HBase-存储-文件
文件
HBase使用一个HDFS中可配置的根目录,默认设为“/hbase”。可使用hadoop fs -lsr /hbase查看目录结构,文件可以被分为两类,一类位于HBase根目录下,另一类位于根目录中的表目录下。
Flush命令可以将内存中的数据写到存储文件中,否则就必须等插入的数据达到配置的刷写大小。
1.根级文件
第一组文件是被HLog实例管理的WAL文件,这些日志文件被创建在HBase的根目录下一个名为.logs的目录中。对于每个HRegionServer,日志目录中都包含一个对应的子目录。在每个子目录中有多个HLog文件(因为日志滚动)。一个region服务器的所有region共享同一组HLog文件。
由于HDFS使用内置的append机制来追加写入日志文件,所以只有等到文件大小达到一个完整的块时,文件对用户才是可见的—包括hadoop fs -lsr命令。虽然put操作的数据被安全持久化了,但当前写入日志文件的数据大小是稍微偏离的。
当所有包含的修改都被持久化到存储文件中,从而不再需要日志文件时,它们会被放到HBase根目录下的.oldlogs目录中。当条件满足配置上的阈值会触发日志的滚动。在十分钟后,旧的日志文件将被master删除,这是通过hbase.master.logcleaner.ttl属性设置的。Master
2.表级文件
在HBase中,每张表都有自己的目录,其位于文件系统中HBase根目录下。每张表目录包括一个名为.tabledesc的顶层文件,该文件存储表对应序列化后的HTableDescriptor。其中包括表和列族的定义,同时其内容也可以被读取。
3.region级文件
在每张表的目录里面,表模式中每个列族都有一个单独的目录。目录的名字是一部分region名字的MD5散列值。
Region文件的总体结构是
/<hbase-root-dir>/<tablename>/<encoded-regionname>/<column-family>/<filename> /apps/hbase/data/data/hbase/namespace/d25b2b8cb0d3d1c538437c1b89b8f8c8/info/7aef732982e04b77b7ee2a0ef9d7adc3
可以在每个列族目录中看到实际的数据文件。
Region目录中也有一个.regioninfo文件,这个文件包含了对应region的HRegionInfo实例序列化后的信息。与.tabledesc文件类似,它能被外部工具用来查看region的相关信息。例如,HBase的hbck工具就用它来检查并生成元数据表中丢失的条目。
可选的.tmp目录是按需求创建的,它被用来存放临时文件,例如,一次合并的重写文件。一旦这个过程完成,这些临时生成的文件通常会被移到region目录中。
在WAL回放时,任何未提交的修改都会被写入到每个region的一个单独的文件中。以上是第一步,然后如果日志拆分过程已经成功完成,这些文件将被自动移动到临时的recovered.edits目录中。当region被打开时,region服务器将会看到需要恢复的文件,并且回放其中相应的条目。
一旦region超过了配置中region大小的最大值,region就需要拆分,其会创建一个对应的splits目录,它被用来临时存放两个子region相关的数据。如果拆分过程成功,之后它们会被移动到表目录中,并形成两个新的region,每个region代表原始region的一半。
当看到一个region的目录中没有.tmp目录,这就意味着还没有进行过压缩操作。如果没有recovered.edits目录,这就意味着WAL还没有进行过回放操作。
4.region拆分
当一个region里的存储文件增长到大于配置的hbase.hregion.max.filesize大小或者在列族层面配置的大小时,region会被一分为二。这个过程通常非常迅速,因为系统只是为新region创建了两个对应的文件,每个region是原始region的一半。
Region服务器通过在父region中创建splits目录来完成这个过程。接下来关闭该region,此后这个region不再接受任何请求。
然后region服务器通过在splits目录中设立必须的文件结构来准备新的子region(使用多线程),包括新region目录和参考文件。如果这个过程成功完成,它将把两个新region目录移到表目录中。.META.表中父region的状态会被更新,以表示其现在拆分的节点和子节点是什么。以上过程可以避免父region被意外重新打开。
两个子region都准备好后,将会被同一个服务器并行打开。打开的过程包括更新.META.表,这样可以把两个region像其他region一样作为可用region列出来。之后这两个region会上线并开始服务请求。
同时也会初始化为两个region并对region中的内容执行合并,合并过程在替换引用文件之前会把父region的存储文件异步重写到两个子region中。以上过程会在子region的.tmp目录中执行。一旦生成了重写之后的文件,它们将自动取代引用文件。
最终父region会被清理掉,这意味着它在.META.表中的表项会被移除,并且它在磁盘上所有的文件都会被删除。最后,master被告知关于拆分的情况,并且可以由于负载均衡而把新region移动到其它region服务器上。
在拆分过程中,所有的步骤都在ZK中进行跟踪。这使得在一个服务器失效时,其它进程可以知道这个region状态。
5.合并
存储文件会被后台的管理进程仔细地监控起来以确保它们处于控制之下。随着memstore的刷写会生成很多磁盘文件。如果文件的数目达到阈值,合并(compaction)过程将把它们合并成数量更少的体积更大的文件。这个过程持续到这些文件中最大的文件超过配置的最大储存文件大小,此时会触发一个region拆分。
压缩合并有两种,即minor和major。Minor合并负责重写最后生成的几个文件到一个更大的文件中。文件数量是由hbase.hstore.compaction.min属性设置的。它的默认值为3,并且最小值需要大于或等于2.过大的数字将会延迟minor合并的执行,同时也会增加执行时消耗的资源及执行的时间。
Minor合并可以处理的最大文件数量默认为10,用户可以通过hbase.hstore.compaction.max来配置。Hbase.hstore.compaction.min.size(默认设置为region的memstore刷写大小)和hbase.hstore.compaction.max.size(默认设置为Long.MAX_VALUE)配置项属性进一步减少了需要合并的文件列表。任何比最大合并大小大的文件都会被排除在外。最小合并大小的功能稍有不同:它是一个阈值,而不是每个文件的限制。它包括所有小于限制的文件,直到到达每次压缩允许的总文件数量。
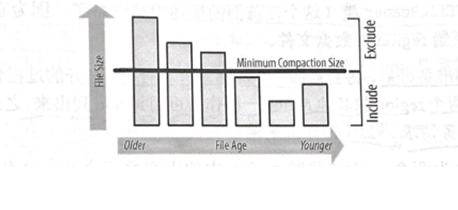
算法使用hbase.hstore.compaction.ratio(默认为1.2,或者120%)来确保在选择过程中包括足够的文件。经过跟新文件总的存储文件比较之后,这个比例仍将选择达到那个值的文件。评估总是按照从老文件到新文件的顺序来进行的,这样可以确保更老的文件首先被合并。这些属性的组合允许用户微调一个minor合并包括文件的数量。
HBase支持的另外一种合并是major合并:它们把所有文件压缩成一个单独的文件。在执行压缩检查时,系统自动决定运行哪种合并。在memstore被刷写到磁盘后会触发检查,或在shell命令compact、major_compact之后触发检查,或是相应API在被调用后触发检查,抑或是被一个异步的后台进程触发后。Region服务器运行这个进程,而其功能由CompactChecker类实现,它以一个固定的周期触发检查,这个周期由hbase.server.thread.wakefrequency参数控制(乘以hbase.server.thread.wakefrequency.multiplier,设为1000,这样它的执行频率不会像其他基于线程的任务那么频繁)。
除非用户使用shell命令major_compact或者使用majorCompact()这个API,将强制运行major合并,否则服务器会首先检查上次运行到现在是否达到hbase.hregion.majorcompaction(设为24小时)指定的时限。Hbase.hregion.majorcompaction.jitter(设为0.2,即20%)参数会将所有存储的时间周期分开。如果没有这个抖动,所有的存储文件都将在每24小时的同一时间运行一个major合并。
如果还没有达到major合并的执行周期,系统会选择minor合并执行。基于以上配置属性,服务器将检查是否有足够的文件供minor合并执行,如果有就继续。
当minor合并包括所有的存储文件,且所有文件均未达到设置的每次压缩的最大文件数时,minor合并可能被提升成major合并。
HBase-存储-文件的更多相关文章
- 用Hbase存储Log4j日志数据:HbaseAppender
业务需求: 需求很简单,就是把多个系统的日志数据统一存储到Hbase数据库中,方便统一查看和监控. 解决思路: 写针对Hbase存储的Log4j Appender,有一个简单的日志储存策略,把Log4 ...
- HBase存储剖析与数据迁移
1.概述 HBase的存储结构和关系型数据库不一样,HBase面向半结构化数据进行存储.所以,对于结构化的SQL语言查询,HBase自身并没有接口支持.在大数据应用中,虽然也有SQL查询引擎可以查询H ...
- hbase 存储结构和原理
HBase的表结构 建表时要指定的是:表名.列族 建表语句 create 'user_info', 'base_info', 'ext_info' 意思是新建一个表,名称是user_info,包含两个 ...
- HBase存储架构
以下的介绍是基于Apache Hbase 0.94版本: 从HBase的架构图上可以看出,HBase中的存储包括HMaster.HRegionServer.HRegion.Store.MemStore ...
- Hbase存储详解
转自:http://my.oschina.net/mkh/blog/349866 Hbase存储详解 started by chad walters and jim 2006.11 G release ...
- HBase存储及读写原理介绍
一.HBase介绍及其特点 HBase是一个开源的非关系型分布式数据库,它参考了谷歌的BigTable建模,实现的编程语言为Java.它是Apache软件基金会的Hadoop项目的一部分,运行于HDF ...
- File存储 - 文件存储
博客地址 http://www.cnblogs.com/mmyblogs/p/6107472.html(转载请保留) 文件存储 文件存储是 Android 中最基本的一种数据存储方式,它不对存储的内容 ...
- 23 HBase 存储架构。
个 Region,Region会下线,新Split出的2个子Region会被HMaster分配到相应的HRegionServer 上,使得原先1个Region的压力得以分流到2个Region上由此过程 ...
- Android数据存储-文件操作
一.预备知识 1.Android中的MVC设计模式 MVC (Model-View-Controller):M是指逻辑模型,V是指视图模型,C则是控制器.一个逻辑模型可以对于多种视图模型,比如一批统计 ...
- hbase存储优化
1.上面的2张图主要说明hbase的存储特点 (1).每个值(每条记录的每一个列的值)的存储,都完整的存储了rowkey.column family.column.版本(时间戳),以及该列的值. 这样 ...
随机推荐
- Python抓取网页并保存为PDF
https://blog.csdn.net/shenwanjiang111/article/details/67634794
- 32位Win7下安装与配置PHP环境(一)
运行PHP网站,主要需要安装.配置三个软件,Apache.PHP和MySQL.如果需要编辑调试PHP程序,还要安装一个编辑调试软件. 一. Apache Apache是和IIS类似的一个软件,是运行在 ...
- 清空javascript数组数据
var arrayObj = new Array(); arrayObj.splice(0, arrayObj.length);//清空数组数据
- mysql中对应oracle中的to_char()和to_number()函数
TO_CHAR(): CAST(123 AS CHAR(3)) TO_NUMBER(): cast( '123 ' as SIGNED INTEGER)
- this.$apply()
chooseVideo(e) { this.fileInfo = {} let that = this wx.chooseVideo({ sourceType: ['album', 'camera'] ...
- delphi局域网Ping各主机方法及设置本地ip方法
1. 首先引用winsock单元 function PingHost(HostIP: String): Boolean; type PIPOptionInformation=^TIPOptionInf ...
- python函数回顾:getattr()
描述 getattr() 函数用于返回一个对象属性值. 语法 getattr 语法: getattr(object, name[, default]) 参数 object -- 对象. name -- ...
- 实验一中的OOP思想
子类继承父类 父类中声明了接口变量 接口AB中声明了抽象方法 ab 在子类中 可以用这样通俗的语句写程序: while (!(this.termination.shouldTerminate ...
- Linux服务管理(开启关闭防火墙)
1.firewalld的基本使用 启动: systemctl start firewalld 关闭: systemctl stop firewalld 查看状态: systemctl status f ...
- 开机提示memory size decreased怎么办?
ytkah的办公电脑实在是hold不住,win7用2G的内存,基本是在等待中度过的,没有新的只能考虑加格内存了,采购嘛,需走一大堆流程,跟领导请示从其他硬件需求不是很高的电脑那边拔一根内存条吧,小C的 ...