自定义数据类型写入SequenceFile并读出
开头对这边博客的内容做个概述,首先是定义了一个DoubleArrayWritable的类,用于存放矩阵的列向量,然后将其作为value写入SequenceFile中,key就是对应的矩阵的列号,最后(key,value)从SequenceFile中读出,与另一矩阵做乘法。完全通过IDEA在本地调试程序,并未提交集群。一般来说是将hadoop-core-1.2.1.jar和lib目录下的commons-cli-1.2.jar两个包加入到工程的classpath中就可以了,不过仅仅添加这两个包,调试的时候会提示找不到某些类的定义,所以索性将hadoop-core-1.2.1.jar和lib目录下的所有jar包均添加到工程的classpath中,这样完全不必提交到集群就可以在本地调试程序。
1)首先是定义DoubleArrayWritable类,这个类继承与ArrayWritable。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.ArrayWritable;
public class IntArrayWritable extends ArrayWritable {
public IntArrayWritable(){
super(IntWritable.class);
}
}
因为要读取SequenceFile中的(key,value)传给map,所以需要以4-6的形式显示定义构造函数。
2)然后是将DoubleArrayWritable类型的对象作为value写入SequenceFile,使用SequenceFile.writer
/**
* Created with IntelliJ IDEA.
* User: hadoop
* Date: 16-3-4
* Time: 上午10:36
* To change this template use File | Settings | File Templates.
*/
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.ArrayWritable;
public class SequenceFileWriterDemo {
public static void main(String[] args) throws IOException {
String uri="/home/hadoop/2016Test/SeqTest/10IntArray";
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(URI.create(uri),conf);
Path path=new Path(uri);
IntWritable key=new IntWritable();
IntArrayWritable value=new IntArrayWritable();//定义IntArrayWritable类型的alue值。
value.set(new IntWritable[]{new IntWritable(1),new IntWritable(2),new IntWritable(3),
new IntWritable(4)});
SequenceFile.Writer writer=null;
writer=SequenceFile.createWriter(fs,conf,path,key.getClass(),value.getClass());
int i=0;
while(i<10){
key.set(i++);
//value.set(intArray);
writer.append(key,value);
}
writer.close();//一定要加上这句,否则写入SequenceFile会失败,结果是一个空文件。
System.out.println("done!");
}
}
class IntArrayWritable extends ArrayWritable {
public IntArrayWritable(){
super(IntWritable.class);
}
}
这就完成了一个10行4列的矩阵写入SequenceFile文件在,其中key是矩阵行号,value是IntArrayWritable类型的变量。
3)将生成的SequenceFile上传到集群,然后查看其内容,使用命令(需要将IntArrayWritable类打包并将其路径加入到hadoop_env.sh中HADOOP_CLASSPATH中)如下:
hadoop fs -text /testData/10IntArray
结果如下:
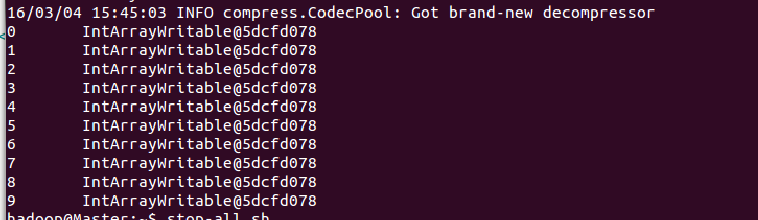
好像哪里不对?应该是[1,2,3,4]数组呀。其实是对的,写入SequenceFile中时就是将”活对象“持久化存储的过程,也就是序列化,所以当我们以文本的方式(-text)打开文件时,就看到了IntArrayWritable...的形式。如果想要看数组也可以,反序列化就好了。
4)使用SequenceFile.reader读取上述SequenceFile文件的内容,我要看到数组~~~,代码如下:
/**
* Created with IntelliJ IDEA.
* User: hadoop
* Date: 16-3-4
* Time: 下午5:41
* To change this template use File | Settings | File Templates.
*/
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.SequenceFile;
//import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.util.ReflectionUtils; import java.io.IOException;
import java.net.URI; public class SequencefileReaderDemo {
public static void main(String[] args) throws IOException {
String uri="/home/hadoop/2016Test/SeqTest/10IntArray";
Configuration conf=new Configuration();
FileSystem fs =FileSystem.get(URI.create(uri),conf);
Path path=new Path(uri);
SequenceFile.Reader reader=null;
try {
reader=new SequenceFile.Reader(fs,path,conf);
Writable key =(Writable)ReflectionUtils.newInstance(reader.getKeyClass(),conf);
IntArrayWritable value=(IntArrayWritable)ReflectionUtils.newInstance(reader.getValueClass(),conf);
long position=reader.getPosition();
String[] sValue=null;
while(reader.next(key,value)){
String syncSeen=reader.syncSeen()?"*":"";
sValue=value.toStrings();
System.out.printf("[%s%s]\t%s\t%s\t",position,syncSeen,key,value);
for (String s:sValue){
System.out.printf("%s\t", s);
}
System.out.println();
position=reader.getPosition();
}
}
finally {
IOUtils.closeStream(reader);
}
} }
运行结果如下:
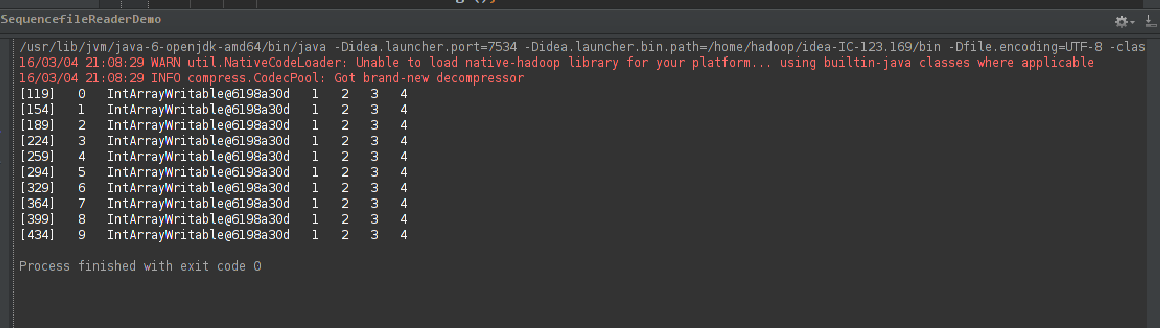
5)最后,利用上述生成的SequenceFile文件作为左矩阵,写一个MR程序计算矩阵的乘法,代码如下:
/**
* Created with IntelliJ IDEA.
* User: hadoop
* Date: 16-3-4
* Time: 上午10:34
* To change this template use File | Settings | File Templates.
*/
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat; import java.io.IOException;
import java.lang.reflect.Array;
import java.net.URI; public class MRTest {
public static class MyMapper extends Mapper<IntWritable,IntArrayWritable,IntWritable,IntArrayWritable>{
public static int[][] rightMatrix=new int[][]{{10,10,10,10,10},{10,10,10,10,10},{10,10,10,10,10},{10,10,10,10,10}};
public IntWritable key=new IntWritable();
public IntArrayWritable value=new IntArrayWritable();
//public IntWritable[] valueInput=null;
public Object valueObject=null;
public IntWritable[] arraySum=new IntWritable[rightMatrix[0].length];
public int sum=0;
public void map(IntWritable key,IntArrayWritable value,Context context) throws IOException, InterruptedException {
valueObject=value.toArray();//value.toArray的返回值是一个Object类型的对象,但是Object内部值是数组呀
//使用Array.get(valueObject,3)可以得到数组中第4个元素,然后将其转化为string,再使用
//Integer.parseInt(str)将其转化为整型值.
for (int i=0;i<rightMatrix[0].length;++i){
sum=0;
for (int j=0;j<rightMatrix.length;++j){
sum+=(Integer.parseInt(((Array.get(valueObject,j)).toString())))*rightMatrix[j][i];
}
arraySum[i]=new IntWritable(sum);
}
value.set(arraySum);
context.write(key,value);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
String uri="/home/hadoop/2016Test/SeqTest/10IntArray";
String outUri="/home/hadoop/2016Test/SeqTest/output";
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(URI.create(uri), conf); fs.delete(new Path(outUri),true);//输出目录存在的话就将其删除。 Job job=new Job(conf,"SeqMatrix");
job.setJarByClass(MRTest.class);
job.setMapperClass(MyMapper.class);
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntArrayWritable.class);
FileInputFormat.setInputPaths(job,new Path(uri));
FileOutputFormat.setOutputPath(job,new Path(outUri));
System.exit(job.waitForCompletion(true)?0:1);
} }
其中,使用Array.get(object,index)从包含数组的Object对象内部获得数组值的方法参考了:http://www.blogjava.net/pengpenglin/archive/2008/09/04/226968.html
最后的计算结果如下:
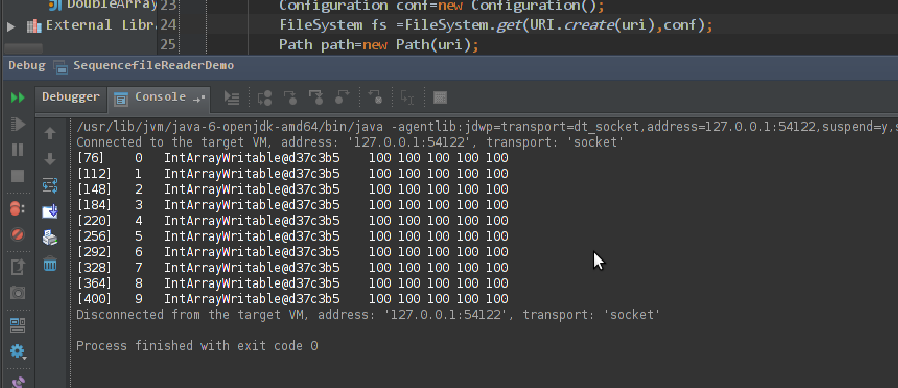
自定义数据类型写入SequenceFile并读出的更多相关文章
- Oracle自定义数据类型 1
原文 oracle 自定义类型 type / create type 一 Oracle中的类型 类型有很多种,主要可以分为以下几类: 1.字符串类型.如:char.nchar.varchar2.nva ...
- 通过SQL Server自定义数据类型实现导入数据
写在前面 在看同事写的代码时看到了SQL Server中可以自定义数据类型,而且定义的是DataTable类型的数据类型. 后我想起了以前我们导入数据时要么是循环insert写入,要么是SqlBulk ...
- 如何在Qt中使用自定义数据类型
这里我们使用下面这个struct来做说明(这里不管是struct还是class都一样): struct Player { int number; QString firstName; QString ...
- hadoop的自定义数据类型和与关系型数据库交互
最近有一个需求就是在建模的时候,有少部分数据是postgres的,只能读取postgres里面的数据到hadoop里面进行建模测试,而不能导出数据到hdfs上去. 读取postgres里面的数据库有两 ...
- OSG 自定义数据类型 关键帧动画
OSG 自定义数据类型 关键帧动画 转自:http://blog.csdn.net/zhuyingqingfen/article/details/12651017 /* 1.创建一个AnimManag ...
- Oracle存储过程-自定义数据类型,集合,遍历取值
摘要 Oracle存储过程,自定义数据类型,集合,遍历取值 目录[-] 0.前言 1.Packages 2.Packages bodies 3.输出结果 0.前言 在Oracle的存储过程中,可能会遇 ...
- Hadoop-MapReduce之自定义数据类型
以下是自定义的一个数据类型,有两个属性,一个是名称,一个是开始点(可以理解为单词和单词的位置) MR程序就不写了,请看WordCount程序. package cn.genekang.hadoop.m ...
- Sql Server 自定义数据类型
SQLServer 提供了 25 种基本数据类型: ·Binary [(n)] 二进制数据 既可以是固定长度的(Binary),也可以是变长度的.其中,n 的取值范围是从 1 到 8000.其存储窨 ...
- 初识Haskell 五:自定义数据类型和类型类
对Discrete Mathematics Using a Computer的第一章Introduction to Haskell进行总结.环境Windows 自定义数据类型 data type de ...
随机推荐
- 使用UMeditor富文本编辑器上传图片
注:本文系作者原创,但可随意转载. 最近写自己的网站玩儿,写到博客的部分,打算使用UMeditor,因为之前也用过(但是好像没实现图片上传的功能),感觉用起来还比较简单. 不过还是折腾了一下午...遇 ...
- webpack 引入 html-webpack-plugin 报错
配置webpack当中,出现一个问题: 引入html-webpack-plugin 插件报错. 这时需要本地(也就是当前项目下)安装一下webpack就可以解决问题了. 注意:现在是webpack4版 ...
- 精通javascript笔记(智能社)——简易tab选项卡及应用面向对象方法实现
javascript代码(常规方式/面向过程): <script type="text/javascript"> window.onload=function(){ v ...
- codeforces739C - Skills &&金中市队儿童节常数赛
http://codeforces.com/problemset/problem/739/C 先上链接 这道题 对于蒟蒻的我来说还是很有难度的 调了很久 对于我的代码 mx2是答案 mx1代表单调 m ...
- 网络流专题练习Day2
04/17 目前做了:题 由于目前六道都是1A感觉非常爽... BZOJ1412: [ZJOI2009]狼和羊的故事 “狼爱上羊啊爱的疯狂,谁让他们真爱了一场:狼爱上羊啊并不荒唐,他们说有爱就有方向 ...
- [BZOJ1025] [SCOI2009]游戏 解题报告
Description windy学会了一种游戏.对于1到N这N个数字,都有唯一且不同的1到N的数字与之对应.最开始windy把数字按顺序1,2,3,……,N写一排在纸上.然后再在这一排下面写上它们对 ...
- mysqli_insert_id
mysqli_insert_id($mysqli),这个函数一开始我用的时候老是返回0,疯掉了,百度了n次,问了n个人,搞了几天,就是解决不了,最后我把他换成面对对象编程,终于成功了,开心,也许这就是 ...
- 01-modal
Demo示例程序源代码
源代码下载链接:01-modal.zip37.8 KB // MJAppDelegate.h // // MJAppDelegate.h // 01-modal // // Created by ...
- 之江学院第0届校赛 qwb与支教 (容斥公式)
description qwb同时也是是之江学院的志愿者,暑期要前往周边地区支教,为了提高小学生的数学水平.她把小学生排成一排,从左至右从1开始依次往上报数. 玩完一轮后,他发现这个游戏太简单了.于是 ...
- python-列表 字典 集合 元祖 字符串的相关总结练习
1.执行python脚本的两种方式指定解释器执行在交互器中执行 2.简述位.字节的关系:ASCII1个二进制位是计算机里的最小表示单元1个字节是计算机里最小的储存单元二进制位=8bits(位)8bit ...