码1:
#include "apue.h" int main()
{
int c;
while ((c=getc(stdin))!=EOF)
if (putc(c, stdout)==EOF)
err_sys("output error");
if (ferror(stdin))
err_sys("input error");
exit();
}
执行耗时如下:

代码2:
int main()
{
char buf[MAXLINE];
while (fgets(buf, MAXLINE, stdin)!=NULL)
{
if (fputs(buf,stdout)==EOF) {
err_sys("output error");
}
} if (ferror(stdin)) {
err_sys("input error");
}
exit();
}
执行耗时如下:

代码1是逐个读字符,代码2是逐行读字符。对比二者执行结果,可以获得以下的结论:
(1)对比二者的耗时,发现system time都差不多:这意味着kernel耗时都差不多。
(2)差别在于user time不一样:原因就在于fgetc fputc读写同样的字符串需要调用的系统read write次数多;而fgets fputs调用的read write次数少很多,所以real time上体现了效率提高了。
5.9 Binary I/O
size_t fread(void *restrict ptr, size_t size, size_t nobj, FILE *restrict fp)
size_t fwrite(const void *restrict ptr, size_t size, size_t nobj, FILE *restrict fp)
每次读写一个完整的数据结构:struct int float这样的内容。
这样binary I/O的关键就在于这样一个完整的数据结构占多少byte。
书上提醒,完整的数据结构到底占多少byte跟编译器complier有关,还跟不同的机器架构有关,即提醒此处可能有坑。
5.10 Positioning a Stream
long ftell(FILE *fp) :返回current file position indicator if OK, -1L on error
int fseek(FILE *fp, long offset, int whence) :操作stream;通过whence参数控制操作的方式;成功返回0,出错返回-1
void rewind(FILE *fp): stream移动到文件的beginning
类比Chapter3.6提出来的lseek()函数,lseek这个函数集成的功能比较多,可以直接得到fd对应的offset位置;而fseek由于只能返回01,因此需要单拎出来ftell这个函数来返回stream的当前位置
书上还介绍了两个ISO C standard的函数:
int fgetpos(FILE *restrict fp, fpos_t *restrict pos)
int fsetpos(FILE *fp, const fpos_t *pos)
书上对这两个函数给出的tips是便于porting to non-Unix systems (便于移植)
5.11 Formatted I/O
printf和scanf函数,用到再细看
5.12 Implementation Details
1. 给出了Unix System中,standard I/O最终还是调用了Chapter3中介绍的各种I/O routine来完成的。因此,每个standard I/O stream必然对应一个file descriptor。靠int fileno(FILE *fp)来实现这个功能。
2. 给出了一个简易的buffering three standard stream的实现,具体如下:
#include "apue.h" void pr_stdio(const char *, FILE *);
int is_unbuffered(FILE *);
int is_linebuffered(FILE *);
int buffer_size(FILE *); int main()
{
FILE *fp;
fputs("enter any character\n", stdout);
if(getchar()==EOF)
err_sys("getchar error");
fputs("one line to standard error\n",stderr); pr_stdio("stdin", stdin);
pr_stdio("stdout", stdout);
pr_stdio("stderr", stderr); if ((fp=fopen("/etc/passwd","r"))==NULL) {
err_sys("fopen error");
}
if (getc(fp)==EOF)
err_sys("getc error");
pr_stdio("/etc/passwd",fp);
exit();
} void pr_stdio(const char *name, FILE *fp)
{
printf("stream = %s, ", name);
if (is_unbuffered(fp)) {
printf("unbuffered");
}
else if (is_linebuffered(fp)) {
printf("line buffered");
}
else
printf("fully buffered");
printf(", buffer size = %d\n", buffer_size(fp));
} #if defined(_IO_UNBUFFERED)
int is_unbuffered(FILE *fp)
{
return(fp->_flags & _IO_UNBUFFERED);
} int is_linebuffered(FILE *fp)
{
return(fp->_flags & _IO_LINE_BUF);
} int buffer_size(FILE *fp)
{
return(fp->_IO_buf_end - fp->_IO_buf_base);
} #elif defined(__SNBF)
int is_unbuffered(FILE *fp)
{
return(fp->_flags & __SNBF);
} int is_linebuffered(FILE *fp)
{
return(fp->_flags & __SLBF);
} int buffer_size(FILE *fp)
{
return(fp->_bf.size);
} #elif defined(_IONBF) #ifdef _LP64
#define _flag __pad[4]
#define _flag __pad[1]
#define _base __pad[2]
#endif int is_unbuffered(FILE *fp)
{
return(fp->_flags & _IONBF);
} int is_linebuffered(FILE *fp)
{
return(fp->_flags & _IOLBF);
} int buffer_size(FILE *fp)
{
#ifdef _LP64
return(fp->_base - fp->_ptr);
#else
return(BUFSIZ);
#endif
} #else #error unknown stdio implementation #endif
执行这个代码,结果如下:
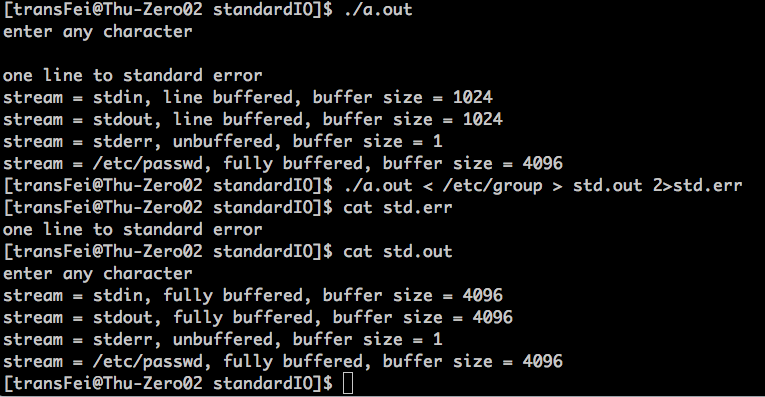
(1)如果输入输出都是终端,则系统给出的buffer策略是line buffered
(2)如果输入输出都是文件,则系统给出的buffer策略是fully buffered
(3)如果是error输出,则默认是unbuffered策略
5.13 Temporary Files
1. 给了char *tmpnam(char *ptr) 和 FILE *tmpfile(void)的例子,使用方法。
#include <stdio.h>
#include <stdlib.h> #define MAXLINE 4096 int main()
{
char name[L_tmpnam], line[MAXLINE];
FILE *fp; printf("%s\n", tmpnam(NULL)); tmpnam(name);
printf("%s\n",name); fp = tmpfile();
fputs("one line of output\n",fp);
rewind(fp);
fgets(line, sizeof(line), fp);
fputs(line, stdout);
exit();
}
代码执行结果如下:

(1)前两个printf是讲tmpnam的用法,作用是生成个独一无二的文件名;并展示了参数是NULL和不是NULL都是怎么个用法。
(2)后面一段是先用tmpfile()生成一个临时文件,向文件中写一行,再把写进去的内容读出来输出到终端。这样证明确实产生了临时文件,并且随着程序结束,临时文件也没有了。
2. 介绍了更为安全的两个临时文件函数char *mkdtemp(char *template) 和 int mkstemp(char *template)
从紧上面1的代码执行结果中可以看到有个关于tmpnam的warning。这个warning的原因是什么呢?
tmpnam函数有个弊端:tmpnam产生独一无二的临时文件名并不是一个原子操作;可能有个time window,tmpnam产生文件名A的同时,另一个应用产生相同文件名的文件了。
因此,就需要引出mkstemp这样的函数,保证是原子操作,即函数产生的文件名是独一无二的。
首先得明确一下临时文件的产生过程:1. 生成一个独一无二的临时文件名 2.马上unlink了
为什么要这么做呢?kernel判断一个file是否可以被delete主要取决于两点:
1. link数是0了
2. 没有process在使用这个file
因此,按照上述临时文件的原理,先生成文件名,然后unlink,则等着当前的process结束,或放弃对file的占用,kernel就把file给delete了。
这里需要注意的是,unlink这个操作需要我们自己来完成。
看个例子:
#include "apue.h"
#include <errno.h> void make_temp(char *template)
{
int fd;
struct stat sbuf; if ((fd = mkstemp(template))<) {
err_sys("can't create temp file");
}
printf("temp name = %s\n", template);
close(fd); if (stat(template,&sbuf)<) {
if(errno==ENOENT)
printf("file doesn't exist\n");
else
err_sys("stat failed");
}
else
{
printf("file exists\n");
unlink(template);
}
} int main()
{
char good_template[] = "/tmp/dirXXXXXX";
char *bad_template = "/tmp/dirXXXXXX"; printf("tring to crate first temp file..\n");
make_temp(good_template);
printf("trying to create second temp file...\n");
make_temp(bad_template);
exit();
}
代码执行结果如下:
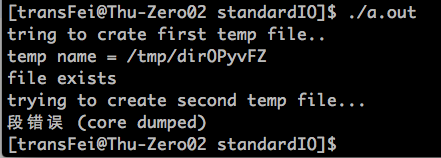
从这段代码中可以看到,临时文件确实是存在的(“file exists”可以说明),并且需要我们手工unlink。
这里还涉及到一个细节,常量字符串不能修改,如果把常量字符串送到mkstemp函数中,会报段错误。因为,常量字符串在只读segment上面,mkstemp函数要修改这个常量字符串就会报错。
5.14 Memory Streams
这个部分说的是:是否可以像读写文件一样操作内存中的一块区域。下面这个函数就帮助user实现了这样的功能。
FILE *fmemopen(void *restrict buf, size_t size, const char *restrict type)
直接看一段代码:
#include "apue.h" #define BSZ 48 int pr_print(char buf[])
{
int i;
for ( i=; i<BSZ; ++i) printf("%c",buf[i]=='\0'?'#':buf[i]);
printf("\n");
} int pr_offset(FILE *fp)
{
printf(" memeory stream offset: %ld\n",ftell(fp));
} int main()
{
FILE *fp;
char buf[BSZ]; memset(buf, 'a', BSZ-);
buf[BSZ-]='\0';
buf[BSZ-] = 'X';
printf("befor fmemopen initial buffer contents: ");pr_print(buf);
fp = fmemopen(buf, BSZ, "w+");
pr_offset(fp);
printf("after fmemopen initial buffer contents: ");pr_print(buf);
fprintf(fp, "hello, world"); /*此时fp标志在buf的起始位置*/
//pr_offset(fp);
printf("before flush: %s\n",buf);
fflush(fp);
printf("after fflush:");
pr_print(buf); /*本来buf的内容是aaaa...\0#,但是由于fprintf的操作hello world写到前面buf的前面几个位置,并且后面跟了一个\0*/
pr_offset(fp);
printf("len of string in buf = %ld\n", (long)strlen(buf)); memset(buf, 'b', BSZ-);
buf[BSZ-] = '\0';
buf[BSZ-] = 'X';
fprintf(fp, "hello, world");
pr_offset(fp);
fseek(fp, , SEEK_SET);
printf("after fseek:");
pr_offset(fp);
pr_print(buf);
printf("len of string in buf = %ld\n", (long)strlen(buf)); memset(buf, 'c', BSZ-);
buf[BSZ-] = '\0';
buf[BSZ-] = 'X';
fprintf(fp, "hello, world");
fclose(fp);
printf("after fclose:");
pr_print(buf);
printf("len of string in buf = %ld\n", (long)strlen(buf)); return();
}
代码执行结果如下:
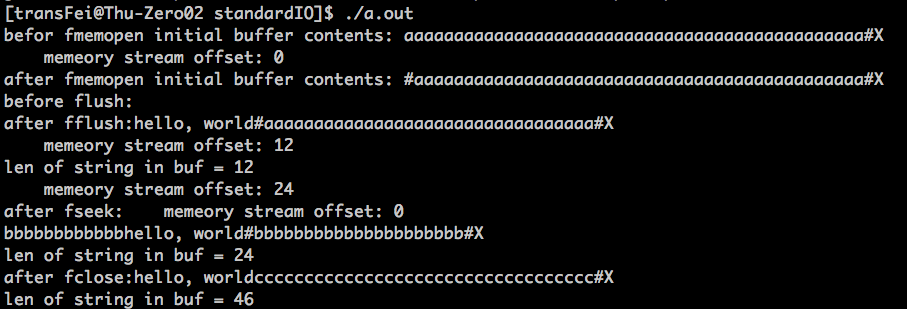
上述代码在书上5.15的例子基础上做了修改,原因是更好的理解各种操作对实际内存数据的影响。
这里有个点需要明确:printf函数在输出内存中字符串的时候,如何判断字符串结束了?首次遇见'\0'就认为字符串结束了。
下面按照执行顺序来分析为:
1. memset()之后,以buf为起始地址的内存字符串都被赋值为'a'了。
2. 执行fmemopen,将buf以w+的方式关联到一个FILE *类型变量fp上。这个时候,看书上P171的阐述,以‘w+’这种方式打开的时候,""truncate to 0 length and open for writing"。
(1)为了验证书上这句话,我调用了DIY的函数pr_offset,来查看此时current file position(具体ftell函数,可以参考书上P158),stream offset确实是0。
(2)那么stream offset是0意味着什么呢?我调用了DIY的函数pr_print函数,逐个输出buf开始的BSZ个字符:发现原来的首个字符'a'变成了'\0',客观上在我实验的环境中就是这样。
3. 执行fprintf函数,向fp指向的buf写“hello, world”12个byte。但是这个写并不会马上写进去:
(1)执行fflush之前,buf的首个字符还是'\0',因此用printf函数输出buf,自然什么都不会输出。
(2)执行fflush之后,fp的内容被写进去了;调用pr_print函数可以看到"hello, world"被写进去了,并且紧接着还写进去了一个'\0';此时fp的offset变成了12,而且用strlen函数去统计buf的长度也是12。由此可见fprintf的工作方式,而且可以看到strlen的实现也差不多是根据第一个遇见的'\0'来统计字符串长度的。
4. 现在另起炉灶,把buf后面的BSZ长度的字符都设成'b'了。
(1)还是调用fprintf往fp里面再写一次“hello, world”;注意,此时fp的offset是12,跟执行memset没有关系,此时执行过第二次写“hello, world”之后,fp的offset变成了24。
(2)此时,执行fseek,将fp的offset移动到0,并用pr_offset函数验证。
(3)再次输出buf起始的BSZ个字符,发现“hello, world"确实从第13个位置写到了第24个位置,并且在末尾跟上了一个'\0',验证了上面的分析。
5. 再次处理一下,把buf后面的BSZ长度的字符都设成'c'了。
(1)先明确一点,此时fp的offset虽然恢复0了,但是fp关联的memory stream的amount of data还是24个字符,这一点比较关键。
(2)此时还是fprintf往fp里面写"hello, world"12个字符,随后把fp关掉。
(3)此时,再用pr_print逐个输出buf起始的BSZ个字符,发现了一个与之前不同的地方,即"hello, world"的后面没有在跟着一个'\0'。回想(1)中提到的,此时fp关联的memory steam的amount还是48,如果从0开始写12个byte,并不会改变整个memory stream的amount,因此后面就没有再跟着'\0'了,这也就解释了最后的一组输出。
6. 如果我们将上述代码的30行的屏蔽符号去掉,在执行代码,会得到以下结果:
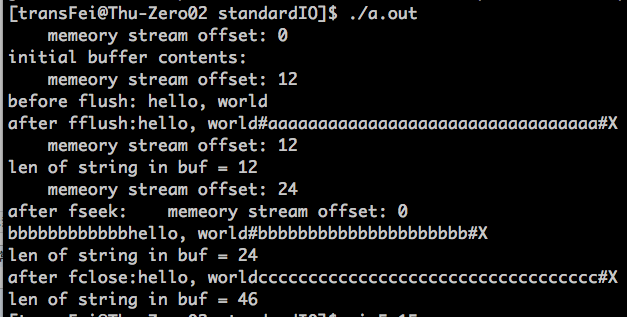
这里只需要注意before flush后面的输出即可:为什么没有用fflush,还是刷出来了buf呢?
我猜,这是因为ftell(fp)中有刷新fp的操作,所以相当于隐藏着调用了一个fflush了。
这个memory streams一开始看的并不清晰,主要是不明确printf的实现原理,遇到'\0'不输出后面的type了。所以,掌握这些基础函数的原理对提高工作效率比较有帮助。
【APUE】Chapter5 Standard I/O Library的更多相关文章
- 【APUE】Chapter10 Signals
Signal主要分两大部分: A. 什么是Signal,有哪些Signal,都是干什么使的. B. 列举了非常多不正确(不可靠)的处理Signal的方式,以及怎么样设计来避免这些错误出现. 10.2 ...
- 【APUE】Chapter8 Process Control
这章的内容比较多.按照小节序号来组织笔记的结构:再结合函数的示例带代码标注出来需要注意的地方. 下面的内容只是个人看书时思考内容的总结,并不能代替看书(毕竟APUE是一本大多数人公认的UNIX圣经). ...
- 【贪心】codeforces B. Heidi and Library (medium)
http://codeforces.com/contest/802/problem/B [题意] 有一个图书馆,刚开始没有书,最多可容纳k本书:有n天,每天会有人借一本书,当天归还:如果图书馆有这个本 ...
- 【贪心】codeforces A. Heidi and Library (easy)
http://codeforces.com/contest/802/problem/A [题意] 有一个图书馆,刚开始没有书,最多可容纳k本书:有n天,每天会有人借一本书,当天归还:如果图书馆有这个本 ...
- 【APUE】Chapter1 UNIX System Overview
这章内容就是“provides a whirlwind tour of the UNIX System from a programmer's perspective”. 其实在看这章内容的时候,已经 ...
- 【转】Unable to load native-hadoop library for your platform(已解决)
1.增加调试信息寻找问题 2.两种方式解决unable to load native-hadoop library for you platform 附:libc/glibc/glib简介 参考: 1 ...
- 【APUE】Chapter15 Interprocess Communication
15.1 Introduction 这部分太多概念我不了解.只看懂了最后一段,进程间通信(IPC)内容被组织成了三个部分: (1)classical IPC : pipes, FIFOs, messa ...
- 【APUE】Chapter3 File I/O
这章主要讲了几类unbuffered I/O函数的用法和设计思路. 3.2 File Descriptors fd本质上是非负整数,当我们执行open或create的时候,kernel向进程返回一个f ...
- 【APUE】Chapter7 Process Environment
这一章内容是Process的基础准备篇章.这一章的内容都是基于C Programm为例子. (一)进程开始: kernel → C start-up rountine → main function ...
随机推荐
- LA 3353 最优巴士线路设计
给出一个 n 个点的有向图,找若干个圈,是的每个结点恰好属于一个圈.要求总长度尽量小. 三倍经验题 Uva 12264,HDU 1853 这题有两种解法,一是匹配: 每个点只在一个圈中,则他有唯一的前 ...
- hiho 第155周 任务分配
最小路径覆盖会超时: 贪心思路: 按照开始时间排序,然后根据结束时间,维护一个以结束时间的单调递增的队列,每次与最快结束的任务进行比较即可: /* #include <cstdio> #i ...
- luogu P2124 奶牛美容
嘟嘟嘟 首先数据范围那么小,那么算法也是相当暴力的. 对于一个点(x, y)所属的联通块,预处理出从这个点出发到这个块外的所有点的曼哈顿距离.复杂度O(n4). 然后求答案:最少答案不一定是三个联通块 ...
- 2018.11.1 Hibernate中的Mapper关系映射文件
Customer.hbm.xml 基本的参数都在里面了 <?xml version="1.0" encoding="UTF-8"?> <!DO ...
- <知识整理>2019清北学堂提高储备D3
全天动态规划入门到入坑... 一.总概: 动态规划是指解最优化问题的一类算法,考察方式灵活,也常是NOIP难题级别.先明确动态规划里的一些概念: 状态:可看做用动态规划求解问题时操作的对象. 边界条件 ...
- python+requests实现接口测试 - get与post请求使用
简介:Requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库.它比 urllib 更加方便,可以节约我们大量的工作,完全满足 ...
- js 原生获取Class元素
function getElementsByClassName(n) { var classElements = [] allElements = document.getElementsByTagN ...
- 【luogu P2746 [USACO5.3]校园网Network of Schools】 题解
题目链接:https://www.luogu.org/problemnew/show/P2812 注意:判断出入度是否为0的时候枚举只需到颜色的数量. 坑点:当只有一个强连通分量时,不需要再添加新边. ...
- 关闭Debut.Log
unity5.3支持了运行时关闭产生的debug.log Debug.logger.logEnabled = false; 谢谢你们,让我能在晚上凝视夜空的时候,脑海中浮现出更广阔的世界.
- Java数据结构的实现
1.基于数组的链表 package array; import java.util.Arrays; /** * 基于数组的链表 * * @author 王彪 * */ public class MyA ...