k-近邻算法 标签分类
k-近邻算法根据特征比较,然后提取样本集中特征最相似数据(最邻近)的分类标签。那么,如何进行比较呢?
怎么判断红色圆点标记的电影所属的类别呢? 如下图所示。
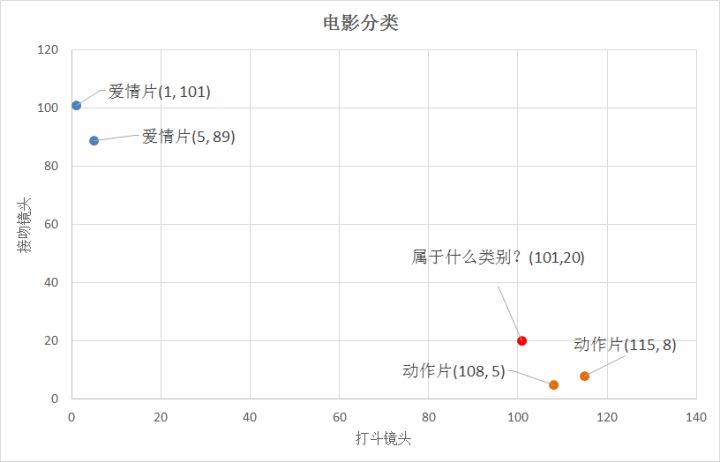
答:距离度量。这个电影分类的例子有2个特征,也就是在2维实数向量空间,可以使用两点距离公式计算距离,如图所示。
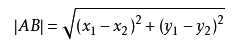
k-近邻算法步骤如下:
- 1.计算已知类别数据集中的点与当前点之间的距离;
- 2.按照距离递增次序排序;
- 3.选取与当前点距离最小的k个点;
- 4.确定前k个点所在类别的出现频率;
- 5.返回前k个点所出现频率最高的类别作为当前点的预测分类。
接下来就是使用Python3实现该算法,以电影分类为例。
(1)准备数据集
(2)k-近邻算法
根据两点距离公式,计算距离,选择距离最小的前k个点,并返回分类结果。
# -*- coding: utf-8 -*-
"""
k-近邻算法
标签分类
group:数据集
lables:标签分类
"""
import numpy as np
import operator
def createDataSet():
#四组二维特征
group = np.array([[1,101],[5,89],[108,5],[115,8]])
#四组特征的标签
labels = ['爱情片','爱情片','动作片','动作片']
return group,labels
# =============================================================================
# if __name__ == '__main__':
# #创建数据集
# group, labels = createDataSet()
# print(group)
# print(labels)
# =============================================================================
"""
k-近邻算法
根据两点距离公式,计算距离,选择距离最小的前k个点,并返回分类结果。
"""
def classify0(inX,dataSet, labels,k):
#numpy函数shape[0]返回dataSet的行数
dataSetSize = dataSet.shape[0]
#print("dataSetSize:",dataSetSize)
#np.tile()表示:在行方向上重复inX数据共1次,在列方向重复inX共dataSetSize次
diffMat = np.tile(inX,(dataSetSize,1)) - dataSet
#二维特征相减后平方
sqDiffMat = diffMat**2
#print(sqDiffMat)
#sum()表示所有元素相加,sum(0)列向量相加,sum(1)行向量分别相加
sqDistances = sqDiffMat.sum(axis = 1)
#print(sqDistances)
#开方求距离
distances = sqDistances**0.5
print(distances)
#argsort()返回的是distances中元素从小到大排序的索引值
sortedDistIndicies = distances.argsort()
print("sortedDostIndicies=",sortedDistIndicies)
#定义一个记录类别次数的字典
classCount = {}
for i in range(k):
print("sortedDistIndicies[",i,"] = ",sortedDistIndicies[i])
voteIlabel = labels[sortedDistIndicies[i]] #排名前k个贴标签
print("voteIlabel=",voteIlabel)
#dict.get(key,defualt = None),字典的get()方法,返回指定键的值,如果值不在字典中,返回默认值
#计算类别次数
#print ("类别 次数:",classCount.get(voteIlabel,0))
classCount[voteIlabel] = classCount.get(voteIlabel,0)+1 #不断累加计数的过程,体现在字典的更新中
print("classCount[",voteIlabel,"]为 :",classCount[voteIlabel])
#python3中用items()替换python2中的iteritems()
#key = operator.itemgetter(1)根据字典的值进行排序
#key = operator.itemgetter(0)根据字典的键进行排列
#reverse降序排列字典
sortedClassCount = sorted(classCount.items(),key = operator.itemgetter(1),reverse = True)
print("sortedClassCount: ",sortedClassCount)
#返回出现次数最多的value的key
return sortedClassCount[0][0]
if __name__ == '__main__':
#创建数据集
group,labels = createDataSet()
test = [101,20]
#KNN分类
test_class = classify0(test,group,labels,3)
#打印分类结果
print(test_class)
----------------------------------------------------------------------------------------------
# 实现 classify0() 方法的第二种方式
---------------------------------------------------------------------------------------------
# """
# 1. 计算距离
# 欧氏距离: 点到点之间的距离
# 第一行: 同一个点 到 dataSet的第一个点的距离。
# 第二行: 同一个点 到 dataSet的第二个点的距离。
# ...
# 第N行: 同一个点 到 dataSet的第N个点的距离。
# [[1,2,3],[1,2,3]]-[[1,2,3],[1,2,0]]
# (A1-A2)^2+(B1-B2)^2+(c1-c2)^2
# inx - dataset 使用了numpy broadcasting,见 https://docs.scipy.org/doc/numpy-1.13.0/user/basics.broadcasting.html
# np.sum() 函数的使用见 https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.sum.html
# """
# dist = np.sum((inx - dataset)**2, axis=1)**0.5
# """
# 2. k个最近的标签
# 对距离排序使用numpy中的argsort函数, 见 https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.sort.html#numpy.sort
# 函数返回的是索引,因此取前k个索引使用[0 : k]
# 将这k个标签存在列表k_labels中
# """
# k_labels = [labels[index] for index in dist.argsort()[0 : k]]
# """
# 3. 出现次数最多的标签即为最终类别
# 使用collections.Counter可以统计各个标签的出现次数,most_common返回出现次数最多的标签tuple,例如[('lable1', 2)],因此[0][0]可以取出标签值
# """
# label = Counter(k_labels).most_common(1)[0][0]
# return label
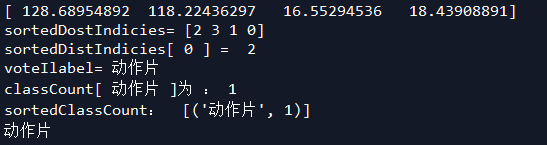
输出结果:
参考来源:
k-近邻算法 标签分类的更多相关文章
- 02-19 k近邻算法(鸢尾花分类)
[TOC] 更新.更全的<机器学习>的更新网站,更有python.go.数据结构与算法.爬虫.人工智能教学等着你:https://www.cnblogs.com/nickchen121/ ...
- 【机器学习】K近邻算法——多分类问题
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该类输入实例分为这个类. KNN是通过测量不同特征值之间的距离进行分类.它的的思路是:如 ...
- 第4章 最基础的分类算法-k近邻算法
思想极度简单 应用数学知识少 效果好(缺点?) 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 distances = [] for x_train in X_train ...
- 02-16 k近邻算法
目录 k近邻算法 一.k近邻算法学习目标 二.k近邻算法引入 三.k近邻算法详解 3.1 k近邻算法三要素 3.1.1 k值的选择 3.1.2 最近邻算法 3.1.3 距离度量的方式 3.1.4 分类 ...
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
- 分类算法----k近邻算法
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- python 机器学习(二)分类算法-k近邻算法
一.什么是K近邻算法? 定义: 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. 来源: KNN算法最早是由Cover和Hart提 ...
- 机器学习实战笔记--k近邻算法
#encoding:utf-8 from numpy import * import operator import matplotlib import matplotlib.pyplot as pl ...
随机推荐
- MFC多国语言——配置文件
前段时间,因工作需要,本地化了一个英文版本的产品. 在网上查阅了若干资料,在此进行一个简单的整理. 在MFC程序中,实现多国语言的方式很多,我们选择的是使用配置文件的方法. 在通过配置文件方式实现多国 ...
- hdu 1078 FatMouse and Cheese【dp】
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1078 题意:每次仅仅能走 横着或竖着的 1~k 个格子.求最多能吃到的奶酪. 代码: #include ...
- Python_Selenium之鼠标右键
Python_Selenium之鼠标右键 一.步骤: (以百度为例)获取百度网址 找到需要右键的元素(定位),xpath表达式为“//*[@id='lg']/img” 然后,右键选择“在新标签页中打开 ...
- python3----连接字符串数组(join)
join 方法用于连接字符串数组 s = ['a', 'b', 'c', 'd'] print(''.join(s)) print('-'.join(s)) results: abcd a-b-c-d ...
- Android错误——基础篇
1. Android工程在真机上运行调试: 花了二个小时的时间来把App热部署到小米机上,简直让我寒透了心, 原本是按照网上提供的步骤一步步的做着,没想到小米神机居然出的是什么内测小米助手,两个窗口来 ...
- [ACM] hdu 3923 Invoker (Poyla计数,高速幂运算,扩展欧几里得或费马小定理)
Invoker Problem Description On of Vance's favourite hero is Invoker, Kael. As many people knows Kael ...
- redis string底层数据结构sds
redis的string没有采用c语言的字符串数组而采用自定义的数据结构SDS(simple dynamic string)设计 len 为字符串的实际长度 在redis中获取字符串的key长度的时 ...
- Sql注入基础一
凡是带入数据库查询的都有可能是注入. 整个数据包 Sql注入原理? 网站数据传输中,接受变量传递的值未进行过滤,导致直接带入数据库查询执行的操作问题. Sql注入对于渗透的作用? 获取数据(网 ...
- MySql 的备份与恢复
1. 数据库导出 SQL 脚本 mysqldump -u 用户名 -p 密码 数据库名称>生成的脚本文件路径 示例: mysqldump -uroot -p 123 mydb1>/User ...
- python基础:while循环,for循环
---恢复内容开始--- 1.使用while循环输出1 2 3 4 5 6 8 9 10 2.求1-100的所有数的和 3.输出 1-100 内的所有奇数 4.输出 1-100 内的所有偶数 ...