Kafka Confluent
今天我们要讲的大数据公司叫作Confluent,这个公司是前LinkedIn员工出来后联合创办的,而创业的基础是一款叫作Apache Kafka的开源软件。
Confluen联合创始人Jun Rao即将在QCon北京2018分享Apache Kafka的前世今生和未来的相关话题。
在整个Hadoop的生态圈里,Kafka是一款非常特殊的软件。它由LinkedIn于2011年开源,并在2012年底从阿帕奇孵化器里面毕业,正式成为阿帕奇的顶级项目。
Kafka和其他的大数据平台都不同,它的主要目的不是数据的存储或者处理,而是用来做数据交换的。要更好地理解它是干什么的,我先谈一下数据库的日志文件。
数据库系统需要保证数据的稳定性,为了确保修改的数据能够写入库,通常会在更改数据之前先在磁盘里写一条日志文件,大致上的格式是“时间戳:做了什么操作”。如果此后因为故障导致数据本身没有被更改,系统可以根据日志文件一条一条地重新执行操作,让数据恢复到应该恢复的状态。
后来有人意识到,这个日志的恢复功能还可以充当数据复制。简单来说,如果两个数据库的初始状态相同,又按照同样的?顺序执行了一系列操作,那么最后的状态也相同。所以在数据库进行数据复制的时候,系统可以把日志文件从一个系统传输到另外一个系统,另外一边只要照着日志同样地执行一遍就好。
这个想法构成了大部分数据库的主从备份机制的核心,而Kafka则把这个机制充分发扬光大了。Kafka允许消费者和生产者注册进Kafka,其中生产者会产生日志,而消费者则消费产生的日志。整个系统允许多个消费者和多个生产者的注册,这就实现了公司内部不同数据源之间的数据交换。
Kafka作为开源产品是如此之成功,在整个Hadoop生态圈,乃至不用Hadoop,而是用其他数据源的产品里,它都可以用来进行数据的备份和交换。所以,我们可以看到几乎所有的互联网公司里都部署了Kafka。
2014年的时候,Kafka的三个主要开发人员从LinkedIn出来创业,开了一家叫?作Confluent的公司。和其他大数据公司类似,Confluent的产品叫作Confluent Platform。这个产品的核心是Kafka,分为三个版本:Confluent Open Source、Confluent Enterprise和Confluent Cloud。
Confluent Open Source是Confluent公司在Kafka上的一个增强版本,其主要增强的地方是:增加了一个REST代理,以便客户端可以使用HTTP连接;增加了对Java以外的语言的支持,比如C++、Python和.NET;增加了对Hadoop文件系统、亚马逊S3存储、JDBC等的连接的支持;最重要的是一个Schema Registry,这是对Kafka一个比较大的增强,它使得Kafka的数据流必须符合注册的Schema,从而增强了可用性。所有这些东西本身也都是开源的,这使得其他第三方在这个上面继续开发新功能成为了可能。
Confluent Enterprise是Confluent面向企业级应用的产品,里面增加了一个叫作Confluent Control Center的非开源产品。Confluent Control Center是一个对整个产品进行管理的控制中心,最主要的功能对这个Kafka里面各个生产者和消费者的性能监控。
Kafka作为一个非常重要的产品,已经在很多互联网企业里被作为关键组件部署了。而Kafka的性能监控也早就是一个非常重要的问题,Kafka本身并不自带性能监控平台,很多公司比如雅虎自己内部开发了这样的系统。但是Confluent开发的控制平台无疑应该是最可靠的,毕竟没有人比Kafka的开发者更了解自己的产品。可惜这个是收费产品,而且不开源。Confluent Enterprise同时还自带了数据自动负载平衡和跨数据中心数据复制的能力。
Confluent Cloud是Confluent Enterprise的云端托管服务,它增加了一个叫作云端管理控制台的组件。除此之外,按照Confluent的说法,其实没有什么差别。但是对于想要省心的用户来说,这个产品无疑是更好的选择。
Confluent的基本做法和Cloudera很像,主要的产品开源,但是控制中心这样的东西不开源,只有买了企业版才能够享受到。而两者不同的地方主要在于,Confluent同时提供了云端服务的版本。加上Confluent有基于S3的连接,这使得从亚马逊AWS读写数据都非常方便。
和Cloudera是Hadoop的集成商不同,Confluent主要还是围绕着不同数据源之间数据的交换这个任务而生的服务。Kafka在整个开源产品里面是一个非常特殊的存在,它没有什么竞争对手,又是各大企业的刚需,它在脱离了整个Hadoop生态圈以后依然非常有价值。
从这个角度来讲,Confluent毫无疑问有很多客户会买单。大部分企业都不可能只有一个数据源,当然谷歌这样的企业?除外。而Kafka给数据源之间的数据交换提供了统一的平台,而Confluent的企业级服务则让这个平台不但更好用了,而且更好管理了。
虽然说是同样的生意模式,用在不同的产品里,产生的结果却可能很不一样。Confluent作为一家公司,是否能够从Kafka这个数据交换平台里面跳出来继续扩张,这很难说。但是仅仅是把这一摊生意做好,也足以支撑Confluent成为一个估值不低的公司,养活自己应该是绰绰有余了。
基本模块
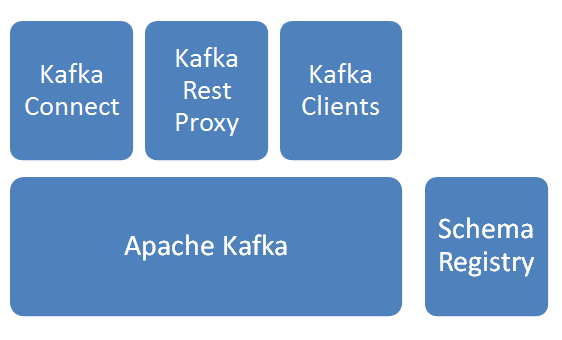
Apache Kafka
消息分发组件,数据采集后先入Kafka。Schema Registry
Schema管理服务,消息出入kafka、入hdfs时,给数据做序列化/反序列化处理。Kafka Connect
提供kafka到其他存储的管道服务,此次焦点是从kafka到hdfs,并建立相关HIVE表。Kafka Rest Proxy
提供kafka的Rest API服务。Kafka Clients
提供Client编程所需SDK。
说明:以上服务除Apache kafka由Linkedin始创并开源,其他组件皆由Confluent公司开发并开源。上图解决方案由confluent提供。
基本逻辑步骤
- 数据通过Kafka Rest/Kafka Client写入Kafka;
- kafka Connect任务作为consumer从kafka订阅数据;
- kafka Connect任务建立HIVE表和hdfs文件的映射关系;
- kafka connect任务收到数据后,以指定格式,写入指定hdfs目录;
Kafka Confluent的更多相关文章
- kafka - Confluent.Kafka
上个章节我们讲了kafka的环境安装(这里),现在主要来了解下Kafka使用,基于.net实现kafka的消息队列应用,本文用的是Confluent.Kafka,版本0.11.6 1.安装: 在NuG ...
- Tencent Cloud 腾讯云上部署 EMR Cluster + Kafka + Confluent (Schema-Registry)
腾讯云上有些操作比起 Amazon AWS 还是很方便的, 尤其部署EMR Cluster,下面详细介绍步骤:
- Oracle GoldenGate to Confluent with Kafka Connect
Confluent is a company founded by the team that built Apache Kafka. It builds a platform around Kafk ...
- kafka技术分享02--------kafka入门
kafka技术分享02--------kafka入门 1. 消息系统 所谓的Messaging System就是一组规范,企业利用这组规范在不同的系统之间传递语义准确对的消息,实现松耦合的异步数据 ...
- (转)消息队列 Kafka 的基本知识及 .NET Core 客户端
原文地址:https://www.cnblogs.com/savorboard/p/dotnetcore-kafka.html 前言 最新项目中要用到消息队列来做消息的传输,之所以选着 Kafka 是 ...
- kafka(一)入门
一.消息引擎系统 这类系统引以为豪的消息传递属性,像引擎一样,具备某种能量转换传输的能力 消息引擎系统是一组规范,企业利用这组规范在不同系统之间传递语义准确的消息,实现松耦合的异步式数据传递.通俗地讲 ...
- China .NET Conf 2019-.NET技术架构下的混沌工程实践
这个月的8号.9号,个人很荣幸参加了China.NET Conf 2019 , 中国.NET开发者峰会,同时分享了技术专题<.NET技术架构下的混沌工程实践>,给广大的.NET开发小伙伴介 ...
- Confluent Platform 3.0支持使用Kafka Streams实现实时的数据处理(最新版已经是3.1了,支持kafka0.10了)
来自 Confluent 的 Confluent Platform 3.0 消息系统支持使用 Kafka Streams 实现实时的数据处理,这家公司也是在背后支撑 Apache Kafka 消息框架 ...
- DataPipeline联合Confluent Kafka Meetup上海站
Confluent作为国际数据“流”处理技术领先者,提供实时数据处理解决方案,在市场上拥有大量企业客户,帮助企业轻松访问各类数据.DataPipeline作为国内首家原生支持Kafka解决方案的“iP ...
随机推荐
- linux挂载远程windows服务器上的ISO,给内网的服务器安装软件
原文: http://blog.csdn.net/chagaostu/article/details/45195817 给内网的服务器安装软件 直接用yum install XXX的话,会告知找不到源 ...
- mysql命令 SHOW TABLE STATUS LIKE '%city%'; 查看表的状态可以查看表的创建时间
show status like '%handler_read_key%'; #走索引的命令的数量. #查看存储引擎 mysql> show variables like '%engine%'; ...
- Oracle 数据库排错之 ORA-00600
[错误代码] ORA-00600 [问题描述] ORA-00600: [kcratr1_lastbwr]错误的处理办法 [问题分析] 出现该错误是因为系统强制关机造成的!症状为数据库无法打开! [问题 ...
- 第一百九十节,jQuery,编辑器插件
jQuery,编辑器插件 学习要点: 1.编辑器简介 2.引入 uEditor 编辑器(Editor),一般用于类似于 word 一样的文本编辑器,只不过是编辑为 HTML 格式的.分类纯 JS 类型 ...
- Struts2开发者模式
在Struts2开发中,这应该是第一个学习配置的值.为了启用 Struts 2 的开发模式,可以通过自动配置显著增加Struts2的开发速度和属性文件加载,以及额外的日志和调试功能. 注:自动重新加载 ...
- centos7 更换yum源为阿里云
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup curl -o /etc/yum.repos ...
- vue - audio标签
audio 标签 <audio :src="current_music" autoplay controls autoloop @end="next_song&qu ...
- Jmeter与LoadRunner 测试Java项目的坑
32位的JDK,Jmeter.bat 最大内存只能配置1G,测不了大并发,所以用Jmeter测试时一定要改成64位的Jmeter用LR测试java程序的时候必须用32位的JDK 环境变量 在path的 ...
- Android无线测试之—UiAutomator UiSelector API介绍之五
对象搜索—文本与描述 一.文本属性定位对象: 返回值 API 描述 UiSelector test(String text) 文本完全匹配 UiSelector testContains(String ...
- hdu 4262(线段树)
题目:有一个圈,可以从某个位置取球,给出原有的顺序,有三种操作,左旋一次,右旋一次,取球,要求按顺序取球,问需要操作多少次 显然操作是确定的,每次将目标球旋转过来,找出左旋和右旋操作少的,然后取球. ...